Le langage de programmation Rust
par Steve Klabnik, Carol Nichols et Chris Krycho, avec les contributions de la communauté Rust
Cette version du texte suppose que vous utilisez Rust 1.90.0 (publié le 18/09/2025) ou une version ultérieure avec edition = "2024" dans le fichier Cargo.toml de tous les projets afin de les configurer pour utiliser les conventions de l’édition 2024 de Rust. Consultez la section « Installation » du chapitre 1 pour les instructions d’installation ou de mise à jour de Rust, et consultez l’annexe E pour des informations sur les éditions.
Le format HTML est disponible en ligne à l’adresse https://doc.rust-lang.org/stable/book/ et hors ligne avec les installations de Rust effectuées avec rustup ; exécutez rustup doc --book pour l’ouvrir.
Plusieurs traductions communautaires sont également disponibles.
Ce texte est disponible en format papier et numérique chez No Starch Press.
🚨 Vous souhaitez une expérience d’apprentissage plus interactive ? Essayez une version différente du Rust Book, avec : des quiz, de la mise en surbrillance, des visualisations, et bien plus : https://rust-book.cs.brown.edu
Avant-propos
Le langage de programmation Rust a parcouru un long chemin en quelques courtes années, depuis sa création et son incubation par une petite communauté naissante de passionnés, jusqu’à devenir l’un des langages de programmation les plus appréciés et les plus demandés au monde. Avec le recul, il était inévitable que la puissance et les promesses de Rust attirent l’attention et gagnent du terrain dans la programmation système. Ce qui n’était pas inévitable, c’est la croissance mondiale de l’intérêt et de l’innovation qui a imprégné les communautés open source et catalysé une adoption à grande échelle dans tous les secteurs.
À ce stade, il est facile de pointer les merveilleuses fonctionnalités que Rust a à offrir pour expliquer cette explosion d’intérêt et d’adoption. Qui ne voudrait pas de la sûreté de la mémoire, et de performances rapides, et d’un compilateur convivial, et d’excellents outils, parmi une foule d’autres fonctionnalités remarquables ? Le langage Rust que vous voyez aujourd’hui combine des années de recherche en programmation système avec la sagesse pratique d’une communauté dynamique et passionnée. Ce langage a été conçu avec un objectif et élaboré avec soin, offrant aux développeurs un outil qui facilite l’écriture de code sûr, rapide et fiable.
Mais ce qui rend Rust véritablement spécial, ce sont ses racines dans l’autonomisation de vous, l’utilisateur, pour atteindre vos objectifs. C’est un langage qui veut que vous réussissiez, et le principe d’autonomisation traverse le cœur de la communauté qui construit, maintient et défend ce langage. Depuis la précédente édition de ce texte de référence, Rust s’est encore développé pour devenir un langage véritablement mondial et de confiance. Le projet Rust est désormais solidement soutenu par la Rust Foundation, qui investit également dans des initiatives clés pour garantir que Rust est sécurisé, stable et pérenne.
Cette édition du Langage de programmation Rust est une mise à jour complète, reflétant l’évolution du langage au fil des années et fournissant de précieuses nouvelles informations. Mais ce n’est pas seulement un guide sur la syntaxe et les bibliothèques — c’est une invitation à rejoindre une communauté qui valorise la qualité, la performance et la conception réfléchie. Que vous soyez un développeur chevronné cherchant à explorer Rust pour la première fois ou un Rustacean expérimenté cherchant à perfectionner vos compétences, cette édition offre quelque chose pour chacun.
Le parcours de Rust a été fait de collaboration, d’apprentissage et d’itération. La croissance du langage et de son écosystème est le reflet direct de la communauté dynamique et diversifiée qui le soutient. Les contributions de milliers de développeurs, des concepteurs du langage aux contributeurs occasionnels, sont ce qui fait de Rust un outil si unique et puissant. En prenant ce livre, vous n’apprenez pas seulement un nouveau langage de programmation — vous rejoignez un mouvement pour rendre les logiciels meilleurs, plus sûrs et plus agréables à utiliser.
Bienvenue dans la communauté Rust !
- Bec Rumbul, directrice exécutive de la Rust Foundation
Introduction
Note : cette édition du livre est identique à The Rust Programming Language disponible en format papier et numérique chez No Starch Press.
Bienvenue dans Le langage de programmation Rust, un livre d’introduction à Rust. Le langage de programmation Rust vous aide à écrire des logiciels plus rapides et plus fiables. L’ergonomie de haut niveau et le contrôle de bas niveau sont souvent en opposition dans la conception des langages de programmation ; Rust remet en question ce conflit. En équilibrant une puissante capacité technique et une excellente expérience de développement, Rust vous donne la possibilité de contrôler les détails de bas niveau (comme l’utilisation de la mémoire) sans toutes les contraintes traditionnellement associées à ce type de contrôle.
À qui s’adresse Rust
Rust est idéal pour de nombreuses personnes et pour des raisons variées. Examinons quelques-uns des groupes les plus importants.
Les équipes de développeurs
Rust s’avère être un outil productif pour la collaboration au sein de grandes équipes de développeurs avec des niveaux variés de connaissances en programmation système. Le code de bas niveau est sujet à divers bugs subtils, qui dans la plupart des autres langages ne peuvent être détectés qu’au travers de tests approfondis et de revues de code minutieuses par des développeurs expérimentés. En Rust, le compilateur joue un rôle de gardien en refusant de compiler le code contenant ces bugs insaisissables, y compris les bugs de concurrence. En travaillant avec le compilateur, l’équipe peut consacrer son temps à se concentrer sur la logique du programme plutôt qu’à traquer des bugs.
Rust apporte également des outils de développement modernes au monde de la programmation système :
- Cargo, le gestionnaire de dépendances et outil de compilation intégré, rend l’ajout, la compilation et la gestion des dépendances simples et cohérents à travers tout l’écosystème Rust.
- L’outil de formatage
rustfmtassuré un style de code cohérent entre les développeurs. - Le Rust Language Server alimente l’intégration avec les environnements de développement intégrés (IDE) pour la complétion de code et les messages d’erreur en ligne.
En utilisant ces outils et d’autres dans l’écosystème Rust, les développeurs peuvent être productifs tout en écrivant du code au niveau système.
Les étudiants
Rust s’adresse aux étudiants et à ceux qui souhaitent apprendre les concepts système. Grâce à Rust, de nombreuses personnes ont appris des sujets comme le développement de systèmes d’exploitation. La communauté est très accueillante et se fait un plaisir de répondre aux questions des étudiants. À travers des initiatives comme ce livre, les équipes Rust souhaitent rendre les concepts système plus accessibles à un plus grand nombre de personnes, en particulier celles qui débutent en programmation.
Les entreprises
Des centaines d’entreprises, grandes et petites, utilisent Rust en production pour une variété de tâches, notamment des outils en ligne de commande, des services web, des outils DevOps, des systèmes embarqués, de l’analyse et du transcodage audio et vidéo, des cryptomonnaies, de la bio-informatique, des moteurs de recherche, des applications pour l’Internet des objets, de l’apprentissage automatique, et même des parties majeures du navigateur web Firefox.
Les développeurs open source
Rust s’adresse aux personnes qui veulent contribuer au langage de programmation Rust, à sa communauté, à ses outils de développement et à ses bibliothèques. Nous serions ravis que vous contribuiez au langage Rust.
Les personnes qui valorisent la vitesse et la stabilité
Rust s’adresse aux personnes qui recherchent la vitesse et la stabilité dans un langage. Par vitesse, nous entendons à la fois la rapidité d’exécution du code Rust et la rapidité avec laquelle Rust vous permet d’écrire des programmes. Les vérifications du compilateur Rust garantissent la stabilité lors de l’ajout de fonctionnalités et du refactoring. Cela contraste avec le code hérité fragile dans les langages dépourvus de ces vérifications, que les développeurs ont souvent peur de modifier. En visant des abstractions à coût nul — des fonctionnalités de haut niveau qui compilent en code de bas niveau aussi rapide que du code écrit manuellement — Rust s’efforce de faire en sorte que le code sûr soit également du code rapide.
Le langage Rust espère également prendre en charge de nombreux autres utilisateurs ; ceux mentionnés ici ne sont que quelques-unes des parties prenantes les plus importantes. Globalement, la plus grande ambition de Rust est d’éliminer les compromis que les programmeurs ont acceptés pendant des décennies en offrant la sûreté et la productivité, la vitesse et l’ergonomie. Essayez Rust et voyez si ses choix vous conviennent.
À qui s’adresse ce livre
Ce livre suppose que vous avez déjà écrit du code dans un autre langage de programmation, mais ne fait aucune supposition sur lequel. Nous avons essayé de rendre le contenu largement accessible aux personnes venant d’horizons de programmation variés. Nous ne passons pas beaucoup de temps à parler de ce qu’est la programmation ou de comment y réfléchir. Si vous êtes complètement novice en programmation, il serait préférable de lire un livre qui offre spécifiquement une introduction à la programmation.
Comment utiliser ce livre
En général, ce livre suppose que vous le lisez dans l’ordre, du début à la fin. Les chapitres ultérieurs s’appuient sur les concepts des chapitres précédents, et les chapitres précédents pourraient ne pas approfondir un sujet particulier mais y reviendront dans un chapitre ultérieur.
Vous trouverez deux types de chapitres dans ce livre : des chapitres conceptuels et des chapitres de projet. Dans les chapitres conceptuels, vous apprendrez un aspect de Rust. Dans les chapitres de projet, nous construirons ensemble de petits programmes, en appliquant ce que vous avez appris jusque-là. Les chapitres 2, 12 et 21 sont des chapitres de projet ; les autres sont des chapitres conceptuels.
Le chapitre 1 explique comment installer Rust, comment écrire un programme “Hello, world!” et comment utiliser Cargo, le gestionnaire de paquets et outil de compilation de Rust. Le chapitre 2 est une introduction pratique à l’écriture d’un programme en Rust, dans laquelle vous construirez un jeu de devinette de nombre. Nous y abordons les concepts à un haut niveau, et les chapitres ultérieurs fourniront des détails supplémentaires. Si vous voulez mettre les mains dans le cambouis tout de suite, le chapitre 2 est l’endroit idéal. Si vous êtes un apprenant particulièrement méticuleux qui préfère apprendre chaque détail avant de passer au suivant, vous voudrez peut-être sauter le chapitre 2 et aller directement au chapitre 3, qui couvre les fonctionnalités de Rust similaires à celles d’autres langages de programmation ; ensuite, vous pourrez revenir au chapitre 2 quand vous souhaiterez travailler sur un projet en appliquant les détails que vous aurez appris.
Au chapitre 4, vous découvrirez le système de possession (ownership) de Rust. Le chapitre 5 traite des structures (structs) et des méthodes. Le chapitre 6 couvre les énumérations (enums), les expressions match et les constructions de flux de contrôle if let et let...else. Vous utiliserez les structures et les énumérations pour créer des types personnalisés.
Au chapitre 7, vous apprendrez le système de modules de Rust et les règles de visibilité pour organiser votre code et son interface de programmation applicative (API) publique. Le chapitre 8 présente certaines structures de données de collection courantes fournies par la bibliothèque standard : les vecteurs, les chaînes de caractères et les tables de hachage. Le chapitre 9 explore la philosophie et les techniques de gestion des erreurs en Rust.
Le chapitre 10 approfondit les génériques, les traits et les durées de vie (lifetimes), qui vous donnent le pouvoir de définir du code applicable à plusieurs types. Le chapitre 11 est entièrement consacré aux tests, qui même avec les garanties de sûreté de Rust sont nécessaires pour s’assurer que la logique de votre programme est correcte. Au chapitre 12, nous construirons notre propre implémentation d’un sous-ensemble des fonctionnalités de l’outil en ligne de commande grep qui recherche du texte dans des fichiers. Pour cela, nous utiliserons de nombreux concepts abordés dans les chapitres précédents.
Le chapitre 13 explore les fermetures (closures) et les itérateurs : des fonctionnalités de Rust issues des langages de programmation fonctionnelle. Au chapitre 14, nous examinerons Cargo plus en profondeur et parlerons des bonnes pratiques pour partager vos bibliothèques avec d’autres. Le chapitre 15 traite des pointeurs intelligents (smart pointers) fournis par la bibliothèque standard et des traits qui permettent leur fonctionnement.
Au chapitre 16, nous parcourrons différents modèles de programmation concurrente et verrons comment Rust vous aide à programmer avec plusieurs fils d’exécution (threads) sans crainte. Au chapitre 17, nous poursuivrons en explorant la syntaxe async et await de Rust, ainsi que les tâches (tasks), les futures et les flux (streams), et le modèle de concurrence léger qu’ils permettent.
Le chapitre 18 examine comment les idiomes Rust se comparent aux principes de programmation orientée objet que vous connaissez peut-être. Le chapitre 19 est une référence sur les motifs (patterns) et le filtrage par motif (pattern matching), qui sont des moyens puissants d’exprimer des idées dans les programmes Rust. Le chapitre 20 contient un assortiment de sujets avancés intéressants, incluant le Rust unsafe, les macros, et davantage sur les durées de vie, les traits, les types, les fonctions et les fermetures.
Au chapitre 21, nous terminerons un projet dans lequel nous implémenterons un serveur web multithreadé de bas niveau !
Enfin, certaines annexes contiennent des informations utiles sur le langage dans un format plus proche d’une référence. L’annexe A couvre les mots-clés de Rust, l’annexe B couvre les opérateurs et symboles de Rust, l’annexe C couvre les traits dérivables fournis par la bibliothèque standard, l’annexe D couvre certains outils de développement utiles, et l’annexe E explique les éditions de Rust. Dans l’annexe F, vous trouverez des traductions du livre, et dans l’annexe G nous verrons comment Rust est développé et ce qu’est Rust nightly.
Il n’y a pas de mauvaise façon de lire ce livre : si vous voulez sauter des chapitres, n’hésitez pas ! Vous devrez peut-être revenir aux chapitres précédents si vous rencontrez des difficultés. Mais faites ce qui vous convient.
Une part importante du processus d’apprentissage de Rust est d’apprendre à lire les messages d’erreur affichés par le compilateur : ils vous guideront vers un code fonctionnel. Ainsi, nous fournirons de nombreux exemples qui ne compilent pas, accompagnés du message d’erreur que le compilateur vous montrera dans chaque situation. Sachez que si vous saisissez et exécutez un exemple au hasard, il pourrait ne pas compiler ! Assurez-vous de lire le texte environnant pour voir si l’exemple que vous essayez d’exécuter est censé produire une erreur. Dans la plupart des situations, nous vous guiderons vers la version correcte de tout code qui ne compilé pas. Ferris vous aidera également à distinguer le code qui n’est pas censé fonctionner :
| Ferris | Signification |
|---|---|
 | Ce code ne compilé pas ! |
 | Ce code panique ! |
 | Ce code ne produit pas le comportement souhaité. |
Dans la plupart des situations, nous vous guiderons vers la version correcte de tout code qui ne compilé pas.
Code source
Les fichiers sources à partir desquels ce livre est généré se trouvent sur GitHub.
Mise en route
Commençons votre aventure avec Rust ! Il y a beaucoup à apprendre, mais chaque voyage commence quelque part. Dans ce chapitre, nous aborderons :
- L’installation de Rust sur Linux, macOS et Windows
- L’écriture d’un programme qui affiche
Hello, world! - L’utilisation de
cargo, le gestionnaire de paquets et système de compilation de Rust
Installation
Installation
La première étape est d’installer Rust. Nous telechargerons Rust via rustup, un outil en ligne de commande permettant de gérer les versions de Rust et les outils associes. Vous aurez besoin d’une connexion internet pour le téléchargement.
Note : si vous préférez ne pas utiliser
rustuppour une raison quelconque, veuillez consulter la page des autres méthodes d’installation de Rust pour plus d’options.
Les étapes suivantes installent la derniere version stable du compilateur Rust. Les garanties de stabilite de Rust assurent que tous les exemples du livre qui compilent continueront a compiler avec les versions plus récentes de Rust. La sortie peut varier legerement d’une version à l’autre, car Rust ameliore souvent les messages d’erreur et les avertissements. Autrement dit, toute version stable plus récente de Rust que vous installez en suivant ces étapes devrait fonctionner comme prevu avec le contenu de ce livre.
Notation de la ligne de commande
Dans ce chapitre et tout au long du livre, nous montrerons certaines commandes utilisées dans le terminal. Les lignes que vous devez saisir dans un terminal commencent toutes par $. Vous n’avez pas besoin de taper le caractère $ ; c’est l’invite de la ligne de commande affichée pour indiquer le début de chaque commande. Les lignes qui ne commencent pas par $ affichent généralement la sortie de la commande précédente. De plus, les exemples spécifiques à PowerShell utiliseront > au lieu de $.
Installer rustup sur Linux ou macOS
Si vous utilisez Linux ou macOS, ouvrez un terminal et entrez la commande suivante :
$ curl --proto '=https' --tlsv1.2 https://sh.rustup.rs -sSf | sh
La commande téléchargé un script et lance l’installation de l’outil rustup, qui installé la derniere version stable de Rust. Il se peut que votre mot de passe vous soit demande. Si l’installation reussit, la ligne suivante apparaîtra :
Rust is installed now. Great!
Vous aurez également besoin d’un linker (éditeur de liens), qui est un programme que Rust utilise pour regrouper ses sorties compilées en un seul fichier. Il est probable que vous en ayez déjà un. Si vous obtenez des erreurs de linker, vous devriez installer un compilateur C, qui inclura généralement un éditeur de liens. Un compilateur C est également utile car certains packages Rust courants dependent de code C et nécessitent un compilateur C.
Sur macOS, vous pouvez obtenir un compilateur C en exécutant :
$ xcode-select --install
Les utilisateurs Linux devraient généralement installer GCC ou Clang, conformement à la documentation de leur distribution. Par exemple, si vous utilisez Ubuntu, vous pouvez installer le paquet build-essential.
Installer rustup sur Windows
Sur Windows, rendez-vous sur https://www.rust-lang.org/tools/install et suivez les instructions pour installer Rust. À un moment de l’installation, il vous sera demandé d’installer Visual Studio. Celui-ci fournit un éditeur de liens et les bibliothèques natives nécessaires pour compiler les programmes. Si vous avez besoin d’aide supplémentaire pour cette étape, consultez https://rust-lang.github.io/rustup/installation/windows-msvc.html.
Le reste de ce livre utilise des commandes qui fonctionnent aussi bien dans cmd.exe que dans PowerShell. S’il y à des differences spécifiques, nous expliquerons laquelle utiliser.
Resolution de problèmes
Pour vérifier que Rust est correctement installé, ouvrez un terminal et entrez cette ligne :
$ rustc --version
Vous devriez voir le numéro de version, le hash du commit et la date du commit pour la derniere version stable publiée, dans le format suivant :
rustc x.y.z (abcabcabc yyyy-mm-dd)
Si vous voyez cette information, vous avez installé Rust avec succès ! Si vous ne voyez pas cette information, vérifiez que Rust se trouve dans votre variable système %PATH% comme suit.
Dans le CMD Windows, utilisez :
> echo %PATH%
Dans PowerShell, utilisez :
> echo $env:Path
Sous Linux et macOS, utilisez :
$ echo $PATH
Si tout est correct et que Rust ne fonctionne toujours pas, il existe plusieurs endroits où vous pouvez obtenir de l’aide. Découvrez comment entrer en contact avec d’autres Rustaceans (un surnom amusant que nous nous donnons) sur la page de la communauté.
Mise à jour et désinstallation
Une fois Rust installé via rustup, la mise à jour vers une nouvelle version est simple. Depuis votre terminal, exécutez le script de mise à jour suivant :
$ rustup update
Pour désinstaller Rust et rustup, exécutez le script de désinstallation suivant depuis votre terminal :
$ rustup self uninstall
Lire la documentation locale
L’installation de Rust inclut également une copie locale de la documentation afin que vous puissiez la lire hors ligne. Exécutez rustup doc pour ouvrir la documentation locale dans votre navigateur.
Chaque fois qu’un type ou une fonction est fourni par la bibliothèque standard et que vous n’etes pas sur de ce qu’il fait ou comment l’utiliser, consultez la documentation de l’interface de programmation applicative (API) pour le découvrir !
Utiliser des éditeurs de texte et des IDE
Ce livre ne fait aucune hypothèse sur les outils que vous utilisez pour écrire du code Rust. Presque n’importe quel éditeur de texte fera l’affaire ! Cependant, de nombreux éditeurs de texte et environnements de développement intégrés (IDE) offrent une prise en charge intégrée de Rust. Vous pouvez toujours trouver une liste assez à jour de nombreux éditeurs et IDE sur la page des outils du site web de Rust.
Travailler hors ligne avec ce livre
Dans plusieurs exemples, nous utiliserons des packages Rust au-dela de la bibliothèque standard. Pour travailler sur ces exemples, vous aurez besoin soit d’une connexion internet, soit d’avoir téléchargé ces dépendances à l’avance. Pour télécharger les dépendances à l’avance, vous pouvez exécuter les commandes suivantes. (Nous expliquerons ce qu’est cargo et ce que fait chacune de ces commandes en détail plus tard.)
$ cargo new get-dependencies
$ cd get-dependencies
$ cargo add rand@0.8.5 trpl@0.2.0
Cela mettra en cache les téléchargements de ces packages afin que vous n’ayez pas à les télécharger plus tard. Une fois cette commande exécutée, vous n’avez pas besoin de conserver le dossier get-dependencies. Si vous avez exécute cette commande, vous pouvez utiliser le drapeau --offline avec toutes les commandes cargo dans le reste du livre pour utiliser ces versions en cache au lieu de tenter d’utiliser le reseau.
Hello, World!
Hello, World!
Maintenant que vous avez installé Rust, il est temps d’écrire votre premier programme Rust. C’est une tradition lorsqu’on apprend un nouveau langage d’écrire un petit programme qui affiche le texte Hello, world! à l’ecran, alors faisons de même !
Note : ce livre suppose une familiarité basique avec la ligne de commande. Rust n’impose aucune exigence particulière concernant votre éditeur, vos outils ou l’emplacement de votre code. Si vous préférez utiliser un IDE plutôt que la ligne de commande, n’hésitez pas à utiliser votre IDE préféré. De nombreux IDE offrent désormais un certain niveau de prise en charge de Rust ; consultez la documentation de l’IDE pour plus de détails. L’équipe Rust s’est concentrée sur l’activation d’une excellente prise en charge des IDE via
rust-analyzer. Consultez l’annexe D pour plus de détails.
Mise en place du repertoire du projet
Vous commencerez par créer un repertoire pour stocker votre code Rust. Peu importe pour Rust ou se trouve votre code, mais pour les exercices et projets de ce livre, nous suggerons de créer un repertoire projects dans votre repertoire personnel et d’y conserver tous vos projets.
Ouvrez un terminal et entrez les commandes suivantes pour créer un repertoire projects et un repertoire pour le projet “Hello, world!” à l’intérieur du repertoire projects.
Pour Linux, macOS et PowerShell sur Windows, entrez ceci :
$ mkdir ~/projects
$ cd ~/projects
$ mkdir hello_world
$ cd hello_world
Pour le CMD Windows, entrez ceci :
> mkdir "%USERPROFILE%\projects"
> cd /d "%USERPROFILE%\projects"
> mkdir hello_world
> cd hello_world
Les bases d’un programme Rust
Ensuite, créez un nouveau fichier source et appelez-le main.rs. Les fichiers Rust se terminent toujours par l’extension .rs. Si vous utilisez plusieurs mots dans votre nom de fichier, la convention est d’utiliser un underscore pour les séparer. Par exemple, utilisez hello_world.rs plutot que helloworld.rs.
Maintenant, ouvrez le fichier main.rs que vous venez de créer et entrez le code de l’Encadre 1-1.
fn main() {
println!("Hello, world!");
}Hello, world!Sauvegardez le fichier et retournez à votre fenêtre de terminal dans le repertoire ~/projects/hello_world. Sous Linux ou macOS, entrez les commandes suivantes pour compiler et exécuter le fichier :
$ rustc main.rs
$ ./main
Hello, world!
Sous Windows, entrez la commande .\main au lieu de ./main :
> rustc main.rs
> .\main
Hello, world!
Quel que soit votre système d’exploitation, la chaîne Hello, world! devrait s’afficher dans le terminal. Si vous ne voyez pas cette sortie, reportez-vous à la partie « Résolution de problèmes » de la section Installation pour obtenir de l’aide.
Si Hello, world! s’est bien affiche, felicitations ! Vous avez officiellement écrit un programme Rust. Cela fait de vous un programmeur Rust – bienvenue !
L’anatomie d’un programme Rust
Examinons ce programme “Hello, world!” en détail. Voici le premier élément du puzzle :
fn main() {
}Ces lignes définissent une fonction nommee main. La fonction main est speciale : c’est toujours le premier code qui s’exécute dans tout programme Rust exécutable. Ici, la première ligne déclaré une fonction nommee main qui n’a pas de paramètres et ne retourné rien. S’il y avait des paramètres, ils iraient à l’intérieur des parentheses (()).
Le corps de la fonction est entouré par {}. Rust exige des accolades autour de tous les corps de fonctions. Il est de bon style de placer l’accolade ouvrante sur la même ligne que la déclaration de la fonction, en ajoutant un espace entre les deux.
Note : si vous souhaitez respecter un style standard dans vos projets Rust, vous pouvez utiliser un outil de formatage automatique appelé
rustfmtpour formater votre code dans un style particulier (plus d’informations surrustfmtdans l’annexe D). L’équipe Rust a inclus cet outil dans la distribution standard de Rust, tout commerustc, il devrait donc déjà être installé sur votre ordinateur !
Le corps de la fonction main contient le code suivant :
#![allow(unused)]
fn main() {
println!("Hello, world!");
}Cette ligne fait tout le travail dans ce petit programme : elle affiche du texte à l’ecran. Il y a trois détails importants a remarquer ici.
Premièrement, println! appelle une macro Rust. Si c’était un appel de fonction, cela s’écrirait println (sans le !). Les macros Rust sont un moyen d’écrire du code qui génère du code pour étendre la syntaxe de Rust, et nous en discuterons plus en détail au chapitre 20. Pour l’instant, vous devez simplement savoir que l’utilisation d’un ! signifie que vous appelez une macro plutôt qu’une fonction normale, et que les macros ne suivent pas toujours les mêmes règles que les fonctions.
Deuxiemement, vous voyez la chaîne "Hello, world!". Nous passons cette chaîne en argument a println!, et la chaîne est affichée à l’ecran.
Troisiemement, nous terminons la ligne par un point-virgule (;), qui indique que cette expression est terminée et que la suivante est prête a commencer. La plupart des lignes de code Rust se terminent par un point-virgule.
Compilation et exécution
Vous venez d’exécuter un programme nouvellement crée, alors examinons chaque étape du processus.
Avant d’exécuter un programme Rust, vous devez le compiler en utilisant le compilateur Rust en entrant la commande rustc et en lui passant le nom de votre fichier source, comme ceci :
$ rustc main.rs
Si vous avez une experience en C ou C++, vous remarquerez que c’est similaire a gcc ou clang. Après une compilation reussie, Rust produit un exécutable binaire.
Sous Linux, macOS et PowerShell sur Windows, vous pouvez voir l’exécutable en entrant la commande ls dans votre terminal :
$ ls
main main.rs
Sous Linux et macOS, vous verrez deux fichiers. Avec PowerShell sur Windows, vous verrez les mêmes trois fichiers que vous verriez en utilisant CMD. Avec CMD sur Windows, vous entreriez la commande suivante :
> dir /B %= the /B option says to only show the file names =%
main.exe
main.pdb
main.rs
Cela montre le fichier de code source avec l’extension .rs, le fichier exécutable (main.exe sous Windows, mais main sur toutes les autres plateformes), et, sous Windows, un fichier contenant des informations de debogage avec l’extension .pdb. A partir de la, vous exécutez le fichier main ou main.exe, comme ceci :
$ ./main # or .\main on Windows
Si votre main.rs est votre programme “Hello, world!”, cette ligne affiche Hello, world! dans votre terminal.
Si vous etes plus familier avec un langage dynamique, comme Ruby, Python ou JavaScript, vous n’etes peut-etre pas habitue a compiler et exécuter un programme en deux étapes séparées. Rust est un langage compile à l’avance (ahead-of-time compiled), ce qui signifie que vous pouvez compiler un programme et donner l’exécutable a quelqu’un d’autre, qui pourra l’exécuter même sans avoir Rust installé. Si vous donnez a quelqu’un un fichier .rb, .py ou .js, cette personne doit avoir une implémentation de Ruby, Python ou JavaScript installée (respectivement). Mais dans ces langages, vous n’avez besoin que d’une seule commande pour compiler et exécuter votre programme. Tout est un compromis dans la conception des langages.
Compiler simplement avec rustc convient pour les programmes simples, mais a mesure que votre projet grandit, vous voudrez gérer toutes les options et faciliter le partage de votre code. Ensuite, nous vous présenterons l’outil Cargo, qui vous aidera a écrire des programmes Rust concrets.
Hello, Cargo!
Hello, Cargo!
Cargo est le système de build et le gestionnaire de paquets de Rust. La plupart des Rustaceans utilisent cet outil pour gérer leurs projets Rust car Cargo géré de nombreuses tâches pour vous, comme compiler votre code, télécharger les bibliothèques dont votre code depend, et compiler ces bibliothèques. (Nous appelons les bibliothèques dont votre code a besoin des dependances.)
Les programmes Rust les plus simples, comme celui que nous avons écrit jusqu’ici, n’ont aucune dépendance. Si nous avions construit le projet “Hello, world!” avec Cargo, nous n’aurions utilise que la partie de Cargo qui géré la compilation de votre code. A mesure que vous écrirez des programmes Rust plus complexes, vous ajouterez des dépendances, et si vous demarrez un projet avec Cargo, l’ajout de dépendances sera beaucoup plus facile.
Comme la grande majorité des projets Rust utilisent Cargo, le reste de ce livre suppose que vous utilisez également Cargo. Cargo est installé avec Rust si vous avez utilisé les installateurs officiels présentés dans la section « Installation ». Si vous avez installé Rust par un autre moyen, vérifiez si Cargo est installé en entrant la commande suivante dans votre terminal :
$ cargo --version
Si vous voyez un numéro de version, vous l’avez ! Si vous voyez une erreur, comme command not found, consultez la documentation de votre methode d’installation pour déterminer comment installer Cargo séparément.
Créer un projet avec Cargo
Créons un nouveau projet en utilisant Cargo et voyons en quoi il diffère de notre projet “Hello, world!” original. Retournez dans votre repertoire projects (ou la où vous avez decide de stocker votre code). Puis, sur n’importe quel système d’exploitation, exécutez la commande suivante :
$ cargo new hello_cargo
$ cd hello_cargo
La première commande crée un nouveau repertoire et un projet appelé hello_cargo. Nous avons nomme notre projet hello_cargo, et Cargo crée ses fichiers dans un repertoire du même nom.
Entrez dans le repertoire hello_cargo et listez les fichiers. Vous verrez que Cargo a généré deux fichiers et un repertoire pour nous : un fichier Cargo.toml et un repertoire src contenant un fichier main.rs.
Il a également initialise un nouveau dépôt Git avec un fichier .gitignore. Les fichiers Git ne seront pas générés si vous exécutez cargo new dans un dépôt Git existant ; vous pouvez forcer ce comportement en utilisant cargo new --vcs=git.
Note : Git est un système de contrôle de version courant. Vous pouvez configurer
cargo newpour utiliser un autre système de contrôle de version ou aucun système de contrôle de version en utilisant le drapeau--vcs. Exécutezcargo new --helppour voir les options disponibles.
Ouvrez Cargo.toml dans l’éditeur de texte de votre choix. Il devrait ressembler au code de l’Encadre 1-2.
[package]
name = "hello_cargo"
version = "0.1.0"
edition = "2024"
[dependencies]
cargo newCe fichier est au format TOML (Tom’s Obvious, Minimal Language), qui est le format de configuration de Cargo.
La première ligne, [package], est un en-tete de section qui indique que les instructions suivantes configurent un package. Au fur et a mesure que nous ajouterons des informations à ce fichier, nous ajouterons d’autres sections.
Les trois lignes suivantes définissent les informations de configuration dont Cargo a besoin pour compiler votre programme : le nom, la version et l’édition de Rust à utiliser. Nous parlerons de la clé edition dans l’annexe E.
La derniere ligne, [dependencies], est le début d’une section ou vous pouvez lister les dépendances de votre projet. En Rust, les packages de code sont appelés des crates. Nous n’aurons besoin d’aucune autre crate pour ce projet, mais nous en aurons besoin dans le premier projet du Chapitre 2, et nous utiliserons alors cette section de dépendances.
Maintenant, ouvrez src/main.rs et jetez-y un coup d’oeil :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
println!("Hello, world!");
}Cargo a généré un programme “Hello, world!” pour vous, exactement comme celui que nous avons écrit dans l’Encadre 1-1 ! Jusqu’ici, les differences entre notre projet et le projet généré par Cargo sont que Cargo a place le code dans le repertoire src, et que nous avons un fichier de configuration Cargo.toml dans le repertoire racine.
Cargo s’attend à ce que vos fichiers source se trouvent dans le repertoire src. Le repertoire racine du projet est reserve aux fichiers README, aux informations de licence, aux fichiers de configuration et à tout ce qui n’est pas lie à votre code. Utiliser Cargo vous aide a organiser vos projets. Il y à une place pour chaque chose, et chaque chose est à sa place.
Si vous avez demarre un projet qui n’utilise pas Cargo, comme nous l’avons fait avec le projet “Hello, world!”, vous pouvez le convertir en un projet qui utilise Cargo. Deplacez le code du projet dans le repertoire src et créez un fichier Cargo.toml appropriate. Un moyen facile d’obtenir ce fichier Cargo.toml est d’exécuter cargo init, qui le créera automatiquement pour vous.
Compiler et exécuter un projet Cargo
Voyons maintenant ce qui change lorsque nous compilons et exécutons le programme “Hello, world!” avec Cargo ! Depuis votre repertoire hello_cargo, compilez votre projet en entrant la commande suivante :
$ cargo build
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 2.85 secs
Cette commande crée un fichier exécutable dans target/debug/hello_cargo (ou target\debug\hello_cargo.exe sous Windows) plutot que dans votre repertoire courant. Comme la compilation par défaut est une compilation de debogage, Cargo place le binaire dans un repertoire nomme debug. Vous pouvez exécuter l’exécutable avec cette commande :
$ ./target/debug/hello_cargo # or .\target\debug\hello_cargo.exe on Windows
Hello, world!
Si tout se passe bien, Hello, world! devrait s’afficher dans le terminal. Exécuter cargo build pour la première fois amene également Cargo a créer un nouveau fichier à la racine : Cargo.lock. Ce fichier garde la trace des versions exactes des dépendances de votre projet. Ce projet n’a pas de dépendances, donc le fichier est un peu vide. Vous n’aurez jamais besoin de modifier ce fichier manuellement ; Cargo géré son contenu pour vous.
Nous venons de compiler un projet avec cargo build et de l’exécuter avec ./target/debug/hello_cargo, mais nous pouvons aussi utiliser cargo run pour compiler le code puis exécuter l’exécutable resultant, le tout en une seule commande :
$ cargo run
Finished dev [unoptimized + debuginfo] target(s) in 0.0 secs
Running `target/debug/hello_cargo`
Hello, world!
Utiliser cargo run est plus pratique que de devoir se souvenir d’exécuter cargo build puis d’utiliser le chemin complet vers le binaire, c’est pourquoi la plupart des développeurs utilisent cargo run.
Remarquez que cette fois, nous n’avons pas vu de sortie indiquant que Cargo compilait hello_cargo. Cargo a déterminé que les fichiers n’avaient pas change, donc il n’a pas recompile mais a simplement exécute le binaire. Si vous aviez modifié votre code source, Cargo aurait recompile le projet avant de l’exécuter, et vous auriez vu cette sortie :
$ cargo run
Compiling hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.33 secs
Running `target/debug/hello_cargo`
Hello, world!
Cargo fournit également une commande appelée cargo check. Cette commande vérifie rapidement votre code pour s’assurer qu’il compilé, mais ne produit pas d’exécutable :
$ cargo check
Checking hello_cargo v0.1.0 (file:///projects/hello_cargo)
Finished dev [unoptimized + debuginfo] target(s) in 0.32 secs
Pourquoi ne voudriez-vous pas d’exécutable ? Souvent, cargo check est beaucoup plus rapide que cargo build car il saute l’étape de production d’un exécutable. Si vous vérifiez continuellement votre travail pendant que vous écrivez le code, utiliser cargo check accelerera le processus pour savoir si votre projet compilé toujours ! C’est pourquoi de nombreux Rustaceans exécutent cargo check periodiquement pendant qu’ils écrivent leur programme pour s’assurer qu’il compilé. Ensuite, ils exécutent cargo build lorsqu’ils sont prêts à utiliser l’exécutable.
Récapitulons ce que nous avons appris jusqu’ici sur Cargo :
- Nous pouvons créer un projet en utilisant
cargo new. - Nous pouvons compiler un projet en utilisant
cargo build. - Nous pouvons compiler et exécuter un projet en une seule étape en utilisant
cargo run. - Nous pouvons compiler un projet sans produire de binaire pour vérifier les erreurs en utilisant
cargo check. - Au lieu de sauvegarder le résultat de la compilation dans le même répertoire que notre code, Cargo le stocké dans le répertoire target/debug.
Un avantage supplementaire de l’utilisation de Cargo est que les commandes sont les mêmes quel que soit le système d’exploitation sur lequel vous travaillez. Donc, à partir de maintenant, nous ne fournirons plus d’instructions spécifiques pour Linux et macOS par rapport a Windows.
Compiler pour la publication
Lorsque votre projet est enfin prêt pour la publication, vous pouvez utiliser cargo build --release pour le compiler avec des optimisations. Cette commande créera un exécutable dans target/release au lieu de target/debug. Les optimisations rendent votre code Rust plus rapide, mais les activer allonge le temps de compilation de votre programme. C’est pourquoi il y a deux profils différents : un pour le développement, quand vous voulez recompiler rapidement et souvent, et un autre pour construire le programme final que vous donnerez à un utilisateur, qui ne sera pas recompile frequemment et qui s’exécutera aussi vite que possible. Si vous mesurez les performances de votre code, assurez-vous d’exécuter cargo build --release et de tester avec l’exécutable dans target/release.
Tirer parti des conventions de Cargo
Pour les projets simples, Cargo n’apporte pas beaucoup de valeur ajoutée par rapport à la simple utilisation de rustc, mais il prouvera sa valeur a mesure que vos programmes deviendront plus complexes. Une fois que les programmes s’etendent à plusieurs fichiers ou nécessitent une dépendance, il est beaucoup plus facile de laisser Cargo coordonner la compilation.
Même si le projet hello_cargo est simple, il utilise déjà une grande partie des outils réels que vous utiliserez tout au long de votre parcours avec Rust. En fait, pour travailler sur n’importe quel projet existant, vous pouvez utiliser les commandes suivantes pour recuperer le code avec Git, accéder au repertoire du projet et compiler :
$ git clone example.org/someproject
$ cd someproject
$ cargo build
Pour plus d’informations sur Cargo, consultez sa documentation.
Résumé
Vous avez déjà pris un excellent départ dans votre parcours Rust ! Dans ce chapitre, vous avez appris à :
- Installer la dernière version stable de Rust en utilisant
rustup. - Mettre à jour vers une version plus récente de Rust.
- Ouvrir la documentation installée localement.
- Écrire et exécuter un programme
Hello, world!en utilisant directementrustc. - Créer et exécuter un nouveau projet en utilisant les conventions de Cargo.
C’est le moment ideal pour construire un programme plus consequent afin de vous habituer a lire et écrire du code Rust. Ainsi, au Chapitre 2, nous construirons un programme de jeu de devinettes. Si vous preferez commencer par apprendre comment les concepts de programmation courants fonctionnent en Rust, consultez le Chapitre 3 puis revenez au Chapitre 2.
Programmer un jeu de devinettes
Plongeons dans Rust en travaillant ensemble sur un projet concret ! Ce chapitre vous présente quelques concepts courants de Rust en vous montrant comment les utiliser dans un vrai programme. Vous découvrirez let, match, les méthodes, les fonctions associées, les crates externes, et bien plus ! Dans les chapitres suivants, nous explorerons ces notions plus en détail. Dans ce chapitre, vous pratiquerez simplement les bases.
Nous allons implémenter un problème classique de programmation pour débutants : un jeu de devinettes. Voici comment il fonctionne : le programme génère un nombre entier aléatoire entre 1 et 100. Il demande ensuite au joueur de saisir une proposition. Après chaque saisie, le programme indique si la proposition est trop basse ou trop haute. Si la proposition est correcte, le jeu affiche un message de félicitations et se terminé.
Mise en place d’un nouveau projet
Pour mettre en place un nouveau projet, rendez-vous dans le répertoire projects que vous avez créé au chapitre 1 et créez un nouveau projet avec Cargo, comme ceci :
$ cargo new guessing_game
$ cd guessing_game
La première commande, cargo new, prend le nom du projet (guessing_game) comme premier argument. La seconde commande se déplace dans le répertoire du nouveau projet.
Regardons le fichier Cargo.toml généré :
Fichier : Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2024"
[dependencies]
Comme vous l’avez vu au chapitre 1, cargo new génère un programme “Hello, world!” pour vous. Regardons le fichier src/main.rs : Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch02-guessing-game-tutorial/no-listing-01-cargo-new/src/main.rs}}
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
println!("Hello, world!");
}Maintenant, compilons ce programme “Hello, world!” et exécutons-le en une seule étape avec la commande cargo run : console {{#include ../listings/ch02-guessing-game-tutorial/no-listing-01-cargo-new/output.txt}}
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/guessing_game`
Hello, world!
La commande run est pratique lorsque vous avez besoin d’itérer rapidement sur un projet, comme nous le ferons dans ce jeu, en testant rapidement chaque itération avant de passer à la suivante.
Rouvrez le fichier src/main.rs. Vous écrirez tout le code dans ce fichier.
Traitement d’une proposition
La première partie du programme du jeu de devinettes demandera une saisie à l’utilisateur, traitera cette saisie et vérifiera qu’elle est dans la forme attendue. Pour commencer, nous allons permettre au joueur de saisir une proposition. Entrez le code de l’encart 2-1 dans src/main.rs.
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Ce code contient beaucoup d’informations, alors parcourons-le ligne par ligne. Pour obtenir la saisie de l’utilisateur puis afficher le résultat en sortie, nous devons importer la bibliothèque d’entrée/sortie io dans la portée. La bibliothèque io provient de la bibliothèque standard, connue sous le nom de std : rust,ignore {{#rustdoc_include ../listings/ch02-guessing-game-tutorial/listing-02-01/src/main.rs:io}}
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Par défaut, Rust dispose d’un ensemble d’éléments définis dans la bibliothèque standard qu’il importe dans la portée de chaque programme. Cet ensemble s’appelle le prelude, et vous pouvez voir tout ce qu’il contient [dans la documentation de la bibliothèque standard][prelude].
Si un type que vous souhaitez utiliser n’est pas dans le prelude, vous devez l’importer explicitement dans la portée avec une instruction use. Utiliser la bibliothèque std::io vous fournit un certain nombre de fonctionnalités utiles, notamment la possibilité d’accepter des saisies utilisateur.
Comme vous l’avez vu au chapitre 1, la fonction main est le point d’entrée du programme : rust,ignore {{#rustdoc_include ../listings/ch02-guessing-game-tutorial/listing-02-01/src/main.rs:main}}
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}La syntaxe fn déclare une nouvelle fonction ; les parenthèses, (), indiquent qu’il n’y a pas de paramètres ; et l’accolade ouvrante, {, commence le corps de la fonction.
Comme vous l’avez également appris au chapitre 1, println! est une macro qui affiche une chaîne de caractères à l’écran : rust,ignore {{#rustdoc_include ../listings/ch02-guessing-game-tutorial/listing-02-01/src/main.rs:print}}
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Ce code affiche un message indiquant de quoi il s’agit et demande une saisie à l’utilisateur.
Stocker des valeurs avec des variables
Ensuite, nous allons créer une variable pour stocker la saisie de l’utilisateur, comme ceci : rust,ignore {{#rustdoc_include ../listings/ch02-guessing-game-tutorial/listing-02-01/src/main.rs:string}}
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Maintenant le programme devient intéressant ! Il se passe beaucoup de choses dans cette petite ligne. Nous utilisons l’instruction let pour créer la variable. Voici un autre exemple :
let apples = 5;section in Chapter 3. To make a variable mutable, we add mut before the variable name: –> Cette ligne crée une nouvelle variable nommée apples et la lie à la valeur 5. En Rust, les variables sont immuables par défaut, ce qui signifie qu’une fois que nous avons donné une valeur à la variable, la valeur ne changera pas. Nous discuterons de ce concept en détail dans la section [“Variables et mutabilité”][variables-and-mutability] du chapitre 3. Pour rendre une variable mutable, nous ajoutons mut devant le nom de la variable :
let apples = 5; // immutable
let mut bananas = 5; // mutableRemarque : la syntaxe
//commence un commentaire qui se poursuit jusqu’à la fin de la ligne. Rust ignore tout ce qui se trouve dans les commentaires. Nous discuterons des commentaires plus en détail au [chapitre 3][comments].
En revenant au programme du jeu de devinettes, vous savez maintenant que let mut guess introduit une variable mutable nommée guess. Le signé égal (=) indique à Rust que nous voulons lier quelque chose à la variable maintenant. À droite du signé égal se trouve la valeur à laquelle guess est liée, qui est le résultat de l’appel à String::new, une fonction qui renvoie une nouvelle instance de String. [String][string] est un type de chaîne de caractères fourni par la bibliothèque standard, qui est un texte extensible encodé en UTF-8.
La syntaxe :: dans la ligne ::new indique que new est une fonction associée du type String. Une fonction associée est une fonction qui est implémentée sur un type, dans ce cas String. Cette fonction new crée une nouvelle chaîne de caractères vide. Vous trouverez une fonction new sur de nombreux types car c’est un nom courant pour une fonction qui crée une nouvelle valeur d’un certain type.
En résumé, la ligne let mut guess = String::new(); a créé une variable mutable qui est actuellement liée à une nouvelle instance vide de String. Ouf !
Recevoir la saisie de l’utilisateur
Rappelons que nous avons inclus la fonctionnalité d’entrée/sortie de la bibliothèque standard avec use std::io; sur la première ligne du programme. Maintenant, nous allons appeler la fonction stdin du module io, qui nous permettra de gérer la saisie de l’utilisateur : rust,ignore {{#rustdoc_include ../listings/ch02-guessing-game-tutorial/listing-02-01/src/main.rs:read}}
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Si nous n’avions pas importé le module io avec use std::io; au début du programme, nous pourrions quand même utiliser la fonction en écrivant l’appel comme std::io::stdin. La fonction stdin renvoie une instance de [std::io::Stdin][iostdin], qui est un type représentant un descripteur vers l’entrée standard de votre terminal.
Ensuite, la ligne .read_line(&mut guess) appelle la méthode read_line sur le descripteur d’entrée standard pour obtenir la saisie de l’utilisateur. Nous passons également &mut guess comme argument à read_line pour lui indiquer dans quelle chaîne stocker la saisie de l’utilisateur. Le rôle complet de read_line est de prendre tout ce que l’utilisateur saisit dans l’entrée standard et de l’ajouter à une chaîne (sans écraser son contenu), donc nous passons cette chaîne en argument. L’argument chaîne doit être mutable pour que la méthode puisse modifier le contenu de la chaîne.
Le & indique que cet argument est une référence, qui vous permet de laisser plusieurs parties de votre code accéder à une même donnée sans avoir besoin de copier cette donnée en mémoire plusieurs fois. Les références sont une fonctionnalité complexe, et l’un des avantages majeurs de Rust est la sécurité et la facilité d’utilisation des références. Vous n’avez pas besoin de connaître tous ces détails pour terminer ce programme. Pour l’instant, tout ce que vous devez savoir, c’est que, comme les variables, les références sont immuables par défaut. Par conséquent, vous devez écrire &mut guess plutôt que &guess pour la rendre mutable. (Le chapitre 4 expliquera les références plus en détail.)
Gérer les erreurs potentielles avec Result
Nous travaillons toujours sur cette ligne de code. Nous discutons maintenant d’une troisième ligne de texte, mais notez qu’elle fait toujours partie d’une seule ligne logique de code. La partie suivante est cette méthode : rust,ignore {{#rustdoc_include ../listings/ch02-guessing-game-tutorial/listing-02-01/src/main.rs:expect}}
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Nous aurions pu écrire ce code ainsi :
io::stdin().read_line(&mut guess).expect("Failed to read line");Cependant, une seule longue ligne est difficile à lire, il est donc préférable de la diviser. Il est souvent judicieux d’introduire un retour à la ligne et d’autres espaces pour aérer les longues lignes lorsque vous appelez une méthode avec la syntaxe .nom_de_methode(). Voyons maintenant ce que fait cette ligne.
Comme mentionné précédemment, read_line place ce que l’utilisateur saisit dans la chaîne que nous lui passons, mais elle renvoie également une valeur Result. [Result][result] est une [énumération][enums], souvent appelée enum, qui est un type pouvant se trouver dans l’un de plusieurs états possibles. Nous appelons chaque état possible une variante.
Le chapitre 6 couvrira les enums plus en détail. L’objectif de ces types Result est d’encoder les informations de gestion d’erreurs.
Les variantes de Result sont Ok et Err. La variante Ok indique que l’opération a réussi et contient la valeur produite avec succès. La variante Err signifie que l’opération a échoué et contient des informations sur la manière ou la raison de l’échec.
that you can call. If this instance of Result is an Err value, expect will cause the program to crash and display the message that you passed as an argument to expect. If the read_line method returns an Err, it would likely be the result of an error coming from the underlying operating system. If this instance of Result is an Ok value, expect will take the return value that Ok is holding and return just that value to you so that you can use it. In this case, that value is the number of bytes in the user’s input. –> Les valeurs du type Result, comme les valeurs de tout type, ont des méthodes définies sur elles. Une instance de Result possède une [méthode expect][expect] que vous pouvez appeler. Si cette instance de Result est une valeur Err, expect provoquera le plantage du programme et affichera le message que vous avez passé en argument à expect. Si la méthode read_line renvoie un Err, il s’agirait probablement d’une erreur provenant du système d’exploitation sous-jacent. Si cette instance de Result est une valeur Ok, expect prendra la valeur de retour contenue dans Ok et vous renverra uniquement cette valeur afin que vous puissiez l’utiliser. Dans ce cas, cette valeur est le nombre d’octets dans la saisie de l’utilisateur.
Si vous n’appelez pas expect, le programme compilera, mais vous obtiendrez un avertissement : console {{#include ../listings/ch02-guessing-game-tutorial/no-listing-02-without-expect/output.txt}}
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
warning: unused `Result` that must be used
--> src/main.rs:10:5
|
10 | io::stdin().read_line(&mut guess);
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
10 | let _ = io::stdin().read_line(&mut guess);
| +++++++
warning: `guessing_game` (bin "guessing_game") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.59s
Rust vous avertit que vous n’avez pas utilisé la valeur Result renvoyée par read_line, indiquant que le programme n’a pas géré une erreur possible.
La bonne façon de supprimer l’avertissement est d’écrire réellement du code de gestion d’erreurs, mais dans notre cas, nous voulons simplement que le programme plante lorsqu’un problème survient, donc nous pouvons utiliser expect. Vous apprendrez à récupérer des erreurs au [chapitre 9][recover].
Afficher des valeurs avec les espaces réservés de println!
Mis à part l’accolade fermante, il ne reste qu’une seule ligne à discuter dans le code jusqu’ici : rust,ignore {{#rustdoc_include ../listings/ch02-guessing-game-tutorial/listing-02-01/src/main.rs:print_guess}}
use std::io;
fn main() {
println!("Guess the number!");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Cette ligne affiche la chaîne qui contient maintenant la saisie de l’utilisateur. Les accolades {} sont un espace réservé : pensez aux {} comme de petites pinces de crabe qui maintiennent une valeur en place. Lors de l’affichage de la valeur d’une variable, le nom de la variable peut être placé à l’intérieur des accolades. Pour afficher le résultat de l’évaluation d’une expression, placez des accolades vides dans la chaîne de format, puis faites suivre la chaîne de format d’une liste d’expressions séparées par des virgules à afficher dans chaque espace réservé dans le même ordre. Afficher une variable et le résultat d’une expression en un seul appel à println! ressemblerait à ceci :
#![allow(unused)]
fn main() {
let x = 5;
let y = 10;
println!("x = {x} and y + 2 = {}", y + 2);
}Ce code afficherait x = 5 and y + 2 = 12.
Tester la première partie
Testons la première partie du jeu de devinettes. Exécutez-le avec cargo run :
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 6.44s
Running `target/debug/guessing_game`
Guess the number!
Please input your guess.
6
You guessed: 6
À ce stade, la première partie du jeu est terminée : nous récupérons la saisie au clavier puis nous l’affichons.
Générer un nombre secret
Ensuite, nous devons générer un nombre secret que l’utilisateur essaiera de deviner. Le nombre secret devrait être différent à chaque fois pour que le jeu reste amusant à rejouer. Nous utiliserons un nombre aléatoire entre 1 et 100 pour que le jeu ne soit pas trop difficile. Rust n’inclut pas encore de fonctionnalité de génération de nombres aléatoires dans sa bibliothèque standard. Cependant, l’équipe Rust fournit une [crate rand][randcrate] avec cette fonctionnalité.
Enrichir les fonctionnalités avec une crate
Rappelez-vous qu’une crate est une collection de fichiers de code source Rust. Le projet que nous construisons est une crate binaire, c’est-à-dire un exécutable. La crate rand est une crate de bibliothèque, qui contient du code destiné à être utilisé dans d’autres programmes et ne peut pas être exécutée seule.
La coordination des crates externes par Cargo est là où Cargo brille vraiment. Avant de pouvoir écrire du code qui utilise rand, nous devons modifier le fichier Cargo.toml pour inclure la crate rand comme dépendance. Ouvrez ce fichier maintenant et ajoutez la ligne suivante en bas, sous l’en-tête de section [dependencies] que Cargo a créé pour vous. Assurez-vous de spécifier rand exactement comme nous l’avons fait ici, avec ce numéro de version, sinon les exemples de code de ce tutoriel pourraient ne pas fonctionner :
Fichier : Cargo.toml
[dependencies]
rand = "0.8.5"
Dans le fichier Cargo.toml, tout ce qui suit un en-tête fait partie de cette section et continue jusqu’au début d’une autre section. Dans [dependencies], vous indiquez à Cargo de quelles crates externes votre projet dépend et quelles versions de ces crates vous exigez. Dans ce cas, nous spécifions la crate rand avec le spécificateur de version sémantique 0.8.5. Cargo comprend le [versionnement sémantique][semver] (parfois appelé SemVer), qui est un standard pour écrire les numéros de version. Le spécificateur 0.8.5 est en fait un raccourci pour ^0.8.5, ce qui signifie toute version supérieure ou égale à 0.8.5 mais inférieure à 0.9.0.
Cargo considère que ces versions ont des API publiques compatibles avec la version 0.8.5, et cette spécification garantit que vous obtiendrez la dernière version corrective qui compilera encore avec le code de ce chapitre. Toute version 0.9.0 ou supérieure n’est pas garantie d’avoir la même API que celle utilisée dans les exemples suivants.
Maintenant, sans modifier le code, construisons le projet, comme montré dans l’encart 2-2.
$ cargo build
Updating crates.io index
Locking 15 packages to latest Rust 1.85.0 compatible versions
Adding rand v0.8.5 (available: v0.9.0)
Compiling proc-macro2 v1.0.93
Compiling unicode-ident v1.0.17
Compiling libc v0.2.170
Compiling cfg-if v1.0.0
Compiling byteorder v1.5.0
Compiling getrandom v0.2.15
Compiling rand_core v0.6.4
Compiling quote v1.0.38
Compiling syn v2.0.98
Compiling zerocopy-derive v0.7.35
Compiling zerocopy v0.7.35
Compiling ppv-lite86 v0.2.20
Compiling rand_chacha v0.3.1
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 2.48s
cargo build after adding the rand crate as a dependencyVous pourriez voir des numéros de version différents (mais ils seront tous compatibles avec le code, grâce à SemVer !) et des lignes différentes (selon le système d’exploitation), et les lignes pourraient être dans un ordre différent.
Lorsque nous incluons une dépendance externe, Cargo récupère les dernières versions de tout ce dont cette dépendance a besoin depuis le registre, qui est une copie des données de [Crates.io][cratesio]. Crates.io est l’endroit où les membres de l’écosystème Rust publient leurs projets Rust open source pour que d’autres puissent les utiliser.
Après avoir mis à jour le registre, Cargo vérifie la section [dependencies] et télécharge toutes les crates listées qui ne sont pas encore téléchargées. Dans ce cas, bien que nous n’ayons listé que rand comme dépendance, Cargo a également récupéré d’autres crates dont rand dépend pour fonctionner. Après avoir téléchargé les crates, Rust les compilé puis compilé le projet avec les dépendances disponibles.
Si vous exécutez immédiatement cargo build à nouveau sans apporter de modifications, vous n’obtiendrez aucune sortie à part la ligne Finished. Cargo sait qu’il a déjà téléchargé et compilé les dépendances, et que vous n’avez rien changé dans votre fichier Cargo.toml. Cargo sait également que vous n’avez rien changé dans votre code, donc il ne le recompile pas non plus. N’ayant rien à faire, il se terminé simplement.
Si vous ouvrez le fichier src/main.rs, faites une modification mineure, puis sauvegardez-le et reconstruisez, vous ne verrez que deux lignes de sortie :
$ cargo build
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Ces lignes montrent que Cargo ne met à jour la compilation qu’avec votre petite modification du fichier src/main.rs. Vos dépendances n’ont pas changé, donc Cargo sait qu’il peut réutiliser ce qu’il a déjà téléchargé et compilé pour celles-ci.
Garantir des compilations reproductibles
Cargo dispose d’un mécanisme qui garantit que vous pouvez reconstruire le même artefact à chaque fois que vous ou quelqu’un d’autre compilé votre code : Cargo n’utilisera que les versions des dépendances que vous avez spécifiées tant que vous n’indiquez pas le contraire. Par exemple, supposons que la semaine prochaine la version 0.8.6 de la crate rand sorte, et que cette version contienne un correctif important, mais aussi une régression qui casserait votre code. Pour gérer cela, Rust crée le fichier Cargo.lock la première fois que vous exécutez cargo build, donc nous avons maintenant ce fichier dans le répertoire guessing_game.
Lorsque vous compilez un projet pour la première fois, Cargo détermine toutes les versions des dépendances qui correspondent aux critères et les écrit dans le fichier Cargo.lock. Lorsque vous compilerez votre projet à l’avenir, Cargo verra que le fichier Cargo.lock existe et utilisera les versions spécifiées dedans plutôt que de refaire tout le travail de détermination des versions. Cela vous permet d’avoir une compilation reproductible automatiquement. En d’autres termes, votre projet restera en version 0.8.5 jusqu’à ce que vous fassiez une mise à jour explicite, grâce au fichier Cargo.lock. Comme le fichier Cargo.lock est important pour les compilations reproductibles, il est souvent versionné dans le contrôle de source avec le reste du code de votre projet.
Mettre à jour une crate pour obtenir une nouvelle version
Lorsque vous souhaitez effectivement mettre à jour une crate, Cargo fournit la commande update, qui ignorera le fichier Cargo.lock et déterminera toutes les dernières versions correspondant à vos spécifications dans Cargo.toml. Cargo écrira ensuite ces versions dans le fichier Cargo.lock. Par défaut, Cargo ne cherchera que les versions supérieures à 0.8.5 et inférieures à 0.9.0. Si la crate rand a publié deux nouvelles versions 0.8.6 et 0.999.0, vous verriez ce qui suit en exécutant cargo update :
$ cargo update
Updating crates.io index
Locking 1 package to latest Rust 1.85.0 compatible version
Updating rand v0.8.5 -> v0.8.6 (available: v0.999.0)
Cargo ignore la version 0.999.0. À ce stade, vous remarqueriez également un changement dans votre fichier Cargo.lock indiquant que la version de la crate rand que vous utilisez maintenant est 0.8.6. Pour utiliser la version 0.999.0 de rand ou toute version de la série 0.999.x, vous devriez mettre à jour le fichier Cargo.toml pour qu’il ressemble à ceci (ne faites pas réellement cette modification car les exemples suivants supposent que vous utilisez rand 0.8) :
[dependencies]
rand = "0.999.0"
La prochaine fois que vous exécuterez cargo build, Cargo mettra à jour le registre des crates disponibles et réévaluera vos exigences pour rand selon la nouvelle version que vous avez spécifiée.
Il y a beaucoup plus à dire sur Cargo et son écosystème, ce que nous aborderons au chapitre 14, mais pour l’instant, c’est tout ce que vous devez savoir. Cargo facilite la réutilisation des bibliothèques, les Rustaceans peuvent donc écrire des projets plus petits assemblés à partir d’un certain nombre de paquets.
Générer un nombre aléatoire
Commençons à utiliser rand pour générer un nombre à deviner. L’étape suivante est de mettre à jour src/main.rs, comme montré dans l’encart 2-3.
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}D’abord, nous ajoutons la ligne use rand::Rng;. Le trait Rng définit des méthodes que les générateurs de nombres aléatoires implémentent, et ce trait doit être dans la portée pour que nous puissions utiliser ces méthodes. Le chapitre 10 couvrira les traits en détail.
Ensuite, nous ajoutons deux lignes au milieu. Dans la première ligne, nous appelons la fonction rand::thread_rng qui nous donne le générateur de nombres aléatoires particulier que nous allons utiliser : un générateur local au thread d’exécution actuel et initialisé par le système d’exploitation. Puis, nous appelons la méthode gen_range sur le générateur de nombres aléatoires. Cette méthode est définie par le trait Rng que nous avons importé dans la portée avec l’instruction use rand::Rng;. La méthode gen_range prend une expression d’intervalle comme argument et génère un nombre aléatoire dans cet intervalle. Le type d’expression d’intervalle que nous utilisons ici prend la forme start..=end et est inclusif sur les bornes inférieure et supérieure, nous devons donc spécifier 1..=100 pour demander un nombre entre 1 et 100.
Remarque : vous ne saurez pas spontanément quels traits utiliser et quelles méthodes et fonctions appeler depuis une crate, c’est pourquoi chaque crate dispose d’une documentation avec des instructions d’utilisation. Une autre fonctionnalité pratique de Cargo est que l’exécution de la commande
cargo doc --openconstruira la documentation fournie par toutes vos dépendances localement et l’ouvrira dans votre navigateur. Si vous êtes intéressé par d’autres fonctionnalités de la craterand, par exemple, exécutezcargo doc --openet cliquez surranddans la barre latérale de gauche.
La deuxième nouvelle ligne affiche le nombre secret. C’est utile pendant que nous développons le programme pour pouvoir le tester, mais nous la supprimerons de la version finale. Ce n’est pas vraiment un jeu si le programme affiche la réponse dès qu’il démarre !
Essayez d’exécuter le programme quelques fois :
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 7
Please input your guess.
4
You guessed: 4
$ cargo run
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.02s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 83
Please input your guess.
5
You guessed: 5
Vous devriez obtenir des nombres aléatoires différents, et ils devraient tous être des nombres entre 1 et 100. Bon travail !
Comparer la proposition au nombre secret
Maintenant que nous avons la saisie de l’utilisateur et un nombre aléatoire, nous pouvons les comparer. Cette étape est montrée dans l’encart 2-4. Notez que ce code ne compilera pas encore, comme nous allons l’expliquer.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
// --snip--
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}D’abord, nous ajoutons une autre instruction use, important un type appelé std::cmp::Ordering depuis la bibliothèque standard. Le type Ordering est un autre enum et possède les variantes Less, Greater et Equal. Ce sont les trois résultats possibles lorsque vous comparez deux valeurs.
Ensuite, nous ajoutons cinq nouvelles lignes en bas qui utilisent le type Ordering. La méthode cmp compare deux valeurs et peut être appelée sur tout ce qui peut être comparé. Elle prend une référence vers ce avec quoi vous voulez comparer : ici, elle compare guess à secret_number. Puis, elle renvoie une variante de l’enum Ordering que nous avons importé dans la portée avec l’instruction use. Nous utilisons une expression [match][match] pour décider quoi faire ensuite en fonction de la variante d’Ordering renvoyée par l’appel à cmp avec les valeurs de guess et secret_number.
Une expression match est composée de branches. Une branche consiste en un motif auquel correspondre et le code qui devrait être exécuté si la valeur donnée au match correspond au motif de cette branche. Rust prend la valeur donnée au match et examine le motif de chaque branche tour à tour. Les motifs et la construction match sont des fonctionnalités puissantes de Rust : ils vous permettent d’exprimer une variété de situations que votre code pourrait rencontrer et s’assurent que vous les gérez toutes. Ces fonctionnalités seront couvertes en détail aux chapitres 6 et 19, respectivement.
Parcourons un exemple avec l’expression match que nous utilisons ici. Disons que l’utilisateur a proposé 50 et que le nombre secret généré aléatoirement cette fois est 38.
Lorsque le code compare 50 à 38, la méthode cmp renverra Ordering::Greater car 50 est supérieur à 38. L’expression match reçoit la valeur Ordering::Greater et commence à vérifier le motif de chaque branche. Elle regarde le motif de la première branche, Ordering::Less, et constate que la valeur Ordering::Greater ne correspond pas à Ordering::Less, donc elle ignore le code de cette branche et passe à la suivante. Le motif de la branche suivante est Ordering::Greater, qui correspond bien à Ordering::Greater ! Le code associé à cette branche s’exécutera et affichera Too big! à l’écran. L’expression match se terminé après la première correspondance réussie, donc elle ne regardera pas la dernière branche dans ce scénario.
Cependant, le code de l’encart 2-4 ne compilera pas encore. Essayons :
$ cargo build
Compiling libc v0.2.86
Compiling getrandom v0.2.2
Compiling cfg-if v1.0.0
Compiling ppv-lite86 v0.2.10
Compiling rand_core v0.6.2
Compiling rand_chacha v0.3.0
Compiling rand v0.8.5
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
error[E0308]: mismatched types
--> src/main.rs:23:21
|
23 | match guess.cmp(&secret_number) {
| --- ^^^^^^^^^^^^^^ expected `&String`, found `&{integer}`
| |
| arguments to this method are incorrect
|
= note: expected reference `&String`
found reference `&{integer}`
note: method defined here
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/cmp.rs:979:8
For more information about this error, try `rustc --explain E0308`.
error: could not compile `guessing_game` (bin "guessing_game") due to 1 previous error
Le coeur de l’erreur indique qu’il y à des types incompatibles. Rust possède un système de types fort et statique. Cependant, il dispose également de l’inférence de types. Lorsque nous avons écrit let mut guess = String::new(), Rust a pu inférer que guess devait être un String et ne nous a pas demandé d’écrire le type. Le secret_number, en revanche, est un type numérique. Plusieurs types numériques de Rust peuvent avoir une valeur entre 1 et 100 : i32, un nombre 32 bits ; u32, un nombre 32 bits non signé ; i64, un nombre 64 bits ; ainsi que d’autres. Sauf indication contraire, Rust utilise par défaut un i32, qui est le type de secret_number à moins que vous n’ajoutiez des informations de type ailleurs qui amèneraient Rust à inférer un type numérique différent. La raison de l’erreur est que Rust ne peut pas comparer une chaîne de caractères et un type numérique.
En fin de compte, nous voulons convertir le String que le programme lit en entrée en un type numérique afin de pouvoir le comparer numériquement au nombre secret. Nous le faisons en ajoutant cette ligne au corps de la fonction main : Fichier : src/main.rs rust,ignore {{#rustdoc_include ../listings/ch02-guessing-game-tutorial/no-listing-03-convert-string-to-number/src/main.rs:here}}
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}La ligne est :
let guess: u32 = guess.trim().parse().expect("Please type a number!");Nous créons une variable nommée guess. Mais attendez, le programme n’a-t-il pas déjà une variable nommée guess ? C’est le cas, mais Rust nous permet utilement de masquer la valeur précédente de guess avec une nouvelle. Le masquage (shadowing) nous permet de réutiliser le nom de variable guess plutôt que de nous forcer à créer deux variables distinctes, comme guess_str et guess, par exemple. Nous couvrirons cela plus en détail au [chapitre 3][shadowing], mais pour l’instant, sachez que cette fonctionnalité est souvent utilisée lorsque vous voulez convertir une valeur d’un type vers un autre type.
Nous lions cette nouvelle variable à l’expression guess.trim().parse(). Le guess dans l’expression fait référence à la variable guess originale qui contenait la saisie sous forme de chaîne. La méthode trim sur une instance de String éliminera tous les espaces blancs au début et à la fin, ce que nous devons faire avant de pouvoir convertir la chaîne en u32, qui ne peut contenir que des données numériques. L’utilisateur doit appuyer sur Entrée pour valider read_line et saisir sa proposition, ce qui ajouté un caractère de nouvelle ligne à la chaîne. Par exemple, si l’utilisateur tape 5 et appuie sur Entrée, guess ressemble à ceci : 5 . Le représente un “retour à la ligne”. (Sous Windows, appuyer sur Entrée produit un retour chariot et un retour à la ligne, \r .) La méthode trim élimine ou \r , ne laissant que 5.
La méthode parse sur les chaînes convertit une chaîne vers un autre type. Ici, nous l’utilisons pour convertir une chaîne en nombre. Nous devons indiquer à Rust le type numérique exact que nous voulons en utilisant let guess: u32. Les deux-points (:) après guess indiquent à Rust que nous annoterons le type de la variable. Rust possède quelques types numériques intégrés ; le u32 vu ici est un entier non signé de 32 bits. C’est un bon choix par défaut pour un petit nombre positif. Vous en apprendrez davantage sur les autres types numériques au chapitre 3.
De plus, l’annotation u32 dans ce programme d’exemple et la comparaison avec secret_number signifient que Rust inférera que secret_number devrait également être un u32. Ainsi, la comparaison se fera maintenant entre deux valeurs du même type !
La méthode parse ne fonctionnera que sur des caractères qui peuvent logiquement être convertis en nombres et peut donc facilement provoquer des erreurs. Si, par exemple, la chaîne contenait A👍%, il n’y aurait aucun moyen de la convertir en nombre. Comme elle peut échouer, la méthode parse renvoie un type Result, tout comme la méthode read_line (discutée précédemment dans “Gérer les erreurs potentielles avec Result”). Nous traiterons ce Result de la même manière en utilisant à nouveau la méthode expect. Si parse renvoie une variante Err de Result parce qu’elle n’a pas pu créer un nombre à partir de la chaîne, l’appel à expect fera planter le jeu et affichera le message que nous lui donnons. Si parse peut convertir avec succès la chaîne en nombre, elle renverra la variante Ok de Result, et expect renverra le nombre que nous voulons à partir de la valeur Ok.
Exécutons le programme maintenant :
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.26s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 58
Please input your guess.
76
You guessed: 76
Too big!
Super ! Même si des espaces ont été ajoutés avant la proposition, le programme a quand même déterminé que l’utilisateur a proposé 76. Exécutez le programme plusieurs fois pour vérifier le comportement différent avec différents types de saisie : devinez le nombre correctement, proposez un nombre trop élevé et proposez un nombre trop bas.
La majeure partie du jeu fonctionne maintenant, mais l’utilisateur ne peut faire qu’une seule proposition. Changeons cela en ajoutant une boucle !
Permettre plusieurs propositions avec une boucle
Le mot-clé loop crée une boucle infinie. Nous allons ajouter une boucle pour donner aux utilisateurs plus de chances de deviner le nombre : Fichier : src/main.rs rust,ignore {{#rustdoc_include ../listings/ch02-guessing-game-tutorial/no-listing-04-looping/src/main.rs:here}}
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
// --snip--
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
// --snip--
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}
}Comme vous pouvez le voir, nous avons déplacé tout ce qui suit l’invite de saisie dans une boucle. Assurez-vous d’indenter les lignes à l’intérieur de la boucle de quatre espaces supplémentaires chacune et relancez le programme. Le programme demandera désormais une nouvelle proposition indéfiniment, ce qui introduit en fait un nouveau problème. Il semble que l’utilisateur ne puisse pas quitter !
L’utilisateur pourrait toujours interrompre le programme en utilisant le raccourci clavier ctrl-C. Mais il existe une autre façon d’échapper à ce monstre insatiable, comme mentionné dans la discussion sur parse dans « Comparer la supposition au nombre secret » : si le jeu obtient un nombre non valide, le programme plantera. Nous allons exploiter cela pour permettre à l’utilisateur de quitter en cas d’erreur, comme le montre l’Encart 2-5 :
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.23s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 59
Please input your guess.
45
You guessed: 45
Too small!
Please input your guess.
60
You guessed: 60
Too big!
Please input your guess.
59
You guessed: 59
You win!
Please input your guess.
quit
thread 'main' panicked at src/main.rs:28:47:
Please type a number!: ParseIntError { kind: InvalidDigit }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Taper quit quittera le jeu, mais comme vous le remarquerez, saisir toute autre entrée non numérique le fera également. C’est sous-optimal, c’est le moins que l’on puisse dire ; nous voulons que le jeu s’arrête également lorsque le bon nombre est deviné.
Quitter après une bonne réponse
Programmons le jeu pour qu’il se terminé lorsque l’utilisateur gagne en ajoutant une instruction break : Fichier : src/main.rs rust,ignore {{#rustdoc_include ../listings/ch02-guessing-game-tutorial/no-listing-05-quitting/src/main.rs:here}}
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Ajouter la ligne break après You win! fait sortir le programme de la boucle lorsque l’utilisateur devine correctement le nombre secret. Sortir de la boucle signifie également quitter le programme, car la boucle est la dernière partie de main.
Gérer les saisies invalides
Pour affiner davantage le comportement du jeu, plutôt que de faire planter le programme lorsque l’utilisateur saisit autre chose qu’un nombre, faisons en sorte que le jeu ignore les saisies non numériques pour que l’utilisateur puisse continuer à deviner. Nous pouvons le faire en modifiant la ligne où guess est converti d’un String en u32, comme montré dans l’encart 2-5.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}Nous passons d’un appel à expect à une expression match pour passer d’un plantage en cas d’erreur à une gestion de l’erreur. Rappelez-vous que parse renvoie un type Result et que Result est un enum avec les variantes Ok et Err. Nous utilisons ici une expression match, comme nous l’avons fait avec le résultat Ordering de la méthode cmp.
Si parse parvient à transformer la chaîne en nombre, elle renverra une valeur Ok contenant le nombre résultant. Cette valeur Ok correspondra au motif de la première branche, et l’expression match renverra simplement la valeur num que parse a produite et placée dans la valeur Ok. Ce nombre se retrouvera exactement là où nous le voulons, dans la nouvelle variable guess que nous créons.
Si parse n’est pas en mesure de transformer la chaîne en nombre, elle renverra une valeur Err contenant plus d’informations sur l’erreur. La valeur Err ne correspond pas au motif Ok(num) de la première branche du match, mais elle correspond au motif Err(_) de la seconde branche. Le tiret bas, _, est une valeur attrape-tout ; dans cet exemple, nous disons que nous voulons correspondre à toutes les valeurs Err, peu importe les informations qu’elles contiennent. Ainsi, le programme exécutera le code de la seconde branche, continue, qui indique au programme de passer à l’itération suivante de la boucle loop et de demander une autre proposition. De fait, le programme ignore toutes les erreurs que parse pourrait rencontrer !
Maintenant, tout dans le programme devrait fonctionner comme prévu. Essayons :
$ cargo run
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.13s
Running `target/debug/guessing_game`
Guess the number!
The secret number is: 61
Please input your guess.
10
You guessed: 10
Too small!
Please input your guess.
99
You guessed: 99
Too big!
Please input your guess.
foo
Please input your guess.
61
You guessed: 61
You win!
Parfait ! Avec un dernier petit ajustement, nous terminerons le jeu de devinettes. Rappelez-vous que le programme affiche encore le nombre secret. Cela fonctionnait bien pour les tests, mais cela gâche le jeu. Supprimons le println! qui affiche le nombre secret. L’encart 2-6 montre le code final.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}À ce stade, vous avez construit avec succès le jeu de devinettes. Félicitations !
Résumé
Ce projet était une façon pratique de vous présenter de nombreux nouveaux concepts de Rust : let, match, les fonctions, l’utilisation de crates externes, et bien plus. Dans les prochains chapitres, vous en apprendrez davantage sur ces concepts. Le chapitre 3 couvre les concepts que la plupart des langages de programmation possèdent, comme les variables, les types de données et les fonctions, et montre comment les utiliser en Rust. Le chapitre 4 explore la possession (ownership), une fonctionnalité qui distingue Rust des autres langages. Le chapitre 5 traite des structures (structs) et de la syntaxe des méthodes, et le chapitre 6 explique le fonctionnement des enums.
Les concepts courants de programmation
Ce chapitre couvre des concepts que l’on retrouve dans presque tous les langages de programmation, et la manière dont ils fonctionnent en Rust. De nombreux langages de programmation partagent un socle commun. Aucun des concepts présentés dans ce chapitre n’est propre à Rust, mais nous les aborderons dans le contexte de Rust et expliquerons les conventions qui entourent leur utilisation.
Plus précisément, vous découvrirez les variables, les types de base, les fonctions, les commentaires et le flux de contrôle. Ces fondamentaux se retrouvent dans chaque programme Rust, et les apprendre tôt vous donnera une base solide pour démarrer.
Mots-clés
Le langage Rust possède un ensemble de mots-clés qui sont réservés à l’usage exclusif du langage, comme dans d’autres langages. Gardez à l’esprit que vous ne pouvez pas utiliser ces mots comme noms de variables ou de fonctions. La plupart des mots-clés ont des significations particulières, et vous les utiliserez pour accomplir diverses tâches dans vos programmes Rust ; quelques-uns n’ont pas de fonctionnalité actuelle qui leur est associée mais ont été réservés pour une fonctionnalité qui pourrait être ajoutée à Rust dans le futur. Vous pouvez trouver une liste des mots-clés dans l’annexe A.
Les variables et la mutabilité
Les variables et la mutabilité
Comme mentionné dans la section « Stocker des valeurs dans des variables », par défaut, les variables sont immuables. C’est l’un des nombreux coups de pouce que Rust vous donne pour écrire votre code d’une manière qui tire parti de la sécurité et de la concurrence facile qu’offre Rust. Cependant, vous avez toujours la possibilité de rendre vos variables mutables. Explorons comment et pourquoi Rust vous encourage à privilégier l’immuabilité et pourquoi parfois vous voudrez peut-être vous désengager.
Lorsqu’une variable est immuable, une fois qu’une valeur est liée à un nom, vous ne pouvez pas modifier cette valeur. Pour illustrer cela, générez un nouveau projet appelé variables dans votre répertoire projects en utilisant cargo new variables.
Ensuite, dans votre nouveau répertoire variables, ouvrez src/main.rs et remplacez son code par le code suivant, qui ne compilera pas encore :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let x = 5;
println!("The value of x is: {x}");
x = 6;
println!("The value of x is: {x}");
}Enregistrez et exécutez le programme avec cargo run. Vous devriez recevoir un message d’erreur concernant une erreur d’immuabilité, comme le montre cette sortie : console {{#include ../listings/ch03-common-programming-concepts/no-listing-01-variables-are-immutable/output.txt}}
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0384]: cannot assign twice to immutable variable `x`
--> src/main.rs:4:5
|
2 | let x = 5;
| - first assignment to `x`
3 | println!("The value of x is: {x}");
4 | x = 6;
| ^^^^^ cannot assign twice to immutable variable
|
help: consider making this binding mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0384`.
error: could not compile `variables` (bin "variables") due to 1 previous error
Cet exemple montre comment le compilateur vous aide à trouver les erreurs dans vos programmes. Les erreurs de compilation peuvent être frustrantes, mais en réalité elles signifient seulement que votre programme ne fait pas encore ce que vous voulez qu’il fasse de manière sûre ; elles ne signifient pas que vous n’êtes pas un bon programmeur ! Les Rustacés expérimentés obtiennent eux aussi des erreurs de compilation.
Vous avez reçu le message d’erreur cannot assign twice to immutable variable `x` parce que vous avez essayé d’assigner une seconde valeur à la variable immuable x.
Il est important que nous obtenions des erreurs à la compilation lorsque nous essayons de modifier une valeur désignée comme immuable, car cette situation peut mener à des bogues. Si une partie de notre code fonctionne en supposant qu’une valeur ne changera jamais et qu’une autre partie de notre code modifié cette valeur, il est possible que la première partie du code ne fasse pas ce pour quoi elle a été conçue. La cause de ce type de bogue peut être difficile à retrouver après coup, surtout lorsque la seconde portion de code ne modifié la valeur que parfois. Le compilateur Rust garantit que lorsque vous déclarez qu’une valeur ne changera pas, elle ne changera vraiment pas, de sorte que vous n’avez pas à en garder la trace vous-même. Votre code est ainsi plus facile à comprendre.
Mais la mutabilité peut être très utile et peut rendre le code plus pratique à écrire. Bien que les variables soient immuables par défaut, vous pouvez les rendre mutables en ajoutant mut devant le nom de la variable, comme vous l’avez fait au [chapitre 2][storing-values-with-variables]. L’ajout de mut transmet également une intention aux futurs lecteurs du code en indiquant que d’autres parties du code modifieront la valeur de cette variable.
Par exemple, modifions src/main.rs comme suit :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let mut x = 5;
println!("The value of x is: {x}");
x = 6;
println!("The value of x is: {x}");
}Lorsque nous exécutons le programme maintenant, nous obtenons ceci : console {{#include ../listings/ch03-common-programming-concepts/no-listing-02-adding-mut/output.txt}}
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/variables`
The value of x is: 5
The value of x is: 6
Nous sommes autorisés à changer la valeur liée à x de 5 à 6 lorsque mut est utilisé. En fin de compte, le choix d’utiliser ou non la mutabilité vous appartient et dépend de ce que vous estimez être le plus clair dans cette situation particulière.
Déclarer des constantes
Comme les variables immuables, les constantes sont des valeurs qui sont liées à un nom et ne peuvent pas être modifiées, mais il existe quelques différences entre les constantes et les variables.
Premièrement, vous ne pouvez pas utiliser mut avec les constantes. Les constantes ne sont pas simplement immuables par défaut — elles sont toujours immuables. Vous déclarez les constantes en utilisant le mot-clé const au lieu du mot-clé let, et le type de la valeur doit être annoté. Nous aborderons les types et les annotations de type dans la section suivante, [« Les types de données »][data-types], donc ne vous souciez pas des détails pour le moment. Sachez simplement que vous devez toujours annoter le type.
Les constantes peuvent être déclarées dans n’importe quelle portée, y compris la portée globale, ce qui les rend utiles pour les valeurs que de nombreuses parties du code doivent connaître.
La dernière différence est que les constantes ne peuvent être définies qu’avec une expression constante, et non avec le résultat d’une valeur qui ne pourrait être calculée qu’à l’exécution.
Voici un exemple de déclaration de constante :
#![allow(unused)]
fn main() {
const THREE_HOURS_IN_SECONDS: u32 = 60 * 60 * 3;
}Le nom de la constante est THREE_HOURS_IN_SECONDS, et sa valeur est définie comme le résultat de la multiplication de 60 (le nombre de secondes dans une minute) par 60 (le nombre de minutes dans une heure) par 3 (le nombre d’heures que nous voulons compter dans ce programme). La convention de nommage de Rust pour les constantes est d’utiliser des majuscules avec des tirets bas entre les mots. Le compilateur est capable d’évaluer un ensemble limité d’opérations à la compilation, ce qui nous permet de choisir d’écrire cette valeur d’une manière plus facile à comprendre et à vérifier, plutôt que de définir cette constante à la valeur 10 800. Consultez la [section de la référence Rust sur l’évaluation des constantes][const-eval] pour plus d’informations sur les opérations utilisables lors de la déclaration de constantes.
Les constantes sont valides pendant toute la durée d’exécution d’un programme, dans la portée dans laquelle elles ont été déclarées. Cette propriété rend les constantes utiles pour les valeurs de votre domaine applicatif que plusieurs parties du programme pourraient avoir besoin de connaître, comme le nombre maximum de points qu’un joueur peut gagner dans un jeu, ou la vitesse de la lumière.
Nommer les valeurs codées en dur utilisées dans votre programme sous forme de constantes est utile pour transmettre la signification de cette valeur aux futurs mainteneurs du code. Cela permet également de n’avoir qu’un seul endroit dans votre code à modifier si la valeur codée en dur devait être mise à jour à l’avenir.
Le masquage
Comme vous l’avez vu dans le tutoriel du jeu de devinettes au chapitre 2, vous pouvez déclarer une nouvelle variable portant le même nom qu’une variable précédente. Les Rustacés disent que la première variable est masquée par la seconde, ce qui signifie que c’est la seconde variable que le compilateur verra lorsque vous utiliserez le nom de la variable. En effet, la seconde variable masque la première, prenant toute utilisation du nom de variable pour elle-même jusqu’à ce qu’elle-même soit masquée ou que la portée se terminé. Nous pouvons masquer une variable en utilisant le même nom de variable et en répétant l’utilisation du mot-clé let comme suit :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let x = 5;
let x = x + 1;
{
let x = x * 2;
println!("The value of x in the inner scope is: {x}");
}
println!("The value of x is: {x}");
}Ce programme lie d’abord x à la valeur 5. Puis, il crée une nouvelle variable x en répétant let x =, prenant la valeur originale et ajoutant 1 de sorte que la valeur de x est 6. Ensuite, dans une portée intérieure créée avec les accolades, la troisième instruction let masque également x et crée une nouvelle variable, multipliant la valeur précédente par 2 pour donner à x une valeur de 12. Quand cette portée se terminé, le masquage intérieur prend fin et x redevient 6. Lorsque nous exécutons ce programme, il affichera ce qui suit : console {{#include ../listings/ch03-common-programming-concepts/no-listing-03-shadowing/output.txt}}
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/variables`
The value of x in the inner scope is: 12
The value of x is: 6
Le masquage est différent du fait de marquer une variable comme mut car nous obtiendrons une erreur à la compilation si nous essayons accidentellement de réassigner cette variable sans utiliser le mot-clé let. En utilisant let, nous pouvons effectuer quelques transformations sur une valeur tout en rendant la variable immuable une fois ces transformations terminées.
L’autre différence entre mut et le masquage est que, puisque nous créons effectivement une nouvelle variable lorsque nous utilisons à nouveau le mot-clé let, nous pouvons changer le type de la valeur tout en réutilisant le même nom. Par exemple, supposons que notre programme demande à un utilisateur de montrer combien d’espaces il souhaite entre du texte en saisissant des caractères espace, et que nous voulons ensuite stocker cette entrée sous forme de nombre : rust {{#rustdoc_include ../listings/ch03-common-programming-concepts/no-listing-04-shadowing-can-change-types/src/main.rs:here}}
fn main() {
let spaces = " ";
let spaces = spaces.len();
}La première variable spaces est de type chaîne de caractères, et la seconde variable spaces est de type numérique. Le masquage nous évite ainsi de devoir trouver des noms différents, comme spaces_str et spaces_num ; nous pouvons plutôt réutiliser le nom plus simple spaces. Cependant, si nous essayons d’utiliser mut pour cela, comme montré ici, nous obtiendrons une erreur à la compilation : rust,ignore,does_not_compile {{#rustdoc_include ../listings/ch03-common-programming-concepts/no-listing-05-mut-cant-change-types/src/main.rs:here}}
fn main() {
let mut spaces = " ";
spaces = spaces.len();
}L’erreur indique que nous ne sommes pas autorisés à changer le type d’une variable : console {{#include ../listings/ch03-common-programming-concepts/no-listing-05-mut-cant-change-types/output.txt}}
$ cargo run
Compiling variables v0.1.0 (file:///projects/variables)
error[E0308]: mismatched types
--> src/main.rs:3:14
|
2 | let mut spaces = " ";
| ----- expected due to this value
3 | spaces = spaces.len();
| ^^^^^^^^^^^^ expected `&str`, found `usize`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `variables` (bin "variables") due to 1 previous error
Maintenant que nous avons exploré le fonctionnement des variables, examinons les différents types de données qu’elles peuvent avoir.
Les types de données
Les types de données
Chaque valeur en Rust est d’un certain type de données, qui indique à Rust quel genre de données est spécifié afin qu’il sache comment travailler avec ces données. Nous examinerons deux sous-ensembles de types de données : les scalaires et les composés.
Gardez à l’esprit que Rust est un langage à typage statique, ce qui signifie qu’il doit connaître les types de toutes les variables à la compilation. Le compilateur peut généralement inférer le type que nous voulons utiliser en se basant sur la valeur et la façon dont nous l’utilisons. Dans les cas où plusieurs types sont possibles, comme lorsque nous avons converti un String en type numérique en utilisant parse dans la section [« Comparer la supposition au nombre secret »][comparing-the-guess-to-the-secret-number] du chapitre 2, nous devons ajouter une annotation de type, comme ceci :
#![allow(unused)]
fn main() {
let guess: u32 = "42".parse().expect("Not a number!");
}Si nous n’ajoutons pas l’annotation de type : u32 montrée dans le code précédent, Rust affichera l’erreur suivante, ce qui signifie que le compilateur a besoin de plus d’informations de notre part pour savoir quel type nous voulons utiliser : console {{#include ../listings/ch03-common-programming-concepts/output-only-01-no-type-annotations/output.txt}}
$ cargo build
Compiling no_type_annotations v0.1.0 (file:///projects/no_type_annotations)
error[E0284]: type annotations needed
--> src/main.rs:2:9
|
2 | let guess = "42".parse().expect("Not a number!");
| ^^^^^ ----- type must be known at this point
|
= note: cannot satisfy `<_ as FromStr>::Err == _`
help: consider giving `guess` an explicit type
|
2 | let guess: /* Type */ = "42".parse().expect("Not a number!");
| ++++++++++++
For more information about this error, try `rustc --explain E0284`.
error: could not compile `no_type_annotations` (bin "no_type_annotations") due to 1 previous error
Vous verrez différentes annotations de type pour d’autres types de données.
Les types scalaires
Un type scalaire représente une valeur unique. Rust possède quatre types scalaires principaux : les entiers, les nombres à virgule flottante, les booléens et les caractères. Vous les reconnaîtrez peut-être d’autres langages de programmation. Voyons comment ils fonctionnent en Rust.
Les types entiers
Un entier est un nombre sans composante fractionnaire. Nous avons utilisé un type entier au chapitre 2, le type u32. Cette déclaration de type indique que la valeur qui lui est associée doit être un entier non signé (les types entiers signés commencent par i au lieu de u) qui occupe 32 bits d’espace. Le tableau 3-1 montre les types entiers intégrés à Rust. Nous pouvons utiliser n’importe laquelle de ces variantes pour déclarer le type d’une valeur entière.
Tableau 3-1 : Les types entiers en Rust
| Taille | Signé | Non signé |
|---|---|---|
| 8 bits | i8 | u8 |
| 16 bits | i16 | u16 |
| 32 bits | i32 | u32 |
| 64 bits | i64 | u64 |
| 128 bits | i128 | u128 |
| Dépend de l’architecture | isize | usize |
Chaque variante peut être signée ou non signée et possède une taille explicite. Signé et non signé font référence à la possibilité que le nombre soit négatif — en d’autres termes, si le nombre doit porter un signé (signé) ou s’il sera toujours positif et peut donc être représenté sans signé (non signé). C’est comme écrire des nombres sur du papier : quand le signé importe, un nombre est affiché avec un signé plus ou un signé moins ; cependant, quand on peut supposer sans risque que le nombre est positif, il est affiché sans signé. Les nombres signés sont stockés en utilisant la représentation en [complément à deux][twos-complement].
Chaque variante signée peut stocker des nombres de −(2n − 1) à 2n − 1 − 1 inclus, où n est le nombre de bits que la variante utilise. Ainsi, un i8 peut stocker des nombres de −(27) à 27 − 1, soit de −128 à 127. Les variantes non signées peuvent stocker des nombres de 0 à 2n − 1, donc un u8 peut stocker des nombres de 0 à 28 − 1, soit de 0 à 255.
De plus, les types isize et usize dépendent de l’architecture de l’ordinateur sur lequel votre programme s’exécute : 64 bits si vous êtes sur une architecture 64 bits et 32 bits si vous êtes sur une architecture 32 bits.
Vous pouvez écrire des littéraux entiers sous n’importe laquelle des formes indiquées dans le tableau 3-2. Notez que les littéraux numériques qui peuvent être de plusieurs types numériques permettent un suffixe de type, tel que 57u8, pour désigner le type. Les littéraux numériques peuvent également utiliser _ comme séparateur visuel pour rendre le nombre plus facile à lire, comme 1_000, qui aura la même valeur que si vous aviez spécifié 1000.
Tableau 3-2 : Les littéraux entiers en Rust
| Littéraux numériques | Exemple |
|---|---|
| Décimal | 98_222 |
| Hexadécimal | 0xff |
| Octal | 0o77 |
| Binaire | 0b1111_0000 |
Octet (u8 uniquement) | b'A' |
Alors comment savoir quel type d’entier utiliser ? Si vous n’êtes pas sûr, les valeurs par défaut de Rust sont généralement un bon point de départ : les types entiers ont pour valeur par défaut i32. La situation principale dans laquelle vous utiliseriez isize ou usize est lors de l’indexation d’une collection.
Dépassement d’entier
Supposons que vous ayez une variable de type u8 qui peut contenir des valeurs entre 0 et 255. Si vous essayez de changer la variable pour une valeur en dehors de cette plage, comme 256, un dépassement d’entier se produira, ce qui peut entraîner l’un des deux comportements suivants. Lorsque vous compilez en mode débogage, Rust inclut des vérifications de dépassement d’entier qui provoquent un panic de votre programme à l’exécution si ce comportement se produit. Rust utilise le terme panicking (paniquer) lorsqu’un programme se terminé avec une erreur ; nous discuterons des paniques plus en détail dans la section « Les erreurs irrécupérables avec panic! » du chapitre 9.
Lorsque vous compilez en mode release avec le drapeau --release, Rust n’inclut pas les vérifications de dépassement d’entier qui provoquent des panics. Au lieu de cela, si un dépassement se produit, Rust effectue un bouclage en complément à deux. En bref, les valeurs supérieures à la valeur maximale que le type peut contenir « bouclent » vers la valeur minimale que le type peut contenir. Dans le cas d’un u8, la valeur 256 devient 0, la valeur 257 devient 1, et ainsi de suite. Le programme ne paniquera pas, mais la variable aura une valeur qui n’est probablement pas celle que vous attendiez. S’appuyer sur le comportement de bouclage du dépassement d’entier est considéré comme une erreur.
Pour gérer explicitement la possibilité de dépassement, vous pouvez utiliser ces familles de méthodes fournies par la bibliothèque standard pour les types numériques primitifs :
- Boucler dans tous les modes avec les méthodes
wrapping_*, commewrapping_add. - Retourner la valeur
Nones’il y a dépassement avec les méthodeschecked_*. - Retourner la valeur et un booléen indiquant s’il y a eu dépassement avec les méthodes
overflowing_*. - Saturer aux valeurs minimale ou maximale avec les méthodes
saturating_*.
Les types à virgule flottante
Rust possède également deux types primitifs pour les nombres à virgule flottante, qui sont des nombres avec des décimales. Les types à virgule flottante de Rust sont f32 et f64, qui font respectivement 32 bits et 64 bits. Le type par défaut est f64 car sur les processeurs modernes, il est à peu près aussi rapide que f32 mais offre une plus grande précision. Tous les types à virgule flottante sont signés.
Voici un exemple qui montre les nombres à virgule flottante en action :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let x = 2.0; // f64
let y: f32 = 3.0; // f32
}Les nombres à virgule flottante sont représentés conformément à la norme IEEE-754.
Les opérations numériques
Rust prend en charge les opérations mathématiques de base que vous attendez pour tous les types numériques : addition, soustraction, multiplication, division et reste. La division entière tronque vers zéro à l’entier le plus proche. Le code suivant montre comment utiliser chaque opération numérique dans une instruction let :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
// addition
let sum = 5 + 10;
// subtraction
let difference = 95.5 - 4.3;
// multiplication
let product = 4 * 30;
// division
let quotient = 56.7 / 32.2;
let truncated = -5 / 3; // Results in -1
// remainder
let remainder = 43 % 5;
}Chaque expression dans ces instructions utilise un opérateur mathématique et s’évalue en une seule valeur, qui est ensuite liée à une variable. [L’annexe B][appendix_b] contient une liste de tous les opérateurs que Rust fournit.
Le type booléen
Comme dans la plupart des autres langages de programmation, un type booléen en Rust a deux valeurs possibles : true et false. Les booléens font un octet. Le type booléen en Rust est spécifié avec bool. Par exemple :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let t = true;
let f: bool = false; // with explicit type annotation
}La principale façon d’utiliser les valeurs booléennes est à travers les conditions, comme une expression if. Nous verrons comment les expressions if fonctionnent en Rust dans la section [« Flux de contrôle »][control-flow].
Le type caractère
Le type char de Rust est le type alphabétique le plus primitif du langage. Voici quelques exemples de déclaration de valeurs char :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let c = 'z';
let z: char = 'ℤ'; // with explicit type annotation
let heart_eyed_cat = '😻';
}Notez que nous spécifions les littéraux char avec des guillemets simples, contrairement aux littéraux de chaîne de caractères, qui utilisent des guillemets doubles. Le type char de Rust fait 4 octets et représente une valeur scalaire Unicode, ce qui signifie qu’il peut représenter bien plus que de l’ASCII. Les lettres accentuées ; les caractères chinois, japonais et coréens ; les emojis ; et les espaces de largeur nulle sont tous des valeurs char valides en Rust. Les valeurs scalaires Unicode vont de U+0000 à U+D7FF et de U+E000 à U+10FFFF inclus. Cependant, un « caractère » n’est pas vraiment un concept en Unicode, donc votre intuition humaine de ce qu’est un « caractère » peut ne pas correspondre à ce qu’est un char en Rust. Nous aborderons ce sujet en détail dans [« Stocker du texte encodé en UTF-8 avec les String »][strings] au chapitre 8.
Les types composés
Les types composés peuvent regrouper plusieurs valeurs en un seul type. Rust possède deux types composés primitifs : les tuples et les tableaux.
Le type tuple
Un tuple est un moyen général de regrouper un certain nombre de valeurs de types variés en un seul type composé. Les tuples ont une longueur fixe : une fois déclarés, ils ne peuvent ni grandir ni rétrécir.
Nous créons un tuple en écrivant une liste de valeurs séparées par des virgules entre parenthèses. Chaque position dans le tuple à un type, et les types des différentes valeurs du tuple n’ont pas besoin d’être identiques. Nous avons ajouté des annotations de type optionnelles dans cet exemple :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let tup: (i32, f64, u8) = (500, 6.4, 1);
}La variable tup est liée au tuple entier car un tuple est considéré comme un seul élément composé. Pour extraire les valeurs individuelles d’un tuple, nous pouvons utiliser le filtrage par motif pour déstructurer une valeur de tuple, comme ceci :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let tup = (500, 6.4, 1);
let (x, y, z) = tup;
println!("The value of y is: {y}");
}Ce programme crée d’abord un tuple et le lie à la variable tup. Il utilise ensuite un motif avec let pour prendre tup et le transformer en trois variables distinctes, x, y et z. C’est ce qu’on appelle la déstructuration car elle décompose le tuple unique en trois parties. Enfin, le programme affiche la valeur de y, qui est 6.4.
Nous pouvons également accéder directement à un élément du tuple en utilisant un point (.) suivi de l’index de la valeur à laquelle nous voulons accéder. Par exemple :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let x: (i32, f64, u8) = (500, 6.4, 1);
let five_hundred = x.0;
let six_point_four = x.1;
let one = x.2;
}Ce programme crée le tuple x puis accède à chaque élément du tuple en utilisant leurs indices respectifs. Comme dans la plupart des langages de programmation, le premier index d’un tuple est 0.
Le tuple sans aucune valeur porte un nom spécial, unit. Cette valeur et son type correspondant s’écrivent tous deux () et représentent une valeur vide ou un type de retour vide. Les expressions retournent implicitement la valeur unit si elles ne retournent aucune autre valeur.
Le type tableau
Une autre façon d’avoir une collection de plusieurs valeurs est d’utiliser un tableau (array). Contrairement à un tuple, chaque élément d’un tableau doit avoir le même type. Contrairement aux tableaux dans certains autres langages, les tableaux en Rust ont une longueur fixe.
Nous écrivons les valeurs d’un tableau sous forme de liste séparée par des virgules entre crochets :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let a = [1, 2, 3, 4, 5];
}Les tableaux sont utiles lorsque vous voulez que vos données soient allouées sur la pile, de la même manière que les autres types que nous avons vus jusqu’ici, plutôt que sur le tas (nous aborderons la pile et le tas plus en détail au [chapitre 4][stack-and-heap]) ou lorsque vous voulez vous assurer d’avoir toujours un nombre fixe d’éléments. Un tableau n’est cependant pas aussi flexible que le type vecteur. Un vecteur est un type de collection similaire fourni par la bibliothèque standard qui peut grandir ou rétrécir car son contenu vit sur le tas. Si vous n’êtes pas sûr de devoir utiliser un tableau ou un vecteur, il y a de fortes chances que vous devriez utiliser un vecteur. Le [chapitre 8][vectors] traite des vecteurs plus en détail.
Cependant, les tableaux sont plus utiles lorsque vous savez que le nombre d’éléments n’aura pas besoin de changer. Par exemple, si vous utilisiez les noms des mois dans un programme, vous utiliseriez probablement un tableau plutôt qu’un vecteur car vous savez qu’il contiendra toujours 12 éléments :
#![allow(unused)]
fn main() {
let months = ["January", "February", "March", "April", "May", "June", "July",
"August", "September", "October", "November", "December"];
}Vous écrivez le type d’un tableau en utilisant des crochets avec le type de chaque élément, un point-virgule, puis le nombre d’éléments dans le tableau, comme ceci :
#![allow(unused)]
fn main() {
let a: [i32; 5] = [1, 2, 3, 4, 5];
}Ici, i32 est le type de chaque élément. Après le point-virgule, le nombre 5 indique que le tableau contient cinq éléments.
Vous pouvez également initialiser un tableau pour qu’il contienne la même valeur pour chaque élément en spécifiant la valeur initiale, suivie d’un point-virgule, puis la longueur du tableau entre crochets, comme montré ici :
#![allow(unused)]
fn main() {
let a = [3; 5];
}Le tableau nommé a contiendra 5 éléments qui seront tous initialisés à la valeur 3. C’est la même chose que d’écrire let a = [3, 3, 3, 3, 3]; mais de manière plus concise.
Accès aux éléments d’un tableau
Un tableau est un bloc de mémoire unique d’une taille connue et fixe qui peut être alloué sur la pile. Vous pouvez accéder aux éléments d’un tableau en utilisant l’indexation, comme ceci :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let a = [1, 2, 3, 4, 5];
let first = a[0];
let second = a[1];
}Dans cet exemple, la variable nommée first obtiendra la valeur 1 car c’est la valeur à l’index [0] dans le tableau. La variable nommée second obtiendra la valeur 2 à l’index [1] dans le tableau.
Accès invalide à un élément de tableau
Voyons ce qui se passe si vous essayez d’accéder à un élément d’un tableau qui dépasse la fin du tableau. Supposons que vous exécutiez ce code, similaire au jeu de devinettes du chapitre 2, pour obtenir un index de tableau de la part de l’utilisateur :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
use std::io;
fn main() {
let a = [1, 2, 3, 4, 5];
println!("Please enter an array index.");
let mut index = String::new();
io::stdin()
.read_line(&mut index)
.expect("Failed to read line");
let index: usize = index
.trim()
.parse()
.expect("Index entered was not a number");
let element = a[index];
println!("The value of the element at index {index} is: {element}");
}Ce code compilé avec succès. Si vous exécutez ce code avec cargo run et saisissez 0, 1, 2, 3 ou 4, le programme affichera la valeur correspondante à cet index dans le tableau. Si vous saisissez plutôt un nombre dépassant la fin du tableau, comme 10, vous verrez une sortie comme celle-ci :
thread 'main' panicked at src/main.rs:19:19:
index out of bounds: the len is 5 but the index is 10
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Le programme a provoqué une erreur à l’exécution au moment de l’utilisation d’une valeur invalide dans l’opération d’indexation. Le programme s’est terminé avec un message d’erreur et n’a pas exécuté la dernière instruction println!. Lorsque vous tentez d’accéder à un élément par indexation, Rust vérifie que l’index que vous avez spécifié est inférieur à la longueur du tableau. Si l’index est supérieur ou égal à la longueur, Rust paniquera. Cette vérification doit avoir lieu à l’exécution, surtout dans ce cas, car le compilateur ne peut pas savoir quelle valeur un utilisateur saisira lorsqu’il exécutera le code plus tard.
C’est un exemple des principes de sécurité mémoire de Rust en action. Dans de nombreux langages bas niveau, ce type de vérification n’est pas effectué, et lorsque vous fournissez un index incorrect, de la mémoire invalide peut être accédée. Rust vous protège contre ce type d’erreur en quittant immédiatement au lieu de permettre l’accès mémoire et de continuer. Le chapitre 9 aborde plus en détail la gestion des erreurs de Rust et comment vous pouvez écrire du code lisible et sûr qui ne panique pas et ne permet pas d’accès mémoire invalide.
Les fonctions
Les fonctions
Les fonctions sont omniprésentes dans le code Rust. Vous avez déjà vu l’une des fonctions les plus importantes du langage : la fonction main, qui est le point d’entrée de nombreux programmes. Vous avez également vu le mot-clé fn, qui vous permet de déclarer de nouvelles fonctions.
Le code Rust utilise le snake case comme convention de style pour les noms de fonctions et de variables, dans laquelle toutes les lettres sont en minuscules et les mots sont séparés par des tirets bas (underscores). Voici un programme qui contient un exemple de définition de fonction :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
println!("Hello, world!");
another_function();
}
fn another_function() {
println!("Another function.");
}Nous définissons une fonction en Rust en saisissant fn suivi d’un nom de fonction et d’un jeu de parenthèses. Les accolades indiquent au compilateur où le corps de la fonction commence et se terminé.
Nous pouvons appeler n’importe quelle fonction que nous avons définie en saisissant son nom suivi d’un jeu de parenthèses. Comme another_function est définie dans le programme, elle peut être appelée depuis la fonction main. Notez que nous avons défini another_function après la fonction main dans le code source ; nous aurions tout aussi bien pu la définir avant. Rust ne se soucie pas de l’endroit où vous définissez vos fonctions, seulement qu’elles soient définies quelque part dans une portée visible par l’appelant.
Créons un nouveau projet binaire nommé functions pour explorer davantage les fonctions. Placez l’exemple another_function dans src/main.rs et exécutez-le. Vous devriez voir la sortie suivante : console {{#include ../listings/ch03-common-programming-concepts/no-listing-16-functions/output.txt}}
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.28s
Running `target/debug/functions`
Hello, world!
Another function.
Les lignes s’exécutent dans l’ordre dans lequel elles apparaissent dans la fonction main. D’abord le message “Hello, world!” s’affiche, puis another_function est appelée et son message est affiché.
Les paramètres
Nous pouvons définir des fonctions avec des paramètres, qui sont des variables spéciales faisant partie de la signature d’une fonction. Lorsqu’une fonction à des paramètres, vous pouvez lui fournir des valeurs concrètes pour ces paramètres. Techniquement, les valeurs concrètes sont appelées arguments, mais dans la conversation courante, les gens ont tendance à utiliser les mots paramètre et argument de manière interchangeable pour désigner soit les variables dans la définition d’une fonction, soit les valeurs concrètes passées lors de l’appel d’une fonction.
Dans cette version de another_function, nous ajoutons un paramètre :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
another_function(5);
}
fn another_function(x: i32) {
println!("The value of x is: {x}");
}Essayez d’exécuter ce programme ; vous devriez obtenir la sortie suivante : console {{#include ../listings/ch03-common-programming-concepts/no-listing-17-functions-with-parameters/output.txt}}
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.21s
Running `target/debug/functions`
The value of x is: 5
La déclaration de another_function à un paramètre nommé x. Le type de x est spécifié comme i32. Lorsque nous passons 5 à another_function, la macro println! place 5 à l’endroit où se trouvait la paire d’accolades contenant x dans la chaîne de format.
Dans les signatures de fonctions, vous devez déclarer le type de chaque paramètre. C’est une décision délibérée dans la conception de Rust : exiger des annotations de type dans les définitions de fonctions signifie que le compilateur n’a presque jamais besoin que vous les utilisiez ailleurs dans le code pour déterminer le type que vous souhaitez. Le compilateur est également en mesure de fournir des messages d’erreur plus utiles s’il connaît les types attendus par la fonction.
Lorsque vous définissez plusieurs paramètres, séparez les déclarations de paramètres par des virgules, comme ceci :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
print_labeled_measurement(5, 'h');
}
fn print_labeled_measurement(value: i32, unit_label: char) {
println!("The measurement is: {value}{unit_label}");
}Cet exemple crée une fonction nommée print_labeled_measurement avec deux paramètres. Le premier paramètre est nommé value et est de type i32. Le second est nommé unit_label et est de type char. La fonction affiche ensuite un texte contenant à la fois value et unit_label.
Essayons d’exécuter ce code. Remplacez le programme actuellement dans le fichier src/main.rs de votre projet functions par l’exemple précédent et exécutez-le avec cargo run : console {{#include ../listings/ch03-common-programming-concepts/no-listing-18-functions-with-multiple-parameters/output.txt}}
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/functions`
The measurement is: 5h
Comme nous avons appelé la fonction avec 5 comme valeur pour value et 'h' comme valeur pour unit_label, la sortie du programme contient ces valeurs.
Les instructions et les expressions
Les corps de fonctions sont constitués d’une série d’instructions se terminant éventuellement par une expression. Jusqu’à présent, les fonctions que nous avons couvertes n’incluaient pas d’expression finale, mais vous avez vu une expression en tant que partie d’une instruction. Comme Rust est un langage basé sur les expressions, c’est une distinction importante à comprendre. Les autres langages ne font pas les mêmes distinctions, alors examinons ce que sont les instructions et les expressions et comment leurs différences affectent le corps des fonctions.
- Les instructions (statements) sont des directives qui effectuent une action et ne retournent pas de valeur.
- Les expressions s’évaluent pour produire une valeur résultante.
Examinons quelques exemples.
Nous avons en fait déjà utilisé des instructions et des expressions. Créer une variable et lui assigner une valeur avec le mot-clé let est une instruction. Dans le listing 3-1, let y = 6; est une instruction.
fn main() {
let y = 6;
}main function declaration containing one statementLes définitions de fonctions sont également des instructions ; l’exemple précédent dans son intégralité est une instruction en soi. (Comme nous le verrons bientôt, appeler une fonction n’est cependant pas une instruction.)
Les instructions ne retournent pas de valeurs. Par conséquent, vous ne pouvez pas assigner une instruction let à une autre variable, comme le code suivant tente de le faire ; vous obtiendrez une erreur :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let x = (let y = 6);
}Lorsque vous exécutez ce programme, l’erreur que vous obtiendrez ressemble à ceci : console {{#include ../listings/ch03-common-programming-concepts/no-listing-19-statements-vs-expressions/output.txt}}
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error: expected expression, found `let` statement
--> src/main.rs:2:14
|
2 | let x = (let y = 6);
| ^^^
|
= note: only supported directly in conditions of `if` and `while` expressions
warning: unnecessary parentheses around assigned value
--> src/main.rs:2:13
|
2 | let x = (let y = 6);
| ^ ^
|
= note: `#[warn(unused_parens)]` on by default
help: remove these parentheses
|
2 - let x = (let y = 6);
2 + let x = let y = 6;
|
warning: `functions` (bin "functions") generated 1 warning
error: could not compile `functions` (bin "functions") due to 1 previous error; 1 warning emitted
L’instruction let y = 6 ne retourné pas de valeur, il n’y a donc rien à quoi lier x. Ceci est différent de ce qui se passe dans d’autres langages, comme C et Ruby, où l’affectation retourné la valeur de l’affectation. Dans ces langages, vous pouvez écrire x = y = 6 et avoir à la fois x et y avec la valeur 6 ; ce n’est pas le cas en Rust.
Les expressions s’évaluent pour produire une valeur et constituent la majeure partie du code que vous écrirez en Rust. Considérez une opération mathématique, comme 5 + 6, qui est une expression qui s’évalue à la valeur 11. Les expressions peuvent faire partie d’instructions : dans le listing 3-1, le 6 dans l’instruction let y = 6; est une expression qui s’évalue à la valeur 6. Appeler une fonction est une expression. Appeler une macro est une expression. Un nouveau bloc de portée créé avec des accolades est une expression, par exemple :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let y = {
let x = 3;
x + 1
};
println!("The value of y is: {y}");
}Cette expression :
{
let x = 3;
x + 1
}est un bloc qui, dans ce cas, s’évalue à 4. Cette valeur est liée à y dans le cadre de l’instruction let. Notez la ligne x + 1 sans point-virgule à la fin, ce qui est différent de la plupart des lignes que vous avez vues jusqu’ici. Les expressions n’incluent pas de point-virgule final. Si vous ajoutez un point-virgule à la fin d’une expression, vous la transformez en instruction, et elle ne retournera alors pas de valeur. Gardez cela à l’esprit lorsque vous explorerez les valeurs de retour des fonctions et les expressions dans la suite.
Les fonctions avec valeurs de retour
Les fonctions peuvent retourner des valeurs au code qui les appelle. Nous ne nommons pas les valeurs de retour, mais nous devons déclarer leur type après une flèche (->). En Rust, la valeur de retour de la fonction est synonyme de la valeur de la dernière expression dans le bloc du corps d’une fonction. Vous pouvez retourner prématurément d’une fonction en utilisant le mot-clé return et en spécifiant une valeur, mais la plupart des fonctions retournent implicitement la dernière expression. Voici un exemple de fonction qui retourné une valeur :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn five() -> i32 {
5
}
fn main() {
let x = five();
println!("The value of x is: {x}");
}Il n’y a pas d’appels de fonctions, de macros, ni même d’instructions let dans la fonction five – juste le nombre 5 tout seul. C’est une fonction parfaitement valide en Rust. Notez que le type de retour de la fonction est également spécifié, sous la forme -> i32. Essayez d’exécuter ce code ; la sortie devrait ressembler à ceci : console {{#include ../listings/ch03-common-programming-concepts/no-listing-21-function-return-values/output.txt}}
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/functions`
The value of x is: 5
Le 5 dans five est la valeur de retour de la fonction, c’est pourquoi le type de retour est i32. Examinons cela plus en détail. Il y a deux points importants : premièrement, la ligne let x = five(); montre que nous utilisons la valeur de retour d’une fonction pour initialiser une variable. Comme la fonction five retourné un 5, cette ligne est équivalente à la suivante :
#![allow(unused)]
fn main() {
let x = 5;
}Deuxièmement, la fonction five n’a pas de paramètres et définit le type de la valeur de retour, mais le corps de la fonction est un simple 5 sans point-virgule car c’est une expression dont nous voulons retourner la valeur.
Examinons un autre exemple :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let x = plus_one(5);
println!("The value of x is: {x}");
}
fn plus_one(x: i32) -> i32 {
x + 1
}L’exécution de ce code affichera The value of x is: 6. Mais que se passe-t-il si nous plaçons un point-virgule à la fin de la ligne contenant x + 1, la transformant d’une expression en instruction ?
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let x = plus_one(5);
println!("The value of x is: {x}");
}
fn plus_one(x: i32) -> i32 {
x + 1;
}La compilation de ce code produira une erreur, comme suit : console {{#include ../listings/ch03-common-programming-concepts/no-listing-23-statements-dont-return-values/output.txt}}
$ cargo run
Compiling functions v0.1.0 (file:///projects/functions)
error[E0308]: mismatched types
--> src/main.rs:7:24
|
7 | fn plus_one(x: i32) -> i32 {
| -------- ^^^ expected `i32`, found `()`
| |
| implicitly returns `()` as its body has no tail or `return` expression
8 | x + 1;
| - help: remove this semicolon to return this value
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions` (bin "functions") due to 1 previous error
Le message d’erreur principal, mismatched types, révèle le problème fondamental de ce code. La définition de la fonction plus_one indique qu’elle retournera un i32, mais les instructions ne s’évaluent pas en une valeur, ce qui est exprimé par (), le type unitaire. Par conséquent, rien n’est retourné, ce qui contredit la définition de la fonction et provoque une erreur. Dans cette sortie, Rust fournit un message pour aider à corriger ce problème : il suggère de supprimer le point-virgule, ce qui corrigerait l’erreur.
Les commentaires
Les commentaires
Tous les programmeurs s’efforcent de rendre leur code facile à comprendre, mais parfois des explications supplémentaires sont nécessaires. Dans ces cas, les programmeurs laissent des commentaires dans leur code source que le compilateur ignorera mais que les personnes lisant le code source pourront trouver utiles.
Voici un commentaire simple :
#![allow(unused)]
fn main() {
// hello, world
}En Rust, le style de commentaire idiomatique commence un commentaire avec deux barres obliques, et le commentaire continue jusqu’à la fin de la ligne. Pour les commentaires qui s’étendent au-delà d’une seule ligne, vous devrez inclure // sur chaque ligne, comme ceci :
#![allow(unused)]
fn main() {
// So we're doing something complicated here, long enough that we need
// multiple lines of comments to do it! Whew! Hopefully, this comment will
// explain what's going on.
}Les commentaires peuvent également être placés à la fin des lignes contenant du code :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let lucky_number = 7; // I'm feeling lucky today
}Mais vous les verrez plus souvent utilisés dans ce format, avec le commentaire sur une ligne séparée au-dessus du code qu’il annote :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
// I'm feeling lucky today
let lucky_number = 7;
}section of Chapter 14. –> Rust possède également un autre type de commentaire, les commentaires de documentation, que nous aborderons dans la section [“Publishing a Crate to Crates.io”][publishing] du chapitre 14.
Les structures de contrôle
Les structures de contrôle
La capacité d’exécuter du code selon qu’une condition est true et la capacité d’exécuter du code de manière répétée tant qu’une condition est true sont des éléments fondamentaux dans la plupart des langages de programmation. Les constructions les plus courantes qui vous permettent de contrôler le flux d’exécution du code Rust sont les expressions if et les boucles.
Les expressions if
Une expression if vous permet de créer des embranchements dans votre code en fonction de conditions. Vous fournissez une condition puis déclarez : “Si cette condition est remplie, exécute ce bloc de code. Si la condition n’est pas remplie, n’exécute pas ce bloc de code.”
Créez un nouveau projet appelé branches dans votre répertoire projects pour explorer l’expression if. Dans le fichier src/main.rs, saisissez ce qui suit :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let number = 3;
if number < 5 {
println!("condition was true");
} else {
println!("condition was false");
}
}Toutes les expressions if commencent par le mot-clé if, suivi d’une condition. Dans ce cas, la condition vérifie si la variable number à une valeur inférieure à 5. Nous plaçons le bloc de code à exécuter si la condition est true immédiatement après la condition, entre accolades. Les blocs de code associés aux conditions dans les expressions if sont parfois appelés des branches (arms), tout comme les branches dans les expressions match que nous avons abordées dans la section [“Comparing the Guess to the Secret Number”][comparing-the-guess-to-the-secret-number] du chapitre 2.
Optionnellement, nous pouvons également inclure une expression else, ce que nous avons choisi de faire ici, pour donner au programme un bloc de code alternatif à exécuter si la condition s’évalue à false. Si vous ne fournissez pas d’expression else et que la condition est false, le programme passera simplement le bloc if et continuera avec le code suivant.
Essayez d’exécuter ce code ; vous devriez voir la sortie suivante : console {{#include ../listings/ch03-common-programming-concepts/no-listing-26-if-true/output.txt}}
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was true
Essayons de changer la valeur de number pour une valeur qui rend la condition false afin de voir ce qui se passe : rust,ignore {{#rustdoc_include ../listings/ch03-common-programming-concepts/no-listing-27-if-false/src/main.rs:here}}
fn main() {
let number = 7;
if number < 5 {
println!("condition was true");
} else {
println!("condition was false");
}
}Exécutez le programme à nouveau et observez la sortie : console {{#include ../listings/ch03-common-programming-concepts/no-listing-27-if-false/output.txt}}
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
condition was false
Il est également important de noter que la condition dans ce code doit être un bool. Si la condition n’est pas un bool, nous obtiendrons une erreur. Par exemple, essayez d’exécuter le code suivant :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let number = 3;
if number {
println!("number was three");
}
}La condition if s’évalue à une valeur de 3 cette fois, et Rust génère une erreur : console {{#include ../listings/ch03-common-programming-concepts/no-listing-28-if-condition-must-be-bool/output.txt}}
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: mismatched types
--> src/main.rs:4:8
|
4 | if number {
| ^^^^^^ expected `bool`, found integer
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
L’erreur indique que Rust attendait un bool mais a reçu un entier. Contrairement à des langages comme Ruby et JavaScript, Rust ne tentera pas automatiquement de convertir des types non-booléens en booléen. Vous devez être explicite et toujours fournir un booléen comme condition au if. Si nous voulons que le bloc de code if ne s’exécute que lorsqu’un nombre n’est pas égal à 0, par exemple, nous pouvons modifier l’expression if comme suit :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let number = 3;
if number != 0 {
println!("number was something other than zero");
}
}L’exécution de ce code affichera number was something other than zero.
Gérer plusieurs conditions avec else if
Vous pouvez utiliser plusieurs conditions en combinant if et else dans une expression else if. Par exemple :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let number = 6;
if number % 4 == 0 {
println!("number is divisible by 4");
} else if number % 3 == 0 {
println!("number is divisible by 3");
} else if number % 2 == 0 {
println!("number is divisible by 2");
} else {
println!("number is not divisible by 4, 3, or 2");
}
}Ce programme a quatre chemins possibles qu’il peut emprunter. Après l’avoir exécuté, vous devriez voir la sortie suivante : console {{#include ../listings/ch03-common-programming-concepts/no-listing-30-else-if/output.txt}}
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.31s
Running `target/debug/branches`
number is divisible by 3
Lorsque ce programme s’exécute, il vérifie chaque expression if tour à tour et exécute le premier corps pour lequel la condition s’évalue à true. Notez que même si 6 est divisible par 2, nous ne voyons pas la sortie number is divisible by 2, ni le texte number is not divisible by 4, 3, or 2 du bloc else. C’est parce que Rust n’exécute que le bloc de la première condition true, et une fois qu’il en a trouvé une, il ne vérifie même pas les suivantes.
Utiliser trop d’expressions else if peut encombrer votre code, donc si vous en avez plus d’une, vous voudrez peut-être restructurer votre code. Le chapitre 6 décrit une construction de branchement puissante de Rust appelée match pour ces cas-là.
Utiliser if dans une instruction let
Comme if est une expression, nous pouvons l’utiliser du côté droit d’une instruction let pour assigner le résultat à une variable, comme dans le listing 3-2.
fn main() {
let condition = true;
let number = if condition { 5 } else { 6 };
println!("The value of number is: {number}");
}if expression to a variableLa variable number sera liée à une valeur en fonction du résultat de l’expression if. Exécutez ce code pour voir ce qui se passe : console {{#include ../listings/ch03-common-programming-concepts/listing-03-02/output.txt}}
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.30s
Running `target/debug/branches`
The value of number is: 5
Rappelez-vous que les blocs de code s’évaluent à la dernière expression qu’ils contiennent, et que les nombres seuls sont aussi des expressions. Dans ce cas, la valeur de l’expression if entière dépend du bloc de code qui s’exécute. Cela signifie que les valeurs qui peuvent potentiellement être les résultats de chaque branche du if doivent être du même type ; dans le listing 3-2, les résultats de la branche if et de la branche else étaient tous deux des entiers i32. Si les types ne correspondent pas, comme dans l’exemple suivant, nous obtiendrons une erreur :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let condition = true;
let number = if condition { 5 } else { "six" };
println!("The value of number is: {number}");
}Lorsque nous essayons de compiler ce code, nous obtenons une erreur. Les branches if et else ont des types de valeurs incompatibles, et Rust indique exactement où trouver le problème dans le programme : console {{#include ../listings/ch03-common-programming-concepts/no-listing-31-arms-must-return-same-type/output.txt}}
$ cargo run
Compiling branches v0.1.0 (file:///projects/branches)
error[E0308]: `if` and `else` have incompatible types
--> src/main.rs:4:44
|
4 | let number = if condition { 5 } else { "six" };
| - ^^^^^ expected integer, found `&str`
| |
| expected because of this
For more information about this error, try `rustc --explain E0308`.
error: could not compile `branches` (bin "branches") due to 1 previous error
L’expression dans le bloc if s’évalue en un entier, et l’expression dans le bloc else s’évalue en une chaîne de caractères. Cela ne fonctionnera pas, car les variables doivent avoir un seul type, et Rust doit savoir de manière définitive au moment de la compilation quel est le type de la variable number. Connaître le type de number permet au compilateur de vérifier que le type est valide partout où nous utilisons number. Rust ne pourrait pas faire cela si le type de number n’était déterminé qu’à l’exécution ; le compilateur serait plus complexe et offrirait moins de garanties sur le code s’il devait suivre plusieurs types hypothétiques pour chaque variable.
La répétition avec les boucles
Il est souvent utile d’exécuter un bloc de code plus d’une fois. Pour cette tâche, Rust fournit plusieurs boucles, qui exécuteront le code à l’intérieur du corps de la boucle jusqu’à la fin, puis recommenceront immédiatement au début. Pour expérimenter avec les boucles, créons un nouveau projet appelé loops.
Rust dispose de trois types de boucles : loop, while et for. Essayons chacune d’entre elles.
Répéter du code avec loop
Le mot-clé loop indique à Rust d’exécuter un bloc de code encore et encore, soit indéfiniment, soit jusqu’à ce que vous lui disiez explicitement de s’arrêter.
À titre d’exemple, modifiez le fichier src/main.rs dans votre répertoire loops pour qu’il ressemble à ceci :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
loop {
println!("again!");
}
}Lorsque nous exécutons ce programme, nous verrons again! s’afficher en continu jusqu’à ce que nous arrêtions le programme manuellement. La plupart des terminaux prennent en charge le raccourci clavier ctrl-C pour interrompre un programme bloqué dans une boucle continue. Essayez :
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.08s
Running `target/debug/loops`
again!
again!
again!
again!
^Cagain!
Le symbole ^C représente l’endroit où vous avez appuyé sur ctrl-C.
Vous verrez peut-être ou non le mot again! affiché après le ^C, selon l’endroit où le code se trouvait dans la boucle lorsqu’il a reçu le signal d’interruption.
Heureusement, Rust fournit également un moyen de sortir d’une boucle par le code. Vous pouvez placer le mot-clé break à l’intérieur de la boucle pour indiquer au programme quand arrêter l’exécution de la boucle. Rappelez-vous que nous avons fait cela dans le jeu de devinettes dans la section [“Quitting After a Correct Guess”][quitting-after-a-correct-guess] du chapitre 2 pour quitter le programme lorsque l’utilisateur gagnait le jeu en devinant le bon nombre.
Nous avons également utilisé continue dans le jeu de devinettes, qui dans une boucle indique au programme de passer tout le code restant dans cette itération de la boucle et de passer à l’itération suivante.
Retourner des valeurs depuis les boucles
L’une des utilisations d’une boucle loop est de réessayer une opération dont vous savez qu’elle pourrait échouer, comme vérifier si un thread a terminé son travail. Vous pourriez également avoir besoin de transmettre le résultat de cette opération hors de la boucle au reste de votre code. Pour ce faire, vous pouvez ajouter la valeur que vous souhaitez retourner après l’expression break que vous utilisez pour arrêter la boucle ; cette valeur sera retournée hors de la boucle afin que vous puissiez l’utiliser, comme montré ici : rust {{#rustdoc_include ../listings/ch03-common-programming-concepts/no-listing-33-return-value-from-loop/src/main.rs}}
fn main() {
let mut counter = 0;
let result = loop {
counter += 1;
if counter == 10 {
break counter * 2;
}
};
println!("The result is {result}");
}Avant la boucle, nous déclarons une variable nommée counter et l’initialisons à 0. Puis, nous déclarons une variable nommée result pour contenir la valeur retournée par la boucle. À chaque itération de la boucle, nous ajoutons 1 à la variable counter, puis vérifions si counter est égal à 10. Quand c’est le cas, nous utilisons le mot-clé break avec la valeur counter * 2. Après la boucle, nous utilisons un point-virgule pour terminer l’instruction qui assigne la valeur à result. Enfin, nous affichons la valeur dans result, qui dans ce cas est 20.
Vous pouvez également utiliser return depuis l’intérieur d’une boucle. Alors que break ne quitte que la boucle en cours, return quitte toujours la fonction en cours.
Lever l’ambiguïté avec les étiquettes de boucle
Si vous avez des boucles à l’intérieur de boucles, break et continue s’appliquent à la boucle la plus interne à ce moment-là. Vous pouvez optionnellement spécifier une étiquette de boucle (loop label) sur une boucle que vous pouvez ensuite utiliser avec break ou continue pour spécifier que ces mots-clés s’appliquent à la boucle étiquetée plutôt qu’à la boucle la plus interne. Les étiquettes de boucle doivent commencer par une apostrophe. Voici un exemple avec deux boucles imbriquées : rust {{#rustdoc_include ../listings/ch03-common-programming-concepts/no-listing-32-5-loop-labels/src/main.rs}}
fn main() {
let mut count = 0;
'counting_up: loop {
println!("count = {count}");
let mut remaining = 10;
loop {
println!("remaining = {remaining}");
if remaining == 9 {
break;
}
if count == 2 {
break 'counting_up;
}
remaining -= 1;
}
count += 1;
}
println!("End count = {count}");
}La boucle extérieure à l’étiquette 'counting_up, et elle comptera de 0 à 2. La boucle intérieure sans étiquette compte à rebours de 10 à 9. Le premier break qui ne spécifie pas d’étiquette ne quittera que la boucle intérieure. L’instruction break 'counting_up; quittera la boucle extérieure. Ce code affiche : console {{#rustdoc_include ../listings/ch03-common-programming-concepts/no-listing-32-5-loop-labels/output.txt}}
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.58s
Running `target/debug/loops`
count = 0
remaining = 10
remaining = 9
count = 1
remaining = 10
remaining = 9
count = 2
remaining = 10
End count = 2
Simplifier les boucles conditionnelles avec while
Un programme aura souvent besoin d’évaluer une condition à l’intérieur d’une boucle. Tant que la condition est true, la boucle s’exécute. Lorsque la condition cesse d’être true, le programme appelle break, arrêtant la boucle. Il est possible d’implémenter ce comportement en utilisant une combinaison de loop, if, else et break ; vous pourriez essayer cela maintenant dans un programme, si vous le souhaitez. Cependant, ce patron est si courant que Rust dispose d’une construction de langage intégrée pour cela, appelée boucle while. Dans le listing 3-3, nous utilisons while pour boucler le programme trois fois, en comptant à rebours à chaque fois, puis, après la boucle, pour afficher un message et quitter.
fn main() {
let mut number = 3;
while number != 0 {
println!("{number}!");
number -= 1;
}
println!("LIFTOFF!!!");
}while loop to run code while a condition evaluates to trueCette construction élimine beaucoup d’imbrication qui serait nécessaire si vous utilisiez loop, if, else et break, et elle est plus claire. Tant qu’une condition s’évalue à true, le code s’exécute ; sinon, il quitte la boucle.
Parcourir une collection avec for
Vous pouvez choisir d’utiliser la construction while pour parcourir les éléments d’une collection, comme un tableau. Par exemple, la boucle dans le listing 3-4 affiche chaque élément du tableau a.
fn main() {
let a = [10, 20, 30, 40, 50];
let mut index = 0;
while index < 5 {
println!("the value is: {}", a[index]);
index += 1;
}
}while loopIci, le code parcourt les éléments du tableau en incrémentant. Il commence à l’indice 0 puis boucle jusqu’à atteindre le dernier indice du tableau (c’est- à-dire quand index < 5 n’est plus true). L’exécution de ce code affichera chaque élément du tableau : console {{#include ../listings/ch03-common-programming-concepts/listing-03-04/output.txt}}
$ cargo run
Compiling loops v0.1.0 (file:///projects/loops)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.32s
Running `target/debug/loops`
the value is: 10
the value is: 20
the value is: 30
the value is: 40
the value is: 50
Les cinq valeurs du tableau apparaissent dans le terminal, comme prévu. Même si index atteindra la valeur 5 à un moment donné, la boucle s’arrête de s’exécuter avant d’essayer de récupérer une sixième valeur du tableau.
Cependant, cette approche est sujette aux erreurs ; nous pourrions provoquer un panic du programme si la valeur de l’indice ou la condition de test est incorrecte. Par exemple, si vous changiez la définition du tableau a pour avoir quatre éléments mais oubliiez de mettre à jour la condition en while index < 4, le code provoquerait un panic. C’est également lent, car le compilateur ajouté du code à l’exécution pour vérifier si l’indice est dans les limites du tableau à chaque itération de la boucle.
Comme alternative plus concise, vous pouvez utiliser une boucle for et exécuter du code pour chaque élément d’une collection. Une boucle for ressemble au code du listing 3-5.
fn main() {
let a = [10, 20, 30, 40, 50];
for element in a {
println!("the value is: {element}");
}
}for loopLorsque nous exécutons ce code, nous verrons la même sortie que dans le listing 3-4. Plus important encore, nous avons maintenant augmenté la sécurité du code et éliminé le risque de bugs qui pourraient résulter d’un dépassement de la fin du tableau ou d’un parcours insuffisant manquant certains éléments. Le code machine généré par les boucles for peut également être plus efficace car l’indice n’a pas besoin d’être comparé à la longueur du tableau à chaque itération.
En utilisant la boucle for, vous n’auriez pas besoin de vous souvenir de modifier d’autre code si vous changiez le nombre de valeurs dans le tableau, comme ce serait le cas avec la méthode utilisée dans le listing 3-4.
La sécurité et la concision des boucles for en font la construction de boucle la plus couramment utilisée en Rust. Même dans les situations où vous voulez exécuter du code un certain nombre de fois, comme dans l’exemple du compte à rebours qui utilisait une boucle while dans le listing 3-3, la plupart des Rustaceans utiliseraient une boucle for. La façon de le faire serait d’utiliser un Range, fourni par la bibliothèque standard, qui génère tous les nombres en séquence en commençant par un nombre et en s’arrêtant avant un autre nombre.
Voici à quoi ressemblerait le compte à rebours en utilisant une boucle for et une autre méthode dont nous n’avons pas encore parlé, rev, pour inverser l’intervalle :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
for number in (1..4).rev() {
println!("{number}!");
}
println!("LIFTOFF!!!");
}Ce code est un peu plus élégant, n’est-ce pas ?
Résumé
Vous y êtes arrivé ! C’était un chapitre conséquent : vous avez appris les variables, les types de données scalaires et composés, les fonctions, les commentaires, les expressions if et les boucles ! Pour vous entraîner avec les concepts abordés dans ce chapitre, essayez de construire des programmes pour faire ce qui suit :
- Convertir des températures entre Fahrenheit et Celsius.
- Générer le n-ième nombre de Fibonacci.
- Afficher les paroles du chant de Noël “The Twelve Days of Christmas”, en tirant parti de la répétition dans la chanson.
Quand vous serez prêt à continuer, nous parlerons d’un concept en Rust qui n’existe pas couramment dans les autres langages de programmation : l’ownership (la possession).
Comprendre l’ownership
La possession (ownership) est la fonctionnalité la plus distinctive de Rust et à des implications profondes sur le reste du langage. Elle permet a Rust de garantir la securite de la mémoire sans avoir besoin d’un ramasse-miettes (garbage collector), il est donc important de comprendre comment fonctionne la possession. Dans ce chapitre, nous parlerons de la possession ainsi que de plusieurs fonctionnalités associees : l’emprunt (borrowing), les slices, et la façon dont Rust organise les données en mémoire.
Qu’est-ce que l’ownership ?
Qu’est-ce que la possession ?
La possession (ownership) est un ensemble de règles qui regissent la façon dont un programme Rust gère la mémoire. Tous les programmes doivent gérer la façon dont ils utilisent la mémoire d’un ordinateur pendant leur exécution. Certains langages disposent d’un ramasse-miettes (garbage collector) qui recherche regulierement la mémoire inutilisee pendant l’exécution du programme ; dans d’autres langages, le programmeur doit explicitement allouer et libérer la mémoire. Rust utilise une troisième approche : la mémoire est gérée par un système de possession avec un ensemble de règles que le compilateur vérifie. Si l’une des règles est violee, le programme ne compilera pas. Aucune des fonctionnalités de la possession ne ralentira votre programme pendant son exécution.
Comme la possession est un concept nouveau pour de nombreux programmeurs, il faut un certain temps pour s’y habituer. La bonne nouvelle, c’est que plus vous acquerrez de l’experience avec Rust et les règles du système de possession, plus vous trouverez facile de développer naturellement du code sur et efficace. Perseverez !
Lorsque vous comprendrez la possession, vous disposerez d’une base solide pour comprendre les fonctionnalités qui rendent Rust unique. Dans ce chapitre, vous apprendrez la possession en travaillant sur des exemples qui se concentrent sur une structure de données très courante : les chaînes de caractères (strings).
La pile et le tas
De nombreux langages de programmation ne vous demandent pas de penser souvent à la pile (stack) et au tas (heap). Mais dans un langage de programmation système comme Rust, le fait qu’une valeur soit sur la pile ou sur le tas affecte le comportement du langage et explique pourquoi vous devez prendre certaines décisions. Des aspects de la possession seront décrits en relation avec la pile et le tas plus tard dans ce chapitre, voici donc une brève explication en guise de préparation.
La pile et le tas sont tous deux des parties de la mémoire disponibles pour votre code à l’exécution, mais ils sont structurés de manières différentes. La pile stocké les valeurs dans l’ordre où elle les reçoit et les retire dans l’ordre inverse. C’est ce qu’on appelle dernier entré, premier sorti (LIFO, last in, first out). Pensez à une pile d’assiettes : quand vous en ajoutez, vous les posez sur le dessus, et quand vous avez besoin d’une assiette, vous en prenez une sur le dessus. Ajouter ou retirer des assiettes du milieu ou du bas ne fonctionnerait pas aussi bien ! Ajouter des données s’appelle empiler sur la pile, et en retirer s’appelle dépiler de la pile. Toutes les données stockées sur la pile doivent avoir une taille fixe et connue. Les données de taille inconnue à la compilation ou de taille pouvant changer doivent être stockées sur le tas à la place.
Le tas est moins organisé : quand vous placez des données sur le tas, vous demandez une certaine quantité d’espace. L’allocateur de mémoire trouve un emplacement vide dans le tas qui est assez grand, le marque comme étant utilisé, et renvoie un pointeur, qui est l’adresse de cet emplacement. Ce processus s’appelle allouer sur le tas et est parfois abrégé en simplement allouer (empiler des valeurs sur la pile n’est pas considéré comme une allocation). Comme le pointeur vers le tas à une taille connue et fixe, vous pouvez stocker le pointeur sur la pile, mais quand vous voulez les données réelles, vous devez suivre le pointeur. Imaginez que vous arriviez dans un restaurant. À l’entrée, vous indiquez le nombre de personnes dans votre groupe, et le personnel trouve une table vide qui peut accueillir tout le monde et vous y mène. Si quelqu’un dans votre groupe arrive en retard, il peut demander où vous avez été assis pour vous trouver.
Empiler sur la pile est plus rapide qu’allouer sur le tas car l’allocateur n’a jamais besoin de chercher un endroit pour stocker de nouvelles données ; cet endroit est toujours au sommet de la pile. En comparaison, allouer de l’espace sur le tas demande plus de travail car l’allocateur doit d’abord trouver un espace assez grand pour contenir les données, puis effectuer de la comptabilité pour préparer la prochaine allocation.
Accéder aux données sur le tas est généralement plus lent qu’accéder aux données sur la pile car il faut suivre un pointeur pour y arriver. Les processeurs contemporains sont plus rapides s’ils effectuent moins de sauts en mémoire. Pour continuer l’analogie, imaginez un serveur dans un restaurant qui prend les commandes de plusieurs tables. Il est plus efficace de prendre toutes les commandes à une table avant de passer à la suivante. Prendre une commande à la table A, puis une à la table B, puis revenir à la table A, puis à la table B serait un processus bien plus lent. De la même façon, un processeur peut généralement mieux faire son travail s’il travaille sur des données proches les unes des autres (comme sur la pile) plutôt qu’éloignées (comme cela peut être le cas sur le tas).
Quand votre code appelle une fonction, les valeurs passées à la fonction (y compris, potentiellement, des pointeurs vers des données sur le tas) et les variables locales de la fonction sont empilées sur la pile. Quand la fonction se terminé, ces valeurs sont dépilées.
Garder la trace de quelles parties du code utilisent quelles données sur le tas, minimiser la quantité de données dupliquées sur le tas, et nettoyer les données inutilisées sur le tas pour ne pas manquer d’espace sont tous des problèmes que la possession résout. Une fois que vous comprendrez la possession, vous n’aurez plus besoin de penser souvent à la pile et au tas, mais savoir que le but principal de la possession est de gérer les données du tas peut aider à expliquer pourquoi elle fonctionne ainsi.
Les règles de la possession
Tout d’abord, jetons un coup d’oeil aux règles de la possession. Gardez ces règles à l’esprit pendant que nous travaillons sur les exemples qui les illustrent :
- Chaque valeur en Rust à un proprietaire (owner).
- Il ne peut y avoir qu’un seul propriétaire à la fois.
- Quand le propriétaire sort de la portée, la valeur est supprimee (dropped).
La portée des variables
Maintenant que nous avons depasse la syntaxe de base de Rust, nous n’inclurons pas tout le code fn main() { dans les exemples, donc si vous suivez, assurez- vous de placer les exemples suivants à l’intérieur d’une fonction main manuellement. En consequence, nos exemples seront un peu plus concis, ce qui nous permettra de nous concentrer sur les détails importants plutot que sur le code repetitif.
Comme premier exemple de possession, nous allons examiner la portée de certaines variables. Une portee (scope) est la zone au sein d’un programme dans laquelle un élément est valide. Prenons la variable suivante :
#![allow(unused)]
fn main() {
let s = "hello";
}La variable s fait référence à un littéral de chaîne de caractères, dont la valeur est codee en dur dans le texte de notre programme. La variable est valide à partir du moment où elle est déclarée jusqu’à la fin de la portée courante. Le listing 4-1 montre un programme avec des commentaires indiquant ou la variable s serait valide.
fn main() {
{ // s is not valid here, since it's not yet declared
let s = "hello"; // s is valid from this point forward
// do stuff with s
} // this scope is now over, and s is no longer valid
}En d’autres termes, il y a ici deux moments importants :
- Quand
sentre dans la portée, elle est valide. - Elle reste valide jusqu’à ce qu’elle sorte de la portée.
A ce stade, la relation entre les portées et la validite des variables est similaire a celle des autres langages de programmation. Nous allons maintenant approfondir cette comprehension en introduisant le type String.
Le type String
Pour illustrer les règles de la possession, nous avons besoin d’un type de données plus complexe que ceux que nous avons couverts dans la section [“Les types de données”][data-types] du chapitre 3. Les types couverts precedemment ont une taille connue, peuvent être stockés sur la pile et depiles quand leur portée est terminée, et peuvent être copies rapidement et trivialement pour créer une nouvelle instance indépendante si une autre partie du code a besoin d’utiliser la même valeur dans une portée différente. Mais nous voulons examiner des données stockées sur le tas et explorer comment Rust sait quand nettoyer ces données, et le type String en est un excellent exemple.
Nous nous concentrerons sur les aspects de String qui sont lies à la possession. Ces aspects s’appliquent également a d’autres types de données complexes, qu’ils soient fournis par la bibliothèque standard ou créés par vous. Nous aborderons les aspects de String non lies à la possession au [chapitre 8][ch8].
Nous avons déjà vu les littéraux de chaînes de caractères, ou une valeur de chaîne est codee en dur dans notre programme. Les littéraux de chaînes sont pratiques, mais ils ne conviennent pas à toutes les situations ou nous pourrions vouloir utiliser du texte. L’une des raisons est qu’ils sont immuables. Une autre est que toutes les valeurs de chaînes ne peuvent pas être connues au moment où nous écrivons notre code : par exemple, que faire si nous voulons prendre une saisie utilisateur et la stocker ? C’est pour ces situations que Rust dispose du type String. Ce type gère des données allouées sur le tas et est donc capable de stocker une quantite de texte qui nous est inconnue à la compilation. Vous pouvez créer une String à partir d’un littéral de chaîne en utilisant la fonction from, comme ceci :
#![allow(unused)]
fn main() {
let s = String::from("hello");
}L’opérateur double deux-points :: nous permet d’espacer cette fonction from particuliere sous le type String plutot que d’utiliser un nom comme string_from. Nous discuterons de cette syntaxe plus en détail dans la section [“Les methodes”][methods] du chapitre 5, et quand nous parlerons de l’espacement de noms avec les modules dans [“Les chemins pour faire référence à un élément dans l’arborescence des modules”][paths-module-tree] au chapitre 7.
Ce type de chaîne peut être modifié : rust {{#rustdoc_include ../listings/ch04-understanding-ownership/no-listing-01-can-mutate-string/src/main.rs:here}}
fn main() {
let mut s = String::from("hello");
s.push_str(", world!"); // push_str() appends a literal to a String
println!("{s}"); // this will print `hello, world!`
}Alors, quelle est la différence ici ? Pourquoi String peut-elle être modifiée mais pas les littéraux ? La différence reside dans la façon dont ces deux types gèrent la mémoire.
Mémoire et allocation
Dans le cas d’un littéral de chaîne, nous connaissons le contenu à la compilation, donc le texte est code en dur directement dans l’exécutable final. C’est pourquoi les littéraux de chaînes sont rapides et efficaces. Mais ces proprietes ne viennent que de l’immutabilite du littéral de chaîne. Malheureusement, nous ne pouvons pas placer un bloc de mémoire dans le binaire pour chaque morceau de texte dont la taille est inconnue à la compilation et dont la taille pourrait changer pendant l’exécution du programme.
Avec le type String, pour prendre en charge un morceau de texte modifiable et extensible, nous devons allouer une quantite de mémoire sur le tas, inconnue à la compilation, pour contenir le contenu. Cela signifie :
- La mémoire doit être demandee à l’allocateur de mémoire à l’exécution.
- Nous avons besoin d’un moyen de rendre cette mémoire à l’allocateur quand nous avons terminé avec notre
String.
La première partie est faite par nous : quand nous appelons String::from, son implémentation demande la mémoire dont elle a besoin. C’est a peu près universel dans les langages de programmation.
Cependant, la seconde partie est différente. Dans les langages avec un ramasse-miettes (GC), le GC garde la trace de la mémoire qui n’est plus utilisee et la nettoie, et nous n’avons pas besoin d’y penser. Dans la plupart des langages sans GC, c’est notre responsabilite d’identifier quand la mémoire n’est plus utilisee et d’appeler du code pour la libérer explicitement, tout comme nous l’avons fait pour la demander. Faire cela correctement a historiquement été un problème de programmation difficile. Si nous oublions, nous gaspillons de la mémoire. Si nous le faisons trop tot, nous aurons une variable invalide. Si nous le faisons deux fois, c’est aussi un bug. Nous devons associer exactement un allocate avec exactement un free.
Rust prend un chemin différent : la mémoire est automatiquement rendue une fois que la variable qui la possède sort de la portée. Voici une version de notre exemple de portée du listing 4-1 utilisant une String au lieu d’un littéral de chaîne : rust {{#rustdoc_include ../listings/ch04-understanding-ownership/no-listing-02-string-scope/src/main.rs:here}}
fn main() {
{
let s = String::from("hello"); // s is valid from this point forward
// do stuff with s
} // this scope is now over, and s is no
// longer valid
}Il y à un moment naturel auquel nous pouvons rendre la mémoire dont notre String a besoin à l’allocateur : quand s sort de la portée. Quand une variable sort de la portée, Rust appelle une fonction speciale pour nous. Cette fonction s’appelle drop, et c’est la que l’auteur de String peut placer le code pour rendre la mémoire. Rust appelle drop automatiquement à l’accolade fermante.
Note : En C++, ce patron de desallocation des ressources à la fin de la duree de vie d’un élément est parfois appelé Resource Acquisition Is Initialization (RAII). La fonction
dropen Rust vous sera familiere si vous avez utilise des patrons RAII.
Ce patron à un impact profond sur la façon dont le code Rust est écrit. Cela peut sembler simple pour l’instant, mais le comportement du code peut être inattendu dans des situations plus complexes quand nous voulons que plusieurs variables utilisent les données que nous avons allouées sur le tas. Explorons certaines de ces situations maintenant.
Interaction entre les variables et les données avec le deplacement (Move)
Plusieurs variables peuvent interagir avec les mêmes données de différentes façons en Rust. Le listing 4-2 montre un exemple utilisant un entier.
fn main() {
let x = 5;
let y = x;
}x to yNous pouvons probablement deviner ce que cela fait : “Lier la valeur 5 a x ; puis, faire une copie de la valeur dans x et la lier a y.” Nous avons maintenant deux variables, x et y, et les deux valent 5. C’est en effet ce qui se passe, car les entiers sont des valeurs simples avec une taille connue et fixe, et ces deux valeurs 5 sont empilees sur la pile.
Maintenant, regardons la version avec String : rust {{#rustdoc_include ../listings/ch04-understanding-ownership/no-listing-03-string-move/src/main.rs:here}}
fn main() {
let s1 = String::from("hello");
let s2 = s1;
}Cela semble très similaire, donc nous pourrions supposer que le fonctionnement serait le même : c’est-a-dire que la deuxième ligne ferait une copie de la valeur dans s1 et la lierait a s2. Mais ce n’est pas tout a fait ce qui se passe.
Jetez un oeil à la figure 4-1 pour voir ce qui se passe sous le capot avec String. Une String est composee de trois parties, montrées a gauche : un pointeur vers la mémoire qui contient le contenu de la chaîne, une longueur, et une capacité. Ce groupe de données est stocké sur la pile. A droite se trouve la mémoire sur le tas qui contient le contenu.
 Figure 4-1 : La représentation en mémoire d’une `String` contenant la valeur `"hello"` liee a `s1`
Figure 4-1 : La représentation en mémoire d’une `String` contenant la valeur `"hello"` liee a `s1`
La longueur est la quantite de mémoire, en octets, que le contenu de la String utilise actuellement. La capacité est la quantite totale de mémoire, en octets, que la String a recue de l’allocateur. La différence entre la longueur et la capacité est importante, mais pas dans ce contexte, donc pour l’instant, il est acceptable d’ignorer la capacité.
Quand nous assignons s1 a s2, les données de la String sont copiees, ce qui signifie que nous copions le pointeur, la longueur, et la capacité qui sont sur la pile. Nous ne copions pas les données sur le tas auxquelles le pointeur fait référence. En d’autres termes, la représentation des données en mémoire ressemble à la figure 4-2.
 Figure 4-2 : La représentation en mémoire de la variable `s2` qui à une copie du pointeur, de la longueur et de la capacité de `s1`
Figure 4-2 : La représentation en mémoire de la variable `s2` qui à une copie du pointeur, de la longueur et de la capacité de `s1`
La représentation ne ressemble pas à la figure 4-3, qui est ce a quoi la mémoire ressemblerait si Rust copiait également les données du tas. Si Rust faisait cela, l’opération s2 = s1 pourrait être très couteuse en termes de performances à l’exécution si les données sur le tas étaient volumineuses.
 Figure 4-3 : Une autre possibilité de ce que `s2 = s1` pourrait faire si Rust copiait également les données du tas
Figure 4-3 : Une autre possibilité de ce que `s2 = s1` pourrait faire si Rust copiait également les données du tas
Plus tot, nous avons dit que quand une variable sort de la portée, Rust appelle automatiquement la fonction drop et nettoie la mémoire du tas pour cette variable. Mais la figure 4-2 montre les deux pointeurs de données pointant vers le même emplacement. C’est un problème : quand s2 et s1 sortent de la portée, elles essaieront toutes les deux de libérer la même mémoire. C’est ce qu’on appelle une erreur de double liberation (double free) et c’est l’un des bugs de securite mémoire que nous avons mentionnes precedemment. Libérer la mémoire deux fois peut entrainer une corruption de la mémoire, ce qui peut potentiellement mener à des vulnerabilites de securite.
Pour garantir la securite de la mémoire, après la ligne let s2 = s1;, Rust considère s1 comme n’étant plus valide. Par consequent, Rust n’a pas besoin de libérer quoi que ce soit quand s1 sort de la portée. Regardez ce qui se passe quand vous essayez d’utiliser s1 après que s2 a été créée ; cela ne fonctionnera pas : rust,ignore,does_not_compile {{#rustdoc_include ../listings/ch04-understanding-ownership/no-listing-04-cant-use-after-move/src/main.rs:here}}
fn main() {
let s1 = String::from("hello");
let s2 = s1;
println!("{s1}, world!");
}Vous obtiendrez une erreur comme celle-ci car Rust vous empeche d’utiliser la référence invalidee : console {{#include ../listings/ch04-understanding-ownership/no-listing-04-cant-use-after-move/output.txt}}
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0382]: borrow of moved value: `s1`
--> src/main.rs:5:16
|
2 | let s1 = String::from("hello");
| -- move occurs because `s1` has type `String`, which does not implement the `Copy` trait
3 | let s2 = s1;
| -- value moved here
4 |
5 | println!("{s1}, world!");
| ^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
help: consider cloning the value if the performance cost is acceptable
|
3 | let s2 = s1.clone();
| ++++++++
For more information about this error, try `rustc --explain E0382`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Si vous avez entendu les termes copie superficielle (shallow copy) et copie profonde (deep copy) en travaillant avec d’autres langages, le concept de copier le pointeur, la longueur et la capacité sans copier les données ressemble probablement à une copie superficielle. Mais comme Rust invalide aussi la première variable, au lieu d’être appelée une copie superficielle, c’est connu sous le nom de deplacement (move). Dans cet exemple, nous dirions que s1 a été deplacee dans s2. Donc, ce qui se passe réellement est illustre dans la figure 4-4.
 Figure 4-4 : La représentation en mémoire après que `s1` a été invalidee
Figure 4-4 : La représentation en mémoire après que `s1` a été invalidee
Cela resout notre problème ! Avec seulement s2 valide, quand elle sort de la portée, elle seule liberera la mémoire, et c’est terminé.
De plus, il y à un choix de conception qui est implique par cela : Rust ne créera jamais automatiquement de copies “profondes” de vos données. Par consequent, toute copie automatique peut être considérée comme peu couteuse en termes de performances à l’exécution.
Portée et assignation
L’inverse est également vrai pour la relation entre la portée, la possession et la liberation de la mémoire via la fonction drop. Quand vous assignez une valeur completement nouvelle à une variable existante, Rust appellera drop et liberera immediatement la mémoire de la valeur d’origine. Considérez ce code, par exemple : rust {{#rustdoc_include ../listings/ch04-understanding-ownership/no-listing-04b-replacement-drop/src/main.rs:here}}
fn main() {
let mut s = String::from("hello");
s = String::from("ahoy");
println!("{s}, world!");
}Nous declarons d’abord une variable s et la lions à une String avec la valeur "hello". Ensuite, nous créons immediatement une nouvelle String avec la valeur "ahoy" et l’assignons a s. A ce stade, plus rien ne fait référence à la valeur originale sur le tas. La figure 4-5 illustre les données de la pile et du tas maintenant :
 Figure 4-5 : La représentation en mémoire après que la valeur initiale a été entierement remplacee
Figure 4-5 : La représentation en mémoire après que la valeur initiale a été entierement remplacee
La chaîne originale sort donc immediatement de la portée. Rust exécutera la fonction drop sur celle-ci et sa mémoire sera libérée immediatement. Quand nous affichons la valeur à la fin, ce sera "ahoy, world!".
Interaction entre les variables et les données avec Clone
Si nous voulons vraiment copier en profondeur les données du tas de la String, et pas seulement les données de la pile, nous pouvons utiliser une methode courante appelée clone. Nous aborderons la syntaxe des methodes au chapitre 5, mais comme les methodes sont une fonctionnalité courante dans de nombreux langages de programmation, vous les avez probablement déjà vues.
Voici un exemple de la methode clone en action : rust {{#rustdoc_include ../listings/ch04-understanding-ownership/no-listing-05-clone/src/main.rs:here}}
fn main() {
let s1 = String::from("hello");
let s2 = s1.clone();
println!("s1 = {s1}, s2 = {s2}");
}Cela fonctionne parfaitement et produit explicitement le comportement illustre dans la figure 4-3, ou les données du tas sont effectivement copiees.
Quand vous voyez un appel a clone, vous savez qu’un code arbitraire est exécute et que ce code peut être couteux. C’est un indicateur visuel que quelque chose de différent se passe.
Données uniquement sur la pile : Copy
Il y à une autre subtilite dont nous n’avons pas encore parle. Ce code utilisant des entiers – dont une partie a été montrée dans le listing 4-2 – fonctionne et est valide : rust {{#rustdoc_include ../listings/ch04-understanding-ownership/no-listing-06-copy/src/main.rs:here}}
fn main() {
let x = 5;
let y = x;
println!("x = {x}, y = {y}");
}Mais ce code semble contredire ce que nous venons d’apprendre : nous n’avons pas d’appel a clone, mais x est toujours valide et n’a pas été deplace dans y.
La raison est que les types tels que les entiers qui ont une taille connue à la compilation sont entierement stockés sur la pile, donc les copies des valeurs réelles sont rapides a effectuer. Cela signifie qu’il n’y à aucune raison de vouloir empecher x d’être valide après avoir crée la variable y. En d’autres termes, il n’y a pas de différence entre copie profonde et copie superficielle ici, donc appeler clone ne ferait rien de différent de la copie superficielle habituelle, et nous pouvons l’omettre.
Rust à une annotation speciale appelée le trait Copy que nous pouvons placer sur les types stockés sur la pile, comme le sont les entiers (nous parlerons davantage des traits au [chapitre 10][traits]). Si un type implémenté le trait Copy, les variables qui l’utilisent ne sont pas deplacees, mais sont plutot copiees de maniere triviale, ce qui les rend toujours valides après l’assignation à une autre variable.
Rust ne nous laissera pas annoter un type avec Copy si le type, ou l’une de ses parties, a implémenté le trait Drop. Si le type nécessite qu’un traitement special se produise quand la valeur sort de la portée et que nous ajoutons l’annotation Copy à ce type, nous obtiendrons une erreur de compilation. Pour apprendre comment ajouter l’annotation Copy à votre type pour implémenter le trait, consultez [“Les traits derivables”][derivable-traits] dans l’annexe C.
Alors, quels types implementent le trait Copy ? Vous pouvez consulter la documentation du type en question pour en être sur, mais en règle generale, tout groupe de valeurs scalaires simples peut implémenter Copy, et rien qui nécessite une allocation ou qui constitue une forme de ressource ne peut implémenter Copy. Voici quelques-uns des types qui implementent Copy :
- Tous les types d’entiers, comme
u32. - Le type booleen,
bool, avec les valeurstrueetfalse. - Tous les types a virgule flottante, comme
f64. - Le type caractère,
char. - Les tuples, s’ils ne contiennent que des types qui implementent également
Copy. Par exemple,(i32, i32)implémentéCopy, mais(i32, String)ne l’implémenté pas.
La possession et les fonctions
Le mecanisme de passage d’une valeur à une fonction est similaire a celui de l’assignation d’une valeur à une variable. Passer une variable à une fonction la deplacera ou la copiera, tout comme l’assignation. Le listing 4-3 contient un exemple avec des annotations montrant ou les variables entrent et sortent de la portée.
fn main() {
let s = String::from("hello"); // s comes into scope
takes_ownership(s); // s’s value moves into the function...
// ... and so is no longer valid here
let x = 5; // x comes into scope
makes_copy(x); // Because i32 implements the Copy trait,
// x does NOT move into the function,
// so it's okay to use x afterward.
} // Here, x goes out of scope, then s. However, because s’s value was moved,
// nothing special happens.
fn takes_ownership(some_string: String) { // some_string comes into scope
println!("{some_string}");
} // Here, some_string goes out of scope and `drop` is called. The backing
// memory is freed.
fn makes_copy(some_integer: i32) { // some_integer comes into scope
println!("{some_integer}");
} // Here, some_integer goes out of scope. Nothing special happens.Si nous essayions d’utiliser s après l’appel a takes_ownership, Rust lancerait une erreur de compilation. Ces vérifications statiques nous protegent des erreurs. Essayez d’ajouter du code a main qui utilise s et x pour voir ou vous pouvez les utiliser et ou les règles de la possession vous en empechent.
Les valeurs de retour et la portée
Renvoyer des valeurs peut également transferer la possession. Le listing 4-4 montre un exemple de fonction qui renvoie une valeur, avec des annotations similaires a celles du listing 4-3.
fn main() {
let s1 = gives_ownership(); // gives_ownership moves its return
// value into s1
let s2 = String::from("hello"); // s2 comes into scope
let s3 = takes_and_gives_back(s2); // s2 is moved into
// takes_and_gives_back, which also
// moves its return value into s3
} // Here, s3 goes out of scope and is dropped. s2 was moved, so nothing
// happens. s1 goes out of scope and is dropped.
fn gives_ownership() -> String { // gives_ownership will move its
// return value into the function
// that calls it
let some_string = String::from("yours"); // some_string comes into scope
some_string // some_string is returned and
// moves out to the calling
// function
}
// This function takes a String and returns a String.
fn takes_and_gives_back(a_string: String) -> String {
// a_string comes into
// scope
a_string // a_string is returned and moves out to the calling function
}La possession d’une variable suit le même schema à chaque fois : assigner une valeur à une autre variable la deplace. Quand une variable qui inclut des données sur le tas sort de la portée, la valeur sera nettoyee par drop a moins que la possession des données n’ait été transferee à une autre variable.
Bien que cela fonctionne, prendre la possession puis la rendre avec chaque fonction est un peu fastidieux. Que faire si nous voulons laisser une fonction utiliser une valeur sans en prendre la possession ? C’est assez agacant que tout ce que nous passons doive aussi être renvoye si nous voulons le reutiliser, en plus de toutes les données resultant du corps de la fonction que nous pourrions également vouloir renvoyer.
Rust nous permet de renvoyer plusieurs valeurs en utilisant un tuple, comme le montre le listing 4-5.
fn main() {
let s1 = String::from("hello");
let (s2, len) = calculate_length(s1);
println!("The length of '{s2}' is {len}.");
}
fn calculate_length(s: String) -> (String, usize) {
let length = s.len(); // len() returns the length of a String
(s, length)
}Mais c’est beaucoup trop de ceremonie et de travail pour un concept qui devrait être courant. Heureusement pour nous, Rust dispose d’une fonctionnalité pour utiliser une valeur sans transferer la possession : les références.
Les références et l’emprunt
Les références et l’emprunt
Le problème avec le code utilisant des tuples dans le listing 4-5 est que nous devons renvoyer la String à la fonction appelante afin de pouvoir encore utiliser la String après l’appel a calculate_length, car la String a été deplacee dans calculate_length. A la place, nous pouvons fournir une référence à la valeur String. Une référence est comme un pointeur en ce sens que c’est une adresse que nous pouvons suivre pour accéder aux données stockées à cette adresse ; ces données appartiennent à une autre variable. Contrairement à un pointeur, une référence est garantie de pointer vers une valeur valide d’un type particulier pendant toute la duree de vie de cette référence.
Voici comment vous definiriez et utiliseriez une fonction calculate_length qui prend une référence à un objet comme paramètre au lieu de prendre la possession de la valeur :
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{s1}' is {len}.");
}
fn calculate_length(s: &String) -> usize {
s.len()
}Premierement, remarquez que tout le code avec des tuples dans la déclaration de variable et la valeur de retour de la fonction a disparu. Deuxiemement, notez que nous passons &s1 a calculate_length et, dans sa définition, nous prenons &String plutot que String. Ces esperluettes représentent des références, et elles vous permettent de faire référence à une valeur sans en prendre la possession. La figure 4-6 illustre ce concept.
 Figure 4-6 : Un diagramme de `&String` `s` pointant vers `String` `s1`
Figure 4-6 : Un diagramme de `&String` `s` pointant vers `String` `s1`
Note : L’oppose du referencement avec
&est le dereferencement, qui s’effectue avec l’opérateur de dereferencement,*. Nous verrons quelques utilisations de l’opérateur de dereferencement au chapitre 8 et discuterons des détails du dereferencement au chapitre 15.
Examinons de plus près l’appel de fonction ici : rust {{#rustdoc_include ../listings/ch04-understanding-ownership/no-listing-07-reference/src/main.rs:here}}
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{s1}' is {len}.");
}
fn calculate_length(s: &String) -> usize {
s.len()
}La syntaxe &s1 nous permet de créer une référence qui fait reference à la valeur de s1 mais ne la possède pas. Comme la référence ne la possède pas, la valeur vers laquelle elle pointe ne sera pas supprimee quand la référence cesse d’être utilisee.
De même, la signature de la fonction utilise & pour indiquer que le type du paramètre s est une référence. Ajoutons quelques annotations explicatives : rust {{#rustdoc_include ../listings/ch04-understanding-ownership/no-listing-08-reference-with-annotations/src/main.rs:here}}
fn main() {
let s1 = String::from("hello");
let len = calculate_length(&s1);
println!("The length of '{s1}' is {len}.");
}
fn calculate_length(s: &String) -> usize { // s is a référence to a String
s.len()
} // Here, s goes out of scope. But because s does not have ownership of what
// it refers to, the String is not dropped.La portée dans laquelle la variable s est valide est la même que celle de tout paramètre de fonction, mais la valeur pointee par la référence n’est pas supprimee quand s cesse d’être utilisee, car s n’a pas la possession. Quand les fonctions prennent des références comme paramètres au lieu des valeurs réelles, nous n’aurons pas besoin de renvoyer les valeurs pour rendre la possession, car nous n’avons jamais eu la possession.
Nous appelons l’action de créer une référence l’emprunt (borrowing). Comme dans la vie réelle, si une personne possède quelque chose, vous pouvez le lui emprunter. Quand vous avez terminé, vous devez le rendre. Vous ne le possédez pas.
Alors, que se passe-t-il si nous essayons de modifier quelque chose que nous empruntons ? Essayez le code du listing 4-6. Attention spoiler : ca ne marche pas !
fn main() {
let s = String::from("hello");
change(&s);
}
fn change(some_string: &String) {
some_string.push_str(", world");
}Voici l’erreur : console {{#include ../listings/ch04-understanding-ownership/no-listing-14-dangling-reference/output.txt}}
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0596]: cannot borrow `*some_string` as mutable, as it is behind a `&` reference
--> src/main.rs:8:5
|
8 | some_string.push_str(", world");
| ^^^^^^^^^^^ `some_string` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference
|
7 | fn change(some_string: &mut String) {
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Tout comme les variables sont immuables par défaut, les références le sont aussi. Nous ne sommes pas autorises a modifier quelque chose vers quoi nous avons une référence.
Les références mutables
Nous pouvons corriger le code du listing 4-6 pour nous permettre de modifier une valeur empruntée avec seulement quelques petites modifications qui utilisent, à la place, une reference mutable :
fn main() {
let mut s = String::from("hello");
change(&mut s);
}
fn change(some_string: &mut String) {
some_string.push_str(", world");
}D’abord, nous changeons s pour qu’elle soit mut. Ensuite, nous créons une référence mutable avec &mut s la où nous appelons la fonction change et nous mettons à jour la signature de la fonction pour accepter une référence mutable avec some_string: &mut String. Cela rend très clair que la fonction change va modifier la valeur qu’elle emprunté.
Les références mutables ont une grande restriction : si vous avez une référence mutable vers une valeur, vous ne pouvez avoir aucune autre référence vers cette valeur. Ce code qui tente de créer deux références mutables vers s echouera :
fn main() {
let mut s = String::from("hello");
let r1 = &mut s;
let r2 = &mut s;
println!("{r1}, {r2}");
}Voici l’erreur : console {{#include ../listings/ch04-understanding-ownership/no-listing-14-dangling-reference/output.txt}}
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0499]: cannot borrow `s` as mutable more than once at a time
--> src/main.rs:5:14
|
4 | let r1 = &mut s;
| ------ first mutable borrow occurs here
5 | let r2 = &mut s;
| ^^^^^^ second mutable borrow occurs here
6 |
7 | println!("{r1}, {r2}");
| -- first borrow later used here
For more information about this error, try `rustc --explain E0499`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Cette erreur indique que ce code est invalide car nous ne pouvons pas emprunter s de maniere mutable plus d’une fois à la fois. Le premier emprunt mutable est dans r1 et doit durer jusqu’à son utilisation dans le println!, mais entre la creation de cette référence mutable et son utilisation, nous avons essaye de créer une autre référence mutable dans r2 qui emprunté les mêmes données que r1.
La restriction empechant plusieurs références mutables vers les mêmes données en même temps permet la mutation mais de maniere très contrôlée. C’est quelque chose avec lequel les nouveaux Rustaceans ont du mal car la plupart des langages vous permettent de modifier quand vous le souhaitez. L’avantage de cette restriction est que Rust peut prevenir les courses de données (data races) à la compilation. Une course de donnees est similaire à une condition de course (race condition) et se produit quand ces trois comportements surviennent :
- Deux pointeurs ou plus accèdent aux mêmes données en même temps.
- Au moins un des pointeurs est utilise pour écrire dans les données.
- Aucun mecanisme n’est utilise pour synchroniser l’accès aux données.
Les courses de données causent un comportement indefini et peuvent être difficiles a diagnostiquer et corriger quand vous essayez de les traquer à l’exécution ; Rust empeche ce problème en refusant de compiler du code avec des courses de données !
Comme toujours, nous pouvons utiliser des accolades pour créer une nouvelle portée, ce qui permet d’avoir plusieurs références mutables, simplement pas simultanement : rust {{#rustdoc_include ../listings/ch04-understanding-ownership/no-listing-11-muts-in-separate-scopes/src/main.rs:here}}
fn main() {
let mut s = String::from("hello");
{
let r1 = &mut s;
} // r1 goes out of scope here, so we can make a new référence with no problems.
let r2 = &mut s;
}Rust applique une règle similaire pour combiner des références mutables et immuables. Ce code produit une erreur : rust,ignore,does_not_compile {{#rustdoc_include ../listings/ch04-understanding-ownership/no-listing-12-immutable-and-mutable-not-allowed/src/main.rs:here}}
fn main() {
let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
let r3 = &mut s; // BIG PROBLEM
println!("{r1}, {r2}, and {r3}");
}Voici l’erreur : console {{#include ../listings/ch04-understanding-ownership/no-listing-14-dangling-reference/output.txt}}
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:6:14
|
4 | let r1 = &s; // no problem
| -- immutable borrow occurs here
5 | let r2 = &s; // no problem
6 | let r3 = &mut s; // BIG PROBLEM
| ^^^^^^ mutable borrow occurs here
7 |
8 | println!("{r1}, {r2}, and {r3}");
| -- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Ouf ! Nous ne pouvons pas non plus avoir une référence mutable tant que nous avons une référence immuable vers la même valeur.
Les utilisateurs d’une référence immuable ne s’attendent pas à ce que la valeur change soudainement sous leurs pieds ! Cependant, plusieurs références immuables sont autorisees car personne qui se contente de lire les données n’à la capacité d’affecter la lecture des données par quelqu’un d’autre.
Notez que la portée d’une référence commence la où elle est introduite et continue jusqu’à la derniere utilisation de cette référence. Par exemple, ce code compilera car la derniere utilisation des références immuables se trouve dans le println!, avant que la référence mutable ne soit introduite : rust {{#rustdoc_include ../listings/ch04-understanding-ownership/no-listing-13-reference-scope-ends/src/main.rs:here}}
fn main() {
let mut s = String::from("hello");
let r1 = &s; // no problem
let r2 = &s; // no problem
println!("{r1} and {r2}");
// Variables r1 and r2 will not be used after this point.
let r3 = &mut s; // no problem
println!("{r3}");
}Les portées des références immuables r1 et r2 se terminent après le println! ou elles sont utilisees pour la derniere fois, ce qui est avant que la référence mutable r3 ne soit créée. Ces portées ne se chevauchent pas, donc ce code est autorise : le compilateur peut déterminer que la référence n’est plus utilisee à un moment avant la fin de la portée.
Même si les erreurs d’emprunt peuvent être frustrantes parfois, rappelez-vous que c’est le compilateur Rust qui signale un bug potentiel tot (à la compilation plutot qu’à l’exécution) et vous montre exactement ou se trouve le problème. Ainsi, vous n’avez pas a chercher pourquoi vos données ne sont pas ce que vous pensiez qu’elles étaient.
Les références pendantes (dangling références)
Dans les langages avec des pointeurs, il est facile de créer par erreur un pointeur pendant (dangling pointer) – un pointeur qui fait référence à un emplacement en mémoire qui a pu être donne a quelqu’un d’autre – en liberant de la mémoire tout en conservant un pointeur vers cette mémoire. En Rust, en revanche, le compilateur garantit que les références ne seront jamais des références pendantes : si vous avez une référence vers des données, le compilateur s’assurera que les données ne sortiront pas de la portée avant la référence vers ces données.
Essayons de créer une référence pendante pour voir comment Rust les empeche avec une erreur de compilation :
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String {
let s = String::from("hello");
&s
}Voici l’erreur : console {{#include ../listings/ch04-understanding-ownership/no-listing-14-dangling-reference/output.txt}}
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0106]: missing lifetime specifier
--> src/main.rs:5:16
|
5 | fn dangle() -> &String {
| ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but there is no value for it to be borrowed from
help: consider using the `'static` lifetime, but this is uncommon unless you're returning a borrowed value from a `const` or a `static`
|
5 | fn dangle() -> &'static String {
| +++++++
help: instead, you are more likely to want to return an owned value
|
5 - fn dangle() -> &String {
5 + fn dangle() -> String {
|
For more information about this error, try `rustc --explain E0106`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Ce message d’erreur fait référence à une fonctionnalité que nous n’avons pas encore couverte : les durees de vie (lifetimes). Nous discuterons des durees de vie en détail au chapitre 10. Mais, si vous ignorez les parties sur les durees de vie, le message contient la clé de la raison pour laquelle ce code pose problème :
this function's return type contains a borrowed value, but there is no value
for it to be borrowed from
Examinons de plus près ce qui se passe exactement à chaque étape de notre code dangle :
fn main() {
let reference_to_nothing = dangle();
}
fn dangle() -> &String { // dangle returns a référence to a String
let s = String::from("hello"); // s is a new String
&s // we return a référence to the String, s
} // Here, s goes out of scope and is dropped, so its memory goes away.
// Danger!Comme s est créée à l’intérieur de dangle, quand le code de dangle est terminé, s sera desallouee. Mais nous avons essaye de renvoyer une référence vers elle. Cela signifie que cette référence pointerait vers une String invalide. Ce n’est pas bon ! Rust ne nous laissera pas faire cela.
La solution ici est de renvoyer la String directement : rust {{#rustdoc_include ../listings/ch04-understanding-ownership/no-listing-16-no-dangle/src/main.rs:here}}
fn main() {
let string = no_dangle();
}
fn no_dangle() -> String {
let s = String::from("hello");
s
}Cela fonctionne sans aucun problème. La possession est transferee, et rien n’est desalloue.
Les règles des références
Recapitulons ce que nous avons discute au sujet des références :
- A tout moment, vous pouvez avoir soit une référence mutable soit un nombre quelconque de références immuables.
- Les références doivent toujours être valides.
Ensuite, nous examinerons un type différent de référence : les slices.
Le type slice
Le type slice
Les slices vous permettent de faire référence à une séquence contiguë d’éléments dans une collection, plutôt qu’à la collection entière. Une slice est un type de référence, et donc ne possède pas sa valeur.
Voici un petit problème de programmation : écrivez une fonction qui prend une chaîne de mots séparés par des espaces et renvoie le premier mot qu’elle trouve dans cette chaîne. Si la fonction ne trouve pas d’espace dans la chaîne, la chaîne entière doit être un seul mot, donc la chaîne entière doit être renvoyée.
Note : Pour les besoins de l’introduction des slices, nous supposons uniquement de l’ASCII dans cette section ; une discussion plus approfondie du traitement de l’UTF-8 se trouve dans la section [“Stocker du texte encode en UTF-8 avec les Strings”][strings] du chapitre 8.
Voyons comment nous écririons la signature de cette fonction sans utiliser de slices, pour comprendre le problème que les slices vont résoudre :
fn first_word(s: &String) -> ?La fonction first_word à un paramètre de type &String. Nous n’avons pas besoin de la possession, donc c’est bien. (En Rust idiomatique, les fonctions ne prennent pas la possession de leurs arguments a moins qu’elles n’en aient besoin, et les raisons deviendront claires au fur et a mesure.) Mais que devrions-nous renvoyer ? Nous n’avons pas vraiment de moyen de parler d’une partie d’une chaîne. Cependant, nous pourrions renvoyer l’indice de la fin du mot, indique par un espace. Essayons cela, comme le montre le listing 4-7.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}first_word function that returns a byte index value into the String parameterComme nous devons parcourir la String élément par élément et vérifier si une valeur est un espace, nous convertirons notre String en un tableau d’octets en utilisant la methode as_bytes. rust,ignore {{#rustdoc_include ../listings/ch04-understanding-ownership/listing-04-07/src/main.rs:as_bytes}}
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Ensuite, nous créons un iterateur sur le tableau d’octets en utilisant la methode iter : rust,ignore {{#rustdoc_include ../listings/ch04-understanding-ownership/listing-04-07/src/main.rs:iter}}
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Nous discuterons des itérateurs plus en détail au chapitre 13. Pour l’instant, sachez que iter est une méthode qui renvoie chaque élément d’une collection et que enumerate enveloppe le résultat de iter et renvoie chaque élément sous forme de partie d’un tuple à la place. Le premier élément du tuple renvoyé par enumerate est l’index, et le second élément est une référence à l’élément. C’est un peu plus pratique que de calculer l’index nous-mêmes.
Comme la methode enumerate renvoie un tuple, nous pouvons utiliser des motifs (patterns) pour destructurer ce tuple. Nous discuterons des motifs plus en détail au [chapitre 6][ch6]. Dans la boucle for, nous specif ions un motif qui a i pour l’indice dans le tuple et &item pour l’octet unique dans le tuple. Comme nous obtenons une référence vers l’élément depuis .iter().enumerate(), nous utilisons & dans le motif.
A l’intérieur de la boucle for, nous recherchons l’octet qui représente l’espace en utilisant la syntaxe de littéral d’octet. Si nous trouvons un espace, nous renvoyons la position. Sinon, nous renvoyons la longueur de la chaîne en utilisant s.len(). rust,ignore {{#rustdoc_include ../listings/ch04-understanding-ownership/listing-04-07/src/main.rs:inside_for}}
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {}Nous avons maintenant un moyen de trouver l’indice de la fin du premier mot dans la chaîne, mais il y à un problème. Nous renvoyons un usize seul, mais c’est un nombre qui n’a de sens que dans le contexte de la &String. En d’autres termes, comme c’est une valeur séparée de la String, il n’y à aucune garantie qu’elle sera encore valide à l’avenir. Considérez le programme du listing 4-8 qui utilise la fonction first_word du listing 4-7.
fn first_word(s: &String) -> usize {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return i;
}
}
s.len()
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s); // word will get the value 5
s.clear(); // this empties the String, making it equal to ""
// word still has the value 5 here, but s no longer has any content that we
// could meaningfully use with the value 5, so word is now totally invalid!
}first_word function and then changing the String contentsCe programme compilé sans aucune erreur et le ferait également si nous utilisions word après avoir appelé s.clear(). Comme word n’est pas du tout connecte à l’état de s, word contient toujours la valeur 5. Nous pourrions utiliser cette valeur 5 avec la variable s pour essayer d’extraire le premier mot, mais ce serait un bug car le contenu de s a change depuis que nous avons enregistré 5 dans word.
Devoir s’inquieter de la desynchronisation de l’indice dans word avec les données dans s est fastidieux et source d’erreurs ! La gestion de ces indices est encore plus fragile si nous écrivons une fonction second_word. Sa signature devrait ressembler a ceci :
fn second_word(s: &String) -> (usize, usize) {Maintenant nous suivons un indice de début et un indice de fin, et nous avons encore plus de valeurs qui ont été calculees à partir de données dans un état particulier mais qui ne sont pas du tout liees à cet état. Nous avons trois variables non liees qui flottent et qui doivent être maintenues synchronisees.
Heureusement, Rust à une solution à ce problème : les slices de chaînes de caractères.
Les slices de chaînes de caractères
Une slice de chaine est une référence à une séquence contigue des éléments d’une String, et elle ressemble a ceci : rust {{#rustdoc_include ../listings/ch04-understanding-ownership/no-listing-17-slice/src/main.rs:here}}
fn main() {
let s = String::from("hello world");
let hello = &s[0..5];
let world = &s[6..11];
}Plutot qu’une référence à la String entière, hello est une référence à une portion de la String, spécifiée par la partie supplementaire [0..5]. Nous créons des slices en utilisant un intervalle entre crochets en specifiant [indice_de_debut..indice_de_fin], ou indice_de_debut est la première position dans la slice et indice_de_fin est un de plus que la derniere position dans la slice. En interne, la structure de données de la slice stocké la position de début et la longueur de la slice, qui correspond a indice_de_fin moins indice_de_debut. Ainsi, dans le cas de let world = &s[6..11];, world serait une slice qui contient un pointeur vers l’octet à l’indice 6 de s avec une valeur de longueur de 5.
La figure 4-7 montre cela dans un diagramme.
 Figure 4-7 : Une slice de chaîne faisant référence à une partie d’une `String`
Figure 4-7 : Une slice de chaîne faisant référence à une partie d’une `String`
Avec la syntaxe d’intervalle .. de Rust, si vous voulez commencer à l’indice 0, vous pouvez omettre la valeur avant les deux points. En d’autres termes, ceux-ci sont equivalents :
#![allow(unused)]
fn main() {
let s = String::from("hello");
let slice = &s[0..2];
let slice = &s[..2];
}De la même façon, si votre slice inclut le dernier octet de la String, vous pouvez omettre le nombre final. Cela signifie que ceux-ci sont equivalents :
#![allow(unused)]
fn main() {
let s = String::from("hello");
let len = s.len();
let slice = &s[3..len];
let slice = &s[3..];
}Vous pouvez également omettre les deux valeurs pour prendre une slice de la chaîne entière. Ainsi, ceux-ci sont equivalents :
#![allow(unused)]
fn main() {
let s = String::from("hello");
let len = s.len();
let slice = &s[0..len];
let slice = &s[..];
}Note : Les indices d’intervalle des slices de chaînes doivent se situer à des limites de caractères UTF-8 valides. Si vous tentez de créer une slice de chaîne au milieu d’un caractère multi-octets, votre programme se terminera avec une erreur.
Avec toutes ces informations en tete, réécrivons first_word pour renvoyer une slice. Le type qui designe “slice de chaîne” s’écrit &str :
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {}Nous obtenons l’indice de la fin du mot de la même façon que dans le listing 4-7, en recherchant la première occurrence d’un espace. Quand nous trouvons un espace, nous renvoyons une slice de chaîne en utilisant le début de la chaîne et l’indice de l’espace comme indices de début et de fin.
Maintenant, quand nous appelons first_word, nous recuperons une seule valeur qui est liee aux données sous-jacentes. La valeur est composee d’une référence au point de depart de la slice et du nombre d’éléments dans la slice.
Renvoyer une slice fonctionnerait également pour une fonction second_word :
fn second_word(s: &String) -> &str {Nous avons maintenant une API simple qui est beaucoup plus difficile a mal utiliser car le compilateur s’assurera que les références dans la String restent valides. Rappelez-vous le bug dans le programme du listing 4-8, quand nous avons obtenu l’indice de la fin du premier mot mais avons ensuite vide la chaîne, rendant notre indice invalide ? Ce code était logiquement incorrect mais ne montrait aucune erreur immediate. Les problèmes apparaîtraient plus tard si nous continuions a essayer d’utiliser l’indice du premier mot avec une chaîne videe. Les slices rendent ce bug impossible et nous informent bien plus tot que nous avons un problème avec notre code. Utiliser la version avec slice de first_word produira une erreur de compilation :
fn first_word(s: &String) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let mut s = String::from("hello world");
let word = first_word(&s);
s.clear(); // error!
println!("the first word is: {word}");
}Voici l’erreur du compilateur : console {{#include ../listings/ch04-understanding-ownership/no-listing-19-slice-error/output.txt}}
$ cargo run
Compiling ownership v0.1.0 (file:///projects/ownership)
error[E0502]: cannot borrow `s` as mutable because it is also borrowed as immutable
--> src/main.rs:18:5
|
16 | let word = first_word(&s);
| -- immutable borrow occurs here
17 |
18 | s.clear(); // error!
| ^^^^^^^^^ mutable borrow occurs here
19 |
20 | println!("the first word is: {word}");
| ---- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `ownership` (bin "ownership") due to 1 previous error
Rappelez-vous des règles d’emprunt que si nous avons une référence immuable vers quelque chose, nous ne pouvons pas également prendre une référence mutable. Comme clear a besoin de tronquer la String, elle a besoin d’obtenir une référence mutable. Le println! après l’appel a clear utilise la référence dans word, donc la référence immuable doit encore être activé à ce moment-la. Rust interdit à la référence mutable dans clear et à la référence immuable dans word d’exister en même temps, et la compilation echoue. Non seulement Rust a rendu notre API plus facile à utiliser, mais il a aussi elimine toute une classe d’erreurs à la compilation !
Les littéraux de chaînes comme slices
Rappelez-vous que nous avons parle des littéraux de chaînes stockés à l’intérieur du binaire. Maintenant que nous connaissons les slices, nous pouvons comprendre correctement les littéraux de chaînes :
#![allow(unused)]
fn main() {
let s = "Hello, world!";
}Le type de s ici est &str : c’est une slice pointant vers ce point spécifique du binaire. C’est aussi pourquoi les littéraux de chaînes sont immuables ; &str est une référence immuable.
Les slices de chaînes comme paramètres
Savoir que vous pouvez prendre des slices de littéraux et de valeurs String nous amene à une amélioration supplementaire de first_word, et c’est sa signature :
fn first_word(s: &String) -> &str {Un Rustacean plus experimente écrirait plutot la signature montrée dans le listing 4-9 car elle nous permet d’utiliser la même fonction sur les valeurs &String et les valeurs &str.
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// `first_word` works on slices of `String`s, whether partial or whole.
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` also works on références to `String`s, which are equivalent
// to whole slices of `String`s.
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` works on slices of string literals, whether partial or
// whole.
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}first_word function by using a string slice for the type of the s parameterSi nous avons une slice de chaîne, nous pouvons la passer directement. Si nous avons une String, nous pouvons passer une slice de la String ou une référence à la String. Cette flexibilite tire parti des conversions automatiques de dereferencement (deref coercions), une fonctionnalité que nous couvrirons dans la section [“Utiliser les conversions automatiques de dereferencement dans les fonctions et les methodes”][deref-coercions] du chapitre 15.
Définir une fonction pour prendre une slice de chaîne au lieu d’une référence à une String rend notre API plus generale et utile sans perdre de fonctionnalité :
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// `first_word` works on slices of `String`s, whether partial or whole.
let word = first_word(&my_string[0..6]);
let word = first_word(&my_string[..]);
// `first_word` also works on références to `String`s, which are equivalent
// to whole slices of `String`s.
let word = first_word(&my_string);
let my_string_literal = "hello world";
// `first_word` works on slices of string literals, whether partial or
// whole.
let word = first_word(&my_string_literal[0..6]);
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}Les autres slices
Les slices de chaînes, comme vous pouvez l’imaginer, sont spécifiques aux chaînes. Mais il existe aussi un type de slice plus general. Considérez ce tableau :
#![allow(unused)]
fn main() {
let a = [1, 2, 3, 4, 5];
}Tout comme nous pourrions vouloir faire référence à une partie d’une chaîne, nous pourrions vouloir faire référence à une partie d’un tableau. Nous le ferions comme ceci :
#![allow(unused)]
fn main() {
let a = [1, 2, 3, 4, 5];
let slice = &a[1..3];
assert_eq!(slice, &[2, 3]);
}Cette slice à le type &[i32]. Elle fonctionne de la même maniere que les slices de chaînes, en stockant une référence vers le premier élément et une longueur. Vous utiliserez ce type de slice pour toutes sortes d’autres collections. Nous discuterons de ces collections en détail quand nous parlerons des vecteurs au chapitre 8.
Résumé
Les concepts de possession, d’emprunt et de slices garantissent la securite de la mémoire dans les programmes Rust à la compilation. Le langage Rust vous donne le contrôle sur votre utilisation de la mémoire de la même façon que les autres langages de programmation système. Mais le fait que le propriétaire des données nettoie automatiquement ces données quand le propriétaire sort de la portée signifie que vous n’avez pas a écrire et deboguer du code supplementaire pour obtenir ce contrôle.
La possession affecte le fonctionnement de nombreuses autres parties de Rust, nous continuerons donc a parler de ces concepts tout au long du reste du livre. Passons au chapitre 5 et voyons comment regrouper des données dans une struct.
Utiliser les structs pour structurer des données apparentées
Une struct, ou structure, est un type de données personnalisé qui vous permet de regrouper et de nommer plusieurs valeurs apparentées qui forment un ensemble cohérent. Si vous êtes familier avec un langage orienté objet, une struct ressemble aux attributs de données d’un objet. Dans ce chapitre, nous comparerons les tuples et les structs en nous appuyant sur ce que vous savez déjà et nous montrerons quand les structs sont un meilleur moyen de regrouper des données.
Nous montrerons comment définir et instancier des structs. Nous verrons comment définir des fonctions associées, en particulier le type de fonctions associées appelées méthodes, pour spécifier le comportement associé à un type struct. Les structs et les enums (abordés au chapitre 6) sont les briques de base pour créer de nouveaux types dans le domaine de votre programme afin de tirer pleinement parti de la vérification de types à la compilation de Rust.
Définir et instancier des structs
Définir et instancier des structs
Les structs sont similaires aux tuples, abordés dans la section [« Le type tuple »][tuples], en ce sens que les deux contiennent plusieurs valeurs apparentées. Comme les tuples, les éléments d’une struct peuvent être de types différents. Contrairement aux tuples, dans une struct, vous nommerez chaque élément de données pour que la signification des valeurs soit claire. L’ajout de ces noms signifie que les structs sont plus flexibles que les tuples : vous n’avez pas besoin de vous fier à l’ordre des données pour spécifier ou accéder aux valeurs d’une instance.
Pour définir une struct, nous utilisons le mot-clé struct et nommons l’ensemble de la struct. Le nom d’une struct devrait décrire la signification des éléments de données regroupés. Ensuite, à l’intérieur d’accolades, nous définissons les noms et les types des éléments de données, que nous appelons des champs. Par exemple, le listing 5-1 montre une struct qui stocké des informations sur un compte utilisateur.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {}User struct definitionPour utiliser une struct après l’avoir définie, nous créons une instance de cette struct en spécifiant des valeurs concrètes pour chacun des champs. Nous créons une instance en indiquant le nom de la struct puis en ajoutant des accolades contenant des paires clé: valeur, où les clés sont les noms des champs et les valeurs sont les données que nous voulons stocker dans ces champs. Nous n’avons pas besoin de spécifier les champs dans le même ordre que celui dans lequel nous les avons déclarés dans la struct. Autrement dit, la définition de la struct est comme un modèle général pour le type, et les instances remplissent ce modèle avec des données particulières pour créer des valeurs du type. Par exemple, nous pouvons déclarer un utilisateur particulier comme le montre le listing 5-2.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
let user1 = User {
active: true,
username: String::from("someusername123"),
email: String::from("someone@example.com"),
sign_in_count: 1,
};
}User structPour obtenir une valeur spécifique d’une struct, nous utilisons la notation par point. Par exemple, pour accéder à l’adresse e-mail de cet utilisateur, nous utilisons user1.email. Si l’instance est mutable, nous pouvons modifier une valeur en utilisant la notation par point et en assignant une valeur à un champ particulier. Le listing 5-3 montre comment modifier la valeur du champ email d’une instance mutable de User.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
let mut user1 = User {
active: true,
username: String::from("someusername123"),
email: String::from("someone@example.com"),
sign_in_count: 1,
};
user1.email = String::from("anotheremail@example.com");
}email field of a User instanceNotez que l’instance entière doit être mutable ; Rust ne nous permet pas de marquer seulement certains champs comme mutables. Comme pour toute expression, nous pouvons construire une nouvelle instance de la struct comme dernière expression dans le corps de la fonction pour retourner implicitement cette nouvelle instance.
Le listing 5-4 montre une fonction build_user qui retourné une instance de User avec l’e-mail et le nom d’utilisateur donnés. Le champ active reçoit la valeur true, et sign_in_count reçoit la valeur 1.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn build_user(email: String, username: String) -> User {
User {
active: true,
username: username,
email: email,
sign_in_count: 1,
}
}
fn main() {
let user1 = build_user(
String::from("someone@example.com"),
String::from("someusername123"),
);
}build_user function that takes an email and username and returns a User instanceIl est logique de nommer les paramètres de la fonction avec le même nom que les champs de la struct, mais devoir répéter les noms des champs email et username et les variables est un peu fastidieux. Si la struct avait plus de champs, répéter chaque nom deviendrait encore plus pénible. Heureusement, il existe un raccourci pratique !
Utiliser le raccourci d’initialisation de champ
Comme les noms des paramètres et les noms des champs de la struct sont exactement les mêmes dans le listing 5-4, nous pouvons utiliser la syntaxe du raccourci d’initialisation de champ pour réécrire build_user de manière à ce qu’elle se comporte exactement de la même façon mais sans la répétition de username et email, comme le montre le listing 5-5.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn build_user(email: String, username: String) -> User {
User {
active: true,
username,
email,
sign_in_count: 1,
}
}
fn main() {
let user1 = build_user(
String::from("someone@example.com"),
String::from("someusername123"),
);
}build_user function that uses field init shorthand because the username and email parameters have the same name as struct fieldsIci, nous créons une nouvelle instance de la struct User, qui à un champ nommé email. Nous voulons définir la valeur du champ email à la valeur du paramètre email de la fonction build_user. Comme le champ email et le paramètre email portent le même nom, nous n’avons besoin d’écrire que email plutôt que email: email.
Créer des instances avec la syntaxe de mise à jour de struct
Il est souvent utile de créer une nouvelle instance d’une struct qui inclut la plupart des valeurs d’une autre instance du même type, mais en modifié certaines. Vous pouvez le faire en utilisant la syntaxe de mise à jour de struct.
D’abord, dans le listing 5-6, nous montrons comment créer une nouvelle instance de User dans user2 de manière classique, sans la syntaxe de mise à jour. Nous définissons une nouvelle valeur pour email mais utilisons par ailleurs les mêmes valeurs de user1 que nous avons créé dans le listing 5-2.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
// --snip--
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
let user2 = User {
active: user1.active,
username: user1.username,
email: String::from("another@example.com"),
sign_in_count: user1.sign_in_count,
};
}User instance using all but one of the values from user1En utilisant la syntaxe de mise à jour de struct, nous pouvons obtenir le même effet avec moins de code, comme le montre le listing 5-7. La syntaxe .. spécifie que les champs restants non explicitement définis doivent avoir la même valeur que les champs de l’instance donnée.
struct User {
active: bool,
username: String,
email: String,
sign_in_count: u64,
}
fn main() {
// --snip--
let user1 = User {
email: String::from("someone@example.com"),
username: String::from("someusername123"),
active: true,
sign_in_count: 1,
};
let user2 = User {
email: String::from("another@example.com"),
..user1
};
}email value for a User instance but to use the rest of the values from user1Le code du listing 5-7 crée également une instance dans user2 qui à une valeur différente pour email mais qui conserve les mêmes valeurs pour les champs username, active et sign_in_count de user1. Le ..user1 doit apparaître en dernier pour spécifier que tous les champs restants doivent obtenir leurs valeurs des champs correspondants dans user1, mais nous pouvons choisir de spécifier des valeurs pour autant de champs que nous le souhaitons, dans n’importe quel ordre, indépendamment de l’ordre des champs dans la définition de la struct.
section would apply. We can also still use user1.email in this example, because its value was not moved out of user1. –> Notez que la syntaxe de mise à jour de struct utilise = comme une assignation ; c’est parce qu’elle déplace les données, tout comme nous l’avons vu dans la section [« Les variables et les données interagissant avec le déplacement »][move]. Dans cet exemple, nous ne pouvons plus utiliser user1 après avoir créé user2 parce que la String du champ username de user1 a été déplacée dans user2. Si nous avions donné à user2 de nouvelles valeurs String pour email et username, et donc n’avions utilisé que les valeurs active et sign_in_count de user1, alors user1 serait toujours valide après la création de user2. active et sign_in_count sont tous deux des types qui implémentent le trait Copy, donc le comportement que nous avons abordé dans la section [« Données uniquement sur la pile : Copy »][copy] s’appliquerait. Nous pouvons également toujours utiliser user1.email dans cet exemple, car sa valeur n’a pas été déplacée hors de user1.
Créer des types différents avec les structs tuples
Rust prend également en charge des structs qui ressemblent à des tuples, appelées structs tuples. Les structs tuples ont la signification supplémentaire que le nom de la struct apporte, mais n’ont pas de noms associés à leurs champs ; elles n’ont que les types des champs. Les structs tuples sont utiles lorsque vous voulez donner un nom à l’ensemble du tuple et faire du tuple un type différent des autres tuples, et quand nommer chaque champ comme dans une struct classique serait verbeux ou redondant.
Pour définir une struct tuple, commencez par le mot-clé struct et le nom de la struct, suivis des types dans le tuple. Par exemple, ici nous définissons et utilisons deux structs tuples nommées Color et Point :
struct Color(i32, i32, i32);
struct Point(i32, i32, i32);
fn main() {
let black = Color(0, 0, 0);
let origin = Point(0, 0, 0);
}Notez que les valeurs black et origin sont de types différents car ce sont des instances de structs tuples différentes. Chaque struct que vous définissez est son propre type, même si les champs de la struct peuvent avoir les mêmes types. Par exemple, une fonction qui prend un paramètre de type Color ne peut pas prendre un Point comme argument, même si les deux types sont composés de trois valeurs i32. Par ailleurs, les instances de structs tuples sont similaires aux tuples en ce que vous pouvez les déstructurer en leurs éléments individuels, et vous pouvez utiliser un . suivi de l’index pour accéder à une valeur individuelle. Contrairement aux tuples, les structs tuples exigent que vous nommiez le type de la struct lorsque vous les déstructurez. Par exemple, nous écririons let Point(x, y, z) = origin; pour déstructurer les valeurs du point origin dans des variables nommées x, y et z.
Définir des structs unitaires
Vous pouvez également définir des structs qui n’ont aucun champ ! Celles-ci sont appelées structs unitaires car elles se comportent de manière similaire à (), le type unitaire que nous avons mentionné dans la section [« Le type tuple »][tuples]. Les structs unitaires peuvent être utiles lorsque vous devez implémenter un trait sur un type mais que vous n’avez aucune donnée à stocker dans le type lui-même. Nous aborderons les traits au chapitre 10. Voici un exemple de déclaration et d’instanciation d’une struct unitaire nommée AlwaysEqual :
struct AlwaysEqual;
fn main() {
let subject = AlwaysEqual;
}Pour définir AlwaysEqual, nous utilisons le mot-clé struct, le nom que nous souhaitons, puis un point-virgule. Pas besoin d’accolades ni de parenthèses ! Ensuite, nous pouvons obtenir une instance d’AlwaysEqual dans la variable subject de manière similaire : en utilisant le nom que nous avons défini, sans accolades ni parenthèses. Imaginez que plus tard nous implémenterons un comportement pour ce type de sorte que chaque instance d’AlwaysEqual soit toujours égale à chaque instance de tout autre type, peut-être pour avoir un résultat connu à des fins de test. Nous n’aurions besoin d’aucune donnée pour implémenter ce comportement ! Vous verrez au chapitre 10 comment définir des traits et les implémenter sur n’importe quel type, y compris les structs unitaires.
Possession des données d’une struct
Dans la définition de la struct User du listing 5-1, nous avons utilisé le type possédé String plutôt que le type de slice de chaîne &str. C’est un choix délibéré car nous voulons que chaque instance de cette struct possède toutes ses données et que ces données soient valides aussi longtemps que la struct entière est valide.
Il est également possible pour les structs de stocker des références vers des données possédées par autre chose, mais cela nécessite l’utilisation de durées de vie (lifetimes), une fonctionnalité de Rust que nous aborderons au chapitre 10. Les durées de vie garantissent que les données référencées par une struct sont valides aussi longtemps que la struct l’est. Supposons que vous essayiez de stocker une référence dans une struct sans spécifier de durées de vie, comme dans le code suivant dans src/main.rs ; cela ne fonctionnera pas :
struct User {
active: bool,
username: &str,
email: &str,
sign_in_count: u64,
}
fn main() {
let user1 = User {
active: true,
username: "someusername123",
email: "someone@example.com",
sign_in_count: 1,
};
}Le compilateur se plaindra qu’il a besoin de spécificateurs de durée de vie :
$ cargo run
Compiling structs v0.1.0 (file:///projects/structs)
error[E0106]: missing lifetime specifier
--> src/main.rs:3:15
|
3 | username: &str,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
1 ~ struct User<'a> {
2 | active: bool,
3 ~ username: &'a str,
|
error[E0106]: missing lifetime specifier
--> src/main.rs:4:12
|
4 | email: &str,
| ^ expected named lifetime parameter
|
help: consider introducing a named lifetime parameter
|
1 ~ struct User<'a> {
2 | active: bool,
3 | username: &str,
4 ~ email: &'a str,
|
For more information about this error, try `rustc --explain E0106`.
error: could not compile `structs` (bin "structs") due to 2 previous errors
Au chapitre 10, nous expliquerons comment corriger ces erreurs de manière à pouvoir stocker des références dans des structs, mais pour l’instant, nous corrigerons des erreurs comme celles-ci en utilisant des types possédés comme String au lieu de références comme &str.
Un exemple de programme utilisant les structs
Un exemple de programme utilisant les structs
Pour comprendre quand nous pourrions vouloir utiliser des structs, écrivons un programme qui calcule l’aire d’un rectangle. Nous commencerons par utiliser des variables simples, puis nous refactoriserons le programme jusqu’à utiliser des structs à la place.
Créons un nouveau projet binaire avec Cargo appelé rectangles qui prendra la largeur et la hauteur d’un rectangle spécifiées en pixels et calculera l’aire du rectangle. Le listing 5-8 montre un court programme avec une manière de faire exactement cela dans le fichier src/main.rs de notre projet.
fn main() {
let width1 = 30;
let height1 = 50;
println!(
"The area of the rectangle is {} square pixels.",
area(width1, height1)
);
}
fn area(width: u32, height: u32) -> u32 {
width * height
}Maintenant, exécutez ce programme avec cargo run : console {{#include ../listings/ch05-using-structs-to-structure-related-data/listing-05-08/output.txt}}
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/rectangles`
The area of the rectangle is 1500 square pixels.
Ce code réussit à déterminer l’aire du rectangle en appelant la fonction area avec chaque dimension, mais nous pouvons faire davantage pour rendre ce code clair et lisible.
Le problème avec ce code est évident dans la signature de area : rust,ignore {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/listing-05-08/src/main.rs:here}}
fn main() {
let width1 = 30;
let height1 = 50;
println!(
"The area of the rectangle is {} square pixels.",
area(width1, height1)
);
}
fn area(width: u32, height: u32) -> u32 {
width * height
}La fonction area est censée calculer l’aire d’un seul rectangle, mais la fonction que nous avons écrite a deux paramètres, et rien dans notre programme n’indique clairement que ces paramètres sont liés. Il serait plus lisible et plus facile à gérer de regrouper la largeur et la hauteur. Nous avons déjà abordé une façon de le faire dans la section [« Le type tuple »][the-tuple-type] du chapitre 3 : en utilisant des tuples.
Refactorisation avec des tuples
Le listing 5-9 montre une autre version de notre programme qui utilise des tuples.
fn main() {
let rect1 = (30, 50);
println!(
"The area of the rectangle is {} square pixels.",
area(rect1)
);
}
fn area(dimensions: (u32, u32)) -> u32 {
dimensions.0 * dimensions.1
}D’un côté, ce programme est meilleur. Les tuples nous permettent d’ajouter un peu de structure, et nous ne passons maintenant qu’un seul argument. Mais d’un autre côté, cette version est moins claire : les tuples ne nomment pas leurs éléments, donc nous devons accéder aux parties du tuple par index, ce qui rend notre calcul moins évident.
Confondre la largeur et la hauteur n’aurait pas d’importance pour le calcul de l’aire, mais si nous voulions dessiner le rectangle à l’écran, cela compterait ! Nous devrions garder en tête que width est l’index 0 du tuple et height est l’index 1. Ce serait encore plus difficile pour quelqu’un d’autre de comprendre et de retenir s’il devait utiliser notre code. Comme nous n’avons pas exprimé la signification de nos données dans notre code, il est maintenant plus facile d’introduire des erreurs.
Refactorisation avec des structs
Nous utilisons les structs pour ajouter du sens en étiquetant les données. Nous pouvons transformer le tuple que nous utilisons en une struct avec un nom pour l’ensemble ainsi que des noms pour les parties, comme le montre le listing 5-10.
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!(
"The area of the rectangle is {} square pixels.",
area(&rect1)
);
}
fn area(rectangle: &Rectangle) -> u32 {
rectangle.width * rectangle.height
}Rectangle structIci, nous avons défini une struct et l’avons nommée Rectangle. À l’intérieur des accolades, nous avons défini les champs width et height, qui sont tous les deux de type u32. Ensuite, dans main, nous avons créé une instance particulière de Rectangle avec une largeur de 30 et une hauteur de 50.
Notre fonction area est maintenant définie avec un seul paramètre, que nous avons nommé rectangle, dont le type est un emprunt immutable d’une instance de la struct Rectangle. Comme mentionné au chapitre 4, nous voulons emprunter la struct plutôt que d’en prendre possession. De cette façon, main conserve la possession et peut continuer à utiliser rect1, c’est pourquoi nous utilisons le & dans la signature de la fonction et à l’endroit où nous appelons la fonction.
La fonction area accède aux champs width et height de l’instance de Rectangle (notez que l’accès aux champs d’une instance de struct empruntée ne déplace pas les valeurs des champs, c’est pourquoi vous voyez souvent des emprunts de structs). Notre signature de fonction pour area dit maintenant exactement ce que nous voulons dire : calculer l’aire d’un Rectangle en utilisant ses champs width et height. Cela exprime que la largeur et la hauteur sont liées entre elles, et cela donne des noms descriptifs aux valeurs plutôt que d’utiliser les valeurs d’index de tuple 0 et 1. C’est un gain de clarté.
Ajouter des fonctionnalités avec les traits dérivés
Il serait utile de pouvoir afficher une instance de Rectangle pendant que nous déboguons notre programme et de voir les valeurs de tous ses champs. Le listing 5-11 essaie d’utiliser la [macro println!][println] comme nous l’avons fait dans les chapitres précédents. Cependant, cela ne fonctionnera pas.
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {rect1}");
}Rectangle instanceLorsque nous compilons ce code, nous obtenons une erreur avec ce message principal : text {{#include ../listings/ch05-using-structs-to-structure-related-data/listing-05-11/output.txt:3}}
error[E0277]: `Rectangle` doesn't implement `std::fmt::Display`
La macro println! peut effectuer de nombreux types de formatage, et par défaut, les accolades indiquent à println! d’utiliser le formatage connu sous le nom de Display : une sortie destinée à la consommation directe par l’utilisateur final. Les types primitifs que nous avons vus jusqu’ici implémentent Display par défaut car il n’y a qu’une seule façon de montrer un 1 ou tout autre type primitif à un utilisateur. Mais avec les structs, la façon dont println! devrait formater la sortie est moins claire car il y a plus de possibilités d’affichage : voulez-vous des virgules ou non ? Voulez-vous afficher les accolades ? Tous les champs doivent-ils être affichés ? En raison de cette ambiguïté, Rust n’essaie pas de deviner ce que nous voulons, et les structs n’ont pas d’implémentation fournie de Display à utiliser avec println! et le placeholder {}.
Si nous continuons à lire les erreurs, nous trouverons cette note utile : text {{#include ../listings/ch05-using-structs-to-structure-related-data/listing-05-11/output.txt:9:10}}
| |`Rectangle` cannot be formatted with the default formatter
| required by this formatting parameter
Essayons ! L’appel à la macro println! ressemblera maintenant à println!("rect1 is {rect1:?}");. Mettre le spécificateur :? à l’intérieur des accolades indique à println! que nous voulons utiliser un format de sortie appelé Debug. Le trait Debug nous permet d’afficher notre struct d’une manière utile pour les développeurs afin que nous puissions voir sa valeur pendant que nous déboguons notre code.
Compilez le code avec cette modification. Zut ! Nous obtenons toujours une erreur : text {{#include ../listings/ch05-using-structs-to-structure-related-data/output-only-01-debug/output.txt:3}}
error[E0277]: `Rectangle` doesn't implement `Debug`
Mais encore une fois, le compilateur nous donne une note utile : text {{#include ../listings/ch05-using-structs-to-structure-related-data/output-only-01-debug/output.txt:9:10}}
| required by this formatting parameter
|
Rust inclut bien la fonctionnalité pour afficher des informations de débogage, mais nous devons explicitement l’activer pour rendre cette fonctionnalité disponible pour notre struct. Pour ce faire, nous ajoutons l’attribut externe #[derive(Debug)] juste avant la définition de la struct, comme le montre le listing 5-12.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!("rect1 is {rect1:?}");
}Debug trait and printing the Rectangle instance using debug formattingMaintenant, quand nous exécutons le programme, nous n’obtiendrons aucune erreur, et nous verrons la sortie suivante : console {{#include ../listings/ch05-using-structs-to-structure-related-data/listing-05-12/output.txt}}
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle { width: 30, height: 50 }
Bien ! Ce n’est pas la plus jolie sortie, mais elle montre les valeurs de tous les champs pour cette instance, ce qui aiderait certainement lors du débogage. Quand nous avons des structs plus grandes, il est utile d’avoir une sortie un peu plus facile à lire ; dans ces cas-là, nous pouvons utiliser {:#?} au lieu de {:?} dans la chaîne de println!. Dans cet exemple, utiliser le style {:#?} produira la sortie suivante : console {{#include ../listings/ch05-using-structs-to-structure-related-data/output-only-02-pretty-debug/output.txt}}
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/rectangles`
rect1 is Rectangle {
width: 30,
height: 50,
}
Une autre façon d’afficher une valeur en utilisant le format Debug est d’utiliser la macro dbg!, qui prend possession d’une expression (contrairement à println!, qui prend une référence), affiche le fichier et le numéro de ligne où l’appel à la macro dbg! se produit dans votre code ainsi que la valeur résultante de cette expression, et retourné la possession de la valeur.
Note : L’appel à la macro
dbg!affiche sur le flux d’erreur standard de la console (stderr), contrairement àprintln!, qui affiche sur le flux de sortie standard de la console (stdout). Nous parlerons davantage destderretstdoutdans la section [« Rediriger les erreurs vers la sortie d’erreur standard » du chapitre 12][err].
Voici un exemple où nous nous intéressons à la valeur assignée au champ width, ainsi qu’à la valeur de la struct entière dans rect1 : rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-05-dbg-macro/src/main.rs}}
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let scale = 2;
let rect1 = Rectangle {
width: dbg!(30 * scale),
height: 50,
};
dbg!(&rect1);
}Nous pouvons placer dbg! autour de l’expression 30 * scale et, comme dbg! retourné la possession de la valeur de l’expression, le champ width recevra la même valeur que si nous n’avions pas l’appel à dbg! à cet endroit. Nous ne voulons pas que dbg! prenne possession de rect1, donc nous utilisons une référence vers rect1 dans l’appel suivant. Voici à quoi ressemble la sortie de cet exemple : console {{#include ../listings/ch05-using-structs-to-structure-related-data/no-listing-05-dbg-macro/output.txt}}
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/rectangles`
[src/main.rs:10:16] 30 * scale = 60
[src/main.rs:14:5] &rect1 = Rectangle {
width: 60,
height: 50,
}
Nous pouvons voir que la première partie de la sortie provient de src/main.rs ligne 10 où nous déboguons l’expression 30 * scale, et sa valeur résultante est 60 (le formatage Debug implémenté pour les entiers consiste à afficher uniquement leur valeur). L’appel à dbg! à la ligne 14 de src/main.rs affiche la valeur de &rect1, qui est la struct Rectangle. Cette sortie utilise le joli formatage Debug du type Rectangle. La macro dbg! peut être vraiment utile quand vous essayez de comprendre ce que fait votre code !
En plus du trait Debug, Rust fournit un certain nombre de traits à utiliser avec l’attribut derive qui peuvent ajouter des comportements utiles à nos types personnalisés. Ces traits et leurs comportements sont listés dans l’[annexe C][app-c]. Nous verrons comment implémenter ces traits avec un comportement personnalisé ainsi que comment créer vos propres traits au chapitre 10. Il existe également de nombreux attributs autres que derive ; pour plus d’informations, consultez [la section « Attributes » de la référence Rust][attributes].
Notre fonction area est très spécifique : elle ne calcule que l’aire de rectangles. Il serait utile de lier ce comportement plus étroitement à notre struct Rectangle car il ne fonctionnera avec aucun autre type. Voyons comment nous pouvons continuer à refactoriser ce code en transformant la fonction area en une méthode area définie sur notre type Rectangle.
Les méthodes
Les méthodes
Les méthodes sont similaires aux fonctions : nous les déclarons avec le mot-clé fn et un nom, elles peuvent avoir des paramètres et une valeur de retour, et elles contiennent du code qui est exécuté lorsque la méthode est appelée depuis un autre endroit. Contrairement aux fonctions, les méthodes sont définies dans le contexte d’une struct (ou d’un enum ou d’un objet trait, que nous abordons respectivement au [chapitre 6][enums] et au [chapitre 18][trait-objects]), et leur premier paramètre est toujours self, qui représente l’instance de la struct sur laquelle la méthode est appelée.
Syntaxe des méthodes
Modifions la fonction area qui prend une instance de Rectangle comme paramètre et faisons-en plutôt une méthode area définie sur la struct Rectangle, comme le montre le listing 5-13.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
println!(
"The area of the rectangle is {} square pixels.",
rect1.area()
);
}area method on the Rectangle structPour définir la fonction dans le contexte de Rectangle, nous commençons un bloc impl (implémentation) pour Rectangle. Tout ce qui se trouve dans ce bloc impl sera associé au type Rectangle. Ensuite, nous déplaçons la fonction area à l’intérieur des accolades du bloc impl et changeons le premier (et dans ce cas, le seul) paramètre pour qu’il soit self dans la signature et partout dans le corps. Dans main, là où nous appelions la fonction area en passant rect1 comme argument, nous pouvons à la place utiliser la syntaxe de méthode pour appeler la méthode area sur notre instance de Rectangle. La syntaxe de méthode s’écrit après une instance : nous ajoutons un point suivi du nom de la méthode, des parenthèses et des éventuels arguments.
Dans la signature de area, nous utilisons &self au lieu de rectangle: &Rectangle. Le &self est en fait l’abréviation de self: &Self. Dans un bloc impl, le type Self est un alias pour le type auquel le bloc impl est destiné. Les méthodes doivent avoir un paramètre nommé self de type Self comme premier paramètre, donc Rust vous permet d’abréger cela avec uniquement le nom self en première position de paramètre. Notez que nous devons toujours utiliser le & devant le raccourci self pour indiquer que cette méthode emprunté l’instance de Self, tout comme nous l’avons fait avec rectangle: &Rectangle. Les méthodes peuvent prendre possession de self, emprunter self de manière immutable, comme nous l’avons fait ici, ou emprunter self de manière mutable, tout comme elles le peuvent pour n’importe quel autre paramètre.
Nous avons choisi &self ici pour la même raison que nous avons utilisé &Rectangle dans la version avec fonction : nous ne voulons pas prendre possession, et nous voulons seulement lire les données de la struct, pas les modifier. Si nous voulions modifier l’instance sur laquelle nous avons appelé la méthode dans le cadre de ce que fait la méthode, nous utiliserions &mut self comme premier paramètre. Avoir une méthode qui prend possession de l’instance en utilisant simplement self comme premier paramètre est rare ; cette technique est généralement utilisée quand la méthode transformé self en quelque chose d’autre et que vous voulez empêcher l’appelant d’utiliser l’instance originale après la transformation.
La raison principale d’utiliser des méthodes plutôt que des fonctions, en plus de fournir la syntaxe de méthode et de ne pas avoir à répéter le type de self dans la signature de chaque méthode, est l’organisation. Nous avons regroupé tout ce que nous pouvons faire avec une instance d’un type dans un seul bloc impl plutôt que d’obliger les futurs utilisateurs de notre code à chercher les fonctionnalités de Rectangle à différents endroits dans la bibliothèque que nous fournissons.
Notez que nous pouvons choisir de donner à une méthode le même nom qu’un des champs de la struct. Par exemple, nous pouvons définir une méthode sur Rectangle qui s’appelle également width :
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn width(&self) -> bool {
self.width > 0
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
if rect1.width() {
println!("The rectangle has a nonzero width; it is {}", rect1.width);
}
}Ici, nous choisissons de faire en sorte que la méthode width retourné true si la valeur du champ width de l’instance est supérieure à 0 et false si la valeur est 0 : nous pouvons utiliser un champ dans une méthode du même nom pour n’importe quel usage. Dans main, quand nous faisons suivre rect1.width de parenthèses, Rust sait que nous parlons de la méthode width. Quand nous n’utilisons pas de parenthèses, Rust sait que nous parlons du champ width.
Souvent, mais pas toujours, quand nous donnons à une méthode le même nom qu’un champ, nous voulons qu’elle retourné uniquement la valeur du champ sans rien faire d’autre. Les méthodes comme celles-ci sont appelées des accesseurs (getters), et Rust ne les implémente pas automatiquement pour les champs des structs comme le font certains autres langages. Les accesseurs sont utiles car vous pouvez rendre le champ privé mais la méthode publique et ainsi permettre un accès en lecture seule à ce champ dans le cadre de l’API publique du type. Nous verrons ce que sont le public et le privé et comment désigner un champ ou une méthode comme public ou privé au [chapitre 7][public].
Où est l’opérateur -> ?
En C et C++, deux opérateurs différents sont utilisés pour appeler des méthodes : vous utilisez . si vous appelez une méthode directement sur l’objet et -> si vous appelez la méthode sur un pointeur vers l’objet et que vous devez d’abord déréférencer le pointeur. Autrement dit, si object est un pointeur, object->something() est similaire à (*object).something().
Rust n’a pas d’équivalent à l’opérateur -> ; à la place, Rust à une fonctionnalité appelée référencement et déréférencement automatiques. L’appel de méthodes est l’un des rares endroits en Rust où ce comportement s’applique.
Voici comment cela fonctionne : quand vous appelez une méthode avec object.something(), Rust ajouté automatiquement &, &mut ou * pour que object corresponde à la signature de la méthode. Autrement dit, les deux lignes suivantes sont équivalentes :
#![allow(unused)]
fn main() {
#[derive(Debug,Copy,Clone)]
struct Point {
x: f64,
y: f64,
}
impl Point {
fn distance(&self, other: &Point) -> f64 {
let x_squared = f64::powi(other.x - self.x, 2);
let y_squared = f64::powi(other.y - self.y, 2);
f64::sqrt(x_squared + y_squared)
}
}
let p1 = Point { x: 0.0, y: 0.0 };
let p2 = Point { x: 5.0, y: 6.5 };
p1.distance(&p2);
(&p1).distance(&p2);
}La première forme est bien plus propre. Ce comportement de référencement automatique fonctionne car les méthodes ont un receveur clair — le type de self. Étant donné le receveur et le nom d’une méthode, Rust peut déterminer avec certitude si la méthode est en lecture (&self), en mutation (&mut self) ou en consommation (self). Le fait que Rust rende implicite l’emprunt pour les receveurs de méthodes est une grande partie de ce qui rend la possession ergonomique en pratique.
Méthodes avec plus de paramètres
Pratiquons l’utilisation des méthodes en implémentant une deuxième méthode sur la struct Rectangle. Cette fois, nous voulons qu’une instance de Rectangle prenne une autre instance de Rectangle et retourné true si le second Rectangle peut tenir entièrement dans self (le premier Rectangle) ; sinon, elle devrait retourner false. C’est-à-dire qu’une fois que nous aurons défini la méthode can_hold, nous voulons pouvoir écrire le programme montré dans le listing 5-14.
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}can_hold methodLa sortie attendue ressemblerait à ce qui suit car les deux dimensions de rect2 sont plus petites que les dimensions de rect1, mais rect3 est plus large que rect1 :
Can rect1 hold rect2? true
Can rect1 hold rect3? false
Nous savons que nous voulons définir une méthode, donc elle sera dans le bloc impl Rectangle. Le nom de la méthode sera can_hold, et elle prendra un emprunt immutable d’un autre Rectangle comme paramètre. Nous pouvons deviner le type du paramètre en regardant le code qui appelle la méthode : rect1.can_hold(&rect2) passe &rect2, qui est un emprunt immutable de rect2, une instance de Rectangle. Cela a du sens car nous n’avons besoin que de lire rect2 (plutôt que d’écrire, ce qui signifierait que nous aurions besoin d’un emprunt mutable), et nous voulons que main conserve la possession de rect2 pour pouvoir l’utiliser à nouveau après l’appel à la méthode can_hold. La valeur de retour de can_hold sera un booléen, et l’implémentation vérifiera si la largeur et la hauteur de self sont respectivement supérieures à la largeur et à la hauteur de l’autre Rectangle. Ajoutons la nouvelle méthode can_hold au bloc impl du listing 5-13, comme le montre le listing 5-15.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}can_hold method on Rectangle that takes another Rectangle instance as a parameterQuand nous exécutons ce code avec la fonction main du listing 5-14, nous obtiendrons la sortie souhaitée. Les méthodes peuvent prendre plusieurs paramètres que nous ajoutons à la signature après le paramètre self, et ces paramètres fonctionnent exactement comme les paramètres dans les fonctions.
Fonctions associées
Toutes les fonctions définies dans un bloc impl sont appelées fonctions associées car elles sont associées au type nommé après le impl. Nous pouvons définir des fonctions associées qui n’ont pas self comme premier paramètre (et ne sont donc pas des méthodes) car elles n’ont pas besoin d’une instance du type pour fonctionner. Nous avons déjà utilisé une telle fonction : la fonction String::from qui est définie sur le type String.
Les fonctions associées qui ne sont pas des méthodes sont souvent utilisées comme constructeurs qui retourneront une nouvelle instance de la struct. Elles sont souvent appelées new, mais new n’est pas un nom spécial et n’est pas intégré au langage. Par exemple, nous pourrions choisir de fournir une fonction associée nommée square qui aurait un seul paramètre de dimension et l’utiliserait à la fois comme largeur et comme hauteur, rendant ainsi plus facile la création d’un Rectangle carré plutôt que de devoir spécifier la même valeur deux fois :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn square(size: u32) -> Self {
Self {
width: size,
height: size,
}
}
}
fn main() {
let sq = Rectangle::square(3);
}Les mots-clés Self dans le type de retour et dans le corps de la fonction sont des alias pour le type qui apparaît après le mot-clé impl, qui dans ce cas est Rectangle.
Pour appeler cette fonction associée, nous utilisons la syntaxe :: avec le nom de la struct ; let sq = Rectangle::square(3); en est un exemple. Cette fonction est dans l’espace de noms de la struct : la syntaxe :: est utilisée à la fois pour les fonctions associées et les espaces de noms créés par les modules. Nous aborderons les modules au [chapitre 7][modules].
Blocs impl multiples
Chaque struct est autorisée à avoir plusieurs blocs impl. Par exemple, le listing 5-15 est équivalent au code montré dans le listing 5-16, qui à chaque méthode dans son propre bloc impl.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn area(&self) -> u32 {
self.width * self.height
}
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
fn main() {
let rect1 = Rectangle {
width: 30,
height: 50,
};
let rect2 = Rectangle {
width: 10,
height: 40,
};
let rect3 = Rectangle {
width: 60,
height: 45,
};
println!("Can rect1 hold rect2? {}", rect1.can_hold(&rect2));
println!("Can rect1 hold rect3? {}", rect1.can_hold(&rect3));
}impl blocksIl n’y à aucune raison de séparer ces méthodes en plusieurs blocs impl ici, mais c’est une syntaxe valide. Nous verrons un cas où les blocs impl multiples sont utiles au chapitre 10, où nous aborderons les types génériques et les traits.
Résumé
Les structs vous permettent de créer des types personnalisés qui ont du sens pour votre domaine. En utilisant les structs, vous pouvez garder des éléments de données associés connectés les uns aux autres et nommer chaque élément pour rendre votre code clair. Dans les blocs impl, vous pouvez définir des fonctions qui sont associées à votre type, et les méthodes sont un type de fonction associée qui vous permet de spécifier le comportement que les instances de vos structs possèdent.
Mais les structs ne sont pas le seul moyen de créer des types personnalisés : tournons-nous vers la fonctionnalité enum de Rust pour ajouter un autre outil à votre boîte à outils.
Les enums et le filtrage par motif
Dans ce chapitre, nous allons étudier les énumérations, également appelées enums. Les enums vous permettent de définir un type en énumérant ses variantes possibles. D’abord, nous allons définir et utiliser une enum pour montrer comment une enum peut encoder du sens en même temps que des données. Ensuite, nous explorerons une enum particulièrement utile, appelée Option, qui exprime qu’une valeur peut être soit quelque chose, soit rien. Puis, nous verrons comment le filtrage par motif avec l’expression match facilite l’exécution de code différent selon les valeurs d’une enum. Enfin, nous aborderons la construction if let, un autre idiome pratique et concis disponible pour gérer les enums dans votre code.
Définir une enum
Définir une enum
Là où les structures vous permettent de regrouper des champs et des données liées, comme un Rectangle avec sa width (largeur) et sa height (hauteur), les enums vous permettent d’exprimer qu’une valeur fait partie d’un ensemble possible de valeurs. Par exemple, nous pourrions vouloir dire que Rectangle est l’une des formes possibles d’un ensemble qui inclut aussi Circle et Triangle. Pour ce faire, Rust nous permet d’encoder ces possibilités sous forme d’enum.
Examinons une situation que nous pourrions vouloir exprimer dans du code et voyons pourquoi les enums sont utiles et plus appropriées que les structures dans ce cas. Imaginons que nous devions travailler avec des adresses IP. Actuellement, deux standards principaux sont utilisés pour les adresses IP : la version quatre et la version six. Comme ce sont les seules possibilités d’adresse IP que notre programme rencontrera, nous pouvons énumérer toutes les variantes possibles, ce qui est l’origine du nom « énumération ».
Toute adresse IP peut être soit une adresse en version quatre, soit une adresse en version six, mais pas les deux en même temps. Cette propriété des adresses IP rend la structure de données enum appropriée, car une valeur d’enum ne peut être que l’une de ses variantes. Les adresses en version quatre et en version six restent fondamentalement des adresses IP, elles doivent donc être traitées comme le même type lorsque le code gère des situations qui s’appliquent à n’importe quel type d’adresse IP.
Nous pouvons exprimer ce concept dans le code en définissant une énumération IpAddrKind et en listant les types possibles d’adresse IP, V4 et V6. Ce sont les variantes de l’enum : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-01-defining-enums/src/main.rs:def}}
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}IpAddrKind est maintenant un type de données personnalisé que nous pouvons utiliser ailleurs dans notre code.
Valeurs d’enum
Nous pouvons créer des instances de chacune des deux variantes de IpAddrKind comme ceci : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-01-defining-enums/src/main.rs:instance}}
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}Remarquez que les variantes de l’enum sont dans l’espace de noms de son identifiant, et nous utilisons un double deux-points pour les séparer. C’est utile car maintenant les deux valeurs IpAddrKind::V4 et IpAddrKind::V6 sont du même type : IpAddrKind. Nous pouvons alors, par exemple, définir une fonction qui accepte n’importe quel IpAddrKind : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-01-defining-enums/src/main.rs:fn}}
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}Et nous pouvons appeler cette fonction avec l’une où l’autre variante : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-01-defining-enums/src/main.rs:fn_call}}
enum IpAddrKind {
V4,
V6,
}
fn main() {
let four = IpAddrKind::V4;
let six = IpAddrKind::V6;
route(IpAddrKind::V4);
route(IpAddrKind::V6);
}
fn route(ip_kind: IpAddrKind) {}Utiliser des enums présente encore plus d’avantages. En réfléchissant davantage à notre type d’adresse IP, pour l’instant nous n’avons pas de moyen de stocker les données réelles de l’adresse IP ; nous savons seulement de quel type elle est. Étant donné que vous venez d’apprendre les structures au chapitre 5, vous pourriez être tenté de résoudre ce problème avec des structures comme le montre l’encart 6-1.
fn main() {
enum IpAddrKind {
V4,
V6,
}
struct IpAddr {
kind: IpAddrKind,
address: String,
}
let home = IpAddr {
kind: IpAddrKind::V4,
address: String::from("127.0.0.1"),
};
let loopback = IpAddr {
kind: IpAddrKind::V6,
address: String::from("::1"),
};
}IpAddrKind variant of an IP address using a structIci, nous avons défini une structure IpAddr qui possède deux champs : un champ kind de type IpAddrKind (l’enum que nous avons définie précédemment) et un champ address de type String. Nous avons deux instances de cette structure. La première est home, et elle à la valeur IpAddrKind::V4 comme kind avec les données d’adresse associées 127.0.0.1. La seconde instance est loopback. Elle à l’autre variante de IpAddrKind comme valeur de kind, V6, et à l’adresse ::1 associée. Nous avons utilisé une structure pour regrouper les valeurs kind et address, donc maintenant la variante est associée à la valeur.
Cependant, représenter le même concept en utilisant uniquement une enum est plus concis : plutôt qu’une enum à l’intérieur d’une structure, nous pouvons placer les données directement dans chaque variante de l’enum. Cette nouvelle définition de l’enum IpAddr indique que les variantes V4 et V6 auront toutes deux des valeurs String associées : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-02-enum-with-data/src/main.rs:here}}
fn main() {
enum IpAddr {
V4(String),
V6(String),
}
let home = IpAddr::V4(String::from("127.0.0.1"));
let loopback = IpAddr::V6(String::from("::1"));
}Nous attachons les données directement à chaque variante de l’enum, il n’y a donc pas besoin d’une structure supplémentaire. Ici, il est aussi plus facile de voir un autre détail du fonctionnement des enums : le nom de chaque variante d’enum que nous définissons devient aussi une fonction qui construit une instance de l’enum. C’est-à-dire que IpAddr::V4() est un appel de fonction qui prend un argument String et renvoie une instance du type IpAddr. Nous obtenons automatiquement cette fonction constructeur en définissant l’enum.
Il y à un autre avantage à utiliser une enum plutôt qu’une structure : chaque variante peut avoir des types et des quantités différentes de données associées. Les adresses IP en version quatre auront toujours quatre composants numériques dont les valeurs seront comprises entre 0 et 255. Si nous voulions stocker les adresses V4 comme quatre valeurs u8 tout en exprimant les adresses V6 comme une seule valeur String, nous ne pourrions pas le faire avec une structure. Les enums gèrent ce cas avec facilité : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-03-variants-with-different-data/src/main.rs:here}}
fn main() {
enum IpAddr {
V4(u8, u8, u8, u8),
V6(String),
}
let home = IpAddr::V4(127, 0, 0, 1);
let loopback = IpAddr::V6(String::from("::1"));
}Nous avons montré plusieurs façons différentes de définir des structures de données pour stocker les adresses IP en version quatre et en version six. Cependant, il s’avère que vouloir stocker des adresses IP et encoder leur type est si courant que [la bibliothèque standard à une définition que nous pouvons utiliser !][IpAddr] Voyons comment la bibliothèque standard définit IpAddr. Elle possède exactement l’enum et les variantes que nous avons définies et utilisées, mais elle intègre les données d’adresse dans les variantes sous la forme de deux structures différentes, qui sont définies différemment pour chaque variante :
#![allow(unused)]
fn main() {
struct Ipv4Addr {
// --snip--
}
struct Ipv6Addr {
// --snip--
}
enum IpAddr {
V4(Ipv4Addr),
V6(Ipv6Addr),
}
}Ce code illustre que vous pouvez mettre n’importe quel type de données dans une variante d’enum : des chaînes de caractères, des types numériques, ou des structures, par exemple. Vous pouvez même inclure une autre enum ! De plus, les types de la bibliothèque standard ne sont souvent pas beaucoup plus compliqués que ce que vous pourriez concevoir vous-même.
Notez que même si la bibliothèque standard contient une définition pour IpAddr, nous pouvons toujours créer et utiliser notre propre définition sans conflit car nous n’avons pas importé la définition de la bibliothèque standard dans notre portée. Nous parlerons davantage de l’importation de types dans la portée au chapitre 7.
Examinons un autre exemple d’enum dans l’encart 6-2 : celle-ci à une grande variété de types intégrés dans ses variantes.
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {}Message enum whose variants each store different amounts and types of valuesCette enum a quatre variantes avec des types différents :
Quit: n’à aucune donnée associéeMove: à des champs nommés, comme une structureWrite: inclut une seuleStringChangeColor: inclut trois valeursi32
Définir une enum avec des variantes telles que celles de l’encart 6-2 est similaire à définir différents types de structures, sauf que l’enum n’utilise pas le mot-clé struct et que toutes les variantes sont regroupées sous le type Message. Les structures suivantes pourraient contenir les mêmes données que les variantes de l’enum précédente : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-04-structs-similar-to-message-enum/src/main.rs:here}}
struct QuitMessage; // unit struct
struct MoveMessage {
x: i32,
y: i32,
}
struct WriteMessage(String); // tuple struct
struct ChangeColorMessage(i32, i32, i32); // tuple struct
fn main() {}Mais si nous utilisions les différentes structures, chacune ayant son propre type, nous ne pourrions pas aussi facilement définir une fonction acceptant n’importe lequel de ces types de messages que nous le pourrions avec l’enum Message définie dans l’encart 6-2, qui est un type unique.
Il y a encore une similarité entre les enums et les structures : tout comme nous pouvons définir des méthodes sur les structures avec impl, nous pouvons aussi définir des méthodes sur les enums. Voici une méthode nommée call que nous pourrions définir sur notre enum Message : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-05-methods-on-enums/src/main.rs:here}}
fn main() {
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
impl Message {
fn call(&self) {
// method body would be defined here
}
}
let m = Message::Write(String::from("hello"));
m.call();
}Le corps de la méthode utiliserait self pour obtenir la valeur sur laquelle nous avons appelé la méthode. Dans cet exemple, nous avons créé une variable m qui à la valeur Message::Write(String::from("hello")), et c’est ce que self sera dans le corps de la méthode call lorsque m.call() s’exécute.
Examinons une autre enum de la bibliothèque standard qui est très courante et utile : Option.
L’enum Option
Cette section explore une étude de cas sur Option, qui est une autre enum définie par la bibliothèque standard. Le type Option encode le scénario très courant dans lequel une valeur peut être quelque chose, ou peut être rien.
Par exemple, si vous demandez le premier élément d’une liste non vide, vous obtiendrez une valeur. Si vous demandez le premier élément d’une liste vide, vous n’obtiendrez rien. Exprimer ce concept en termes de système de types signifie que le compilateur peut vérifier que vous avez géré tous les cas que vous devriez gérer ; cette fonctionnalité peut prévenir des bogues qui sont extrêmement courants dans d’autres langages de programmation.
La conception de langages de programmation est souvent pensée en termes de fonctionnalités que vous incluez, mais les fonctionnalités que vous excluez sont importantes aussi. Rust n’a pas la fonctionnalité null que beaucoup d’autres langages ont. Null est une valeur qui signifie qu’il n’y a pas de valeur. Dans les langages avec null, les variables peuvent toujours être dans l’un de ces deux états : null ou non-null.
Dans sa présentation de 2009 intitulée « Null Références: The Billion Dollar Mistake » (Les références nulles : l’erreur à un milliard de dollars), Tony Hoare, l’inventeur de null, a déclaré :
Je l’appelle mon erreur à un milliard de dollars. À cette époque, je concevais le premier système de types complet pour les références dans un langage orienté objet. Mon objectif était de garantir que toute utilisation des références soit absolument sûre, avec une vérification effectuée automatiquement par le compilateur. Mais je n’ai pas pu résister à la tentation d’ajouter une référence nulle, simplement parce que c’était si facile à implémenter. Cela a conduit à d’innombrables erreurs, vulnérabilités et plantages système, qui ont probablement causé un milliard de dollars de douleur et de dommages au cours des quarante dernières années.
Le problème avec les valeurs null est que si vous essayez d’utiliser une valeur null comme si c’était une valeur non-null, vous obtiendrez une erreur quelconque. Parce que cette propriété null ou non-null est omniprésente, il est extrêmement facile de faire ce type d’erreur.
Cependant, le concept que null essaie d’exprimer reste utile : un null est une valeur qui est actuellement invalide ou absente pour une raison quelconque.
as follows: –> Le problème n’est pas vraiment le concept mais l’implémentation particulière. En tant que tel, Rust n’a pas de null, mais il possède une enum qui peut encoder le concept d’une valeur étant présente ou absente. Cette enum est Option<T>, et elle est [définie par la bibliothèque standard][option] comme suit :
#![allow(unused)]
fn main() {
enum Option<T> {
None,
Some(T),
}
}L’enum Option<T> est si utile qu’elle est même incluse dans le prelude ; vous n’avez pas besoin de l’importer explicitement dans la portée. Ses variantes sont également incluses dans le prelude : vous pouvez utiliser Some et None directement sans le préfixe Option::. L’enum Option<T> reste simplement une enum ordinaire, et Some(T) et None sont toujours des variantes du type Option<T>.
La syntaxe <T> est une fonctionnalité de Rust dont nous n’avons pas encore parlé. C’est un paramètre de type générique, et nous couvrirons les génériques plus en détail au chapitre 10. Pour l’instant, tout ce que vous devez savoir est que <T> signifie que la variante Some de l’enum Option peut contenir un élément de données de n’importe quel type, et que chaque type concret utilisé à la place de T fait du type Option<T> global un type différent. Voici quelques exemples d’utilisation de valeurs Option pour contenir des types numériques et des types char : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-06-option-examples/src/main.rs:here}}
fn main() {
let some_number = Some(5);
let some_char = Some('e');
let absent_number: Option<i32> = None;
}Le type de some_number est Option<i32>. Le type de some_char est Option<char>, qui est un type différent. Rust peut inférer ces types parce que nous avons spécifié une valeur à l’intérieur de la variante Some. Pour absent_number, Rust nous demande d’annoter le type Option global : le compilateur ne peut pas inférer le type que la variante Some correspondante contiendra en regardant uniquement une valeur None. Ici, nous indiquons à Rust que nous voulons que absent_number soit de type Option<i32>.
Quand nous avons une valeur Some, nous savons qu’une valeur est présente, et la valeur est contenue dans le Some. Quand nous avons une valeur None, dans un certain sens, cela signifie la même chose que null : nous n’avons pas de valeur valide. Alors, pourquoi Option<T> est-il meilleur que null ?
En bref, parce que Option<T> et T (où T peut être n’importe quel type) sont des types différents, le compilateur ne nous laissera pas utiliser une valeur Option<T> comme si c’était assurément une valeur valide. Par exemple, ce code ne compilera pas, parce qu’il essaie d’additionner un i8 et un Option<i8> : rust,ignore,does_not_compile {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-07-cant-use-option-directly/src/main.rs:here}}
fn main() {
let x: i8 = 5;
let y: Option<i8> = Some(5);
let sum = x + y;
}Si nous exécutons ce code, nous obtenons un message d’erreur comme celui-ci : console {{#include ../listings/ch06-enums-and-pattern-matching/no-listing-07-cant-use-option-directly/output.txt}}
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0277]: cannot add `Option<i8>` to `i8`
--> src/main.rs:5:17
|
5 | let sum = x + y;
| ^ no implementation for `i8 + Option<i8>`
|
= help: the trait `Add<Option<i8>>` is not implemented for `i8`
= help: the following other types implement trait `Add<Rhs>`:
`&i8` implements `Add<i8>`
`&i8` implements `Add`
`i8` implements `Add<&i8>`
`i8` implements `Add`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Intense ! En fait, ce message d’erreur signifie que Rust ne comprend pas comment additionner un i8 et un Option<i8>, parce que ce sont des types différents. Quand nous avons une valeur d’un type comme i8 en Rust, le compilateur s’assuré que nous avons toujours une valeur valide. Nous pouvons procéder en toute confiance sans avoir à vérifier null avant d’utiliser cette valeur. Ce n’est que lorsque nous avons un Option<i8> (ou quel que soit le type de valeur avec lequel nous travaillons) que nous devons nous soucier de la possibilité de ne pas avoir de valeur, et le compilateur s’assurera que nous gérons ce cas avant d’utiliser la valeur.
En d’autres termes, vous devez convertir un Option<T> en T avant de pouvoir effectuer des opérations de type T avec. Généralement, cela aide à détecter l’un des problèmes les plus courants avec null : supposer que quelque chose n’est pas null alors qu’en réalité il l’est.
Éliminer le risque de supposer incorrectement une valeur non-null vous aide à avoir plus confiance en votre code. Pour avoir une valeur qui peut possiblement être nulle, vous devez explicitement opter pour cela en faisant du type de cette valeur Option<T>. Ensuite, quand vous utilisez cette valeur, vous êtes obligé de gérer explicitement le cas où la valeur est nulle. Partout où une valeur à un type qui n’est pas un Option<T>, vous pouvez supposer en toute sécurité que la valeur n’est pas nulle. C’était une décision de conception délibérée de Rust pour limiter l’omniprésence du null et augmenter la sécurité du code Rust.
Alors, comment obtenir la valeur T d’une variante Some quand vous avez une valeur de type Option<T> pour pouvoir utiliser cette valeur ? L’enum Option<T> possède un grand nombre de méthodes utiles dans diverses situations ; vous pouvez les consulter dans [sa documentation][docs]. Se familiariser avec les méthodes de Option<T> sera extrêmement utile dans votre parcours avec Rust.
En général, pour utiliser une valeur Option<T>, vous voulez avoir du code qui gère chaque variante. Vous voulez du code qui ne s’exécutera que lorsque vous avez une valeur Some(T), et ce code est autorisé à utiliser le T interne. Vous voulez qu’un autre code ne s’exécute que si vous avez une valeur None, et ce code n’a pas de valeur T disponible. L’expression match est une construction de flux de contrôle qui fait exactement cela lorsqu’elle est utilisée avec des enums : elle exécutera un code différent selon la variante de l’enum, et ce code peut utiliser les données à l’intérieur de la valeur correspondante.
La structure de contrôle match
La structure de contrôle match
Rust possède une construction de flux de contrôle extrêmement puissante appelée match qui vous permet de comparer une valeur à une série de motifs puis d’exécuter du code en fonction du motif qui correspond. Les motifs peuvent être composés de valeurs littérales, de noms de variables, de jokers, et de bien d’autres choses ; le [chapitre 19][ch19-00-patterns] couvre tous les différents types de motifs et ce qu’ils font. La puissance de match vient de l’expressivité des motifs et du fait que le compilateur confirme que tous les cas possibles sont gérés.
Imaginez une expression match comme une machine à trier les pièces de monnaie : les pièces glissent le long d’une piste percée de trous de différentes tailles, et chaque pièce tombe dans le premier trou qu’elle rencontre et dans lequel elle passe. De la même manière, les valeurs passent à travers chaque motif d’un match, et au premier motif auquel la valeur « correspond », la valeur tombe dans le bloc de code associé pour être utilisée lors de l’exécution.
En parlant de pièces de monnaie, utilisons-les comme exemple avec match ! Nous pouvons écrire une fonction qui prend une pièce américaine inconnue et, de manière similaire à la machine à compter, détermine quelle pièce c’est et renvoie sa valeur en centimes, comme le montre l’encart 6-3.
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
fn main() {}match expression that has the variants of the enum as its patternsDécomposons le match dans la fonction value_in_cents. D’abord, nous écrivons le mot-clé match suivi d’une expression, qui dans ce cas est la valeur coin. Cela semble très similaire à une expression conditionnelle utilisée avec if, mais il y à une grande différence : avec if, la condition doit s’évaluer à une valeur booléenne, mais ici elle peut être de n’importe quel type. Le type de coin dans cet exemple est l’enum Coin que nous avons définie à la première ligne.
Ensuite viennent les bras du match. Un bras a deux parties : un motif et du code. Le premier bras ici à un motif qui est la valeur Coin::Penny puis l’opérateur => qui sépare le motif et le code à exécuter. Le code dans ce cas est simplement la valeur 1. Chaque bras est séparé du suivant par une virgule.
Lorsque l’expression match s’exécute, elle compare la valeur résultante au motif de chaque bras, dans l’ordre. Si un motif correspond à la valeur, le code associé à ce motif est exécuté. Si ce motif ne correspond pas à la valeur, l’exécution continue au bras suivant, tout comme dans une machine à trier les pièces. Nous pouvons avoir autant de bras que nécessaire : dans l’encart 6-3, notre match a quatre bras.
Le code associé à chaque bras est une expression, et la valeur résultante de l’expression dans le bras correspondant est la valeur qui est renvoyée pour l’ensemble de l’expression match.
Nous n’utilisons généralement pas d’accolades si le code du bras de match est court, comme c’est le cas dans l’encart 6-3 où chaque bras renvoie simplement une valeur. Si vous voulez exécuter plusieurs lignes de code dans un bras de match, vous devez utiliser des accolades, et la virgule après le bras est alors optionnelle. Par exemple, le code suivant affiche « Lucky penny! » chaque fois que la méthode est appelée avec un Coin::Penny, mais renvoie quand même la dernière valeur du bloc, 1 : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-08-match-arm-multiple-lines/src/main.rs:here}}
enum Coin {
Penny,
Nickel,
Dime,
Quarter,
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => {
println!("Lucky penny!");
1
}
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter => 25,
}
}
fn main() {}Les motifs qui se lient à des valeurs
Une autre fonctionnalité utile des bras de match est qu’ils peuvent se lier aux parties des valeurs qui correspondent au motif. C’est ainsi que nous pouvons extraire des valeurs des variantes d’enum.
À titre d’exemple, modifions l’une de nos variantes d’enum pour qu’elle contienne des données. De 1999 à 2008, les États-Unis ont frappé des quarters (pièces de 25 centimes) avec des designs différents pour chacun des 50 États sur une face. Aucune autre pièce n’a reçu de design d’État, donc seuls les quarters ont cette valeur supplémentaire. Nous pouvons ajouter cette information à notre enum en modifiant la variante Quarter pour qu’elle inclue une valeur UsState stockée à l’intérieur, ce que nous avons fait dans l’encart 6-4.
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn main() {}Coin enum in which the Quarter variant also holds a UsState valueImaginons qu’un ami essaie de collectionner les quarters des 50 États. Pendant que nous trions notre monnaie par type de pièce, nous allons aussi annoncer le nom de l’État associé à chaque quarter afin que si c’en est un que notre ami n’a pas, il puisse l’ajouter à sa collection.
Dans l’expression match pour ce code, nous ajoutons une variable appelée state au motif qui correspond aux valeurs de la variante Coin::Quarter. Quand un Coin::Quarter correspond, la variable state se liera à la valeur de l’État de ce quarter. Ensuite, nous pouvons utiliser state dans le code de ce bras, comme ceci : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-09-variable-in-pattern/src/main.rs:here}}
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn value_in_cents(coin: Coin) -> u8 {
match coin {
Coin::Penny => 1,
Coin::Nickel => 5,
Coin::Dime => 10,
Coin::Quarter(state) => {
println!("State quarter from {state:?}!");
25
}
}
}
fn main() {
value_in_cents(Coin::Quarter(UsState::Alaska));
}Si nous appelions value_in_cents(Coin::Quarter(UsState::Alaska)), coin serait Coin::Quarter(UsState::Alaska). Quand nous comparons cette valeur avec chacun des bras du match, aucun d’entre eux ne correspond jusqu’à ce que nous atteignions Coin::Quarter(state). À ce moment-là, la liaison pour state sera la valeur UsState::Alaska. Nous pouvons ensuite utiliser cette liaison dans l’expression println!, obtenant ainsi la valeur interne de l’État de la variante Coin pour Quarter.
Le motif match avec Option<T>
Dans la section précédente, nous voulions obtenir la valeur interne T du cas Some en utilisant Option<T> ; nous pouvons aussi gérer Option<T> avec match, comme nous l’avons fait avec l’enum Coin ! Au lieu de comparer des pièces, nous allons comparer les variantes d’Option<T>, mais le fonctionnement de l’expression match reste le même.
Disons que nous voulons écrire une fonction qui prend un Option<i32> et, s’il y à une valeur à l’intérieur, ajouté 1 à cette valeur. S’il n’y a pas de valeur à l’intérieur, la fonction devrait renvoyer la valeur None et ne pas tenter d’effectuer d’opération.
Cette fonction est très facile à écrire, grâce à match, et ressemblera à l’encart 6-5.
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}match expression on an Option<i32>Examinons plus en détail la première exécution de plus_one. Lorsque nous appelons plus_one(five), la variable x dans le corps de plus_one aura la valeur Some(5). Nous comparons ensuite cette valeur à chaque bras du match : rust,ignore {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/listing-06-05/src/main.rs:first_arm}}
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}La valeur Some(5) ne correspond pas au motif None, donc nous continuons au bras suivant : rust,ignore {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/listing-06-05/src/main.rs:second_arm}}
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Est-ce que Some(5) correspond à Some(i) ? Oui ! Nous avons la même variante. Le i se lie à la valeur contenue dans Some, donc i prend la valeur 5. Le code du bras de match est alors exécuté, nous ajoutons donc 1 à la valeur de i et créons une nouvelle valeur Some avec notre total 6 à l’intérieur.
Considérons maintenant le second appel de plus_one dans l’encart 6-5, où x est None. Nous entrons dans le match et comparons au premier bras : rust,ignore {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/listing-06-05/src/main.rs:first_arm}}
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
None => None,
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Ça correspond ! Il n’y a pas de valeur à laquelle ajouter, donc le programme s’arrête et renvoie la valeur None à droite du =>. Parce que le premier bras a correspondu, aucun autre bras n’est comparé.
Combiner match et les enums est utile dans de nombreuses situations. Vous verrez beaucoup ce motif dans le code Rust : faire un match sur une enum, lier une variable aux données à l’intérieur, puis exécuter du code en fonction de cela. C’est un peu déroutant au début, mais une fois que vous vous y serez habitué, vous souhaiterez l’avoir dans tous les langages. C’est constamment un favori des utilisateurs.
Les correspondances sont exhaustives
Il y à un autre aspect de match que nous devons aborder : les motifs des bras doivent couvrir toutes les possibilités. Considérez cette version de notre fonction plus_one, qui contient un bogue et ne compilera pas : rust,ignore,does_not_compile {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-10-non-exhaustive-match/src/main.rs:here}}
fn main() {
fn plus_one(x: Option<i32>) -> Option<i32> {
match x {
Some(i) => Some(i + 1),
}
}
let five = Some(5);
let six = plus_one(five);
let none = plus_one(None);
}Nous n’avons pas géré le cas None, donc ce code causera un bogue. Heureusement, c’est un bogue que Rust sait détecter. Si nous essayons de compiler ce code, nous obtiendrons cette erreur : console {{#include ../listings/ch06-enums-and-pattern-matching/no-listing-10-non-exhaustive-match/output.txt}}
$ cargo run
Compiling enums v0.1.0 (file:///projects/enums)
error[E0004]: non-exhaustive patterns: `None` not covered
--> src/main.rs:3:15
|
3 | match x {
| ^ pattern `None` not covered
|
note: `Option<i32>` defined here
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/option.rs:593:1
::: /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/core/src/option.rs:597:5
|
= note: not covered
= note: the matched value is of type `Option<i32>`
help: ensure that all possible cases are being handled by adding a match arm with a wildcard pattern or an explicit pattern as shown
|
4 ~ Some(i) => Some(i + 1),
5 ~ None => todo!(),
|
For more information about this error, try `rustc --explain E0004`.
error: could not compile `enums` (bin "enums") due to 1 previous error
Rust sait que nous n’avons pas couvert tous les cas possibles et sait même quel motif nous avons oublié ! Les correspondances en Rust sont exhaustives : nous devons épuiser toutes les possibilités pour que le code soit valide. En particulier dans le cas d’Option<T>, quand Rust nous empêche d’oublier de gérer explicitement le cas None, il nous protège de l’hypothèse que nous avons une valeur quand nous pourrions avoir null, rendant ainsi impossible l’erreur à un milliard de dollars évoquée précédemment.
Les motifs attrape-tout et le caractère générique _
En utilisant des enums, nous pouvons aussi effectuer des actions spéciales pour quelques valeurs particulières, mais pour toutes les autres valeurs, effectuer une action par défaut. Imaginons que nous implémentons un jeu où, si vous lancez un 3 avec un dé, votre joueur ne bouge pas mais obtient un nouveau chapeau élégant. Si vous lancez un 7, votre joueur perd un chapeau élégant. Pour toutes les autres valeurs, votre joueur avance de ce nombre de cases sur le plateau de jeu. Voici un match qui implémente cette logique, avec le résultat du lancer de dé codé en dur plutôt qu’une valeur aléatoire, et toute autre logique représentée par des fonctions sans corps car leur implémentation réelle dépasse le cadre de cet exemple : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-15-binding-catchall/src/main.rs:here}}
fn main() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
other => move_player(other),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
fn move_player(num_spaces: u8) {}
}Pour les deux premiers bras, les motifs sont les valeurs littérales 3 et 7. Pour le dernier bras qui couvre toutes les autres valeurs possibles, le motif est la variable que nous avons choisi de nommer other. Le code qui s’exécute pour le bras other utilise la variable en la passant à la fonction move_player.
Ce code compilé, même si nous n’avons pas listé toutes les valeurs possibles qu’un u8 peut avoir, parce que le dernier motif correspondra à toutes les valeurs non spécifiquement listées. Ce motif attrape-tout satisfait l’exigence que match doit être exhaustif. Notez que nous devons placer le bras attrape-tout en dernier car les motifs sont évalués dans l’ordre. Si nous avions placé le bras attrape-tout plus tôt, les autres bras ne s’exécuteraient jamais, donc Rust nous avertira si nous ajoutons des bras après un attrape-tout !
Rust a aussi un motif que nous pouvons utiliser lorsque nous voulons un attrape-tout mais ne voulons pas utiliser la valeur dans le motif attrape-tout : _ est un motif spécial qui correspond à n’importe quelle valeur et ne se lie pas à cette valeur. Cela indique à Rust que nous n’allons pas utiliser la valeur, donc Rust ne nous avertira pas d’une variable inutilisée.
Changeons les règles du jeu : maintenant, si vous lancez autre chose qu’un 3 ou un 7, vous devez relancer. Nous n’avons plus besoin d’utiliser la valeur attrape-tout, donc nous pouvons modifier notre code pour utiliser _ au lieu de la variable nommée other : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-16-underscore-catchall/src/main.rs:here}}
fn main() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
_ => reroll(),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
fn reroll() {}
}Cet exemple satisfait aussi l’exigence d’exhaustivité car nous ignorons explicitement toutes les autres valeurs dans le dernier bras ; nous n’avons rien oublié.
Enfin, nous allons modifier les règles du jeu une dernière fois pour que rien d’autre ne se passe pendant votre tour si vous lancez autre chose qu’un 3 ou un 7. Nous pouvons exprimer cela en utilisant la valeur unitaire (le type tuple vide que nous avons mentionné dans la section [« Le type tuple »][tuples]) comme code associé au bras _ : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-17-underscore-unit/src/main.rs:here}}
fn main() {
let dice_roll = 9;
match dice_roll {
3 => add_fancy_hat(),
7 => remove_fancy_hat(),
_ => (),
}
fn add_fancy_hat() {}
fn remove_fancy_hat() {}
}Ici, nous disons explicitement à Rust que nous n’allons pas utiliser d’autre valeur qui ne correspond pas à un motif dans un bras précédent, et que nous ne voulons exécuter aucun code dans ce cas.
Il y a davantage à dire sur les motifs et le filtrage, que nous couvrirons au chapitre 19. Pour le moment, nous allons passer à la syntaxe if let, qui peut être utile dans des situations où l’expression match est un peu verbeuse.
Un contrôle de flux concis avec if let et let...else
Un contrôle de flux concis avec if let et let...else
La syntaxe if let vous permet de combiner if et let de manière moins verbeuse pour gérer les valeurs qui correspondent à un motif tout en ignorant les autres. Considérez le programme de l’encart 6-6 qui fait un filtrage sur une valeur Option<u8> dans la variable config_max mais ne veut exécuter du code que si la valeur est la variante Some.
fn main() {
let config_max = Some(3u8);
match config_max {
Some(max) => println!("The maximum is configured to be {max}"),
_ => (),
}
}match that only cares about executing code when the value is SomeSi la valeur est Some, nous affichons la valeur de la variante Some en liant la valeur à la variable max dans le motif. Nous ne voulons rien faire avec la valeur None. Pour satisfaire l’expression match, nous devons ajouter _ => () après avoir traité une seule variante, ce qui est du code passe-partout ennuyeux à ajouter.
À la place, nous pourrions écrire cela de manière plus courte en utilisant if let. Le code suivant se comporte de la même manière que le match de l’encart 6-6 : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-12-if-let/src/main.rs:here}}
fn main() {
let config_max = Some(3u8);
if let Some(max) = config_max {
println!("The maximum is configured to be {max}");
}
}La syntaxe if let prend un motif et une expression séparés par un signé égal. Elle fonctionne de la même manière qu’un match, où l’expression est donnée au match et le motif est son premier bras. Dans ce cas, le motif est Some(max), et max se lie à la valeur à l’intérieur du Some. Nous pouvons ensuite utiliser max dans le corps du bloc if let de la même manière que nous avons utilisé max dans le bras match correspondant. Le code dans le bloc if let ne s’exécute que si la valeur correspond au motif.
Utiliser if let signifie moins de saisie, moins d’indentation et moins de code passe-partout. Cependant, vous perdez la vérification exhaustive que match impose et qui garantit que vous n’oubliez pas de gérer certains cas. Le choix entre match et if let dépend de ce que vous faites dans votre situation particulière et de savoir si gagner en concision est un compromis approprié par rapport à la perte de la vérification exhaustive.
En d’autres termes, vous pouvez considérer if let comme du sucre syntaxique pour un match qui exécute du code quand la valeur correspond à un motif puis ignore toutes les autres valeurs.
Nous pouvons inclure un else avec un if let. Le bloc de code qui accompagne le else est le même que le bloc de code qui accompagnerait le cas _ dans l’expression match équivalente au if let et else. Rappelons la définition de l’enum Coin dans l’encart 6-4, où la variante Quarter contenait aussi une valeur UsState. Si nous voulions compter toutes les pièces qui ne sont pas des quarters tout en annonçant l’État des quarters, nous pourrions le faire avec une expression match, comme ceci : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-13-count-and-announce-match/src/main.rs:here}}
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn main() {
let coin = Coin::Penny;
let mut count = 0;
match coin {
Coin::Quarter(state) => println!("State quarter from {state:?}!"),
_ => count += 1,
}
}Ou nous pourrions utiliser une expression if let et else, comme ceci : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/no-listing-14-count-and-announce-if-let-else/src/main.rs:here}}
#[derive(Debug)]
enum UsState {
Alabama,
Alaska,
// --snip--
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn main() {
let coin = Coin::Penny;
let mut count = 0;
if let Coin::Quarter(state) = coin {
println!("State quarter from {state:?}!");
} else {
count += 1;
}
}Rester sur le « chemin heureux » avec let...else
Le motif courant consiste à effectuer un calcul lorsqu’une valeur est présente et à renvoyer une valeur par défaut dans le cas contraire. En poursuivant avec notre exemple de pièces avec une valeur UsState, si nous voulions dire quelque chose d’amusant en fonction de l’ancienneté de l’État sur le quarter, nous pourrions introduire une méthode sur UsState pour vérifier l’âge d’un État, comme ceci : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/listing-06-07/src/main.rs:state}}
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
if let Coin::Quarter(state) = coin {
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
} else {
None
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}Ensuite, nous pourrions utiliser if let pour filtrer sur le type de pièce, en introduisant une variable state dans le corps de la condition, comme dans l’encart 6-7.
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
if let Coin::Quarter(state) = coin {
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
} else {
None
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}if letCela fait le travail, mais cela a poussé le travail dans le corps de l’instruction if let, et si le travail à faire est plus complexe, il pourrait être difficile de suivre exactement comment les branches de premier niveau sont liées. Nous pourrions aussi tirer parti du fait que les expressions produisent une valeur soit pour produire state à partir du if let, soit pour retourner prématurément, comme dans l’encart 6-8. (Vous pourriez aussi faire quelque chose de similaire avec un match.)
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
let state = if let Coin::Quarter(state) = coin {
state
} else {
return None;
};
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}if let to produce a value or return earlyC’est cependant un peu pénible à suivre à sa manière ! Une branche du if let produit une valeur, et l’autre retourné entièrement de la fonction.
Pour rendre ce motif courant plus agréable à exprimer, Rust propose let...else. La syntaxe let...else prend un motif à gauche et une expression à droite, de manière très similaire à if let, mais elle n’a pas de branche if, seulement une branche else. Si le motif correspond, la valeur du motif sera liée dans la portée extérieure. Si le motif ne correspond pas, le programme entrera dans le bras else, qui doit retourner de la fonction.
Dans l’encart 6-9, vous pouvez voir à quoi ressemble l’encart 6-8 lorsqu’on utilise let...else à la place de if let.
#[derive(Debug)] // so we can inspect the state in a minute
enum UsState {
Alabama,
Alaska,
// --snip--
}
impl UsState {
fn existed_in(&self, year: u16) -> bool {
match self {
UsState::Alabama => year >= 1819,
UsState::Alaska => year >= 1959,
// -- snip --
}
}
}
enum Coin {
Penny,
Nickel,
Dime,
Quarter(UsState),
}
fn describe_state_quarter(coin: Coin) -> Option<String> {
let Coin::Quarter(state) = coin else {
return None;
};
if state.existed_in(1900) {
Some(format!("{state:?} is pretty old, for America!"))
} else {
Some(format!("{state:?} is relatively new."))
}
}
fn main() {
if let Some(desc) = describe_state_quarter(Coin::Quarter(UsState::Alaska)) {
println!("{desc}");
}
}let...else to clarify the flow through the functionRemarquez que de cette manière, le code reste sur le « chemin heureux » dans le corps principal de la fonction, sans avoir un flux de contrôle significativement différent pour les deux branches comme le faisait le if let.
Si vous avez une situation dans laquelle votre programme à une logique trop verbeuse à exprimer avec un match, rappelez-vous que if let et let...else font aussi partie de votre boîte à outils Rust.
Résumé
Nous avons maintenant vu comment utiliser les enums pour créer des types personnalisés qui peuvent être l’une des valeurs d’un ensemble énuméré. Nous avons montré comment le type Option<T> de la bibliothèque standard vous aide à utiliser le système de types pour prévenir les erreurs. Quand les valeurs d’enum contiennent des données, vous pouvez utiliser match ou if let pour extraire et utiliser ces valeurs, selon le nombre de cas que vous devez gérer.
Vos programmes Rust peuvent maintenant exprimer des concepts de votre domaine en utilisant des structures et des enums. Créer des types personnalisés à utiliser dans votre API garantit la sécurité des types : le compilateur s’assurera que vos fonctions ne reçoivent que des valeurs du type attendu par chaque fonction.
Afin de fournir à vos utilisateurs une API bien organisée, simple à utiliser et qui n’expose que ce dont vos utilisateurs auront besoin, tournons-nous maintenant vers les modules de Rust.
Les packages, les crates et les modules
Au fur et à mesure que vous écrivez des programmes de plus en plus grands, l’organisation de votre code deviendra de plus en plus importante. En regroupant les fonctionnalités associées et en séparant le code selon ses différentes responsabilités, vous clarifierez où trouver le code qui implémente une fonctionnalité particulière et où intervenir pour modifier le comportement d’une fonctionnalité.
Les programmes que nous avons écrits jusqu’à présent se trouvaient dans un seul module dans un seul fichier. À mesure qu’un projet grandit, vous devriez organiser le code en le divisant en plusieurs modules puis en plusieurs fichiers. Un package peut contenir plusieurs crates binaires et éventuellement une crate de bibliothèque. Au fur et à mesure qu’un package grandit, vous pouvez en extraire des parties dans des crates séparées qui deviennent des dépendances externes. Ce chapitre couvre toutes ces techniques. Pour les très grands projets comprenant un ensemble de packages interdépendants qui évoluent ensemble, Cargo fournit les espaces de travail (workspaces), que nous aborderons dans [« Les espaces de travail Cargo »][workspaces] au chapitre 14.
Nous aborderons également l’encapsulation des détails d’implémentation, qui vous permet de réutiliser du code à un niveau plus élevé : une fois que vous avez implémenté une opération, d’autre code peut appeler votre code via son interface publique sans avoir à connaître le fonctionnement de l’implémentation. La façon dont vous écrivez le code définit quelles parties sont publiques pour que d’autre code puisse les utiliser et quelles parties sont des détails d’implémentation privés que vous vous réservez le droit de modifier. C’est une autre façon de limiter la quantité de détails que vous devez garder en tête.
Un concept associé est la portée (scope) : le contexte imbriqué dans lequel le code est écrit possède un ensemble de noms définis comme étant « dans la portée ». Lors de la lecture, de l’écriture et de la compilation du code, les développeurs et les compilateurs doivent savoir si un nom particulier à un endroit particulier fait référence à une variable, une fonction, une struct, une enum, un module, une constante ou un autre élément, et ce que cet élément signifie. Vous pouvez créer des portées et modifier quels noms sont dans ou hors de la portée. Vous ne pouvez pas avoir deux éléments portant le même nom dans la même portée ; des outils sont disponibles pour résoudre les conflits de noms.
Rust dispose d’un certain nombre de fonctionnalités qui vous permettent de gérer l’organisation de votre code, notamment quels détails sont exposés, quels détails sont privés et quels noms se trouvent dans chaque portée de vos programmes. Ces fonctionnalités, parfois collectivement appelées le système de modules, comprennent :
- Les packages : une fonctionnalité de Cargo qui vous permet de compiler, tester et partager des crates
- Les crates : un arbre de modules qui produit une bibliothèque ou un exécutable
- Les modules et
use: vous permettent de contrôler l’organisation, la portée et la confidentialité des chemins - Les chemins (paths) : une façon de nommer un élément, comme une struct, une fonction ou un module
Dans ce chapitre, nous aborderons toutes ces fonctionnalités, discuterons de la façon dont elles interagissent et expliquerons comment les utiliser pour gérer la portée. À la fin, vous devriez avoir une compréhension solide du système de modules et être capable de travailler avec les portées comme un pro !
Les packages et les crates
Les packages et les crates
Les premières parties du système de modules que nous aborderons sont les packages et les crates.
Une crate est la plus petite quantité de code que le compilateur Rust prend en compte à la fois. Même si vous exécutez rustc plutôt que cargo et que vous passez un seul fichier de code source (comme nous l’avons fait au tout début dans [« Les bases d’un programme Rust »][basics] au chapitre 1), le compilateur considère ce fichier comme une crate. Les crates peuvent contenir des modules, et les modules peuvent être définis dans d’autres fichiers qui sont compilés avec la crate, comme nous le verrons dans les sections suivantes.
Une crate peut se présenter sous l’une des deux formes suivantes : une crate binaire ou une crate de bibliothèque. Les crates binaires sont des programmes que vous pouvez compiler en un exécutable que vous pouvez lancer, comme un programme en ligne de commande ou un serveur. Chacune doit avoir une fonction appelée main qui définit ce qui se passe lorsque l’exécutable s’exécute. Toutes les crates que nous avons créées jusqu’à présent étaient des crates binaires.
Les crates de bibliothèque n’ont pas de fonction main et ne se compilent pas en exécutable. À la place, elles définissent des fonctionnalités destinées à être partagées avec plusieurs projets. Par exemple, la crate rand que nous avons utilisée au [chapitre 2][rand] fournit des fonctionnalités qui génèrent des nombres aléatoires. La plupart du temps, quand les Rustacés disent « crate », ils veulent dire crate de bibliothèque, et ils utilisent « crate » de manière interchangeable avec le concept général de programmation de « bibliothèque ».
La racine de la crate (crate root) est un fichier source à partir duquel le compilateur Rust commence et qui constitue le module racine de votre crate (nous expliquerons les modules en détail dans [« Contrôler la portée et la confidentialité avec les modules »][modules]).
Un package est un ensemble d’une où plusieurs crates qui fournit un ensemble de fonctionnalités. Un package contient un fichier Cargo.toml qui décrit comment compiler ces crates. Cargo est en fait un package qui contient la crate binaire pour l’outil en ligne de commande que vous avez utilisé pour compiler votre code. Le package Cargo contient également une crate de bibliothèque dont la crate binaire dépend. D’autres projets peuvent dépendre de la crate de bibliothèque de Cargo pour utiliser la même logique que l’outil en ligne de commande Cargo.
Un package peut contenir autant de crates binaires que vous le souhaitez, mais au maximum une seule crate de bibliothèque. Un package doit contenir au moins une crate, que ce soit une crate de bibliothèque ou une crate binaire.
Voyons ce qui se passe lorsque nous créons un package. Tout d’abord, nous entrons la commande cargo new my-project :
$ cargo new my-project
Created binary (application) `my-project` package
$ ls my-project
Cargo.toml
src
$ ls my-project/src
main.rs
Après avoir exécuté cargo new my-project, nous utilisons ls pour voir ce que Cargo crée. Dans le répertoire my-project, il y à un fichier Cargo.toml, ce qui nous donne un package. Il y a aussi un répertoire src qui contient main.rs. Ouvrez Cargo.toml dans votre éditeur de texte et notez qu’il n’y à aucune mention de src/main.rs. Cargo suit une convention selon laquelle src/main.rs est la racine de la crate binaire portant le même nom que le package. De même, Cargo sait que si le répertoire du package contient src/lib.rs, le package contient une crate de bibliothèque portant le même nom que le package, et src/lib.rs est sa racine de crate. Cargo passe les fichiers racines de crate à rustc pour compiler la bibliothèque ou le binaire.
Ici, nous avons un package qui ne contient que src/main.rs, ce qui signifie qu’il ne contient qu’une crate binaire nommée my-project. Si un package contient src/main.rs et src/lib.rs, il a deux crates : une binaire et une de bibliothèque, toutes deux portant le même nom que le package. Un package peut avoir plusieurs crates binaires en plaçant des fichiers dans le répertoire src/bin : chaque fichier sera une crate binaire distincte.
Contrôler la portée et la visibilité avec les modules
Contrôler la portée et la visibilité avec les modules
Dans cette section, nous parlerons des modules et d’autres parties du système de modules, à savoir les chemins (paths), qui vous permettent de nommer des éléments ; le mot-clé use qui amène un chemin dans la portée ; et le mot-clé pub pour rendre des éléments publics. Nous aborderons également le mot-clé as, les packages externes et l’opérateur glob.
Aide-mémoire des modules
Avant d’entrer dans les détails des modules et des chemins, voici une référence rapide sur le fonctionnement des modules, des chemins, du mot-clé use et du mot-clé pub dans le compilateur, et sur la façon dont la plupart des développeurs organisent leur code. Nous passerons en revue des exemples pour chacune de ces règles tout au long de ce chapitre, mais c’est un excellent endroit auquel se référer pour se rappeler le fonctionnement des modules.
- Commencer par la racine de la crate : lors de la compilation d’une crate, le compilateur cherche d’abord dans le fichier racine de la crate (généralement src/lib.rs pour une crate de bibliothèque et src/main.rs pour une crate binaire) le code à compiler.
- Déclarer des modules : dans le fichier racine de la crate, vous pouvez déclarer de nouveaux modules ; par exemple, vous déclarez un module « garden » avec
mod garden;. Le compilateur cherchera le code du module aux endroits suivants :- En ligne, entre des accolades qui remplacent le point-virgule après
mod garden - Dans le fichier src/garden.rs
- Dans le fichier src/garden/mod.rs
- En ligne, entre des accolades qui remplacent le point-virgule après
- Déclarer des sous-modules : dans tout fichier autre que la racine de la crate, vous pouvez déclarer des sous-modules. Par exemple, vous pourriez déclarer
mod vegetables;dans src/garden.rs. Le compilateur cherchera le code du sous-module dans le répertoire portant le nom du module parent, aux endroits suivants :- En ligne, directement après
mod vegetables, entre des accolades au lieu du point-virgule - Dans le fichier src/garden/vegetables.rs
- Dans le fichier src/garden/vegetables/mod.rs
- En ligne, directement après
- Chemins vers le code dans les modules : une fois qu’un module fait partie de votre crate, vous pouvez faire référence au code de ce module depuis n’importe quel autre endroit de la même crate, tant que les règles de confidentialité le permettent, en utilisant le chemin vers le code. Par exemple, un type
Asparagusdans le module garden vegetables se trouverait àcrate::garden::vegetables::Asparagus. - Privé vs. public : le code au sein d’un module est privé par rapport à ses modules parents par défaut. Pour rendre un module public, déclarez-le avec
pub modau lieu demod. Pour rendre également publics les éléments au sein d’un module public, utilisezpubavant leurs déclarations. - Le mot-clé
use: au sein d’une portée, le mot-cléusecrée des raccourcis vers des éléments pour réduire la répétition de chemins longs. Dans toute portée pouvant faire référence àcrate::garden::vegetables::Asparagus, vous pouvez créer un raccourci avecuse crate::garden::vegetables::Asparagus;, et à partir de là, il vous suffit d’écrireAsparaguspour utiliser ce type dans la portée.
Ici, nous créons une crate binaire nommée backyard qui illustre ces règles. Le répertoire de la crate, également nommé backyard, contient ces fichiers et répertoires :
backyard
├── Cargo.lock
├── Cargo.toml
└── src
├── garden
│ └── vegetables.rs
├── garden.rs
└── main.rs
Le fichier racine de la crate dans ce cas est src/main.rs, et il contient :
use crate::garden::vegetables::Asparagus;
pub mod garden;
fn main() {
let plant = Asparagus {};
println!("I'm growing {plant:?}!");
}La ligne pub mod garden; indique au compilateur d’inclure le code qu’il trouve dans src/garden.rs, qui est :
pub mod vegetables;Ici, pub mod vegetables; signifie que le code dans src/garden/vegetables.rs est également inclus. Ce code est : rust,noplayground,ignore {{#rustdoc_include ../listings/ch07-managing-growing-projects/quick-reference-example/src/garden/vegetables.rs}}
#[derive(Debug)]
pub struct Asparagus {}Maintenant, entrons dans les détails de ces règles et voyons-les en action !
Regrouper le code associé dans des modules
Les modules nous permettent d’organiser le code au sein d’une crate pour la lisibilité et la facilité de réutilisation. Les modules nous permettent également de contrôler la confidentialité des éléments, car le code au sein d’un module est privé par défaut. Les éléments privés sont des détails d’implémentation internes non disponibles pour une utilisation externe. Nous pouvons choisir de rendre les modules et les éléments qu’ils contiennent publics, ce qui les expose pour permettre au code externe de les utiliser et d’en dépendre.
À titre d’exemple, écrivons une crate de bibliothèque qui fournit les fonctionnalités d’un restaurant. Nous définirons les signatures des fonctions mais laisserons leurs corps vides pour nous concentrer sur l’organisation du code plutôt que sur l’implémentation d’un restaurant.
Dans le secteur de la restauration, certaines parties d’un restaurant sont désignées comme la salle (front of house) et d’autres comme les cuisines (back of house). La salle est l’endroit où se trouvent les clients ; cela englobe l’endroit où les hôtes placent les clients, où les serveurs prennent les commandes et les paiements, et où les barmans préparent les boissons. Les cuisines sont l’endroit où les chefs et les cuisiniers travaillent, où les plongeurs nettoient et où les responsables effectuent le travail administratif.
Pour structurer notre crate de cette façon, nous pouvons organiser ses fonctions en modules imbriqués. Créez une nouvelle bibliothèque nommée restaurant en exécutant cargo new restaurant --lib. Ensuite, entrez le code du listing 7-1 dans src/lib.rs pour définir quelques modules et signatures de fonctions ; ce code est la section de la salle.
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
fn seat_at_table() {}
}
mod serving {
fn take_order() {}
fn serve_order() {}
fn take_payment() {}
}
}front_of_house module containing other modules that then contain functionsNous définissons un module avec le mot-clé mod suivi du nom du module (dans ce cas, front_of_house). Le corps du module se place ensuite entre des accolades. À l’intérieur des modules, nous pouvons placer d’autres modules, comme dans ce cas avec les modules hosting et serving. Les modules peuvent également contenir des définitions pour d’autres éléments, tels que des structs, des enums, des constantes, des traits et, comme dans le listing 7-1, des fonctions.
En utilisant des modules, nous pouvons regrouper les définitions associées ensemble et nommer pourquoi elles sont liées. Les développeurs utilisant ce code peuvent naviguer dans le code en se basant sur les groupes plutôt que de devoir lire toutes les définitions, ce qui facilite la recherche des définitions qui les intéressent. Les développeurs ajoutant de nouvelles fonctionnalités à ce code sauraient où placer le code pour garder le programme organisé.
Plus tôt, nous avons mentionné que src/main.rs et src/lib.rs sont appelés racines de crate. La raison de ce nom est que le contenu de l’un où l’autre de ces deux fichiers forme un module nommé crate à la racine de la structure de modules de la crate, connue sous le nom d’arbre de modules.
Le listing 7-2 montre l’arbre de modules pour la structure du listing 7-1.
crate
└── front_of_house
├── hosting
│ ├── add_to_waitlist
│ └── seat_at_table
└── serving
├── take_order
├── serve_order
└── take_payment
Cet arbre montre comment certains modules s’imbriquent dans d’autres modules ; par exemple, hosting s’imbrique dans front_of_house. L’arbre montre également que certains modules sont frères et sœurs (siblings), ce qui signifie qu’ils sont définis dans le même module ; hosting et serving sont des modules frères définis au sein de front_of_house. Si le module A est contenu dans le module B, nous disons que le module A est l’enfant du module B et que le module B est le parent du module A. Notez que l’arbre de modules entier est enraciné sous le module implicite nommé crate.
L’arbre de modules pourrait vous rappeler l’arborescence de répertoires du système de fichiers de votre ordinateur ; c’est une comparaison très pertinente ! Tout comme les répertoires dans un système de fichiers, vous utilisez les modules pour organiser votre code. Et tout comme les fichiers dans un répertoire, nous avons besoin d’un moyen de trouver nos modules.
Les chemins pour désigner un élément dans l’arborescence des modules
Les chemins pour désigner un élément dans l’arborescence des modules
Pour indiquer à Rust où trouver un élément dans un arbre de modules, nous utilisons un chemin de la même manière que nous utilisons un chemin pour naviguer dans un système de fichiers. Pour appeler une fonction, nous devons connaître son chemin.
Un chemin peut prendre deux formes :
- Un chemin absolu est le chemin complet à partir de la racine d’une crate ; pour du code provenant d’une crate externe, le chemin absolu commence par le nom de la crate, et pour du code provenant de la crate courante, il commence par le mot littéral
crate. - Un chemin relatif commence à partir du module courant et utilise
self,superou un identifiant dans le module courant.
Les chemins absolus et relatifs sont suivis d’un où plusieurs identifiants séparés par des doubles deux-points (::).
Revenons au listing 7-1, et supposons que nous voulions appeler la fonction add_to_waitlist. C’est comme demander : quel est le chemin de la fonction add_to_waitlist ? Le listing 7-3 contient le listing 7-1 avec certains modules et fonctions supprimés.
Nous montrerons deux façons d’appeler la fonction add_to_waitlist depuis une nouvelle fonction, eat_at_restaurant, définie à la racine de la crate. Ces chemins sont corrects, mais il reste un autre problème qui empêchera cet exemple de compiler en l’état. Nous expliquerons pourquoi dans un instant.
La fonction eat_at_restaurant fait partie de l’API publique de notre crate de bibliothèque, nous la marquons donc avec le mot-clé pub. Dans la section [« Exposer les chemins avec le mot-clé pub »][pub], nous entrerons plus en détail sur pub.
mod front_of_house {
mod hosting {
fn add_to_waitlist() {}
}
}
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}add_to_waitlist function using absolute and relative pathsLa première fois que nous appelons la fonction add_to_waitlist dans eat_at_restaurant, nous utilisons un chemin absolu. La fonction add_to_waitlist est définie dans la même crate que eat_at_restaurant, ce qui signifie que nous pouvons utiliser le mot-clé crate pour commencer un chemin absolu. Nous incluons ensuite chacun des modules successifs jusqu’à atteindre add_to_waitlist. Vous pouvez imaginer un système de fichiers avec la même structure : nous spécifierions le chemin /front_of_house/hosting/add_to_waitlist pour exécuter le programme add_to_waitlist ; utiliser le nom crate pour partir de la racine de la crate revient à utiliser / pour partir de la racine du système de fichiers dans votre terminal.
La deuxième fois que nous appelons add_to_waitlist dans eat_at_restaurant, nous utilisons un chemin relatif. Le chemin commence par front_of_house, le nom du module défini au même niveau de l’arbre de modules que eat_at_restaurant. Ici, l’équivalent dans le système de fichiers serait d’utiliser le chemin front_of_house/hosting/add_to_waitlist. Commencer par un nom de module signifie que le chemin est relatif.
Choisir d’utiliser un chemin relatif ou absolu est une décision que vous prendrez en fonction de votre projet, et cela dépend de la probabilité que vous déplaciez le code de définition de l’élément séparément ou ensemble avec le code qui utilise l’élément. Par exemple, si nous déplacions le module front_of_house et la fonction eat_at_restaurant dans un module nommé customer_experience, nous devrions mettre à jour le chemin absolu vers add_to_waitlist, mais le chemin relatif serait toujours valide. En revanche, si nous déplacions la fonction eat_at_restaurant séparément dans un module nommé dining, le chemin absolu vers l’appel add_to_waitlist resterait le même, mais le chemin relatif devrait être mis à jour. Notre préférence en général est de spécifier des chemins absolus, car il est plus probable que nous voudrons déplacer les définitions de code et les appels d’éléments indépendamment les uns des autres.
Essayons de compiler le listing 7-3 et découvrons pourquoi il ne compilé pas encore ! Les erreurs que nous obtenons sont présentées dans le listing 7-4.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: module `hosting` is private
--> src/lib.rs:9:28
|
9 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
error[E0603]: module `hosting` is private
--> src/lib.rs:12:21
|
12 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^ --------------- function `add_to_waitlist` is not publicly re-exported
| |
| private module
|
note: the module `hosting` is defined here
--> src/lib.rs:2:5
|
2 | mod hosting {
| ^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
Les messages d’erreur indiquent que le module hosting est privé. En d’autres termes, nous avons les chemins corrects pour le module hosting et la fonction add_to_waitlist, mais Rust ne nous permet pas de les utiliser car il n’a pas accès aux sections privées. En Rust, tous les éléments (fonctions, méthodes, structs, enums, modules et constantes) sont privés par rapport aux modules parents par défaut. Si vous voulez rendre un élément comme une fonction ou une struct privé, vous le placez dans un module.
Les éléments d’un module parent ne peuvent pas utiliser les éléments privés à l’intérieur des modules enfants, mais les éléments des modules enfants peuvent utiliser les éléments de leurs modules ancêtres. C’est parce que les modules enfants enveloppent et cachent leurs détails d’implémentation, mais les modules enfants peuvent voir le contexte dans lequel ils sont définis. Pour continuer avec notre métaphore, pensez aux règles de confidentialité comme au bureau de direction d’un restaurant : ce qui s’y passe est privé pour les clients du restaurant, mais les responsables peuvent voir et faire tout dans le restaurant qu’ils gèrent.
Rust a choisi de faire fonctionner le système de modules de cette manière afin que masquer les détails d’implémentation internes soit le comportement par défaut. De cette façon, vous savez quelles parties du code interne vous pouvez modifier sans casser le code externe. Cependant, Rust vous donne la possibilité d’exposer les parties internes du code des modules enfants aux modules ancêtres externes en utilisant le mot-clé pub pour rendre un élément public.
Exposer les chemins avec le mot-clé pub
Revenons à l’erreur du listing 7-4 qui nous indiquait que le module hosting est privé. Nous voulons que la fonction eat_at_restaurant dans le module parent ait accès à la fonction add_to_waitlist dans le module enfant, donc nous marquons le module hosting avec le mot-clé pub, comme montré dans le listing 7-5.
mod front_of_house {
pub mod hosting {
fn add_to_waitlist() {}
}
}
// -- snip --
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}hosting module as pub to use it from eat_at_restaurantMalheureusement, le code du listing 7-5 produit toujours des erreurs de compilation, comme montré dans le listing 7-6.
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:10:37
|
10 | crate::front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
error[E0603]: function `add_to_waitlist` is private
--> src/lib.rs:13:30
|
13 | front_of_house::hosting::add_to_waitlist();
| ^^^^^^^^^^^^^^^ private function
|
note: the function `add_to_waitlist` is defined here
--> src/lib.rs:3:9
|
3 | fn add_to_waitlist() {}
| ^^^^^^^^^^^^^^^^^^^^
For more information about this error, try `rustc --explain E0603`.
error: could not compile `restaurant` (lib) due to 2 previous errors
Que s’est-il passé ? Ajouter le mot-clé pub devant mod hosting rend le module public. Avec ce changement, si nous pouvons accéder à front_of_house, nous pouvons accéder à hosting. Mais le contenu de hosting est toujours privé ; rendre le module public ne rend pas son contenu public. Le mot-clé pub sur un module permet uniquement au code de ses modules ancêtres de s’y référer, pas d’accéder à son code interne. Puisque les modules sont des conteneurs, nous ne pouvons pas faire grand-chose en rendant uniquement le module public ; nous devons aller plus loin et choisir de rendre un où plusieurs des éléments du module publics également.
Les erreurs du listing 7-6 indiquent que la fonction add_to_waitlist est privée. Les règles de confidentialité s’appliquent aux structs, enums, fonctions et méthodes ainsi qu’aux modules.
Rendons également la fonction add_to_waitlist publique en ajoutant le mot-clé pub avant sa définition, comme dans le listing 7-7.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
// -- snip --
pub fn eat_at_restaurant() {
// Absolute path
crate::front_of_house::hosting::add_to_waitlist();
// Relative path
front_of_house::hosting::add_to_waitlist();
}pub keyword to mod hosting and fn add_to_waitlist lets us call the function from eat_at_restaurant.Maintenant le code va compiler ! Pour comprendre pourquoi l’ajout du mot-clé pub nous permet d’utiliser ces chemins dans eat_at_restaurant conformément aux règles de confidentialité, examinons les chemins absolus et relatifs.
Dans le chemin absolu, nous commençons par crate, la racine de l’arbre de modules de notre crate. Le module front_of_house est défini à la racine de la crate. Bien que front_of_house ne soit pas public, comme la fonction eat_at_restaurant est définie dans le même module que front_of_house (c’est-à-dire que eat_at_restaurant et front_of_house sont frères), nous pouvons faire référence à front_of_house depuis eat_at_restaurant. Ensuite vient le module hosting marqué avec pub. Nous pouvons accéder au module parent de hosting, donc nous pouvons accéder à hosting. Enfin, la fonction add_to_waitlist est marquée avec pub, et nous pouvons accéder à son module parent, donc cet appel de fonction fonctionne !
Dans le chemin relatif, la logique est la même que pour le chemin absolu sauf pour la première étape : plutôt que de commencer à la racine de la crate, le chemin commence à partir de front_of_house. Le module front_of_house est défini dans le même module que eat_at_restaurant, donc le chemin relatif commençant depuis le module dans lequel eat_at_restaurant est défini fonctionne. Ensuite, puisque hosting et add_to_waitlist sont marqués avec pub, le reste du chemin fonctionne, et cet appel de fonction est valide !
Si vous prévoyez de partager votre crate de bibliothèque pour que d’autres projets puissent utiliser votre code, votre API publique est votre contrat avec les utilisateurs de votre crate qui détermine comment ils peuvent interagir avec votre code. Il y a de nombreuses considérations autour de la gestion des modifications de votre API publique pour faciliter la dépendance des gens envers votre crate. Ces considérations dépassent le cadre de ce livre ; si vous êtes intéressé par ce sujet, consultez [les directives de l’API Rust][api-guidelines].
Bonnes pratiques pour les packages avec un binaire et une bibliothèque
Nous avons mentionné qu’un package peut contenir à la fois une racine de crate binaire src/main.rs et une racine de crate de bibliothèque src/lib.rs, et les deux crates porteront le nom du package par défaut. Typiquement, les packages suivant ce schéma de contenir à la fois une crate de bibliothèque et une crate binaire auront juste assez de code dans la crate binaire pour démarrer un exécutable qui appelle du code défini dans la crate de bibliothèque. Cela permet à d’autres projets de bénéficier du maximum de fonctionnalités que le package fournit, car le code de la crate de bibliothèque peut être partagé.
L’arbre de modules devrait être défini dans src/lib.rs. Ensuite, tous les éléments publics peuvent être utilisés dans la crate binaire en commençant les chemins par le nom du package. La crate binaire devient un utilisateur de la crate de bibliothèque, tout comme une crate complètement externe utiliserait la crate de bibliothèque : elle ne peut utiliser que l’API publique. Cela vous aide à concevoir une bonne API ; vous n’êtes pas seulement l’auteur, mais aussi un client !
Au chapitre 12, nous démontrerons cette pratique d’organisation avec un programme en ligne de commande qui contiendra à la fois une crate binaire et une crate de bibliothèque.
Commencer les chemins relatifs avec super
Nous pouvons construire des chemins relatifs qui commencent dans le module parent, plutôt que dans le module courant ou la racine de la crate, en utilisant super au début du chemin. C’est comme commencer un chemin de système de fichiers avec la syntaxe .. qui signifie aller au répertoire parent. Utiliser super nous permet de faire référence à un élément que nous savons être dans le module parent, ce qui peut faciliter la réorganisation de l’arbre de modules lorsque le module est étroitement lié au parent mais que le parent pourrait être déplacé ailleurs dans l’arbre de modules un jour.
Considérons le code du listing 7-8 qui modélise la situation dans laquelle un chef corrige une commande incorrecte et l’apporte personnellement au client. La fonction fix_incorrect_order définie dans le module back_of_house appelle la fonction deliver_order définie dans le module parent en spécifiant le chemin vers deliver_order, en commençant par super.
fn deliver_order() {}
mod back_of_house {
fn fix_incorrect_order() {
cook_order();
super::deliver_order();
}
fn cook_order() {}
}superLa fonction fix_incorrect_order se trouve dans le module back_of_house, donc nous pouvons utiliser super pour aller au module parent de back_of_house, qui dans ce cas est crate, la racine. De là, nous cherchons deliver_order et le trouvons. Succès ! Nous pensons que le module back_of_house et la fonction deliver_order sont susceptibles de rester dans la même relation l’un avec l’autre et d’être déplacés ensemble si nous décidons de réorganiser l’arbre de modules de la crate. Par conséquent, nous avons utilisé super afin d’avoir moins d’endroits où mettre à jour le code à l’avenir si ce code est déplacé vers un autre module.
Rendre les structs et les enums publics
Nous pouvons également utiliser pub pour désigner les structs et les enums comme publics, mais il y à quelques détails supplémentaires concernant l’utilisation de pub avec les structs et les enums. Si nous utilisons pub avant une définition de struct, nous rendons la struct publique, mais les champs de la struct resteront privés. Nous pouvons rendre chaque champ public ou non au cas par cas. Dans le listing 7-9, nous avons défini une struct publique back_of_house::Breakfast avec un champ public toast mais un champ privé seasonal_fruit. Cela modélise le cas d’un restaurant où le client peut choisir le type de pain qui accompagne un repas, mais le chef décide quel fruit accompagne le repas en fonction de ce qui est de saison et en stock. Les fruits disponibles changent rapidement, donc les clients ne peuvent pas choisir le fruit ni même voir quel fruit ils recevront.
mod back_of_house {
pub struct Breakfast {
pub toast: String,
seasonal_fruit: String,
}
impl Breakfast {
pub fn summer(toast: &str) -> Breakfast {
Breakfast {
toast: String::from(toast),
seasonal_fruit: String::from("peaches"),
}
}
}
}
pub fn eat_at_restaurant() {
// Order a breakfast in the summer with Rye toast.
let mut meal = back_of_house::Breakfast::summer("Rye");
// Change our mind about what bread we'd like.
meal.toast = String::from("Wheat");
println!("I'd like {} toast please", meal.toast);
// The next line won't compilé if we uncomment it; we're not allowed
// to see or modify the seasonal fruit that comes with the meal.
// meal.seasonal_fruit = String::from("blueberries");
}Puisque le champ toast de la struct back_of_house::Breakfast est public, dans eat_at_restaurant nous pouvons écrire et lire le champ toast en utilisant la notation avec point. Remarquez que nous ne pouvons pas utiliser le champ seasonal_fruit dans eat_at_restaurant, car seasonal_fruit est privé. Essayez de décommenter la ligne modifiant la valeur du champ seasonal_fruit pour voir quelle erreur vous obtenez !
Notez également que, puisque back_of_house::Breakfast à un champ privé, la struct doit fournir une fonction associée publique qui construit une instance de Breakfast (nous l’avons nommée summer ici). Si Breakfast n’avait pas une telle fonction, nous ne pourrions pas créer une instance de Breakfast dans eat_at_restaurant, car nous ne pourrions pas définir la valeur du champ privé seasonal_fruit dans eat_at_restaurant.
En revanche, si nous rendons une enum publique, tous ses variants sont alors publics. Nous n’avons besoin du pub que devant le mot-clé enum, comme montré dans le listing 7-10.
mod back_of_house {
pub enum Appetizer {
Soup,
Salad,
}
}
pub fn eat_at_restaurant() {
let order1 = back_of_house::Appetizer::Soup;
let order2 = back_of_house::Appetizer::Salad;
}Puisque nous avons rendu l’enum Appetizer publique, nous pouvons utiliser les variants Soup et Salad dans eat_at_restaurant.
Les enums ne sont pas très utiles à moins que leurs variants soient publics ; il serait pénible de devoir annoter tous les variants d’enum avec pub dans chaque cas, donc le comportement par défaut pour les variants d’enum est d’être publics. Les structs sont souvent utiles sans que leurs champs soient publics, donc les champs de struct suivent la règle générale selon laquelle tout est privé par défaut sauf annotation avec pub.
Il y à une dernière situation impliquant pub que nous n’avons pas couverte, et c’est notre dernière fonctionnalité du système de modules : le mot-clé use. Nous couvrirons d’abord use seul, puis nous montrerons comment combiner pub et use.
Importer des chemins dans la portée avec le mot-clé use
Amener des chemins dans la portée avec le mot-clé use
Devoir écrire les chemins pour appeler des fonctions peut sembler peu pratique et répétitif. Dans le listing 7-7, que nous ayons choisi le chemin absolu ou relatif vers la fonction add_to_waitlist, chaque fois que nous voulions appeler add_to_waitlist, nous devions aussi spécifier front_of_house et hosting. Heureusement, il existe un moyen de simplifier ce processus : nous pouvons créer un raccourci vers un chemin avec le mot-clé use une seule fois, puis utiliser le nom plus court partout ailleurs dans la portée.
Dans le listing 7-11, nous amenons le module crate::front_of_house::hosting dans la portée de la fonction eat_at_restaurant afin de n’avoir qu’à spécifier hosting::add_to_waitlist pour appeler la fonction add_to_waitlist dans eat_at_restaurant.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}useAjouter use et un chemin dans une portée est similaire à la création d’un lien symbolique dans le système de fichiers. En ajoutant use crate::front_of_house::hosting à la racine de la crate, hosting est désormais un nom valide dans cette portée, comme si le module hosting avait été défini à la racine de la crate. Les chemins amenés dans la portée avec use vérifient également la confidentialité, comme tout autre chemin.
Notez que use ne crée le raccourci que pour la portée particulière dans laquelle le use se trouve. Le listing 7-12 déplace la fonction eat_at_restaurant dans un nouveau module enfant nommé customer, qui est alors une portée différente de celle de l’instruction use, donc le corps de la fonction ne compilera pas.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting;
mod customer {
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}
}use statement only applies in the scope it’s in.L’erreur du compilateur montre que le raccourci ne s’applique plus au sein du module customer : console {{#include ../listings/ch07-managing-growing-projects/listing-07-12/output.txt}}
$ cargo build
Compiling restaurant v0.1.0 (file:///projects/restaurant)
error[E0433]: failed to resolve: use of unresolved module or unlinked crate `hosting`
--> src/lib.rs:11:9
|
11 | hosting::add_to_waitlist();
| ^^^^^^^ use of unresolved module or unlinked crate `hosting`
|
= help: if you wanted to use a crate named `hosting`, use `cargo add hosting` to add it to your `Cargo.toml`
help: consider importing this module through its public re-export
|
10 + use crate::hosting;
|
warning: unused import: `crate::front_of_house::hosting`
--> src/lib.rs:7:5
|
7 | use crate::front_of_house::hosting;
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: `#[warn(unused_imports)]` on by default
For more information about this error, try `rustc --explain E0433`.
warning: `restaurant` (lib) generated 1 warning
error: could not compile `restaurant` (lib) due to 1 previous error; 1 warning emitted
Remarquez qu’il y a aussi un avertissement indiquant que le use n’est plus utilisé dans sa portée ! Pour corriger ce problème, déplacez le use dans le module customer également, ou faites référence au raccourci du module parent avec super::hosting dans le module enfant customer.
Créer des chemins use idiomatiques
Dans le listing 7-11, vous vous êtes peut-être demandé pourquoi nous avons spécifié use crate::front_of_house::hosting puis appelé hosting::add_to_waitlist dans eat_at_restaurant, plutôt que de spécifier le chemin use jusqu’à la fonction add_to_waitlist pour obtenir le même résultat, comme dans le listing 7-13.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
use crate::front_of_house::hosting::add_to_waitlist;
pub fn eat_at_restaurant() {
add_to_waitlist();
}add_to_waitlist function into scope with use, which is unidiomaticBien que le listing 7-11 et le listing 7-13 accomplissent la même tâche, le listing 7-11 est la manière idiomatique d’amener une fonction dans la portée avec use. Amener le module parent de la fonction dans la portée avec use signifie que nous devons spécifier le module parent lors de l’appel de la fonction. Spécifier le module parent lors de l’appel de la fonction rend clair que la fonction n’est pas définie localement tout en minimisant la répétition du chemin complet. Le code du listing 7-13 ne permet pas de savoir clairement où add_to_waitlist est défini.
D’un autre côté, lorsqu’on amène des structs, des enums et d’autres éléments avec use, il est idiomatique de spécifier le chemin complet. Le listing 7-14 montre la manière idiomatique d’amener la struct HashMap de la bibliothèque standard dans la portée d’une crate binaire.
use std::collections::HashMap;
fn main() {
let mut map = HashMap::new();
map.insert(1, 2);
}HashMap into scope in an idiomatic wayIl n’y a pas de raison forte derrière cet idiome : c’est simplement la convention qui a émergé, et les gens se sont habitués à lire et écrire du code Rust de cette manière.
L’exception à cet idiome est lorsque nous amenons deux éléments portant le même nom dans la portée avec des instructions use, car Rust ne le permet pas. Le listing 7-15 montre comment amener deux types Result dans la portée qui ont le même nom mais des modules parents différents, et comment s’y référer.
use std::fmt;
use std::io;
fn function1() -> fmt::Result {
// --snip--
Ok(())
}
fn function2() -> io::Result<()> {
// --snip--
Ok(())
}Comme vous pouvez le voir, utiliser les modules parents permet de distinguer les deux types Result. Si au contraire nous avions spécifié use std::fmt::Result et use std::io::Result, nous aurions deux types Result dans la même portée, et Rust ne saurait pas lequel nous voulions dire quand nous utiliserions Result.
Fournir de nouveaux noms avec le mot-clé as
Il existe une autre solution au problème d’amener deux types portant le même nom dans la même portée avec use : après le chemin, nous pouvons spécifier as et un nouveau nom local, ou alias, pour le type. Le listing 7-16 montre une autre façon d’écrire le code du listing 7-15 en renommant l’un des deux types Result en utilisant as.
use std::fmt::Result;
use std::io::Result as IoResult;
fn function1() -> Result {
// --snip--
Ok(())
}
fn function2() -> IoResult<()> {
// --snip--
Ok(())
}as keywordDans la deuxième instruction use, nous avons choisi le nouveau nom IoResult pour le type std::io::Result, qui n’entrera pas en conflit avec le Result de std::fmt que nous avons également amené dans la portée. Le listing 7-15 et le listing 7-16 sont considérés comme idiomatiques, donc le choix vous appartient !
Réexporter des noms avec pub use
Lorsque nous amenons un nom dans la portée avec le mot-clé use, le nom est privé à la portée dans laquelle nous l’avons importé. Pour permettre au code en dehors de cette portée de se référer à ce nom comme s’il avait été défini dans cette portée, nous pouvons combiner pub et use. Cette technique s’appelle la réexportation (re-exporting) parce que nous amenons un élément dans la portée mais le rendons également disponible pour que d’autres puissent l’amener dans leur portée.
Le listing 7-17 montre le code du listing 7-11 avec use dans le module racine changé en pub use.
mod front_of_house {
pub mod hosting {
pub fn add_to_waitlist() {}
}
}
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}pub useAvant ce changement, le code externe aurait dû appeler la fonction add_to_waitlist en utilisant le chemin restaurant::front_of_house::hosting::add_to_waitlist(), ce qui aurait également nécessité que le module front_of_house soit marqué comme pub. Maintenant que ce pub use a réexporté le module hosting depuis le module racine, le code externe peut utiliser le chemin restaurant::hosting::add_to_waitlist() à la place.
La réexportation est utile lorsque la structure interne de votre code est différente de la façon dont les développeurs appelant votre code penseraient au domaine. Par exemple, dans cette métaphore du restaurant, les personnes qui gèrent le restaurant pensent en termes de « salle » et « cuisines ». Mais les clients visitant un restaurant ne penseront probablement pas aux parties du restaurant en ces termes. Avec pub use, nous pouvons écrire notre code avec une structure mais en exposer une différente. Ce faisant, notre bibliothèque est bien organisée à la fois pour les développeurs travaillant sur la bibliothèque et ceux qui l’utilisent. Nous verrons un autre exemple de pub use et comment cela affecte la documentation de votre crate dans [« Exporter une API publique pratique »][ch14-pub-use] au chapitre 14.
Utiliser des packages externes
Au chapitre 2, nous avons programmé un projet de jeu de devinettes qui utilisait un package externe appelé rand pour obtenir des nombres aléatoires. Pour utiliser rand dans notre projet, nous avons ajouté cette ligne à Cargo.toml :
rand = "0.8.5"
Ajouter rand comme dépendance dans Cargo.toml indique à Cargo de télécharger le package rand et toutes ses dépendances depuis crates.io et de rendre rand disponible pour notre projet.
Ensuite, pour amener les définitions de rand dans la portée de notre package, nous avons ajouté une ligne use commençant par le nom de la crate, rand, et listé les éléments que nous voulions amener dans la portée. Rappelons que dans [« Générer un nombre aléatoire »][rand] au chapitre 2, nous avons amené le trait Rng dans la portée et appelé la fonction rand::thread_rng : rust,ignore {{#rustdoc_include ../listings/ch02-guessing-game-tutorial/listing-02-03/src/main.rs:ch07-04}}
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
}Les membres de la communauté Rust ont rendu de nombreux packages disponibles sur crates.io, et intégrer n’importe lequel d’entre eux dans votre package implique les mêmes étapes : les lister dans le fichier Cargo.toml de votre package et utiliser use pour amener les éléments de leurs crates dans la portée.
Notez que la bibliothèque standard std est également une crate externe à notre package. Comme la bibliothèque standard est livrée avec le langage Rust, nous n’avons pas besoin de modifier Cargo.toml pour inclure std. Mais nous devons nous y référer avec use pour amener les éléments dans la portée de notre package. Par exemple, pour HashMap, nous utiliserions cette ligne :
#![allow(unused)]
fn main() {
use std::collections::HashMap;
}C’est un chemin absolu commençant par std, le nom de la crate de la bibliothèque standard.
Utiliser des chemins imbriqués pour nettoyer les listes use
Si nous utilisons plusieurs éléments définis dans la même crate ou le même module, lister chaque élément sur sa propre ligne peut prendre beaucoup d’espace vertical dans nos fichiers. Par exemple, ces deux instructions use que nous avions dans le jeu de devinettes du listing 2-4 amènent des éléments de std dans la portée :
use rand::Rng;
// --snip--
use std::cmp::Ordering;
use std::io;
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}À la place, nous pouvons utiliser des chemins imbriqués pour amener les mêmes éléments dans la portée en une seule ligne. Nous faisons cela en spécifiant la partie commune du chemin, suivie de deux deux-points, puis des accolades autour d’une liste des parties des chemins qui diffèrent, comme montré dans le listing 7-18.
use rand::Rng;
// --snip--
use std::{cmp::Ordering, io};
// --snip--
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = guess.trim().parse().expect("Please type a number!");
println!("You guessed: {guess}");
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => println!("You win!"),
}
}Dans des programmes plus grands, amener de nombreux éléments dans la portée depuis la même crate ou le même module en utilisant des chemins imbriqués peut réduire considérablement le nombre d’instructions use séparées nécessaires !
Nous pouvons utiliser un chemin imbriqué à n’importe quel niveau d’un chemin, ce qui est utile lorsqu’on combine deux instructions use qui partagent un sous-chemin. Par exemple, le listing 7-19 montre deux instructions use : une qui amène std::io dans la portée et une qui amène std::io::Write dans la portée.
use std::io;
use std::io::Write;use statements where one is a subpath of the otherLa partie commune de ces deux chemins est std::io, et c’est le premier chemin complet. Pour fusionner ces deux chemins en une seule instruction use, nous pouvons utiliser self dans le chemin imbriqué, comme montré dans le listing 7-20.
use std::io::{self, Write};use statementCette ligne amène std::io et std::io::Write dans la portée.
Importer des éléments avec l’opérateur glob
Si nous voulons amener tous les éléments publics définis dans un chemin dans la portée, nous pouvons spécifier ce chemin suivi de l’opérateur glob * :
#![allow(unused)]
fn main() {
use std::collections::*;
}Cette instruction use amène tous les éléments publics définis dans std::collections dans la portée courante. Soyez prudent lorsque vous utilisez l’opérateur glob ! Glob peut rendre plus difficile de savoir quels noms sont dans la portée et où un nom utilisé dans votre programme a été défini. De plus, si la dépendance modifié ses définitions, ce que vous avez importé change également, ce qui peut entraîner des erreurs de compilation lorsque vous mettez à jour la dépendance si celle-ci ajouté par exemple une définition portant le même nom qu’une de vos définitions dans la même portée.
L’opérateur glob est souvent utilisé lors des tests pour amener tout ce qui est testé dans le module tests ; nous en parlerons dans [« Comment écrire des tests »][writing-tests] au chapitre 11. L’opérateur glob est aussi parfois utilisé dans le cadre du patron prelude : consultez la documentation de la bibliothèque standard pour plus d’informations sur ce patron.
Séparer les modules dans différents fichiers
Séparer les modules dans différents fichiers
Jusqu’à présent, tous les exemples de ce chapitre définissaient plusieurs modules dans un seul fichier. Lorsque les modules deviennent volumineux, vous pourriez vouloir déplacer leurs définitions dans un fichier séparé pour rendre le code plus facile à naviguer.
Par exemple, partons du code du listing 7-17 qui avait plusieurs modules de restaurant. Nous allons extraire les modules dans des fichiers au lieu d’avoir tous les modules définis dans le fichier racine de la crate. Dans ce cas, le fichier racine de la crate est src/lib.rs, mais cette procédure fonctionne aussi avec les crates binaires dont le fichier racine est src/main.rs.
Tout d’abord, nous allons extraire le module front_of_house dans son propre fichier. Supprimez le code à l’intérieur des accolades du module front_of_house, en ne laissant que la déclaration mod front_of_house;, de sorte que src/lib.rs contienne le code montré dans le listing 7-21. Notez que cela ne compilera pas tant que nous n’aurons pas créé le fichier src/front_of_house.rs dans le listing 7-22.
mod front_of_house;
pub use crate::front_of_house::hosting;
pub fn eat_at_restaurant() {
hosting::add_to_waitlist();
}front_of_house module whose body will be in src/front_of_house.rsEnsuite, placez le code qui se trouvait entre les accolades dans un nouveau fichier nommé src/front_of_house.rs, comme montré dans le listing 7-22. Le compilateur sait qu’il doit chercher dans ce fichier car il a rencontré la déclaration de module dans la racine de la crate avec le nom front_of_house.
pub mod hosting {
pub fn add_to_waitlist() {}
}front_of_house module in src/front_of_house.rsNotez que vous n’avez besoin de charger un fichier avec une déclaration mod qu’une seule fois dans votre arbre de modules. Une fois que le compilateur sait que le fichier fait partie du projet (et sait où dans l’arbre de modules le code réside grâce à l’endroit où vous avez placé l’instruction mod), les autres fichiers de votre projet doivent faire référence au code du fichier chargé en utilisant un chemin vers l’endroit où il a été déclaré, comme couvert dans la section [« Les chemins pour faire référence à un élément dans l’arbre de modules »][paths]. En d’autres termes, mod n’est pas une opération « include » que vous avez peut-être vue dans d’autres langages de programmation.
Ensuite, nous allons extraire le module hosting dans son propre fichier. Le processus est un peu différent car hosting est un module enfant de front_of_house, et non du module racine. Nous placerons le fichier pour hosting dans un nouveau répertoire qui sera nommé d’après ses ancêtres dans l’arbre de modules, dans ce cas src/front_of_house.
Pour commencer à déplacer hosting, nous modifions src/front_of_house.rs pour qu’il ne contienne que la déclaration du module hosting :
pub mod hosting;Ensuite, nous créons un répertoire src/front_of_house et un fichier hosting.rs pour contenir les définitions faites dans le module hosting :
pub fn add_to_waitlist() {}Si au contraire nous placions hosting.rs dans le répertoire src, le compilateur s’attendrait à ce que le code de hosting.rs soit dans un module hosting déclaré à la racine de la crate et non déclaré comme enfant du module front_of_house. Les règles du compilateur concernant les fichiers à vérifier pour le code de chaque module font que les répertoires et les fichiers correspondent plus étroitement à l’arbre de modules.
Chemins de fichiers alternatifs
Jusqu’ici, nous avons couvert les chemins de fichiers les plus idiomatiques que le compilateur Rust utilise, mais Rust prend aussi en charge un ancien style de chemin de fichier. Pour un module nommé front_of_house déclaré à la racine de la crate, le compilateur cherchera le code du module dans :
- src/front_of_house.rs (ce que nous avons couvert)
- src/front_of_house/mod.rs (ancien style, chemin toujours pris en charge)
Pour un module nommé hosting qui est un sous-module de front_of_house, le compilateur cherchera le code du module dans :
- src/front_of_house/hosting.rs (ce que nous avons couvert)
- src/front_of_house/hosting/mod.rs (ancien style, chemin toujours pris en charge)
Si vous utilisez les deux styles pour le même module, vous obtiendrez une erreur de compilation. Utiliser un mélange des deux styles pour différents modules dans le même projet est autorisé mais pourrait être déroutant pour les personnes naviguant dans votre projet.
Le principal inconvénient du style utilisant des fichiers nommés mod.rs est que votre projet peut se retrouver avec de nombreux fichiers nommés mod.rs, ce qui peut prêter à confusion lorsque vous les avez ouverts en même temps dans votre éditeur.
Nous avons déplacé le code de chaque module dans un fichier séparé, et l’arbre de modules reste le même. Les appels de fonction dans eat_at_restaurant fonctionneront sans aucune modification, même si les définitions se trouvent dans des fichiers différents. Cette technique vous permet de déplacer les modules vers de nouveaux fichiers à mesure qu’ils grandissent en taille.
Notez que l’instruction pub use crate::front_of_house::hosting dans src/lib.rs n’a pas changé non plus, et use n’à aucun impact sur les fichiers qui sont compilés en tant que partie de la crate. Le mot-clé mod déclare les modules, et Rust cherche dans un fichier portant le même nom que le module le code qui va dans ce module.
Résumé
Rust vous permet de diviser un package en plusieurs crates et une crate en modules afin que vous puissiez faire référence à des éléments définis dans un module depuis un autre module. Vous pouvez le faire en spécifiant des chemins absolus ou relatifs. Ces chemins peuvent être amenés dans la portée avec une instruction use afin que vous puissiez utiliser un chemin plus court pour plusieurs utilisations de l’élément dans cette portée. Le code des modules est privé par défaut, mais vous pouvez rendre les définitions publiques en ajoutant le mot-clé pub.
Dans le prochain chapitre, nous examinerons quelques structures de données de collections dans la bibliothèque standard que vous pouvez utiliser dans votre code bien organisé.
Les collections courantes
La bibliothèque standard de Rust comprend un certain nombre de structures de données très utiles appelées collections. La plupart des autres types de données représentent une valeur spécifique, mais les collections peuvent contenir plusieurs valeurs. Contrairement aux types tableau et tuple intégrés, les données vers lesquelles ces collections pointent sont stockées sur le tas, ce qui signifie que la quantité de données n’a pas besoin d’être connue à la compilation et peut augmenter ou diminuer pendant l’exécution du programme. Chaque type de collection à des capacités et des coûts différents, et choisir celui qui convient à votre situation actuelle est une compétence que vous développerez avec le temps. Dans ce chapitre, nous allons aborder trois collections qui sont très fréquemment utilisées dans les programmes Rust :
- Un vector vous permet de stocker un nombre variable de valeurs les unes à côté des autres.
- Une string (chaîne de caractères) est une collection de caractères. Nous avons mentionné le type
Stringprécédemment, mais dans ce chapitre, nous en parlerons en profondeur. - Une hash map (table de hachage) vous permet d’associer une valeur à une clé spécifique. C’est une implémentation particulière de la structure de données plus générale appelée map (tableau associatif).
Pour en savoir plus sur les autres types de collections fournies par la bibliothèque standard, consultez [la documentation][collections].
Nous verrons comment créer et mettre à jour des vectors, des strings et des hash maps, ainsi que ce qui rend chacune d’entre elles spéciale.
Stocker des listes de valeurs avec les vecteurs
Stocker des listes de valeurs avec les vecteurs
Le premier type de collection que nous allons examiner est Vec<T>, également appelé vector. Les vectors vous permettent de stocker plus d’une valeur dans une seule structure de données qui place toutes les valeurs les unes à côté des autres en mémoire. Les vectors ne peuvent stocker que des valeurs du même type. Ils sont utiles lorsque vous avez une liste d’éléments, comme les lignes de texte dans un fichier ou les prix des articles dans un panier.
Créer un nouveau vector
Pour créer un nouveau vector vide, nous appelons la fonction Vec::new, comme montré dans l’encart 8-1.
fn main() {
let v: Vec<i32> = Vec::new();
}i32Notez que nous avons ajouté une annotation de type ici. Comme nous n’insérons aucune valeur dans ce vector, Rust ne sait pas quel type d’éléments nous avons l’intention de stocker. C’est un point important. Les vectors sont implémentés à l’aide de la généricité ; nous verrons comment utiliser la généricité avec vos propres types au chapitre 10. Pour l’instant, sachez que le type Vec<T> fourni par la bibliothèque standard peut contenir n’importe quel type. Quand nous créons un vector pour contenir un type spécifique, nous pouvons préciser le type entre chevrons. Dans l’encart 8-1, nous avons indiqué à Rust que le Vec<T> dans v contiendra des éléments de type i32.
Le plus souvent, vous créerez un Vec<T> avec des valeurs initiales, et Rust déduira le type de valeur que vous souhaitez stocker, de sorte que vous avez rarement besoin de faire cette annotation de type. Rust fournit la macro vec! pour plus de commodité, qui crée un nouveau vector contenant les valeurs que vous lui donnez. L’encart 8-2 crée un nouveau Vec<i32> qui contient les valeurs 1, 2 et 3. Le type entier est i32 car c’est le type entier par défaut, comme nous l’avons vu dans la section [“Types de données”][data-types] du chapitre 3.
fn main() {
let v = vec![1, 2, 3];
}Comme nous avons donné des valeurs i32 initiales, Rust peut déduire que le type de v est Vec<i32>, et l’annotation de type n’est pas nécessaire. Voyons maintenant comment modifier un vector.
Mettre à jour un vector
Pour créer un vector puis y ajouter des éléments, nous pouvons utiliser la méthode push, comme montré dans l’encart 8-3.
fn main() {
let mut v = Vec::new();
v.push(5);
v.push(6);
v.push(7);
v.push(8);
}push method to add values to a vectorComme pour toute variable, si nous voulons pouvoir modifier sa valeur, nous devons la rendre mutable en utilisant le mot-clé mut, comme nous l’avons vu au chapitre 3. Les nombres que nous plaçons à l’intérieur sont tous de type i32, et Rust le déduit à partir des données, donc nous n’avons pas besoin de l’annotation Vec<i32>.
Lire les éléments d’un vector
Il existe deux façons de référencer une valeur stockée dans un vector : par l’indexation ou en utilisant la méthode get. Dans les exemples suivants, nous avons annoté les types des valeurs renvoyées par ces fonctions pour plus de clarté.
L’encart 8-4 montre les deux méthodes d’accès à une valeur dans un vector, avec la syntaxe d’indexation et la méthode get.
fn main() {
let v = vec![1, 2, 3, 4, 5];
let third: &i32 = &v[2];
println!("The third element is {third}");
let third: Option<&i32> = v.get(2);
match third {
Some(third) => println!("The third element is {third}"),
None => println!("There is no third element."),
}
}get method to access an item in a vectorNotez quelques détails ici. Nous utilisons l’indice 2 pour obtenir le troisième élément car les vectors sont indexés par numéro, en commençant à zéro. L’utilisation de & et [] nous donne une référence à l’élément situé à cet indice. Lorsque nous utilisons la méthode get avec l’indice passé en argument, nous obtenons un Option<&T> que nous pouvons utiliser avec match.
Rust fournit ces deux façons de référencer un élément afin que vous puissiez choisir comment le programme se comporte lorsque vous essayez d’utiliser un indice en dehors de la plage des éléments existants. Par exemple, voyons ce qui se passe lorsque nous avons un vector de cinq éléments et que nous essayons d’accéder à un élément à l’indice 100 avec chaque technique, comme montré dans l’encart 8-5.
fn main() {
let v = vec![1, 2, 3, 4, 5];
let does_not_exist = &v[100];
let does_not_exist = v.get(100);
}Lorsque nous exécutons ce code, la première méthode avec [] provoquera un panic du programme car elle référence un élément inexistant. Cette méthode est à privilégier lorsque vous souhaitez que votre programme plante s’il y à une tentative d’accès à un élément au-delà de la fin du vector.
Lorsque la méthode get reçoit un indice en dehors du vector, elle renvoie None sans paniquer. Vous utiliseriez cette méthode si l’accès à un élément au-delà de la plage du vector peut arriver occasionnellement dans des circonstances normales. Votre code aura alors la logique pour gérer soit Some(&element) soit None, comme nous l’avons vu au chapitre 6. Par exemple, l’indice pourrait provenir d’une personne qui saisit un nombre. Si elle entre accidentellement un nombre trop grand et que le programme obtient une valeur None, vous pourriez indiquer à l’utilisateur combien d’éléments se trouvent dans le vector actuel et lui donner une autre chance de saisir une valeur valide. Ce serait plus convivial que de faire planter le programme à cause d’une faute de frappe !
Lorsque le programme détient une référence valide, le vérificateur d’emprunt applique les règles de possession et d’emprunt (couvertes au chapitre 4) pour garantir que cette référence et toute autre référence au contenu du vector restent valides. Rappelez-vous la règle qui stipule que vous ne pouvez pas avoir des références mutables et immuables dans la même portée. Cette règle s’applique dans l’encart 8-6, où nous détenons une référence immuable au premier élément d’un vector et essayons d’ajouter un élément à la fin. Ce programme ne fonctionnera pas si nous essayons aussi de faire référence à cet élément plus tard dans la fonction.
fn main() {
let mut v = vec![1, 2, 3, 4, 5];
let first = &v[0];
v.push(6);
println!("The first element is: {first}");
}La compilation de ce code produira cette erreur : console {{#include ../listings/ch08-common-collections/listing-08-06/output.txt}}
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0502]: cannot borrow `v` as mutable because it is also borrowed as immutable
--> src/main.rs:6:5
|
4 | let first = &v[0];
| - immutable borrow occurs here
5 |
6 | v.push(6);
| ^^^^^^^^^ mutable borrow occurs here
7 |
8 | println!("The first element is: {first}");
| ----- immutable borrow later used here
For more information about this error, try `rustc --explain E0502`.
error: could not compile `collections` (bin "collections") due to 1 previous error
Le code de l’encart 8-6 pourrait sembler devoir fonctionner : pourquoi une référence au premier élément se soucierait-elle de changements à la fin du vector ? Cette erreur est due au fonctionnement des vectors : comme les vectors placent les valeurs les unes à côté des autres en mémoire, l’ajout d’un nouvel élément à la fin du vector pourrait nécessiter l’allocation de nouvelle mémoire et la copie des anciens éléments vers le nouvel espace, s’il n’y a pas assez de place pour mettre tous les éléments les uns à côté des autres là où le vector est actuellement stocké. Dans ce cas, la référence au premier élément pointerait vers de la mémoire désallouée. Les règles d’emprunt empêchent les programmes de se retrouver dans cette situation.
Remarque : Pour plus de détails sur l’implémentation du type
Vec<T>, consultez [“The Rustonomicon”][nomicon].
Itérer sur les valeurs d’un vector
Pour accéder à chaque élément d’un vector à tour de rôle, nous itérerions sur tous les éléments plutôt que d’utiliser des indices pour y accéder un par un. L’encart 8-7 montre comment utiliser une boucle for pour obtenir des références immuables à chaque élément d’un vector de valeurs i32 et les afficher.
fn main() {
let v = vec![100, 32, 57];
for i in &v {
println!("{i}");
}
}for loopNous pouvons également itérer sur des références mutables à chaque élément d’un vector mutable afin d’apporter des modifications à tous les éléments. La boucle for de l’encart 8-8 ajoutera 50 à chaque élément.
fn main() {
let mut v = vec![100, 32, 57];
for i in &mut v {
*i += 50;
}
}Pour modifier la valeur à laquelle la référence mutable fait référence, nous devons utiliser l’opérateur de déréférencement * pour accéder à la valeur dans i avant de pouvoir utiliser l’opérateur +=. Nous parlerons davantage de l’opérateur de déréférencement dans la section [“Suivre la référence jusqu’à la valeur”][deref] du chapitre 15.
Itérer sur un vector, que ce soit de manière immuable ou mutable, est sûr grâce aux règles du vérificateur d’emprunt. Si nous tentions d’insérer ou de supprimer des éléments dans le corps des boucles for des encarts 8-7 et 8-8, nous obtiendrions une erreur de compilation similaire à celle que nous avons obtenue avec le code de l’encart 8-6. La référence au vector que la boucle for détient empêche la modification simultanée de l’ensemble du vector.
Utiliser une enum pour stocker plusieurs types
Les vectors ne peuvent stocker que des valeurs du même type. Cela peut être gênant ; il existe assurément des cas d’utilisation où l’on a besoin de stocker une liste d’éléments de différents types. Heureusement, les variantes d’une enum sont définies sous le même type d’enum, donc lorsque nous avons besoin d’un seul type pour représenter des éléments de différents types, nous pouvons définir et utiliser une enum !
Par exemple, supposons que nous voulions obtenir des valeurs d’une ligne dans un tableur dans lequel certaines colonnes de la ligne contiennent des entiers, d’autres des nombres à virgule flottante, et d’autres des chaînes de caractères. Nous pouvons définir une enum dont les variantes contiendront les différents types de valeurs, et toutes les variantes de l’enum seront considérées comme le même type : celui de l’enum. Ensuite, nous pouvons créer un vector pour contenir cette enum et ainsi, au final, contenir des types différents. Nous l’avons démontré dans l’encart 8-9.
fn main() {
enum SpreadsheetCell {
Int(i32),
Float(f64),
Text(String),
}
let row = vec![
SpreadsheetCell::Int(3),
SpreadsheetCell::Text(String::from("blue")),
SpreadsheetCell::Float(10.12),
];
}Rust a besoin de savoir quels types seront dans le vector à la compilation afin de savoir exactement combien de mémoire sur le tas sera nécessaire pour stocker chaque élément. Nous devons également être explicites sur les types autorisés dans ce vector. Si Rust permettait à un vector de contenir n’importe quel type, il y aurait un risque qu’un où plusieurs de ces types causent des erreurs avec les opérations effectuées sur les éléments du vector. L’utilisation d’une enum combinée à une expression match signifie que Rust s’assurera à la compilation que chaque cas possible est traité, comme nous l’avons vu au chapitre 6.
Si vous ne connaissez pas l’ensemble exhaustif des types qu’un programme recevra à l’exécution pour les stocker dans un vector, la technique de l’enum ne fonctionnera pas. À la place, vous pouvez utiliser un objet trait, que nous couvrirons au chapitre 18.
Maintenant que nous avons discuté de certaines des façons les plus courantes d’utiliser les vectors, n’oubliez pas de consulter [la documentation de l’API][vec-api] pour toutes les nombreuses méthodes utiles définies sur Vec<T> par la bibliothèque standard. Par exemple, en plus de push, une méthode pop supprime et renvoie le dernier élément.
Libérer un vector libère ses éléments
Comme toute autre struct, un vector est libéré lorsqu’il sort de la portée, comme annoté dans l’encart 8-10.
fn main() {
{
let v = vec![1, 2, 3, 4];
// do stuff with v
} // <- v goes out of scope and is freed here
}Lorsque le vector est libéré, tout son contenu est également libéré, ce qui signifie que les entiers qu’il contient seront nettoyés. Le vérificateur d’emprunt garantit que toute référence au contenu d’un vector n’est utilisée que tant que le vector lui-même est valide.
Passons au type de collection suivant : String !
Stocker du texte encodé en UTF-8 avec les String
Stocker du texte encodé en UTF-8 avec les String
Nous avons parlé des strings au chapitre 4, mais nous allons maintenant les examiner plus en profondeur. Les nouveaux Rustacés se retrouvent souvent bloqués sur les strings pour une combinaison de trois raisons : la propension de Rust à exposer les erreurs possibles, les strings étant une structure de données plus compliquée que ce que de nombreux développeurs imaginent, et l’UTF-8. Ces facteurs se combinent d’une manière qui peut sembler difficile lorsqu’on vient d’autres langages de programmation.
Nous abordons les strings dans le contexte des collections car les strings sont implémentées comme une collection d’octets, avec en plus quelques méthodes pour fournir des fonctionnalités utiles lorsque ces octets sont interprétés comme du texte. Dans cette section, nous parlerons des opérations sur String que possède chaque type de collection, comme la création, la mise à jour et la lecture. Nous discuterons également des manières dont String diffère des autres collections, à savoir comment l’indexation dans une String est compliquée par les différences entre la façon dont les humains et les ordinateurs interprètent les données d’une String.
Définir les strings
Nous allons d’abord définir ce que nous entendons par le terme string. Rust n’a qu’un seul type de string dans le langage de base, qui est la slice de chaîne str que l’on voit généralement sous sa forme empruntée, &str. Au chapitre 4, nous avons parlé des slices de chaîne, qui sont des références à des données de chaîne encodées en UTF-8 stockées ailleurs. Les littéraux de chaîne, par exemple, sont stockés dans le binaire du programme et sont donc des slices de chaîne.
Le type String, qui est fourni par la bibliothèque standard de Rust plutôt que codé dans le langage de base, est un type de chaîne extensible, mutable, possédé et encodé en UTF-8. Quand les Rustacés font référence aux “strings” en Rust, ils peuvent désigner soit le type String soit le type slice de chaîne &str, et pas seulement l’un de ces types. Bien que cette section porte principalement sur String, les deux types sont intensivement utilisés dans la bibliothèque standard de Rust, et tant String que les slices de chaîne sont encodés en UTF-8.
Créer une nouvelle String
Beaucoup des mêmes opérations disponibles avec Vec<T> sont aussi disponibles avec String car String est en fait implémenté comme un wrapper autour d’un vector d’octets avec quelques garanties, restrictions et capacités supplémentaires. Un exemple de fonction qui fonctionne de la même manière avec Vec<T> et String est la fonction new pour créer une instance, montrée dans l’encart 8-11.
fn main() {
let mut s = String::new();
}StringCette ligne crée une nouvelle chaîne vide appelée s, dans laquelle nous pouvons ensuite charger des données. Souvent, nous aurons des données initiales avec lesquelles nous voudrons démarrer la chaîne. Pour cela, nous utilisons la méthode to_string, qui est disponible sur tout type implémentant le trait Display, comme c’est le cas des littéraux de chaîne. L’encart 8-12 montre deux exemples.
fn main() {
let data = "initial contents";
let s = data.to_string();
// The method also works on a literal directly:
let s = "initial contents".to_string();
}to_string method to create a String from a string literalCe code crée une chaîne contenant initial contents.
Nous pouvons également utiliser la fonction String::from pour créer une String à partir d’un littéral de chaîne. Le code de l’encart 8-13 est équivalent au code de l’encart 8-12 qui utilise to_string.
fn main() {
let s = String::from("initial contents");
}String::from function to create a String from a string literalParce que les strings sont utilisées pour tellement de choses, nous pouvons utiliser de nombreuses API génériques différentes pour les strings, ce qui nous offre beaucoup d’options. Certaines d’entre elles peuvent sembler redondantes, mais elles ont toutes leur utilité ! Dans ce cas, String::from et to_string font la même chose, donc le choix entre les deux est une question de style et de lisibilité.
N’oubliez pas que les strings sont encodées en UTF-8, donc nous pouvons y inclure toute donnée correctement encodée, comme montré dans l’encart 8-14.
fn main() {
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שלום");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
}Toutes ces valeurs sont des String valides.
Mettre à jour une String
Une String peut grandir en taille et son contenu peut changer, tout comme le contenu d’un Vec<T>, si vous y ajoutez plus de données. De plus, vous pouvez utiliser l’opérateur + ou la macro format! pour concaténer des valeurs String.
Ajouter du contenu avec push_str ou push
Nous pouvons faire grandir une String en utilisant la méthode push_str pour ajouter une slice de chaîne, comme montré dans l’encart 8-15.
fn main() {
let mut s = String::from("foo");
s.push_str("bar");
}String using the push_str methodAprès ces deux lignes, s contiendra foobar. La méthode push_str prend une slice de chaîne car nous ne voulons pas nécessairement prendre possession du paramètre. Par exemple, dans le code de l’encart 8-16, nous voulons pouvoir utiliser s2 après avoir ajouté son contenu à s1.
fn main() {
let mut s1 = String::from("foo");
let s2 = "bar";
s1.push_str(s2);
println!("s2 is {s2}");
}StringSi la méthode push_str prenait possession de s2, nous ne pourrions pas afficher sa valeur à la dernière ligne. Cependant, ce code fonctionne comme prévu !
La méthode push prend un seul caractère en paramètre et l’ajouté à la String. L’encart 8-17 ajouté la lettre l à une String en utilisant la méthode push.
fn main() {
let mut s = String::from("lo");
s.push('l');
}String value using pushEn conséquence, s contiendra lol.
Concaténer avec + ou format!
Souvent, vous voudrez combiner deux chaînes existantes. Une façon de le faire est d’utiliser l’opérateur +, comme montré dans l’encart 8-18.
fn main() {
let s1 = String::from("Hello, ");
let s2 = String::from("world!");
let s3 = s1 + &s2; // note s1 has been moved here and can no longer be used
}+ operator to combine two String values into a new String valueLa chaîne s3 contiendra Hello, world!. La raison pour laquelle s1 n’est plus valide après l’addition, et la raison pour laquelle nous avons utilisé une référence à s2, est liée à la signature de la méthode qui est appelée lorsque nous utilisons l’opérateur +. L’opérateur + utilise la méthode add, dont la signature ressemble à ceci :
fn add(self, s: &str) -> String {Dans la bibliothèque standard, vous verrez add définie à l’aide de la généricité et de types associés. Ici, nous avons substitué des types concrets, ce qui est ce qui se passe lorsque nous appelons cette méthode avec des valeurs String. Nous discuterons de la généricité au chapitre 10. Cette signature nous donne les indices nécessaires pour comprendre les subtilités de l’opérateur +.
Premièrement, s2 à un &, ce qui signifie que nous ajoutons une référence de la deuxième chaîne à la première chaîne. C’est à cause du paramètre s dans la fonction add : nous ne pouvons ajouter qu’une slice de chaîne à une String ; nous ne pouvons pas additionner deux valeurs String. Mais attendez – le type de &s2 est &String, et non &str, comme spécifié dans le second paramètre de add. Alors, pourquoi l’encart 8-18 compile-t-il ?
La raison pour laquelle nous pouvons utiliser &s2 dans l’appel à add est que le compilateur peut contraindre l’argument &String en &str. Lorsque nous appelons la méthode add, Rust utilise une coercition de déréférencement (deref coercion), qui transformé ici &s2 en &s2[..]. Nous discuterons de la coercition de déréférencement plus en profondeur au chapitre 15. Comme add ne prend pas possession du paramètre s, s2 sera toujours une String valide après cette opération.
Deuxièmement, nous pouvons voir dans la signature que add prend possession de self car self n’a pas de &. Cela signifie que s1 dans l’encart 8-18 sera déplacé dans l’appel à add et ne sera plus valide après. Donc, bien que let s3 = s1 + &s2; semble copier les deux chaînes et en créer une nouvelle, cette instruction prend en fait possession de s1, ajouté une copie du contenu de s2, puis renvoie la possession du résultat. En d’autres termes, cela semble faire beaucoup de copies, mais ce n’est pas le cas ; l’implémentation est plus efficace qu’une copie.
Si nous devons concaténer plusieurs chaînes, le comportement de l’opérateur + devient lourd à manier : rust {{#rustdoc_include ../listings/ch08-common-collections/no-listing-01-concat-multiple-strings/src/main.rs:here}}
fn main() {
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = s1 + "-" + &s2 + "-" + &s3;
}À ce stade, s vaudra tic-tac-toe. Avec tous les caractères + et ", il est difficile de voir ce qui se passe. Pour combiner des chaînes de manière plus complexe, nous pouvons utiliser la macro format! à la place : rust {{#rustdoc_include ../listings/ch08-common-collections/no-listing-02-format/src/main.rs:here}}
fn main() {
let s1 = String::from("tic");
let s2 = String::from("tac");
let s3 = String::from("toe");
let s = format!("{s1}-{s2}-{s3}");
}Ce code assigne également tic-tac-toe à s. La macro format! fonctionne comme println!, mais au lieu d’afficher la sortie à l’écran, elle renvoie une String avec le contenu. La version du code utilisant format! est beaucoup plus facile à lire, et le code généré par la macro format! utilise des références pour que cet appel ne prenne possession d’aucun de ses paramètres.
Indexer dans les strings
Dans de nombreux autres langages de programmation, accéder aux caractères individuels d’une chaîne en les référençant par indice est une opération valide et courante. Cependant, si vous essayez d’accéder à des parties d’une String en utilisant la syntaxe d’indexation en Rust, vous obtiendrez une erreur. Considérez le code invalide de l’encart 8-19.
fn main() {
let s1 = String::from("hi");
let h = s1[0];
}StringCe code produira l’erreur suivante : console {{#include ../listings/ch08-common-collections/listing-08-19/output.txt}}
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
error[E0277]: the type `str` cannot be indexed by `{integer}`
--> src/main.rs:3:16
|
3 | let h = s1[0];
| ^ string indices are ranges of `usize`
|
= help: the trait `SliceIndex<str>` is not implemented for `{integer}`
= note: you can use `.chars().nth()` or `.bytes().nth()`
for more information, see chapter 8 in The Book: <https://doc.rust-lang.org/book/ch08-02-strings.html#indexing-into-strings>
= help: the following other types implement trait `SliceIndex<T>`:
`usize` implements `SliceIndex<ByteStr>`
`usize` implements `SliceIndex<[T]>`
= note: required for `String` to implement `Index<{integer}>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `collections` (bin "collections") due to 1 previous error
L’erreur dit tout : les strings en Rust ne supportent pas l’indexation. Mais pourquoi ? Pour répondre à cette question, nous devons aborder la façon dont Rust stocké les strings en mémoire.
Représentation interne
Une String est un wrapper autour d’un Vec<u8>. Examinons certaines de nos chaînes d’exemple correctement encodées en UTF-8 de l’encart 8-14. D’abord, celle-ci : rust {{#rustdoc_include ../listings/ch08-common-collections/listing-08-14/src/main.rs:spanish}}
fn main() {
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שלום");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
}Dans ce cas, len vaudra 4, ce qui signifie que le vector stockant la chaîne "Hola" fait 4 octets de long. Chacune de ces lettres occupe 1 octet lorsqu’elle est encodée en UTF-8. La ligne suivante, cependant, pourrait vous surprendre (notez que cette chaîne commence par la lettre cyrillique majuscule Ze, et non le chiffre 3) : rust {{#rustdoc_include ../listings/ch08-common-collections/listing-08-14/src/main.rs:russian}}
fn main() {
let hello = String::from("السلام عليكم");
let hello = String::from("Dobrý den");
let hello = String::from("Hello");
let hello = String::from("שלום");
let hello = String::from("नमस्ते");
let hello = String::from("こんにちは");
let hello = String::from("안녕하세요");
let hello = String::from("你好");
let hello = String::from("Olá");
let hello = String::from("Здравствуйте");
let hello = String::from("Hola");
}Si on vous demandait la longueur de la chaîne, vous pourriez dire 12. En fait, la réponse de Rust est 24 : c’est le nombre d’octets nécessaires pour encoder “Здравствуйте” en UTF-8, car chaque valeur scalaire Unicode dans cette chaîne occupe 2 octets de stockage. Par conséquent, un indice dans les octets de la chaîne ne correspondra pas toujours à une valeur scalaire Unicode valide. Pour illustrer cela, considérez ce code Rust invalide :
let hello = "Здравствуйте";
let answer = &hello[0];Vous savez déjà que answer ne sera pas З, la première lettre. Encodé en UTF-8, le premier octet de З est 208 et le second est 151, donc il semblerait que answer devrait en fait être 208, mais 208 n’est pas un caractère valide en soi. Renvoyer 208 n’est probablement pas ce qu’un utilisateur souhaiterait s’il demandait la première lettre de cette chaîne ; cependant, c’est la seule donnée que Rust a à l’indice d’octet 0. Les utilisateurs ne veulent généralement pas que la valeur de l’octet soit renvoyée, même si la chaîne ne contient que des lettres latines : si &"hi"[0] était du code valide renvoyant la valeur de l’octet, il renverrait 104, et non h.
La réponse est donc que, pour éviter de renvoyer une valeur inattendue et de causer des bogues qui pourraient ne pas être découverts immédiatement, Rust ne compilé tout simplement pas ce code et prévient les malentendus tôt dans le processus de développement.
Octets, valeurs scalaires et groupes de graphèmes
Un autre point concernant l’UTF-8 est qu’il y a en fait trois façons pertinentes de regarder les strings du point de vue de Rust : sous forme d’octets, de valeurs scalaires et de groupes de graphèmes (ce qui se rapproche le plus de ce que nous appellerions des lettres).
Si nous regardons le mot hindi “नमस्ते” écrit en alphabet devanagari, il est stocké comme un vector de valeurs u8 qui ressemble à ceci :
[224, 164, 168, 224, 164, 174, 224, 164, 184, 224, 165, 141, 224, 164, 164,
224, 165, 135]
Cela fait 18 octets et c’est ainsi que les ordinateurs stockent finalement ces données. Si nous les regardons comme des valeurs scalaires Unicode, ce que représente le type char de Rust, ces octets ressemblent à ceci :
['न', 'म', 'स', '्', 'त', 'े']
Il y a six valeurs char ici, mais la quatrième et la sixième ne sont pas des lettres : ce sont des signes diacritiques qui n’ont pas de sens isolément. Enfin, si nous les regardons comme des groupes de graphèmes, nous obtiendrions ce qu’une personne appellerait les quatre lettres qui composent le mot hindi :
["न", "म", "स्", "ते"]
Rust fournit différentes façons d’interpréter les données brutes de chaîne que les ordinateurs stockent afin que chaque programme puisse choisir l’interprétation dont il a besoin, quelle que soit la langue humaine dans laquelle se trouvent les données.
Une dernière raison pour laquelle Rust ne nous permet pas d’indexer dans une String pour obtenir un caractère est que les opérations d’indexation sont censées toujours s’exécuter en temps constant (O(1)). Mais il n’est pas possible de garantir cette performance avec une String, car Rust devrait parcourir le contenu depuis le début jusqu’à l’indice pour déterminer combien de caractères valides il y a.
Découper les strings en slices
Indexer dans une chaîne est souvent une mauvaise idée car il n’est pas clair quel devrait être le type de retour de l’opération d’indexation de la chaîne : une valeur d’octet, un caractère, un groupe de graphèmes ou une slice de chaîne. Si vous avez vraiment besoin d’utiliser des indices pour créer des slices de chaîne, Rust vous demande donc d’être plus précis.
Au lieu d’indexer en utilisant [] avec un seul nombre, vous pouvez utiliser [] avec un intervalle pour créer une slice de chaîne contenant des octets particuliers :
#![allow(unused)]
fn main() {
let hello = "Здравствуйте";
let s = &hello[0..4];
}Ici, s sera un &str contenant les 4 premiers octets de la chaîne. Plus tôt, nous avons mentionné que chacun de ces caractères faisait 2 octets, ce qui signifie que s sera Зд.
Si nous essayions de découper seulement une partie des octets d’un caractère avec quelque chose comme &hello[0..1], Rust paniquerait à l’exécution de la même manière que si un indice invalide était accédé dans un vector : console {{#include ../listings/ch08-common-collections/output-only-01-not-char-boundary/output.txt}}
$ cargo run
Compiling collections v0.1.0 (file:///projects/collections)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/collections`
thread 'main' panicked at src/main.rs:4:19:
byte index 1 is not a char boundary; it is inside 'З' (bytes 0..2) of `Здравствуйте`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Vous devriez faire preuve de prudence lorsque vous créez des slices de chaîne avec des intervalles, car cela peut faire planter votre programme.
Itérer sur les strings
La meilleure façon d’opérer sur des morceaux de strings est d’être explicite sur le fait que vous vouliez des caractères ou des octets. Pour les valeurs scalaires Unicode individuelles, utilisez la méthode chars. Appeler chars sur “Зд” sépare et renvoie deux valeurs de type char, et vous pouvez itérer sur le résultat pour accéder à chaque élément :
#![allow(unused)]
fn main() {
for c in "Зд".chars() {
println!("{c}");
}
}Ce code affichera ce qui suit :
З
д
Alternativement, la méthode bytes renvoie chaque octet brut, ce qui pourrait être approprié pour votre domaine :
#![allow(unused)]
fn main() {
for b in "Зд".bytes() {
println!("{b}");
}
}Ce code affichera les 4 octets qui composent cette chaîne :
208
151
208
180
Mais n’oubliez pas que les valeurs scalaires Unicode valides peuvent être composées de plus d’un octet.
Obtenir les groupes de graphèmes à partir de strings, comme avec l’alphabet devanagari, est complexe, c’est pourquoi cette fonctionnalité n’est pas fournie par la bibliothèque standard. Des crates sont disponibles sur crates.io si c’est la fonctionnalité dont vous avez besoin.
Gérer la complexité des strings
En résumé, les strings sont compliquées. Les différents langages de programmation font des choix différents quant à la manière de présenter cette complexité au développeur. Rust a choisi de faire du traitement correct des données String le comportement par défaut pour tous les programmes Rust, ce qui signifie que les développeurs doivent réfléchir davantage à la gestion des données UTF-8 dès le départ. Ce compromis expose davantage la complexité des strings que ce qui est apparent dans d’autres langages de programmation, mais cela vous évite d’avoir à gérer des erreurs impliquant des caractères non-ASCII plus tard dans votre cycle de développement.
La bonne nouvelle est que la bibliothèque standard offre beaucoup de fonctionnalités construites sur les types String et &str pour aider à gérer correctement ces situations complexes. N’hésitez pas à consulter la documentation pour des méthodes utiles comme contains pour chercher dans une chaîne et replace pour substituer des parties d’une chaîne par une autre chaîne.
Passons à quelque chose d’un peu moins complexe : les hash maps !
Stocker des clés associées à des valeurs dans des tables de hachage
Stocker des clés associées à des valeurs dans des tables de hachage
La dernière de nos collections courantes est la hash map. Le type HashMap<K, V> stocké une association de clés de type K vers des valeurs de type V en utilisant une fonction de hachage, qui détermine comment il place ces clés et valeurs en mémoire. De nombreux langages de programmation prennent en charge ce type de structure de données, mais ils utilisent souvent un nom différent, comme hash, map, object, hash table, dictionary ou associative array (tableau associatif), pour n’en citer que quelques-uns.
Les hash maps sont utiles lorsque vous voulez rechercher des données non pas en utilisant un indice, comme vous pouvez le faire avec les vectors, mais en utilisant une clé qui peut être de n’importe quel type. Par exemple, dans un jeu, vous pourriez suivre le score de chaque équipe dans une hash map dans laquelle chaque clé est le nom d’une équipe et les valeurs sont les scores de chaque équipe. À partir d’un nom d’équipe, vous pouvez récupérer son score.
Nous allons parcourir l’API de base des hash maps dans cette section, mais de nombreuses autres fonctionnalités se cachent dans les fonctions définies sur HashMap<K, V> par la bibliothèque standard. Comme toujours, consultez la documentation de la bibliothèque standard pour plus d’informations.
Créer une nouvelle hash map
Une façon de créer une hash map vide est d’utiliser new et d’ajouter des éléments avec insert. Dans l’encart 8-20, nous suivons les scores de deux équipes dont les noms sont Blue et Yellow. L’équipe Blue commence avec 10 points et l’équipe Yellow commence avec 50.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
}Notez que nous devons d’abord importer (use) le HashMap de la partie collections de la bibliothèque standard. Parmi nos trois collections courantes, celle-ci est la moins souvent utilisée, elle n’est donc pas incluse dans les fonctionnalités automatiquement mises en portée par le prelude. Les hash maps bénéficient également de moins de support de la part de la bibliothèque standard ; il n’y a pas de macro intégrée pour les construire, par exemple.
Tout comme les vectors, les hash maps stockent leurs données sur le tas. Ce HashMap à des clés de type String et des valeurs de type i32. Comme les vectors, les hash maps sont homogènes : toutes les clés doivent avoir le même type, et toutes les valeurs doivent avoir le même type.
Accéder aux valeurs dans une hash map
Nous pouvons obtenir une valeur de la hash map en fournissant sa clé à la méthode get, comme montré dans l’encart 8-21.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
let team_name = String::from("Blue");
let score = scores.get(&team_name).copied().unwrap_or(0);
}Ici, score aura la valeur associée à l’équipe Blue, et le résultat sera 10. La méthode get renvoie un Option<&V> ; s’il n’y a pas de valeur pour cette clé dans la hash map, get renverra None. Ce programme gère l’Option en appelant copied pour obtenir un Option<i32> plutôt qu’un Option<&i32>, puis unwrap_or pour mettre score à zéro si scores n’a pas d’entrée pour la clé.
Nous pouvons itérer sur chaque paire clé-valeur dans une hash map de la même manière que nous le faisons avec les vectors, en utilisant une boucle for : rust {{#rustdoc_include ../listings/ch08-common-collections/no-listing-03-iterate-over-hashmap/src/main.rs:here}}
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Yellow"), 50);
for (key, value) in &scores {
println!("{key}: {value}");
}
}Ce code affichera chaque paire dans un ordre arbitraire :
Yellow: 50
Blue: 10
Gérer la possession dans les hash maps
Pour les types qui implémentent le trait Copy, comme i32, les valeurs sont copiées dans la hash map. Pour les valeurs possédées comme String, les valeurs seront déplacées et la hash map deviendra propriétaire de ces valeurs, comme démontré dans l’encart 8-22.
fn main() {
use std::collections::HashMap;
let field_name = String::from("Favorite color");
let field_value = String::from("Blue");
let mut map = HashMap::new();
map.insert(field_name, field_value);
// field_name and field_value are invalid at this point, try using them and
// see what compiler error you get!
}Nous ne pouvons pas utiliser les variables field_name et field_value après qu’elles ont été déplacées dans la hash map lors de l’appel à insert.
Si nous insérons des références vers des valeurs dans la hash map, les valeurs ne seront pas déplacées dans la hash map. Les valeurs vers lesquelles les références pointent doivent être valides au moins aussi longtemps que la hash map est valide. Nous parlerons davantage de ces questions dans [“Valider les références avec les durées de vie”][validating-references-with-lifetimes] au chapitre 10.
Mettre à jour une hash map
Bien que le nombre de paires clé-valeur puisse augmenter, chaque clé unique ne peut avoir qu’une seule valeur associée à la fois (mais pas l’inverse : par exemple, l’équipe Blue et l’équipe Yellow pourraient toutes deux avoir la valeur 10 stockée dans la hash map scores).
Lorsque vous voulez modifier les données dans une hash map, vous devez décider comment gérer le cas où une clé a déjà une valeur assignée. Vous pourriez remplacer l’ancienne valeur par la nouvelle, en ignorant complètement l’ancienne valeur. Vous pourriez conserver l’ancienne valeur et ignorer la nouvelle, en n’ajoutant la nouvelle valeur que si la clé n’a pas déjà de valeur. Ou vous pourriez combiner l’ancienne et la nouvelle valeur. Voyons comment faire chacune de ces opérations !
Écraser une valeur
Si nous insérons une clé et une valeur dans une hash map puis insérons cette même clé avec une valeur différente, la valeur associée à cette clé sera remplacée. Même si le code de l’encart 8-23 appelle insert deux fois, la hash map ne contiendra qu’une seule paire clé-valeur car nous insérons la valeur pour la clé de l’équipe Blue les deux fois.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.insert(String::from("Blue"), 25);
println!("{scores:?}");
}Ce code affichera {"Blue": 25}. La valeur originale de 10 a été écrasée.
Ajouter une clé et une valeur uniquement si la clé n’est pas présente
Il est courant de vérifier si une clé particulière existe déjà dans la hash map avec une valeur, puis de prendre les actions suivantes : si la clé existe dans la hash map, la valeur existante doit rester telle quelle ; si la clé n’existe pas, l’insérer avec une valeur.
Les hash maps ont une API spéciale pour cela appelée entry qui prend en paramètre la clé que vous souhaitez vérifier. La valeur de retour de la méthode entry est une enum appelée Entry qui représente une valeur qui pourrait ou non exister. Disons que nous voulons vérifier si la clé de l’équipe Yellow à une valeur associée. Si ce n’est pas le cas, nous voulons insérer la valeur 50, et de même pour l’équipe Blue. En utilisant l’API entry, le code ressemble à l’encart 8-24.
fn main() {
use std::collections::HashMap;
let mut scores = HashMap::new();
scores.insert(String::from("Blue"), 10);
scores.entry(String::from("Yellow")).or_insert(50);
scores.entry(String::from("Blue")).or_insert(50);
println!("{scores:?}");
}entry method to only insert if the key does not already have a valueLa méthode or_insert sur Entry est définie pour renvoyer une référence mutable à la valeur correspondant à la clé de l’Entry si cette clé existe, et sinon, elle insère le paramètre comme nouvelle valeur pour cette clé et renvoie une référence mutable à la nouvelle valeur. Cette technique est beaucoup plus propre que d’écrire la logique nous-mêmes et, de plus, fonctionne mieux avec le vérificateur d’emprunt.
L’exécution du code de l’encart 8-24 affichera {"Yellow": 50, "Blue": 10}. Le premier appel à entry insérera la clé pour l’équipe Yellow avec la valeur 50 car l’équipe Yellow n’a pas encore de valeur. Le second appel à entry ne modifiera pas la hash map, car l’équipe Blue a déjà la valeur 10.
Mettre à jour une valeur en fonction de l’ancienne valeur
Un autre cas d’utilisation courant des hash maps est de rechercher la valeur d’une clé puis de la mettre à jour en fonction de l’ancienne valeur. Par exemple, l’encart 8-25 montre du code qui compte combien de fois chaque mot apparaît dans un texte. Nous utilisons une hash map avec les mots comme clés et incrémentons la valeur pour suivre combien de fois nous avons vu ce mot. Si c’est la première fois que nous voyons un mot, nous insérons d’abord la valeur 0.
fn main() {
use std::collections::HashMap;
let text = "hello world wonderful world";
let mut map = HashMap::new();
for word in text.split_whitespace() {
let count = map.entry(word).or_insert(0);
*count += 1;
}
println!("{map:?}");
}Ce code affichera {"world": 2, "hello": 1, "wonderful": 1}. Vous pourriez voir les mêmes paires clé-valeur affichées dans un ordre différent : rappelez-vous de la section [“Accéder aux valeurs dans une hash map”][access] que l’itération sur une hash map se fait dans un ordre arbitraire.
La méthode split_whitespace renvoie un itérateur sur des sous-slices, séparées par des espaces, de la valeur dans text. La méthode or_insert renvoie une référence mutable (&mut V) à la valeur pour la clé spécifiée. Ici, nous stockons cette référence mutable dans la variable count, donc pour assigner une valeur, nous devons d’abord déréférencer count en utilisant l’astérisque (*). La référence mutable sort de la portée à la fin de la boucle for, donc tous ces changements sont sûrs et autorisés par les règles d’emprunt.
Fonctions de hachage
has libraries shared by other Rust users that provide hashers implementing many common hashing algorithms. –> Par défaut, HashMap utilise une fonction de hachage appelée SipHash qui peut fournir une résistance aux attaques par déni de service (DoS) impliquant des tables de hachage1. Ce n’est pas l’algorithme de hachage le plus rapide disponible, mais le compromis pour une meilleure sécurité qui accompagne la baisse de performance en vaut la peine. Si vous profilez votre code et constatez que la fonction de hachage par défaut est trop lente pour vos besoins, vous pouvez passer à une autre fonction en spécifiant un hasher différent. Un hasher est un type qui implémente le trait BuildHasher. Nous parlerons des traits et de leur implémentation au [chapitre 10][traits]. Vous n’avez pas nécessairement besoin d’implémenter votre propre hasher de zéro ; crates.io propose des bibliothèques partagées par d’autres utilisateurs de Rust qui fournissent des hashers implémentant de nombreux algorithmes de hachage courants. 1: https://en.wikipedia.org/wiki/SipHash
Résumé
Les vectors, les strings et les hash maps fournissent une grande quantité de fonctionnalités nécessaires dans les programmes lorsque vous avez besoin de stocker, d’accéder et de modifier des données. Voici quelques exercices que vous devriez maintenant être en mesure de résoudre :
- À partir d’une liste d’entiers, utilisez un vector et renvoyez la médiane (une fois triée, la valeur en position centrale) et le mode (la valeur qui apparaît le plus souvent ; une hash map sera utile ici) de la liste.
- Convertissez des chaînes en Pig Latin. La première consonne de chaque mot est déplacée à la fin du mot et ay est ajouté, donc first devient irst-fay. Les mots qui commencent par une voyelle ont hay ajouté à la fin à la place (apple devient apple-hay). Gardez à l’esprit les détails concernant l’encodage UTF-8 !
- En utilisant une hash map et des vectors, créez une interface textuelle pour permettre à un utilisateur d’ajouter des noms d’employés à un département dans une entreprise ; par exemple, “Add Sally to Engineering” ou “Add Amir to Sales.” Ensuite, permettez à l’utilisateur de récupérer la liste de toutes les personnes d’un département ou de toutes les personnes de l’entreprise par département, triées par ordre alphabétique.
La documentation de l’API de la bibliothèque standard décrit les méthodes que possèdent les vectors, les strings et les hash maps et qui seront utiles pour ces exercices !
Nous abordons des programmes plus complexes dans lesquels les opérations peuvent échouer, c’est donc le moment idéal pour discuter de la gestion des erreurs. C’est ce que nous ferons ensuite !
La gestion des erreurs
Les erreurs font partie de la réalité du développement logiciel, c’est pourquoi Rust dispose de nombreuses fonctionnalités pour gérer les situations où quelque chose se passe mal. Dans de nombreux cas, Rust vous oblige à reconnaître la possibilité d’une erreur et à prendre des mesures avant que votre code ne puisse compiler. Cette exigence rend votre programme plus robuste en garantissant que vous découvrirez les erreurs et les traiterez correctement avant de déployer votre code en production !
Rust classe les erreurs en deux grandes catégories : les erreurs récupérables et les erreurs irrécupérables. Pour une erreur récupérable, comme une erreur de type fichier introuvable, nous voulons très probablement simplement signaler le problème à l’utilisateur et réessayer l’opération. Les erreurs irrécupérables sont toujours des symptômes de bogues, comme tenter d’accéder à un emplacement au-delà de la fin d’un tableau, et dans ce cas nous voulons arrêter immédiatement le programme.
La plupart des langages ne font pas la distinction entre ces deux types d’erreurs et les gèrent de la même manière, en utilisant des mécanismes tels que les exceptions. Rust ne possède pas d’exceptions. À la place, il dispose du type Result<T, E> pour les erreurs récupérables et de la macro panic! qui arrête l’exécution lorsque le programme rencontre une erreur irrécupérable. Ce chapitre traite d’abord de l’appel à panic!, puis aborde le renvoi de valeurs Result<T, E>. De plus, nous examinerons les considérations à prendre en compte pour décider s’il faut tenter de récupérer d’une erreur ou arrêter l’exécution.
Les erreurs irrécupérables avec panic!
Les erreurs irrécupérables avec panic!
Parfois, de mauvaises choses se produisent dans votre code, et vous ne pouvez rien y faire. Dans ces cas-là, Rust dispose de la macro panic!. Il y a deux manières de provoquer un panic en pratique : en effectuant une action qui fait paniquer notre code (comme accéder à un tableau au-delà de sa fin) ou en appelant explicitement la macro panic!. Dans les deux cas, nous provoquons un panic dans notre programme. Par défaut, ces panics affichent un message d’erreur, déroulent la pile, nettoient la mémoire et quittent le programme. Via une variable d’environnement, vous pouvez également demander à Rust d’afficher la pile d’appels lorsqu’un panic se produit, afin de faciliter la recherche de son origine.
Dérouler la pile ou abandonner en réponse à un panic
Par défaut, lorsqu’un panic se produit, le programme commence à dérouler la pile (unwinding), ce qui signifie que Rust remonte la pile et nettoie les données de chaque fonction qu’il rencontre. Cependant, remonter et nettoyer demande beaucoup de travail. Rust vous permet donc de choisir l’alternative d’abandonner (aborting) immédiatement, ce qui met fin au programme sans nettoyage.
La mémoire utilisée par le programme devra alors être nettoyée par le système d’exploitation. Si dans votre projet vous avez besoin de rendre le binaire résultant aussi petit que possible, vous pouvez passer du déroulement de pile à l’abandon en cas de panic en ajoutant panic = 'abort' aux sections [profile] appropriées dans votre fichier Cargo.toml. Par exemple, si vous voulez abandonner en cas de panic en mode release, ajoutez ceci{N}:
[profile.release]
panic = 'abort'
Essayons d’appeler panic! dans un programme simple :
fn main() {
panic!("crash and burn");
}Lorsque vous exécutez le programme, vous verrez quelque chose comme ceci : console {{#include ../listings/ch09-error-handling/no-listing-01-panic/output.txt}}
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.25s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:2:5:
crash and burn
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
L’appel à panic! provoque le message d’erreur contenu dans les deux dernières lignes. La première ligne affiche notre message de panic et l’endroit dans notre code source où le panic s’est produit : src/main.rs:2:5 indique qu’il s’agit de la deuxième ligne, cinquième caractère de notre fichier src/main.rs.
Dans ce cas, la ligne indiquée fait partie de notre code, et si nous allons à cette ligne, nous voyons l’appel à la macro panic!. Dans d’autres cas, l’appel à panic! pourrait se trouver dans du code que notre code appelle, et le nom de fichier et le numéro de ligne signalés par le message d’erreur correspondront au code de quelqu’un d’autre où la macro panic! est appelée, et non à la ligne de notre code qui a finalement conduit à l’appel de panic!.
Nous pouvons utiliser la trace d’appels (backtrace) des fonctions d’où provient l’appel à panic! pour déterminer la partie de notre code qui cause le problème. Pour comprendre comment utiliser une trace d’appels de panic!, examinons un autre exemple et voyons ce qui se passe lorsqu’un appel à panic! provient d’une bibliothèque à cause d’un bogue dans notre code plutôt que de notre code appelant directement la macro. L’encart 9-1 contient du code qui tente d’accéder à un index dans un vecteur au-delà de la plage des index valides.
fn main() {
let v = vec![1, 2, 3];
v[99];
}panic!Ici, nous tentons d’accéder au 100e élément de notre vecteur (qui se trouve à l’index 99 car l’indexation commence à zéro), mais le vecteur n’a que trois éléments. Dans cette situation, Rust va paniquer. L’utilisation de [] est censée renvoyer un élément, mais si vous passez un index invalide, il n’y à aucun élément que Rust pourrait renvoyer ici qui serait correct.
En C, tenter de lire au-delà de la fin d’une structure de données est un comportement indéfini. Vous pourriez obtenir n’importe quelle valeur se trouvant à l’emplacement mémoire qui correspondrait à cet élément dans la structure de données, même si la mémoire n’appartient pas à cette structure. Cela s’appelle un buffer overread (dépassement de lecture de tampon) et peut conduire à des vulnérabilités de sécurité si un attaquant est capable de manipuler l’index de manière à lire des données auxquelles il ne devrait pas avoir accès, stockées après la structure de données.
Pour protéger votre programme de ce type de vulnérabilité, si vous essayez de lire un élément à un index qui n’existe pas, Rust arrêtera l’exécution et refusera de continuer. Essayons pour voir : console {{#include ../listings/ch09-error-handling/listing-09-01/output.txt}}
$ cargo run
Compiling panic v0.1.0 (file:///projects/panic)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/panic`
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Cette erreur pointe vers la ligne 4 de notre fichier main.rs où nous tentons d’accéder à l’index 99 du vecteur v.
La ligne note: nous indique que nous pouvons définir la variable d’environnement RUST_BACKTRACE pour obtenir une trace d’appels montrant exactement ce qui s’est passé pour provoquer l’erreur. Une trace d’appels (backtrace) est une liste de toutes les fonctions qui ont été appelées pour arriver à ce point. Les traces d’appels en Rust fonctionnent comme dans les autres langages : la clé pour lire la trace d’appels est de commencer par le haut et de lire jusqu’à ce que vous voyiez des fichiers que vous avez écrits. C’est l’endroit où le problème est né. Les lignes au-dessus de cet endroit sont du code que votre code a appelé ; les lignes en dessous sont du code qui a appelé votre code. Ces lignes avant et après peuvent inclure du code du noyau de Rust, du code de la bibliothèque standard ou des crates que vous utilisez. Essayons d’obtenir une trace d’appels en définissant la variable d’environnement RUST_BACKTRACE à n’importe quelle valeur sauf 0. L’encart 9-2 montre une sortie similaire à ce que vous verrez.
$ RUST_BACKTRACE=1 cargo run
thread 'main' panicked at src/main.rs:4:6:
index out of bounds: the len is 3 but the index is 99
stack backtrace:
0: rust_begin_unwind
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/std/src/panicking.rs:692:5
1: core::panicking::panic_fmt
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:75:14
2: core::panicking::panic_bounds_check
at /rustc/4d91de4e48198da2e33413efdcd9cd2cc0c46688/library/core/src/panicking.rs:273:5
3: <usize as core::slice::index::SliceIndex<[T]>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:274:10
4: core::slice::index::<impl core::ops::index::Index<I> for [T]>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/slice/index.rs:16:9
5: <alloc::vec::Vec<T,A> as core::ops::index::Index<I>>::index
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/alloc/src/vec/mod.rs:3361:9
6: panic::main
at ./src/main.rs:4:6
7: core::ops::function::FnOnce::call_once
at file:///home/.rustup/toolchains/1.85/lib/rustlib/src/rust/library/core/src/ops/function.rs:250:5
note: Some details are omitted, run with `RUST_BACKTRACE=full` for a verbose backtrace.
panic! displayed when the environment variable RUST_BACKTRACE is setCela fait beaucoup de sortie ! La sortie exacte que vous verrez peut différer selon votre système d’exploitation et votre version de Rust. Pour obtenir des traces d’appels avec ces informations, les symboles de débogage doivent être activés. Les symboles de débogage sont activés par défaut lorsque vous utilisez cargo build ou cargo run sans le drapeau --release, comme c’est le cas ici.
Dans la sortie de l’encart 9-2, la ligne 6 de la trace d’appels pointe vers la ligne de notre projet qui cause le problème : la ligne 4 de src/main.rs. Si nous ne voulons pas que notre programme panique, nous devrions commencer notre investigation à l’emplacement indiqué par la première ligne mentionnant un fichier que nous avons écrit. Dans l’encart 9-1, où nous avons délibérément écrit du code qui paniquerait, la façon de corriger le panic est de ne pas demander un élément au-delà de la plage des index du vecteur. Lorsque votre code paniquera à l’avenir, vous devrez déterminer quelle action le code effectue avec quelles valeurs pour provoquer le panic et ce que le code devrait faire à la place.
Nous reviendrons sur panic! et sur les cas où nous devrions ou ne devrions pas utiliser panic! pour gérer les conditions d’erreur dans la section [« Utiliser panic! ou ne pas utiliser panic! »][to-panic-or-not-to-panic] plus loin dans ce chapitre. Ensuite, nous verrons comment récupérer d’une erreur en utilisant Result.
Les erreurs récupérables avec Result
Les erreurs récupérables avec Result
La plupart des erreurs ne sont pas suffisamment graves pour nécessiter l’arrêt complet du programme. Parfois, lorsqu’une fonction échoue, c’est pour une raison que vous pouvez facilement interpréter et traiter. Par exemple, si vous essayez d’ouvrir un fichier et que cette opération échoue parce que le fichier n’existe pas, vous voudrez peut-être créer le fichier plutôt que de terminer le processus.
Rappelez-vous, dans [« Gérer les échecs potentiels avec Result »][handle_failure] au chapitre 2, que l’enum Result est définie comme ayant deux variantes, Ok et Err, comme suit :
#![allow(unused)]
fn main() {
enum Result<T, E> {
Ok(T),
Err(E),
}
}T et E sont des paramètres de type générique : nous aborderons les génériques plus en détail au chapitre 10. Ce que vous devez savoir pour l’instant, c’est que T représente le type de la valeur qui sera renvoyée en cas de succès dans la variante Ok, et E représente le type de l’erreur qui sera renvoyée en cas d’échec dans la variante Err. Comme Result possède ces paramètres de type générique, nous pouvons utiliser le type Result et les fonctions définies dessus dans de nombreuses situations différentes où la valeur de succès et la valeur d’erreur que nous voulons renvoyer peuvent différer.
Appelons une fonction qui renvoie une valeur Result parce que la fonction pourrait échouer. Dans l’encart 9-3, nous essayons d’ouvrir un fichier.
use std::fs::File;
fn main() {
let greeting_file_result = File::open("hello.txt");
}Le type de retour de File::open est un Result<T, E>. Le paramètre générique T a été rempli par l’implémentation de File::open avec le type de la valeur de succès, std::fs::File, qui est un descripteur de fichier. Le type de E utilisé dans la valeur d’erreur est std::io::Error. Ce type de retour signifie que l’appel à File::open pourrait réussir et renvoyer un descripteur de fichier à partir duquel nous pouvons lire ou écrire. L’appel de fonction pourrait également échouer : par exemple, le fichier pourrait ne pas exister, ou nous pourrions ne pas avoir la permission d’accéder au fichier. La fonction File::open a besoin d’un moyen de nous dire si elle a réussi ou échoué et en même temps de nous fournir soit le descripteur de fichier, soit les informations d’erreur. C’est exactement ce que l’enum Result transmet.
Dans le cas où File::open réussit, la valeur dans la variable greeting_file_result sera une instance de Ok contenant un descripteur de fichier. Dans le cas où elle échoue, la valeur dans greeting_file_result sera une instance de Err contenant plus d’informations sur le type d’erreur qui s’est produite.
Nous devons compléter le code de l’encart 9-3 pour effectuer différentes actions selon la valeur renvoyée par File::open. L’encart 9-4 montre une façon de gérer le Result en utilisant un outil de base, l’expression match que nous avons abordée au chapitre 6.
use std::fs::File;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => panic!("Problem opening the file: {error:?}"),
};
}match expression to handle the Result variants that might be returnedNotez que, comme l’enum Option, l’enum Result et ses variantes ont été importées dans la portée par le prelude, donc nous n’avons pas besoin de spécifier Result:: avant les variantes Ok et Err dans les branches du match.
Lorsque le résultat est Ok, ce code renverra la valeur interne file de la variante Ok, et nous assignons ensuite cette valeur de descripteur de fichier à la variable greeting_file. Après le match, nous pouvons utiliser le descripteur de fichier pour lire ou écrire.
L’autre branche du match gère le cas où nous obtenons une valeur Err de File::open. Dans cet exemple, nous avons choisi d’appeler la macro panic!. S’il n’y a pas de fichier nommé hello.txt dans notre répertoire actuel et que nous exécutons ce code, nous verrons la sortie suivante de la macro panic! : console {{#include ../listings/ch09-error-handling/listing-09-04/output.txt}}
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/error-handling`
thread 'main' panicked at src/main.rs:8:23:
Problem opening the file: Os { code: 2, kind: NotFound, message: "No such file or directory" }
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Comme d’habitude, cette sortie nous indique exactement ce qui s’est mal passé.
Réagir selon les différentes erreurs
Le code de l’encart 9-4 va appeler panic! quelle que soit la raison de l’échec de File::open. Cependant, nous voulons effectuer différentes actions selon les différentes raisons de l’échec. Si File::open a échoué parce que le fichier n’existe pas, nous voulons créer le fichier et renvoyer le descripteur du nouveau fichier. Si File::open a échoué pour toute autre raison – par exemple, parce que nous n’avions pas la permission d’ouvrir le fichier – nous voulons toujours que le code appelle panic! de la même manière que dans l’encart 9-4. Pour cela, nous ajoutons une expression match interne, montrée dans l’encart 9-5.
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let greeting_file_result = File::open("hello.txt");
let greeting_file = match greeting_file_result {
Ok(file) => file,
Err(error) => match error.kind() {
ErrorKind::NotFound => match File::create("hello.txt") {
Ok(fc) => fc,
Err(e) => panic!("Problem creating the file: {e:?}"),
},
_ => {
panic!("Problem opening the file: {error:?}");
}
},
};
}Le type de la valeur que File::open renvoie à l’intérieur de la variante Err est io::Error, qui est une structure fournie par la bibliothèque standard. Cette structure possède une méthode, kind, que nous pouvons appeler pour obtenir une valeur io::ErrorKind. L’enum io::ErrorKind est fournie par la bibliothèque standard et possède des variantes représentant les différents types d’erreurs qui peuvent résulter d’une opération d’io. La variante que nous voulons utiliser est ErrorKind::NotFound, qui indique que le fichier que nous essayons d’ouvrir n’existe pas encore. Donc, nous faisons un match sur greeting_file_result, mais nous avons aussi un match interne sur error.kind().
La condition que nous voulons vérifier dans le match interne est si la valeur renvoyée par error.kind() est la variante NotFound de l’enum ErrorKind. Si c’est le cas, nous essayons de créer le fichier avec File::create. Cependant, comme File::create pourrait également échouer, nous avons besoin d’une deuxième branche dans l’expression match interne. Lorsque le fichier ne peut pas être créé, un message d’erreur différent est affiché. La deuxième branche du match externe reste la même, de sorte que le programme panique pour toute erreur autre que l’erreur de fichier manquant.
Alternatives à l’utilisation de match avec Result<T, E>
Cela fait beaucoup de match ! L’expression match est très utile mais aussi très primitive. Au chapitre 13, vous apprendrez les fermetures (closures), qui sont utilisées avec beaucoup de méthodes définies sur Result<T, E>. Ces méthodes peuvent être plus concises que l’utilisation de match lors de la gestion des valeurs Result<T, E> dans votre code.
Par exemple, voici une autre façon d’écrire la même logique que celle montrée dans l’encart 9-5, cette fois en utilisant des fermetures et la méthode unwrap_or_else :
use std::fs::File;
use std::io::ErrorKind;
fn main() {
let greeting_file = File::open("hello.txt").unwrap_or_else(|error| {
if error.kind() == ErrorKind::NotFound {
File::create("hello.txt").unwrap_or_else(|error| {
panic!("Problem creating the file: {error:?}");
})
} else {
panic!("Problem opening the file: {error:?}");
}
});
}Bien que ce code ait le même comportement que l’encart 9-5, il ne contient aucune expression match et est plus agréable à lire. Revenez à cet exemple après avoir lu le chapitre 13 et consultez la méthode unwrap_or_else dans la documentation de la bibliothèque standard. Beaucoup d’autres méthodes de ce type peuvent simplifier d’énormes expressions match imbriquées lorsque vous gérez des erreurs.
Raccourcis pour paniquer en cas d’erreur
L’utilisation de match fonctionne assez bien, mais elle peut être un peu verbeuse et ne communique pas toujours bien l’intention. Le type Result<T, E> possède de nombreuses méthodes utilitaires définies dessus pour effectuer diverses tâches plus spécifiques. La méthode unwrap est une méthode raccourci implémentée exactement comme l’expression match que nous avons écrite dans l’encart 9-4. Si la valeur Result est la variante Ok, unwrap renverra la valeur à l’intérieur du Ok. Si le Result est la variante Err, unwrap appellera la macro panic! pour nous. Voici un exemple de unwrap en action :
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt").unwrap();
}Si nous exécutons ce code sans fichier hello.txt, nous verrons un message d’erreur provenant de l’appel à panic! que la méthode unwrap effectue :
thread 'main' panicked at src/main.rs:4:49:
called `Result::unwrap()` on an `Err` value: Os { code: 2, kind: NotFound, message: "No such file or directory" }
De la même manière, la méthode expect nous permet également de choisir le message d’erreur du panic!. Utiliser expect au lieu de unwrap et fournir de bons messages d’erreur peut transmettre votre intention et faciliter la recherche de l’origine d’un panic. La syntaxe de expect ressemble à ceci :
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt")
.expect("hello.txt should be included in this project");
}Nous utilisons expect de la même manière que unwrap : pour renvoyer le descripteur de fichier ou appeler la macro panic!. Le message d’erreur utilisé par expect dans son appel à panic! sera le paramètre que nous passons à expect, plutôt que le message par défaut de panic! qu’utilise unwrap. Voici à quoi cela ressemble :
thread 'main' panicked at src/main.rs:5:10:
hello.txt should be included in this project: Os { code: 2, kind: NotFound, message: "No such file or directory" }
Dans du code de qualité production, la plupart des Rustacés choisissent expect plutôt que unwrap et donnent plus de contexte sur la raison pour laquelle l’opération est censée toujours réussir. De cette façon, si vos hypothèses s’avèrent un jour incorrectes, vous avez plus d’informations à utiliser pour le débogage.
Propager les erreurs
Lorsque l’implémentation d’une fonction appelle quelque chose qui pourrait échouer, au lieu de gérer l’erreur au sein de la fonction elle-même, vous pouvez renvoyer l’erreur au code appelant afin qu’il puisse décider quoi faire. C’est ce qu’on appelle propager l’erreur, et cela donne plus de contrôle au code appelant, là où il pourrait y avoir plus d’informations ou de logique dictant comment l’erreur devrait être gérée que ce dont vous disposez dans le contexte de votre code.
Par exemple, l’encart 9-6 montre une fonction qui lit un nom d’utilisateur à partir d’un fichier. Si le fichier n’existe pas ou ne peut pas être lu, cette fonction renverra ces erreurs au code qui a appelé la fonction.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let username_file_result = File::open("hello.txt");
let mut username_file = match username_file_result {
Ok(file) => file,
Err(e) => return Err(e),
};
let mut username = String::new();
match username_file.read_to_string(&mut username) {
Ok(_) => Ok(username),
Err(e) => Err(e),
}
}
}matchCette fonction peut être écrite de manière beaucoup plus concise, mais nous allons commencer par faire beaucoup de choses manuellement afin d’explorer la gestion des erreurs ; à la fin, nous montrerons la manière plus courte. Examinons d’abord le type de retour de la fonction : Result<String, io::Error>. Cela signifie que la fonction renvoie une valeur du type Result<T, E>, où le paramètre générique T a été rempli avec le type concret String et le type générique E a été rempli avec le type concret io::Error.
Si cette fonction réussit sans aucun problème, le code qui appelle cette fonction recevra une valeur Ok contenant une String – le username que cette fonction a lu dans le fichier. Si cette fonction rencontre un problème, le code appelant recevra une valeur Err contenant une instance de io::Error qui contient plus d’informations sur la nature des problèmes. Nous avons choisi io::Error comme type de retour de cette fonction parce que c’est justement le type de la valeur d’erreur renvoyée par les deux opérations que nous appelons dans le corps de cette fonction et qui pourraient échouer : la fonction File::open et la méthode read_to_string.
Le corps de la fonction commence par appeler la fonction File::open. Ensuite, nous gérons la valeur Result avec un match similaire au match de l’encart 9-4. Si File::open réussit, le descripteur de fichier dans la variable de motif file devient la valeur dans la variable mutable username_file et la fonction continue. Dans le cas Err, au lieu d’appeler panic!, nous utilisons le mot-clé return pour sortir prématurément de la fonction et transmettre la valeur d’erreur de File::open, maintenant dans la variable de motif e, au code appelant comme valeur d’erreur de cette fonction.
Donc, si nous avons un descripteur de fichier dans username_file, la fonction crée ensuite une nouvelle String dans la variable username et appelle la méthode read_to_string sur le descripteur de fichier dans username_file pour lire le contenu du fichier dans username. La méthode read_to_string renvoie également un Result car elle pourrait échouer, même si File::open a réussi. Nous avons donc besoin d’un autre match pour gérer ce Result : si read_to_string réussit, alors notre fonction a réussi, et nous renvoyons le nom d’utilisateur du fichier qui se trouve maintenant dans username, enveloppé dans un Ok. Si read_to_string échoue, nous renvoyons la valeur d’erreur de la même manière que nous avons renvoyé la valeur d’erreur dans le match qui gérait la valeur de retour de File::open. Cependant, nous n’avons pas besoin de dire explicitement return, car c’est la dernière expression de la fonction.
Le code qui appelle ce code devra ensuite gérer soit une valeur Ok contenant un nom d’utilisateur, soit une valeur Err contenant un io::Error. C’est au code appelant de décider quoi faire avec ces valeurs. Si le code appelant obtient une valeur Err, il pourrait appeler panic! et faire planter le programme, utiliser un nom d’utilisateur par défaut, ou chercher le nom d’utilisateur ailleurs que dans un fichier, par exemple. Nous n’avons pas assez d’informations sur ce que le code appelant essaie réellement de faire, donc nous propageons toutes les informations de succès ou d’erreur vers le haut pour qu’il les gère de manière appropriée.
Ce patron de propagation des erreurs est tellement courant en Rust que Rust fournit l’opérateur point d’interrogation ? pour faciliter les choses.
Le raccourci de l’opérateur ?
L’encart 9-7 montre une implémentation de read_username_from_file qui à la même fonctionnalité que dans l’encart 9-6, mais cette implémentation utilise l’opérateur ?.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let mut username_file = File::open("hello.txt")?;
let mut username = String::new();
username_file.read_to_string(&mut username)?;
Ok(username)
}
}? operatorLe ? placé après une valeur Result est défini pour fonctionner presque de la même manière que les expressions match que nous avons définies pour gérer les valeurs Result dans l’encart 9-6. Si la valeur du Result est un Ok, la valeur à l’intérieur du Ok sera renvoyée par cette expression et le programme continuera. Si la valeur est un Err, le Err sera renvoyé par la fonction entière comme si nous avions utilisé le mot-clé return, de sorte que la valeur d’erreur est propagée au code appelant.
Il y à une différence entre ce que fait l’expression match de l’encart 9-6 et ce que fait l’opérateur ? : les valeurs d’erreur sur lesquelles l’opérateur ? est appelé passent par la fonction from, définie dans le trait From de la bibliothèque standard, qui est utilisée pour convertir des valeurs d’un type en un autre. Lorsque l’opérateur ? appelle la fonction from, le type d’erreur reçu est converti dans le type d’erreur défini dans le type de retour de la fonction courante. C’est utile lorsqu’une fonction renvoie un seul type d’erreur pour représenter toutes les façons dont une fonction peut échouer, même si certaines parties peuvent échouer pour de nombreuses raisons différentes.
Par exemple, nous pourrions modifier la fonction read_username_from_file de l’encart 9-7 pour renvoyer un type d’erreur personnalisé nommé OurError que nous définissons. Si nous définissons également impl From<io::Error> for OurError pour construire une instance de OurError à partir d’un io::Error, alors les appels à l’opérateur ? dans le corps de read_username_from_file appelleront from et convertiront les types d’erreur sans avoir besoin d’ajouter du code supplémentaire à la fonction.
Dans le contexte de l’encart 9-7, le ? à la fin de l’appel à File::open renverra la valeur à l’intérieur d’un Ok dans la variable username_file. Si une erreur se produit, l’opérateur ? sortira prématurément de la fonction entière et transmettra toute valeur Err au code appelant. La même chose s’applique au ? à la fin de l’appel à read_to_string.
L’opérateur ? élimine beaucoup de code répétitif et rend l’implémentation de cette fonction plus simple. Nous pourrions même raccourcir davantage ce code en enchaînant les appels de méthode immédiatement après le ?, comme montré dans l’encart 9-8.
#![allow(unused)]
fn main() {
use std::fs::File;
use std::io::{self, Read};
fn read_username_from_file() -> Result<String, io::Error> {
let mut username = String::new();
File::open("hello.txt")?.read_to_string(&mut username)?;
Ok(username)
}
}? operatorNous avons déplacé la création de la nouvelle String dans username au début de la fonction ; cette partie n’a pas changé. Au lieu de créer une variable username_file, nous avons enchaîné l’appel à read_to_string directement sur le résultat de File::open("hello.txt")?. Nous avons toujours un ? à la fin de l’appel à read_to_string, et nous renvoyons toujours une valeur Ok contenant username lorsque File::open et read_to_string réussissent tous les deux, plutôt que de renvoyer des erreurs. La fonctionnalité est à nouveau la même que dans les encarts 9-6 et 9-7 ; c’est simplement une manière différente et plus ergonomique de l’écrire.
L’encart 9-9 montre un moyen de rendre cela encore plus court en utilisant fs::read_to_string.
#![allow(unused)]
fn main() {
use std::fs;
use std::io;
fn read_username_from_file() -> Result<String, io::Error> {
fs::read_to_string("hello.txt")
}
}fs::read_to_string instead of opening and then reading the fileLire un fichier dans une chaîne de caractères est une opération assez courante, c’est pourquoi la bibliothèque standard fournit la fonction pratique fs::read_to_string qui ouvre le fichier, crée une nouvelle String, lit le contenu du fichier, place le contenu dans cette String et la renvoie. Bien sûr, utiliser fs::read_to_string ne nous donne pas l’occasion d’expliquer toute la gestion des erreurs, c’est pourquoi nous l’avons fait de la manière longue d’abord.
Où utiliser l’opérateur ?
L’opérateur ? ne peut être utilisé que dans les fonctions dont le type de retour est compatible avec la valeur sur laquelle le ? est utilisé. C’est parce que l’opérateur ? est défini pour effectuer un retour anticipé d’une valeur hors de la fonction, de la même manière que l’expression match que nous avons définie dans l’encart 9-6. Dans l’encart 9-6, le match utilisait une valeur Result, et la branche de retour anticipé renvoyait une valeur Err(e). Le type de retour de la fonction doit être un Result pour être compatible avec ce return.
Dans l’encart 9-10, examinons l’erreur que nous obtiendrons si nous utilisons l’opérateur ? dans une fonction main avec un type de retour incompatible avec le type de la valeur sur laquelle nous utilisons ?.
use std::fs::File;
fn main() {
let greeting_file = File::open("hello.txt")?;
}? in the main function that returns () won’t compile.Ce code ouvre un fichier, ce qui pourrait échouer. L’opérateur ? suit la valeur Result renvoyée par File::open, mais cette fonction main à le type de retour (), pas Result. Lorsque nous compilons ce code, nous obtenons le message d’erreur suivant : console {{#include ../listings/ch09-error-handling/listing-09-10/output.txt}}
$ cargo run
Compiling error-handling v0.1.0 (file:///projects/error-handling)
error[E0277]: the `?` operator can only be used in a function that returns `Result` or `Option` (or another type that implements `FromResidual`)
--> src/main.rs:4:48
|
3 | fn main() {
| --------- this function should return `Result` or `Option` to accept `?`
4 | let greeting_file = File::open("hello.txt")?;
| ^ cannot use the `?` operator in a function that returns `()`
|
help: consider adding return type
|
3 ~ fn main() -> Result<(), Box<dyn std::error::Error>> {
4 | let greeting_file = File::open("hello.txt")?;
5 + Ok(())
|
For more information about this error, try `rustc --explain E0277`.
error: could not compile `error-handling` (bin "error-handling") due to 1 previous error
Cette erreur indique que nous ne sommes autorisés à utiliser l’opérateur ? que dans une fonction qui renvoie Result, Option, ou un autre type qui implémente FromResidual.
Pour corriger l’erreur, vous avez deux choix. Un choix consiste à modifier le type de retour de votre fonction pour le rendre compatible avec la valeur sur laquelle vous utilisez l’opérateur ?, tant qu’il n’y a pas de restrictions qui l’empêchent. L’autre choix consiste à utiliser un match ou l’une des méthodes de Result<T, E> pour gérer le Result<T, E> de la manière appropriée.
Le message d’erreur mentionnait également que ? peut être utilisé avec des valeurs Option<T>. Comme avec l’utilisation de ? sur Result, vous ne pouvez utiliser ? sur Option que dans une fonction qui renvoie une Option. Le comportement de l’opérateur ? lorsqu’il est appelé sur un Option<T> est similaire à son comportement lorsqu’il est appelé sur un Result<T, E> : si la valeur est None, le None sera renvoyé prématurément par la fonction à ce moment-là. Si la valeur est Some, la valeur à l’intérieur du Some est la valeur résultante de l’expression, et la fonction continue. L’encart 9-11 contient un exemple de fonction qui trouve le dernier caractère de la première ligne dans le texte donné.
fn last_char_of_first_line(text: &str) -> Option<char> {
text.lines().next()?.chars().last()
}
fn main() {
assert_eq!(
last_char_of_first_line("Hello, world
How are you today?"),
Some('d')
);
assert_eq!(last_char_of_first_line(""), None);
assert_eq!(last_char_of_first_line("
hi"), None);
}? operator on an Option<T> valueCette fonction renvoie Option<char> parce qu’il est possible qu’il y ait un caractère, mais il est aussi possible qu’il n’y en ait pas. Ce code prend l’argument de tranche de chaîne text et appelle la méthode lines dessus, qui renvoie un itérateur sur les lignes de la chaîne. Comme cette fonction veut examiner la première ligne, elle appelle next sur l’itérateur pour obtenir la première valeur de l’itérateur. Si text est la chaîne vide, cet appel à next renverra None, auquel cas nous utilisons ? pour nous arrêter et renvoyer None depuis last_char_of_first_line. Si text n’est pas la chaîne vide, next renverra une valeur Some contenant une tranche de chaîne de la première ligne de text.
Le ? extrait la tranche de chaîne, et nous pouvons appeler chars sur cette tranche de chaîne pour obtenir un itérateur sur ses caractères. Nous nous intéressons au dernier caractère de cette première ligne, donc nous appelons last pour renvoyer le dernier élément de l’itérateur. C’est une Option parce qu’il est possible que la première ligne soit la chaîne vide ; par exemple, si text commence par une ligne vide mais contient des caractères sur d’autres lignes, comme dans " hi". Cependant, s’il y à un dernier caractère sur la première ligne, il sera renvoyé dans la variante Some. L’opérateur ? au milieu nous donne une manière concise d’exprimer cette logique, nous permettant d’implémenter la fonction en une seule ligne. Si nous ne pouvions pas utiliser l’opérateur ? sur Option, nous devrions implémenter cette logique en utilisant plus d’appels de méthode ou une expression match.
Notez que vous pouvez utiliser l’opérateur ? sur un Result dans une fonction qui renvoie Result, et vous pouvez utiliser l’opérateur ? sur une Option dans une fonction qui renvoie Option, mais vous ne pouvez pas mélanger les deux. L’opérateur ? ne convertira pas automatiquement un Result en Option ou vice versa ; dans ces cas, vous pouvez utiliser des méthodes comme la méthode ok sur Result ou la méthode ok_or sur Option pour effectuer la conversion explicitement.
Jusqu’à présent, toutes les fonctions main que nous avons utilisées renvoient (). La fonction main est spéciale car elle est le point d’entrée et de sortie d’un programme exécutable, et il y à des restrictions sur ce que son type de retour peut être pour que le programme se comporte comme prévu.
Heureusement, main peut également renvoyer un Result<(), E>. L’encart 9-12 reprend le code de l’encart 9-10, mais nous avons changé le type de retour de main en Result<(), Box<dyn Error>> et ajouté une valeur de retour Ok(()) à la fin. Ce code compilera maintenant.
use std::error::Error;
use std::fs::File;
fn main() -> Result<(), Box<dyn Error>> {
let greeting_file = File::open("hello.txt")?;
Ok(())
}main to return Result<(), E> allows the use of the ? operator on Result values.in Chapter 18. For now, you can read Box<dyn Error> to mean “any kind of error.” Using ? on a Result value in a main function with the error type Box<dyn Error> is allowed because it allows any Err value to be returned early. Even though the body of this main function will only ever return errors of type std::io::Error, by specifying Box<dyn Error>, this signature will continue to be correct even if more code that returns other errors is added to the body of main. –> Le type Box<dyn Error> est un objet trait, dont nous parlerons dans [« Utiliser des objets trait pour abstraire les comportements partagés »][trait-objects] au chapitre 18. Pour l’instant, vous pouvez lire Box<dyn Error> comme signifiant « n’importe quel type d’erreur ». Utiliser ? sur une valeur Result dans une fonction main avec le type d’erreur Box<dyn Error> est autorisé car cela permet à n’importe quelle valeur Err d’être renvoyée prématurément. Même si le corps de cette fonction main ne renverra jamais que des erreurs de type std::io::Error, en spécifiant Box<dyn Error>, cette signature restera correcte même si du code supplémentaire renvoyant d’autres erreurs est ajouté au corps de main.
Lorsqu’une fonction main renvoie un Result<(), E>, l’exécutable se terminera avec la valeur 0 si main renvoie Ok(()) et se terminera avec une valeur non nulle si main renvoie une valeur Err. Les exécutables écrits en C renvoient des entiers lorsqu’ils se terminent : les programmes qui se terminent avec succès renvoient l’entier 0, et les programmes qui échouent renvoient un entier autre que 0. Rust renvoie également des entiers depuis les exécutables pour être compatible avec cette convention.
La fonction main peut retourner n’importe quel type qui implémente le trait std::process::Termination, qui contient une fonction report retournant un ExitCode. Consultez la documentation de la bibliothèque standard pour plus d’informations sur l’implémentation du trait Termination pour vos propres types.
Maintenant que nous avons abordé les détails de l’appel à panic! ou du renvoi de Result, revenons au sujet de la façon de décider lequel est approprié dans quels cas.
panic! ou ne pas panic!
panic! ou ne pas panic!
Alors, comment décider quand vous devriez appeler panic! et quand vous devriez renvoyer Result ? Lorsque le code panique, il n’y à aucun moyen de récupérer. Vous pourriez appeler panic! pour n’importe quelle situation d’erreur, qu’il y ait un moyen possible de récupérer ou non, mais dans ce cas vous prenez la décision qu’une situation est irrécupérable au nom du code appelant. Lorsque vous choisissez de renvoyer une valeur Result, vous donnez des options au code appelant. Le code appelant pourrait choisir de tenter de récupérer d’une manière appropriée à sa situation, ou il pourrait décider qu’une valeur Err dans ce cas est irrécupérable, et ainsi appeler panic! pour transformer votre erreur récupérable en erreur irrécupérable. Par conséquent, renvoyer Result est un bon choix par défaut lorsque vous définissez une fonction qui pourrait échouer.
Dans des situations telles que les exemples, le code de prototypage et les tests, il est plus approprié d’écrire du code qui panique plutôt que de renvoyer un Result. Explorons pourquoi, puis discutons des situations dans lesquelles le compilateur ne peut pas déterminer que l’échec est impossible, mais vous en tant qu’humain le pouvez. Le chapitre se conclura par quelques directives générales sur la façon de décider s’il faut paniquer dans du code de bibliothèque.
Exemples, code de prototypage et tests
Lorsque vous écrivez un exemple pour illustrer un concept, inclure également du code robuste de gestion des erreurs peut rendre l’exemple moins clair. Dans les exemples, il est entendu qu’un appel à une méthode comme unwrap qui pourrait paniquer est destiné à servir de substitut pour la manière dont vous voudriez que votre application gère les erreurs, ce qui peut différer selon ce que fait le reste de votre code.
De la même manière, les méthodes unwrap et expect sont très pratiques lorsque vous faites du prototypage et que vous n’êtes pas encore prêt à décider comment gérer les erreurs. Elles laissent des marqueurs clairs dans votre code pour le moment où vous serez prêt à rendre votre programme plus robuste.
Si un appel de méthode échoue dans un test, vous voudriez que le test entier échoue, même si cette méthode n’est pas la fonctionnalité testée. Comme panic! est la façon dont un test est marqué comme échoué, appeler unwrap ou expect est exactement ce qui devrait se passer.
Quand vous en savez plus que le compilateur
Il serait également approprié d’appeler expect lorsque vous avez une autre logique qui garantit que le Result aura une valeur Ok, mais que cette logique n’est pas quelque chose que le compilateur comprend. Vous aurez toujours une valeur Result que vous devez gérer : quelle que soit l’opération que vous appelez, elle a toujours la possibilité d’échouer en général, même si c’est logiquement impossible dans votre situation particulière. Si vous pouvez garantir en inspectant manuellement le code que vous n’aurez jamais de variante Err, il est tout à fait acceptable d’appeler expect et de documenter la raison pour laquelle vous pensez ne jamais avoir de variante Err dans le texte de l’argument. Voici un exemple : rust {{#rustdoc_include ../listings/ch09-error-handling/no-listing-08-unwrap-that-cant-fail/src/main.rs:here}}
fn main() {
use std::net::IpAddr;
let home: IpAddr = "127.0.0.1"
.parse()
.expect("Hardcoded IP address should be valid");
}Nous créons une instance d’IpAddr en analysant une chaîne de caractères codée en dur. Nous pouvons voir que 127.0.0.1 est une adresse IP valide, il est donc acceptable d’utiliser expect ici. Cependant, avoir une chaîne valide codée en dur ne change pas le type de retour de la méthode parse : nous obtenons toujours une valeur Result, et le compilateur nous obligera toujours à gérer le Result comme si la variante Err était une possibilité, car le compilateur n’est pas assez intelligent pour voir que cette chaîne est toujours une adresse IP valide. Si la chaîne de l’adresse IP provenait d’un utilisateur plutôt que d’être codée en dur dans le programme et avait donc effectivement une possibilité d’échec, nous voudrions certainement gérer le Result de manière plus robuste. Mentionner l’hypothèse que cette adresse IP est codée en dur nous incitera à remplacer expect par un meilleur code de gestion des erreurs si, à l’avenir, nous devons obtenir l’adresse IP depuis une autre source.
Directives pour la gestion des erreurs
Il est conseillé de faire paniquer votre code lorsqu’il est possible que votre code se retrouve dans un état incohérent. Dans ce contexte, un état incohérent (bad state) survient lorsqu’une hypothèse, une garantie, un contrat ou un invariant a été violé, par exemple lorsque des valeurs invalides, contradictoires ou manquantes sont passées à votre code – plus une où plusieurs des conditions suivantes :
- L’état incohérent est quelque chose d’inattendu, par opposition à quelque chose qui se produira probablement de temps en temps, comme un utilisateur saisissant des données dans le mauvais format.
- Votre code après ce point doit pouvoir compter sur le fait de ne pas être dans cet état incohérent, plutôt que de vérifier le problème à chaque étape.
- Il n’y a pas de bonne façon d’encoder cette information dans les types que vous utilisez. Nous travaillerons sur un exemple de ce que nous voulons dire dans [« Encoder les états et les comportements comme des types »][encoding] au chapitre 18.
Si quelqu’un appelle votre code et passe des valeurs qui n’ont pas de sens, il est préférable de renvoyer une erreur si vous le pouvez afin que l’utilisateur de la bibliothèque puisse décider ce qu’il veut faire dans ce cas. Cependant, dans les cas où continuer pourrait être dangereux ou nuisible, le meilleur choix pourrait être d’appeler panic! et d’alerter la personne utilisant votre bibliothèque du bogue dans son code afin qu’elle puisse le corriger pendant le développement. De même, panic! est souvent approprié si vous appelez du code externe qui échappe à votre contrôle et qui renvoie un état invalide que vous n’avez aucun moyen de corriger.
Cependant, lorsque l’échec est attendu, il est plus approprié de renvoyer un Result que de faire un appel à panic!. Les exemples incluent un analyseur recevant des données malformées ou une requête HTTP renvoyant un statut indiquant que vous avez atteint une limite de débit. Dans ces cas, renvoyer un Result indique que l’échec est une possibilité attendue que le code appelant doit décider comment gérer.
Lorsque votre code effectue une opération qui pourrait mettre un utilisateur en danger si elle est appelée avec des valeurs invalides, votre code devrait vérifier que les valeurs sont valides en premier et paniquer si les valeurs ne sont pas valides. C’est principalement pour des raisons de sécurité : tenter d’opérer sur des données invalides peut exposer votre code à des vulnérabilités. C’est la raison principale pour laquelle la bibliothèque standard appellera panic! si vous tentez un accès mémoire hors limites : essayer d’accéder à de la mémoire qui n’appartient pas à la structure de données actuelle est un problème de sécurité courant. Les fonctions ont souvent des contrats : leur comportement n’est garanti que si les entrées satisfont des exigences particulières. Paniquer lorsque le contrat est violé est logique car une violation de contrat indique toujours un bogue du côté de l’appelant, et ce n’est pas un type d’erreur que vous voulez que le code appelant doive explicitement gérer. En fait, il n’y a pas de moyen raisonnable pour le code appelant de récupérer ; ce sont les programmeurs appelants qui doivent corriger le code. Les contrats d’une fonction, en particulier lorsqu’une violation provoquera un panic, devraient être expliqués dans la documentation de l’API de la fonction.
Cependant, avoir de nombreuses vérifications d’erreurs dans toutes vos fonctions serait verbeux et agaçant. Heureusement, vous pouvez utiliser le système de types de Rust (et donc la vérification de types effectuée par le compilateur) pour faire beaucoup de ces vérifications à votre place. Si votre fonction à un type particulier comme paramètre, vous pouvez poursuivre la logique de votre code en sachant que le compilateur a déjà garanti que vous avez une valeur valide. Par exemple, si vous avez un type plutôt qu’une Option, votre programme s’attend à avoir quelque chose plutôt que rien. Votre code n’a alors pas besoin de gérer deux cas pour les variantes Some et None : il n’aura qu’un seul cas pour avoir définitivement une valeur. Du code essayant de passer rien à votre fonction ne compilera même pas, donc votre fonction n’a pas besoin de vérifier ce cas à l’exécution. Un autre exemple est l’utilisation d’un type d’entier non signé comme u32, qui garantit que le paramètre n’est jamais négatif.
Types personnalisés pour la validation
Poussons l’idée d’utiliser le système de types de Rust pour garantir que nous avons une valeur valide un cran plus loin et examinons la création d’un type personnalisé pour la validation. Rappelez-vous le jeu de devinettes du chapitre 2 dans lequel notre code demandait à l’utilisateur de deviner un nombre entre 1 et 100. Nous n’avons jamais validé que la supposition de l’utilisateur se trouvait entre ces nombres avant de la comparer avec notre nombre secret ; nous avons seulement validé que la supposition était positive. Dans ce cas, les conséquences n’étaient pas très graves : notre affichage de « Trop grand » ou « Trop petit » serait toujours correct. Mais ce serait une amélioration utile de guider l’utilisateur vers des suppositions valides et d’avoir un comportement différent lorsque l’utilisateur devine un nombre hors de la plage par rapport à quand l’utilisateur tape, par exemple, des lettres à la place.
Une façon de faire cela serait d’analyser la supposition comme un i32 au lieu d’un u32 uniquement pour permettre des nombres potentiellement négatifs, puis d’ajouter une vérification que le nombre est dans la plage, comme ceci :
use rand::Rng;
use std::cmp::Ordering;
use std::io;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
loop {
// --snip--
println!("Please input your guess.");
let mut guess = String::new();
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: i32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
if guess < 1 || guess > 100 {
println!("The secret number will be between 1 and 100.");
continue;
}
match guess.cmp(&secret_number) {
// --snip--
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}L’expression if vérifie si notre valeur est hors de la plage, informe l’utilisateur du problème et appelle continue pour démarrer la prochaine itération de la boucle et demander une autre supposition. Après l’expression if, nous pouvons poursuivre avec les comparaisons entre guess et le nombre secret en sachant que guess est entre 1 et 100.
Cependant, ce n’est pas une solution idéale : s’il était absolument critique que le programme n’opère que sur des valeurs entre 1 et 100, et qu’il avait de nombreuses fonctions avec cette exigence, avoir une vérification comme celle-ci dans chaque fonction serait fastidieux (et pourrait impacter les performances).
À la place, nous pouvons créer un nouveau type dans un module dédié et placer les validations dans une fonction qui crée une instance du type plutôt que de répéter les validations partout. De cette façon, les fonctions peuvent utiliser le nouveau type dans leurs signatures en toute sécurité et utiliser avec confiance les valeurs qu’elles reçoivent. L’encart 9-13 montre une façon de définir un type Guess qui ne créera une instance de Guess que si la fonction new reçoit une valeur entre 1 et 100.
#![allow(unused)]
fn main() {
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
pub fn value(&self) -> i32 {
self.value
}
}
}Guess type that will only continue with values between 1 and 100Notez que ce code dans src/guessing_game.rs dépend de l’ajout d’une déclaration de module mod guessing_game; dans src/lib.rs que nous n’avons pas montrée ici. Dans le fichier de ce nouveau module, nous définissons une structure nommée Guess qui à un champ nommé value contenant un i32. C’est là que le nombre sera stocké.
Ensuite, nous implémentons une fonction associée nommée new sur Guess qui crée des instances de valeurs Guess. La fonction new est définie avec un paramètre nommé value de type i32 et renvoie un Guess. Le code dans le corps de la fonction new teste value pour s’assurer qu’il est entre 1 et 100. Si value ne passe pas ce test, nous faisons un appel à panic!, qui alertera le programmeur écrivant le code appelant qu’il à un bogue qu’il doit corriger, car créer un Guess avec une value en dehors de cette plage violerait le contrat sur lequel Guess::new s’appuie. Les conditions dans lesquelles Guess::new pourrait paniquer devraient être discutées dans sa documentation d’API publique ; nous couvrirons les conventions de documentation indiquant la possibilité d’un panic! dans la documentation d’API que vous créerez au chapitre 14. Si value passe le test, nous créons un nouveau Guess avec son champ value défini sur le paramètre value et renvoyons le Guess.
Ensuite, nous implémentons une méthode nommée value qui emprunté self, n’à aucun autre paramètre et renvoie un i32. Ce type de méthode est parfois appelé un getter car son but est d’obtenir des données de ses champs et de les renvoyer. Cette méthode publique est nécessaire car le champ value de la structure Guess est privé. Il est important que le champ value soit privé afin que le code utilisant la structure Guess ne soit pas autorisé à définir value directement : le code en dehors du module guessing_game doit utiliser la fonction Guess::new pour créer une instance de Guess, garantissant ainsi qu’il n’y à aucun moyen pour un Guess d’avoir une value qui n’a pas été vérifiée par les conditions de la fonction Guess::new.
Une fonction qui à un paramètre ou ne renvoie que des nombres entre 1 et 100 pourrait alors déclarer dans sa signature qu’elle prend ou renvoie un Guess plutôt qu’un i32 et n’aurait pas besoin de faire de vérifications supplémentaires dans son corps.
Résumé
Les fonctionnalités de gestion des erreurs de Rust sont conçues pour vous aider à écrire du code plus robuste. La macro panic! signale que votre programme est dans un état qu’il ne peut pas gérer et vous permet de dire au processus de s’arrêter au lieu d’essayer de continuer avec des valeurs invalides ou incorrectes. L’enum Result utilise le système de types de Rust pour indiquer que des opérations pourraient échouer d’une manière dont votre code pourrait récupérer. Vous pouvez utiliser Result pour indiquer au code qui appelle votre code qu’il doit également gérer le succès ou l’échec potentiel. Utiliser panic! et Result dans les situations appropriées rendra votre code plus fiable face aux problèmes inévitables.
Maintenant que vous avez vu des manières utiles dont la bibliothèque standard utilise les génériques avec les enums Option et Result, nous parlerons de la façon dont les génériques fonctionnent et comment vous pouvez les utiliser dans votre code.
Les types génériques, les traits et les durées de vie
Chaque langage de programmation dispose d’outils pour gérer efficacement la duplication de concepts. En Rust, l’un de ces outils est la généricité : des substituts abstraits pour des types concrets ou d’autres propriétés. Nous pouvons exprimer le comportement des génériques ou la manière dont ils interagissent entre eux sans savoir ce qui les remplacera lors de la compilation et de l’exécution du code.
Les fonctions peuvent prendre des paramètres d’un type générique, plutôt qu’un type concret comme i32 ou String, de la même manière qu’elles prennent des paramètres avec des valeurs inconnues pour exécuter le même code sur plusieurs valeurs concrètes. En fait, nous avons déjà utilisé les génériques au chapitre 6 avec Option<T>, au chapitre 8 avec Vec<T> et HashMap<K, V>, et au chapitre 9 avec Result<T, E>. Dans ce chapitre, vous découvrirez comment définir vos propres types, fonctions et méthodes avec des génériques !
D’abord, nous reverrons comment extraire une fonction pour réduire la duplication de code. Nous utiliserons ensuite la même technique pour créer une fonction générique à partir de deux fonctions qui ne diffèrent que par les types de leurs paramètres. Nous expliquerons aussi comment utiliser les types génériques dans les définitions de structs et d’énumérations.
Ensuite, vous apprendrez à utiliser les traits pour définir un comportement de manière générique. Vous pouvez combiner les traits avec les types génériques pour contraindre un type générique à n’accepter que les types qui ont un comportement particulier, plutôt que n’importe quel type.
Enfin, nous aborderons les durées de vie (lifetimes) : une variété de génériques qui donnent au compilateur des informations sur la manière dont les références sont liées entre elles. Les durées de vie nous permettent de donner au compilateur suffisamment d’informations sur les valeurs empruntées pour qu’il puisse garantir que les références seront valides dans plus de situations qu’il ne le pourrait sans notre aide.
Éliminer la duplication en extrayant une fonction
Les génériques nous permettent de remplacer des types spécifiques par un espace réservé qui représente plusieurs types afin d’éliminer la duplication de code. Avant de plonger dans la syntaxe des génériques, voyons d’abord comment éliminer la duplication d’une manière qui n’implique pas de types génériques, en extrayant une fonction qui remplace des valeurs spécifiques par un espace réservé représentant plusieurs valeurs. Ensuite, nous appliquerons la même technique pour extraire une fonction générique ! En apprenant à reconnaître le code dupliqué que vous pouvez extraire dans une fonction, vous commencerez à reconnaître le code dupliqué qui peut utiliser des génériques.
Nous commencerons par le court programme de l’encart 10-1 qui trouve le plus grand nombre dans une liste.
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let mut largest = &number_list[0];
for number in &number_list {
if number > largest {
largest = number;
}
}
println!("The largest number is {largest}");
assert_eq!(*largest, 100);
}Nous stockons une liste d’entiers dans la variable number_list et plaçons une référence vers le premier nombre de la liste dans une variable nommée largest. Nous itérons ensuite sur tous les nombres de la liste, et si le nombre actuel est supérieur au nombre stocké dans largest, nous remplaçons la référence dans cette variable. En revanche, si le nombre actuel est inférieur ou égal au plus grand nombre rencontré jusqu’à présent, la variable ne change pas, et le code passe au nombre suivant dans la liste. Après avoir examiné tous les nombres de la liste, largest devrait référencer le plus grand nombre, qui dans ce cas est 100.
On nous demande maintenant de trouver le plus grand nombre dans deux listes de nombres différentes. Pour ce faire, nous pouvons choisir de dupliquer le code de l’encart 10-1 et utiliser la même logique à deux endroits différents du programme, comme le montre l’encart 10-2.
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let mut largest = &number_list[0];
for number in &number_list {
if number > largest {
largest = number;
}
}
println!("The largest number is {largest}");
let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8];
let mut largest = &number_list[0];
for number in &number_list {
if number > largest {
largest = number;
}
}
println!("The largest number is {largest}");
}Bien que ce code fonctionne, dupliquer du code est fastidieux et source d’erreurs. Nous devons aussi nous souvenir de mettre à jour le code à plusieurs endroits lorsque nous voulons le modifier.
Pour éliminer cette duplication, nous allons créer une abstraction en définissant une fonction qui opère sur n’importe quelle liste d’entiers passée en paramètre. Cette solution rend notre code plus clair et nous permet d’exprimer de manière abstraite le concept de recherche du plus grand nombre dans une liste.
Dans l’encart 10-3, nous extrayons le code qui trouve le plus grand nombre dans une fonction nommée largest. Ensuite, nous appelons la fonction pour trouver le plus grand nombre dans les deux listes de l’encart 10-2. Nous pourrions aussi utiliser la fonction sur n’importe quelle autre liste de valeurs i32 que nous pourrions avoir à l’avenir.
fn largest(list: &[i32]) -> &i32 {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {result}");
assert_eq!(*result, 100);
let number_list = vec![102, 34, 6000, 89, 54, 2, 43, 8];
let result = largest(&number_list);
println!("The largest number is {result}");
assert_eq!(*result, 6000);
}La fonction largest à un paramètre appelé list, qui représente n’importe quelle slice concrète de valeurs i32 que nous pourrions passer à la fonction. En conséquence, lorsque nous appelons la fonction, le code s’exécute sur les valeurs spécifiques que nous lui passons.
En résumé, voici les étapes que nous avons suivies pour transformer le code de l’encart 10-2 en l’encart 10-3 :
- Identifier le code dupliqué.
- Extraire le code dupliqué dans le corps de la fonction, et spécifier les entrées et valeurs de retour de ce code dans la signature de la fonction.
- Mettre à jour les deux instances de code dupliqué pour appeler la fonction à la place.
Ensuite, nous utiliserons ces mêmes étapes avec les génériques pour réduire la duplication de code. De la même manière que le corps de la fonction peut opérer sur une list abstraite plutôt que sur des valeurs spécifiques, les génériques permettent au code d’opérer sur des types abstraits.
Par exemple, supposons que nous ayons deux fonctions : l’une qui trouve le plus grand élément dans une slice de valeurs i32 et l’autre qui trouve le plus grand élément dans une slice de valeurs char. Comment éliminerions-nous cette duplication ? Découvrons-le !
Les types de données génériques
Les types de données génériques
Nous utilisons les génériques pour créer des définitions d’éléments comme des signatures de fonctions ou des structs, que nous pouvons ensuite utiliser avec de nombreux types de données concrets. Voyons d’abord comment définir des fonctions, des structs, des énumérations et des méthodes en utilisant les génériques. Ensuite, nous verrons comment les génériques affectent les performances du code.
Dans les définitions de fonctions
Lorsque nous définissons une fonction qui utilise des génériques, nous plaçons les génériques dans la signature de la fonction à l’endroit où nous spécifierions normalement les types de données des paramètres et de la valeur de retour. Ce faisant, notre code devient plus flexible et offre plus de fonctionnalités aux appelants de notre fonction tout en évitant la duplication de code.
En poursuivant avec notre fonction largest, l’encart 10-4 montre deux fonctions qui trouvent toutes deux la plus grande valeur dans une slice. Nous les combinerons ensuite en une seule fonction qui utilise des génériques.
fn largest_i32(list: &[i32]) -> &i32 {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn largest_char(list: &[char]) -> &char {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest_i32(&number_list);
println!("The largest number is {result}");
assert_eq!(*result, 100);
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest_char(&char_list);
println!("The largest char is {result}");
assert_eq!(*result, 'y');
}La fonction largest_i32 est celle que nous avons extraite dans l’encart 10-3 et qui trouve le plus grand i32 dans une slice. La fonction largest_char trouve le plus grand char dans une slice. Les corps des fonctions contiennent le même code, alors éliminons la duplication en introduisant un paramètre de type générique dans une seule fonction.
Pour paramétrer les types dans une nouvelle fonction unique, nous devons nommer le paramètre de type, tout comme nous le faisons pour les paramètres de valeur d’une fonction. Vous pouvez utiliser n’importe quel identifiant comme nom de paramètre de type. Mais nous utiliserons T car, par convention, les noms de paramètres de type en Rust sont courts, souvent une seule lettre, et la convention de nommage des types en Rust est l’UpperCamelCase. Abréviation de type, T est le choix par défaut de la plupart des programmeurs Rust.
Lorsque nous utilisons un paramètre dans le corps de la fonction, nous devons déclarer le nom du paramètre dans la signature pour que le compilateur sache ce que ce nom signifie. De même, lorsque nous utilisons un nom de paramètre de type dans une signature de fonction, nous devons déclarer le nom du paramètre de type avant de l’utiliser. Pour définir la fonction générique largest, nous plaçons les déclarations de noms de types entre chevrons, <>, entre le nom de la fonction et la liste des paramètres, comme ceci :
fn largest<T>(list: &[T]) -> &T {Nous lisons cette définition comme : « La fonction largest est générique sur un certain type T. » Cette fonction à un paramètre nommé list, qui est une slice de valeurs de type T. La fonction largest retournera une référence vers une valeur du même type T.
L’encart 10-5 montre la définition combinée de la fonction largest utilisant le type de données générique dans sa signature. L’encart montre aussi comment nous pouvons appeler la fonction avec une slice de valeurs i32 ou de valeurs char. Notez que ce code ne compilera pas encore.
fn largest<T>(list: &[T]) -> &T {
let mut largest = &list[0];
for item in list {
if item > largest {
largest = item;
}
}
largest
}
fn main() {
let number_list = vec![34, 50, 25, 100, 65];
let result = largest(&number_list);
println!("The largest number is {result}");
let char_list = vec!['y', 'm', 'a', 'q'];
let result = largest(&char_list);
println!("The largest char is {result}");
}largest function using generic type parameters; this doesn’t compile yetSi nous compilons ce code maintenant, nous obtiendrons cette erreur : console {{#include ../listings/ch10-generic-types-traits-and-lifetimes/listing-10-05/output.txt}}
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0369]: binary operation `>` cannot be applied to type `&T`
--> src/main.rs:5:17
|
5 | if item > largest {
| ---- ^ ------- &T
| |
| &T
|
help: consider restricting type parameter `T` with trait `PartialOrd`
|
1 | fn largest<T: std::cmp::PartialOrd>(list: &[T]) -> &T {
| ++++++++++++++++++++++
For more information about this error, try `rustc --explain E0369`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Le texte d’aide mentionné std::cmp::PartialOrd, qui est un trait, et nous allons parler des traits dans la prochaine section. Pour l’instant, sachez que cette erreur indique que le corps de largest ne fonctionnera pas pour tous les types possibles que T pourrait être. Comme nous voulons comparer des valeurs de type T dans le corps, nous ne pouvons utiliser que des types dont les valeurs peuvent être ordonnées. Pour permettre les comparaisons, la bibliothèque standard dispose du trait std::cmp::PartialOrd que vous pouvez implémenter sur les types (voir l’annexe C pour plus d’informations sur ce trait). Pour corriger l’encart 10-5, nous pouvons suivre la suggestion du texte d’aide et restreindre les types valides pour T à ceux qui implémentent PartialOrd. L’encart compilera alors, car la bibliothèque standard implémente PartialOrd pour i32 et char.
Dans les définitions de structs
Nous pouvons aussi définir des structs qui utilisent un paramètre de type générique dans un où plusieurs champs en utilisant la syntaxe <>. L’encart 10-6 définit une struct Point<T> pour contenir des valeurs de coordonnées x et y de n’importe quel type.
struct Point<T> {
x: T,
y: T,
}
fn main() {
let integer = Point { x: 5, y: 10 };
let float = Point { x: 1.0, y: 4.0 };
}Point<T> struct that holds x and y values of type TLa syntaxe pour utiliser les génériques dans les définitions de structs est similaire à celle utilisée dans les définitions de fonctions. D’abord, nous déclarons le nom du paramètre de type entre chevrons juste après le nom de la struct. Ensuite, nous utilisons le type générique dans la définition de la struct là où nous spécifierions autrement des types de données concrets.
Notez que, comme nous n’avons utilisé qu’un seul type générique pour définir Point<T>, cette définition indique que la struct Point<T> est générique sur un certain type T, et que les champs x et y sont tous les deux de ce même type, quel qu’il soit. Si nous créons une instance de Point<T> avec des valeurs de types différents, comme dans l’encart 10-7, notre code ne compilera pas.
struct Point<T> {
x: T,
y: T,
}
fn main() {
let wont_work = Point { x: 5, y: 4.0 };
}x and y must be the same type because both have the same generic data type T.Dans cet exemple, lorsque nous assignons la valeur entière 5 à x, nous informons le compilateur que le type générique T sera un entier pour cette instance de Point<T>. Ensuite, lorsque nous spécifions 4.0 pour y, que nous avons défini comme ayant le même type que x, nous obtiendrons une erreur de non-correspondance de type comme celle-ci : console {{#include ../listings/ch10-generic-types-traits-and-lifetimes/listing-10-07/output.txt}}
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0308]: mismatched types
--> src/main.rs:7:38
|
7 | let wont_work = Point { x: 5, y: 4.0 };
| ^^^ expected integer, found floating-point number
For more information about this error, try `rustc --explain E0308`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Pour définir une struct Point où x et y sont tous les deux génériques mais pourraient avoir des types différents, nous pouvons utiliser plusieurs paramètres de type générique. Par exemple, dans l’encart 10-8, nous changeons la définition de Point pour qu’elle soit générique sur les types T et U, où x est de type T et y est de type U.
struct Point<T, U> {
x: T,
y: U,
}
fn main() {
let both_integer = Point { x: 5, y: 10 };
let both_float = Point { x: 1.0, y: 4.0 };
let integer_and_float = Point { x: 5, y: 4.0 };
}Point<T, U> generic over two types so that x and y can be values of different typesMaintenant, toutes les instances de Point présentées sont autorisées ! Vous pouvez utiliser autant de paramètres de type générique que vous le souhaitez dans une définition, mais en utiliser trop rend votre code difficile à lire. Si vous constatez que vous avez besoin de beaucoup de types génériques dans votre code, cela pourrait indiquer que votre code a besoin d’être restructuré en morceaux plus petits.
Dans les définitions d’énumérations
Comme nous l’avons fait avec les structs, nous pouvons définir des énumérations qui contiennent des types de données génériques dans leurs variantes. Regardons à nouveau l’énumération Option<T> que la bibliothèque standard fournit et que nous avons utilisée au chapitre 6 :
#![allow(unused)]
fn main() {
enum Option<T> {
Some(T),
None,
}
}Cette définition devrait maintenant avoir plus de sens pour vous. Comme vous pouvez le voir, l’énumération Option<T> est générique sur le type T et possède deux variantes : Some, qui contient une valeur de type T, et une variante None qui ne contient aucune valeur. En utilisant l’énumération Option<T>, nous pouvons exprimer le concept abstrait d’une valeur optionnelle, et comme Option<T> est générique, nous pouvons utiliser cette abstraction quel que soit le type de la valeur optionnelle.
Les énumérations peuvent aussi utiliser plusieurs types génériques. La définition de l’énumération Result que nous avons utilisée au chapitre 9 en est un exemple :
#![allow(unused)]
fn main() {
enum Result<T, E> {
Ok(T),
Err(E),
}
}L’énumération Result est générique sur deux types, T et E, et possède deux variantes : Ok, qui contient une valeur de type T, et Err, qui contient une valeur de type E. Cette définition rend pratique l’utilisation de l’énumération Result partout où nous avons une opération qui peut réussir (retourner une valeur d’un certain type T) ou échouer (retourner une erreur d’un certain type E). En fait, c’est ce que nous avons utilisé pour ouvrir un fichier dans l’encart 9-3, où T a été rempli avec le type std::fs::File lorsque le fichier a été ouvert avec succès et E a été rempli avec le type std::io::Error lorsqu’il y a eu des problèmes à l’ouverture du fichier.
Lorsque vous reconnaissez dans votre code des situations avec plusieurs définitions de structs ou d’énumérations qui ne diffèrent que par les types des valeurs qu’elles contiennent, vous pouvez éviter la duplication en utilisant des types génériques à la place.
Dans les définitions de méthodes
Nous pouvons implémenter des méthodes sur les structs et les énumérations (comme nous l’avons fait au chapitre 5) et utiliser des types génériques dans leurs définitions aussi. L’encart 10-9 montre la struct Point<T> que nous avons définie dans l’encart 10-6 avec une méthode nommée x implémentée dessus.
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.x());
}x on the Point<T> struct that will return a reference to the x field of type TIci, nous avons défini une méthode nommée x sur Point<T> qui retourné une référence vers les données du champ x.
Notez que nous devons déclarer T juste après impl pour pouvoir utiliser T afin de spécifier que nous implémentons des méthodes sur le type Point<T>. En déclarant T comme type générique après impl, Rust peut identifier que le type entre chevrons dans Point est un type générique plutôt qu’un type concret. Nous aurions pu choisir un nom différent pour ce paramètre générique par rapport au paramètre générique déclaré dans la définition de la struct, mais utiliser le même nom est conventionnel. Si vous écrivez une méthode dans un impl qui déclare un type générique, cette méthode sera définie sur n’importe quelle instance du type, quel que soit le type concret qui finit par se substituer au type générique.
Nous pouvons aussi spécifier des contraintes sur les types génériques lors de la définition de méthodes sur le type. Nous pourrions, par exemple, implémenter des méthodes uniquement sur les instances de Point<f32> plutôt que sur les instances de Point<T> avec n’importe quel type générique. Dans l’encart 10-10, nous utilisons le type concret f32, ce qui signifie que nous ne déclarons aucun type après impl.
struct Point<T> {
x: T,
y: T,
}
impl<T> Point<T> {
fn x(&self) -> &T {
&self.x
}
}
impl Point<f32> {
fn distance_from_origin(&self) -> f32 {
(self.x.powi(2) + self.y.powi(2)).sqrt()
}
}
fn main() {
let p = Point { x: 5, y: 10 };
println!("p.x = {}", p.x());
}impl block that only applies to a struct with a particular concrete type for the generic type parameter TCe code signifie que le type Point<f32> aura une méthode distance_from_origin ; les autres instances de Point<T> où T n’est pas de type f32 n’auront pas cette méthode définie. La méthode mesure la distance entre notre point et le point aux coordonnées (0.0, 0.0) et utilise des opérations mathématiques qui ne sont disponibles que pour les types à virgule flottante.
Les paramètres de type générique dans une définition de struct ne sont pas toujours les mêmes que ceux que vous utilisez dans les signatures de méthodes de cette même struct. L’encart 10-11 utilise les types génériques X1 et Y1 pour la struct Point et X2 et Y2 pour la signature de la méthode mixup afin de rendre l’exemple plus clair. La méthode crée une nouvelle instance de Point avec la valeur x du Point self (de type X1) et la valeur y du Point passé en argument (de type Y2).
struct Point<X1, Y1> {
x: X1,
y: Y1,
}
impl<X1, Y1> Point<X1, Y1> {
fn mixup<X2, Y2>(self, other: Point<X2, Y2>) -> Point<X1, Y2> {
Point {
x: self.x,
y: other.y,
}
}
}
fn main() {
let p1 = Point { x: 5, y: 10.4 };
let p2 = Point { x: "Hello", y: 'c' };
let p3 = p1.mixup(p2);
println!("p3.x = {}, p3.y = {}", p3.x, p3.y);
}Dans main, nous avons défini un Point qui à un i32 pour x (avec la valeur 5) et un f64 pour y (avec la valeur 10.4). La variable p2 est une struct Point qui à une slice de chaîne de caractères pour x (avec la valeur "Hello") et un char pour y (avec la valeur c). Appeler mixup sur p1 avec l’argument p2 nous donne p3, qui aura un i32 pour x car x vient de p1. La variable p3 aura un char pour y car y vient de p2. L’appel de la macro println! affichera p3.x = 5, p3.y = c.
Le but de cet exemple est de démontrer une situation dans laquelle certains paramètres génériques sont déclarés avec impl et d’autres sont déclarés avec la définition de la méthode. Ici, les paramètres génériques X1 et Y1 sont déclarés après impl car ils accompagnent la définition de la struct. Les paramètres génériques X2 et Y2 sont déclarés après fn mixup car ils ne sont pertinents que pour la méthode.
Performances du code utilisant les génériques
Vous vous demandez peut-être s’il y à un coût à l’exécution lors de l’utilisation de paramètres de type générique. La bonne nouvelle est que l’utilisation de types génériques ne ralentira pas votre programme par rapport à l’utilisation de types concrets.
Rust accomplit cela en effectuant la monomorphisation du code utilisant les génériques au moment de la compilation. La monomorphisation est le processus de transformation du code générique en code spécifique en remplissant les types concrets utilisés lors de la compilation. Dans ce processus, le compilateur fait l’inverse des étapes que nous avons utilisées pour créer la fonction générique dans l’encart 10-5 : le compilateur examine tous les endroits où le code générique est appelé et génère du code pour les types concrets avec lesquels le code générique est appelé.
Voyons comment cela fonctionne en utilisant l’énumération générique Option<T> de la bibliothèque standard :
#![allow(unused)]
fn main() {
let integer = Some(5);
let float = Some(5.0);
}Lorsque Rust compilé ce code, il effectue la monomorphisation. Au cours de ce processus, le compilateur lit les valeurs qui ont été utilisées dans les instances d’Option<T> et identifie deux sortes d’Option<T> : l’une est i32 et l’autre est f64. Ainsi, il développe la définition générique d’Option<T> en deux définitions spécialisées pour i32 et f64, remplaçant ainsi la définition générique par les définitions spécifiques.
La version monomorphisée du code ressemble à ce qui suit (le compilateur utilise des noms différents de ceux que nous utilisons ici à titre d’illustration) :
enum Option_i32 {
Some(i32),
None,
}
enum Option_f64 {
Some(f64),
None,
}
fn main() {
let integer = Option_i32::Some(5);
let float = Option_f64::Some(5.0);
}Le Option<T> générique est remplacé par les définitions spécifiques créées par le compilateur. Comme Rust compilé le code générique en code qui spécifie le type dans chaque instance, nous ne payons aucun coût à l’exécution pour l’utilisation des génériques. Lorsque le code s’exécute, il se comporte exactement comme si nous avions dupliqué chaque définition à la main. Le processus de monomorphisation rend les génériques de Rust extrêmement efficaces à l’exécution.
Définir un comportement partagé avec les traits
Définir un comportement partagé avec les traits
Un trait définit la fonctionnalité qu’un type particulier possède et peut partager avec d’autres types. Nous pouvons utiliser les traits pour définir un comportement partagé de manière abstraite. Nous pouvons utiliser les trait bounds (limites de trait) pour spécifier qu’un type générique peut être n’importe quel type possédant un certain comportement.
Remarque : les traits sont similaires à une fonctionnalité souvent appelée interfaces dans d’autres langages, bien qu’avec quelques différences.
Définir un trait
Le comportement d’un type consiste en les méthodes que nous pouvons appeler sur ce type. Différents types partagent le même comportement si nous pouvons appeler les mêmes méthodes sur chacun de ces types. Les définitions de traits sont un moyen de regrouper des signatures de méthodes pour définir un ensemble de comportements nécessaires pour accomplir un certain objectif.
Par exemple, supposons que nous ayons plusieurs structs qui contiennent différents types et quantités de texte : une struct NewsArticle qui contient un article de presse classé dans un lieu particulier et un SocialPost qui peut avoir au maximum 280 caractères avec des métadonnées indiquant s’il s’agissait d’une nouvelle publication, d’un repartage ou d’une réponse à une autre publication.
Nous voulons créer une crate de bibliothèque d’agrégation de médias nommée aggregator qui peut afficher des résumés de données qui pourraient être stockées dans une instance de NewsArticle ou de SocialPost. Pour cela, nous avons besoin d’un résumé de chaque type, et nous demanderons ce résumé en appelant une méthode summarize sur une instance. L’encart 10-12 montre la définition d’un trait public Summary qui exprime ce comportement.
pub trait Summary {
fn summarize(&self) -> String;
}Summary trait that consists of the behavior provided by a summarize methodIci, nous déclarons un trait en utilisant le mot-clé trait puis le nom du trait, qui est Summary dans ce cas. Nous déclarons aussi le trait comme pub pour que les crates qui dépendent de cette crate puissent aussi utiliser ce trait, comme nous le verrons dans quelques exemples. À l’intérieur des accolades, nous déclarons les signatures de méthodes qui décrivent les comportements des types qui implémentent ce trait, ce qui dans ce cas est fn summarize(&self) -> String.
Après la signature de la méthode, au lieu de fournir une implémentation entre accolades, nous utilisons un point-virgule. Chaque type implémentant ce trait doit fournir son propre comportement personnalisé pour le corps de la méthode. Le compilateur s’assurera que tout type qui possède le trait Summary aura la méthode summarize définie avec exactement cette signature.
Un trait peut avoir plusieurs méthodes dans son corps : les signatures de méthodes sont listées une par ligne, et chaque ligne se terminé par un point-virgule.
Implémenter un trait sur un type
Maintenant que nous avons défini les signatures souhaitées des méthodes du trait Summary, nous pouvons l’implémenter sur les types de notre agrégateur de médias. L’encart 10-13 montre une implémentation du trait Summary sur la struct NewsArticle qui utilise le titre, l’auteur et le lieu pour créer la valeur de retour de summarize. Pour la struct SocialPost, nous définissons summarize comme le nom d’utilisateur suivi du texte entier de la publication, en supposant que le contenu de la publication est déjà limité à 280 caractères.
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}Summary trait on the NewsArticle and SocialPost typesImplémenter un trait sur un type est similaire à implémenter des méthodes classiques. La différence est qu’après impl, nous mettons le nom du trait que nous voulons implémenter, puis nous utilisons le mot-clé for, puis nous spécifions le nom du type sur lequel nous voulons implémenter le trait. À l’intérieur du bloc impl, nous mettons les signatures de méthodes que la définition du trait a définies. Au lieu d’ajouter un point-virgule après chaque signature, nous utilisons des accolades et remplissons le corps de la méthode avec le comportement spécifique que nous voulons que les méthodes du trait aient pour le type particulier.
Maintenant que la bibliothèque a implémenté le trait Summary sur NewsArticle et SocialPost, les utilisateurs de la crate peuvent appeler les méthodes du trait sur des instances de NewsArticle et SocialPost de la même manière que nous appelons des méthodes classiques. La seule différence est que l’utilisateur doit importer le trait dans la portée ainsi que les types. Voici un exemple de la façon dont une crate binaire pourrait utiliser notre crate de bibliothèque aggregator : rust,ignore {{#rustdoc_include ../listings/ch10-generic-types-traits-and-lifetimes/no-listing-01-calling-trait-method/src/main.rs}}
use aggregator::{SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
};
println!("1 new post: {}", post.summarize());
}Ce code affiche 1 new post: horse_ebooks: of course, as you probably already know, people.
D’autres crates qui dépendent de la crate aggregator peuvent aussi importer le trait Summary dans la portée pour implémenter Summary sur leurs propres types. Une restriction à noter est que nous ne pouvons implémenter un trait sur un type que si le trait ou le type, ou les deux, sont locaux à notre crate. Par exemple, nous pouvons implémenter des traits de la bibliothèque standard comme Display sur un type personnalisé comme SocialPost dans le cadre de la fonctionnalité de notre crate aggregator car le type SocialPost est local à notre crate aggregator. Nous pouvons aussi implémenter Summary sur Vec<T> dans notre crate aggregator car le trait Summary est local à notre crate aggregator.
Mais nous ne pouvons pas implémenter des traits externes sur des types externes. Par exemple, nous ne pouvons pas implémenter le trait Display sur Vec<T> dans notre crate aggregator, car Display et Vec<T> sont tous deux définis dans la bibliothèque standard et ne sont pas locaux à notre crate aggregator. Cette restriction fait partie d’une propriété appelée cohérence, et plus spécifiquement la règle de l’orphelin, ainsi nommée car le type parent n’est pas présent. Cette règle garantit que le code des autres ne peut pas casser votre code et vice versa. Sans cette règle, deux crates pourraient implémenter le même trait pour le même type, et Rust ne saurait pas quelle implémentation utiliser.
Utiliser les implémentations par défaut
Parfois, il est utile d’avoir un comportement par défaut pour certaines ou toutes les méthodes d’un trait au lieu d’exiger des implémentations pour toutes les méthodes sur chaque type. Ensuite, lorsque nous implémentons le trait sur un type particulier, nous pouvons conserver ou remplacer le comportement par défaut de chaque méthode.
Dans l’encart 10-14, nous spécifions une chaîne de caractères par défaut pour la méthode summarize du trait Summary au lieu de définir uniquement la signature de la méthode, comme nous l’avons fait dans l’encart 10-12.
pub trait Summary {
fn summarize(&self) -> String {
String::from("(Read more...)")
}
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}Summary trait with a default implementation of the summarize methodPour utiliser une implémentation par défaut afin de résumer les instances de NewsArticle, nous spécifions un bloc impl vide avec impl Summary for NewsArticle {}.
Même si nous ne définissons plus directement la méthode summarize sur NewsArticle, nous avons fourni une implémentation par défaut et spécifié que NewsArticle implémente le trait Summary. En conséquence, nous pouvons toujours appeler la méthode summarize sur une instance de NewsArticle, comme ceci : rust,ignore {{#rustdoc_include ../listings/ch10-generic-types-traits-and-lifetimes/no-listing-02-calling-default-impl/src/main.rs:here}}
use aggregator::{self, NewsArticle, Summary};
fn main() {
let article = NewsArticle {
headline: String::from("Penguins win the Stanley Cup Championship!"),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \n hockey team in the NHL.",
),
};
println!("New article available! {}", article.summarize());
}Ce code affiche New article available! (Read more...).
Créer une implémentation par défaut ne nous oblige pas à modifier quoi que ce soit dans l’implémentation de Summary sur SocialPost dans l’encart 10-13. La raison est que la syntaxe pour remplacer une implémentation par défaut est la même que celle pour implémenter une méthode de trait qui n’a pas d’implémentation par défaut.
Les implémentations par défaut peuvent appeler d’autres méthodes du même trait, même si ces autres méthodes n’ont pas d’implémentation par défaut. De cette façon, un trait peut fournir beaucoup de fonctionnalités utiles et n’exiger des implémenteurs qu’ils ne spécifient qu’une petite partie. Par exemple, nous pourrions définir le trait Summary avec une méthode summarize_author dont l’implémentation est requise, puis définir une méthode summarize qui à une implémentation par défaut qui appelle la méthode summarize_author : rust,noplayground {{#rustdoc_include ../listings/ch10-generic-types-traits-and-lifetimes/no-listing-03-default-impl-calls-other-methods/src/lib.rs:here}}
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}Pour utiliser cette version de Summary, nous n’avons besoin de définir que summarize_author lorsque nous implémentons le trait sur un type : rust,ignore {{#rustdoc_include ../listings/ch10-generic-types-traits-and-lifetimes/no-listing-03-default-impl-calls-other-methods/src/lib.rs:impl}}
pub trait Summary {
fn summarize_author(&self) -> String;
fn summarize(&self) -> String {
format!("(Read more from {}...)", self.summarize_author())
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize_author(&self) -> String {
format!("@{}", self.username)
}
}Après avoir défini summarize_author, nous pouvons appeler summarize sur des instances de la struct SocialPost, et l’implémentation par défaut de summarize appellera la définition de summarize_author que nous avons fournie. Comme nous avons implémenté summarize_author, le trait Summary nous a donné le comportement de la méthode summarize sans que nous ayons besoin d’écrire du code supplémentaire. Voici à quoi cela ressemble : rust,ignore {{#rustdoc_include ../listings/ch10-generic-types-traits-and-lifetimes/no-listing-03-default-impl-calls-other-methods/src/main.rs:here}}
use aggregator::{self, SocialPost, Summary};
fn main() {
let post = SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
};
println!("1 new post: {}", post.summarize());
}Ce code affiche 1 new post: (Read more from @horse_ebooks...).
Notez qu’il n’est pas possible d’appeler l’implémentation par défaut depuis une implémentation qui remplace cette même méthode.
Utiliser les traits comme paramètres
Maintenant que vous savez comment définir et implémenter des traits, nous pouvons explorer comment utiliser les traits pour définir des fonctions qui acceptent de nombreux types différents. Nous utiliserons le trait Summary que nous avons implémenté sur les types NewsArticle et SocialPost dans l’encart 10-13 pour définir une fonction notify qui appelle la méthode summarize sur son paramètre item, qui est d’un certain type implémentant le trait Summary. Pour ce faire, nous utilisons la syntaxe impl Trait, comme ceci : rust,ignore {{#rustdoc_include ../listings/ch10-generic-types-traits-and-lifetimes/no-listing-04-traits-as-parameters/src/lib.rs:here}}
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
pub fn notify(item: &impl Summary) {
println!("Breaking news! {}", item.summarize());
}Au lieu d’un type concret pour le paramètre item, nous spécifions le mot-clé impl et le nom du trait. Ce paramètre accepte n’importe quel type qui implémente le trait spécifié. Dans le corps de notify, nous pouvons appeler n’importe quelle méthode sur item provenant du trait Summary, comme summarize. Nous pouvons appeler notify et passer n’importe quelle instance de NewsArticle ou SocialPost. Le code qui appelle la fonction avec n’importe quel autre type, comme un String ou un i32, ne compilera pas, car ces types n’implémentent pas Summary.
La syntaxe des trait bounds
La syntaxe impl Trait fonctionne pour les cas simples mais est en fait du sucre syntaxique pour une forme plus longue connue sous le nom de trait bound ; elle ressemble à ceci :
pub fn notify<T: Summary>(item: &T) {
println!("Breaking news! {}", item.summarize());
}Cette forme plus longue est équivalente à l’exemple de la section précédente mais est plus verbeuse. Nous plaçons les trait bounds avec la déclaration du paramètre de type générique après un deux-points et entre chevrons.
La syntaxe impl Trait est pratique et permet un code plus concis dans les cas simples, tandis que la syntaxe plus complète des trait bounds peut exprimer plus de complexité dans d’autres cas. Par exemple, nous pouvons avoir deux paramètres qui implémentent Summary. Le faire avec la syntaxe impl Trait ressemble à ceci :
pub fn notify(item1: &impl Summary, item2: &impl Summary) {Utiliser impl Trait est approprié si nous voulons que cette fonction permette à item1 et item2 d’avoir des types différents (tant que les deux types implémentent Summary). Si nous voulons forcer les deux paramètres à avoir le même type, cependant, nous devons utiliser un trait bound, comme ceci :
pub fn notify<T: Summary>(item1: &T, item2: &T) {Le type générique T spécifié comme type des paramètres item1 et item2 contraint la fonction de telle sorte que le type concret de la valeur passée en argument pour item1 et item2 doit être le même.
Trait bounds multiples avec la syntaxe +
Nous pouvons aussi spécifier plus d’un trait bound. Supposons que nous voulions que notify utilise le formatage d’affichage ainsi que summarize sur item : nous spécifions dans la définition de notify que item doit implémenter à la fois Display et Summary. Nous pouvons le faire en utilisant la syntaxe + :
pub fn notify(item: &(impl Summary + Display)) {La syntaxe + est aussi valide avec les trait bounds sur les types génériques :
pub fn notify<T: Summary + Display>(item: &T) {Avec les deux trait bounds spécifiés, le corps de notify peut appeler summarize et utiliser {} pour formater item.
Des trait bounds plus clairs avec les clauses where
Utiliser trop de trait bounds à ses inconvénients. Chaque générique à ses propres trait bounds, donc les fonctions avec plusieurs paramètres de type générique peuvent contenir beaucoup d’informations de trait bounds entre le nom de la fonction et sa liste de paramètres, rendant la signature de la fonction difficile à lire. Pour cette raison, Rust dispose d’une syntaxe alternative pour spécifier les trait bounds dans une clause where après la signature de la fonction. Ainsi, au lieu d’écrire ceci :
fn some_function<T: Display + Clone, U: Clone + Debug>(t: &T, u: &U) -> i32 {nous pouvons utiliser une clause where, comme ceci : rust,ignore {{#rustdoc_include ../listings/ch10-generic-types-traits-and-lifetimes/no-listing-07-where-clause/src/lib.rs:here}}
fn some_function<T, U>(t: &T, u: &U) -> i32
where
T: Display + Clone,
U: Clone + Debug,
{
unimplemented!()
}La signature de cette fonction est moins encombrée : le nom de la fonction, la liste des paramètres et le type de retour sont proches les uns des autres, similaire à une fonction sans beaucoup de trait bounds.
Retourner des types qui implémentent des traits
Nous pouvons aussi utiliser la syntaxe impl Trait en position de retour pour retourner une valeur d’un certain type qui implémente un trait, comme montré ici : rust,ignore {{#rustdoc_include ../listings/ch10-generic-types-traits-and-lifetimes/no-listing-05-returning-impl-trait/src/lib.rs:here}}
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable() -> impl Summary {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
}
}En utilisant impl Summary comme type de retour, nous spécifions que la fonction returns_summarizable retourné un certain type qui implémente le trait Summary sans nommer le type concret. Dans ce cas, returns_summarizable retourné un SocialPost, mais le code qui appelle cette fonction n’a pas besoin de le savoir.
La possibilité de spécifier un type de retour uniquement par le trait qu’il implémente est particulièrement utile dans le contexte des fermetures (closures) et des itérateurs, que nous couvrons au chapitre 13. Les fermetures et les itérateurs créent des types que seul le compilateur connaît ou des types très longs à spécifier. La syntaxe impl Trait vous permet de spécifier de manière concise qu’une fonction retourné un certain type qui implémente le trait Iterator sans avoir besoin d’écrire un type très long.
Cependant, vous ne pouvez utiliser impl Trait que si vous retournez un seul type. Par exemple, ce code qui retourné soit un NewsArticle soit un SocialPost avec le type de retour spécifié comme impl Summary ne fonctionnerait pas : rust,ignore,does_not_compile {{#rustdoc_include ../listings/ch10-generic-types-traits-and-lifetimes/no-listing-06-impl-trait-returns-one-type/src/lib.rs:here}}
pub trait Summary {
fn summarize(&self) -> String;
}
pub struct NewsArticle {
pub headline: String,
pub location: String,
pub author: String,
pub content: String,
}
impl Summary for NewsArticle {
fn summarize(&self) -> String {
format!("{}, by {} ({})", self.headline, self.author, self.location)
}
}
pub struct SocialPost {
pub username: String,
pub content: String,
pub reply: bool,
pub repost: bool,
}
impl Summary for SocialPost {
fn summarize(&self) -> String {
format!("{}: {}", self.username, self.content)
}
}
fn returns_summarizable(switch: bool) -> impl Summary {
if switch {
NewsArticle {
headline: String::from(
"Penguins win the Stanley Cup Championship!",
),
location: String::from("Pittsburgh, PA, USA"),
author: String::from("Iceburgh"),
content: String::from(
"The Pittsburgh Penguins once again are the best \n hockey team in the NHL.",
),
}
} else {
SocialPost {
username: String::from("horse_ebooks"),
content: String::from(
"of course, as you probably already know, people",
),
reply: false,
repost: false,
}
}
}section of Chapter 18. –> Retourner soit un NewsArticle soit un SocialPost n’est pas autorisé en raison de restrictions liées à la façon dont la syntaxe impl Trait est implémentée dans le compilateur. Nous verrons comment écrire une fonction avec ce comportement dans la section [« Utiliser les objets trait pour abstraire un comportement partagé »][trait-objects] du chapitre 18.
Utiliser les trait bounds pour implémenter des méthodes conditionnellement
En utilisant un trait bound avec un bloc impl qui utilise des paramètres de type générique, nous pouvons implémenter des méthodes conditionnellement pour les types qui implémentent les traits spécifiés. Par exemple, le type Pair<T> dans l’encart 10-15 implémente toujours la fonction new pour retourner une nouvelle instance de Pair<T> (rappelez-vous de la section [« La syntaxe des méthodes »][methods] du chapitre 5 que Self est un alias de type pour le type du bloc impl, qui dans ce cas est Pair<T>). Mais dans le bloc impl suivant, Pair<T> n’implémente la méthode cmp_display que si son type interne T implémente le trait PartialOrd qui permet la comparaison et le trait Display qui permet l’affichage.
use std::fmt::Display;
struct Pair<T> {
x: T,
y: T,
}
impl<T> Pair<T> {
fn new(x: T, y: T) -> Self {
Self { x, y }
}
}
impl<T: Display + PartialOrd> Pair<T> {
fn cmp_display(&self) {
if self.x >= self.y {
println!("The largest member is x = {}", self.x);
} else {
println!("The largest member is y = {}", self.y);
}
}
}Nous pouvons aussi implémenter conditionnellement un trait pour n’importe quel type qui implémente un autre trait. Les implémentations d’un trait sur n’importe quel type qui satisfait les trait bounds sont appelées implémentations couvertures (blanket implémentations) et sont largement utilisées dans la bibliothèque standard de Rust. Par exemple, la bibliothèque standard implémente le trait ToString sur n’importe quel type qui implémente le trait Display. Le bloc impl dans la bibliothèque standard ressemble à ce code :
impl<T: Display> ToString for T {
// --snip--
}Comme la bibliothèque standard possède cette implémentation couverture, nous pouvons appeler la méthode to_string définie par le trait ToString sur n’importe quel type qui implémente le trait Display. Par exemple, nous pouvons convertir des entiers en leurs valeurs String correspondantes comme ceci car les entiers implémentent Display :
#![allow(unused)]
fn main() {
let s = 3.to_string();
}Les implémentations couvertures apparaissent dans la documentation du trait dans la section « Implementors ».
Les traits et les trait bounds nous permettent d’écrire du code qui utilise des paramètres de type générique pour réduire la duplication tout en spécifiant au compilateur que nous voulons que le type générique ait un comportement particulier. Le compilateur peut alors utiliser les informations des trait bounds pour vérifier que tous les types concrets utilisés avec notre code fournissent le comportement correct. Dans les langages à typage dynamique, nous obtiendrions une erreur à l’exécution si nous appelions une méthode sur un type qui ne définit pas cette méthode. Mais Rust déplace ces erreurs au moment de la compilation pour que nous soyons obligés de corriger les problèmes avant même que notre code ne puisse s’exécuter. De plus, nous n’avons pas besoin d’écrire du code qui vérifie le comportement à l’exécution, car nous l’avons déjà vérifié à la compilation. Cela améliore les performances sans avoir à renoncer à la flexibilité des génériques.
Valider les références avec les durées de vie
Valider les références avec les durées de vie
Les durées de vie sont un autre type de générique que nous avons déjà utilisé. Plutôt que de s’assurer qu’un type à le comportement que nous souhaitons, les durées de vie s’assurent que les références sont valides aussi longtemps que nous en avons besoin.
Un détail que nous n’avons pas abordé dans la section « Les références et l’emprunt » du chapitre 4 est que chaque référence en Rust à une durée de vie, qui est la portée dans laquelle cette référence est valide. La plupart du temps, les durées de vie sont implicites et inférées, tout comme la plupart du temps, les types sont inférés. Nous ne devons annoter explicitement les types que lorsque plusieurs types sont possibles. De la même manière, nous devons annoter les durées de vie lorsque les durées de vie des références peuvent être liées de plusieurs façons différentes. Rust nous demande d’annoter les relations en utilisant des paramètres génériques de durée de vie pour s’assurer que les références réelles utilisées à l’exécution seront certainement valides.
Annoter les durées de vie n’est même pas un concept que la plupart des autres langages de programmation possèdent, donc cela va sembler inhabituel. Bien que nous ne couvrirons pas les durées de vie dans leur intégralité dans ce chapitre, nous aborderons les façons courantes dont vous pourriez rencontrer la syntaxe des durées de vie afin que vous puissiez vous familiariser avec le concept.
Les références pendantes (dangling références)
L’objectif principal des durées de vie est d’empêcher les références pendantes (dangling références) qui, si elles étaient autorisées à exister, amèneraient un programme à référencer des données autres que celles qu’il est censé référencer. Considérez le programme de l’encart 10-16, qui à une portée externe et une portée interne.
fn main() {
let r;
{
let x = 5;
r = &x;
}
println!("r: {r}");
}Remarque : les exemples des encarts 10-16, 10-17 et 10-23 déclarent des variables sans leur donner de valeur initiale, de sorte que le nom de la variable existe dans la portée externe. À première vue, cela pourrait sembler en conflit avec le fait que Rust n’a pas de valeurs nulles. Cependant, si nous essayons d’utiliser une variable avant de lui donner une valeur, nous obtiendrons une erreur de compilation, ce qui montre qu’effectivement Rust n’autorise pas les valeurs nulles.
La portée externe déclare une variable nommée r sans valeur initiale, et la portée interne déclare une variable nommée x avec la valeur initiale 5. À l’intérieur de la portée interne, nous tentons de définir la valeur de r comme une référence vers x. Ensuite, la portée interne se terminé, et nous tentons d’afficher la valeur dans r. Ce code ne compilera pas, car la valeur à laquelle r fait référence est sortie de la portée avant que nous n’essayions de l’utiliser. Voici le message d’erreur : console {{#include ../listings/ch10-generic-types-traits-and-lifetimes/listing-10-16/output.txt}}
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `x` does not live long enough
--> src/main.rs:6:13
|
5 | let x = 5;
| - binding `x` declared here
6 | r = &x;
| ^^ borrowed value does not live long enough
7 | }
| - `x` dropped here while still borrowed
8 |
9 | println!("r: {r}");
| - borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Le message d’erreur dit que la variable x « ne vit pas assez longtemps ». La raison est que x sera hors de portée lorsque la portée interne se terminera à la ligne 7. Mais r est encore valide pour la portée externe ; comme sa portée est plus grande, nous disons qu’elle « vit plus longtemps ». Si Rust autorisait ce code à fonctionner, r référencerait de la mémoire qui a été désallouée lorsque x est sorti de la portée, et tout ce que nous essaierions de faire avec r ne fonctionnerait pas correctement. Alors, comment Rust détermine-t-il que ce code est invalide ? Il utilise le vérificateur d’emprunt (borrow checker).
Le vérificateur d’emprunt
Le compilateur Rust possède un vérificateur d’emprunt (borrow checker) qui compare les portées pour déterminer si tous les emprunts sont valides. L’encart 10-17 montre le même code que l’encart 10-16 mais avec des annotations montrant les durées de vie des variables.
fn main() {
let r; // ---------+-- 'a
// |
{ // |
let x = 5; // -+-- 'b |
r = &x; // | |
} // -+ |
// |
println!("r: {r}"); // |
} // ---------+r and x, named 'a and 'b, respectivelyIci, nous avons annoté la durée de vie de r avec 'a et la durée de vie de x avec 'b. Comme vous pouvez le voir, le bloc interne 'b est beaucoup plus petit que le bloc de durée de vie externe 'a. Au moment de la compilation, Rust compare la taille des deux durées de vie et constate que r à une durée de vie de 'a mais qu’il fait référence à de la mémoire avec une durée de vie de 'b. Le programme est rejeté car 'b est plus court que 'a : le sujet de la référence ne vit pas aussi longtemps que la référence.
L’encart 10-18 corrige le code pour qu’il n’ait pas de référence pendante et qu’il compilé sans aucune erreur.
fn main() {
let x = 5; // ----------+-- 'b
// |
let r = &x; // --+-- 'a |
// | |
println!("r: {r}"); // | |
// --+ |
} // ----------+Ici, x à la durée de vie 'b, qui dans ce cas est plus grande que 'a. Cela signifie que r peut référencer x car Rust sait que la référence dans r sera toujours valide tant que x est valide.
Maintenant que vous savez où se trouvent les durées de vie des références et comment Rust analyse les durées de vie pour s’assurer que les références seront toujours valides, explorons les durées de vie génériques dans les paramètres de fonction et les valeurs de retour.
Les durées de vie génériques dans les fonctions
Nous allons écrire une fonction qui retourné la plus longue de deux slices de chaînes de caractères. Cette fonction prendra deux slices de chaînes de caractères et retournera une seule slice de chaîne de caractères. Après avoir implémenté la fonction longest, le code de l’encart 10-19 devrait afficher The longest string is abcd.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}main function that calls the longest function to find the longer of two string slicesNotez que nous voulons que la fonction prenne des slices de chaînes de caractères, qui sont des références, plutôt que des chaînes de caractères, car nous ne voulons pas que la fonction longest prenne la possession de ses paramètres. Reportez-vous à [« Les slices de chaînes de caractères comme paramètres »][string-slices-as-parameters] au chapitre 4 pour plus de discussion sur les raisons pour lesquelles les paramètres que nous utilisons dans l’encart 10-19 sont ceux que nous souhaitons.
Si nous essayons d’implémenter la fonction longest comme montré dans l’encart 10-20, elle ne compilera pas.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest(x: &str, y: &str) -> &str {
if x.len() > y.len() { x } else { y }
}longest function that returns the longer of two string slices but does not yet compileÀ la place, nous obtenons l’erreur suivante qui parle de durées de vie : console {{#include ../listings/ch10-generic-types-traits-and-lifetimes/listing-10-20/output.txt}}
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0106]: missing lifetime specifier
--> src/main.rs:9:33
|
9 | fn longest(x: &str, y: &str) -> &str {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `x` or `y`
help: consider introducing a named lifetime parameter
|
9 | fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Le texte d’aide révèle que le type de retour a besoin d’un paramètre de durée de vie générique car Rust ne peut pas déterminer si la référence retournée fait référence à x ou à y. En fait, nous ne le savons pas non plus, car le bloc if dans le corps de cette fonction retourné une référence vers x et le bloc else retourné une référence vers y !
Lorsque nous définissons cette fonction, nous ne connaissons pas les valeurs concrètes qui seront passées à cette fonction, donc nous ne savons pas si le cas if ou le cas else s’exécutera. Nous ne connaissons pas non plus les durées de vie concrètes des références qui seront passées, donc nous ne pouvons pas examiner les portées comme nous l’avons fait dans les encarts 10-17 et 10-18 pour déterminer si la référence que nous retournons sera toujours valide. Le vérificateur d’emprunt ne peut pas non plus le déterminer, car il ne sait pas comment les durées de vie de x et y sont liées à la durée de vie de la valeur de retour. Pour corriger cette erreur, nous ajouterons des paramètres de durée de vie génériques qui définissent la relation entre les références afin que le vérificateur d’emprunt puisse effectuer son analyse.
La syntaxe des annotations de durée de vie
Les annotations de durée de vie ne changent pas la durée de vie d’une référence. Elles décrivent plutôt les relations entre les durées de vie de plusieurs références sans affecter les durées de vie elles-mêmes. Tout comme les fonctions peuvent accepter n’importe quel type lorsque la signature spécifie un paramètre de type générique, les fonctions peuvent accepter des références avec n’importe quelle durée de vie en spécifiant un paramètre de durée de vie générique.
Les annotations de durée de vie ont une syntaxe légèrement inhabituelle : les noms des paramètres de durée de vie doivent commencer par une apostrophe (') et sont généralement tout en minuscules et très courts, comme les types génériques. La plupart des gens utilisent le nom 'a pour la première annotation de durée de vie. Nous plaçons les annotations de paramètre de durée de vie après le & d’une référence, en utilisant un espace pour séparer l’annotation du type de la référence.
Voici quelques exemples : une référence vers un i32 sans paramètre de durée de vie, une référence vers un i32 qui à un paramètre de durée de vie nommé 'a, et une référence mutable vers un i32 qui a aussi la durée de vie 'a :
&i32 // a référence
&'a i32 // a référence with an explicit lifetime
&'a mut i32 // a mutable référence with an explicit lifetimeUne seule annotation de durée de vie n’a pas beaucoup de sens en elle-même, car les annotations sont destinées à indiquer à Rust comment les paramètres de durée de vie génériques de plusieurs références sont liés les uns aux autres. Examinons comment les annotations de durée de vie sont liées les unes aux autres dans le contexte de la fonction longest.
Dans les signatures de fonctions
Pour utiliser les annotations de durée de vie dans les signatures de fonctions, nous devons déclarer les paramètres de durée de vie génériques entre chevrons entre le nom de la fonction et la liste des paramètres, tout comme nous l’avons fait avec les paramètres de type générique.
Nous voulons que la signature exprime la contrainte suivante : la référence retournée sera valide tant que les deux paramètres sont valides. C’est la relation entre les durées de vie des paramètres et la valeur de retour. Nous nommerons la durée de vie 'a puis l’ajouterons à chaque référence, comme montré dans l’encart 10-21.
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}longest function definition specifying that all the references in the signature must have the same lifetime 'aCe code devrait compiler et produire le résultat souhaité lorsque nous l’utilisons avec la fonction main de l’encart 10-19.
La signature de la fonction indique maintenant à Rust que pour une certaine durée de vie 'a, la fonction prend deux paramètres, qui sont tous les deux des slices de chaînes de caractères qui vivent au moins aussi longtemps que la durée de vie 'a. La signature de la fonction indique aussi à Rust que la slice de chaîne de caractères retournée par la fonction vivra au moins aussi longtemps que la durée de vie 'a. En pratique, cela signifie que la durée de vie de la référence retournée par la fonction longest est la même que la plus petite des durées de vie des valeurs référencées par les arguments de la fonction. Ce sont ces relations que nous voulons que Rust utilise lors de l’analyse de ce code.
Rappelez-vous, lorsque nous spécifions les paramètres de durée de vie dans cette signature de fonction, nous ne changeons pas les durées de vie des valeurs passées ou retournées. Nous spécifions plutôt que le vérificateur d’emprunt doit rejeter toute valeur qui ne respecte pas ces contraintes. Notez que la fonction longest n’a pas besoin de savoir exactement combien de temps x et y vivront, seulement qu’une certaine portée peut être substituée à 'a qui satisfera cette signature.
Lorsque nous annotons les durées de vie dans les fonctions, les annotations vont dans la signature de la fonction, pas dans le corps de la fonction. Les annotations de durée de vie font partie du contrat de la fonction, tout comme les types dans la signature. Avoir des signatures de fonctions contenant le contrat de durée de vie signifie que l’analyse effectuée par le compilateur Rust peut être plus simple. S’il y à un problème avec la façon dont une fonction est annotée ou la façon dont elle est appelée, les erreurs du compilateur peuvent pointer plus précisément vers la partie de notre code et les contraintes. Si, au contraire, le compilateur Rust faisait plus d’inférences sur ce que nous voulions que soient les relations entre les durées de vie, le compilateur ne pourrait peut-être pointer que vers une utilisation de notre code à plusieurs étapes de la cause du problème.
Lorsque nous passons des références concrètes à longest, la durée de vie concrète qui est substituée à 'a est la partie de la portée de x qui chevauche la portée de y. En d’autres termes, la durée de vie générique 'a obtiendra la durée de vie concrète qui est égale à la plus petite des durées de vie de x et y. Comme nous avons annoté la référence retournée avec le même paramètre de durée de vie 'a, la référence retournée sera aussi valide pour la durée de la plus petite des durées de vie de x et y.
Voyons comment les annotations de durée de vie restreignent la fonction longest en passant des références qui ont des durées de vie concrètes différentes. L’encart 10-22 est un exemple simple.
fn main() {
let string1 = String::from("long string is long");
{
let string2 = String::from("xyz");
let result = longest(string1.as_str(), string2.as_str());
println!("The longest string is {result}");
}
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}longest function with references to String values that have different concrete lifetimesDans cet exemple, string1 est valide jusqu’à la fin de la portée externe, string2 est valide jusqu’à la fin de la portée interne, et result référence quelque chose qui est valide jusqu’à la fin de la portée interne. Exécutez ce code et vous verrez que le vérificateur d’emprunt approuve ; il compilera et affichera The longest string is long string is long.
Ensuite, essayons un exemple qui montre que la durée de vie de la référence dans result doit être la plus petite durée de vie des deux arguments. Nous déplacerons la déclaration de la variable result à l’extérieur de la portée interne mais laisserons l’assignation de la valeur à la variable result à l’intérieur de la portée avec string2. Ensuite, nous déplacerons le println! qui utilise result à l’extérieur de la portée interne, après la fin de la portée interne. Le code de l’encart 10-23 ne compilera pas.
fn main() {
let string1 = String::from("long string is long");
let result;
{
let string2 = String::from("xyz");
result = longest(string1.as_str(), string2.as_str());
}
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &'a str) -> &'a str {
if x.len() > y.len() { x } else { y }
}result after string2 has gone out of scopeLorsque nous essayons de compiler ce code, nous obtenons cette erreur : console {{#include ../listings/ch10-generic-types-traits-and-lifetimes/listing-10-23/output.txt}}
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0597]: `string2` does not live long enough
--> src/main.rs:6:44
|
5 | let string2 = String::from("xyz");
| ------- binding `string2` declared here
6 | result = longest(string1.as_str(), string2.as_str());
| ^^^^^^^ borrowed value does not live long enough
7 | }
| - `string2` dropped here while still borrowed
8 | println!("The longest string is {result}");
| ------ borrow later used here
For more information about this error, try `rustc --explain E0597`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
L’erreur montre que pour que result soit valide pour l’instruction println!, string2 devrait être valide jusqu’à la fin de la portée externe. Rust le sait car nous avons annoté les durées de vie des paramètres de fonction et des valeurs de retour en utilisant le même paramètre de durée de vie 'a.
En tant qu’humains, nous pouvons regarder ce code et voir que string1 est plus longue que string2, et donc, result contiendra une référence vers string1. Comme string1 n’est pas encore sortie de la portée, une référence vers string1 sera toujours valide pour l’instruction println!. Cependant, le compilateur ne peut pas voir que la référence est valide dans ce cas. Nous avons dit à Rust que la durée de vie de la référence retournée par la fonction longest est la même que la plus petite des durées de vie des références passées. Par conséquent, le vérificateur d’emprunt interdit le code de l’encart 10-23 comme pouvant avoir une référence invalide.
Essayez de concevoir d’autres expériences qui font varier les valeurs et les durées de vie des références passées à la fonction longest et la façon dont la référence retournée est utilisée. Faites des hypothèses sur le fait que vos expériences passeront ou non le vérificateur d’emprunt avant de compiler ; puis, vérifiez si vous avez raison !
Les relations
La façon dont vous devez spécifier les paramètres de durée de vie dépend de ce que fait votre fonction. Par exemple, si nous changions l’implémentation de la fonction longest pour toujours retourner le premier paramètre plutôt que la plus longue slice de chaîne de caractères, nous n’aurions pas besoin de spécifier une durée de vie sur le paramètre y. Le code suivant compilera :
fn main() {
let string1 = String::from("abcd");
let string2 = "efghijklmnopqrstuvwxyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &'a str, y: &str) -> &'a str {
x
}Nous avons spécifié un paramètre de durée de vie 'a pour le paramètre x et le type de retour, mais pas pour le paramètre y, car la durée de vie de y n’à aucune relation avec la durée de vie de x ou la valeur de retour.
Lorsqu’on retourné une référence depuis une fonction, le paramètre de durée de vie pour le type de retour doit correspondre au paramètre de durée de vie de l’un des paramètres. Si la référence retournée ne fait pas référence à l’un des paramètres, elle doit faire référence à une valeur créée dans cette fonction. Cependant, ce serait une référence pendante car la valeur sortira de la portée à la fin de la fonction. Considérez cette tentative d’implémentation de la fonction longest qui ne compilera pas :
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest(string1.as_str(), string2);
println!("The longest string is {result}");
}
fn longest<'a>(x: &str, y: &str) -> &'a str {
let result = String::from("really long string");
result.as_str()
}Ici, même si nous avons spécifié un paramètre de durée de vie 'a pour le type de retour, cette implémentation ne compilera pas car la durée de vie de la valeur de retour n’est pas du tout liée à la durée de vie des paramètres. Voici le message d’erreur que nous obtenons : console {{#include ../listings/ch10-generic-types-traits-and-lifetimes/no-listing-09-unrelated-lifetime/output.txt}}
$ cargo run
Compiling chapter10 v0.1.0 (file:///projects/chapter10)
error[E0515]: cannot return value referencing local variable `result`
--> src/main.rs:11:5
|
11 | result.as_str()
| ------^^^^^^^^^
| |
| returns a value referencing data owned by the current function
| `result` is borrowed here
For more information about this error, try `rustc --explain E0515`.
error: could not compile `chapter10` (bin "chapter10") due to 1 previous error
Le problème est que result sort de la portée et est nettoyé à la fin de la fonction longest. Nous essayons aussi de retourner une référence vers result depuis la fonction. Il n’y à aucun moyen de spécifier des paramètres de durée de vie qui changeraient la référence pendante, et Rust ne nous laissera pas créer une référence pendante. Dans ce cas, la meilleure solution serait de retourner un type de données possédé plutôt qu’une référence afin que la fonction appelante soit alors responsable du nettoyage de la valeur.
En fin de compte, la syntaxe des durées de vie consiste à connecter les durées de vie des différents paramètres et valeurs de retour des fonctions. Une fois qu’elles sont connectées, Rust a suffisamment d’informations pour autoriser les opérations sûres pour la mémoire et interdire les opérations qui créeraient des pointeurs pendants ou violeraient autrement la sécurité de la mémoire.
Dans les définitions de structs
Jusqu’à présent, les structs que nous avons définies contiennent toutes des types possédés. Nous pouvons définir des structs qui contiennent des références, mais dans ce cas, nous devrions ajouter une annotation de durée de vie sur chaque référence dans la définition de la struct. L’encart 10-24 possède une struct nommée ImportantExcerpt qui contient une slice de chaîne de caractères.
struct ImportantExcerpt<'a> {
part: &'a str,
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().unwrap();
let i = ImportantExcerpt {
part: first_sentence,
};
}Cette struct à un seul champ part qui contient une slice de chaîne de caractères, qui est une référence. Comme pour les types de données génériques, nous déclarons le nom du paramètre de durée de vie générique entre chevrons après le nom de la struct afin de pouvoir utiliser le paramètre de durée de vie dans le corps de la définition de la struct. Cette annotation signifie qu’une instance de ImportantExcerpt ne peut pas survivre à la référence qu’elle contient dans son champ part.
La fonction main ici crée une instance de la struct ImportantExcerpt qui contient une référence vers la première phrase du String possédé par la variable novel. Les données dans novel existent avant que l’instance de ImportantExcerpt ne soit créée. De plus, novel ne sort pas de la portée avant que ImportantExcerpt ne sorte de la portée, donc la référence dans l’instance de ImportantExcerpt est valide.
L’élision des durées de vie
Vous avez appris que chaque référence à une durée de vie et que vous devez spécifier des paramètres de durée de vie pour les fonctions ou structs qui utilisent des références. Cependant, nous avions une fonction dans l’encart 4-9, montrée à nouveau dans l’encart 10-25, qui compilait sans annotations de durée de vie.
fn first_word(s: &str) -> &str {
let bytes = s.as_bytes();
for (i, &item) in bytes.iter().enumerate() {
if item == b' ' {
return &s[0..i];
}
}
&s[..]
}
fn main() {
let my_string = String::from("hello world");
// first_word works on slices of `String`s
let word = first_word(&my_string[..]);
let my_string_literal = "hello world";
// first_word works on slices of string literals
let word = first_word(&my_string_literal[..]);
// Because string literals *are* string slices already,
// this works too, without the slice syntax!
let word = first_word(my_string_literal);
}La raison pour laquelle cette fonction compilé sans annotations de durée de vie est historique : dans les premières versions (pré-1.0) de Rust, ce code n’aurait pas compilé, car chaque référence nécessitait une durée de vie explicite. À cette époque, la signature de la fonction aurait été écrite comme ceci :
fn first_word<'a>(s: &'a str) -> &'a str {Après avoir écrit beaucoup de code Rust, l’équipe Rust a constaté que les programmeurs Rust saisissaient les mêmes annotations de durée de vie encore et encore dans des situations particulières. Ces situations étaient prévisibles et suivaient quelques modèles déterministes. Les développeurs ont programmé ces modèles dans le code du compilateur afin que le vérificateur d’emprunt puisse inférer les durées de vie dans ces situations sans avoir besoin d’annotations explicites.
Ce morceau d’histoire de Rust est pertinent car il est possible que d’autres modèles déterministes émergent et soient ajoutés au compilateur. À l’avenir, encore moins d’annotations de durée de vie pourraient être nécessaires.
Les modèles programmés dans l’analyse des références par Rust sont appelés les règles d’élision des durées de vie. Ce ne sont pas des règles que les programmeurs doivent suivre ; ce sont un ensemble de cas particuliers que le compilateur considérera, et si votre code correspond à ces cas, vous n’avez pas besoin d’écrire les durées de vie explicitement.
Les règles d’élision ne fournissent pas une inférence complète. S’il reste de l’ambiguïté sur les durées de vie des références après que Rust a appliqué les règles, le compilateur ne devinera pas quelle devrait être la durée de vie des références restantes. Au lieu de deviner, le compilateur vous donnera une erreur que vous pouvez résoudre en ajoutant les annotations de durée de vie.
Les durées de vie sur les paramètres de fonction ou de méthode sont appelées durées de vie d’entrée, et les durées de vie sur les valeurs de retour sont appelées durées de vie de sortie.
Le compilateur utilise trois règles pour déterminer les durées de vie des références lorsqu’il n’y a pas d’annotations explicites. La première règle s’applique aux durées de vie d’entrée, et les deuxième et troisième règles s’appliquent aux durées de vie de sortie. Si le compilateur arrive à la fin des trois règles et qu’il reste des références pour lesquelles il ne peut pas déterminer les durées de vie, le compilateur s’arrêtera avec une erreur. Ces règles s’appliquent aux définitions fn ainsi qu’aux blocs impl.
La première règle est que le compilateur assigne un paramètre de durée de vie à chaque paramètre qui est une référence. En d’autres termes, une fonction avec un paramètre obtient un paramètre de durée de vie : fn foo<'a>(x: &'a i32) ; une fonction avec deux paramètres obtient deux paramètres de durée de vie séparés : fn foo<'a, 'b>(x: &'a i32, y: &'b i32) ; et ainsi de suite.
La deuxième règle est que, s’il y a exactement un paramètre de durée de vie d’entrée, cette durée de vie est assignée à tous les paramètres de durée de vie de sortie : fn foo<'a>(x: &'a i32) -> &'a i32.
La troisième règle est que, s’il y à plusieurs paramètres de durée de vie d’entrée, mais que l’un d’eux est &self ou &mut self parce qu’il s’agit d’une méthode, la durée de vie de self est assignée à tous les paramètres de durée de vie de sortie. Cette troisième règle rend les méthodes beaucoup plus agréables à lire et à écrire car moins de symboles sont nécessaires.
Faisons comme si nous étions le compilateur. Nous appliquerons ces règles pour déterminer les durées de vie des références dans la signature de la fonction first_word de l’encart 10-25. La signature commence sans aucune durée de vie associée aux références :
fn first_word(s: &str) -> &str {Ensuite, le compilateur applique la première règle, qui spécifie que chaque paramètre obtient sa propre durée de vie. Nous l’appellerons 'a comme d’habitude, donc maintenant la signature est celle-ci :
fn first_word<'a>(s: &'a str) -> &str {La deuxième règle s’applique car il y a exactement une durée de vie d’entrée. La deuxième règle spécifie que la durée de vie du seul paramètre d’entrée est assignée à la durée de vie de sortie, donc la signature est maintenant celle-ci :
fn first_word<'a>(s: &'a str) -> &'a str {Maintenant, toutes les références dans cette signature de fonction ont des durées de vie, et le compilateur peut continuer son analyse sans avoir besoin que le programmeur annote les durées de vie dans cette signature de fonction.
Regardons un autre exemple, cette fois en utilisant la fonction longest qui n’avait pas de paramètres de durée de vie lorsque nous avons commencé à travailler avec dans l’encart 10-20 :
fn longest(x: &str, y: &str) -> &str {Appliquons la première règle : chaque paramètre obtient sa propre durée de vie. Cette fois nous avons deux paramètres au lieu d’un, donc nous avons deux durées de vie :
fn longest<'a, 'b>(x: &'a str, y: &'b str) -> &str {Vous pouvez voir que la deuxième règle ne s’applique pas, car il y a plus d’une durée de vie d’entrée. La troisième règle ne s’applique pas non plus, car longest est une fonction plutôt qu’une méthode, donc aucun des paramètres n’est self. Après avoir appliqué les trois règles, nous n’avons toujours pas déterminé quelle est la durée de vie du type de retour. C’est pourquoi nous avons obtenu une erreur en essayant de compiler le code de l’encart 10-20 : le compilateur a appliqué les règles d’élision des durées de vie mais n’a toujours pas pu déterminer toutes les durées de vie des références dans la signature.
Comme la troisième règle ne s’applique vraiment que dans les signatures de méthodes, nous examinerons les durées de vie dans ce contexte ensuite pour voir pourquoi la troisième règle fait que nous n’avons pas à annoter les durées de vie dans les signatures de méthodes très souvent.
Dans les définitions de méthodes
Lorsque nous implémentons des méthodes sur une struct avec des durées de vie, nous utilisons la même syntaxe que celle des paramètres de type générique, comme montré dans l’encart 10-11. L’endroit où nous déclarons et utilisons les paramètres de durée de vie dépend de s’ils sont liés aux champs de la struct ou aux paramètres et valeurs de retour de la méthode.
Les noms de durée de vie pour les champs de la struct doivent toujours être déclarés après le mot-clé impl puis utilisés après le nom de la struct car ces durées de vie font partie du type de la struct.
Dans les signatures de méthodes à l’intérieur du bloc impl, les références peuvent être liées à la durée de vie des références dans les champs de la struct, ou elles peuvent être indépendantes. De plus, les règles d’élision des durées de vie font souvent en sorte que les annotations de durée de vie ne soient pas nécessaires dans les signatures de méthodes. Examinons quelques exemples en utilisant la struct nommée ImportantExcerpt que nous avons définie dans l’encart 10-24.
D’abord, nous utiliserons une méthode nommée level dont le seul paramètre est une référence vers self et dont la valeur de retour est un i32, qui n’est pas une référence vers quoi que ce soit : rust {{#rustdoc_include ../listings/ch10-generic-types-traits-and-lifetimes/no-listing-10-lifetimes-on-methods/src/main.rs:1st}}
struct ImportantExcerpt<'a> {
part: &'a str,
}
impl<'a> ImportantExcerpt<'a> {
fn level(&self) -> i32 {
3
}
}
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part(&self, announcement: &str) -> &str {
println!("Attention please: {announcement}");
self.part
}
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().unwrap();
let i = ImportantExcerpt {
part: first_sentence,
};
}La déclaration du paramètre de durée de vie après impl et son utilisation après le nom du type sont requises, mais en raison de la première règle d’élision, nous ne sommes pas tenus d’annoter la durée de vie de la référence vers self.
Voici un exemple où la troisième règle d’élision des durées de vie s’applique : rust {{#rustdoc_include ../listings/ch10-generic-types-traits-and-lifetimes/no-listing-10-lifetimes-on-methods/src/main.rs:3rd}}
struct ImportantExcerpt<'a> {
part: &'a str,
}
impl<'a> ImportantExcerpt<'a> {
fn level(&self) -> i32 {
3
}
}
impl<'a> ImportantExcerpt<'a> {
fn announce_and_return_part(&self, announcement: &str) -> &str {
println!("Attention please: {announcement}");
self.part
}
}
fn main() {
let novel = String::from("Call me Ishmael. Some years ago...");
let first_sentence = novel.split('.').next().unwrap();
let i = ImportantExcerpt {
part: first_sentence,
};
}Il y a deux durées de vie d’entrée, donc Rust applique la première règle d’élision des durées de vie et donne à &self et à announcement leurs propres durées de vie. Ensuite, comme l’un des paramètres est &self, le type de retour obtient la durée de vie de &self, et toutes les durées de vie ont été prises en compte.
La durée de vie statique
Une durée de vie spéciale que nous devons aborder est 'static, qui indique que la référence concernée peut vivre pendant toute la durée du programme. Toutes les chaînes de caractères littérales ont la durée de vie 'static, que nous pouvons annoter comme suit :
#![allow(unused)]
fn main() {
let s: &'static str = "I have a static lifetime.";
}Le texte de cette chaîne de caractères est stocké directement dans le binaire du programme, qui est toujours disponible. Par conséquent, la durée de vie de toutes les chaînes de caractères littérales est 'static.
Vous pourriez voir des suggestions dans les messages d’erreur pour utiliser la durée de vie 'static. Mais avant de spécifier 'static comme durée de vie pour une référence, demandez-vous si la référence que vous avez vit réellement pendant toute la durée de vie de votre programme, et si vous le souhaitez. La plupart du temps, un message d’erreur suggérant la durée de vie 'static résulte d’une tentative de création d’une référence pendante ou d’une incompatibilité des durées de vie disponibles. Dans de tels cas, la solution est de corriger ces problèmes, pas de spécifier la durée de vie 'static.
Paramètres de type générique, trait bounds et durées de vie
Examinons brièvement la syntaxe pour spécifier des paramètres de type générique, des trait bounds et des durées de vie, le tout dans une seule fonction ! rust {{#rustdoc_include ../listings/ch10-generic-types-traits-and-lifetimes/no-listing-11-generics-traits-and-lifetimes/src/main.rs:here}}
fn main() {
let string1 = String::from("abcd");
let string2 = "xyz";
let result = longest_with_an_announcement(
string1.as_str(),
string2,
"Today is someone's birthday!",
);
println!("The longest string is {result}");
}
use std::fmt::Display;
fn longest_with_an_announcement<'a, T>(
x: &'a str,
y: &'a str,
ann: T,
) -> &'a str
where
T: Display,
{
println!("Announcement! {ann}");
if x.len() > y.len() { x } else { y }
}C’est la fonction longest de l’encart 10-21 qui retourné la plus longue de deux slices de chaînes de caractères. Mais maintenant elle à un paramètre supplémentaire nommé ann du type générique T, qui peut être rempli par n’importe quel type qui implémente le trait Display comme spécifié par la clause where. Ce paramètre supplémentaire sera affiché en utilisant {}, c’est pourquoi le trait bound Display est nécessaire. Comme les durées de vie sont un type de générique, les déclarations du paramètre de durée de vie 'a et du paramètre de type générique T vont dans la même liste entre chevrons après le nom de la fonction.
Résumé
Nous avons couvert beaucoup de choses dans ce chapitre ! Maintenant que vous connaissez les paramètres de type générique, les traits et les trait bounds, et les paramètres de durée de vie génériques, vous êtes prêt à écrire du code sans répétition qui fonctionne dans de nombreuses situations différentes. Les paramètres de type générique vous permettent d’appliquer le code à différents types. Les traits et les trait bounds s’assurent que même si les types sont génériques, ils auront le comportement dont le code a besoin. Vous avez appris à utiliser les annotations de durée de vie pour vous assurer que ce code flexible n’aura pas de références pendantes. Et toute cette analyse se fait au moment de la compilation, ce qui n’affecte pas les performances à l’exécution !
Croyez-le où non, il y a encore beaucoup à apprendre sur les sujets que nous avons abordés dans ce chapitre : le chapitre 18 traite des objets trait, qui sont une autre façon d’utiliser les traits. Il existe aussi des scénarios plus complexes impliquant des annotations de durée de vie dont vous n’aurez besoin que dans des cas très avancés ; pour ceux-là, vous devriez lire la [Référence Rust][référence]. Mais ensuite, vous apprendrez à écrire des tests en Rust pour vous assurer que votre code fonctionne comme il le devrait.
Écrire des tests automatisés
Dans son essai de 1972 “The Humble Programmer”, Edsger W. Dijkstra a dit que “les tests de programmes peuvent être un moyen très efficace de montrer la présence de bogues, mais ils sont desespérement insuffisants pour prouver leur absence.” Cela ne signifie pas que nous ne devrions pas essayer de tester autant que possible !
La correction de nos programmes correspond à la mesure dans laquelle notre code fait ce que nous voulons qu’il fasse. Rust est concu avec un souci eleve de la correction des programmes, mais la correction est complexe et difficile a prouver. Le système de types de Rust prend en charge une grande partie de ce fardeau, mais le système de types ne peut pas tout détecter. C’est pourquoi Rust inclut la possibilité d’écrire des tests logiciels automatises.
Imaginons que nous ecrivions une fonction add_two qui ajouté 2 a n’importe quel nombre qui lui est passe. La signature de cette fonction accepte un entier en paramètre et retourné un entier en résultat. Quand nous implementons et compilons cette fonction, Rust effectue toutes les vérifications de types et d’emprunts que vous avez apprises jusqu’ici pour s’assurer que, par exemple, nous ne passons pas une valeur String ou une référence invalide à cette fonction. Mais Rust ne peut pas vérifier que cette fonction fera précisément ce que nous voulons, c’est-a-dire retourner le paramètre plus 2 plutot que, disons, le paramètre plus 10 ou le paramètre moins 50 ! C’est la que les tests entrent en jeu.
Nous pouvons écrire des tests qui vérifient, par exemple, que lorsque nous passons 3 à la fonction add_two, la valeur retournée est 5. Nous pouvons exécuter ces tests chaque fois que nous modifions notre code pour nous assurer que tout comportement correct existant n’a pas change.
Tester est une competence complexe : bien que nous ne puissions pas couvrir dans un seul chapitre chaque détail sur la maniere d’écrire de bons tests, dans ce chapitre nous aborderons les mecanismes des outils de test de Rust. Nous parlerons des annotations et des macros disponibles lors de l’écriture de vos tests, du comportement par défaut et des options fournies pour l’exécution de vos tests, et de la façon d’organiser les tests en tests unitaires et tests d’intégration.
Comment écrire des tests
Comment écrire des tests
Les tests sont des fonctions Rust qui vérifient que le code non-test fonctionne de la maniere attendue. Le corps des fonctions de test effectue généralement ces trois actions :
- Mettre en place les données ou l’état nécessaires.
- Exécuter le code que vous souhaitez tester.
- Vérifier que les résultats sont ceux que vous attendez.
Examinons les fonctionnalités que Rust fournit specifiquement pour écrire des tests qui effectuent ces actions, notamment l’attribut test, quelques macros et l’attribut should_panic.
Structurer les fonctions de test
Dans sa forme la plus simple, un test en Rust est une fonction annotee avec l’attribut test. Les attributs sont des metadonnees sur des portions de code Rust ; un exemple est l’attribut derive que nous avons utilise avec les structures au chapitre 5. Pour transformer une fonction en fonction de test, ajoutez #[test] sur la ligne avant fn. Quand vous exécutez vos tests avec la commande cargo test, Rust compilé un binaire d’exécution de tests qui lance les fonctions annotees et rapporte si chaque fonction de test reussit ou echoue.
Chaque fois que nous créons un nouveau projet de bibliothèque avec Cargo, un module de test contenant une fonction de test est automatiquement génère pour nous. Ce module vous fournit un modèle pour écrire vos tests afin que vous n’ayez pas a rechercher la structure et la syntaxe exactes chaque fois que vous demarrez un nouveau projet. Vous pouvez ajouter autant de fonctions de test et de modules de test supplementaires que vous le souhaitez !
Nous allons explorer certains aspects du fonctionnement des tests en experimentant avec le test modèle avant de tester réellement du code. Ensuite, nous ecrirons des tests concrets qui appellent du code que nous avons écrit et vérifient que son comportement est correct.
Créons un nouveau projet de bibliothèque appelé adder qui additionnera deux nombres :
$ cargo new adder --lib
Created library `adder` project
$ cd adder
Le contenu du fichier src/lib.rs de votre bibliothèque adder devrait ressembler à l’encart 11-1.
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}cargo newLe fichier commence par un exemple de fonction add afin que nous ayons quelque chose a tester.
Pour l’instant, concentrons-nous uniquement sur la fonction it_works. Notez l’annotation #[test] : cet attribut indique qu’il s’agit d’une fonction de test, de sorte que l’executeur de tests sait qu’il doit traiter cette fonction comme un test. Nous pourrions aussi avoir des fonctions non-test dans le module tests pour aider a mettre en place des scenarios communs ou effectuer des opérations courantes, c’est pourquoi nous devons toujours indiquer quelles fonctions sont des tests.
Le corps de la fonction d’exemple utilise la macro assert_eq! pour vérifier que result, qui contient le résultat de l’appel de add avec 2 et 2, est egal à 4. Cette assertion sert d’exemple de format pour un test typique. Executons-le pour voir que ce test reussit.
La commande cargo test exécute tous les tests de notre projet, comme montre dans l’encart 11-2.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.57s
Running unittests src/lib.rs (target/debug/deps/adder-01ad14159ff659ab)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Cargo a compilé et exécute le test. Nous voyons la ligne running 1 test. La ligne suivante montre le nom de la fonction de test générée, appelée tests::it_works, et que le résultat de l’exécution de ce test est ok. Le resume global test result: ok. signifie que tous les tests ont réussi, et la partie qui indique 1 passed; 0 failed totalise le nombre de tests qui ont réussi ou echoue.
Il est possible de marquer un test comme ignore afin qu’il ne s’exécute pas dans un cas particulier ; nous aborderons cela dans la section [“Ignorer des tests sauf demande explicite”][ignoring] plus loin dans ce chapitre. Comme nous ne l’avons pas fait ici, le resume affiche 0 ignored. Nous pouvons également passer un argument à la commande cargo test pour n’exécuter que les tests dont le nom correspond à une chaîne de caractères ; c’est ce qu’on appelle le filtrage, et nous l’aborderons dans la section [“Exécuter un sous-ensemble de tests par nom”][subset]. Ici, nous n’avons pas filtre les tests exécutés, donc la fin du resume affiche 0 filtered out.
La statistique 0 measured concerne les tests de performance (benchmarks) qui mesurent les performances. Les tests de performance ne sont, au moment de la redaction de ce livre, disponibles que dans la version nightly de Rust. Consultez [la documentation sur les tests de performance][bench] pour en savoir plus.
La partie suivante de la sortie des tests, commencant par Doc-tests adder, concerne les résultats des tests de documentation. Nous n’avons pas encore de tests de documentation, mais Rust peut compiler tous les exemples de code qui apparaissent dans notre documentation d’API. Cette fonctionnalité aide a garder votre documentation et votre code synchronises ! Nous verrons comment écrire des tests de documentation dans la section [“Les commentaires de documentation comme tests”][doc-comments] du chapitre 14. Pour l’instant, nous ignorerons la sortie Doc-tests.
Commencons a personnaliser le test selon nos besoins. D’abord, changez le nom de la fonction it_works pour un nom différent, comme exploration, comme ceci :
Fichier : src/lib.rs rust,noplayground {{#rustdoc_include ../listings/ch11-writing-automated-tests/listing-11-01/src/lib.rs}}
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}Ensuite, exécutez cargo test à nouveau. La sortie affiche maintenant exploration au lieu de it_works : console {{#include ../listings/ch11-writing-automated-tests/no-listing-01-changing-test-name/output.txt}}
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.59s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::exploration ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Maintenant, nous allons ajouter un autre test, mais cette fois nous allons créer un test qui echoue ! Les tests echouent quand quelque chose dans la fonction de test provoque un panic. Chaque test est exécute dans un nouveau thread, et quand le thread principal voit qu’un thread de test est mort, le test est marque comme echoue. Au chapitre 9, nous avons parle de la façon la plus simple de provoquer un panic : appeler la macro panic!. Entrez le nouveau test sous forme de fonction nommee another, pour que votre fichier src/lib.rs ressemble à l’encart 11-3.
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn exploration() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
fn another() {
panic!("Make this test fail");
}
}panic! macroExécutez les tests à nouveau avec cargo test. La sortie devrait ressembler à l’encart 11-4, qui montre que notre test exploration a réussi et que another a echoue.
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.72s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::another ... FAILED
test tests::exploration ... ok
failures:
---- tests::another stdout ----
thread 'tests::another' panicked at src/lib.rs:17:9:
Make this test fail
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::another
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Au lieu de ok, la ligne test tests::another affiche FAILED. Deux nouvelles sections apparaissent entre les résultats individuels et le resume : la première affiche la raison détaillée de chaque échec de test. Dans ce cas, nous obtenons les détails indiquant que tests::another a echoue parce qu’il a provoque un panic avec le message Make this test fail à la ligne 17 du fichier src/lib.rs. La section suivante liste uniquement les noms de tous les tests en échec, ce qui est utile quand il y a beaucoup de tests et beaucoup de sorties detaillees de tests en échec. Nous pouvons utiliser le nom d’un test en échec pour n’exécuter que ce test et le deboguer plus facilement ; nous parlerons davantage des façons d’exécuter les tests dans la section [“Controler comment les tests sont exécutés”][controlling-how-tests-are-run].
La ligne de resume s’affiche à la fin : globalement, notre résultat de test est FAILED. Nous avions un test réussi et un test en échec.
Maintenant que vous avez vu a quoi ressemblent les résultats des tests dans différents scenarios, examinons quelques macros autres que panic! qui sont utiles dans les tests.
Vérifier les résultats avec assert!
La macro assert!, fournie par la bibliothèque standard, est utile quand vous voulez vous assurer qu’une certaine condition dans un test s’evalue a true. Nous donnons à la macro assert! un argument qui s’evalue en un booleen. Si la valeur est true, rien ne se passe et le test reussit. Si la valeur est false, la macro assert! appelle panic! pour faire echouer le test. Utiliser la macro assert! nous aide a vérifier que notre code fonctionne de la maniere prevue.
Au chapitre 5, dans l’encart 5-15, nous avons utilise une structure Rectangle et une methode can_hold, qui sont reproduites ici dans l’encart 11-5. Mettons ce code dans le fichier src/lib.rs, puis écrivons quelques tests en utilisant la macro assert!.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}Rectangle struct and its can_hold method from Chapter 5La methode can_hold retourné un booleen, ce qui en fait un cas d’utilisation parfait pour la macro assert!. Dans l’encart 11-6, nous écrivons un test qui exerce la methode can_hold en creant une instance de Rectangle ayant une largeur de 8 et une hauteur de 7, et en verifiant qu’elle peut contenir une autre instance de Rectangle ayant une largeur de 5 et une hauteur de 1.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
}can_hold that checks whether a larger rectangle can indeed hold a smaller rectanglesection. Because the tests module is an inner module, we need to bring the code under test in the outer module into the scope of the inner module. We use a glob here, so anything we define in the outer module is available to this tests module. –> Notez la ligne use super::*; à l’intérieur du module tests. Le module tests est un module ordinaire qui suit les règles de visibilite habituelles que nous avons couvertes au chapitre 7 dans la section [“Les chemins pour faire référence à un élément dans l’arborescence des modules”][paths-for-referring-to-an-item-in-the-module-tree]. Comme le module tests est un module interne, nous devons importer le code a tester du module externe dans la portée du module interne. Nous utilisons un glob ici, de sorte que tout ce que nous définissons dans le module externe est disponible dans ce module tests.
Nous avons nomme notre test larger_can_hold_smaller, et nous avons crée les deux instances de Rectangle dont nous avons besoin. Ensuite, nous avons appelé la macro assert! en lui passant le résultat de l’appel larger.can_hold(&smaller). Cette expression est censee retourner true, donc notre test devrait réussir. Voyons cela ! console {{#include ../listings/ch11-writing-automated-tests/listing-11-06/output.txt}}
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 1 test
test tests::larger_can_hold_smaller ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Il reussit ! Ajoutons un autre test, cette fois en verifiant qu’un plus petit rectangle ne peut pas contenir un plus grand rectangle :
Fichier : src/lib.rs rust,noplayground {{#rustdoc_include ../listings/ch11-writing-automated-tests/listing-11-01/src/lib.rs}}
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width > other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
// --snip--
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}Comme le résultat correct de la fonction can_hold dans ce cas est false, nous devons inverser ce résultat avant de le passer à la macro assert!. En consequence, notre test reussira si can_hold retourné false : console {{#include ../listings/ch11-writing-automated-tests/no-listing-02-adding-another-rectangle-test/output.txt}}
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... ok
test tests::smaller_cannot_hold_larger ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests rectangle
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Deux tests qui reussissent ! Maintenant, voyons ce qui arrive a nos résultats de tests quand nous introduisons un bogue dans notre code. Nous allons changer l’implémentation de la methode can_hold en remplacant le signé supérieur (>) par un signé inférieur (<) lors de la comparaison des largeurs : rust,not_desired_behavior,noplayground {{#rustdoc_include ../listings/ch11-writing-automated-tests/no-listing-03-introducing-a-bug/src/lib.rs:here}}
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
// --snip--
impl Rectangle {
fn can_hold(&self, other: &Rectangle) -> bool {
self.width < other.width && self.height > other.height
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn larger_can_hold_smaller() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(larger.can_hold(&smaller));
}
#[test]
fn smaller_cannot_hold_larger() {
let larger = Rectangle {
width: 8,
height: 7,
};
let smaller = Rectangle {
width: 5,
height: 1,
};
assert!(!smaller.can_hold(&larger));
}
}L’exécution des tests produit maintenant le résultat suivant : console {{#include ../listings/ch11-writing-automated-tests/no-listing-03-introducing-a-bug/output.txt}}
$ cargo test
Compiling rectangle v0.1.0 (file:///projects/rectangle)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/rectangle-6584c4561e48942e)
running 2 tests
test tests::larger_can_hold_smaller ... FAILED
test tests::smaller_cannot_hold_larger ... ok
failures:
---- tests::larger_can_hold_smaller stdout ----
thread 'tests::larger_can_hold_smaller' panicked at src/lib.rs:28:9:
assertion failed: larger.can_hold(&smaller)
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::larger_can_hold_smaller
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Nos tests ont detecte le bogue ! Comme larger.width vaut 8 et smaller.width vaut 5, la comparaison des largeurs dans can_hold retourné maintenant false : 8 n’est pas inférieur à 5.
Tester l’egalite avec assert_eq! et assert_ne!
Une façon courante de vérifier le fonctionnement est de tester l’egalite entre le résultat du code teste et la valeur que vous attendez du code. Vous pourriez le faire en utilisant la macro assert! et en lui passant une expression utilisant l’opérateur ==. Cependant, c’est un test si courant que la bibliothèque standard fournit une paire de macros – assert_eq! et assert_ne! – pour effectuer ce test plus facilement. Ces macros comparent deux arguments pour l’egalite ou l’inegalite, respectivement. Elles affichent également les deux valeurs si l’assertion echoue, ce qui permet de voir plus facilement pourquoi le test a echoue ; à l’inverse, la macro assert! indique seulement qu’elle a obtenu une valeur false pour l’expression ==, sans afficher les valeurs qui ont mene à la valeur false.
Dans l’encart 11-7, nous écrivons une fonction nommee add_two qui ajouté 2 à son paramètre, puis nous testons cette fonction en utilisant la macro assert_eq!.
pub fn add_two(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
}add_two using the assert_eq! macroVerifions que ca reussit ! console {{#include ../listings/ch11-writing-automated-tests/listing-11-07/output.txt}}
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Nous créons une variable nommee result qui contient le résultat de l’appel de add_two(2). Ensuite, nous passons result et 4 comme arguments à la macro assert_eq!. La ligne de sortie pour ce test est test tests::it_adds_two ... ok, et le texte ok indique que notre test a réussi !
Introduisons un bogue dans notre code pour voir a quoi ressemble assert_eq! quand il echoue. Changez l’implémentation de la fonction add_two pour qu’elle ajouté 3 à la place : rust,not_desired_behavior,noplayground {{#rustdoc_include ../listings/ch11-writing-automated-tests/no-listing-04-bug-in-add-two/src/lib.rs:here}}
pub fn add_two(a: u64) -> u64 {
a + 3
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
}Exécutez les tests à nouveau : console {{#include ../listings/ch11-writing-automated-tests/no-listing-04-bug-in-add-two/output.txt}}
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::it_adds_two ... FAILED
failures:
---- tests::it_adds_two stdout ----
thread 'tests::it_adds_two' panicked at src/lib.rs:12:9:
assertion `left == right` failed
left: 5
right: 4
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_adds_two
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Notre test a detecte le bogue ! Le test tests::it_adds_two a echoue, et le message nous indique que l’assertion qui a echoue était left == right et quelles sont les valeurs de left et right. Ce message nous aide a commencer le debogage : l’argument left, ou nous avions le résultat de l’appel de add_two(2), était 5, mais l’argument right était 4. Vous pouvez imaginer que cela serait particulierement utile quand nous avons beaucoup de tests en cours.
Notez que dans certains langages et frameworks de test, les paramètres des fonctions d’assertion d’egalite sont appelés expected et actual, et l’ordre dans lequel nous specifiions les arguments a de l’importance. Cependant, en Rust, ils sont appelés left et right, et l’ordre dans lequel nous specifiions la valeur attendue et la valeur produite par le code n’a pas d’importance. Nous pourrions écrire l’assertion dans ce test comme assert_eq!(4, result), ce qui produirait le même message d’échec affichant assertion `left == right` failed.
La macro assert_ne! reussira si les deux valeurs que nous lui donnons ne sont pas egales et echouera si elles sont egales. Cette macro est surtout utile dans les cas où nous ne savons pas quelle valeur quelque chose aura, mais nous savons quelle valeur elle ne devrait definitivement pas avoir. Par exemple, si nous testons une fonction qui est garantie de modifier son entrée d’une certaine façon, mais la façon dont l’entrée est modifiée depend du jour de la semaine ou nous exécutons nos tests, la meilleure chose a vérifier pourrait être que la sortie de la fonction n’est pas egale à l’entrée.
Sous la surface, les macros assert_eq! et assert_ne! utilisent respectivement les opérateurs == et !=. Quand les assertions echouent, ces macros affichent leurs arguments en utilisant le formatage de debogage, ce qui signifie que les valeurs comparees doivent implémenter les traits PartialEq et Debug. Tous les types primitifs et la plupart des types de la bibliothèque standard implementent ces traits. Pour les structures et les énumérations que vous définissez vous-meme, vous devrez implémenter PartialEq pour vérifier l’egalite de ces types. Vous devrez aussi implémenter Debug pour afficher les valeurs quand l’assertion echoue. Comme les deux traits sont derivables, comme mentionné dans l’encart 5-12 au chapitre 5, c’est généralement aussi simple que d’ajouter l’annotation #[derive(PartialEq, Debug)] à votre définition de structure ou d’énumération. Voir l’annexe C, [“Les traits derivables”][derivable-traits], pour plus de détails sur ces traits derivables et les autres.
Ajouter des messages d’échec personnalises
Vous pouvez aussi ajouter un message personnalise a afficher avec le message d’échec en tant qu’arguments optionnels des macros assert!, assert_eq! et assert_ne!. Tous les arguments spécifiés après les arguments requis sont passes à la macro format! (discutee dans [“La concatenation avec + ou format!”][concatenating] au chapitre 8), vous pouvez donc passer une chaîne de format contenant des emplacements {} et des valeurs a y inserer. Les messages personnalises sont utiles pour documenter ce que signifie une assertion ; quand un test echoue, vous aurez une meilleure idee du problème dans le code.
Par exemple, disons que nous avons une fonction qui salue les personnes par leur nom et que nous voulons tester que le nom que nous passons à la fonction apparaît dans la sortie :
Fichier : src/lib.rs rust,noplayground {{#rustdoc_include ../listings/ch11-writing-automated-tests/listing-11-01/src/lib.rs}}
pub fn greeting(name: &str) -> String {
format!("Hello {name}!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}Les exigences de ce programme n’ont pas encore été définies, et nous sommes assez surs que le texte Hello au début du message de bienvenue changera. Nous avons decide que nous ne voulons pas avoir a mettre à jour le test quand les exigences changent, donc au lieu de vérifier l’egalite exacte avec la valeur retournée par la fonction greeting, nous allons simplement vérifier que la sortie contient le texte du paramètre d’entrée.
Maintenant, introduisons un bogue dans ce code en modifiant greeting pour exclure name afin de voir a quoi ressemble un échec de test par défaut : rust,not_desired_behavior,noplayground {{#rustdoc_include ../listings/ch11-writing-automated-tests/no-listing-06-greeter-with-bug/src/lib.rs:here}}
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(result.contains("Carol"));
}
}L’exécution de ce test produit le résultat suivant : console {{#include ../listings/ch11-writing-automated-tests/no-listing-06-greeter-with-bug/output.txt}}
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at src/lib.rs:12:9:
assertion failed: result.contains("Carol")
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Ce résultat indique seulement que l’assertion a echoue et sur quelle ligne se trouve l’assertion. Un message d’échec plus utile afficherait la valeur de la fonction greeting. Ajoutons un message d’échec personnalise compose d’une chaîne de format avec un emplacement rempli par la valeur réelle que nous avons obtenue de la fonction greeting : rust,ignore {{#rustdoc_include ../listings/ch11-writing-automated-tests/no-listing-07-custom-failure-message/src/lib.rs:here}}
pub fn greeting(name: &str) -> String {
String::from("Hello!")
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn greeting_contains_name() {
let result = greeting("Carol");
assert!(
result.contains("Carol"),
"Greeting did not contain name, value was `{result}`"
);
}
}Maintenant, quand nous exécutons le test, nous obtenons un message d’erreur plus informatif : console {{#include ../listings/ch11-writing-automated-tests/no-listing-07-custom-failure-message/output.txt}}
$ cargo test
Compiling greeter v0.1.0 (file:///projects/greeter)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.93s
Running unittests src/lib.rs (target/debug/deps/greeter-170b942eb5bf5e3a)
running 1 test
test tests::greeting_contains_name ... FAILED
failures:
---- tests::greeting_contains_name stdout ----
thread 'tests::greeting_contains_name' panicked at src/lib.rs:12:9:
Greeting did not contain name, value was `Hello!`
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::greeting_contains_name
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Nous pouvons voir la valeur que nous avons réellement obtenue dans la sortie du test, ce qui nous aide a deboguer ce qui s’est passe au lieu de ce que nous nous attendions a voir se produire.
Vérifier les panics avec should_panic
En plus de vérifier les valeurs de retour, il est important de vérifier que notre code gère les conditions d’erreur comme nous l’attendons. Par exemple, considérez le type Guess que nous avons crée au chapitre 9, dans l’encart 9-13. Le code qui utilise Guess depend de la garantie que les instances de Guess ne contiendront que des valeurs entre 1 et 100. Nous pouvons écrire un test qui s’assuré que tenter de créer une instance de Guess avec une valeur en dehors de cette plage provoque un panic.
Nous faisons cela en ajoutant l’attribut should_panic à notre fonction de test. Le test reussit si le code à l’intérieur de la fonction provoque un panic ; le test echoue si le code à l’intérieur de la fonction ne provoque pas de panic.
L’encart 11-8 montre un test qui vérifie que les conditions d’erreur de Guess::new se produisent quand nous nous y attendons.
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 || value > 100 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}panic!Nous placons l’attribut #[should_panic] après l’attribut #[test] et avant la fonction de test a laquelle il s’applique. Regardons le résultat quand ce test reussit : console {{#include ../listings/ch11-writing-automated-tests/listing-11-08/output.txt}}
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests guessing_game
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Ca à l’air bon ! Maintenant, introduisons un bogue dans notre code en supprimant la condition qui fait que la fonction new provoque un panic si la valeur est supérieure à 100 : rust,not_desired_behavior,noplayground {{#rustdoc_include ../listings/ch11-writing-automated-tests/no-listing-08-guess-with-bug/src/lib.rs:here}}
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!("Guess value must be between 1 and 100, got {value}.");
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic]
fn greater_than_100() {
Guess::new(200);
}
}Quand nous exécutons le test de l’encart 11-8, il echouera : console {{#include ../listings/ch11-writing-automated-tests/no-listing-08-guess-with-bug/output.txt}}
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
note: test did not panic as expected at src/lib.rs:21:8
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Nous n’obtenons pas un message très utile dans ce cas, mais quand nous regardons la fonction de test, nous voyons qu’elle est annotee avec #[should_panic]. L’échec que nous avons obtenu signifie que le code dans la fonction de test n’a pas provoque de panic.
Les tests utilisant should_panic peuvent être imprecis. Un test should_panic reussirait même si le test provoque un panic pour une raison différente de celle que nous attendions. Pour rendre les tests should_panic plus précis, nous pouvons ajouter un paramètre optionnel expected à l’attribut should_panic. Le harnais de test s’assurera que le message d’échec contient le texte fourni. Par exemple, considérez le code modifié pour Guess dans l’encart 11-9 ou la fonction new provoque un panic avec des messages différents selon que la valeur est trop petite ou trop grande.
pub struct Guess {
value: i32,
}
// --snip--
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be greater than or equal to 1, got {value}."
);
} else if value > 100 {
panic!(
"Guess value must be less than or equal to 100, got {value}."
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}panic! with a panic message containing a specified substringCe test reussira parce que la valeur que nous avons mise dans le paramètre expected de l’attribut should_panic est une sous-chaine du message avec lequel la fonction Guess::new provoque un panic. Nous aurions pu spécifier le message de panic complet que nous attendions, qui dans ce cas serait Guess value must be less than or equal to 100, got 200. Ce que vous choisissez de spécifier depend de la quantite du message de panic qui est unique ou dynamique et de la precision que vous souhaitez pour votre test. Dans ce cas, une sous-chaine du message de panic suffit pour s’assurer que le code dans la fonction de test exécute le cas else if value > 100.
Pour voir ce qui se passe quand un test should_panic avec un message expected echoue, introduisons à nouveau un bogue dans notre code en echangeant les corps des blocs if value < 1 et else if value > 100 : rust,ignore,not_desired_behavior {{#rustdoc_include ../listings/ch11-writing-automated-tests/no-listing-09-guess-with-panic-msg-bug/src/lib.rs:here}}
pub struct Guess {
value: i32,
}
impl Guess {
pub fn new(value: i32) -> Guess {
if value < 1 {
panic!(
"Guess value must be less than or equal to 100, got {value}."
);
} else if value > 100 {
panic!(
"Guess value must be greater than or equal to 1, got {value}."
);
}
Guess { value }
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
#[should_panic(expected = "less than or equal to 100")]
fn greater_than_100() {
Guess::new(200);
}
}Cette fois, quand nous exécutons le test should_panic, il echouera : console {{#include ../listings/ch11-writing-automated-tests/no-listing-09-guess-with-panic-msg-bug/output.txt}}
$ cargo test
Compiling guessing_game v0.1.0 (file:///projects/guessing_game)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.66s
Running unittests src/lib.rs (target/debug/deps/guessing_game-57d70c3acb738f4d)
running 1 test
test tests::greater_than_100 - should panic ... FAILED
failures:
---- tests::greater_than_100 stdout ----
thread 'tests::greater_than_100' panicked at src/lib.rs:12:13:
Guess value must be greater than or equal to 1, got 200.
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
note: panic did not contain expected string
panic message: "Guess value must be greater than or equal to 1, got 200."
expected substring: "less than or equal to 100"
failures:
tests::greater_than_100
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Le message d’échec indique que ce test a bien provoque un panic comme nous l’attendions, mais le message de panic ne contenait pas la chaîne attendue less than or equal to 100. Le message de panic que nous avons obtenu dans ce cas était Guess value must be greater than or equal to 1, got 200. Nous pouvons maintenant commencer a chercher ou se trouve notre bogue !
Utiliser Result<T, E> dans les tests
Tous nos tests jusqu’ici provoquent un panic quand ils echouent. Nous pouvons aussi écrire des tests qui utilisent Result<T, E> ! Voici le test de l’encart 11-1, reecrit pour utiliser Result<T, E> et retourner un Err au lieu de provoquer un panic : rust,noplayground {{#rustdoc_include ../listings/ch11-writing-automated-tests/no-listing-10-result-in-tests/src/lib.rs:here}}
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() -> Result<(), String> {
let result = add(2, 2);
if result == 4 {
Ok(())
} else {
Err(String::from("two plus two does not equal four"))
}
}
}La fonction it_works a maintenant le type de retour Result<(), String>. Dans le corps de la fonction, au lieu d’appeler la macro assert_eq!, nous retournons Ok(()) quand le test reussit et un Err contenant un String quand le test echoue.
Écrire des tests qui retournent un Result<T, E> vous permet d’utiliser l’opérateur point d’interrogation dans le corps des tests, ce qui peut être une façon pratique d’écrire des tests qui devraient echouer si une opération en leur sein retourné une variante Err.
Vous ne pouvez pas utiliser l’annotation #[should_panic] sur les tests qui utilisent Result<T, E>. Pour vérifier qu’une opération retourné une variante Err, n’utilisez pas l’opérateur point d’interrogation sur la valeur Result<T, E>. Utilisez plutot assert!(value.is_err()).
Maintenant que vous connaissez plusieurs façons d’écrire des tests, voyons ce qui se passe quand nous exécutons nos tests et explorons les différentes options que nous pouvons utiliser avec cargo test.
Contrôler l’exécution des tests
Contrôler l’exécution des tests
Tout comme cargo run compilé votre code puis exécute le binaire resultant, cargo test compilé votre code en mode test et exécute le binaire de test resultant. Le comportement par défaut du binaire produit par cargo test est d’exécuter tous les tests en parallèle et de capturer la sortie générée pendant l’exécution des tests, empechant la sortie d’être affichée et facilitant la lecture de la sortie liee aux résultats des tests. Vous pouvez cependant spécifier des options en ligne de commande pour modifier ce comportement par défaut.
Certaines options en ligne de commande sont destinees a cargo test, et d’autres au binaire de test resultant. Pour séparer ces deux types d’arguments, vous listez les arguments destines a cargo test suivis du separateur -- puis ceux destines au binaire de test. Exécuter cargo test --help affiche les options utilisables avec cargo test, et exécuter cargo test -- --help affiche les options utilisables après le separateur. Ces options sont également documentees dans [la section “Tests” du livre The rustc Book][tests].
Exécuter les tests en parallèle ou consecutivement
Quand vous exécutez plusieurs tests, par défaut ils s’exécutent en parallèle en utilisant des threads, ce qui signifie qu’ils se terminent plus rapidement et que vous obtenez un retour plus tot. Comme les tests s’exécutent en même temps, vous devez vous assurer que vos tests ne dependent pas les uns des autres ni d’un état partage, y compris un environnement partage, comme le repertoire de travail courant ou les variables d’environnement.
Par exemple, imaginons que chacun de vos tests exécute du code qui crée un fichier sur le disque nomme test-output.txt et écrit des données dans ce fichier. Ensuite, chaque test lit les données de ce fichier et vérifie que le fichier contient une valeur particuliere, qui est différente dans chaque test. Comme les tests s’exécutent en même temps, un test pourrait ecraser le fichier entre le moment où un autre test écrit et lit le fichier. Le second test echouera alors, non pas parce que le code est incorrect mais parce que les tests se sont interferes mutuellement en s’exécutant en parallèle. Une solution est de s’assurer que chaque test écrit dans un fichier différent ; une autre solution est d’exécuter les tests un par un.
Si vous ne voulez pas exécuter les tests en parallèle ou si vous souhaitez un contrôle plus fin sur le nombre de threads utilises, vous pouvez envoyer le drapeau --test-threads et le nombre de threads que vous souhaitez utiliser au binaire de test. Regardez l’exemple suivant :
$ cargo test -- --test-threads=1
Nous avons défini le nombre de threads de test a 1, indiquant au programme de ne pas utiliser de parallelisme. Exécuter les tests avec un seul thread prendra plus de temps que de les exécuter en parallèle, mais les tests ne s’interfereront pas les uns avec les autres s’ils partagent un état.
Afficher la sortie des fonctions
Par défaut, si un test reussit, la bibliothèque de test de Rust capture tout ce qui est affiche sur la sortie standard. Par exemple, si nous appelons println! dans un test et que le test reussit, nous ne verrons pas la sortie de println! dans le terminal ; nous verrons seulement la ligne qui indique que le test a réussi. Si un test echoue, nous verrons tout ce qui a été affiche sur la sortie standard avec le reste du message d’échec.
A titre d’exemple, l’encart 11-10 contient une fonction simple qui affiche la valeur de son paramètre et retourné 10, ainsi qu’un test qui reussit et un test qui echoue.
fn prints_and_returns_10(a: i32) -> i32 {
println!("I got the value {a}");
10
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn this_test_will_pass() {
let value = prints_and_returns_10(4);
assert_eq!(value, 10);
}
#[test]
fn this_test_will_fail() {
let value = prints_and_returns_10(8);
assert_eq!(value, 5);
}
}println!Quand nous exécutons ces tests avec cargo test, nous verrons la sortie suivante : console {{#include ../listings/ch11-writing-automated-tests/listing-11-10/output.txt}}
$ cargo test
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.58s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Notez que nulle part dans cette sortie nous ne voyons I got the value 4, qui est affiche quand le test qui reussit s’exécute. Cette sortie a été capturee. La sortie du test qui a echoue, I got the value 8, apparaît dans la section du resume de sortie des tests, qui montre également la cause de l’échec du test.
Si nous voulons voir les valeurs affichées pour les tests qui reussissent également, nous pouvons demander a Rust d’afficher aussi la sortie des tests reussis avec --show-output :
$ cargo test -- --show-output
Quand nous exécutons les tests de l’encart 11-10 à nouveau avec le drapeau --show-output, nous voyons la sortie suivante : console {{#include ../listings/ch11-writing-automated-tests/output-only-01-show-output/output.txt}}
$ cargo test -- --show-output
Compiling silly-function v0.1.0 (file:///projects/silly-function)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/silly_function-160869f38cff9166)
running 2 tests
test tests::this_test_will_fail ... FAILED
test tests::this_test_will_pass ... ok
successes:
---- tests::this_test_will_pass stdout ----
I got the value 4
successes:
tests::this_test_will_pass
failures:
---- tests::this_test_will_fail stdout ----
I got the value 8
thread 'tests::this_test_will_fail' panicked at src/lib.rs:19:9:
assertion `left == right` failed
left: 10
right: 5
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::this_test_will_fail
test result: FAILED. 1 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Exécuter un sous-ensemble de tests par nom
Exécuter une suite de tests complète peut parfois prendre beaucoup de temps. Si vous travaillez sur du code dans un domaine particulier, vous pourriez vouloir n’exécuter que les tests relatifs à ce code. Vous pouvez choisir quels tests exécuter en passant a cargo test le nom ou les noms du ou des tests que vous souhaitez exécuter en argument.
Pour montrer comment exécuter un sous-ensemble de tests, nous allons d’abord créer trois tests pour notre fonction add_two, comme montre dans l’encart 11-11, et choisir lesquels exécuter.
pub fn add_two(a: u64) -> u64 {
a + 2
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn add_two_and_two() {
let result = add_two(2);
assert_eq!(result, 4);
}
#[test]
fn add_three_and_two() {
let result = add_two(3);
assert_eq!(result, 5);
}
#[test]
fn one_hundred() {
let result = add_two(100);
assert_eq!(result, 102);
}
}Si nous exécutons les tests sans passer d’arguments, comme nous l’avons vu precedemment, tous les tests s’exécuteront en parallèle : console {{#include ../listings/ch11-writing-automated-tests/listing-11-11/output.txt}}
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.62s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 3 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test tests::one_hundred ... ok
test result: ok. 3 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Exécuter un seul test
Nous pouvons passer le nom de n’importe quelle fonction de test a cargo test pour n’exécuter que ce test : console {{#include ../listings/ch11-writing-automated-tests/output-only-02-single-test/output.txt}}
$ cargo test one_hundred
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.69s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::one_hundred ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 2 filtered out; finished in 0.00s
Seul le test nomme one_hundred a été exécute ; les deux autres tests ne correspondaient pas à ce nom. La sortie des tests nous indique qu’il y avait d’autres tests qui n’ont pas été exécutés en affichant 2 filtered out à la fin.
Nous ne pouvons pas spécifier les noms de plusieurs tests de cette façon ; seule la première valeur donnée a cargo test sera utilisee. Mais il existe un moyen d’exécuter plusieurs tests.
Filtrer pour exécuter plusieurs tests
Nous pouvons spécifier une partie d’un nom de test, et tout test dont le nom correspond à cette valeur sera exécute. Par exemple, comme deux de nos noms de tests contiennent add, nous pouvons exécuter ces deux-la en lancant cargo test add : console {{#include ../listings/ch11-writing-automated-tests/output-only-03-multiple-tests/output.txt}}
$ cargo test add
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::add_three_and_two ... ok
test tests::add_two_and_two ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Cette commande a exécute tous les tests contenant add dans leur nom et a filtre le test nomme one_hundred. Notez également que le module dans lequel un test apparaît fait partie du nom du test, nous pouvons donc exécuter tous les tests d’un module en filtrant sur le nom du module.
Ignorer des tests sauf demande explicite
Parfois, quelques tests spécifiques peuvent être très longs a exécuter, vous pourriez donc vouloir les exclure lors de la plupart des exécutions de cargo test. Plutot que de lister en arguments tous les tests que vous souhaitez exécuter, vous pouvez annoter les tests chronophages avec l’attribut ignore pour les exclure, comme montre ici :
Fichier : src/lib.rs rust,noplayground {{#rustdoc_include ../listings/ch11-writing-automated-tests/listing-11-01/src/lib.rs}}
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
#[test]
#[ignore]
fn expensive_test() {
// code that takes an hour to run
}
}Après #[test], nous ajoutons la ligne #[ignore] au test que nous voulons exclure. Maintenant, quand nous exécutons nos tests, it_works s’exécute, mais expensive_test ne s’exécute pas : console {{#include ../listings/ch11-writing-automated-tests/no-listing-11-ignore-a-test/output.txt}}
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.60s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 2 tests
test tests::expensive_test ... ignored
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 1 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
La fonction expensive_test est listee comme ignored. Si nous voulons n’exécuter que les tests ignores, nous pouvons utiliser cargo test -- --ignored : console {{#include ../listings/ch11-writing-automated-tests/output-only-04-running-ignored/output.txt}}
$ cargo test -- --ignored
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.61s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::expensive_test ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 1 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
En controlant quels tests s’exécutent, vous pouvez vous assurer que les résultats de cargo test seront retournés rapidement. Quand vous en etes à un point ou il est logique de vérifier les résultats des tests ignored et que vous avez le temps d’attendre les résultats, vous pouvez exécuter cargo test -- --ignored à la place. Si vous voulez exécuter tous les tests, qu’ils soient ignores ou non, vous pouvez exécuter cargo test -- --include-ignored.
L’organisation des tests
L’organisation des tests
Comme mentionné au début du chapitre, les tests sont une discipline complexe, et différentes personnes utilisent une terminologie et une organisation différentes. La communauté Rust pense aux tests en termes de deux catégories principales : les tests unitaires et les tests d’intégration. Les tests unitaires sont petits et plus cibles, testant un module à la fois de maniere isolee, et peuvent tester les interfaces privees. Les tests d’integration sont entierement externes à votre bibliothèque et utilisent votre code de la même façon que n’importe quel autre code externe le ferait, en n’utilisant que l’interface publique et en exercant potentiellement plusieurs modules par test.
Écrire les deux types de tests est important pour s’assurer que les composants de votre bibliothèque font ce que vous attendez d’eux, séparément et ensemble.
Tests unitaires
L’objectif des tests unitaires est de tester chaque unité de code isolement du reste du code pour identifier rapidement ou le code fonctionne ou ne fonctionne pas comme prevu. Vous placerez les tests unitaires dans le repertoire src dans chaque fichier avec le code qu’ils testent. La convention est de créer un module nomme tests dans chaque fichier pour contenir les fonctions de test et d’annoter le module avec cfg(test).
Le module tests et #[cfg(test)]
L’annotation #[cfg(test)] sur le module tests indique a Rust de compiler et d’exécuter le code de test uniquement quand vous exécutez cargo test, et non quand vous exécutez cargo build. Cela economise du temps de compilation quand vous voulez seulement compiler la bibliothèque et economise de l’espace dans l’artefact compilé resultant parce que les tests ne sont pas inclus. Vous verrez que comme les tests d’intégration sont dans un repertoire différent, ils n’ont pas besoin de l’annotation #[cfg(test)]. Cependant, comme les tests unitaires sont dans les mêmes fichiers que le code, vous utiliserez #[cfg(test)] pour spécifier qu’ils ne doivent pas être inclus dans le résultat compilé.
Rappelez-vous que lorsque nous avons génère le nouveau projet adder dans la première section de ce chapitre, Cargo a génère ce code pour nous :
Fichier : src/lib.rs rust,noplayground {{#rustdoc_include ../listings/ch11-writing-automated-tests/listing-11-01/src/lib.rs}}
pub fn add(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
let result = add(2, 2);
assert_eq!(result, 4);
}
}Sur le module tests génère automatiquement, l’attribut cfg signifie configuration et indique a Rust que l’élément suivant ne doit être inclus que pour une certaine option de configuration. Dans ce cas, l’option de configuration est test, qui est fournie par Rust pour la compilation et l’exécution des tests. En utilisant l’attribut cfg, Cargo ne compilé notre code de test que si nous exécutons activement les tests avec cargo test. Cela inclut toutes les fonctions utilitaires qui pourraient se trouver dans ce module, en plus des fonctions annotees avec #[test].
Tests de fonctions privees
Il y à un debat au sein de la communauté des testeurs pour savoir si les fonctions privees doivent être testees directement ou non, et d’autres langages rendent difficile ou impossible le test des fonctions privees. Quelle que soit l’ideologie de test a laquelle vous adherez, les règles de confidentialite de Rust vous permettent de tester les fonctions privees. Considérez le code de l’encart 11-12 avec la fonction privee internal_adder.
pub fn add_two(a: u64) -> u64 {
internal_adder(a, 2)
}
fn internal_adder(left: u64, right: u64) -> u64 {
left + right
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn internal() {
let result = internal_adder(2, 2);
assert_eq!(result, 4);
}
}Notez que la fonction internal_adder n’est pas marquee comme pub. Les tests ne sont que du code Rust, et le module tests n’est qu’un autre module. Comme nous l’avons vu dans [“Les chemins pour faire référence à un élément dans l’arborescence des modules”][paths], les éléments des modules enfants peuvent utiliser les éléments de leurs modules ancetres. Dans ce test, nous importons tous les éléments appartenant au parent du module tests dans la portée avec use super::*, et le test peut alors appeler internal_adder. Si vous pensez que les fonctions privees ne devraient pas être testees, rien dans Rust ne vous obligera à le faire.
Tests d’intégration
En Rust, les tests d’intégration sont entierement externes à votre bibliothèque. Ils utilisent votre bibliothèque de la même façon que n’importe quel autre code le ferait, ce qui signifie qu’ils ne peuvent appeler que les fonctions faisant partie de l’API publique de votre bibliothèque. Leur objectif est de tester si de nombreuses parties de votre bibliothèque fonctionnent correctement ensemble. Des unités de code qui fonctionnent correctement individuellement pourraient avoir des problèmes une fois intégrées, donc la couverture de test du code integre est également importante. Pour créer des tests d’intégration, vous avez d’abord besoin d’un repertoire tests.
Le repertoire tests
Nous créons un repertoire tests au niveau supérieur de notre repertoire de projet, a côté de src. Cargo sait qu’il doit chercher les fichiers de tests d’intégration dans ce repertoire. Nous pouvons alors créer autant de fichiers de test que nous le souhaitons, et Cargo compilera chacun des fichiers comme un crate individuel.
Créons un test d’intégration. Avec le code de l’encart 11-12 toujours dans le fichier src/lib.rs, créez un repertoire tests et créez un nouveau fichier nomme tests/integration_test.rs. Votre structure de repertoire devrait ressembler a ceci :
adder
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
└── integration_test.rs
Entrez le code de l’encart 11-13 dans le fichier tests/integration_test.rs.
use adder::add_two;
#[test]
fn it_adds_two() {
let result = add_two(2);
assert_eq!(result, 4);
}adder crateChaque fichier dans le repertoire tests est un crate séparé, nous devons donc importer notre bibliothèque dans la portée de chaque crate de test. C’est pourquoi nous ajoutons use adder::add_two; en haut du code, ce que nous n’avions pas besoin de faire dans les tests unitaires.
Nous n’avons pas besoin d’annoter le code dans tests/integration_test.rs avec #[cfg(test)]. Cargo traite le repertoire tests de maniere speciale et ne compilé les fichiers de ce repertoire que lorsque nous exécutons cargo test. Exécutez cargo test maintenant : console {{#include ../listings/ch11-writing-automated-tests/listing-11-13/output.txt}}
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.31s
Running unittests src/lib.rs (target/debug/deps/adder-1082c4b063a8fbe6)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-1082c4b063a8fbe6)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Les trois sections de sortie comprennent les tests unitaires, le test d’intégration et les tests de documentation. Notez que si un test d’une section echoue, les sections suivantes ne seront pas exécutées. Par exemple, si un test unitaire echoue, il n’y aura pas de sortie pour les tests d’intégration et de documentation, car ces tests ne seront exécutés que si tous les tests unitaires reussissent.
La première section pour les tests unitaires est la même que ce que nous avons vu : une ligne pour chaque test unitaire (un nomme internal que nous avons ajouté dans l’encart 11-12) puis une ligne de resume pour les tests unitaires.
La section des tests d’intégration commence par la ligne Running tests/integration_test.rs. Ensuite, il y à une ligne pour chaque fonction de test dans ce test d’intégration et une ligne de resume pour les résultats du test d’intégration juste avant le début de la section Doc-tests adder.
Chaque fichier de test d’intégration à sa propre section, donc si nous ajoutons plus de fichiers dans le repertoire tests, il y aura plus de sections de tests d’intégration.
Nous pouvons toujours exécuter une fonction de test d’intégration particuliere en specifiant le nom de la fonction de test comme argument de cargo test. Pour exécuter tous les tests d’un fichier de test d’intégration particulier, utilisez l’argument --test de cargo test suivi du nom du fichier : console {{#include ../listings/ch11-writing-automated-tests/output-only-05-single-integration/output.txt}}
$ cargo test --test integration_test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.64s
Running tests/integration_test.rs (target/debug/deps/integration_test-82e7799c1bc62298)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Cette commande n’exécute que les tests du fichier tests/integration_test.rs.
Sous-modules dans les tests d’intégration
Au fur et a mesure que vous ajoutez des tests d’intégration, vous pourriez vouloir créer plus de fichiers dans le repertoire tests pour les organiser ; par exemple, vous pouvez regrouper les fonctions de test par la fonctionnalité qu’elles testent. Comme mentionné precedemment, chaque fichier dans le repertoire tests est compilé comme son propre crate séparé, ce qui est utile pour créer des portées séparées afin d’imiter plus fidèlement la façon dont les utilisateurs finaux utiliseront votre crate. Cependant, cela signifie que les fichiers dans le repertoire tests ne partagent pas le même comportement que les fichiers dans src, comme vous l’avez appris au chapitre 7 concernant la séparation du code en modules et fichiers.
Le comportement différent des fichiers du repertoire tests est plus visible quand vous avez un ensemble de fonctions utilitaires à utiliser dans plusieurs fichiers de tests d’intégration, et que vous essayez de suivre les étapes de la section [“Séparer les modules dans différents fichiers”][separating-modules-into-files] du chapitre 7 pour les extraire dans un module commun. Par exemple, si nous créons tests/common.rs et y placons une fonction nommee setup, nous pouvons ajouter du code a setup que nous voulons appeler depuis plusieurs fonctions de test dans plusieurs fichiers de test :
Fichier : tests/common.rs rust,noplayground {{#rustdoc_include ../listings/ch11-writing-automated-tests/no-listing-12-shared-test-code-problem/tests/common.rs}}
pub fn setup() {
// setup code specific to your library's tests would go here
}Quand nous exécutons les tests à nouveau, nous verrons une nouvelle section dans la sortie des tests pour le fichier common.rs, même si ce fichier ne contient aucune fonction de test et que nous n’avons appelé la fonction setup depuis nulle part : console {{#include ../listings/ch11-writing-automated-tests/no-listing-12-shared-test-code-problem/output.txt}}
$ cargo test
Compiling adder v0.1.0 (file:///projects/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.89s
Running unittests src/lib.rs (target/debug/deps/adder-92948b65e88960b4)
running 1 test
test tests::internal ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/common.rs (target/debug/deps/common-92948b65e88960b4)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running tests/integration_test.rs (target/debug/deps/integration_test-92948b65e88960b4)
running 1 test
test it_adds_two ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests adder
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Voir common apparaître dans les résultats de test avec running 0 tests affiche n’est pas ce que nous voulions. Nous voulions simplement partager du code avec les autres fichiers de tests d’intégration. Pour éviter que common apparaisse dans la sortie des tests, au lieu de créer tests/common.rs, nous allons créer tests/common/mod.rs. Le repertoire du projet ressemble maintenant a ceci :
├── Cargo.lock
├── Cargo.toml
├── src
│ └── lib.rs
└── tests
├── common
│ └── mod.rs
└── integration_test.rs
C’est l’ancienne convention de nommage que Rust comprend également et que nous avons mentionnée dans [“Chemins de fichiers alternatifs”][alt-paths] au chapitre 7. Nommer le fichier de cette façon indique a Rust de ne pas traiter le module common comme un fichier de test d’intégration. Quand nous deplacons le code de la fonction setup dans tests/common/mod.rs et supprimons le fichier tests/common.rs, la section dans la sortie des tests n’apparaîtra plus. Les fichiers dans les sous-repertoires du repertoire tests ne sont pas compilés comme des crates séparés et n’ont pas de sections dans la sortie des tests.
Après avoir crée tests/common/mod.rs, nous pouvons l’utiliser depuis n’importe quel fichier de test d’intégration en tant que module. Voici un exemple d’appel de la fonction setup depuis le test it_adds_two dans tests/integration_test.rs :
Fichier : tests/integration_test.rs rust,ignore {{#rustdoc_include ../listings/ch11-writing-automated-tests/no-listing-13-fix-shared-test-code-problem/tests/integration_test.rs}}
use adder::add_two;
mod common;
#[test]
fn it_adds_two() {
common::setup();
let result = add_two(2);
assert_eq!(result, 4);
}Notez que la déclaration mod common; est la même que la déclaration de module que nous avons montrée dans l’encart 7-21. Ensuite, dans la fonction de test, nous pouvons appeler la fonction common::setup().
Tests d’intégration pour les crates binaires
Si notre projet est un crate binaire qui ne contient qu’un fichier src/main.rs et n’a pas de fichier src/lib.rs, nous ne pouvons pas créer de tests d’intégration dans le repertoire tests et importer les fonctions définies dans le fichier src/main.rs dans la portée avec une instruction use. Seuls les crates de bibliothèque exposent des fonctions que d’autres crates peuvent utiliser ; les crates binaires sont destines a être exécutés de maniere autonome.
C’est l’une des raisons pour lesquelles les projets Rust qui fournissent un binaire ont un fichier src/main.rs simple qui appelle la logique qui reside dans le fichier src/lib.rs. Avec cette structure, les tests d’intégration peuvent tester le crate de bibliothèque avec use pour rendre la fonctionnalité importante disponible. Si la fonctionnalité importante fonctionne, la petite quantite de code dans le fichier src/main.rs fonctionnera également, et cette petite quantite de code n’a pas besoin d’être testee.
Résumé
Les fonctionnalités de test de Rust fournissent un moyen de spécifier comment le code devrait fonctionner pour s’assurer qu’il continue a fonctionner comme vous l’attendez, même lorsque vous apportez des modifications. Les tests unitaires exercent différentes parties d’une bibliothèque séparément et peuvent tester les détails d’implémentation prives. Les tests d’intégration vérifient que de nombreuses parties de la bibliothèque fonctionnent correctement ensemble, et ils utilisent l’API publique de la bibliothèque pour tester le code de la même maniere que le code externe l’utilisera. Même si le système de types et les règles de possession de Rust aident a prevenir certains types de bogues, les tests restent importants pour reduire les bogues logiques lies à la façon dont votre code est cense se comporter.
Combinons les connaissances que vous avez acquises dans ce chapitre et dans les chapitres précédents pour travailler sur un projet !
Un projet d’E/S : construire un programme en ligne de commande
Ce chapitre est un récapitulatif des nombreuses compétences que vous avez acquises jusqu’ici, ainsi qu’une exploration de quelques fonctionnalités supplémentaires de la bibliothèque standard. Nous allons construire un outil en ligne de commande qui interagit avec les entrées/sorties de fichiers et de la ligne de commande pour mettre en pratique certains des concepts de Rust que vous maîtrisez désormais.
La rapidité, la sécurité, la production d’un binaire unique et la prise en charge multiplateforme de Rust en font un langage idéal pour créer des outils en ligne de commande. Pour notre projet, nous allons donc créer notre propre version du classique outil de recherche en ligne de commande grep (globally search a regular expression and print). Dans le cas d’utilisation le plus simple, grep recherche une chaîne de caractères spécifiée dans un fichier donné. Pour ce faire, grep prend en arguments un chemin de fichier et une chaîne de caractères. Ensuite, il lit le fichier, trouve les lignes qui contiennent la chaîne en argument, et affiche ces lignes.
En cours de route, nous montrerons comment faire en sorte que notre outil en ligne de commande utilise les fonctionnalités du terminal que de nombreux autres outils en ligne de commande utilisent. Nous lirons la valeur d’une variable d’environnement pour permettre à l’utilisateur de configurer le comportement de notre outil. Nous afficherons également les messages d’erreur sur le flux d’erreur standard (stderr) plutôt que sur la sortie standard (stdout), de sorte que, par exemple, l’utilisateur puisse rediriger la sortie réussie vers un fichier tout en continuant à voir les messages d’erreur à l’écran.
Un membre de la communauté Rust, Andrew Gallant, a déjà créé une version complète et très rapide de grep, appelée ripgrep. En comparaison, notre version sera assez simple, mais ce chapitre vous donnera les connaissances de base nécessaires pour comprendre un projet concret tel que ripgrep.
Notre projet grep combinera un certain nombre de concepts que vous avez appris jusqu’ici :
- Organiser le code (chapitre 7)
- Utiliser les vecteurs et les chaînes de caractères (chapitre 8)
- Gérer les erreurs (chapitre 9)
- Utiliser les traits et les durées de vie là où c’est approprié (chapitre 10)
- Écrire des tests (chapitre 11)
Nous introduirons également brièvement les fermetures, les itérateurs et les objets trait, que le chapitre 13 et le chapitre 18 couvriront en détail.
Accepter des arguments en ligne de commande
Accepter des arguments en ligne de commande
Créons un nouveau projet avec, comme toujours, cargo new. Nous appellerons notre projet minigrep pour le distinguer de l’outil grep que vous avez peut-être déjà sur votre système :
$ cargo new minigrep
Created binary (application) `minigrep` project
$ cd minigrep
La première tâche consiste à faire en sorte que minigrep accepte ses deux arguments de ligne de commande : le chemin du fichier et une chaîne de caractères à rechercher. Autrement dit, nous voulons pouvoir exécuter notre programme avec cargo run, deux tirets pour indiquer que les arguments suivants sont destinés à notre programme plutôt qu’à cargo, une chaîne à rechercher, et un chemin vers un fichier dans lequel chercher, comme ceci :
$ cargo run -- searchstring example-filename.txt
Pour le moment, le programme généré par cargo new ne peut pas traiter les arguments que nous lui fournissons. Certaines bibliothèques existantes sur crates.io peuvent aider à écrire un programme qui accepte des arguments de ligne de commande, mais comme vous êtes en train d’apprendre ce concept, implémentons cette fonctionnalité nous-mêmes.
Lire les valeurs des arguments
Pour permettre à minigrep de lire les valeurs des arguments de ligne de commande que nous lui passons, nous aurons besoin de la fonction std::env::args fournie par la bibliothèque standard de Rust. Cette fonction renvoie un itérateur des arguments de ligne de commande passés à minigrep. Nous couvrirons les itérateurs en détail dans le [Chapitre 13][ch13]. Pour le moment, vous n’avez besoin de connaître que deux détails sur les itérateurs : les itérateurs produisent une série de valeurs, et nous pouvons appeler la méthode collect sur un itérateur pour le transformer en une collection, telle qu’un vecteur, qui contient tous les éléments produits par l’itérateur.
Le code de l’encart 12-1 permet à votre programme minigrep de lire tous les arguments de ligne de commande qui lui sont passés, puis de rassembler les valeurs dans un vecteur.
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
dbg!(args);
}Tout d’abord, nous importons le module std::env dans la portée avec une instruction use afin de pouvoir utiliser sa fonction args. Remarquez que la fonction std::env::args est imbriquée dans deux niveaux de modules. Comme nous l’avons vu dans le [Chapitre 7][ch7-idiomatic-use], dans les cas où la fonction souhaitée est imbriquée dans plus d’un module, nous avons choisi d’importer le module parent dans la portée plutôt que la fonction elle-même. Ce faisant, nous pouvons facilement utiliser d’autres fonctions de std::env. C’est aussi moins ambigu que d’ajouter use std::env::args puis d’appeler la fonction avec simplement args, car args pourrait facilement être confondu avec une fonction définie dans le module courant.
La fonction args et l’Unicode invalide
Notez que std::env::args va paniquer si un argument contient de l’Unicode invalide. Si votre programme doit accepter des arguments contenant de l’Unicode invalide, utilisez plutôt std::env::args_os. Cette fonction renvoie un itérateur qui produit des valeurs OsString au lieu de valeurs String. Nous avons choisi d’utiliser std::env::args ici par souci de simplicité, car les valeurs OsString diffèrent selon la plateforme et sont plus complexes à manipuler que les valeurs String.
Sur la première ligne de main, nous appelons env::args, et nous utilisons immédiatement collect pour transformer l’itérateur en un vecteur contenant toutes les valeurs produites par l’itérateur. Nous pouvons utiliser la fonction collect pour créer de nombreux types de collections, nous annotons donc explicitement le type de args pour spécifier que nous voulons un vecteur de chaînes de caractères. Bien que vous ayez très rarement besoin d’annoter les types en Rust, collect est une fonction pour laquelle vous devez souvent le faire, car Rust n’est pas en mesure d’inférer le type de collection que vous souhaitez.
Enfin, nous affichons le vecteur en utilisant la macro de débogage. Essayons d’exécuter le code d’abord sans arguments, puis avec deux arguments : console {{#include ../listings/ch12-an-io-project/listing-12-01/output.txt}} console {{#include ../listings/ch12-an-io-project/output-only-01-with-args/output.txt}}
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.61s
Running `target/debug/minigrep`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
]
$ cargo run -- needle haystack
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.57s
Running `target/debug/minigrep needle haystack`
[src/main.rs:5:5] args = [
"target/debug/minigrep",
"needle",
"haystack",
]
Remarquez que la première valeur du vecteur est "target/debug/minigrep", qui est le nom de notre binaire. Cela correspond au comportement de la liste d’arguments en C, permettant aux programmes d’utiliser le nom par lequel ils ont été invoqués lors de leur exécution. Il est souvent pratique d’avoir accès au nom du programme au cas où vous voudriez l’afficher dans des messages ou modifier le comportement du programme en fonction de l’alias de ligne de commande utilisé pour l’invoquer. Mais pour les besoins de ce chapitre, nous l’ignorerons et ne conserverons que les deux arguments dont nous avons besoin.
Sauvegarder les valeurs des arguments dans des variables
Le programme est actuellement capable d’accéder aux valeurs spécifiées comme arguments de ligne de commande. Maintenant, nous devons sauvegarder les valeurs des deux arguments dans des variables afin de pouvoir utiliser ces valeurs dans le reste du programme. Nous faisons cela dans l’encart 12-2.
use std::env;
fn main() {
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {query}");
println!("In file {file_path}");
}Comme nous l’avons vu lorsque nous avons affiché le vecteur, le nom du programme occupe la première valeur du vecteur à args[0], nous commençons donc les arguments à l’index 1. Le premier argument que prend minigrep est la chaîne que nous recherchons, nous plaçons donc une référence au premier argument dans la variable query. Le second argument sera le chemin du fichier, nous plaçons donc une référence au second argument dans la variable file_path.
Nous affichons temporairement les valeurs de ces variables pour prouver que le code fonctionne comme prévu. Exécutons à nouveau ce programme avec les arguments test et sample.txt : console {{#include ../listings/ch12-an-io-project/listing-12-02/output.txt}}
$ cargo run -- test sample.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep test sample.txt`
Searching for test
In file sample.txt
Parfait, le programme fonctionne ! Les valeurs des arguments dont nous avons besoin sont sauvegardées dans les bonnes variables. Plus tard, nous ajouterons de la gestion d’erreurs pour traiter certaines situations potentiellement erronées, comme lorsque l’utilisateur ne fournit aucun argument ; pour l’instant, nous ignorerons cette situation et travaillerons plutôt sur l’ajout de fonctionnalités de lecture de fichiers.
Lire un fichier
Lire un fichier
Nous allons maintenant ajouter la fonctionnalité de lecture du fichier spécifié dans l’argument file_path. Tout d’abord, nous avons besoin d’un fichier d’exemple pour le tester : nous utiliserons un fichier contenant une petite quantité de texte sur plusieurs lignes avec quelques mots répétés. L’encart 12-3 contient un poème d’Emily Dickinson qui conviendra parfaitement ! Créez un fichier appelé poem.txt à la racine de votre projet, et saisissez le poème “I’m Nobody! Who are you?”
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Avec le texte en place, modifiez src/main.rs et ajoutez du code pour lire le fichier, comme illustré dans l’encart 12-4.
use std::env;
use std::fs;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let query = &args[1];
let file_path = &args[2];
println!("Searching for {query}");
println!("In file {file_path}");
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:
{contents}");
}Tout d’abord, nous importons une partie pertinente de la bibliothèque standard avec une instruction use : nous avons besoin de std::fs pour manipuler les fichiers.
Dans main, la nouvelle instruction fs::read_to_string prend le file_path, ouvre ce fichier, et renvoie une valeur de type std::io::Result<String> qui contient le contenu du fichier.
Ensuite, nous ajoutons à nouveau une instruction println! temporaire qui affiche la valeur de contents après la lecture du fichier afin de vérifier que le programme fonctionne jusqu’ici.
Exécutons ce code avec n’importe quelle chaîne comme premier argument de ligne de commande (car nous n’avons pas encore implémenté la partie recherche) et le fichier poem.txt comme second argument : console {{#rustdoc_include ../listings/ch12-an-io-project/listing-12-04/output.txt}}
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Parfait ! Le code a lu puis affiché le contenu du fichier. Mais le code présente quelques défauts. Pour le moment, la fonction main à plusieurs responsabilités : en général, les fonctions sont plus claires et plus faciles à maintenir si chaque fonction n’est responsable que d’une seule chose. L’autre problème est que nous ne gérons pas les erreurs aussi bien que nous le pourrions. Le programme est encore petit, donc ces défauts ne constituent pas un gros problème, mais à mesure que le programme grandit, il sera plus difficile de les corriger proprement. C’est une bonne pratique de commencer le refactoring tôt lors du développement d’un programme, car il est beaucoup plus facile de remanier de petites quantités de code. C’est ce que nous ferons ensuite.
Refactoriser pour améliorer la modularité et la gestion des erreurs
Refactoriser pour améliorer la modularité et la gestion des erreurs
Pour améliorer notre programme, nous allons corriger quatre problèmes liés à la structure du programme et à la façon dont il gère les erreurs potentielles. Premièrement, notre fonction main effectue désormais deux tâches : elle analyse les arguments et lit les fichiers. À mesure que notre programme grandit, le nombre de tâches distinctes que la fonction main gère augmentera. Quand une fonction accumule les responsabilités, elle devient plus difficile à comprendre, plus difficile à tester et plus difficile à modifier sans casser l’une de ses parties. Il est préférable de séparer les fonctionnalités de sorte que chaque fonction soit responsable d’une seule tâche.
Ce problème est aussi lié au deuxième : bien que query et file_path soient des variables de configuration de notre programme, des variables comme contents sont utilisées pour exécuter la logique du programme. Plus main s’allonge, plus nous aurons de variables à mettre en portée ; plus nous avons de variables en portée, plus il sera difficile de suivre l’objectif de chacune. Il est préférable de regrouper les variables de configuration dans une seule structure pour clarifier leur rôle.
Le troisième problème est que nous avons utilisé expect pour afficher un message d’erreur lorsque la lecture du fichier échoue, mais le message d’erreur affiche simplement Should have been able to read the file. La lecture d’un fichier peut échouer de nombreuses façons : par exemple, le fichier pourrait être manquant, ou nous pourrions ne pas avoir la permission de l’ouvrir. Actuellement, quelle que soit la situation, nous afficherions le même message d’erreur pour tout, ce qui ne donnerait aucune information à l’utilisateur !
Quatrièmement, nous utilisons expect pour gérer une erreur, et si l’utilisateur exécute notre programme sans spécifier suffisamment d’arguments, il obtiendra une erreur index out of bounds de Rust qui n’explique pas clairement le problème. Il serait préférable que tout le code de gestion des erreurs soit au même endroit, de sorte que les futurs mainteneurs n’aient qu’un seul endroit à consulter si la logique de gestion des erreurs devait changer. Avoir tout le code de gestion des erreurs au même endroit garantira également que nous affichons des messages significatifs pour nos utilisateurs finaux.
Résolvons ces quatre problèmes en refactorisant notre projet.
Séparer les responsabilités dans les projets binaires
Le problème organisationnel consistant à attribuer la responsabilité de plusieurs tâches à la fonction main est commun à de nombreux projets binaires. Par conséquent, de nombreux programmeurs Rust trouvent utile de séparer les différentes responsabilités d’un programme binaire lorsque la fonction main commence à devenir volumineuse. Ce processus comprend les étapes suivantes : - Diviser votre programme en un fichier main.rs et un fichier lib.rs, et déplacer la logique de votre programme dans lib.rs. - Tant que votre logique d’analyse de la ligne de commande est petite, elle peut rester dans la fonction main. - Lorsque la logique d’analyse de la ligne de commande commence à devenir complexe, l’extraire de la fonction main dans d’autres fonctions ou types.
- Diviser votre programme en un fichier main.rs et un fichier lib.rs, et déplacer la logique de votre programme dans lib.rs.
- Tant que votre logique d’analyse de la ligne de commande est petite, elle peut rester dans la fonction
main. - Lorsque la logique d’analyse de la ligne de commande commence à devenir complexe, l’extraire de la fonction
maindans d’autres fonctions ou types.
Les responsabilités qui restent dans la fonction main après ce processus devraient se limiter aux suivantes : - Appeler la logique d’analyse de la ligne de commande avec les valeurs des arguments - Mettre en place toute autre configuration - Appeler une fonction run dans lib.rs - Gérer l’erreur si run renvoie une erreur
- Appeler la logique d’analyse de la ligne de commande avec les valeurs des arguments
- Mettre en place toute autre configuration
- Appeler une fonction
rundans lib.rs - Gérer l’erreur si
runrenvoie une erreur
Ce patron consiste à séparer les responsabilités : main.rs gère l’exécution du programme et lib.rs gère toute la logique de la tâche en cours. Comme vous ne pouvez pas tester directement la fonction main, cette structure vous permet de tester toute la logique de votre programme en la déplaçant hors de la fonction main. Le code qui reste dans la fonction main sera suffisamment petit pour vérifier son exactitude en le lisant. Retravaillons notre programme en suivant ce processus.
Extraire l’analyseur d’arguments
Nous allons extraire la fonctionnalité d’analyse des arguments dans une fonction que main appellera. L’encart 12-5 montre le nouveau début de la fonction main qui appelle une nouvelle fonction parse_config, que nous définirons dans src/main.rs.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let (query, file_path) = parse_config(&args);
// --snip--
println!("Searching for {query}");
println!("In file {file_path}");
let contents = fs::read_to_string(file_path)
.expect("Should have been able to read the file");
println!("With text:
{contents}");
}
fn parse_config(args: &[String]) -> (&str, &str) {
let query = &args[1];
let file_path = &args[2];
(query, file_path)
}parse_config function from mainNous collectons toujours les arguments de ligne de commande dans un vecteur, mais au lieu d’assigner la valeur de l’argument à l’index 1 à la variable query et la valeur de l’argument à l’index 2 à la variable file_path dans la fonction main, nous passons le vecteur entier à la fonction parse_config. La fonction parse_config contient alors la logique qui détermine quel argument va dans quelle variable et renvoie les valeurs à main. Nous créons toujours les variables query et file_path dans main, mais main n’a plus la responsabilité de déterminer comment les arguments de ligne de commande et les variables correspondent.
Cette refonte peut sembler excessive pour notre petit programme, mais nous refactorisons par petites étapes incrémentales. Après avoir effectué ce changement, exécutez à nouveau le programme pour vérifier que l’analyse des arguments fonctionne toujours. Il est bon de vérifier vos progrès fréquemment, pour aider à identifier la cause des problèmes lorsqu’ils surviennent.
Regrouper les valeurs de configuration
Nous pouvons faire un autre petit pas pour améliorer davantage la fonction parse_config. Pour le moment, nous renvoyons un tuple, mais ensuite nous décomposons immédiatement ce tuple en parties individuelles. C’est un signé que nous n’avons peut-être pas encore la bonne abstraction.
Un autre indicateur qui montre qu’il y à une marge d’amélioration est la partie config de parse_config, qui implique que les deux valeurs que nous renvoyons sont liées et font toutes deux partie d’une seule valeur de configuration. Nous ne transmettons pas actuellement cette signification dans la structure des données autrement qu’en regroupant les deux valeurs dans un tuple ; nous allons plutôt placer les deux valeurs dans une structure et donner à chaque champ de la structure un nom significatif. Cela permettra aux futurs mainteneurs de ce code de comprendre plus facilement comment les différentes valeurs sont liées entre elles et quel est leur rôle.
L’encart 12-6 montre les améliorations apportées à la fonction parse_config.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = parse_config(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
// --snip--
println!("With text:
{contents}");
}
struct Config {
query: String,
file_path: String,
}
fn parse_config(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}parse_config to return an instance of a Config structNous avons ajouté une structure nommée Config définie avec des champs nommés query et file_path. La signature de parse_config indique maintenant qu’elle renvoie une valeur Config. Dans le corps de parse_config, là où nous renvoyions auparavant des tranches de chaînes qui référençaient des valeurs String dans args, nous définissons maintenant Config pour contenir des valeurs String possédées. La variable args dans main est la propriétaire des valeurs d’arguments et ne fait que les prêter à la fonction parse_config, ce qui signifie que nous violerions les règles d’emprunt de Rust si Config essayait de prendre possession des valeurs dans args.
Il existe plusieurs façons de gérer les données String ; la plus simple, bien que quelque peu inefficace, est d’appeler la méthode clone sur les valeurs. Cela créera une copie complète des données que l’instance de Config pourra posséder, ce qui prend plus de temps et de mémoire que de stocker une référence aux données de la chaîne. Cependant, cloner les données rend aussi notre code très simple car nous n’avons pas à gérer les durées de vie des références ; dans ce contexte, sacrifier un peu de performance pour gagner en simplicité est un compromis qui en vaut la peine.
Les compromis de l’utilisation de clone
Il y à une tendance parmi les Rustacés à éviter d’utiliser clone pour résoudre les problèmes de possession en raison de son coût à l’exécution. Au chapitre 13, vous apprendrez à utiliser des méthodes plus efficaces dans ce type de situation. Mais pour l’instant, il convient de copier quelques chaînes de caractères pour continuer à faire des progrès, car vous ne ferez ces copies qu’une seule fois et que votre chemin de fichier et votre chaîne de requête sont très petits. Il vaut mieux avoir un programme qui fonctionne mais qui est un peu inefficace que d’essayer d’hyper-optimiser le code lors de votre première tentative. Avec plus d’expérience avec Rust, il sera plus facile de partir de la solution la plus efficace, mais pour l’instant, il est parfaitement acceptable d’appeler clone.
Nous avons mis à jour main de sorte qu’il place l’instance de Config renvoyée par parse_config dans une variable nommée config, et nous avons mis à jour le code qui utilisait auparavant les variables séparées query et file_path pour qu’il utilise désormais les champs de la structure Config.
Maintenant, notre code exprime plus clairement que query et file_path sont liés et que leur objectif est de configurer le fonctionnement du programme. Tout code qui utilise ces valeurs sait qu’il les trouvera dans l’instance config, dans les champs nommés selon leur fonction.
Créer un constructeur pour Config
Jusqu’ici, nous avons extrait la logique responsable de l’analyse des arguments de ligne de commande de main et l’avons placée dans la fonction parse_config. Cela nous a aidés à voir que les valeurs query et file_path étaient liées, et que cette relation devait être exprimée dans notre code. Nous avons ensuite ajouté une structure Config pour nommer la relation entre query et file_path et pouvoir renvoyer les noms des valeurs comme noms de champs de la structure depuis la fonction parse_config.
Maintenant que l’objectif de la fonction parse_config est de créer une instance de Config, nous pouvons transformer parse_config d’une simple fonction en une fonction nommée new associée à la structure Config. Ce changement rendra le code plus idiomatique. Nous pouvons créer des instances de types de la bibliothèque standard, comme String, en appelant String::new. De même, en transformant parse_config en une fonction new associée à Config, nous pourrons créer des instances de Config en appelant Config::new. L’encart 12-7 montre les changements que nous devons apporter.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:
{contents}");
// --snip--
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn new(args: &[String]) -> Config {
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}parse_config into Config::newNous avons mis à jour main là où nous appelions parse_config pour appeler à la place Config::new. Nous avons changé le nom de parse_config en new et l’avons déplacée dans un bloc impl, ce qui associe la fonction new à Config. Essayez de compiler ce code à nouveau pour vous assurer qu’il fonctionne.
Corriger la gestion des erreurs
Nous allons maintenant travailler à la correction de notre gestion des erreurs. Rappelez-vous que tenter d’accéder aux valeurs du vecteur args à l’index 1 ou à l’index 2 provoquera un panic du programme si le vecteur contient moins de trois éléments. Essayez d’exécuter le programme sans aucun argument ; voici ce que cela donnera : console {{#include ../listings/ch12-an-io-project/listing-12-07/output.txt}}
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:27:21:
index out of bounds: the len is 1 but the index is 1
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
La ligne index out of bounds: the len is 1 but the index is 1 est un message d’erreur destiné aux programmeurs. Il n’aidera pas nos utilisateurs finaux à comprendre ce qu’ils devraient faire à la place. Corrigeons cela maintenant.
Améliorer le message d’erreur
Dans l’encart 12-8, nous ajoutons une vérification dans la fonction new qui vérifiera que la tranche est suffisamment longue avant d’accéder aux index 1 et 2. Si la tranche n’est pas assez longue, le programme panique et affiche un meilleur message d’erreur.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:
{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
// --snip--
fn new(args: &[String]) -> Config {
if args.len() < 3 {
panic!("not enough arguments");
}
// --snip--
let query = args[1].clone();
let file_path = args[2].clone();
Config { query, file_path }
}
}Ce code est similaire à la fonction Guess::new que nous avons écrite dans l’encart 9-13, où nous appelions panic! lorsque l’argument value était en dehors de la plage de valeurs valides. Au lieu de vérifier une plage de valeurs ici, nous vérifions que la longueur de args est d’au moins 3 et le reste de la fonction peut fonctionner en supposant que cette condition est remplie. Si args contient moins de trois éléments, cette condition sera true, et nous appelons la macro panic! pour mettre fin au programme immédiatement.
Avec ces quelques lignes de code supplémentaires dans new, exécutons à nouveau le programme sans aucun argument pour voir à quoi ressemble l’erreur maintenant : console {{#include ../listings/ch12-an-io-project/listing-12-08/output.txt}}
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep`
thread 'main' panicked at src/main.rs:26:13:
not enough arguments
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
Cette sortie est meilleure : nous avons maintenant un message d’erreur raisonnable. Cependant, nous avons aussi des informations superflues que nous ne voulons pas donner à nos utilisateurs. La technique que nous avons utilisée dans l’encart 9-13 n’est peut-être pas la meilleure à utiliser ici : un appel à panic! est plus approprié pour un problème de programmation que pour un problème d’utilisation, [comme discuté au Chapitre 9][ch9-error-guidelines]. À la place, nous utiliserons l’autre technique que vous avez apprise au Chapitre 9 — [renvoyer un Result][ch9-result] qui indique soit un succès, soit une erreur.
Renvoyer un Result au lieu d’appeler panic!
Nous pouvons à la place renvoyer une valeur Result qui contiendra une instance de Config en cas de succès et décrira le problème en cas d’erreur. Nous allons aussi changer le nom de la fonction de new à build car de nombreux programmeurs s’attendent à ce que les fonctions new n’échouent jamais. Lorsque Config::build communique avec main, nous pouvons utiliser le type Result pour signaler qu’il y a eu un problème. Ensuite, nous pouvons modifier main pour convertir un variant Err en une erreur plus pratique pour nos utilisateurs, sans le texte environnant sur thread 'main' et RUST_BACKTRACE qu’un appel à panic! provoque.
L’encart 12-9 montre les changements que nous devons apporter à la valeur de retour de la fonction que nous appelons maintenant Config::build et au corps de la fonction pour renvoyer un Result. Notez que cela ne compilera pas tant que nous n’aurons pas aussi mis à jour main, ce que nous ferons dans le prochain encart.
use std::env;
use std::fs;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::new(&args);
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:
{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Result from Config::buildNotre fonction build renvoie un Result avec une instance de Config en cas de succès et un littéral de chaîne en cas d’erreur. Nos valeurs d’erreur seront toujours des littéraux de chaîne qui ont la durée de vie 'static.
Nous avons apporté deux modifications au corps de la fonction : au lieu d’appeler panic! lorsque l’utilisateur ne passe pas assez d’arguments, nous renvoyons maintenant une valeur Err, et nous avons enveloppé la valeur de retour Config dans un Ok. Ces changements font que la fonction se conforme à sa nouvelle signature de type.
Renvoyer une valeur Err depuis Config::build permet à la fonction main de gérer la valeur Result renvoyée par la fonction build et de quitter le processus plus proprement en cas d’erreur.
Appeler Config::build et gérer les erreurs
Pour gérer le cas d’erreur et afficher un message convivial, nous devons mettre à jour main pour gérer le Result renvoyé par Config::build, comme illustré dans l’encart 12-10. Nous prendrons également la responsabilité de quitter l’outil en ligne de commande avec un code d’erreur non nul, en l’implémentant nous-mêmes au lieu de laisser panic! s’en charger. Un code de sortie non nul est une convention pour signaler au processus qui a appelé notre programme que celui-ci s’est terminé dans un état d’erreur.
use std::env;
use std::fs;
use std::process;
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:
{contents}");
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Config failsDans cet encart, nous avons utilisé une méthode que nous n’avons pas encore couverte en détail : unwrap_or_else, qui est définie sur Result<T, E> par la bibliothèque standard. Utiliser unwrap_or_else nous permet de définir une gestion d’erreur personnalisée, sans panic!. Si le Result est une valeur Ok, le comportement de cette méthode est similaire à unwrap : elle renvoie la valeur interne que Ok enveloppe. Cependant, si la valeur est un Err, cette méthode appelle le code dans la fermeture, qui est une fonction anonyme que nous définissons et passons en argument à unwrap_or_else. Nous couvrirons les fermetures plus en détail dans le [Chapitre 13][ch13]. Pour l’instant, vous devez simplement savoir que unwrap_or_else passera la valeur interne de l’Err, qui dans ce cas est la chaîne statique "not enough arguments" que nous avons ajoutée dans l’encart 12-9, à notre fermeture dans l’argument err qui apparaît entre les barres verticales. Le code dans la fermeture peut alors utiliser la valeur err lorsqu’il s’exécute.
Nous avons ajouté une nouvelle ligne use pour importer process de la bibliothèque standard dans la portée. Le code dans la fermeture qui sera exécuté en cas d’erreur ne fait que deux lignes : nous affichons la valeur err puis appelons process::exit. La fonction process::exit arrêtera le programme immédiatement et renverra le nombre passé comme code de sortie. C’est similaire à la gestion basée sur panic! que nous avons utilisée dans l’encart 12-8, mais nous n’obtenons plus toute la sortie supplémentaire. Essayons : console {{#include ../listings/ch12-an-io-project/listing-12-10/output.txt}}
$ cargo run
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/minigrep`
Problem parsing arguments: not enough arguments
Parfait ! Cette sortie est beaucoup plus conviviale pour nos utilisateurs.
Extraire la logique de main
Maintenant que nous avons fini de refactoriser l’analyse de la configuration, tournons-nous vers la logique du programme. Comme nous l’avons indiqué dans « Séparer les responsabilités dans les projets binaires », nous allons extraire une fonction nommée run qui contiendra toute la logique actuellement dans la fonction main qui n’est pas impliquée dans la mise en place de la configuration ou la gestion des erreurs. Une fois terminé, la fonction main sera concise et facile à vérifier par inspection, et nous pourrons écrire des tests pour toute la logique restante.
L’encart 12-11 montre la petite amélioration incrémentale consistant à extraire une fonction run.
use std::env;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) {
let contents = fs::read_to_string(config.file_path)
.expect("Should have been able to read the file");
println!("With text:
{contents}");
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}run function containing the rest of the program logicLa fonction run contient maintenant toute la logique restante de main, à partir de la lecture du fichier. La fonction run prend l’instance de Config comme argument.
Renvoyer les erreurs depuis run
Avec la logique restante du programme séparée dans la fonction run, nous pouvons améliorer la gestion des erreurs, comme nous l’avons fait avec Config::build dans l’encart 12-9. Au lieu de permettre au programme de paniquer en appelant expect, la fonction run renverra un Result<T, E> quand quelque chose se passe mal. Cela nous permettra de consolider davantage la logique de gestion des erreurs dans main de manière conviviale. L’encart 12-12 montre les changements que nous devons apporter à la signature et au corps de run.
use std::env;
use std::fs;
use std::process;
use std::error::Error;
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
run(config);
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:
{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}run function to return ResultNous avons apporté trois changements significatifs ici. Premièrement, nous avons changé le type de retour de la fonction run en Result<(), Box<dyn Error>>. Cette fonction renvoyait auparavant le type unité, (), et nous gardons cela comme valeur renvoyée dans le cas Ok.
Pour le type d’erreur, nous avons utilisé l’objet trait Box<dyn Error> (et nous avons importé std::error::Error dans la portée avec une instruction use en haut). Nous couvrirons les objets trait dans le [Chapitre 18][ch18]. Pour l’instant, sachez simplement que Box<dyn Error> signifie que la fonction renverra un type qui implémente le trait Error, mais nous n’avons pas à spécifier quel type particulier sera la valeur de retour. Cela nous donne la flexibilité de renvoyer des valeurs d’erreur qui peuvent être de types différents dans différents cas d’erreur. Le mot-clé dyn est l’abréviation de dynamic (dynamique).
Deuxièmement, nous avons supprimé l’appel à expect en faveur de l’opérateur ?, comme nous en avons parlé dans le [Chapitre 9][ch9-question-mark]. Au lieu de faire un panic! sur une erreur, ? renverra la valeur d’erreur depuis la fonction courante pour que l’appelant la gère.
Troisièmement, la fonction run renvoie maintenant une valeur Ok en cas de succès. Nous avons déclaré le type de succès de la fonction run comme () dans la signature, ce qui signifie que nous devons envelopper la valeur de type unité dans la valeur Ok. Cette syntaxe Ok(()) peut sembler un peu étrange au premier abord. Mais utiliser () de cette façon est la manière idiomatique d’indiquer que nous appelons run uniquement pour ses effets de bord ; elle ne renvoie pas de valeur dont nous avons besoin.
Lorsque vous exécuterez ce code, il compilera mais affichera un avertissement : console {{#include ../listings/ch12-an-io-project/listing-12-12/output.txt}}
$ cargo run -- the poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
warning: unused `Result` that must be used
--> src/main.rs:19:5
|
19 | run(config);
| ^^^^^^^^^^^
|
= note: this `Result` may be an `Err` variant, which should be handled
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
19 | let _ = run(config);
| +++++++
warning: `minigrep` (bin "minigrep") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.71s
Running `target/debug/minigrep the poem.txt`
Searching for the
In file poem.txt
With text:
I'm nobody! Who are you?
Are you nobody, too?
Then there's a pair of us - don't tell!
They'd banish us, you know.
How dreary to be somebody!
How public, like a frog
To tell your name the livelong day
To an admiring bog!
Rust nous dit que notre code a ignoré la valeur Result et que la valeur Result pourrait indiquer qu’une erreur s’est produite. Mais nous ne vérifions pas s’il y a eu une erreur, et le compilateur nous rappelle que nous avions probablement l’intention d’avoir du code de gestion d’erreurs ici ! Rectifions ce problème maintenant.
Gérer les erreurs renvoyées par run dans main
Nous vérifierons les erreurs et les gérerons en utilisant une technique similaire à celle que nous avons utilisée avec Config::build dans l’encart 12-10, mais avec une légère différence :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
use std::env;
use std::error::Error;
use std::fs;
use std::process;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
println!("Searching for {}", config.query);
println!("In file {}", config.file_path);
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
println!("With text:
{contents}");
Ok(())
}
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}Nous utilisons if let plutôt que unwrap_or_else pour vérifier si run renvoie une valeur Err et appeler process::exit(1) si c’est le cas. La fonction run ne renvoie pas de valeur que nous voulons « déballer » (unwrap) de la même manière que Config::build renvoie l’instance de Config. Comme run renvoie () en cas de succès, nous ne nous soucions que de détecter une erreur, nous n’avons donc pas besoin de unwrap_or_else pour renvoyer la valeur déballée, qui ne serait que ().
Les corps de if let et des fonctions unwrap_or_else sont les mêmes dans les deux cas : nous affichons l’erreur et quittons.
Séparer le code dans un crate de bibliothèque
Notre projet minigrep a bonne allure jusqu’ici ! Maintenant, nous allons diviser le fichier src/main.rs et mettre du code dans le fichier src/lib.rs. De cette façon, nous pourrons tester le code et avoir un fichier src/main.rs avec moins de responsabilités.
Définissons le code responsable de la recherche de texte dans src/lib.rs plutôt que dans src/main.rs, ce qui nous permettra (ou permettra à quiconque utilise notre bibliothèque minigrep) d’appeler la fonction de recherche depuis plus de contextes que notre binaire minigrep.
Tout d’abord, définissons la signature de la fonction search dans src/lib.rs comme illustré dans l’encart 12-13, avec un corps qui appelle la macro unimplemented!. Nous expliquerons la signature plus en détail lorsque nous remplirons l’implémentation.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
unimplemented!();
}search function in src/lib.rsNous avons utilisé le mot-clé pub sur la définition de la fonction pour désigner search comme faisant partie de l’API publique de notre crate de bibliothèque. Nous avons maintenant un crate de bibliothèque que nous pouvons utiliser depuis notre crate binaire et que nous pouvons tester !
Nous devons maintenant importer le code défini dans src/lib.rs dans la portée du crate binaire dans src/main.rs et l’appeler, comme illustré dans l’encart 12-14.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
// --snip--
use minigrep::search;
fn main() {
// --snip--
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
// --snip--
struct Config {
query: String,
file_path: String,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
for line in search(&config.query, &contents) {
println!("{line}");
}
Ok(())
}minigrep library crate’s search function in src/main.rsNous ajoutons une ligne use minigrep::search pour importer la fonction search du crate de bibliothèque dans la portée du crate binaire. Ensuite, dans la fonction run, au lieu d’afficher le contenu du fichier, nous appelons la fonction search et passons la valeur config.query et contents comme arguments. Ensuite, run utilisera une boucle for pour afficher chaque ligne renvoyée par search qui correspondait à la requête. C’est aussi le bon moment pour supprimer les appels à println! dans la fonction main qui affichaient la requête et le chemin du fichier, afin que notre programme n’affiche que les résultats de la recherche (si aucune erreur ne survient).
Notez que la fonction de recherche collectera tous les résultats dans un vecteur qu’elle renvoie avant que l’affichage n’ait lieu. Cette implémentation pourrait être lente à afficher les résultats lors de la recherche dans de gros fichiers, car les résultats ne sont pas affichés au fur et à mesure qu’ils sont trouvés ; nous discuterons d’une façon possible de corriger cela en utilisant les itérateurs au Chapitre 13.
Ouf ! C’était beaucoup de travail, mais nous nous sommes préparés pour le succès futur. Maintenant, il est beaucoup plus facile de gérer les erreurs, et nous avons rendu le code plus modulaire. Presque tout notre travail se fera dans src/lib.rs à partir de maintenant.
Profitons de cette nouvelle modularité en faisant quelque chose qui aurait été difficile avec l’ancien code mais qui est facile avec le nouveau : nous allons écrire des tests !
Ajouter des fonctionnalités avec le développement piloté par les tests
Ajouter des fonctionnalités avec le développement piloté par les tests
Maintenant que la logique de recherche se trouve dans src/lib.rs, séparée de la fonction main, il est beaucoup plus facile d’écrire des tests pour les fonctionnalités principales de notre code. Nous pouvons appeler les fonctions directement avec divers arguments et vérifier les valeurs de retour sans avoir à appeler notre binaire depuis la ligne de commande.
Dans cette section, nous allons ajouter la logique de recherche au programme minigrep en utilisant le processus de développement piloté par les tests (TDD) avec les étapes suivantes : 1. Écrire un test qui échoue et l’exécuter pour s’assurer qu’il échoue pour la raison attendue. 2. Écrire ou modifier juste assez de code pour faire passer le nouveau test. 3. Refactoriser le code que vous venez d’ajouter ou de modifier et vous assurer que les tests continuent de passer. 4. Recommencer à l’étape 1 !
- Écrire un test qui échoue et l’exécuter pour s’assurer qu’il échoue pour la raison attendue.
- Écrire ou modifier juste assez de code pour faire passer le nouveau test.
- Refactoriser le code que vous venez d’ajouter ou de modifier et vous assurer que les tests continuent de passer.
- Recommencer à l’étape 1 !
Bien que ce ne soit qu’une des nombreuses façons d’écrire du logiciel, le TDD peut aider à orienter la conception du code. Écrire le test avant d’écrire le code qui fait passer le test aide à maintenir une couverture de test élevée tout au long du processus.
Nous allons piloter par les tests l’implémentation de la fonctionnalité qui effectuera réellement la recherche de la chaîne de requête dans le contenu du fichier et produira une liste de lignes correspondant à la requête. Nous ajouterons cette fonctionnalité dans une fonction appelée search.
Écrire un test qui échoue
Dans src/lib.rs, nous ajouterons un module tests avec une fonction de test, comme nous l’avons fait dans le chapitre 11. La fonction de test spécifie le comportement que nous voulons que la fonction search ait : elle prendra une requête et le texte à rechercher, et ne renverra que les lignes du texte qui contiennent la requête. L’encart 12-15 montre ce test.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
unimplemented!();
}
// --snip--
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\nRust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}search function for the functionality we wish we hadCe test recherche la chaîne "duct". Le texte dans lequel nous cherchons fait trois lignes, dont une seule contient "duct" (notez que la barre oblique inverse après le guillemet double ouvrant indique à Rust de ne pas mettre de caractère de nouvelle ligne au début du contenu de ce littéral de chaîne). Nous vérifions que la valeur renvoyée par la fonction search contient uniquement la ligne attendue.
Si nous exécutons ce test, il échouera actuellement car la macro unimplemented! panique avec le message “not implemented”. Conformément aux principes du TDD, nous ferons un petit pas en ajoutant juste assez de code pour que le test ne panique pas lors de l’appel de la fonction, en définissant la fonction search pour qu’elle renvoie toujours un vecteur vide, comme illustré dans l’encart 12-16. Ensuite, le test devrait compiler et échouer car un vecteur vide ne correspond pas à un vecteur contenant la ligne "safe, fast, productive.".
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
vec![]
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\n# Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}search function so that calling it won’t panicVoyons maintenant pourquoi nous devons définir une durée de vie explicite 'a dans la signature de search et utiliser cette durée de vie avec l’argument contents et la valeur de retour. Rappelez-vous que dans le [Chapitre 10][ch10-lifetimes], les paramètres de durée de vie spécifient quelle durée de vie d’argument est connectée à la durée de vie de la valeur de retour. Dans ce cas, nous indiquons que le vecteur renvoyé doit contenir des tranches de chaîne qui référencent des tranches de l’argument contents (plutôt que de l’argument query).
Autrement dit, nous indiquons à Rust que les données renvoyées par la fonction search vivront aussi longtemps que les données passées à la fonction search dans l’argument contents. C’est important ! Les données référencées par une tranche doivent être valides pour que la référence soit valide ; si le compilateur suppose que nous créons des tranches de chaîne de query plutôt que de contents, il effectuera ses vérifications de sécurité de manière incorrecte.
Si nous oublions les annotations de durée de vie et essayons de compiler cette fonction, nous obtiendrons cette erreur : console {{#include ../listings/ch12-an-io-project/output-only-02-missing-lifetimes/output.txt}}
$ cargo build
Compiling minigrep v0.1.0 (file:///projects/minigrep)
error[E0106]: missing lifetime specifier
--> src/lib.rs:1:51
|
1 | pub fn search(query: &str, contents: &str) -> Vec<&str> {
| ---- ---- ^ expected named lifetime parameter
|
= help: this function's return type contains a borrowed value, but the signature does not say whether it is borrowed from `query` or `contents`
help: consider introducing a named lifetime parameter
|
1 | pub fn search<'a>(query: &'a str, contents: &'a str) -> Vec<&'a str> {
| ++++ ++ ++ ++
For more information about this error, try `rustc --explain E0106`.
error: could not compile `minigrep` (lib) due to 1 previous error
Rust ne peut pas savoir lequel des deux paramètres nous avons besoin pour la sortie, nous devons donc le lui indiquer explicitement. Notez que le texte d’aide suggère de spécifier le même paramètre de durée de vie pour tous les paramètres et le type de sortie, ce qui est incorrect ! Comme contents est le paramètre qui contient tout notre texte et que nous voulons renvoyer les parties de ce texte qui correspondent, nous savons que contents est le seul paramètre qui doit être connecté à la valeur de retour en utilisant la syntaxe de durée de vie.
D’autres langages de programmation ne vous obligent pas à connecter les arguments aux valeurs de retour dans la signature, mais cette pratique deviendra plus facile avec le temps. Vous voudrez peut-être comparer cet exemple avec les exemples de la section [« Valider les références avec les durées de vie »][validating-references-with-lifetimes] du Chapitre 10.
Écrire du code pour faire passer le test
Actuellement, notre test échoue car nous renvoyons toujours un vecteur vide. Pour corriger cela et implémenter search, notre programme doit suivre ces étapes : 1. Itérer sur chaque ligne du contenu. 2. Vérifier si la ligne contient notre chaîne de requête. 3. Si c’est le cas, l’ajouter à la liste des valeurs que nous renvoyons. 4. Si ce n’est pas le cas, ne rien faire. 5. Renvoyer la liste des résultats correspondants.
- Itérer sur chaque ligne du contenu.
- Vérifier si la ligne contient notre chaîne de requête.
- Si c’est le cas, l’ajouter à la liste des valeurs que nous renvoyons.
- Si ce n’est pas le cas, ne rien faire.
- Renvoyer la liste des résultats correspondants.
Travaillons sur chaque étape, en commençant par l’itération sur les lignes.
Itérer sur les lignes avec la méthode lines
Rust dispose d’une méthode utile pour gérer l’itération ligne par ligne des chaînes de caractères, judicieusement nommée lines, qui fonctionne comme illustré dans l’encart 12-17. Notez que cela ne compilera pas encore.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
// do something with line
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\n# Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}contentsLa méthode lines renvoie un itérateur. Nous parlerons des itérateurs en profondeur dans le chapitre 13. Mais rappelez-vous que vous avez vu cette façon d’utiliser un itérateur dans l’encart 3-5, où nous avons utilisé une boucle for avec un itérateur pour exécuter du code sur chaque élément d’une collection.
Rechercher la requête dans chaque ligne
Ensuite, nous vérifierons si la ligne courante contient notre chaîne de requête. Heureusement, les chaînes de caractères ont une méthode utile nommée contains qui fait cela pour nous ! Ajoutez un appel à la méthode contains dans la fonction search, comme illustré dans l’encart 12-18. Notez que cela ne compilera toujours pas encore.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
for line in contents.lines() {
if line.contains(query) {
// do something with line
}
}
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\n# Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}queryPour le moment, nous construisons la fonctionnalité progressivement. Pour que le code compilé, nous devons renvoyer une valeur depuis le corps de la fonction comme nous l’avons indiqué dans la signature de la fonction.
Stocker les lignes correspondantes
Pour terminer cette fonction, nous avons besoin d’un moyen de stocker les lignes correspondantes que nous voulons renvoyer. Pour cela, nous pouvons créer un vecteur mutable avant la boucle for et appeler la méthode push pour stocker une line dans le vecteur. Après la boucle for, nous renvoyons le vecteur, comme illustré dans l’encart 12-19.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\n# Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}Maintenant, la fonction search ne devrait renvoyer que les lignes qui contiennent query, et notre test devrait passer. Exécutons le test : console {{#include ../listings/ch12-an-io-project/listing-12-19/output.txt}}
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.22s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 1 test
test tests::one_result ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Notre test est passé, donc nous savons que ça fonctionne !
À ce stade, nous pourrions envisager des opportunités de refactorisation de l’implémentation de la fonction de recherche tout en gardant les tests passants pour maintenir la même fonctionnalité. Le code de la fonction de recherche n’est pas trop mal, mais il ne tire pas parti de certaines fonctionnalités utiles des itérateurs. Nous reviendrons à cet exemple dans le [Chapitre 13][ch13-iterators], où nous explorerons les itérateurs en détail, et verrons comment l’améliorer.
Maintenant, le programme entier devrait fonctionner ! Essayons-le, d’abord avec un mot qui devrait renvoyer exactement une ligne du poème d’Emily Dickinson : frog. console {{#include ../listings/ch12-an-io-project/no-listing-02-using-search-in-run/output.txt}}
$ cargo run -- frog poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.38s
Running `target/debug/minigrep frog poem.txt`
How public, like a frog
Super ! Essayons maintenant un mot qui correspondra à plusieurs lignes, comme body : console {{#include ../listings/ch12-an-io-project/output-only-03-multiple-matches/output.txt}}
$ cargo run -- body poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep body poem.txt`
I'm nobody! Who are you?
Are you nobody, too?
How dreary to be somebody!
Et enfin, assurons-nous que nous n’obtenons aucune ligne lorsque nous recherchons un mot qui n’apparaît nulle part dans le poème, comme monomorphization : console {{#include ../listings/ch12-an-io-project/output-only-04-no-matches/output.txt}}
$ cargo run -- monomorphization poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep monomorphization poem.txt`
Excellent ! Nous avons construit notre propre mini version d’un outil classique et avons beaucoup appris sur la structuration des applications. Nous avons aussi appris un peu sur les entrées/sorties de fichiers, les durées de vie, les tests et l’analyse de la ligne de commande.
Pour compléter ce projet, nous montrerons brièvement comment travailler avec les variables d’environnement et comment écrire sur la sortie d’erreur standard, deux choses utiles lorsque vous écrivez des programmes en ligne de commande.
Travailler avec les variables d’environnement
Travailler avec les variables d’environnement
Nous allons améliorer le binaire minigrep en ajoutant une fonctionnalité supplémentaire : une option de recherche insensible à la casse que l’utilisateur peut activer via une variable d’environnement. Nous pourrions faire de cette fonctionnalité une option de ligne de commande et exiger que les utilisateurs la saisissent à chaque fois qu’ils veulent l’appliquer, mais en en faisant plutôt une variable d’environnement, nous permettons à nos utilisateurs de définir la variable d’environnement une seule fois et d’avoir toutes leurs recherches insensibles à la casse dans cette session de terminal.
Écrire un test qui échoue pour la recherche insensible à la casse
Nous ajoutons d’abord une nouvelle fonction search_case_insensitive à la bibliothèque minigrep qui sera appelée lorsque la variable d’environnement à une valeur. Nous continuerons à suivre le processus TDD, donc la première étape est à nouveau d’écrire un test qui échoue. Nous ajouterons un nouveau test pour la nouvelle fonction search_case_insensitive et renommerons notre ancien test de one_result en case_sensitive pour clarifier les différences entre les deux tests, comme illustré dans l’encart 12-20.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\nRust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\nRust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}Notez que nous avons aussi modifié le contents de l’ancien test. Nous avons ajouté une nouvelle ligne avec le texte "Duct tape." utilisant un D majuscule qui ne devrait pas correspondre à la requête "duct" lorsque nous cherchons de manière sensible à la casse. Modifier l’ancien test de cette façon permet de s’assurer que nous ne cassons pas accidentellement la fonctionnalité de recherche sensible à la casse que nous avons déjà implémentée. Ce test devrait passer maintenant et continuer à passer pendant que nous travaillons sur la recherche insensible à la casse.
Le nouveau test pour la recherche insensible à la casse utilise "rUsT" comme requête. Dans la fonction search_case_insensitive que nous sommes sur le point d’ajouter, la requête "rUsT" devrait correspondre à la ligne contenant "Rust:" avec un R majuscule et correspondre à la ligne "Trust me." même si les deux ont une casse différente de la requête. C’est notre test qui échoue, et il ne compilera pas car nous n’avons pas encore défini la fonction search_case_insensitive. N’hésitez pas à ajouter une implémentation squelette qui renvoie toujours un vecteur vide, de la même manière que nous l’avons fait pour la fonction search dans l’encart 12-16, pour voir le test compiler et échouer.
Implémenter la fonction search_case_insensitive
La fonction search_case_insensitive, illustrée dans l’encart 12-21, sera presque identique à la fonction search. La seule différence est que nous mettrons en minuscules la query et chaque line de sorte que, quelle que soit la casse des arguments d’entrée, ils seront dans la même casse lorsque nous vérifierons si la ligne contient la requête.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\n# Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\n# Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}search_case_insensitive function to lowercase the query and the line before comparing themTout d’abord, nous mettons en minuscules la chaîne query et la stockons dans une nouvelle variable du même nom, masquant la query originale. Appeler to_lowercase sur la requête est nécessaire pour que, quelle que soit la requête de l’utilisateur — "rust", "RUST", "Rust" ou "rUsT" — nous traitions la requête comme si elle était "rust" et soyons insensibles à la casse. Bien que to_lowercase gère l’Unicode de base, ce ne sera pas précis à 100 %. Si nous écrivions une vraie application, nous voudrions faire un peu plus de travail ici, mais cette section porte sur les variables d’environnement, pas sur l’Unicode, donc nous en resterons là.
Notez que query est maintenant un String plutôt qu’une tranche de chaîne, car l’appel à to_lowercase crée de nouvelles données plutôt que de référencer des données existantes. Prenons l’exemple de la requête "rUsT" : cette tranche de chaîne ne contient pas de u ou de t minuscule que nous pourrions utiliser, nous devons donc allouer un nouveau String contenant "rust". Lorsque nous passons query comme argument à la méthode contains maintenant, nous devons ajouter une esperluette car la signature de contains est définie pour prendre une tranche de chaîne.
Ensuite, nous ajoutons un appel à to_lowercase sur chaque line pour mettre tous les caractères en minuscules. Maintenant que nous avons converti line et query en minuscules, nous trouverons des correspondances quelle que soit la casse de la requête.
Voyons si cette implémentation passe les tests : console {{#include ../listings/ch12-an-io-project/listing-12-21/output.txt}}
$ cargo test
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `test` profile [unoptimized + debuginfo] target(s) in 1.33s
Running unittests src/lib.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 2 tests
test tests::case_insensitive ... ok
test tests::case_sensitive ... ok
test result: ok. 2 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/minigrep-9cd200e5fac0fc94)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests minigrep
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Parfait ! Ils sont passés. Maintenant, appelons la nouvelle fonction search_case_insensitive depuis la fonction run. Tout d’abord, nous ajouterons une option de configuration à la structure Config pour basculer entre la recherche sensible et insensible à la casse. L’ajout de ce champ provoquera des erreurs de compilation car nous n’initialisons ce champ nulle part pour le moment :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Nous avons ajouté le champ ignore_case qui contient un booléen. Ensuite, nous avons besoin que la fonction run vérifie la valeur du champ ignore_case et l’utilise pour décider s’il faut appeler la fonction search ou la fonction search_case_insensitive, comme illustré dans l’encart 12-22. Cela ne compilera toujours pas encore.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
// --snip--
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
Ok(Config { query, file_path })
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}search or search_case_insensitive based on the value in config.ignore_caseEnfin, nous devons vérifier la variable d’environnement. Les fonctions pour travailler avec les variables d’environnement sont dans le module env de la bibliothèque standard, qui est déjà dans la portée en haut de src/main.rs. Nous utiliserons la fonction var du module env pour vérifier si une valeur a été définie pour une variable d’environnement nommée IGNORE_CASE, comme illustré dans l’encart 12-23.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}IGNORE_CASEIci, nous créons une nouvelle variable, ignore_case. Pour définir sa valeur, nous appelons la fonction env::var et lui passons le nom de la variable d’environnement IGNORE_CASE. La fonction env::var renvoie un Result qui sera le variant Ok de succès contenant la valeur de la variable d’environnement si celle-ci est définie à une quelconque valeur. Elle renverra le variant Err si la variable d’environnement n’est pas définie.
Nous utilisons la méthode is_ok sur le Result pour vérifier si la variable d’environnement est définie, ce qui signifie que le programme devrait effectuer une recherche insensible à la casse. Si la variable d’environnement IGNORE_CASE n’est définie à rien, is_ok renverra false et le programme effectuera une recherche sensible à la casse. Nous ne nous soucions pas de la valeur de la variable d’environnement, juste de savoir si elle est définie ou non, donc nous vérifions is_ok plutôt que d’utiliser unwrap, expect ou l’une des autres méthodes que nous avons vues sur Result.
Nous passons la valeur de la variable ignore_case à l’instance de Config afin que la fonction run puisse lire cette valeur et décider s’il faut appeler search_case_insensitive ou search, comme nous l’avons implémenté dans l’encart 12-22.
Essayons ! D’abord, nous exécuterons notre programme sans la variable d’environnement définie et avec la requête to, qui devrait correspondre à toute ligne contenant le mot to entièrement en minuscules : console {{#include ../listings/ch12-an-io-project/listing-12-23/output.txt}}
$ cargo run -- to poem.txt
Compiling minigrep v0.1.0 (file:///projects/minigrep)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.0s
Running `target/debug/minigrep to poem.txt`
Are you nobody, too?
How dreary to be somebody!
Il semblerait que ça fonctionne toujours ! Maintenant, exécutons le programme avec IGNORE_CASE défini à 1 mais avec la même requête to :
$ IGNORE_CASE=1 cargo run -- to poem.txt
Si vous utilisez PowerShell, vous devrez définir la variable d’environnement et exécuter le programme comme des commandes séparées :
PS> $Env:IGNORE_CASE=1; cargo run -- to poem.txt
Cela fera persister IGNORE_CASE pour le reste de votre session shell. Elle peut être supprimée avec le cmdlet Remove-Item :
PS> Remove-Item Env:IGNORE_CASE
Nous devrions obtenir des lignes contenant to qui pourraient avoir des lettres majuscules :
Are you nobody, too?
How dreary to be somebody!
To tell your name the livelong day
To an admiring bog!
Excellent, nous avons aussi obtenu des lignes contenant To ! Notre programme minigrep peut maintenant effectuer une recherche insensible à la casse contrôlée par une variable d’environnement. Vous savez maintenant comment gérer des options définies en utilisant soit des arguments de ligne de commande, soit des variables d’environnement.
Certains programmes permettent des arguments et des variables d’environnement pour la même configuration. Dans ces cas, les programmes décident que l’un où l’autre à la priorité. Pour un autre exercice de votre côté, essayez de contrôler la sensibilité à la casse via un argument de ligne de commande ou une variable d’environnement. Décidez si l’argument de ligne de commande ou la variable d’environnement devrait avoir la priorité si le programme est exécuté avec l’un défini sur sensible à la casse et l’autre sur insensible à la casse.
Le module std::env contient de nombreuses autres fonctionnalités utiles pour travailler avec les variables d’environnement : consultez sa documentation pour voir ce qui est disponible.
Rediriger les erreurs vers la sortie d’erreur standard
Rediriger les erreurs vers la sortie d’erreur standard
Pour le moment, nous écrivons toutes nos sorties sur le terminal en utilisant la macro println!. Dans la plupart des terminaux, il existe deux types de sortie : la sortie standard (stdout) pour les informations générales et la sortie d’erreur standard (stderr) pour les messages d’erreur. Cette distinction permet aux utilisateurs de choisir de rediriger la sortie réussie d’un programme vers un fichier tout en affichant les messages d’erreur à l’écran.
La macro println! n’est capable d’écrire que sur la sortie standard, nous devons donc utiliser autre chose pour écrire sur la sortie d’erreur standard.
Vérifier où les erreurs sont écrites
Tout d’abord, observons comment le contenu affiché par minigrep est actuellement écrit sur la sortie standard, y compris les messages d’erreur que nous voudrions écrire sur la sortie d’erreur standard à la place. Nous ferons cela en redirigeant le flux de sortie standard vers un fichier tout en provoquant intentionnellement une erreur. Nous ne redirigerons pas le flux d’erreur standard, donc tout contenu envoyé vers la sortie d’erreur standard continuera à s’afficher à l’écran.
Les programmes en ligne de commande sont censés envoyer les messages d’erreur sur le flux d’erreur standard afin que nous puissions toujours voir les messages d’erreur à l’écran même si nous redirigeons le flux de sortie standard vers un fichier. Notre programme ne se comporte pas correctement actuellement : nous allons voir qu’il enregistré le message d’erreur dans un fichier à la place !
Pour démontrer ce comportement, nous exécuterons le programme avec > et le chemin de fichier, output.txt, vers lequel nous voulons rediriger le flux de sortie standard. Nous ne passerons aucun argument, ce qui devrait provoquer une erreur :
$ cargo run > output.txt
La syntaxe > indique au shell d’écrire le contenu de la sortie standard dans output.txt au lieu de l’écran. Nous n’avons pas vu le message d’erreur que nous attendions à l’écran, ce qui signifie qu’il a dû finir dans le fichier. Voici ce que contient output.txt :
Problem parsing arguments: not enough arguments
En effet, notre message d’erreur est affiché sur la sortie standard. Il est beaucoup plus utile que les messages d’erreur comme celui-ci soient affichés sur la sortie d’erreur standard afin que seules les données d’une exécution réussie se retrouvent dans le fichier. Nous allons changer cela.
Afficher les erreurs sur la sortie d’erreur standard
Nous utiliserons le code de l’encart 12-24 pour changer la façon dont les messages d’erreur sont affichés. Grâce au refactoring que nous avons fait plus tôt dans ce chapitre, tout le code qui affiche des messages d’erreur se trouve dans une seule fonction, main. La bibliothèque standard fournit la macro eprintln! qui écrit sur le flux d’erreur standard, donc changeons les deux endroits où nous appelions println! pour afficher les erreurs afin d’utiliser eprintln! à la place.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}eprintln!Exécutons maintenant à nouveau le programme de la même manière, sans aucun argument et en redirigeant la sortie standard avec > :
$ cargo run > output.txt
Problem parsing arguments: not enough arguments
Maintenant, nous voyons l’erreur à l’écran et output.txt ne contient rien, ce qui est le comportement attendu des programmes en ligne de commande.
Exécutons à nouveau le programme avec des arguments qui ne provoquent pas d’erreur mais en redirigeant toujours la sortie standard vers un fichier, comme ceci :
$ cargo run -- to poem.txt > output.txt
Nous ne verrons aucune sortie sur le terminal, et output.txt contiendra nos résultats :
Fichier : output.txt
Are you nobody, too?
How dreary to be somebody!
Cela démontre que nous utilisons maintenant la sortie standard pour les sorties réussies et la sortie d’erreur standard pour les sorties d’erreur, comme il se doit.
Résumé
Ce chapitre a récapitulé certains des concepts majeurs que vous avez appris jusqu’ici et a couvert la façon d’effectuer des opérations d’E/S courantes en Rust. En utilisant les arguments de ligne de commande, les fichiers, les variables d’environnement et la macro eprintln! pour afficher les erreurs, vous êtes maintenant prêt à écrire des applications en ligne de commande. Combiné avec les concepts des chapitres précédents, votre code sera bien organisé, stockera les données efficacement dans les structures de données appropriées, gérera les erreurs correctement et sera bien testé.
Ensuite, nous explorerons certaines fonctionnalités de Rust qui ont été influencées par les langages fonctionnels : les fermetures (closures) et les itérateurs.
Les fonctionnalités de langage fonctionnel : les itérateurs et les closures
La conception de Rust s’est inspiree de nombreux langages et techniques existants, et une influence notable est la programmation fonctionnelle. Programmer dans un style fonctionnel consiste souvent à utiliser des fonctions comme des valeurs en les passant en arguments, en les retournant depuis d’autres fonctions, en les assignant à des variables pour une exécution ulterieure, et ainsi de suite.
Dans ce chapitre, nous ne debattrons pas de ce qu’est ou n’est pas la programmation fonctionnelle, mais nous aborderons plutot certaines fonctionnalités de Rust qui sont similaires a celles de nombreux langages souvent qualifies de fonctionnels.
Plus précisément, nous aborderons :
- Les fermetures (closures), une construction semblable à une fonction que vous pouvez stocker dans une variable
- Les itérateurs, un moyen de traiter une série d’éléments
- Comment utiliser les fermetures et les itérateurs pour améliorer le projet d’E/S du chapitre 12
- Les performances des fermetures et des itérateurs (attention spoiler : ils sont plus rapides que vous ne le pensez !)
Nous avons déjà couvert d’autres fonctionnalités de Rust, comme le filtrage par motif et les enums, qui sont également influencees par le style fonctionnel. Parce que maitriser les fermetures et les iterateurs est une part importante de l’écriture de code Rust rapide et idiomatique, nous consacrerons ce chapitre entier à ces sujets.
Les closures
Les closures
Les fermetures en Rust sont des fonctions anonymes que vous pouvez enregistrer dans une variable ou passer en arguments a d’autres fonctions. Vous pouvez créer la fermeture à un endroit puis l’appeler ailleurs pour l’evaluer dans un contexte différent. Contrairement aux fonctions, les fermetures peuvent capturer des valeurs de la portée dans laquelle elles sont définies. Nous allons montrer comment ces caracteristiques des fermetures permettent la reutilisation du code et la personnalisation du comportement.
Capturer l’environnement
Nous allons d’abord examiner comment nous pouvons utiliser les fermetures pour capturer des valeurs de l’environnement dans lequel elles sont définies pour une utilisation ulterieure. Voici le scenario : de temps en temps, notre entreprise de T-shirts offre un T-shirt exclusif en édition limitee a quelqu’un de notre liste de diffusion comme promotion. Les personnes inscrites sur la liste de diffusion peuvent optionnellement ajouter leur couleur préférée à leur profil. Si la personne choisie pour un T-shirt gratuit a défini sa couleur préférée, elle recoit un T-shirt de cette couleur. Si la personne n’a pas spécifié de couleur préférée, elle recoit la couleur dont l’entreprise à le plus en stock.
Il existe de nombreuses façons d’implémenter cela. Pour cet exemple, nous allons utiliser un enum appelé ShirtColor qui à les variantes Red et Blue (limitant le nombre de couleurs disponibles par souci de simplicite). Nous representons l’inventaire de l’entreprise avec une struct Inventory qui à un champ nomme shirts contenant un Vec<ShirtColor> representant les couleurs de T-shirts actuellement en stock. La methode giveaway définie sur Inventory obtient la preference optionnelle de couleur de T-shirt du gagnant, et retourné la couleur de T-shirt que la personne recevra. Cette configuration est présentée dans l’encart 13-1.
#[derive(Debug, PartialEq, Copy, Clone)]
enum ShirtColor {
Red,
Blue,
}
struct Inventory {
shirts: Vec<ShirtColor>,
}
impl Inventory {
fn giveaway(&self, user_preference: Option<ShirtColor>) -> ShirtColor {
user_preference.unwrap_or_else(|| self.most_stocked())
}
fn most_stocked(&self) -> ShirtColor {
let mut num_red = 0;
let mut num_blue = 0;
for color in &self.shirts {
match color {
ShirtColor::Red => num_red += 1,
ShirtColor::Blue => num_blue += 1,
}
}
if num_red > num_blue {
ShirtColor::Red
} else {
ShirtColor::Blue
}
}
}
fn main() {
let store = Inventory {
shirts: vec![ShirtColor::Blue, ShirtColor::Red, ShirtColor::Blue],
};
let user_pref1 = Some(ShirtColor::Red);
let giveaway1 = store.giveaway(user_pref1);
println!(
"The user with preference {:?} gets {:?}",
user_pref1, giveaway1
);
let user_pref2 = None;
let giveaway2 = store.giveaway(user_pref2);
println!(
"The user with preference {:?} gets {:?}",
user_pref2, giveaway2
);
}Le store défini dans main a deux T-shirts bleus et un T-shirt rouge restants a distribuer pour cette promotion en édition limitee. Nous appelons la methode giveaway pour un utilisateur avec une preference pour un T-shirt rouge et un utilisateur sans aucune preference.
Encore une fois, ce code pourrait être implémenté de nombreuses façons, et ici, pour nous concentrer sur les fermetures, nous nous sommes limites aux concepts que vous avez déjà appris, à l’exception du corps de la methode giveaway qui utilise une fermeture. Dans la methode giveaway, nous obtenons la preference de l’utilisateur sous forme de paramètre de type Option<ShirtColor> et appelons la methode unwrap_or_else sur user_preference. La methode [unwrap_or_else sur Option<T>][unwrap-or-else] est définie par la bibliothèque standard. Elle prend un argument : une fermeture sans aucun argument qui retourné une valeur T (le même type stocké dans la variante Some de Option<T>, dans ce cas ShirtColor). Si Option<T> est la variante Some, unwrap_or_else retourné la valeur contenue dans le Some. Si Option<T> est la variante None, unwrap_or_else appelle la fermeture et retourné la valeur renvoyee par la fermeture.
Nous specifions l’expression de fermeture || self.most_stocked() comme argument de unwrap_or_else. C’est une fermeture qui ne prend aucun paramètre (si la fermeture avait des paramètres, ils apparaîtraient entre les deux barres verticales). Le corps de la fermeture appelle self.most_stocked(). Nous définissons la fermeture ici, et l’implémentation de unwrap_or_else evaluera la fermeture plus tard si le résultat est nécessaire.
L’exécution de ce code affiche le résultat suivant : console {{#include ../listings/ch13-functional-features/listing-13-01/output.txt}}
$ cargo run
Compiling shirt-company v0.1.0 (file:///projects/shirt-company)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.27s
Running `target/debug/shirt-company`
The user with preference Some(Red) gets Red
The user with preference None gets Blue
Un aspect interessant ici est que nous avons passe une fermeture qui appelle self.most_stocked() sur l’instance actuelle d’Inventory. La bibliothèque standard n’avait pas besoin de connaitre quoi que ce soit sur les types Inventory ou ShirtColor que nous avons définis, ni sur la logique que nous voulons utiliser dans ce scenario. La fermeture capture une référence immuable vers l’instance self d’Inventory et la transmet avec le code que nous specifions à la methode unwrap_or_else. Les fonctions, en revanche, ne sont pas capables de capturer leur environnement de cette maniere.
Inference et annotation des types de fermetures
Il y a d’autres differences entre les fonctions et les fermetures. Les fermetures ne nécessitent généralement pas d’annoter les types des paramètres ou de la valeur de retour comme le font les fonctions fn. Les annotations de types sont requises sur les fonctions car les types font partie d’une interface explicite exposee a vos utilisateurs. Définir cette interface de maniere rigide est important pour s’assurer que tout le monde est d’accord sur les types de valeurs qu’une fonction utilise et retourné. Les fermetures, en revanche, ne sont pas utilisees dans une interface exposee de cette façon : elles sont stockées dans des variables et utilisees sans être nommees ni exposees aux utilisateurs de notre bibliothèque.
Les fermetures sont généralement courtes et pertinentes uniquement dans un contexte restreint plutot que dans n’importe quel scenario arbitraire. Dans ces contextes limites, le compilateur peut inferer les types des paramètres et le type de retour, de la même maniere qu’il est capable d’inferer les types de la plupart des variables (il y a de rares cas où le compilateur a également besoin d’annotations de types pour les fermetures).
Comme avec les variables, nous pouvons ajouter des annotations de types si nous voulons augmenter l’explicite et la clarte au prix d’être plus verbeux que strictement nécessaire. Annoter les types pour une fermeture ressemblerait à la définition montrée dans l’encart 13-2. Dans cet exemple, nous définissons une fermeture et la stockons dans une variable plutot que de définir la fermeture à l’endroit où nous la passons en argument, comme nous l’avons fait dans l’encart 13-1.
use std::thread;
use std::time::Duration;
fn generate_workout(intensity: u32, random_number: u32) {
let expensive_closure = |num: u32| -> u32 {
println!("calculating slowly...");
thread::sleep(Duration::from_secs(2));
num
};
if intensity < 25 {
println!("Today, do {} pushups!", expensive_closure(intensity));
println!("Next, do {} situps!", expensive_closure(intensity));
} else {
if random_number == 3 {
println!("Take a break today! Remember to stay hydrated!");
} else {
println!(
"Today, run for {} minutes!",
expensive_closure(intensity)
);
}
}
}
fn main() {
let simulated_user_specified_value = 10;
let simulated_random_number = 7;
generate_workout(simulated_user_specified_value, simulated_random_number);
}Avec les annotations de types ajoutées, la syntaxe des fermetures ressemble davantage à la syntaxe des fonctions. Ici, nous définissons une fonction qui ajouté 1 à son paramètre et une fermeture qui à le même comportement, a titre de comparaison. Nous avons ajouté des espaces pour aligner les parties pertinentes. Cela illustre comment la syntaxe des fermetures est similaire à la syntaxe des fonctions, à l’exception de l’utilisation des barres verticales et de la quantite de syntaxe qui est optionnelle :
fn add_one_v1 (x: u32) -> u32 { x + 1 }
let add_one_v2 = |x: u32| -> u32 { x + 1 };
let add_one_v3 = |x| { x + 1 };
let add_one_v4 = |x| x + 1 ;La première ligne montre une définition de fonction et la deuxième ligne montre une définition de fermeture entierement annotee. A la troisième ligne, nous retirons les annotations de types de la définition de la fermeture. A la quatrieme ligne, nous retirons les accolades, qui sont optionnelles car le corps de la fermeture n’a qu’une seule expression. Ce sont toutes des définitions valides qui produiront le même comportement lorsqu’elles seront appelées. Les lignes add_one_v3 et add_one_v4 nécessitent que les fermetures soient evaluees pour pouvoir compiler car les types seront inferes à partir de leur utilisation. C’est similaire a let v = Vec::new(); qui nécessite soit des annotations de types, soit des valeurs d’un certain type a inserer dans le Vec pour que Rust puisse inferer le type.
Pour les définitions de fermetures, le compilateur inferera un type concret pour chacun de leurs paramètres et pour leur valeur de retour. Par exemple, l’encart 13-3 montre la définition d’une courte fermeture qui retourné simplement la valeur qu’elle recoit en paramètre. Cette fermeture n’est pas très utile sauf dans le cadre de cet exemple. Notez que nous n’avons ajouté aucune annotation de type à la définition. Parce qu’il n’y a pas d’annotations de types, nous pouvons appeler la fermeture avec n’importe quel type, ce que nous avons fait ici avec String la première fois. Si nous essayons ensuite d’appeler example_closure avec un entier, nous obtiendrons une erreur.
fn main() {
let example_closure = |x| x;
let s = example_closure(String::from("hello"));
let n = example_closure(5);
}Le compilateur nous donne cette erreur : console {{#include ../listings/ch13-functional-features/listing-13-03/output.txt}}
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
error[E0308]: mismatched types
--> src/main.rs:5:29
|
5 | let n = example_closure(5);
| --------------- ^ expected `String`, found integer
| |
| arguments to this function are incorrect
|
note: expected because the closure was earlier called with an argument of type `String`
--> src/main.rs:4:29
|
4 | let s = example_closure(String::from("hello"));
| --------------- ^^^^^^^^^^^^^^^^^^^^^ expected because this argument is of type `String`
| |
| in this closure call
note: closure parameter defined here
--> src/main.rs:2:28
|
2 | let example_closure = |x| x;
| ^
help: try using a conversion method
|
5 | let n = example_closure(5.to_string());
| ++++++++++++
For more information about this error, try `rustc --explain E0308`.
error: could not compile `closure-example` (bin "closure-example") due to 1 previous error
La première fois que nous appelons example_closure avec la valeur String, le compilateur infere que le type de x et le type de retour de la fermeture sont String. Ces types sont alors verrouilles dans la fermeture example_closure, et nous obtenons une erreur de type lorsque nous essayons ensuite d’utiliser un type différent avec la même fermeture.
Capturer des références ou transferer la possession
Les fermetures peuvent capturer des valeurs de leur environnement de trois façons, qui correspondent directement aux trois façons dont une fonction peut prendre un paramètre : emprunter de maniere immuable, emprunter de maniere mutable et prendre la possession. La fermeture decidera laquelle de ces methodes utiliser en fonction de ce que le corps de la fonction fait avec les valeurs capturees.
Dans l’encart 13-4, nous définissons une fermeture qui capture une référence immuable vers le vecteur nomme list car elle n’a besoin que d’une référence immuable pour afficher la valeur.
fn main() {
let list = vec![1, 2, 3];
println!("Before defining closure: {list:?}");
let only_borrows = || println!("From closure: {list:?}");
println!("Before calling closure: {list:?}");
only_borrows();
println!("After calling closure: {list:?}");
}Cet exemple illustre également qu’une variable peut être liee à une définition de fermeture, et nous pouvons ensuite appeler la fermeture en utilisant le nom de la variable et des parentheses comme si le nom de la variable était un nom de fonction.
Parce que nous pouvons avoir plusieurs références immuables vers list en même temps, list est toujours accessible depuis le code avant la définition de la fermeture, après la définition de la fermeture mais avant que la fermeture ne soit appelée, et après que la fermeture ait été appelée. Ce code compilé, s’exécute et affiche : console {{#include ../listings/ch13-functional-features/listing-13-04/output.txt}}
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
Before calling closure: [1, 2, 3]
From closure: [1, 2, 3]
After calling closure: [1, 2, 3]
Ensuite, dans l’encart 13-5, nous modifions le corps de la fermeture pour qu’il ajouté un élément au vecteur list. La fermeture capture maintenant une référence mutable.
fn main() {
let mut list = vec![1, 2, 3];
println!("Before defining closure: {list:?}");
let mut borrows_mutably = || list.push(7);
borrows_mutably();
println!("After calling closure: {list:?}");
}Ce code compilé, s’exécute et affiche : console {{#include ../listings/ch13-functional-features/listing-13-05/output.txt}}
$ cargo run
Compiling closure-example v0.1.0 (file:///projects/closure-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.43s
Running `target/debug/closure-example`
Before defining closure: [1, 2, 3]
After calling closure: [1, 2, 3, 7]
Notez qu’il n’y a plus de println! entre la définition et l’appel de la fermeture borrows_mutably : quand borrows_mutably est définie, elle capture une référence mutable vers list. Nous n’utilisons plus la fermeture après son appel, donc l’emprunt mutable se terminé. Entre la définition de la fermeture et l’appel de la fermeture, un emprunt immuable pour afficher n’est pas autorise, car aucun autre emprunt n’est permis lorsqu’il y à un emprunt mutable. Essayez d’ajouter un println! à cet endroit pour voir quel message d’erreur vous obtenez !
Si vous voulez forcer la fermeture a prendre la possession des valeurs qu’elle utilise dans l’environnement même si le corps de la fermeture n’a pas strictement besoin de la possession, vous pouvez utiliser le mot-clé move avant la liste de paramètres.
Cette technique est surtout utile lorsque vous passez une fermeture à un nouveau thread pour deplacer les données afin qu’elles soient possedees par le nouveau thread. Nous discuterons des threads et de pourquoi vous voudriez les utiliser en détail dans le chapitre 16 lorsque nous parlerons de la concurrence, mais pour l’instant, explorons brievement la creation d’un nouveau thread en utilisant une fermeture qui nécessite le mot-clé move. L’encart 13-6 montre l’encart 13-4 modifié pour afficher le vecteur dans un nouveau thread plutot que dans le thread principal.
use std::thread;
fn main() {
let list = vec![1, 2, 3];
println!("Before defining closure: {list:?}");
thread::spawn(move || println!("From thread: {list:?}"))
.join()
.unwrap();
}move to force the closure for the thread to take ownership of listNous créons un nouveau thread en lui donnant une fermeture a exécuter comme argument. Le corps de la fermeture affiche la liste. Dans l’encart 13-4, la fermeture ne capturait list qu’avec une référence immuable car c’est le minimum d’accès a list nécessaire pour l’afficher. Dans cet exemple, même si le corps de la fermeture n’a toujours besoin que d’une référence immuable, nous devons spécifier que list doit être deplacee dans la fermeture en mettant le mot-clé move au début de la définition de la fermeture. Si le thread principal effectuait d’autres opérations avant d’appeler join sur le nouveau thread, le nouveau thread pourrait se terminer avant que le reste du thread principal ne se terminé, ou le thread principal pourrait se terminer en premier. Si le thread principal conservait la possession de list mais se terminait avant le nouveau thread et liberait list, la référence immuable dans le thread serait invalide. Par consequent, le compilateur exige que list soit deplacee dans la fermeture donnée au nouveau thread pour que la référence soit valide. Essayez de retirer le mot-clé move ou d’utiliser list dans le thread principal après que la fermeture ait été définie pour voir quelles erreurs du compilateur vous obtenez !
Deplacer les valeurs capturees hors des fermetures
Une fois qu’une fermeture a capture une référence ou pris la possession d’une valeur de l’environnement ou la fermeture est définie (affectant ainsi ce qui, le cas echeant, est deplace dans la fermeture), le code dans le corps de la fermeture définit ce qui arrive aux références ou aux valeurs lorsque la fermeture est evaluee plus tard (affectant ainsi ce qui, le cas echeant, est deplace hors de la fermeture).
Le corps d’une fermeture peut faire l’une des choses suivantes : deplacer une valeur capturee hors de la fermeture, muter la valeur capturee, ne ni deplacer ni muter la valeur, ou ne rien capturer de l’environnement au depart.
La façon dont une fermeture capture et gère les valeurs de l’environnement affecte les traits que la fermeture implémenté, et les traits sont la maniere dont les fonctions et les structs peuvent spécifier quels types de fermetures elles peuvent utiliser. Les fermetures implementeront automatiquement un, deux ou les trois traits Fn, de maniere additive, selon la façon dont le corps de la fermeture gère les valeurs :
FnOnces’applique aux fermetures qui peuvent être appelées une seule fois. Toutes les fermetures implementent au moins ce trait car toutes les fermetures peuvent être appelées. Une fermeture qui deplace les valeurs capturees hors de son corps n’implementera queFnOnceet aucun des autres traitsFncar elle ne peut être appelée qu’une seule fois.FnMuts’applique aux fermetures qui ne deplacent pas les valeurs capturees hors de leur corps mais qui pourraient muter les valeurs capturees. Ces fermetures peuvent être appelées plusieurs fois.Fns’applique aux fermetures qui ne deplacent pas les valeurs capturees hors de leur corps et qui ne mutent pas les valeurs capturees, ainsi qu’aux fermetures qui ne capturent rien de leur environnement. Ces fermetures peuvent être appelées plusieurs fois sans muter leur environnement, ce qui est important dans des cas comme l’appel concurrent d’une fermeture plusieurs fois.
Examinons la définition de la methode unwrap_or_else sur Option<T> que nous avons utilisee dans l’encart 13-1 :
impl<T> Option<T> {
pub fn unwrap_or_else<F>(self, f: F) -> T
where
F: FnOnce() -> T
{
match self {
Some(x) => x,
None => f(),
}
}
}Rappelez-vous que T est le type générique representant le type de la valeur dans la variante Some d’une Option. Ce type T est également le type de retour de la fonction unwrap_or_else : du code qui appelle unwrap_or_else sur une Option<String>, par exemple, obtiendra une String.
Ensuite, remarquez que la fonction unwrap_or_else à le paramètre de type générique supplementaire F. Le type F est le type du paramètre nomme f, qui est la fermeture que nous fournissons lors de l’appel a unwrap_or_else.
La contrainte de trait spécifiée sur le type générique F est FnOnce() -> T, ce qui signifie que F doit pouvoir être appelé une fois, ne prendre aucun argument et retourner un T. Utiliser FnOnce dans la contrainte de trait exprime la contrainte que unwrap_or_else n’appellera pas f plus d’une fois. Dans le corps de unwrap_or_else, nous pouvons voir que si Option est Some, f ne sera pas appelée. Si Option est None, f sera appelée une fois. Parce que toutes les fermetures implementent FnOnce, unwrap_or_else accepte les trois types de fermetures et est aussi flexible que possible.
Remarque : si ce que nous voulons faire ne nécessite pas de capturer une valeur de l’environnement, nous pouvons utiliser le nom d’une fonction plutot qu’une fermeture la où nous avons besoin de quelque chose qui implémenté l’un des traits
Fn. Par exemple, sur une valeurOption<Vec<T>>, nous pourrions appelerunwrap_or_else(Vec::new)pour obtenir un nouveau vecteur vide si la valeur estNone. Le compilateur implémenté automatiquement celui des traitsFnqui est applicable pour une définition de fonction.
Examinons maintenant la methode de la bibliothèque standard sort_by_key, définie sur les slices, pour voir en quoi elle diffère de unwrap_or_else et pourquoi sort_by_key utilise FnMut au lieu de FnOnce pour la contrainte de trait. La fermeture recoit un argument sous la forme d’une référence vers l’élément actuel de la slice considérée, et retourné une valeur de type K qui peut être ordonnee. Cette fonction est utile lorsque vous voulez trier une slice selon un attribut particulier de chaque élément. Dans l’encart 13-7, nous avons une liste d’instances de Rectangle, et nous utilisons sort_by_key pour les ordonner par leur attribut width du plus petit au plus grand.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
list.sort_by_key(|r| r.width);
println!("{list:#?}");
}sort_by_key to order rectangles by widthCe code affiche : console {{#include ../listings/ch13-functional-features/listing-13-07/output.txt}}
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/rectangles`
[
Rectangle {
width: 3,
height: 5,
},
Rectangle {
width: 7,
height: 12,
},
Rectangle {
width: 10,
height: 1,
},
]
La raison pour laquelle sort_by_key est définie pour prendre une fermeture FnMut est qu’elle appelle la fermeture plusieurs fois : une fois pour chaque élément de la slice. La fermeture |r| r.width ne capture, ne mute ni ne deplace rien hors de son environnement, donc elle respecte les exigences de la contrainte de trait.
En revanche, l’encart 13-8 montre un exemple de fermeture qui n’implémenté que le trait FnOnce, car elle deplace une valeur hors de l’environnement. Le compilateur ne nous laissera pas utiliser cette fermeture avec sort_by_key.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut sort_operations = vec![];
let value = String::from("closure called");
list.sort_by_key(|r| {
sort_operations.push(value);
r.width
});
println!("{list:#?}");
}FnOnce closure with sort_by_keyIl s’agit d’une façon artificielle et alambiquee (qui ne fonctionne pas) d’essayer de compter le nombre de fois que sort_by_key appelle la fermeture lors du tri de list. Ce code tente de faire ce comptage en poussant value – une String de l’environnement de la fermeture – dans le vecteur sort_operations. La fermeture capture value puis deplace value hors de la fermeture en transferant la possession de value au vecteur sort_operations. Cette fermeture ne peut être appelée qu’une seule fois ; essayer de l’appeler une deuxième fois ne fonctionnerait pas, car value ne serait plus dans l’environnement pour être poussee dans sort_operations à nouveau ! Par consequent, cette fermeture n’implémenté que FnOnce. Lorsque nous essayons de compiler ce code, nous obtenons cette erreur indiquant que value ne peut pas être deplacee hors de la fermeture car la fermeture doit implémenter FnMut : console {{#include ../listings/ch13-functional-features/listing-13-08/output.txt}}
$ cargo run
Compiling rectangles v0.1.0 (file:///projects/rectangles)
error[E0507]: cannot move out of `value`, a captured variable in an `FnMut` closure
--> src/main.rs:18:30
|
15 | let value = String::from("closure called");
| ----- ------------------------------ move occurs because `value` has type `String`, which does not implement the `Copy` trait
| |
| captured outer variable
16 |
17 | list.sort_by_key(|r| {
| --- captured by this `FnMut` closure
18 | sort_operations.push(value);
| ^^^^^ `value` is moved here
|
help: consider cloning the value if the performance cost is acceptable
|
18 | sort_operations.push(value.clone());
| ++++++++
For more information about this error, try `rustc --explain E0507`.
error: could not compile `rectangles` (bin "rectangles") due to 1 previous error
L’erreur pointe vers la ligne dans le corps de la fermeture qui deplace value hors de l’environnement. Pour corriger cela, nous devons modifier le corps de la fermeture pour qu’il ne deplace pas de valeurs hors de l’environnement. Garder un compteur dans l’environnement et incrementer sa valeur dans le corps de la fermeture est une façon plus directe de compter le nombre de fois que la fermeture est appelée. La fermeture de l’encart 13-9 fonctionne avec sort_by_key car elle ne capture qu’une référence mutable vers le compteur num_sort_operations et peut donc être appelée plus d’une fois.
#[derive(Debug)]
struct Rectangle {
width: u32,
height: u32,
}
fn main() {
let mut list = [
Rectangle { width: 10, height: 1 },
Rectangle { width: 3, height: 5 },
Rectangle { width: 7, height: 12 },
];
let mut num_sort_operations = 0;
list.sort_by_key(|r| {
num_sort_operations += 1;
r.width
});
println!("{list:#?}, sorted in {num_sort_operations} operations");
}FnMut closure with sort_by_key is allowed.Les traits Fn sont importants lors de la définition ou de l’utilisation de fonctions ou de types qui utilisent des fermetures. Dans la prochaine section, nous aborderons les iterateurs. De nombreuses methodes d’iterateurs prennent des fermetures en arguments, alors gardez ces détails sur les fermetures à l’esprit pendant que nous continuons !
Traiter une série d’éléments avec les itérateurs
Traiter une série d’éléments avec les itérateurs
Le patron de conception iterateur vous permet d’effectuer une tâche sur une séquence d’éléments tour a tour. Un iterateur est responsable de la logique d’iteration sur chaque élément et de la determination de la fin de la séquence. Lorsque vous utilisez des iterateurs, vous n’avez pas a reimplementer cette logique vous-meme.
En Rust, les iterateurs sont paresseux (lazy), ce qui signifie qu’ils n’ont aucun effet tant que vous n’appelez pas de methodes qui consomment l’iterateur pour l’utiliser. Par exemple, le code de l’encart 13-10 crée un iterateur sur les éléments du vecteur v1 en appelant la methode iter définie sur Vec<T>. Ce code en lui-meme ne fait rien d’utile.
fn main() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
}L’iterateur est stocké dans la variable v1_iter. Une fois que nous avons crée un iterateur, nous pouvons l’utiliser de diverses façons. Dans l’encart 3-5, nous avons itere sur un tableau en utilisant une boucle for pour exécuter du code sur chacun de ses éléments. Sous le capot, cela a implicitement crée puis consomme un iterateur, mais nous avons passe sous silence le fonctionnement exact de ce mecanisme jusqu’a maintenant.
Dans l’exemple de l’encart 13-11, nous separons la creation de l’iterateur de l’utilisation de l’iterateur dans la boucle for. Lorsque la boucle for est appelée en utilisant l’iterateur dans v1_iter, chaque élément de l’iterateur est utilise dans une iteration de la boucle, ce qui affiche chaque valeur.
fn main() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
for val in v1_iter {
println!("Got: {val}");
}
}for loopDans les langages dont les bibliothèques standard ne fournissent pas d’iterateurs, vous ecririez probablement cette même fonctionnalité en initialisant une variable à l’index 0, en utilisant cette variable pour indexer le vecteur et obtenir une valeur, puis en incrementant la valeur de la variable dans une boucle jusqu’a atteindre le nombre total d’éléments du vecteur.
Les iterateurs gèrent toute cette logique pour vous, reduisant le code repetitif que vous pourriez potentiellement mal écrire. Les iterateurs vous donnent plus de flexibilite pour utiliser la même logique avec de nombreux types différents de séquences, pas seulement des structures de données que vous pouvez indexer, comme les vecteurs. Examinons comment les iterateurs font cela.
Le trait Iterator et la methode next
Tous les iterateurs implementent un trait nomme Iterator qui est défini dans la bibliothèque standard. La définition du trait ressemble a ceci :
#![allow(unused)]
fn main() {
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
// methods with default implémentations elided
}
}Remarquez que cette définition utilise une syntaxe nouvelle : type Item et Self::Item, qui définissent un type associe à ce trait. Nous parlerons des types associes en détail dans le chapitre 20. Pour l’instant, tout ce que vous devez savoir est que ce code dit qu’implémenter le trait Iterator nécessite que vous definissiez également un type Item, et ce type Item est utilise dans le type de retour de la methode next. En d’autres termes, le type Item sera le type retourné par l’iterateur.
Le trait Iterator n’exige des implementeurs que la définition d’une seule methode : la methode next, qui retourné un élément de l’iterateur à la fois, enveloppe dans Some, et, lorsque l’iteration est terminée, retourné None.
Nous pouvons appeler la methode next directement sur les iterateurs ; l’encart 13-12 montre quelles valeurs sont retournées par des appels repetes a next sur l’iterateur crée à partir du vecteur.
#[cfg(test)]
mod tests {
#[test]
fn iterator_demonstration() {
let v1 = vec![1, 2, 3];
let mut v1_iter = v1.iter();
assert_eq!(v1_iter.next(), Some(&1));
assert_eq!(v1_iter.next(), Some(&2));
assert_eq!(v1_iter.next(), Some(&3));
assert_eq!(v1_iter.next(), None);
}
}next method on an iteratorNotez que nous avons du rendre v1_iter mutable : appeler la methode next sur un iterateur modifié l’état interne que l’iterateur utilise pour garder une trace de sa position dans la séquence. En d’autres termes, ce code consomme, ou epuise, l’iterateur. Chaque appel a next consomme un élément de l’iterateur. Nous n’avions pas besoin de rendre v1_iter mutable lorsque nous utilisions une boucle for, car la boucle a pris la possession de v1_iter et l’a rendue mutable en coulisses.
Notez également que les valeurs que nous obtenons des appels a next sont des références immuables vers les valeurs du vecteur. La methode iter produit un iterateur sur des références immuables. Si nous voulons créer un iterateur qui prend la possession de v1 et retourné des valeurs possedees, nous pouvons appeler into_iter au lieu de iter. De même, si nous voulons iterer sur des références mutables, nous pouvons appeler iter_mut au lieu de iter.
Les methodes qui consomment l’iterateur
Le trait Iterator possède un certain nombre de methodes différentes avec des implémentations par défaut fournies par la bibliothèque standard ; vous pouvez découvrir ces methodes en consultant la documentation de l’API de la bibliothèque standard pour le trait Iterator. Certaines de ces methodes appellent la methode next dans leur définition, c’est pourquoi vous devez implémenter la methode next lorsque vous implementez le trait Iterator.
Les methodes qui appellent next sont appelées adaptateurs consommateurs car les appeler consomme l’iterateur. Un exemple est la methode sum, qui prend la possession de l’iterateur et parcourt les éléments en appelant next de maniere repetee, consommant ainsi l’iterateur. Au fur et a mesure qu’elle itere, elle ajouté chaque élément à un total cumulatif et retourné le total lorsque l’iteration est terminée. L’encart 13-13 contient un test illustrant l’utilisation de la methode sum.
#[cfg(test)]
mod tests {
#[test]
fn iterator_sum() {
let v1 = vec![1, 2, 3];
let v1_iter = v1.iter();
let total: i32 = v1_iter.sum();
assert_eq!(total, 6);
}
}sum method to get the total of all items in the iteratorNous n’avons pas le droit d’utiliser v1_iter après l’appel a sum, car sum prend la possession de l’iterateur sur lequel nous l’appelons.
Les methodes qui produisent d’autres iterateurs
Les adaptateurs d’iterateurs sont des methodes définies sur le trait Iterator qui ne consomment pas l’iterateur. Au lieu de cela, ils produisent des iterateurs différents en modifiant un aspect de l’iterateur original.
L’encart 13-14 montre un exemple d’appel de la methode d’adaptateur d’iterateur map, qui prend une fermeture a appeler sur chaque élément au fur et a mesure que les éléments sont parcourus. La methode map retourné un nouvel iterateur qui produit les éléments modifiés. La fermeture ici crée un nouvel iterateur dans lequel chaque élément du vecteur sera incremente de 1.
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
v1.iter().map(|x| x + 1);
}map to create a new iteratorCependant, ce code produit un avertissement : console {{#include ../listings/ch13-functional-features/listing-13-14/output.txt}}
$ cargo run
Compiling iterators v0.1.0 (file:///projects/iterators)
warning: unused `Map` that must be used
--> src/main.rs:4:5
|
4 | v1.iter().map(|x| x + 1);
| ^^^^^^^^^^^^^^^^^^^^^^^^
|
= note: iterators are lazy and do nothing unless consumed
= note: `#[warn(unused_must_use)]` on by default
help: use `let _ = ...` to ignore the resulting value
|
4 | let _ = v1.iter().map(|x| x + 1);
| +++++++
warning: `iterators` (bin "iterators") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.47s
Running `target/debug/iterators`
Le code de l’encart 13-14 ne fait rien ; la fermeture que nous avons spécifiée n’est jamais appelée. L’avertissement nous rappelle pourquoi : les adaptateurs d’iterateurs sont paresseux, et nous devons consommer l’iterateur ici.
Pour corriger cet avertissement et consommer l’iterateur, nous utiliserons la methode collect, que nous avons utilisee avec env::args dans l’encart 12-1. Cette methode consomme l’iterateur et collecte les valeurs resultantes dans un type de données de collection.
Dans l’encart 13-15, nous collectons les résultats de l’iteration sur l’iterateur retourné par l’appel a map dans un vecteur. Ce vecteur finira par contenir chaque élément du vecteur original, incremente de 1.
fn main() {
let v1: Vec<i32> = vec![1, 2, 3];
let v2: Vec<_> = v1.iter().map(|x| x + 1).collect();
assert_eq!(v2, vec![2, 3, 4]);
}map method to create a new iterator, and then calling the collect method to consume the new iterator and create a vectorParce que map prend une fermeture, nous pouvons spécifier n’importe quelle opération que nous voulons effectuer sur chaque élément. C’est un excellent exemple de la façon dont les fermetures vous permettent de personnaliser un comportement tout en reutilisant le comportement d’iteration que le trait Iterator fournit.
Vous pouvez enchainer plusieurs appels à des adaptateurs d’iterateurs pour effectuer des actions complexes de maniere lisible. Mais parce que tous les iterateurs sont paresseux, vous devez appeler l’une des methodes d’adaptateur consommateur pour obtenir des résultats à partir des appels aux adaptateurs d’iterateurs.
Les fermetures qui capturent leur environnement
De nombreux adaptateurs d’iterateurs prennent des fermetures en arguments, et généralement les fermetures que nous specifierons comme arguments aux adaptateurs d’iterateurs seront des fermetures qui capturent leur environnement.
Pour cet exemple, nous utiliserons la methode filter qui prend une fermeture. La fermeture recoit un élément de l’iterateur et retourné un bool. Si la fermeture retourné true, la valeur sera incluse dans l’iteration produite par filter. Si la fermeture retourné false, la valeur ne sera pas incluse.
Dans l’encart 13-16, nous utilisons filter avec une fermeture qui capture la variable shoe_size de son environnement pour iterer sur une collection d’instances de la struct Shoe. Elle ne retournera que les chaussures de la taille spécifiée.
#[derive(PartialEq, Debug)]
struct Shoe {
size: u32,
style: String,
}
fn shoes_in_size(shoes: Vec<Shoe>, shoe_size: u32) -> Vec<Shoe> {
shoes.into_iter().filter(|s| s.size == shoe_size).collect()
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn filters_by_size() {
let shoes = vec![
Shoe {
size: 10,
style: String::from("sneaker"),
},
Shoe {
size: 13,
style: String::from("sandal"),
},
Shoe {
size: 10,
style: String::from("boot"),
},
];
let in_my_size = shoes_in_size(shoes, 10);
assert_eq!(
in_my_size,
vec![
Shoe {
size: 10,
style: String::from("sneaker")
},
Shoe {
size: 10,
style: String::from("boot")
},
]
);
}
}filter method with a closure that captures shoe_sizeLa fonction shoes_in_size prend la possession d’un vecteur de chaussures et une taille de chaussure en paramètres. Elle retourné un vecteur contenant uniquement les chaussures de la taille spécifiée.
Dans le corps de shoes_in_size, nous appelons into_iter pour créer un iterateur qui prend la possession du vecteur. Ensuite, nous appelons filter pour adapter cet iterateur en un nouvel iterateur qui ne contient que les éléments pour lesquels la fermeture retourné true.
La fermeture capture le paramètre shoe_size de l’environnement et compare la valeur avec la taille de chaque chaussure, ne gardant que les chaussures de la taille spécifiée. Enfin, l’appel a collect rassemble les valeurs retournées par l’iterateur adapte dans un vecteur qui est retourné par la fonction.
Le test montre que lorsque nous appelons shoes_in_size, nous ne recuperons que les chaussures qui ont la même taille que la valeur que nous avons spécifiée.
Améliorer notre projet d’E/S
Améliorer notre projet d’E/S
Avec ces nouvelles connaissances sur les iterateurs, nous pouvons améliorer le projet d’E/S du chapitre 12 en utilisant des iterateurs pour rendre certaines parties du code plus claires et plus concises. Voyons comment les iterateurs peuvent améliorer notre implémentation de la fonction Config::build et de la fonction search.
Supprimer un clone en utilisant un iterateur
Dans l’encart 12-6, nous avons ajouté du code qui prenait une slice de valeurs String et creait une instance de la struct Config en indexant la slice et en clonant les valeurs, permettant à la struct Config de posséder ces valeurs. Dans l’encart 13-17, nous avons reproduit l’implémentation de la fonction Config::build telle qu’elle était dans l’encart 12-23.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
println!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
println!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Config::build function from Listing 12-23A l’epoque, nous avions dit de ne pas s’inquieter des appels inefficaces a clone car nous les supprimerions à l’avenir. Eh bien, ce moment est arrive !
Nous avions besoin de clone ici car nous avons une slice avec des éléments String dans le paramètre args, mais la fonction build ne possède pas args. Pour retourner la possession d’une instance de Config, nous devions cloner les valeurs des champs query et file_path de Config afin que l’instance de Config puisse posséder ses valeurs.
Avec nos nouvelles connaissances sur les iterateurs, nous pouvons modifier la fonction build pour qu’elle prenne la possession d’un iterateur comme argument au lieu d’emprunter une slice. Nous utiliserons la fonctionnalité d’iterateur au lieu du code qui vérifie la longueur de la slice et indexe des emplacements spécifiques. Cela clarifiera ce que fait la fonction Config::build car l’iterateur accède aux valeurs.
Une fois que Config::build prend la possession de l’iterateur et cesse d’utiliser des opérations d’indexation qui empruntent, nous pouvons deplacer les valeurs String de l’iterateur dans Config plutot que d’appeler clone et de faire une nouvelle allocation.
Utiliser l’iterateur retourné directement
Ouvrez le fichier src/main.rs de votre projet d’E/S, qui devrait ressembler a ceci :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let args: Vec<String> = env::args().collect();
let config = Config::build(&args).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Nous allons d’abord modifier le début de la fonction main que nous avions dans l’encart 12-24 par le code de l’encart 13-18, qui cette fois utilise un iterateur. Cela ne compilera pas tant que nous n’aurons pas également mis à jour Config::build.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
// --snip--
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(args: &[String]) -> Result<Config, &'static str> {
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}env::args to Config::buildLa fonction env::args retourné un iterateur ! Plutot que de collecter les valeurs de l’iterateur dans un vecteur puis de passer une slice a Config::build, nous passons maintenant directement la possession de l’iterateur retourné par env::args a Config::build.
Ensuite, nous devons mettre à jour la définition de Config::build. Modifions la signature de Config::build pour qu’elle ressemble à l’encart 13-19. Cela ne compilera toujours pas, car nous devons mettre à jour le corps de la fonction.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
// --snip--
if args.len() < 3 {
return Err("not enough arguments");
}
let query = args[1].clone();
let file_path = args[2].clone();
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Config::build to expect an iteratorLa documentation de la bibliothèque standard pour la fonction env::args montre que le type de l’iterateur qu’elle retourné est std::env::Args, et ce type implémenté le trait Iterator et retourné des valeurs String.
section of Chapter 10 means that args can be any type that implements the Iterator trait and returns String items. –> Nous avons mis à jour la signature de la fonction Config::build pour que le paramètre args ait un type générique avec les contraintes de trait impl Iterator<Item = String> au lieu de &[String]. Cette utilisation de la syntaxe impl Trait que nous avons abordee dans la section [“Utiliser les traits comme paramètres”][impl-trait] du chapitre 10 signifie que args peut être n’importe quel type qui implémenté le trait Iterator et retourné des éléments String.
Parce que nous prenons la possession de args et que nous allons muter args en iterant dessus, nous pouvons ajouter le mot-clé mut dans la specification du paramètre args pour le rendre mutable.
Utiliser les methodes du trait Iterator
Ensuite, nous allons corriger le corps de Config::build. Parce que args implémenté le trait Iterator, nous savons que nous pouvons appeler la methode next dessus ! L’encart 13-20 met à jour le code de l’encart 12-23 pour utiliser la methode next.
use std::env;
use std::error::Error;
use std::fs;
use std::process;
use minigrep::{search, search_case_insensitive};
fn main() {
let config = Config::build(env::args()).unwrap_or_else(|err| {
eprintln!("Problem parsing arguments: {err}");
process::exit(1);
});
if let Err(e) = run(config) {
eprintln!("Application error: {e}");
process::exit(1);
}
}
pub struct Config {
pub query: String,
pub file_path: String,
pub ignore_case: bool,
}
impl Config {
fn build(
mut args: impl Iterator<Item = String>,
) -> Result<Config, &'static str> {
args.next();
let query = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a query string"),
};
let file_path = match args.next() {
Some(arg) => arg,
None => return Err("Didn't get a file path"),
};
let ignore_case = env::var("IGNORE_CASE").is_ok();
Ok(Config {
query,
file_path,
ignore_case,
})
}
}
fn run(config: Config) -> Result<(), Box<dyn Error>> {
let contents = fs::read_to_string(config.file_path)?;
let results = if config.ignore_case {
search_case_insensitive(&config.query, &contents)
} else {
search(&config.query, &contents)
};
for line in results {
println!("{line}");
}
Ok(())
}Config::build to use iterator methodsRappelez-vous que la première valeur dans la valeur de retour de env::args est le nom du programme. Nous voulons l’ignorer et passer à la valeur suivante, donc nous appelons d’abord next et ne faisons rien avec la valeur de retour. Ensuite, nous appelons next pour obtenir la valeur que nous voulons mettre dans le champ query de Config. Si next retourné Some, nous utilisons un match pour extraire la valeur. Si elle retourné None, cela signifie que pas assez d’arguments ont été fournis, et nous retournons prematurement avec une valeur Err. Nous faisons la même chose pour la valeur file_path.
Clarifier le code avec les adaptateurs d’iterateurs
Nous pouvons également tirer parti des iterateurs dans la fonction search de notre projet d’E/S, qui est reproduite ici dans l’encart 13-21 telle qu’elle était dans l’encart 12-19.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
let mut results = Vec::new();
for line in contents.lines() {
if line.contains(query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn one_result() {
let query = "duct";
let contents = "\n# Rust:
safe, fast, productive.
Pick three.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
}search function from Listing 12-19Nous pouvons écrire ce code de maniere plus concise en utilisant des methodes d’adaptateur d’iterateur. Ce faisant, nous evitons également d’avoir un vecteur results intermediaire mutable. Le style de programmation fonctionnelle préfère minimiser la quantite d’état mutable pour rendre le code plus clair. Supprimer l’état mutable pourrait permettre une amélioration future pour effectuer la recherche en parallele, car nous n’aurions pas a gérer l’accès concurrent au vecteur results. L’encart 13-22 montre ce changement.
pub fn search<'a>(query: &str, contents: &'a str) -> Vec<&'a str> {
contents
.lines()
.filter(|line| line.contains(query))
.collect()
}
pub fn search_case_insensitive<'a>(
query: &str,
contents: &'a str,
) -> Vec<&'a str> {
let query = query.to_lowercase();
let mut results = Vec::new();
for line in contents.lines() {
if line.to_lowercase().contains(&query) {
results.push(line);
}
}
results
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn case_sensitive() {
let query = "duct";
let contents = "\n# Rust:
safe, fast, productive.
Pick three.
Duct tape.";
assert_eq!(vec!["safe, fast, productive."], search(query, contents));
}
#[test]
fn case_insensitive() {
let query = "rUsT";
let contents = "\n# Rust:
safe, fast, productive.
Pick three.
Trust me.";
assert_eq!(
vec!["Rust:", "Trust me."],
search_case_insensitive(query, contents)
);
}
}search functionRappelez-vous que le but de la fonction search est de retourner toutes les lignes de contents qui contiennent la query. De maniere similaire à l’exemple filter de l’encart 13-16, ce code utilise l’adaptateur filter pour ne garder que les lignes pour lesquelles line.contains(query) retourné true. Nous collectons ensuite les lignes correspondantes dans un autre vecteur avec collect. Bien plus simple ! N’hesitez pas a faire le même changement pour utiliser les methodes d’iterateur dans la fonction search_case_insensitive également.
Pour une amélioration supplementaire, retournez un iterateur depuis la fonction search en supprimant l’appel a collect et en changeant le type de retour en impl Iterator<Item = &'a str> afin que la fonction devienne un adaptateur d’iterateur. Notez que vous devrez également mettre à jour les tests ! Effectuez une recherche dans un gros fichier en utilisant votre outil minigrep avant et après ce changement pour observer la différence de comportement. Avant ce changement, le programme n’affichera aucun résultat tant qu’il n’aura pas collecte tous les résultats, mais après le changement, les résultats seront affiches au fur et a mesure que chaque ligne correspondante est trouvee car la boucle for dans la fonction run peut tirer parti de la paresse de l’iterateur.
Choisir entre les boucles et les iterateurs
La question logique suivante est quel style vous devriez choisir dans votre propre code et pourquoi : l’implémentation originale de l’encart 13-21 ou la version utilisant les iterateurs de l’encart 13-22 (en supposant que nous collectons tous les résultats avant de les retourner plutot que de retourner l’iterateur). La plupart des programmeurs Rust preferent utiliser le style iterateur. C’est un peu plus difficile a maitriser au début, mais une fois que vous avez une bonne comprehension des différents adaptateurs d’iterateurs et de ce qu’ils font, les iterateurs peuvent être plus faciles a comprendre. Au lieu de bricoler les différentes parties des boucles et de construire de nouveaux vecteurs, le code se concentre sur l’objectif de haut niveau de la boucle. Cela abstrait une partie du code courant de sorte qu’il est plus facile de voir les concepts propres à ce code, comme la condition de filtrage que chaque élément de l’iterateur doit satisfaire.
Mais les deux implémentations sont-elles vraiment equivalentes ? L’hypothese intuitive pourrait être que la boucle de bas niveau sera plus rapide. Parlons des performances.
Performances : boucles vs. itérateurs
Performances : boucles vs. itérateurs
Pour déterminer s’il faut utiliser des boucles ou des iterateurs, vous devez savoir quelle implémentation est la plus rapide : la version de la fonction search avec une boucle for explicite ou la version avec des iterateurs.
Nous avons effectue un benchmark en chargeant l’integralite du contenu des Aventures de Sherlock Holmes de Sir Arthur Conan Doyle dans une String et en recherchant le mot the dans le contenu. Voici les résultats du benchmark sur la version de search utilisant la boucle for et la version utilisant les iterateurs :
test bench_search_for ... bench: 19,620,300 ns/iter (+/- 915,700)
test bench_search_iter ... bench: 19,234,900 ns/iter (+/- 657,200)
Les deux implémentations ont des performances similaires ! Nous n’expliquerons pas le code du benchmark ici car l’objectif n’est pas de prouver que les deux versions sont equivalentes, mais d’avoir une idee generale de la comparaison de performances entre ces deux implémentations.
Pour un benchmark plus complet, vous devriez tester avec différents textes de différentes tailles comme contents, différents mots et mots de différentes longueurs comme query, et toutes sortes d’autres variations. Le point essentiel est le suivant : les iterateurs, bien qu’étant une abstraction de haut niveau, sont compilés en un code a peu près identique a celui que vous auriez écrit vous-meme a plus bas niveau. Les iterateurs sont l’une des abstractions a cout zero de Rust, ce qui signifie que l’utilisation de l’abstraction n’impose aucun surcout à l’exécution. Cela est analogue à la maniere dont Bjarne Stroustrup, le concepteur et implementeur original du C++, définit le zero-overhead dans sa presentation ETAPS de 2012 intitulee “Foundations of C++” :
En general, les implémentations C++ obeissent au principe du zero-overhead : ce que vous n’utilisez pas, vous ne le payez pas. Et de plus : ce que vous utilisez, vous ne pourriez pas le coder mieux à la main.
Dans de nombreux cas, le code Rust utilisant des iterateurs est compilé en un assembleur identique a celui que vous ecririez à la main. Des optimisations telles que le deroulement de boucles et l’elimination des vérifications de bornes lors de l’accès aux tableaux s’appliquent et rendent le code resultant extremement efficace. Maintenant que vous savez cela, vous pouvez utiliser les iterateurs et les fermetures sans crainte ! Ils donnent au code une apparence de haut niveau sans imposer de penalite de performance à l’exécution.
Résumé
Les fermetures et les iterateurs sont des fonctionnalités de Rust inspirees des idees de la programmation fonctionnelle. Ils contribuent à la capacité de Rust a exprimer clairement des idees de haut niveau avec des performances de bas niveau. Les implémentations des fermetures et des iterateurs sont telles que les performances à l’exécution ne sont pas affectees. Cela fait partie de l’objectif de Rust de fournir des abstractions a cout zero.
Maintenant que nous avons ameliore l’expressivite de notre projet d’E/S, examinons d’autres fonctionnalités de cargo qui nous aideront a partager le projet avec le monde.
En savoir plus sur Cargo et Crates.io
Jusqu’a présent, nous n’avons utilise que les fonctionnalités les plus basiques de Cargo pour compiler, exécuter et tester notre code, mais il peut faire bien plus. Dans ce chapitre, nous aborderons certaines de ses fonctionnalités plus avancees pour vous montrer comment effectuer les opérations suivantes :
- Personnaliser votre compilation grâce aux profils de publication.
- Publier des bibliothèques sur crates.io.
- Organiser de grands projets avec des espaces de travail (workspaces).
- Installer des binaires depuis crates.io.
- Etendre Cargo avec des commandes personnalisees.
Cargo peut faire encore plus que les fonctionnalités que nous couvrons dans ce chapitre, donc pour une explication complète de toutes ses fonctionnalités, consultez sa documentation.
Personnaliser les compilations avec les profils de publication
Personnaliser les compilations avec les profils de publication
En Rust, les profils de publication (release profiles) sont des profils predefinis et personnalisables avec différentes configurations qui permettent à un programmeur d’avoir plus de contrôle sur les différentes options de compilation du code. Chaque profil est configure indépendamment des autres.
Cargo a deux profils principaux : le profil dev que Cargo utilise lorsque vous exécutez cargo build, et le profil release que Cargo utilise lorsque vous exécutez cargo build --release. Le profil dev est défini avec de bons paramètres par défaut pour le développement, et le profil release a de bons paramètres par défaut pour les compilations de publication.
Ces noms de profils vous sont peut-etre familiers d’après la sortie de vos compilations :
$ cargo build
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
$ cargo build --release
Finished `release` profile [optimized] target(s) in 0.32s
dev et release sont ces différents profils utilises par le compilateur.
Cargo à des paramètres par défaut pour chacun des profils qui s’appliquent lorsque vous n’avez explicitement ajouté aucune section [profile.*] dans le fichier Cargo.toml du projet. En ajoutant des sections [profile.*] pour tout profil que vous souhaitez personnaliser, vous remplacez n’importe quel sous-ensemble des paramètres par défaut. Par exemple, voici les valeurs par défaut pour le paramètre opt-level des profils dev et release :
Fichier : Cargo.toml
[profile.dev]
opt-level = 0
[profile.release]
opt-level = 3
Le paramètre opt-level contrôle le nombre d’optimisations que Rust appliquera à votre code, avec une plage de 0 à 3. Appliquer plus d’optimisations allonge le temps de compilation, donc si vous etes en développement et que vous compilez souvent votre code, vous voudrez moins d’optimisations pour compiler plus rapidement même si le code resultant s’exécute plus lentement. Le opt-level par défaut pour dev est donc 0. Lorsque vous etes prêt a publier votre code, il est preferable de passer plus de temps a compiler. Vous ne compilerez en mode release qu’une seule fois, mais vous executerez le programme compilé de nombreuses fois, donc le mode release echange un temps de compilation plus long contre un code qui s’exécute plus rapidement. C’est pourquoi le opt-level par défaut pour le profil release est 3.
Vous pouvez remplacer un paramètre par défaut en ajoutant une valeur différente dans Cargo.toml. Par exemple, si nous voulons utiliser le niveau d’optimisation 1 dans le profil de développement, nous pouvons ajouter ces deux lignes au fichier Cargo.toml de notre projet :
Fichier : Cargo.toml
[profile.dev]
opt-level = 1
Ce code remplace le paramètre par défaut de 0. Maintenant, lorsque nous exécutons cargo build, Cargo utilisera les paramètres par défaut du profil dev plus notre personnalisation de opt-level. Parce que nous avons défini opt-level a 1, Cargo appliquera plus d’optimisations que le paramètre par défaut, mais pas autant que dans une compilation de publication.
Pour la liste complète des options de configuration et des valeurs par défaut pour chaque profil, consultez la documentation de Cargo.
Publier une crate sur Crates.io
Publier une crate sur Crates.io
Nous avons utilisé des packages de crates.io comme dépendances de nos projets, mais vous pouvez aussi partager votre code avec d’autres personnes en publiant vos propres packages. Le registre des crates sur crates.io distribue le code source de vos packages, il héberge donc principalement le code qui est open source.
Rust et Cargo ont des fonctionnalités qui rendent votre paquet publié plus facile a trouver et à utiliser pour les autres. Nous allons parler de certaines de ces fonctionnalités puis expliquer comment publier un paquet.
Rédiger des commentaires de documentation utiles
Documenter précisément vos paquets aidera les autres utilisateurs a savoir comment et quand les utiliser, donc cela vaut la peine d’investir du temps pour écrire de la documentation. Dans le chapitre 3, nous avons vu comment commenter le code Rust en utilisant deux barres obliques, //. Rust possède également un type particulier de commentaire pour la documentation, connu de maniere pratique sous le nom de commentaire de documentation, qui generera une documentation HTML. Le HTML affiche le contenu des commentaires de documentation pour les éléments de l’API publique, destine aux programmeurs interesses par savoir comment utiliser votre crate par opposition a comment votre crate est implemente.
Les commentaires de documentation utilisent trois barres obliques, ///, au lieu de deux et supportent la notation Markdown pour le formatage du texte. Placez les commentaires de documentation juste avant l’élément qu’ils documentent. L’encart 14-1 montre des commentaires de documentation pour une fonction add_one dans un crate nomme my_crate.
/// Adds one to the number given.
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}Ici, nous donnons une description de ce que fait la fonction add_one, commencons une section avec le titre Examples, puis fournissons du code qui montre comment utiliser la fonction add_one. Nous pouvons générer la documentation HTML à partir de ce commentaire de documentation en exécutant cargo doc. Cette commande exécute l’outil rustdoc distribue avec Rust et place la documentation HTML générée dans le repertoire target/doc.
Par commodite, exécuter cargo doc --open construira le HTML de la documentation de votre crate actuel (ainsi que la documentation de toutes les dépendances de votre crate) et ouvrira le résultat dans un navigateur web. Naviguez vers la fonction add_one et vous verrez comment le texte des commentaires de documentation est rendu, comme montre dans la figure 14-1.
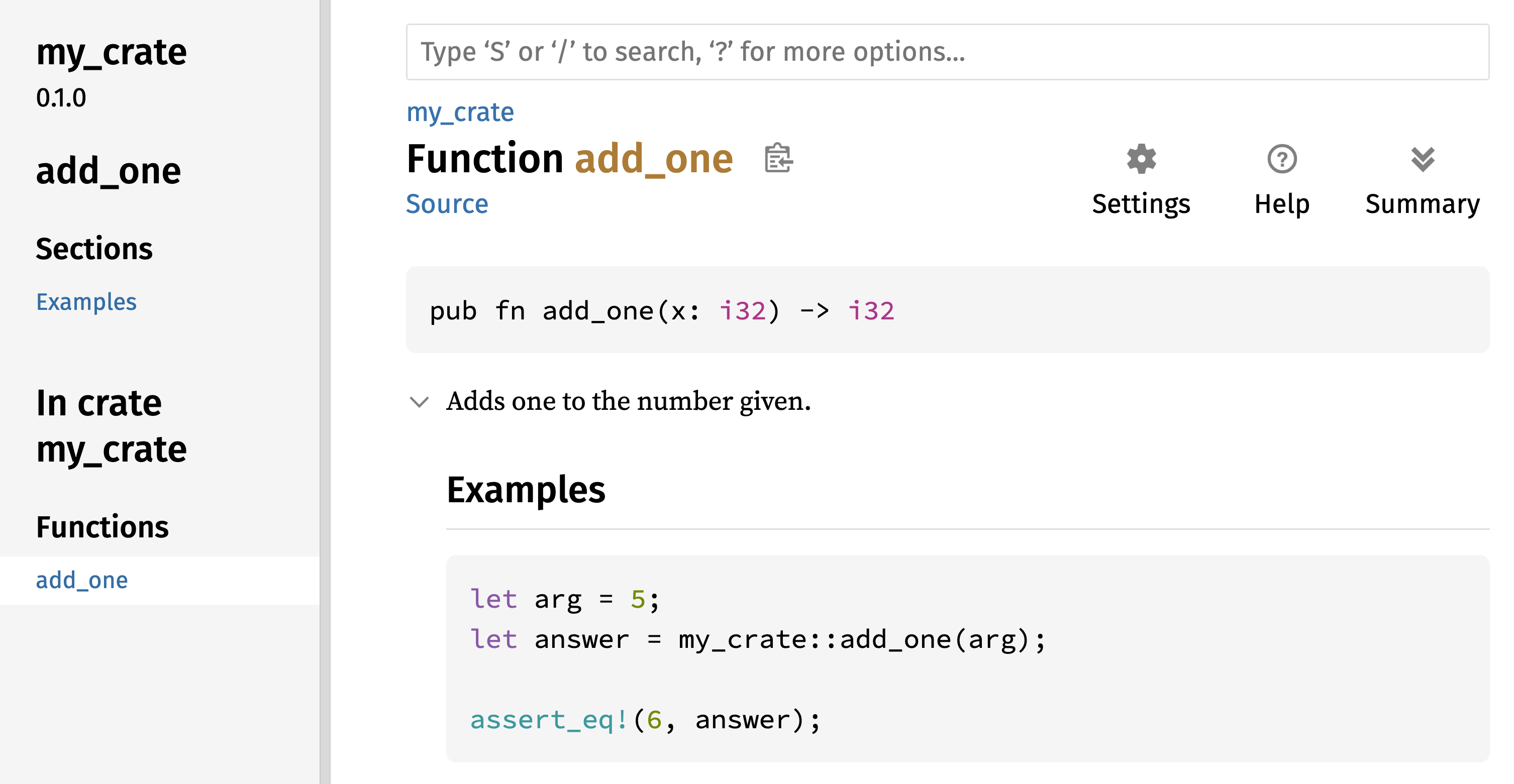
Figure 14-1 : La documentation HTML de la fonction add_one
Sections couramment utilisees
Nous avons utilise le titre Markdown # Examples dans l’encart 14-1 pour créer une section dans le HTML avec le titre “Examples”. Voici d’autres sections que les auteurs de crates utilisent couramment dans leur documentation :
- Panics : ce sont les scenarios dans lesquels la fonction documentee pourrait paniquer. Les appelants de la fonction qui ne veulent pas que leurs programmes paniquent doivent s’assurer de ne pas appeler la fonction dans ces situations.
- Errors : si la fonction retourné un
Result, décrire les types d’erreurs qui pourraient survenir et quelles conditions pourraient provoquer le retour de ces erreurs peut être utile aux appelants afin qu’ils puissent écrire du code pour gérer les différents types d’erreurs de différentes manieres. - Safety : si la fonction est
unsafea appeler (nous discutons de l’unsafety dans le chapitre 20), il devrait y avoir une section expliquant pourquoi la fonction est unsafe et couvrant les invariants que la fonction attend des appelants qu’ils respectent.
La plupart des commentaires de documentation n’ont pas besoin de toutes ces sections, mais c’est une bonne liste de vérification pour vous rappeler les aspects de votre code que les utilisateurs seront interesses a connaitre.
Les commentaires de documentation comme tests
Ajouter des blocs de code d’exemple dans vos commentaires de documentation peut aider a montrer comment utiliser votre bibliothèque et offre un avantage supplementaire : exécuter cargo test exécutera les exemples de code dans votre documentation comme des tests ! Rien n’est mieux que de la documentation avec des exemples. Mais rien n’est pire que des exemples qui ne fonctionnent pas parce que le code a change depuis que la documentation a été écrite. Si nous exécutons cargo test avec la documentation de la fonction add_one de l’encart 14-1, nous verrons une section dans les résultats de test qui ressemble a ceci :
Doc-tests my_crate
running 1 test
test src/lib.rs - add_one (line 5) ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.27s
Maintenant, si nous modifions soit la fonction soit l’exemple de sorte que le assert_eq! dans l’exemple panique, et exécutons cargo test à nouveau, nous verrons que les tests de documentation detectent que l’exemple et le code ne sont plus synchronises !
Les commentaires d’éléments conteneurs
Le style de commentaire de documentation //! ajouté de la documentation à l’élément qui contient les commentaires plutôt qu’aux éléments qui suivent les commentaires. Nous utilisons généralement ces commentaires de documentation à l’intérieur du fichier racine de la crate (src/lib.rs par convention) ou à l’intérieur d’un module pour documenter la crate ou le module dans son ensemble.
Par exemple, pour ajouter de la documentation qui décrit l’objectif du crate my_crate qui contient la fonction add_one, nous ajoutons des commentaires de documentation qui commencent par //! au début du fichier src/lib.rs, comme montre dans l’encart 14-2.
//! # My Crate
//!
//! `my_crate` is a collection of utilities to make performing certain
//! calculations more convenient.
/// Adds one to the number given.
// --snip--
///
/// # Examples
///
/// ```
/// let arg = 5;
/// let answer = my_crate::add_one(arg);
///
/// assert_eq!(6, answer);
/// ```
pub fn add_one(x: i32) -> i32 {
x + 1
}my_crate crate as a wholeRemarquez qu’il n’y à aucun code après la derniere ligne qui commence par //!. Parce que nous avons commence les commentaires avec //! au lieu de ///, nous documentons l’élément qui contient ce commentaire plutot qu’un élément qui suit ce commentaire. Dans ce cas, cet élément est le fichier src/lib.rs, qui est la racine du crate. Ces commentaires decrivent l’ensemble du crate.
Lorsque nous exécutons cargo doc --open, ces commentaires s’afficheront sur la page d’accueil de la documentation de my_crate au-dessus de la liste des éléments publics du crate, comme montre dans la figure 14-2.
Les commentaires de documentation à l’intérieur des éléments sont utiles pour décrire les crates et les modules en particulier. Utilisez-les pour expliquer l’objectif general du conteneur afin d’aider vos utilisateurs a comprendre l’organisation du crate.
Figure 14-2 : La documentation rendue pour my_crate, incluant le commentaire decrivant le crate dans son ensemble
Exporter une API publique pratique
La structure de votre API publique est une consideration majeure lors de la publication d’un crate. Les personnes qui utilisent votre crate sont moins familieres avec la structure que vous et pourraient avoir des difficultes a trouver les éléments qu’elles veulent utiliser si votre crate à une grande hierarchie de modules.
Dans le chapitre 7, nous avons vu comment rendre des éléments publics en utilisant le mot-clé pub, et comment amener des éléments dans une portée avec le mot-clé use. Cependant, la structure qui a du sens pour vous pendant que vous developpez un crate pourrait ne pas être très pratique pour vos utilisateurs. Vous pourriez vouloir organiser vos structs dans une hierarchie contenant plusieurs niveaux, mais alors les personnes qui veulent utiliser un type que vous avez défini en profondeur dans la hierarchie pourraient avoir du mal a découvrir que ce type existe. Elles pourraient aussi être agacees de devoir écrire use my_crate::some_module::another_module::UsefulType; plutot que use my_crate::UsefulType;.
La bonne nouvelle est que si la structure n’est pas pratique pour que d’autres l’utilisent depuis une autre bibliothèque, vous n’avez pas a reorganiser votre organisation interne : au lieu de cela, vous pouvez re-exporter des éléments pour créer une structure publique différente de votre structure privee en utilisant pub use. La re-exportation prend un élément public à un emplacement et le rend public à un autre emplacement, comme s’il était défini à l’autre emplacement.
Par exemple, supposons que nous ayons crée une bibliothèque nommee art pour modeliser des concepts artistiques. Dans cette bibliothèque se trouvent deux modules : un module kinds contenant deux enums nommes PrimaryColor et SecondaryColor et un module utils contenant une fonction nommee mix, comme montre dans l’encart 14-3.
//! # Art
//!
//! A library for modeling artistic concepts.
pub mod kinds {
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
// --snip--
unimplemented!();
}
}art library with items organized into kinds and utils modulesLa figure 14-3 montre a quoi ressemblerait la page d’accueil de la documentation de ce crate générée par cargo doc.
Figure 14-3 : La page d’accueil de la documentation pour art qui liste les modules kinds et utils
Notez que les types PrimaryColor et SecondaryColor ne sont pas listes sur la page d’accueil, pas plus que la fonction mix. Nous devons cliquer sur kinds et utils pour les voir.
Un autre crate qui depend de cette bibliothèque aurait besoin d’instructions use qui amenent les éléments d’art dans la portée, en specifiant la structure de modules actuellement définie. L’encart 14-4 montre un exemple de crate qui utilise les éléments PrimaryColor et mix du crate art.
use art::kinds::PrimaryColor;
use art::utils::mix;
fn main() {
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}art crate’s items with its internal structure exportedL’auteur du code de l’encart 14-4, qui utilise le crate art, a du comprendre que PrimaryColor est dans le module kinds et que mix est dans le module utils. La structure de modules du crate art est plus pertinente pour les développeurs travaillant sur le crate art que pour ceux qui l’utilisent. La structure interne ne contient aucune information utile pour quelqu’un essayant de comprendre comment utiliser le crate art, mais cause plutot de la confusion car les développeurs qui l’utilisent doivent comprendre ou chercher et doivent spécifier les noms de modules dans les instructions use.
Pour retirer l’organisation interne de l’API publique, nous pouvons modifier le code du crate art de l’encart 14-3 pour ajouter des instructions pub use afin de re-exporter les éléments au niveau supérieur, comme montre dans l’encart 14-5.
//! # Art
//!
//! A library for modeling artistic concepts.
pub use self::kinds::PrimaryColor;
pub use self::kinds::SecondaryColor;
pub use self::utils::mix;
pub mod kinds {
// --snip--
/// The primary colors according to the RYB color model.
pub enum PrimaryColor {
Red,
Yellow,
Blue,
}
/// The secondary colors according to the RYB color model.
pub enum SecondaryColor {
Orange,
Green,
Purple,
}
}
pub mod utils {
// --snip--
use crate::kinds::*;
/// Combines two primary colors in equal amounts to create
/// a secondary color.
pub fn mix(c1: PrimaryColor, c2: PrimaryColor) -> SecondaryColor {
SecondaryColor::Orange
}
}pub use statements to re-export itemsLa documentation de l’API que cargo doc génère pour ce crate listera et liera desormais les re-exportations sur la page d’accueil, comme montre dans la figure 14-4, rendant les types PrimaryColor et SecondaryColor et la fonction mix plus faciles a trouver.
Figure 14-4 : La page d’accueil de la documentation pour art qui liste les re-exportations
Les utilisateurs du crate art peuvent toujours voir et utiliser la structure interne de l’encart 14-3 comme demontre dans l’encart 14-4, ou ils peuvent utiliser la structure plus pratique de l’encart 14-5, comme montre dans l’encart 14-6.
use art::PrimaryColor;
use art::mix;
fn main() {
// --snip--
let red = PrimaryColor::Red;
let yellow = PrimaryColor::Yellow;
mix(red, yellow);
}art crateDans les cas où il y a de nombreux modules imbriques, re-exporter les types au niveau supérieur avec pub use peut faire une différence significative dans l’experience des personnes qui utilisent le crate. Une autre utilisation courante de pub use est de re-exporter les définitions d’une dépendance dans le crate actuel pour faire de ces définitions une partie de l’API publique de votre crate.
Créer une structure d’API publique utile est plus un art qu’une science, et vous pouvez iterer pour trouver l’API qui fonctionne le mieux pour vos utilisateurs. Choisir pub use vous donne de la flexibilite dans la façon dont vous structurez votre crate en interne et decouple cette structure interne de ce que vous presentez a vos utilisateurs. Examinez le code de certains crates que vous avez installés pour voir si leur structure interne diffère de leur API publique.
Configurer un compte Crates.io
Avant de pouvoir publier des crates, vous devez créer un compte sur crates.io et obtenir un jeton d’API. Pour ce faire, visitez la page d’accueil de crates.io et connectez-vous via un compte GitHub. (Le compte GitHub est actuellement une exigence, mais le site pourrait supporter d’autres moyens de créer un compte à l’avenir.) Une fois connecté, visitez les paramètres de votre compte à https://crates.io/me/ et récupérez votre clé d’API. Ensuite, exécutez la commande cargo login et collez votre clé d’API lorsqu’elle est demandée, comme ceci{N}:
$ cargo login
abcdefghijklmnopqrstuvwxyz012345
Cette commande informera Cargo de votre jeton d’API et le stockera localement dans ~/.cargo/credentials.toml. Notez que ce jeton est un secret : ne le partagez avec personne. Si vous le partagez avec quelqu’un pour quelque raison que ce soit, vous devez le revoquer et générer un nouveau jeton sur crates.io.
Ajouter des metadonnees à un nouveau crate
Supposons que vous avez un crate que vous souhaitez publier. Avant de publier, vous devrez ajouter des metadonnees dans la section [package] du fichier Cargo.toml du crate.
Votre crate aura besoin d’un nom unique. Pendant que vous travaillez sur un crate localement, vous pouvez nommer le crate comme vous le souhaitez. Cependant, les noms de crates sur crates.io sont attribues selon le principe du premier arrive, premier servi. Une fois qu’un nom de crate est pris, personne d’autre ne peut publier un crate avec ce nom. Avant de tenter de publier un crate, recherchez le nom que vous souhaitez utiliser. Si le nom a déjà été utilise, vous devrez trouver un autre nom et modifier le champ name dans le fichier Cargo.toml sous la section [package] pour utiliser le nouveau nom pour la publication, comme ceci :
Fichier : Cargo.toml
[package]
name = "guessing_game"
Même si vous avez choisi un nom unique, lorsque vous exécutez cargo publish pour publier le crate à ce stade, vous obtiendrez un avertissement puis une erreur :
$ cargo publish
Updating crates.io index
warning: manifest has no description, license, license-file, documentation, homepage or repository.
See https://doc.rust-lang.org/cargo/reference/manifest.html#package-metadata for more info.
--snip--
error: failed to publish to registry at https://crates.io
Caused by:
the remote server responded with an error (status 400 Bad Request): missing or empty metadata fields: description, license. Please see https://doc.rust-lang.org/cargo/reference/manifest.html for more information on configuring these fields
Cela entraine une erreur car il vous manque des informations cruciales : une description et une licence sont requises pour que les gens sachent ce que fait votre crate et sous quelles conditions ils peuvent l’utiliser. Dans Cargo.toml, ajoutez une description d’une où deux phrases, car elle apparaîtra avec votre crate dans les résultats de recherche. Pour le champ license, vous devez donner une valeur d’identifiant de licence. Le [Software Package Data Exchange (SPDX) de la Linux Foundation][spdx] liste les identifiants que vous pouvez utiliser pour cette valeur. Par exemple, pour spécifier que vous avez licencie votre crate sous la licence MIT, ajoutez l’identifiant MIT :
Fichier : Cargo.toml
[package]
name = "guessing_game"
license = "MIT"
Si vous souhaitez utiliser une licence qui n’apparaît pas dans le SPDX, vous devez placer le texte de cette licence dans un fichier, inclure le fichier dans votre projet, puis utiliser license-file pour spécifier le nom de ce fichier au lieu d’utiliser la clé license.
Les conseils sur la licence appropriee pour votre projet depassent le cadre de ce livre. De nombreuses personnes dans la communauté Rust licencient leurs projets de la même maniere que Rust en utilisant une double licence MIT OR Apache-2.0. Cette pratique demontre que vous pouvez également spécifier plusieurs identifiants de licence séparés par OR pour avoir plusieurs licences pour votre projet.
Avec un nom unique, la version, votre description et une licence ajoutée, le fichier Cargo.toml d’un projet prêt a être publié pourrait ressembler a ceci :
Fichier : Cargo.toml
[package]
name = "guessing_game"
version = "0.1.0"
edition = "2024"
description = "A fun game where you guess what number the computer has chosen."
license = "MIT OR Apache-2.0"
[dependencies]
La documentation de Cargo décrit d’autres metadonnees que vous pouvez spécifier pour vous assurer que d’autres puissent découvrir et utiliser votre crate plus facilement.
Publier sur Crates.io
Maintenant que vous avez crée un compte, sauvegarde votre jeton d’API, choisi un nom pour votre crate et spécifié les metadonnees requises, vous etes prêt a publier ! Publier un crate televerse une version spécifique sur crates.io pour que d’autres puissent l’utiliser.
Soyez prudent, car une publication est permanente. La version ne peut jamais être ecrasee, et le code ne peut pas être supprime sauf dans certaines circonstances. Un objectif majeur de Crates.io est d’agir comme une archive permanente de code afin que les compilations de tous les projets qui dependent de crates de crates.io continuent de fonctionner. Permettre la suppression de versions rendrait impossible la realisation de cet objectif. Cependant, il n’y a pas de limite au nombre de versions de crate que vous pouvez publier.
Exécutez à nouveau la commande cargo publish. Elle devrait réussir maintenant :
$ cargo publish
Updating crates.io index
Packaging guessing_game v0.1.0 (file:///projects/guessing_game)
Packaged 6 files, 1.2KiB (895.0B compressed)
Verifying guessing_game v0.1.0 (file:///projects/guessing_game)
Compiling guessing_game v0.1.0
(file:///projects/guessing_game/target/package/guessing_game-0.1.0)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.19s
Uploading guessing_game v0.1.0 (file:///projects/guessing_game)
Uploaded guessing_game v0.1.0 to registry `crates-io`
note: waiting for `guessing_game v0.1.0` to be available at registry
`crates-io`.
You may press ctrl-c to skip waiting; the crate should be available shortly.
Published guessing_game v0.1.0 at registry `crates-io`
Felicitations ! Vous avez maintenant partage votre code avec la communauté Rust, et n’importe qui peut facilement ajouter votre crate comme dépendance de son projet.
Publier une nouvelle version d’un crate existant
Lorsque vous avez apporte des modifications à votre crate et que vous etes prêt a publier une nouvelle version, vous modifiez la valeur version spécifiée dans votre fichier Cargo.toml et republiez. Utilisez les [règles de versionnage sémantique][semver] pour decider quel est le numéro de version suivant approprie, en fonction des types de modifications que vous avez apportees. Ensuite, exécutez cargo publish pour televerser la nouvelle version.
Deprecier des versions de Crates.io
Bien que vous ne puissiez pas supprimer les versions précédentes d’un crate, vous pouvez empecher tout futur projet de les ajouter comme nouvelle dépendance. Cela est utile lorsqu’une version de crate est cassee pour une raison ou une autre. Dans de telles situations, Cargo supporté le retrait (yank) d’une version de crate.
Retirer (yank) une version empeche les nouveaux projets de dependre de cette version tout en permettant à tous les projets existants qui en dependent de continuer. Essentiellement, un yank signifie que tous les projets avec un Cargo.lock ne seront pas casses, et que tout futur fichier Cargo.lock génère n’utilisera pas la version retiree.
Pour retirer une version d’un crate, dans le repertoire du crate que vous avez precedemment publié, exécutez cargo yank et specifiez quelle version vous souhaitez retirer. Par exemple, si nous avons publié un crate nomme guessing_game version 1.0.1 et que nous voulons le retirer, nous executerions la commande suivante dans le repertoire du projet guessing_game :
$ cargo yank --vers 1.0.1
Updating crates.io index
Yank guessing_game@1.0.1
En ajoutant --undo à la commande, vous pouvez également annuler un retrait et permettre aux projets de dependre à nouveau d’une version :
$ cargo yank --vers 1.0.1 --undo
Updating crates.io index
Unyank guessing_game@1.0.1
Un retrait ne supprime pas de code. Il ne peut pas, par exemple, supprimer des secrets accidentellement televerses. Si cela arrive, vous devez reinitialiser ces secrets immediatement.
Les espaces de travail Cargo
Les espaces de travail Cargo
Dans le chapitre 12, nous avons construit un paquet qui incluait un crate binaire et un crate de bibliothèque. Au fur et a mesure que votre projet se developpe, vous pourriez constater que le crate de bibliothèque continue de grossir et que vous souhaitez diviser votre paquet en plusieurs crates de bibliothèque. Cargo offre une fonctionnalité appelée workspaces (espaces de travail) qui peut aider a gérer plusieurs paquets lies developpes en tandem.
Créer un espace de travail
Un workspace est un ensemble de paquets qui partagent le même Cargo.lock et le même repertoire de sortie. Créons un projet utilisant un workspace – nous utiliserons du code trivial pour pouvoir nous concentrer sur la structure du workspace. Il y à plusieurs façons de structurer un workspace, donc nous n’en montrerons qu’une courante. Nous aurons un workspace contenant un binaire et deux bibliothèques. Le binaire, qui fournira la fonctionnalité principale, dependra des deux bibliothèques. Une bibliothèque fournira une fonction add_one et l’autre bibliothèque une fonction add_two. Ces trois crates feront partie du même workspace. Nous commencerons par créer un nouveau repertoire pour le workspace :
$ mkdir add
$ cd add
Ensuite, dans le repertoire add, nous créons le fichier Cargo.toml qui configurera l’ensemble du workspace. Ce fichier n’aura pas de section [package]. A la place, il commencera par une section [workspace] qui nous permettra d’ajouter des membres au workspace. Nous prenons également soin d’utiliser la version la plus récente de l’algorithme de resolution de Cargo dans notre workspace en definissant la valeur resolver a "3" :
Fichier : Cargo.toml
[workspace]
resolver = "3"
Ensuite, nous allons créer le crate binaire adder en exécutant cargo new dans le repertoire add :
$ cargo new adder
Created binary (application) `adder` package
Adding `adder` as member of workspace at `file:///projects/add`
Exécuter cargo new à l’intérieur d’un workspace ajouté également automatiquement le paquet nouvellement crée à la clé members dans la définition [workspace] du Cargo.toml du workspace, comme ceci : toml {{#include ../listings/ch14-more-about-cargo/output-only-01-adder-crate/add/Cargo.toml}}
[workspace]
resolver = "3"
members = ["adder"]
A ce stade, nous pouvons compiler le workspace en exécutant cargo build. Les fichiers dans votre repertoire add devraient ressembler a ceci :
├── Cargo.lock
├── Cargo.toml
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Le workspace à un seul repertoire target au niveau supérieur dans lequel les artefacts compilés seront places ; le paquet adder n’a pas son propre repertoire target. Même si nous exécutons cargo build depuis l’intérieur du repertoire adder, les artefacts compilés finiraient quand même dans add/target plutot que dans add/adder/target. Cargo structure le repertoire target dans un workspace de cette façon parce que les crates dans un workspace sont destines a dependre les uns des autres. Si chaque crate avait son propre repertoire target, chaque crate devrait recompiler chacun des autres crates du workspace pour placer les artefacts dans son propre repertoire target. En partageant un seul repertoire target, les crates peuvent éviter les recompilations inutiles.
Créer le deuxième paquet dans le workspace
Ensuite, créons un autre paquet membre dans le workspace et appelons-le add_one. Generez un nouveau crate de bibliothèque nomme add_one :
$ cargo new add_one --lib
Created library `add_one` package
Adding `add_one` as member of workspace at `file:///projects/add`
Le Cargo.toml de niveau supérieur inclura maintenant le chemin add_one dans la liste members :
Fichier : Cargo.toml
[workspace]
resolver = "3"
members = ["adder", "add_one"]
Votre repertoire add devrait maintenant avoir ces repertoires et fichiers :
├── Cargo.lock
├── Cargo.toml
├── add_one
│ ├── Cargo.toml
│ └── src
│ └── lib.rs
├── adder
│ ├── Cargo.toml
│ └── src
│ └── main.rs
└── target
Dans le fichier add_one/src/lib.rs, ajoutons une fonction add_one :
Fichier : add_one/src/lib.rs rust,noplayground {{#rustdoc_include ../listings/ch14-more-about-cargo/no-listing-04-workspace-with-tests/add/add_one/src/lib.rs}}
pub fn add_one(x: i32) -> i32 {
x + 1
}Maintenant, nous pouvons faire dependre le paquet adder avec notre binaire du paquet add_one qui contient notre bibliothèque. D’abord, nous devrons ajouter une dépendance de chemin vers add_one dans adder/Cargo.toml.
Fichier : adder/Cargo.toml toml {{#include ../listings/ch14-more-about-cargo/no-listing-02-workspace-with-two-crates/add/adder/Cargo.toml:6:7}}
[dependencies]
add_one = { path = "../add_one" }
Cargo ne suppose pas que les crates dans un workspace dependront les uns des autres, nous devons donc être explicites sur les relations de dépendance.
Ensuite, utilisons la fonction add_one (du crate add_one) dans le crate adder. Ouvrez le fichier adder/src/main.rs et modifiez la fonction main pour appeler la fonction add_one, comme dans l’encart 14-7.
fn main() {
let num = 10;
println!("Hello, world! {num} plus one is {}!", add_one::add_one(num));
}add_one library crate from the adder crateCompilons le workspace en exécutant cargo build dans le repertoire add de niveau supérieur !
$ cargo build
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.22s
Pour exécuter le crate binaire depuis le repertoire add, nous pouvons spécifier quel paquet dans le workspace nous voulons exécuter en utilisant l’argument -p et le nom du paquet avec cargo run :
$ cargo run -p adder
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.00s
Running `target/debug/adder`
Hello, world! 10 plus one is 11!
Cela exécute le code dans adder/src/main.rs, qui depend du crate add_one.
Dependre d’un paquet externe
Remarquez que le workspace n’a qu’un seul fichier Cargo.lock au niveau supérieur, plutot qu’un Cargo.lock dans le repertoire de chaque crate. Cela garantit que tous les crates utilisent la même version de toutes les dépendances. Si nous ajoutons le paquet rand aux fichiers adder/Cargo.toml et add_one/Cargo.toml, Cargo resoudra les deux vers une seule version de rand et l’enregistrera dans l’unique Cargo.lock. Faire en sorte que tous les crates du workspace utilisent les mêmes dépendances signifie que les crates seront toujours compatibles entre eux. Ajoutons le crate rand à la section [dependencies] dans le fichier add_one/Cargo.toml afin de pouvoir utiliser le crate rand dans le crate add_one :
Fichier : add_one/Cargo.toml toml {{#include ../listings/ch14-more-about-cargo/no-listing-03-workspace-with-external-dependency/add/add_one/Cargo.toml:6:7}}
[dependencies]
rand = "0.8.5"
Nous pouvons maintenant ajouter use rand; au fichier add_one/src/lib.rs, et compiler l’ensemble du workspace en exécutant cargo build dans le repertoire add integrera et compilera le crate rand. Nous obtiendrons un avertissement car nous ne faisons pas référence au rand que nous avons amene dans la portée :
$ cargo build
Updating crates.io index
Downloaded rand v0.8.5
--snip--
Compiling rand v0.8.5
Compiling add_one v0.1.0 (file:///projects/add/add_one)
warning: unused import: `rand`
--> add_one/src/lib.rs:1:5
|
1 | use rand;
| ^^^^
|
= note: `#[warn(unused_imports)]` on by default
warning: `add_one` (lib) generated 1 warning (run `cargo fix --lib -p add_one` to apply 1 suggestion)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.95s
Le Cargo.lock de niveau supérieur contient maintenant des informations sur la dépendance d’add_one envers rand. Cependant, même si rand est utilise quelque part dans le workspace, nous ne pouvons pas l’utiliser dans d’autres crates du workspace a moins d’ajouter également rand à leurs fichiers Cargo.toml. Par exemple, si nous ajoutons use rand; au fichier adder/src/main.rs pour le paquet adder, nous obtiendrons une erreur :
$ cargo build
--snip--
Compiling adder v0.1.0 (file:///projects/add/adder)
error[E0432]: unresolved import `rand`
--> adder/src/main.rs:2:5
|
2 | use rand;
| ^^^^ no external crate `rand`
Pour corriger cela, editez le fichier Cargo.toml du paquet adder et indiquez que rand est également une dépendance pour celui-ci. Compiler le paquet adder ajoutera rand à la liste des dépendances pour adder dans Cargo.lock, mais aucune copie supplementaire de rand ne sera téléchargée. Cargo s’assurera que chaque crate dans chaque paquet du workspace utilisant le paquet rand utilisera la même version tant qu’ils specifient des versions compatibles de rand, nous faisant economiser de l’espace et garantissant que les crates du workspace seront compatibles entre eux.
Si les crates du workspace specifient des versions incompatibles de la même dépendance, Cargo resoudra chacune d’entre elles mais essaiera quand même de résoudre le moins de versions possible.
Ajouter un test à un workspace
Pour une autre amélioration, ajoutons un test de la fonction add_one::add_one dans le crate add_one :
Fichier : add_one/src/lib.rs rust,noplayground {{#rustdoc_include ../listings/ch14-more-about-cargo/no-listing-04-workspace-with-tests/add/add_one/src/lib.rs}}
pub fn add_one(x: i32) -> i32 {
x + 1
}
#[cfg(test)]
mod tests {
use super::*;
#[test]
fn it_works() {
assert_eq!(3, add_one(2));
}
}Maintenant, exécutez cargo test dans le repertoire add de niveau supérieur. Exécuter cargo test dans un workspace structure comme celui-ci exécutera les tests pour tous les crates du workspace :
$ cargo test
Compiling add_one v0.1.0 (file:///projects/add/add_one)
Compiling adder v0.1.0 (file:///projects/add/adder)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.20s
Running unittests src/lib.rs (target/debug/deps/add_one-93c49ee75dc46543)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Running unittests src/main.rs (target/debug/deps/adder-3a47283c568d2b6a)
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
La première section de la sortie montre que le test it_works dans le crate add_one a réussi. La section suivante montre que zero test a été trouve dans le crate adder, puis la derniere section montre que zero test de documentation a été trouve dans le crate add_one.
Nous pouvons également exécuter les tests pour un crate particulier dans un workspace depuis le repertoire de niveau supérieur en utilisant le drapeau -p et en specifiant le nom du crate que nous voulons tester :
$ cargo test -p add_one
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.00s
Running unittests src/lib.rs (target/debug/deps/add_one-93c49ee75dc46543)
running 1 test
test tests::it_works ... ok
test result: ok. 1 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Doc-tests add_one
running 0 tests
test result: ok. 0 passed; 0 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
Cette sortie montre que cargo test n’a exécute que les tests du crate add_one et n’a pas exécute les tests du crate adder.
Si vous publiez les crates du workspace sur crates.io, chaque crate du workspace devra être publiée séparément. Comme pour cargo test, nous pouvons publier une crate particulière dans notre workspace en utilisant le drapeau -p et en spécifiant le nom de la crate que nous voulons publier.
Pour vous exercer davantage, ajoutez un crate add_two à ce workspace de la même maniere que le crate add_one !
Au fur et a mesure que votre projet grandit, envisagez d’utiliser un workspace : il vous permet de travailler avec des composants plus petits et plus faciles a comprendre plutot qu’un seul gros bloc de code. De plus, garder les crates dans un workspace peut faciliter la coordination entre les crates s’ils sont souvent modifiés en même temps.
Installer des binaires avec cargo install
Installer des binaires avec cargo install
La commande cargo install vous permet d’installer et d’utiliser des crates binaires localement. Cela n’est pas destine a remplacer les paquets système ; c’est un moyen pratique pour les développeurs Rust d’installer des outils que d’autres ont partages sur crates.io. Notez que vous ne pouvez installer que des paquets qui ont des cibles binaires. Une cible binaire est le programme exécutable qui est crée si le crate possède un fichier src/main.rs ou un autre fichier spécifié comme binaire, par opposition à une cible de bibliothèque qui n’est pas exécutable en soi mais qui est adaptee pour être incluse dans d’autres programmes. En general, les crates contiennent des informations dans le fichier README indiquant si un crate est une bibliothèque, possède une cible binaire, ou les deux.
Tous les binaires installés avec cargo install sont stockés dans le dossier bin du repertoire racine d’installation. Si vous avez installé Rust avec rustup.rs et que vous n’avez aucune configuration personnalisee, ce repertoire sera $HOME/.cargo/bin. Assurez-vous que ce repertoire est dans votre $PATH pour pouvoir exécuter les programmes que vous avez installés avec cargo install.
Par exemple, dans le chapitre 12, nous avons mentionné qu’il existe une implémentation en Rust de l’outil grep appelée ripgrep pour rechercher dans les fichiers. Pour installer ripgrep, nous pouvons exécuter la commande suivante :
$ cargo install ripgrep
Updating crates.io index
Downloaded ripgrep v14.1.1
Downloaded 1 crate (213.6 KB) in 0.40s
Installing ripgrep v14.1.1
--snip--
Compiling grep v0.3.2
Finished `release` profile [optimized + debuginfo] target(s) in 6.73s
Installing ~/.cargo/bin/rg
Installed package `ripgrep v14.1.1` (executable `rg`)
L’avant-derniere ligne de la sortie indique l’emplacement et le nom du binaire installé, qui dans le cas de ripgrep est rg. Tant que le repertoire d’installation est dans votre $PATH, comme mentionné precedemment, vous pouvez alors exécuter rg --help et commencer à utiliser un outil plus rapide, écrit en Rust, pour rechercher dans les fichiers !
Étendre Cargo avec des commandes personnalisées
Étendre Cargo avec des commandes personnalisées
Cargo est concu de maniere a pouvoir être etendu avec de nouvelles sous-commandes sans avoir à le modifier. Si un binaire dans votre $PATH est nomme cargo-something, vous pouvez l’exécuter comme s’il s’agissait d’une sous-commande de Cargo en exécutant cargo something. Les commandes personnalisees comme celle-ci sont également listees lorsque vous exécutez cargo --list. Pouvoir utiliser cargo install pour installer des extensions puis les exécuter exactement comme les outils intégrés de Cargo est un avantage extremement pratique de la conception de Cargo !
Résumé
Le partage de code avec Cargo et crates.io fait partie de ce qui rend l’écosystème Rust utile pour de nombreuses tâches différentes. La bibliothèque standard de Rust est petite et stable, mais les crates sont faciles à partager, à utiliser et à améliorer selon un calendrier différent de celui du langage. N’hésitez pas à partager sur crates.io le code qui vous est utile ; il sera probablement aussi utile à quelqu’un d’autre !
Les pointeurs intelligents
Un pointeur est un concept général pour une variable qui contient une adresse en mémoire. Cette adresse fait référence, ou “pointe vers”, d’autres données. Le type de pointeur le plus courant en Rust est une référence, que vous avez découverte au chapitre 4. Les références sont indiquées par le symbole & et empruntent la valeur vers laquelle elles pointent. Elles n’ont pas de capacités particulières autres que de faire référence à des données, et elles n’ont aucun surcoût.
Les pointeurs intelligents (smart pointers), en revanche, sont des structures de données qui agissent comme un pointeur mais possèdent également des métadonnées et des capacités supplémentaires. Le concept de pointeurs intelligents n’est pas propre à Rust : les pointeurs intelligents sont apparus en C++ et existent également dans d’autres langages. Rust dispose d’une variété de pointeurs intelligents définis dans la bibliothèque standard qui fournissent des fonctionnalités au-delà de celles offertes par les références. Pour explorer le concept général, nous examinerons quelques exemples différents de pointeurs intelligents, notamment un type de pointeur intelligent à comptage de références. Ce pointeur vous permet de donner plusieurs propriétaires à des données en suivant le nombre de propriétaires et, lorsqu’il n’en reste plus aucun, en nettoyant les données.
En Rust, avec son concept de possession et d’emprunt, il existe une différence supplémentaire entre les références et les pointeurs intelligents : alors que les références ne font qu’emprunter des données, dans de nombreux cas les pointeurs intelligents possèdent les données vers lesquelles ils pointent.
Les pointeurs intelligents sont généralement implémentés à l’aide de structs. Contrairement à une struct ordinaire, les pointeurs intelligents implémentent les traits Deref et Drop. Le trait Deref permet à une instance de la struct du pointeur intelligent de se comporter comme une référence afin que vous puissiez écrire du code qui fonctionne avec des références ou des pointeurs intelligents. Le trait Drop vous permet de personnaliser le code qui s’exécute lorsqu’une instance du pointeur intelligent sort de la portée. Dans ce chapitre, nous aborderons ces deux traits et montrerons pourquoi ils sont importants pour les pointeurs intelligents.
Étant donné que le patron de pointeur intelligent est un patron de conception général fréquemment utilisé en Rust, ce chapitre ne couvrira pas tous les pointeurs intelligents existants. De nombreuses bibliothèques ont leurs propres pointeurs intelligents, et vous pouvez même écrire les vôtres. Nous couvrirons les pointeurs intelligents les plus courants de la bibliothèque standard :
Box<T>, pour allouer des valeurs sur le tasRc<T>, un type à comptage de références qui permet la possession multipleRef<T>etRefMut<T>, accessibles viaRefCell<T>, un type qui applique les règles d’emprunt à l’exécution plutôt qu’à la compilation
De plus, nous couvrirons le patron de mutabilité intérieure où un type immuable expose une API pour modifier une valeur intérieure. Nous aborderons également les cycles de références : comment ils peuvent provoquer des fuites de mémoire et comment les éviter.
Plongeons-nous dans le sujet !
Utiliser Box<T> pour pointer vers des données sur le tas
Utiliser Box<T> pour pointer vers des données sur le tas
Le pointeur intelligent le plus simple est une boîte (box), dont le type s’écrit Box<T>. Les boîtes vous permettent de stocker des données sur le tas plutôt que sur la pile. Ce qui reste sur la pile est le pointeur vers les données du tas. Reportez-vous au chapitre 4 pour revoir la différence entre la pile et le tas.
Les boîtes n’ont pas de surcoût en performance, hormis le fait de stocker leurs données sur le tas au lieu de la pile. Mais elles n’ont pas non plus beaucoup de capacités supplémentaires. Vous les utiliserez le plus souvent dans ces situations : - Quand vous avez un type dont la taille ne peut pas être connue à la compilation, et que vous voulez utiliser une valeur de ce type dans un contexte qui nécessite une taille exacte - Quand vous avez une grande quantité de données, et que vous voulez transférer la possession tout en vous assurant que les données ne seront pas copiées - Quand vous voulez posséder une valeur, et que vous vous souciez uniquement du fait qu’elle implémente un trait particulier plutôt que d’être d’un type spécifique
- Quand vous avez un type dont la taille ne peut pas être connue à la compilation, et que vous voulez utiliser une valeur de ce type dans un contexte qui nécessite une taille exacte
- Quand vous avez une grande quantité de données, et que vous voulez transférer la possession tout en vous assurant que les données ne seront pas copiées
- Quand vous voulez posséder une valeur, et que vous vous souciez uniquement du fait qu’elle implémente un trait particulier plutôt que d’être d’un type spécifique
Nous démontrerons la première situation dans « Permettre les types récursifs avec les boîtes ». Dans le deuxième cas, transférer la possession d’une grande quantité de données peut prendre beaucoup de temps car les données sont copiées sur la pile. Pour améliorer les performances dans cette situation, nous pouvons stocker la grande quantité de données sur le tas dans une boîte. Ainsi, seule la petite quantité de données du pointeur est copiée sur la pile, tandis que les données référencées restent au même endroit sur le tas. Le troisième cas est connu sous le nom d’objet trait, et « Utiliser les objets trait pour abstraire des comportements communs » au chapitre 18 est consacré exclusivement à ce sujet. Donc, ce que vous apprenez ici vous sera utile à nouveau au chapitre 18{N}!
Stocker des données sur le tas
Avant de discuter du cas d’utilisation de Box<T> pour le stockage sur le tas, nous couvrirons la syntaxe et comment interagir avec les valeurs stockées dans un Box<T>.
L’encart 15-1 montre comment utiliser une boîte pour stocker une valeur i32 sur le tas.
fn main() {
let b = Box::new(5);
println!("b = {b}");
}i32 value on the heap using a boxNous définissons la variable b avec la valeur d’un Box qui pointe vers la valeur 5, qui est allouée sur le tas. Ce programme affichera b = 5 ; dans ce cas, nous pouvons accéder aux données dans la boîte de manière similaire à ce que nous ferions si ces données étaient sur la pile. Comme toute valeur possédée, quand une boîte sort de la portée, comme b le fait à la fin de main, elle sera désallouée. La désallocation se produit à la fois pour la boîte (stockée sur la pile) et les données vers lesquelles elle pointe (stockées sur le tas).
Placer une seule valeur sur le tas n’est pas très utile, donc vous n’utiliserez pas les boîtes seules de cette manière très souvent. Avoir des valeurs comme un seul i32 sur la pile, où elles sont stockées par défaut, est plus approprié dans la majorité des situations. Examinons un cas où les boîtes nous permettent de définir des types que nous ne pourrions pas définir sans elles.
Permettre les types récursifs avec les boîtes
Une valeur d’un type récursif peut contenir une autre valeur du même type comme partie d’elle-même. Les types récursifs posent un problème car Rust a besoin de savoir à la compilation combien d’espace un type occupe. Cependant, l’imbrication de valeurs de types récursifs pourrait théoriquement continuer à l’infini, donc Rust ne peut pas savoir combien d’espace la valeur nécessite. Comme les boîtes ont une taille connue, nous pouvons permettre les types récursifs en insérant une boîte dans la définition du type récursif.
Comme exemple de type récursif, explorons la liste cons. C’est un type de données couramment trouvé dans les langages de programmation fonctionnelle. Le type de liste cons que nous définirons est simple à l’exception de la récursion ; par conséquent, les concepts de l’exemple avec lequel nous travaillerons seront utiles chaque fois que vous rencontrerez des situations plus complexes impliquant des types récursifs.
Comprendre la liste cons
Une liste cons est une structure de données qui provient du langage de programmation Lisp et de ses dialectes, elle est composée de paires imbriquées, et c’est la version Lisp d’une liste chaînée. Son nom vient de la fonction cons (abréviation de construct function, fonction de construction) en Lisp qui construit une nouvelle paire à partir de ses deux arguments. En appelant cons sur une paire composée d’une valeur et d’une autre paire, nous pouvons construire des listes cons composées de paires récursives.
Par exemple, voici une représentation en pseudo-code d’une liste cons contenant la liste 1, 2, 3 avec chaque paire entre parenthèses :
(1, (2, (3, Nil)))
Chaque élément d’une liste cons contient deux éléments : la valeur de l’élément courant et celle de l’élément suivant. Le dernier élément de la liste ne contient qu’une valeur appelée Nil sans élément suivant. Une liste cons est produite en appelant récursivement la fonction cons. Le nom canonique pour désigner le cas de base de la récursion est Nil. Notez que ce n’est pas la même chose que le concept de “null” ou “nil” abordé au chapitre 6, qui est une valeur invalide ou absente.
La liste cons n’est pas une structure de données couramment utilisée en Rust. La plupart du temps, quand vous avez une liste d’éléments en Rust, Vec<T> est un meilleur choix. D’autres types de données récursifs plus complexes sont utiles dans diverses situations, mais en commençant par la liste cons dans ce chapitre, nous pouvons explorer comment les boîtes nous permettent de définir un type de données récursif sans trop de distraction.
L’encart 15-2 contient une définition d’enum pour une liste cons. Notez que ce code ne compilera pas encore, car le type List n’a pas de taille connue, ce que nous allons démontrer.
enum List {
Cons(i32, List),
Nil,
}
fn main() {}i32 valuesRemarque : nous implémentons une liste cons qui ne contient que des valeurs
i32pour les besoins de cet exemple. Nous aurions pu l’implémenter avec des génériques, comme nous l’avons vu au chapitre 10, pour définir un type de liste cons pouvant stocker des valeurs de n’importe quel type.
Utiliser le type List pour stocker la liste 1, 2, 3 ressemblerait au code de l’encart 15-3.
enum List {
Cons(i32, List),
Nil,
}
// --snip--
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Cons(2, Cons(3, Nil)));
}List enum to store the list 1, 2, 3La première valeur Cons contient 1 et une autre valeur List. Cette valeur List est une autre valeur Cons qui contient 2 et une autre valeur List. Cette valeur List est encore une autre valeur Cons qui contient 3 et une valeur List, qui est finalement Nil, la variante non récursive qui signale la fin de la liste.
Si nous essayons de compiler le code de l’encart 15-3, nous obtenons l’erreur montrée dans l’encart 15-4.
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0072]: recursive type `List` has infinite size
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
2 | Cons(i32, List),
| ---- recursive without indirection
|
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
error[E0391]: cycle detected when computing when `List` needs drop
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^
|
= note: ...which immediately requires computing when `List` needs drop again
= note: cycle used when computing whether `List` needs drop
= note: see https://rustc-dev-guide.rust-lang.org/overview.html#queries and https://rustc-dev-guide.rust-lang.org/query.html for more information
Some errors have detailed explanations: E0072, E0391.
For more information about an error, try `rustc --explain E0072`.
error: could not compile `cons-list` (bin "cons-list") due to 2 previous errors
L’erreur indique que ce type “à une taille infinie”. La raison est que nous avons défini List avec une variante qui est récursive : elle contient directement une autre valeur d’elle-même. En conséquence, Rust ne peut pas déterminer combien d’espace il a besoin pour stocker une valeur List. Analysons pourquoi nous obtenons cette erreur. D’abord, nous verrons comment Rust décide de l’espace nécessaire pour stocker une valeur d’un type non récursif.
Calculer la taille d’un type non récursif
Rappelez-vous l’enum Message que nous avons définie dans l’encart 6-2 lorsque nous avons abordé les définitions d’enum au chapitre 6 : rust {{#rustdoc_include ../listings/ch06-enums-and-pattern-matching/listing-06-02/src/main.rs:here}}
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {}Pour déterminer combien d’espace allouer pour une valeur Message, Rust parcourt chacune des variantes pour voir laquelle nécessite le plus d’espace. Rust constate que Message::Quit n’a besoin d’aucun espace, Message::Move a besoin de suffisamment d’espace pour stocker deux valeurs i32, et ainsi de suite. Comme une seule variante sera utilisée, l’espace maximum dont une valeur Message aura besoin est l’espace nécessaire pour stocker la plus grande de ses variantes.
Comparez cela avec ce qui se passe lorsque Rust essaie de déterminer combien d’espace un type récursif comme l’enum List de l’encart 15-2 nécessite. Le compilateur commence par examiner la variante Cons, qui contient une valeur de type i32 et une valeur de type List. Par conséquent, Cons a besoin d’un espace égal à la taille d’un i32 plus la taille d’un List. Pour déterminer combien de mémoire le type List nécessite, le compilateur examine les variantes, en commençant par la variante Cons. La variante Cons contient une valeur de type i32 et une valeur de type List, et ce processus continue à l’infini, comme illustré dans la figure 15-1.

Figure 15-1 : Une List infinie composée de variantes Cons infinies
Obtenir un type récursif avec une taille connue
Comme Rust ne peut pas déterminer combien d’espace allouer pour les types définis récursivement, le compilateur donne une erreur avec cette suggestion utile :
help: insert some indirection (e.g., a `Box`, `Rc`, or `&`) to break the cycle
|
2 | Cons(i32, Box<List>),
| ++++ +
Dans cette suggestion, indirection signifie qu’au lieu de stocker une valeur directement, nous devrions modifier la structure de données pour stocker la valeur indirectement en stockant un pointeur vers la valeur à la place.
Comme un Box<T> est un pointeur, Rust sait toujours combien d’espace un Box<T> nécessite : la taille d’un pointeur ne change pas en fonction de la quantité de données vers laquelle il pointe. Cela signifie que nous pouvons mettre un Box<T> dans la variante Cons au lieu d’une autre valeur List directement. Le Box<T> pointera vers la prochaine valeur List qui sera sur le tas plutôt qu’à l’intérieur de la variante Cons. Conceptuellement, nous avons toujours une liste, créée avec des listes contenant d’autres listes, mais cette implémentation ressemble désormais davantage à placer les éléments les uns à côté des autres plutôt que les uns dans les autres.
Nous pouvons modifier la définition de l’enum List de l’encart 15-2 et l’utilisation de List de l’encart 15-3 pour obtenir le code de l’encart 15-5, qui compilera.
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let list = Cons(1, Box::new(Cons(2, Box::new(Cons(3, Box::new(Nil))))));
}List that uses Box<T> in order to have a known sizeLa variante Cons a besoin de la taille d’un i32 plus l’espace pour stocker les données du pointeur de la boîte. La variante Nil ne stocké aucune valeur, donc elle nécessite moins d’espace sur la pile que la variante Cons. Nous savons maintenant que toute valeur List occupera la taille d’un i32 plus la taille des données du pointeur d’une boîte. En utilisant une boîte, nous avons brisé la chaîne récursive infinie, de sorte que le compilateur peut déterminer la taille nécessaire pour stocker une valeur List. La figure 15-2 montre à quoi ressemble désormais la variante Cons.

Figure 15-2 : Une List qui n’est pas de taille infinie, car Cons contient un Box
Les boîtes ne fournissent que l’indirection et l’allocation sur le tas ; elles n’ont pas d’autres capacités spéciales, comme celles que nous verrons avec les autres types de pointeurs intelligents. Elles n’ont pas non plus le surcoût en performance que ces capacités spéciales entraînent, ce qui les rend utiles dans des cas comme la liste cons où l’indirection est la seule fonctionnalité dont nous avons besoin. Nous examinerons d’autres cas d’utilisation des boîtes au chapitre 18.
Le type Box<T> est un pointeur intelligent car il implémente le trait Deref, qui permet aux valeurs Box<T> d’être traitées comme des références. Quand une valeur Box<T> sort de la portée, les données du tas vers lesquelles la boîte pointe sont également nettoyées grâce à l’implémentation du trait Drop. Ces deux traits seront encore plus importants pour les fonctionnalités fournies par les autres types de pointeurs intelligents que nous aborderons dans le reste de ce chapitre. Explorons ces deux traits plus en détail.
Traiter les pointeurs intelligents comme des références classiques
Traiter les pointeurs intelligents comme des références classiques
Implémenter le trait Deref vous permet de personnaliser le comportement de l’opérateur de déréférencement * (à ne pas confondre avec l’opérateur de multiplication ou le glob). En implémentant Deref de manière à ce qu’un pointeur intelligent puisse être traité comme une référence classique, vous pouvez écrire du code qui opère sur des références et utiliser ce code aussi avec des pointeurs intelligents.
Commençons par voir comment l’opérateur de déréférencement fonctionne avec des références classiques. Ensuite, nous essaierons de définir un type personnalisé qui se comporte comme Box<T> et nous verrons pourquoi l’opérateur de déréférencement ne fonctionne pas comme une référence sur notre type nouvellement défini. Nous explorerons comment l’implémentation du trait Deref permet aux pointeurs intelligents de fonctionner de manière similaire aux références. Puis, nous examinerons la fonctionnalité de coercition de déréférencement de Rust et comment elle nous permet de travailler avec des références ou des pointeurs intelligents.
Suivre la référence jusqu’à la valeur
Une référence classique est un type de pointeur, et une façon de penser à un pointeur est comme une flèche vers une valeur stockée ailleurs. Dans l’encart 15-6, nous créons une référence vers une valeur i32 puis utilisons l’opérateur de déréférencement pour suivre la référence jusqu’à la valeur.
fn main() {
let x = 5;
let y = &x;
assert_eq!(5, x);
assert_eq!(5, *y);
}i32 valueLa variable x contient une valeur i32 de 5. Nous définissons y égal à une référence vers x. Nous pouvons vérifier que x est égal à 5. Cependant, si nous voulons faire une assertion sur la valeur dans y, nous devons utiliser *y pour suivre la référence jusqu’à la valeur vers laquelle elle pointe (d’où le déréférencement) afin que le compilateur puisse comparer la valeur réelle. Une fois que nous déréférençons y, nous avons accès à la valeur entière vers laquelle y pointe, que nous pouvons comparer avec 5.
Si nous avions essayé d’écrire assert_eq!(5, y); à la place, nous aurions obtenu cette erreur de compilation : console {{#include ../listings/ch15-smart-pointers/output-only-01-comparing-to-reference/output.txt}}
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0277]: can't compare `{integer}` with `&{integer}`
--> src/main.rs:6:5
|
6 | assert_eq!(5, y);
| ^^^^^^^^^^^^^^^^ no implementation for `{integer} == &{integer}`
|
= help: the trait `PartialEq<&{integer}>` is not implemented for `{integer}`
= note: this error originates in the macro `assert_eq` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0277`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
Comparer un nombre et une référence vers un nombre n’est pas autorisé car ce sont des types différents. Nous devons utiliser l’opérateur de déréférencement pour suivre la référence jusqu’à la valeur vers laquelle elle pointe.
Utiliser Box<T> comme une référence
Nous pouvons réécrire le code de l’encart 15-6 pour utiliser un Box<T> au lieu d’une référence ; l’opérateur de déréférencement utilisé sur le Box<T> dans l’encart 15-7 fonctionne de la même manière que l’opérateur de déréférencement utilisé sur la référence de l’encart 15-6.
fn main() {
let x = 5;
let y = Box::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}Box<i32>La principale différence entre l’encart 15-7 et l’encart 15-6 est qu’ici nous définissons y comme une instance d’une boîte pointant vers une copie de la valeur de x plutôt qu’une référence pointant vers la valeur de x. Dans la dernière assertion, nous pouvons utiliser l’opérateur de déréférencement pour suivre le pointeur de la boîte de la même manière que lorsque y était une référence. Ensuite, nous explorerons ce qui est spécial dans Box<T> et qui nous permet d’utiliser l’opérateur de déréférencement en définissant notre propre type de boîte.
Définir notre propre pointeur intelligent
Construisons un type enveloppeur similaire au type Box<T> fourni par la bibliothèque standard pour expérimenter comment les types de pointeurs intelligents se comportent différemment des références par défaut. Ensuite, nous verrons comment ajouter la possibilité d’utiliser l’opérateur de déréférencement.
Remarque : il y à une grande différence entre le type
MyBox<T>que nous allons construire et le vraiBox<T>: notre version ne stockera pas ses données sur le tas. Nous concentrons cet exemple surDeref, donc l’endroit où les données sont réellement stockées est moins important que le comportement de type pointeur.
Le type Box<T> est fondamentalement défini comme une struct tuple avec un seul élément, donc l’encart 15-8 définit un type MyBox<T> de la même manière. Nous définirons également une fonction new correspondant à la fonction new définie sur Box<T>.
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {}MyBox<T> typeNous définissons une struct nommée MyBox et déclarons un paramètre générique T car nous voulons que notre type puisse contenir des valeurs de n’importe quel type. Le type MyBox est une struct tuple avec un élément de type T. La fonction MyBox::new prend un paramètre de type T et retourné une instance MyBox qui contient la valeur passée.
Essayons d’ajouter la fonction main de l’encart 15-7 à l’encart 15-8 en la modifiant pour utiliser le type MyBox<T> que nous avons défini au lieu de Box<T>. Le code de l’encart 15-9 ne compilera pas, car Rust ne sait pas comment déréférencer MyBox.
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}MyBox<T> in the same way we used references and Box<T>Voici l’erreur de compilation résultante : console {{#include ../listings/ch15-smart-pointers/listing-15-09/output.txt}}
$ cargo run
Compiling deref-example v0.1.0 (file:///projects/deref-example)
error[E0614]: type `MyBox<{integer}>` cannot be dereferenced
--> src/main.rs:14:19
|
14 | assert_eq!(5, *y);
| ^^ can't be dereferenced
For more information about this error, try `rustc --explain E0614`.
error: could not compile `deref-example` (bin "deref-example") due to 1 previous error
Notre type MyBox<T> ne peut pas être déréférencé car nous n’avons pas implémenté cette capacité sur notre type. Pour activer le déréférencement avec l’opérateur *, nous implémentons le trait Deref.
Implémenter le trait Deref
Comme abordé dans « Implémenter un trait sur un type » au chapitre 10, pour implémenter un trait nous devons fournir des implémentations pour les méthodes requises du trait. Le trait Deref, fourni par la bibliothèque standard, nous demande d’implémenter une méthode nommée deref qui emprunté self et retourné une référence vers les données internes. L’encart 15-10 contient une implémentation de Deref à ajouter à la définition de MyBox<T>.
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &Self::Target {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn main() {
let x = 5;
let y = MyBox::new(x);
assert_eq!(5, x);
assert_eq!(5, *y);
}Deref on MyBox<T>La syntaxe type Target = T; définit un type associé que le trait Deref utilisera. Les types associés sont une manière légèrement différente de déclarer un paramètre générique, mais vous n’avez pas besoin de vous en préoccuper pour l’instant ; nous les couvrirons plus en détail au chapitre 20.
Nous remplissons le corps de la méthode deref avec &self.0 pour que deref retourné une référence vers la valeur que nous voulons accéder avec l’opérateur * ; rappelez-vous de [“Créer des types différents avec les structs tuples”][tuple-structs] au chapitre 5 que .0 accède à la première valeur d’une struct tuple. La fonction main de l’encart 15-9 qui appelle * sur la valeur MyBox<T> compilé maintenant, et les assertions passent !
Sans le trait Deref, le compilateur ne peut déréférencer que les références &. La méthode deref donne au compilateur la capacité de prendre une valeur de n’importe quel type qui implémente Deref et d’appeler la méthode deref pour obtenir une référence qu’il sait comment déréférencer.
Quand nous avons saisi *y dans l’encart 15-9, derrière les coulisses, Rust a en fait exécuté ce code :
*(y.deref())Rust substitue l’opérateur * par un appel à la méthode deref suivi d’un déréférencement simple afin que nous n’ayons pas à nous demander si nous devons appeler la méthode deref ou non. Cette fonctionnalité de Rust nous permet d’écrire du code qui fonctionne de manière identique que nous ayons une référence classique ou un type qui implémente Deref.
La raison pour laquelle la méthode deref retourné une référence vers une valeur, et que le déréférencement simple en dehors des parenthèses dans *(y.deref()) est toujours nécessaire, est liée au système de possession. Si la méthode deref retournait la valeur directement au lieu d’une référence vers la valeur, la valeur serait déplacée hors de self. Nous ne voulons pas prendre la possession de la valeur intérieure dans MyBox<T> dans ce cas ni dans la plupart des cas où nous utilisons l’opérateur de déréférencement.
Notez que l’opérateur * est remplacé par un appel à la méthode deref puis un appel à l’opérateur * une seule fois, à chaque fois que nous utilisons un * dans notre code. Comme la substitution de l’opérateur * ne récurse pas indéfiniment, nous obtenons des données de type i32, qui correspondent au 5 dans assert_eq! de l’encart 15-9.
Utiliser la coercition de déréférencement dans les fonctions et les méthodes
La coercition de déréférencement (deref coercion) convertit une référence vers un type qui implémente le trait Deref en une référence vers un autre type. Par exemple, la coercition de déréférencement peut convertir &String en &str car String implémente le trait Deref de manière à retourner &str. La coercition de déréférencement est une facilité que Rust effectue sur les arguments des fonctions et des méthodes, et elle ne fonctionne que sur les types qui implémentent le trait Deref. Elle se produit automatiquement lorsque nous passons une référence vers la valeur d’un type particulier comme argument à une fonction ou une méthode dont le type de paramètre ne correspond pas dans la définition de la fonction ou de la méthode. Une séquence d’appels à la méthode deref convertit le type que nous avons fourni en le type dont le paramètre a besoin.
La coercition de déréférencement a été ajoutée à Rust pour que les programmeurs écrivant des appels de fonctions et de méthodes n’aient pas besoin d’ajouter autant de références et de déréférencements explicites avec & et *. La fonctionnalité de coercition de déréférencement nous permet également d’écrire plus de code qui fonctionne aussi bien avec des références qu’avec des pointeurs intelligents.
Pour voir la coercition de déréférencement en action, utilisons le type MyBox<T> que nous avons défini dans l’encart 15-8 ainsi que l’implémentation de Deref que nous avons ajoutée dans l’encart 15-10. L’encart 15-11 montre la définition d’une fonction qui à un paramètre de type slice de chaîne de caractères.
fn hello(name: &str) {
println!("Hello, {name}!");
}
fn main() {}hello function that has the parameter name of type &strNous pouvons appeler la fonction hello avec une slice de chaîne de caractères comme argument, comme hello("Rust"); par exemple. La coercition de déréférencement rend possible l’appel de hello avec une référence vers une valeur de type MyBox<String>, comme montré dans l’encart 15-12.
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn hello(name: &str) {
println!("Hello, {name}!");
}
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&m);
}hello with a reference to a MyBox<String> value, which works because of deref coercionIci, nous appelons la fonction hello avec l’argument &m, qui est une référence vers une valeur MyBox<String>. Comme nous avons implémenté le trait Deref sur MyBox<T> dans l’encart 15-10, Rust peut transformer &MyBox<String> en &String en appelant deref. La bibliothèque standard fournit une implémentation de Deref sur String qui retourné une slice de chaîne de caractères, et cela se trouve dans la documentation de l’API de Deref. Rust appelle deref à nouveau pour transformer le &String en &str, ce qui correspond à la définition de la fonction hello.
Si Rust n’implémentait pas la coercition de déréférencement, nous devrions écrire le code de l’encart 15-13 au lieu du code de l’encart 15-12 pour appeler hello avec une valeur de type &MyBox<String>.
use std::ops::Deref;
impl<T> Deref for MyBox<T> {
type Target = T;
fn deref(&self) -> &T {
&self.0
}
}
struct MyBox<T>(T);
impl<T> MyBox<T> {
fn new(x: T) -> MyBox<T> {
MyBox(x)
}
}
fn hello(name: &str) {
println!("Hello, {name}!");
}
fn main() {
let m = MyBox::new(String::from("Rust"));
hello(&(*m)[..]);
}Le (*m) déréférence le MyBox<String> en un String. Ensuite, le & et le [..] prennent une slice de chaîne de caractères du String qui est égale à la chaîne entière pour correspondre à la signature de hello. Ce code sans coercition de déréférencement est plus difficile à lire, écrire et comprendre avec tous ces symboles impliqués. La coercition de déréférencement permet à Rust de gérer ces conversions pour nous automatiquement.
Quand le trait Deref est défini pour les types concernés, Rust analysera les types et utilisera Deref::deref autant de fois que nécessaire pour obtenir une référence correspondant au type du paramètre. Le nombre de fois où Deref::deref doit être inséré est résolu à la compilation, il n’y a donc aucune pénalité à l’exécution pour tirer parti de la coercition de déréférencement !
Gérer la coercition de déréférencement avec les références mutables
De la même manière que vous utilisez le trait Deref pour redéfinir l’opérateur * sur les références immuables, vous pouvez utiliser le trait DerefMut pour redéfinir l’opérateur * sur les références mutables.
Rust effectue la coercition de déréférencement lorsqu’il trouve des types et des implémentations de traits dans trois cas :
- De
&Tvers&UquandT: Deref<Target=U> - De
&mut Tvers&mut UquandT: DerefMut<Target=U> - De
&mut Tvers&UquandT: Deref<Target=U>
Les deux premiers cas sont identiques sauf que le deuxième implémente la mutabilité. Le premier cas indique que si vous avez un &T, et que T implémente Deref vers un certain type U, vous pouvez obtenir un &U de manière transparente. Le deuxième cas indique que la même coercition de déréférencement se produit pour les références mutables.
Le troisième cas est plus délicat : Rust convertira aussi une référence mutable en une référence immuable. Mais l’inverse n’est pas possible : les références immuables ne seront jamais converties en références mutables. En raison des règles d’emprunt, si vous avez une référence mutable, cette référence mutable doit être la seule référence vers ces données (sinon, le programme ne compilerait pas). Convertir une référence mutable en une référence immuable ne violera jamais les règles d’emprunt. Convertir une référence immuable en une référence mutable nécessiterait que la référence immuable initiale soit la seule référence immuable vers ces données, mais les règles d’emprunt ne le garantissent pas. Par conséquent, Rust ne peut pas supposer que convertir une référence immuable en une référence mutable est possible.
Exécuter du code au nettoyage avec le trait Drop
Exécuter du code au nettoyage avec le trait Drop
Le deuxième trait important pour le patron des pointeurs intelligents est Drop, qui vous permet de personnaliser ce qui se passe quand une valeur est sur le point de sortir de la portée. Vous pouvez fournir une implémentation du trait Drop sur n’importe quel type, et ce code peut être utilisé pour libérer des ressources comme des fichiers ou des connexions réseau.
Nous introduisons Drop dans le contexte des pointeurs intelligents car la fonctionnalité du trait Drop est presque toujours utilisée lors de l’implémentation d’un pointeur intelligent. Par exemple, quand un Box<T> est libéré (dropped), il désallouera l’espace sur le tas vers lequel la boîte pointe.
Dans certains langages, pour certains types, le programmeur doit appeler du code pour libérer la mémoire ou les ressources chaque fois qu’il a fini d’utiliser une instance de ces types. Les exemples incluent les descripteurs de fichiers, les sockets et les verrous. Si le programmeur oublie, le système peut devenir surchargé et planter. En Rust, vous pouvez spécifier qu’un morceau de code particulier soit exécuté chaque fois qu’une valeur sort de la portée, et le compilateur insérera ce code automatiquement. En conséquence, vous n’avez pas besoin de faire attention à placer du code de nettoyage partout dans le programme quand vous avez fini avec une instance d’un type particulier – vous ne fuirez toujours pas de ressources !
Vous spécifiez le code à exécuter quand une valeur sort de la portée en implémentant le trait Drop. Le trait Drop vous demande d’implémenter une méthode nommée drop qui prend une référence mutable vers self. Pour voir quand Rust appelle drop, implémentons drop avec des instructions println! pour l’instant.
L’encart 15-14 montre une struct CustomSmartPointer dont la seule fonctionnalité personnalisée est qu’elle affichera Dropping CustomSmartPointer! quand l’instance sort de la portée, pour montrer quand Rust exécute la méthode drop.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("my stuff"),
};
let d = CustomSmartPointer {
data: String::from("other stuff"),
};
println!("CustomSmartPointers created");
}CustomSmartPointer struct that implements the Drop trait where we would put our cleanup codeLe trait Drop est inclus dans le prélude, nous n’avons donc pas besoin de l’importer dans la portée. Nous implémentons le trait Drop sur CustomSmartPointer et fournissons une implémentation de la méthode drop qui appelle println!. Le corps de la méthode drop est l’endroit où vous placeriez toute logique que vous souhaitez exécuter quand une instance de votre type sort de la portée. Nous affichons du texte ici pour démontrer visuellement quand Rust appellera drop.
Dans main, nous créons deux instances de CustomSmartPointer puis affichons CustomSmartPointers created. À la fin de main, nos instances de CustomSmartPointer sortiront de la portée, et Rust appellera le code que nous avons mis dans la méthode drop, affichant notre message final. Notez que nous n’avons pas eu besoin d’appeler la méthode drop explicitement.
Lorsque nous exécutons ce programme, nous verrons la sortie suivante : console {{#include ../listings/ch15-smart-pointers/listing-15-14/output.txt}}
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.60s
Running `target/debug/drop-example`
CustomSmartPointers created
Dropping CustomSmartPointer with data `other stuff`!
Dropping CustomSmartPointer with data `my stuff`!
Rust a automatiquement appelé drop pour nous quand nos instances sont sorties de la portée, en appelant le code que nous avons spécifié. Les variables sont libérées dans l’ordre inverse de leur création, donc d a été libéré avant c. Le but de cet exemple est de vous donner un guide visuel de comment la méthode drop fonctionne ; habituellement, vous spécifieriez le code de nettoyage que votre type doit exécuter plutôt qu’un message d’affichage.
Malheureusement, il n’est pas simple de désactiver la fonctionnalité automatique de drop. Désactiver drop n’est généralement pas nécessaire ; tout l’intérêt du trait Drop est qu’il est géré automatiquement. Cependant, il arrive parfois que vous souhaitiez nettoyer une valeur plus tôt. Un exemple est lorsque vous utilisez des pointeurs intelligents qui gèrent des verrous : vous pourriez vouloir forcer la méthode drop qui libère le verrou afin que d’autre code dans la même portée puisse acquérir le verrou. Rust ne vous permet pas d’appeler manuellement la méthode drop du trait Drop ; à la place, vous devez appeler la fonction std::mem::drop fournie par la bibliothèque standard si vous voulez forcer la libération d’une valeur avant la fin de sa portée.
Essayer d’appeler manuellement la méthode drop du trait Drop en modifiant la fonction main de l’encart 15-14 ne fonctionnera pas, comme montré dans l’encart 15-15.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created");
c.drop();
println!("CustomSmartPointer dropped before the end of main");
}drop method from the Drop trait manually to clean up earlyLorsque nous essayons de compiler ce code, nous obtenons cette erreur : console {{#include ../listings/ch15-smart-pointers/listing-15-15/output.txt}}
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
error[E0040]: explicit use of destructor method
--> src/main.rs:16:7
|
16 | c.drop();
| ^^^^ explicit destructor calls not allowed
|
help: consider using `drop` function
|
16 - c.drop();
16 + drop(c);
|
For more information about this error, try `rustc --explain E0040`.
error: could not compile `drop-example` (bin "drop-example") due to 1 previous error
Ce message d’erreur indique que nous ne sommes pas autorisés à appeler explicitement drop. Le message d’erreur utilise le terme destructeur, qui est le terme de programmation générale pour une fonction qui nettoie une instance. Un destructeur est l’analogue d’un constructeur, qui crée une instance. La fonction drop en Rust est un destructeur particulier.
Rust ne nous permet pas d’appeler drop explicitement, car Rust appellerait quand même automatiquement drop sur la valeur à la fin de main. Cela provoquerait une erreur de double libération car Rust essaierait de nettoyer la même valeur deux fois.
Nous ne pouvons pas désactiver l’insertion automatique de drop quand une valeur sort de la portée, et nous ne pouvons pas appeler la méthode drop explicitement. Donc, si nous avons besoin de forcer le nettoyage anticipé d’une valeur, nous utilisons la fonction std::mem::drop.
La fonction std::mem::drop est différente de la méthode drop du trait Drop. Nous l’appelons en passant comme argument la valeur que nous voulons forcer à libérer. La fonction est dans le prélude, donc nous pouvons modifier main dans l’encart 15-15 pour appeler la fonction drop, comme montré dans l’encart 15-16.
struct CustomSmartPointer {
data: String,
}
impl Drop for CustomSmartPointer {
fn drop(&mut self) {
println!("Dropping CustomSmartPointer with data `{}`!", self.data);
}
}
fn main() {
let c = CustomSmartPointer {
data: String::from("some data"),
};
println!("CustomSmartPointer created");
drop(c);
println!("CustomSmartPointer dropped before the end of main");
}std::mem::drop to explicitly drop a value before it goes out of scopeL’exécution de ce code affichera ce qui suit : console {{#include ../listings/ch15-smart-pointers/listing-15-16/output.txt}}
$ cargo run
Compiling drop-example v0.1.0 (file:///projects/drop-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.73s
Running `target/debug/drop-example`
CustomSmartPointer created
Dropping CustomSmartPointer with data `some data`!
CustomSmartPointer dropped before the end of main
Le texte Dropping CustomSmartPointer with data `some data`! est affiché entre les textes CustomSmartPointer created et CustomSmartPointer dropped before the end of main, montrant que le code de la méthode drop est appelé pour libérer c à ce moment-là.
Vous pouvez utiliser le code spécifié dans une implémentation du trait Drop de nombreuses manières pour rendre le nettoyage pratique et sûr : par exemple, vous pourriez l’utiliser pour créer votre propre allocateur de mémoire ! Avec le trait Drop et le système de possession de Rust, vous n’avez pas à vous souvenir de nettoyer, car Rust le fait automatiquement.
Vous n’avez pas non plus à vous soucier des problèmes résultant du nettoyage accidentel de valeurs encore utilisées : le système de possession qui s’assuré que les références sont toujours valides garantit également que drop n’est appelé qu’une seule fois lorsque la valeur n’est plus utilisée.
Maintenant que nous avons examiné Box<T> et certaines des caractéristiques des pointeurs intelligents, examinons quelques autres pointeurs intelligents définis dans la bibliothèque standard.
Rc<T>, le pointeur intelligent à compteur de références
Rc<T>, le pointeur intelligent à comptage de références
Dans la majorité des cas, la possession est claire : vous savez exactement quelle variable possède une valeur donnée. Cependant, il existe des cas où une seule valeur peut avoir plusieurs propriétaires. Par exemple, dans les structures de données de graphe, plusieurs arêtes peuvent pointer vers le même noeud, et ce noeud est conceptuellement possédé par toutes les arêtes qui pointent vers lui. Un noeud ne devrait pas être nettoyé à moins qu’il n’ait plus aucune arête pointant vers lui et donc plus aucun propriétaire.
Vous devez activer la possession multiple explicitement en utilisant le type Rust Rc<T>, qui est une abréviation de reference counting (comptage de références). Le type Rc<T> suit le nombre de références vers une valeur pour déterminer si la valeur est encore utilisée ou non. S’il y a zéro références vers une valeur, celle-ci peut être nettoyée sans qu’aucune référence ne devienne invalide.
Imaginez Rc<T> comme une télévision dans un salon familial. Quand une personne entre pour regarder la télé, elle l’allume. D’autres peuvent entrer dans la pièce et regarder la télé. Quand la dernière personne quitte la pièce, elle éteint la télé car elle n’est plus utilisée. Si quelqu’un éteignait la télé alors que d’autres la regardent encore, il y aurait un tollé parmi les téléspectateurs restants !
Nous utilisons le type Rc<T> quand nous voulons allouer des données sur le tas pour que plusieurs parties de notre programme puissent les lire et que nous ne pouvons pas déterminer à la compilation quelle partie finira d’utiliser les données en dernier. Si nous savions quelle partie finirait en dernier, nous pourrions simplement faire de cette partie le propriétaire des données, et les règles normales de possession appliquées à la compilation prendraient effet.
Notez que Rc<T> est uniquement destiné aux scénarios mono-thread. Quand nous aborderons la concurrence au chapitre 16, nous couvrirons comment faire du comptage de références dans les programmes multi-threads.
Partager des données
Revenons à notre exemple de liste cons de l’encart 15-5. Rappelez-vous que nous l’avons définie avec Box<T>. Cette fois, nous allons créer deux listes qui partagent toutes les deux la possession d’une troisième liste. Conceptuellement, cela ressemble à la figure 15-3.
 Figure 15-3 : Deux listes, `b` et `c`, partageant la possession d’une troisième liste, `a`
Figure 15-3 : Deux listes, `b` et `c`, partageant la possession d’une troisième liste, `a`
Nous allons créer la liste a qui contient 5 puis 10. Ensuite, nous créerons deux autres listes : b qui commence par 3 et c qui commence par 4. Les listes b et c continueront ensuite vers la première liste a contenant 5 et 10. En d’autres termes, les deux listes partageront la première liste contenant 5 et 10.
Essayer d’implémenter ce scénario en utilisant notre définition de List avec Box<T> ne fonctionnera pas, comme montré dans l’encart 15-17.
enum List {
Cons(i32, Box<List>),
Nil,
}
use crate::List::{Cons, Nil};
fn main() {
let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
let b = Cons(3, Box::new(a));
let c = Cons(4, Box::new(a));
}Box<T> that try to share ownership of a third listQuand nous compilons ce code, nous obtenons cette erreur : console {{#include ../listings/ch15-smart-pointers/listing-15-17/output.txt}}
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
error[E0382]: use of moved value: `a`
--> src/main.rs:11:30
|
9 | let a = Cons(5, Box::new(Cons(10, Box::new(Nil))));
| - move occurs because `a` has type `List`, which does not implement the `Copy` trait
10 | let b = Cons(3, Box::new(a));
| - value moved here
11 | let c = Cons(4, Box::new(a));
| ^ value used here after move
|
note: if `List` implemented `Clone`, you could clone the value
--> src/main.rs:1:1
|
1 | enum List {
| ^^^^^^^^^ consider implementing `Clone` for this type
...
10 | let b = Cons(3, Box::new(a));
| - you could clone this value
For more information about this error, try `rustc --explain E0382`.
error: could not compile `cons-list` (bin "cons-list") due to 1 previous error
Les variantes Cons possèdent les données qu’elles contiennent, donc quand nous créons la liste b, a est déplacé dans b et b possède a. Ensuite, quand nous essayons d’utiliser a à nouveau lors de la création de c, nous ne sommes pas autorisés car a a été déplacé.
Nous pourrions modifier la définition de Cons pour contenir des références à la place, mais alors nous devrions spécifier des paramètres de durée de vie. En spécifiant des paramètres de durée de vie, nous spécifierions que chaque élément de la liste vivra au moins aussi longtemps que la liste entière. C’est le cas pour les éléments et les listes de l’encart 15-17, mais pas dans tous les scénarios.
À la place, nous allons changer notre définition de List pour utiliser Rc<T> au lieu de Box<T>, comme montré dans l’encart 15-18. Chaque variante Cons contiendra maintenant une valeur et un Rc<T> pointant vers une List. Quand nous créons b, au lieu de prendre la possession de a, nous clonerons le Rc<List> que a contient, augmentant ainsi le nombre de références de un à deux et permettant à a et b de partager la possession des données dans ce Rc<List>. Nous clonerons aussi a lors de la création de c, augmentant le nombre de références de deux à trois. Chaque fois que nous appelons Rc::clone, le compteur de références vers les données dans le Rc<List> augmentera, et les données ne seront pas nettoyées à moins qu’il n’y ait zéro références vers elles.
enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
let b = Cons(3, Rc::clone(&a));
let c = Cons(4, Rc::clone(&a));
}List that uses Rc<T>Nous devons ajouter une instruction use pour amener Rc<T> dans la portée car il n’est pas dans le prélude. Dans main, nous créons la liste contenant 5 et 10 et la stockons dans un nouveau Rc<List> dans a. Ensuite, quand nous créons b et c, nous appelons la fonction Rc::clone et passons une référence vers le Rc<List> dans a comme argument.
Nous aurions pu appeler a.clone() au lieu de Rc::clone(&a), mais la convention de Rust est d’utiliser Rc::clone dans ce cas. L’implémentation de Rc::clone ne fait pas une copie profonde de toutes les données comme le font la plupart des implémentations de clone des autres types. L’appel à Rc::clone ne fait qu’incrémenter le compteur de références, ce qui ne prend pas beaucoup de temps. Les copies profondes de données peuvent prendre beaucoup de temps. En utilisant Rc::clone pour le comptage de références, nous pouvons distinguer visuellement les clones de type copie profonde des clones qui augmentent le compteur de références. Quand on cherche des problèmes de performance dans le code, nous n’avons besoin de considérer que les clones de copie profonde et pouvons ignorer les appels à Rc::clone.
Cloner pour augmenter le compteur de références
Modifions notre exemple fonctionnel de l’encart 15-18 pour que nous puissions voir les compteurs de références changer au fur et à mesure que nous créons et libérons des références vers le Rc<List> dans a.
Dans l’encart 15-19, nous allons modifier main pour qu’il ait une portée intérieure autour de la liste c ; ensuite, nous pourrons voir comment le compteur de références change quand c sort de la portée.
enum List {
Cons(i32, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::rc::Rc;
// --snip--
fn main() {
let a = Rc::new(Cons(5, Rc::new(Cons(10, Rc::new(Nil)))));
println!("count after creating a = {}", Rc::strong_count(&a));
let b = Cons(3, Rc::clone(&a));
println!("count after creating b = {}", Rc::strong_count(&a));
{
let c = Cons(4, Rc::clone(&a));
println!("count after creating c = {}", Rc::strong_count(&a));
}
println!("count after c goes out of scope = {}", Rc::strong_count(&a));
}À chaque point du programme où le compteur de références change, nous affichons le compteur de références, que nous obtenons en appelant la fonction Rc::strong_count. Cette fonction s’appelle strong_count plutôt que count car le type Rc<T> a aussi un weak_count ; nous verrons à quoi sert weak_count dans [“Prévenir les cycles de références avec Weak<T>”][preventing-ref-cycles].
Ce code affiche ce qui suit : console {{#include ../listings/ch15-smart-pointers/listing-15-19/output.txt}}
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.45s
Running `target/debug/cons-list`
count after creating a = 1
count after creating b = 2
count after creating c = 3
count after c goes out of scope = 2
Nous pouvons voir que le Rc<List> dans a à un compteur de références initial de 1 ; ensuite, chaque fois que nous appelons clone, le compteur augmente de 1. Quand c sort de la portée, le compteur diminue de 1. Nous n’avons pas besoin d’appeler une fonction pour diminuer le compteur de références comme nous devons appeler Rc::clone pour l’augmenter : l’implémentation du trait Drop diminue automatiquement le compteur de références quand une valeur Rc<T> sort de la portée.
Ce que nous ne pouvons pas voir dans cet exemple, c’est que quand b puis a sortent de la portée à la fin de main, le compteur est à 0, et le Rc<List> est complètement nettoyé. Utiliser Rc<T> permet à une seule valeur d’avoir plusieurs propriétaires, et le compteur garantit que la valeur reste valide tant qu’un des propriétaires existe encore.
Via des références immuables, Rc<T> vous permet de partager des données entre plusieurs parties de votre programme en lecture seule. Si Rc<T> vous permettait d’avoir aussi plusieurs références mutables, vous pourriez violer l’une des règles d’emprunt discutées au chapitre 4 : les emprunts mutables multiples vers le même endroit peuvent provoquer des courses de données et des incohérences. Mais pouvoir modifier des données est très utile ! Dans la prochaine section, nous aborderons le patron de mutabilité intérieure et le type RefCell<T> que vous pouvez utiliser conjointement avec un Rc<T> pour contourner cette restriction d’immuabilité.
RefCell<T> et le patron de mutabilité intérieure
RefCell<T> et le patron de mutabilité intérieure
La mutabilité intérieure est un patron de conception en Rust qui vous permet de modifier des données même lorsqu’il existe des références immuables vers ces données ; normalement, cette action est interdite par les règles d’emprunt. Pour modifier des données, le patron utilise du code unsafe à l’intérieur d’une structure de données pour contourner les règles habituelles de Rust qui régissent la mutation et l’emprunt. Le code unsafe indique au compilateur que nous vérifions les règles manuellement au lieu de compter sur le compilateur pour les vérifier à notre place ; nous aborderons le code unsafe plus en détail au chapitre 20.
Nous ne pouvons utiliser les types qui emploient le patron de mutabilité intérieure que lorsque nous pouvons nous assurer que les règles d’emprunt seront respectées à l’exécution, même si le compilateur ne peut pas le garantir. Le code unsafe impliqué est alors enveloppé dans une API sûre, et le type externe reste immuable.
Explorons ce concept en examinant le type RefCell<T> qui suit le patron de mutabilité intérieure.
Appliquer les règles d’emprunt à l’exécution
Contrairement à Rc<T>, le type RefCell<T> représente une possession unique des données qu’il contient. Alors, qu’est-ce qui rend RefCell<T> différent d’un type comme Box<T> ? Rappelez-vous les règles d’emprunt que vous avez apprises au chapitre 4 : - À tout moment, vous pouvez avoir soit une référence mutable, soit un nombre quelconque de références immuables (mais pas les deux). - Les références doivent toujours être valides.
- À tout moment, vous pouvez avoir soit une référence mutable, soit un nombre quelconque de références immuables (mais pas les deux).
- Les références doivent toujours être valides.
Avec les références et Box<T>, les invariants des règles d’emprunt sont appliqués à la compilation. Avec RefCell<T>, ces invariants sont appliqués à l’exécution. Avec les références, si vous enfreignez ces règles, vous obtiendrez une erreur de compilation. Avec RefCell<T>, si vous enfreignez ces règles, votre programme paniquera et se terminera.
Les avantages de vérifier les règles d’emprunt à la compilation sont que les erreurs seront détectées plus tôt dans le processus de développement, et qu’il n’y à aucun impact sur les performances à l’exécution car toute l’analyse est effectuée au préalable. Pour ces raisons, vérifier les règles d’emprunt à la compilation est le meilleur choix dans la majorité des cas, c’est pourquoi c’est le comportement par défaut de Rust.
L’avantage de vérifier les règles d’emprunt à l’exécution à la place est que certains scénarios sûrs en mémoire sont alors autorisés, là où ils auraient été interdits par les vérifications à la compilation. L’analyse statique, comme celle du compilateur Rust, est intrinsèquement conservatrice. Certaines propriétés du code sont impossibles à détecter en analysant le code : l’exemple le plus célèbre est le problème de l’arrêt, qui dépasse le cadre de ce livre mais constitue un sujet de recherche intéressant.
Comme certaines analyses sont impossibles, si le compilateur Rust ne peut pas être sûr que le code respecte les règles de possession, il pourrait rejeter un programme correct ; en ce sens, il est conservateur. Si Rust acceptait un programme incorrect, les utilisateurs ne pourraient pas faire confiance aux garanties que Rust offre. Cependant, si Rust rejette un programme correct, le programmeur sera gêné, mais rien de catastrophique ne peut se produire. Le type RefCell<T> est utile quand vous êtes sûr que votre code suit les règles d’emprunt mais que le compilateur est incapable de le comprendre et de le garantir.
De manière similaire à Rc<T>, RefCell<T> est uniquement destiné aux scénarios mono-thread et vous donnera une erreur de compilation si vous essayez de l’utiliser dans un contexte multi-thread. Nous parlerons de comment obtenir la fonctionnalité de RefCell<T> dans un programme multi-thread au chapitre 16.
Voici un récapitulatif des raisons de choisir Box<T>, Rc<T> ou RefCell<T> :
Rc<T>permet plusieurs propriétaires des mêmes données ;Box<T>etRefCell<T>ont un seul propriétaire.Box<T>autorise des emprunts immuables ou mutables vérifiés à la compilation ;Rc<T>autorise uniquement des emprunts immuables vérifiés à la compilation ;RefCell<T>autorise des emprunts immuables ou mutables vérifiés à l’exécution.- Parce que
RefCell<T>autorise des emprunts mutables vérifiés à l’exécution, vous pouvez muter la valeur à l’intérieur duRefCell<T>même lorsque leRefCell<T>est immuable.
Modifier la valeur à l’intérieur d’une valeur immuable est le patron de mutabilité intérieure. Examinons une situation dans laquelle la mutabilité intérieure est utile et voyons comment c’est possible.
Utiliser la mutabilité intérieure
Une conséquence des règles d’emprunt est que quand vous avez une valeur immuable, vous ne pouvez pas l’emprunter de manière mutable. Par exemple, ce code ne compilera pas : rust,ignore,does_not_compile {{#rustdoc_include ../listings/ch15-smart-pointers/no-listing-01-cant-borrow-immutable-as-mutable/src/main.rs}}
fn main() {
let x = 5;
let y = &mut x;
}Si vous tentiez de compiler ce code, vous obtiendriez l’erreur suivante : console {{#include ../listings/ch15-smart-pointers/no-listing-01-cant-borrow-immutable-as-mutable/output.txt}}
$ cargo run
Compiling borrowing v0.1.0 (file:///projects/borrowing)
error[E0596]: cannot borrow `x` as mutable, as it is not declared as mutable
--> src/main.rs:3:13
|
3 | let y = &mut x;
| ^^^^^^ cannot borrow as mutable
|
help: consider changing this to be mutable
|
2 | let mut x = 5;
| +++
For more information about this error, try `rustc --explain E0596`.
error: could not compile `borrowing` (bin "borrowing") due to 1 previous error
Cependant, il existe des situations dans lesquelles il serait utile qu’une valeur se modifié elle-même dans ses méthodes mais apparaisse immuable au code extérieur. Le code en dehors des méthodes de la valeur ne pourrait pas modifier la valeur. Utiliser RefCell<T> est un moyen d’obtenir la capacité d’avoir une mutabilité intérieure, mais RefCell<T> ne contourne pas complètement les règles d’emprunt : le vérificateur d’emprunts dans le compilateur autorise cette mutabilité intérieure, et les règles d’emprunt sont vérifiées à l’exécution à la place. Si vous violez les règles, vous obtiendrez un panic! au lieu d’une erreur de compilation.
Travaillons sur un exemple pratique où nous pouvons utiliser RefCell<T> pour modifier une valeur immuable et voir pourquoi c’est utile.
Tester avec des objets simulés
Parfois, lors des tests, un programmeur utilise un type à la place d’un autre type, afin d’observer un comportement particulier et de vérifier qu’il est correctement implémenté. Ce type de substitution s’appelle un doublure de test (test double). Pensez-y comme une doublure cascade au cinéma, où une personne se substitue à un acteur pour réaliser une scène particulièrement périlleuse. Les doublures de test remplacent d’autres types lorsque nous exécutons des tests. Les objets simulés (mock objects) sont des types spécifiques de doublures de test qui enregistrent ce qui se passe pendant un test afin que vous puissiez vérifier que les actions correctes ont eu lieu.
Rust n’a pas d’objets au même sens que d’autres langages, et Rust n’a pas de fonctionnalité d’objets simulés intégrée dans la bibliothèque standard comme le font certains autres langages. Cependant, vous pouvez tout à fait créer une struct qui servira les mêmes objectifs qu’un objet simulé.
Voici le scénario que nous allons tester : nous allons créer une bibliothèque qui suit une valeur par rapport à une valeur maximale et envoie des messages en fonction de la proximité de la valeur courante par rapport à la valeur maximale. Cette bibliothèque pourrait être utilisée pour suivre le quota d’un utilisateur pour le nombre d’appels API qu’il est autorisé à effectuer, par exemple.
Notre bibliothèque ne fournira que la fonctionnalité de suivi de la proximité d’une valeur par rapport au maximum et les messages à envoyer à quels moments. Les applications qui utilisent notre bibliothèque devront fournir le mécanisme d’envoi des messages : l’application pourrait afficher le message directement à l’utilisateur, envoyer un email, envoyer un SMS, ou faire autre chose. La bibliothèque n’a pas besoin de connaître ce détail. Tout ce dont elle a besoin est quelque chose qui implémente un trait que nous fournirons, appelé Messenger. L’encart 15-20 montre le code de la bibliothèque.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}Une partie importante de ce code est que le trait Messenger à une méthode appelée send qui prend une référence immuable vers self et le texte du message. Ce trait est l’interface que notre objet simulé doit implémenter pour que le simulacre puisse être utilisé de la même manière qu’un vrai objet. L’autre partie importante est que nous voulons tester le comportement de la méthode set_value sur le LimitTracker. Nous pouvons changer ce que nous passons pour le paramètre value, mais set_value ne retourné rien sur quoi faire des assertions. Nous voulons pouvoir dire que si nous créons un LimitTracker avec quelque chose qui implémente le trait Messenger et une valeur particulière pour max, le messager reçoit l’instruction d’envoyer les messages appropriés quand nous passons différents nombres pour value.
Nous avons besoin d’un objet simulé qui, au lieu d’envoyer un email ou un SMS quand nous appelons send, ne fera que garder trace des messages qu’on lui demande d’envoyer. Nous pouvons créer une nouvelle instance de l’objet simulé, créer un LimitTracker qui utilise l’objet simulé, appeler la méthode set_value sur LimitTracker, puis vérifier que l’objet simulé contient les messages attendus. L’encart 15-21 montre une tentative d’implémentation d’un objet simulé pour faire exactement cela, mais le vérificateur d’emprunts ne le permettra pas.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
struct MockMessenger {
sent_messages: Vec<String>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: vec![],
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.len(), 1);
}
}MockMessenger that isn’t allowed by the borrow checkerCe code de test définit une struct MockMessenger qui à un champ sent_messages avec un Vec de valeurs String pour garder trace des messages qu’on lui demande d’envoyer. Nous définissons aussi une fonction associée new pour faciliter la création de nouvelles valeurs MockMessenger qui commencent avec une liste vide de messages. Nous implémentons ensuite le trait Messenger pour MockMessenger afin de pouvoir donner un MockMessenger à un LimitTracker. Dans la définition de la méthode send, nous prenons le message passé en paramètre et le stockons dans la liste sent_messages du MockMessenger.
Dans le test, nous testons ce qui se passe quand on demande au LimitTracker de définir value à quelque chose qui représente plus de 75 pour cent de la valeur max. D’abord, nous créons un nouveau MockMessenger, qui commencera avec une liste vide de messages. Ensuite, nous créons un nouveau LimitTracker et lui donnons une référence vers le nouveau MockMessenger et une valeur max de 100. Nous appelons la méthode set_value sur le LimitTracker avec une valeur de 80, qui est plus de 75 pour cent de 100. Puis, nous vérifions que la liste de messages que le MockMessenger suit devrait maintenant contenir un message.
Cependant, il y à un problème avec ce test, comme montré ici : console {{#include ../listings/ch15-smart-pointers/listing-15-21/output.txt}}
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
error[E0596]: cannot borrow `self.sent_messages` as mutable, as it is behind a `&` reference
--> src/lib.rs:58:13
|
58 | self.sent_messages.push(String::from(message));
| ^^^^^^^^^^^^^^^^^^ `self` is a `&` reference, so the data it refers to cannot be borrowed as mutable
|
help: consider changing this to be a mutable reference in the `impl` method and the `trait` definition
|
2 ~ fn send(&mut self, msg: &str);
3 | }
...
56 | impl Messenger for MockMessenger {
57 ~ fn send(&mut self, message: &str) {
|
For more information about this error, try `rustc --explain E0596`.
error: could not compile `limit-tracker` (lib test) due to 1 previous error
Nous ne pouvons pas modifier le MockMessenger pour garder trace des messages, car la méthode send prend une référence immuable vers self. Nous ne pouvons pas non plus suivre la suggestion du texte d’erreur d’utiliser &mut self à la fois dans la méthode impl et la définition du trait. Nous ne voulons pas changer le trait Messenger uniquement pour les besoins des tests. Au lieu de cela, nous devons trouver un moyen de faire fonctionner correctement notre code de test avec notre conception existante.
C’est une situation dans laquelle la mutabilité intérieure peut aider ! Nous allons stocker les sent_messages dans un RefCell<T>, et alors la méthode send pourra modifier sent_messages pour stocker les messages que nous avons vus. L’encart 15-22 montre à quoi cela ressemble.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
self.sent_messages.borrow_mut().push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
// --snip--
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}RefCell<T> to mutate an inner value while the outer value is considered immutableLe champ sent_messages est maintenant de type RefCell<Vec<String>> au lieu de Vec<String>. Dans la fonction new, nous créons une nouvelle instance RefCell<Vec<String>> autour du vecteur vide.
Pour l’implémentation de la méthode send, le premier paramètre est toujours un emprunt immuable de self, ce qui correspond à la définition du trait. Nous appelons borrow_mut sur le RefCell<Vec<String>> dans self.sent_messages pour obtenir une référence mutable vers la valeur à l’intérieur du RefCell<Vec<String>>, qui est le vecteur. Ensuite, nous pouvons appeler push sur la référence mutable vers le vecteur pour garder trace des messages envoyés pendant le test.
Le dernier changement que nous devons faire est dans l’assertion : pour voir combien d’éléments se trouvent dans le vecteur intérieur, nous appelons borrow sur le RefCell<Vec<String>> pour obtenir une référence immuable vers le vecteur.
Maintenant que vous avez vu comment utiliser RefCell<T>, examinons comment il fonctionne !
Suivre les emprunts à l’exécution
Lors de la création de références immuables et mutables, nous utilisons respectivement la syntaxe & et &mut. Avec RefCell<T>, nous utilisons les méthodes borrow et borrow_mut, qui font partie de l’API sûre de RefCell<T>. La méthode borrow retourné le type de pointeur intelligent Ref<T>, et borrow_mut retourné le type de pointeur intelligent RefMut<T>. Les deux types implémentent Deref, nous pouvons donc les traiter comme des références classiques.
Le RefCell<T> suit le nombre de pointeurs intelligents Ref<T> et RefMut<T> actuellement actifs. Chaque fois que nous appelons borrow, le RefCell<T> augmente son compteur d’emprunts immuables actifs. Quand une valeur Ref<T> sort de la portée, le compteur d’emprunts immuables diminue de 1. Tout comme les règles d’emprunt à la compilation, RefCell<T> nous permet d’avoir de nombreux emprunts immuables ou un seul emprunt mutable à tout moment.
Si nous essayons de violer ces règles, plutôt que d’obtenir une erreur de compilation comme ce serait le cas avec les références, l’implémentation de RefCell<T> paniquera à l’exécution. L’encart 15-23 montre une modification de l’implémentation de send de l’encart 15-22. Nous essayons délibérément de créer deux emprunts mutables actifs dans la même portée pour illustrer que RefCell<T> nous empêche de le faire à l’exécution.
pub trait Messenger {
fn send(&self, msg: &str);
}
pub struct LimitTracker<'a, T: Messenger> {
messenger: &'a T,
value: usize,
max: usize,
}
impl<'a, T> LimitTracker<'a, T>
where
T: Messenger,
{
pub fn new(messenger: &'a T, max: usize) -> LimitTracker<'a, T> {
LimitTracker {
messenger,
value: 0,
max,
}
}
pub fn set_value(&mut self, value: usize) {
self.value = value;
let percentage_of_max = self.value as f64 / self.max as f64;
if percentage_of_max >= 1.0 {
self.messenger.send("Error: You are over your quota!");
} else if percentage_of_max >= 0.9 {
self.messenger
.send("Urgent warning: You've used up over 90% of your quota!");
} else if percentage_of_max >= 0.75 {
self.messenger
.send("Warning: You've used up over 75% of your quota!");
}
}
}
#[cfg(test)]
mod tests {
use super::*;
use std::cell::RefCell;
struct MockMessenger {
sent_messages: RefCell<Vec<String>>,
}
impl MockMessenger {
fn new() -> MockMessenger {
MockMessenger {
sent_messages: RefCell::new(vec![]),
}
}
}
impl Messenger for MockMessenger {
fn send(&self, message: &str) {
let mut one_borrow = self.sent_messages.borrow_mut();
let mut two_borrow = self.sent_messages.borrow_mut();
one_borrow.push(String::from(message));
two_borrow.push(String::from(message));
}
}
#[test]
fn it_sends_an_over_75_percent_warning_message() {
let mock_messenger = MockMessenger::new();
let mut limit_tracker = LimitTracker::new(&mock_messenger, 100);
limit_tracker.set_value(80);
assert_eq!(mock_messenger.sent_messages.borrow().len(), 1);
}
}RefCell<T> will panicNous créons une variable one_borrow pour le pointeur intelligent RefMut<T> retourné par borrow_mut. Ensuite, nous créons un autre emprunt mutable de la même manière dans la variable two_borrow. Cela crée deux références mutables dans la même portée, ce qui n’est pas autorisé. Quand nous exécutons les tests de notre bibliothèque, le code de l’encart 15-23 compilera sans aucune erreur, mais le test échouera : console {{#include ../listings/ch15-smart-pointers/listing-15-23/output.txt}}
$ cargo test
Compiling limit-tracker v0.1.0 (file:///projects/limit-tracker)
Finished `test` profile [unoptimized + debuginfo] target(s) in 0.91s
Running unittests src/lib.rs (target/debug/deps/limit_tracker-e599811fa246dbde)
running 1 test
test tests::it_sends_an_over_75_percent_warning_message ... FAILED
failures:
---- tests::it_sends_an_over_75_percent_warning_message stdout ----
thread 'tests::it_sends_an_over_75_percent_warning_message' panicked at src/lib.rs:60:53:
RefCell already borrowed
note: run with `RUST_BACKTRACE=1` environment variable to display a backtrace
failures:
tests::it_sends_an_over_75_percent_warning_message
test result: FAILED. 0 passed; 1 failed; 0 ignored; 0 measured; 0 filtered out; finished in 0.00s
error: test failed, to rerun pass `--lib`
Remarquez que le code a paniqué avec le message already borrowed: BorrowMutError. C’est ainsi que RefCell<T> gère les violations des règles d’emprunt à l’exécution.
Choisir de capturer les erreurs d’emprunt à l’exécution plutôt qu’à la compilation, comme nous l’avons fait ici, signifie que vous trouveriez potentiellement des erreurs dans votre code plus tard dans le processus de développement : peut-être pas avant que votre code ne soit déployé en production. De plus, votre code subirait une légère pénalité de performance à l’exécution du fait du suivi des emprunts à l’exécution plutôt qu’à la compilation. Cependant, utiliser RefCell<T> rend possible l’écriture d’un objet simulé qui peut se modifier lui-même pour garder trace des messages qu’il a vus tout en l’utilisant dans un contexte où seules les valeurs immuables sont autorisées. Vous pouvez utiliser RefCell<T> malgré ses compromis pour obtenir plus de fonctionnalités que ce que les références classiques fournissent.
Permettre plusieurs propriétaires de données mutables
Une façon courante d’utiliser RefCell<T> est en combinaison avec Rc<T>. Rappelez-vous que Rc<T> vous permet d’avoir plusieurs propriétaires de certaines données, mais il ne donne qu’un accès immuable à ces données. Si vous avez un Rc<T> qui contient un RefCell<T>, vous pouvez obtenir une valeur qui peut avoir plusieurs propriétaires et que vous pouvez modifier !
Par exemple, rappelez-vous l’exemple de la liste cons de l’encart 15-18 où nous avons utilisé Rc<T> pour permettre à plusieurs listes de partager la possession d’une autre liste. Comme Rc<T> ne contient que des valeurs immuables, nous ne pouvons pas changer les valeurs de la liste une fois que nous les avons créées. Ajoutons RefCell<T> pour sa capacité à changer les valeurs dans les listes. L’encart 15-24 montre qu’en utilisant un RefCell<T> dans la définition de Cons, nous pouvons modifier la valeur stockée dans toutes les listes.
#[derive(Debug)]
enum List {
Cons(Rc<RefCell<i32>>, Rc<List>),
Nil,
}
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
fn main() {
let value = Rc::new(RefCell::new(5));
let a = Rc::new(Cons(Rc::clone(&value), Rc::new(Nil)));
let b = Cons(Rc::new(RefCell::new(3)), Rc::clone(&a));
let c = Cons(Rc::new(RefCell::new(4)), Rc::clone(&a));
*value.borrow_mut() += 10;
println!("a after = {a:?}");
println!("b after = {b:?}");
println!("c after = {c:?}");
}Rc<RefCell<i32>> to create a List that we can mutateNous créons une valeur qui est une instance de Rc<RefCell<i32>> et la stockons dans une variable nommée value afin de pouvoir y accéder directement plus tard. Ensuite, nous créons une List dans a avec une variante Cons qui contient value. Nous devons cloner value pour que a et value aient tous les deux la possession de la valeur intérieure 5 plutôt que de transférer la possession de value vers a ou de faire emprunter a depuis value.
Nous enveloppons la liste a dans un Rc<T> pour que quand nous créons les listes b et c, elles puissent toutes les deux faire référence à a, ce que nous avons fait dans l’encart 15-18.
Après avoir créé les listes dans a, b et c, nous voulons ajouter 10 à la valeur dans value. Nous le faisons en appelant borrow_mut sur value, qui utilise la fonctionnalité de déréférencement automatique dont nous avons discuté dans [“Où est l’opérateur -> ?”][wheres-the—operator] au chapitre 5 pour déréférencer le Rc<T> vers la valeur intérieure RefCell<T>. La méthode borrow_mut retourné un pointeur intelligent RefMut<T>, et nous utilisons l’opérateur de déréférencement dessus pour changer la valeur intérieure.
Quand nous affichons a, b et c, nous pouvons voir qu’ils ont tous la valeur modifiée de 15 plutôt que 5 : console {{#include ../listings/ch15-smart-pointers/listing-15-24/output.txt}}
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.63s
Running `target/debug/cons-list`
a after = Cons(RefCell { value: 15 }, Nil)
b after = Cons(RefCell { value: 3 }, Cons(RefCell { value: 15 }, Nil))
c after = Cons(RefCell { value: 4 }, Cons(RefCell { value: 15 }, Nil))
Cette technique est plutôt élégante ! En utilisant RefCell<T>, nous avons une valeur List extérieurement immuable. Mais nous pouvons utiliser les méthodes de RefCell<T> qui fournissent l’accès à sa mutabilité intérieure afin de pouvoir modifier nos données quand nous en avons besoin. Les vérifications à l’exécution des règles d’emprunt nous protègent des courses de données, et il vaut parfois la peine d’échanger un peu de vitesse contre cette flexibilité dans nos structures de données. Notez que RefCell<T> ne fonctionne pas pour le code multi-thread ! Mutex<T> est la version sûre pour les threads de RefCell<T>, et nous aborderons Mutex<T> au chapitre 16.
Les cycles de références peuvent provoquer des fuites de mémoire
Les cycles de références peuvent provoquer des fuites de mémoire
Les garanties de sécurité de la mémoire de Rust rendent difficile, mais pas impossible, la création accidentelle de mémoire qui n’est jamais nettoyée (connue sous le nom de fuite de mémoire). Prévenir entièrement les fuites de mémoire ne fait pas partie des garanties de Rust, ce qui signifie que les fuites de mémoire sont considérées comme sûres en mémoire en Rust. Nous pouvons constater que Rust permet les fuites de mémoire en utilisant Rc<T> et RefCell<T> : il est possible de créer des références où les éléments se réfèrent les uns aux autres dans un cycle. Cela crée des fuites de mémoire car le compteur de références de chaque élément dans le cycle n’atteindra jamais 0, et les valeurs ne seront jamais libérées.
Créer un cycle de références
Voyons comment un cycle de références peut se produire et comment le prévenir, en commençant par la définition de l’enum List et une méthode tail dans l’encart 15-25.
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell<Rc<List>>),
Nil,
}
impl List {
fn tail(&self) -> Option<&RefCell<Rc<List>>> {
match self {
Cons(_, item) => Some(item),
Nil => None,
}
}
}
fn main() {}RefCell<T> so that we can modify what a Cons variant is referring toNous utilisons une autre variation de la définition de List de l’encart 15-5. Le deuxième élément de la variante Cons est maintenant RefCell<Rc<List>>, ce qui signifie qu’au lieu de pouvoir modifier la valeur i32 comme nous l’avons fait dans l’encart 15-24, nous voulons modifier la valeur List vers laquelle une variante Cons pointe. Nous ajoutons aussi une méthode tail pour faciliter l’accès au deuxième élément si nous avons une variante Cons.
Dans l’encart 15-26, nous ajoutons une fonction main qui utilise les définitions de l’encart 15-25. Ce code crée une liste dans a et une liste dans b qui pointe vers la liste dans a. Ensuite, il modifié la liste dans a pour pointer vers b, créant un cycle de références. Il y à des instructions println! tout au long du processus pour montrer quels sont les compteurs de références à différents moments.
use crate::List::{Cons, Nil};
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
enum List {
Cons(i32, RefCell<Rc<List>>),
Nil,
}
impl List {
fn tail(&self) -> Option<&RefCell<Rc<List>>> {
match self {
Cons(_, item) => Some(item),
Nil => None,
}
}
}
fn main() {
let a = Rc::new(Cons(5, RefCell::new(Rc::new(Nil))));
println!("a initial rc count = {}", Rc::strong_count(&a));
println!("a next item = {:?}", a.tail());
let b = Rc::new(Cons(10, RefCell::new(Rc::clone(&a))));
println!("a rc count after b creation = {}", Rc::strong_count(&a));
println!("b initial rc count = {}", Rc::strong_count(&b));
println!("b next item = {:?}", b.tail());
if let Some(link) = a.tail() {
*link.borrow_mut() = Rc::clone(&b);
}
println!("b rc count after changing a = {}", Rc::strong_count(&b));
println!("a rc count after changing a = {}", Rc::strong_count(&a));
// Uncomment the next line to see that we have a cycle;
// it will overflow the stack.
// println!("a next item = {:?}", a.tail());
}List values pointing to each otherNous créons une instance Rc<List> contenant une valeur List dans la variable a avec une liste initiale de 5, Nil. Nous créons ensuite une instance Rc<List> contenant une autre valeur List dans la variable b qui contient la valeur 10 et pointe vers la liste dans a.
Nous modifions a pour qu’il pointe vers b au lieu de Nil, créant un cycle. Nous le faisons en utilisant la méthode tail pour obtenir une référence vers le RefCell<Rc<List>> dans a, que nous mettons dans la variable link. Ensuite, nous utilisons la méthode borrow_mut sur le RefCell<Rc<List>> pour changer la valeur à l’intérieur d’un Rc<List> contenant une valeur Nil vers le Rc<List> dans b.
Quand nous exécutons ce code, en gardant le dernier println! commenté pour le moment, nous obtenons cette sortie : console {{#include ../listings/ch15-smart-pointers/listing-15-26/output.txt}}
$ cargo run
Compiling cons-list v0.1.0 (file:///projects/cons-list)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.53s
Running `target/debug/cons-list`
a initial rc count = 1
a next item = Some(RefCell { value: Nil })
a rc count after b creation = 2
b initial rc count = 1
b next item = Some(RefCell { value: Cons(5, RefCell { value: Nil }) })
b rc count after changing a = 2
a rc count after changing a = 2
Le compteur de références des instances Rc<List> dans a et b est de 2 après que nous avons modifié la liste dans a pour pointer vers b. À la fin de main, Rust libère la variable b, ce qui diminue le compteur de références de l’instance Rc<List> de b de 2 à 1. La mémoire que Rc<List> occupe sur le tas ne sera pas libérée à ce stade car son compteur de références est 1, pas 0. Ensuite, Rust libère a, ce qui diminue aussi le compteur de références de l’instance Rc<List> de a de 2 à 1. La mémoire de cette instance ne peut pas non plus être libérée, car l’autre instance Rc<List> y fait encore référence. La mémoire allouée à la liste restera non récupérée pour toujours. Pour visualiser ce cycle de références, nous avons créé le diagramme de la figure 15-4.

Figure 15-4 : Un cycle de références des listes a et b pointant l’une vers l’autre
Si vous décommentez le dernier println! et exécutez le programme, Rust essaiera d’afficher ce cycle avec a pointant vers b pointant vers a et ainsi de suite jusqu’à ce qu’il déborde la pile.
Comparé à un programme réel, les conséquences de la création d’un cycle de références dans cet exemple ne sont pas très graves : juste après avoir créé le cycle de références, le programme se terminé. Cependant, si un programme plus complexe allouait beaucoup de mémoire dans un cycle et la conservait longtemps, le programme utiliserait plus de mémoire que nécessaire et pourrait submerger le système, le faisant manquer de mémoire disponible.
Créer des cycles de références ne se fait pas facilement, mais ce n’est pas impossible non plus. Si vous avez des valeurs RefCell<T> qui contiennent des valeurs Rc<T> ou des combinaisons imbriquées similaires de types avec mutabilité intérieure et comptage de références, vous devez vous assurer de ne pas créer de cycles ; vous ne pouvez pas compter sur Rust pour les détecter. Créer un cycle de références serait un bogue logique dans votre programme que vous devriez minimiser en utilisant des tests automatisés, des revues de code et d’autres pratiques de développement logiciel.
Une autre solution pour éviter les cycles de références est de réorganiser vos structures de données de sorte que certaines références expriment la possession et d’autres non. Ainsi, vous pouvez avoir des cycles composés de certaines relations de possession et de certaines relations sans possession, et seules les relations de possession affectent si une valeur peut être libérée ou non. Dans l’encart 15-25, nous voulons toujours que les variantes Cons possèdent leur liste, donc réorganiser la structure de données n’est pas possible. Examinons un exemple utilisant des graphes composés de noeuds parents et de noeuds enfants pour voir quand les relations sans possession sont un moyen approprié de prévenir les cycles de références.
Prévenir les cycles de références avec Weak<T>
Jusqu’ici, nous avons démontré que l’appel à Rc::clone augmente le strong_count d’une instance Rc<T>, et qu’une instance Rc<T> n’est nettoyée que si son strong_count est à 0. Vous pouvez aussi créer une référence faible vers la valeur dans une instance Rc<T> en appelant Rc::downgrade et en passant une référence vers le Rc<T>. Les références fortes sont la façon dont vous pouvez partager la possession d’une instance Rc<T>. Les références faibles n’expriment pas une relation de possession, et leur compteur n’affecte pas le moment où une instance Rc<T> est nettoyée. Elles ne causeront pas de cycle de références, car tout cycle impliquant des références faibles sera brisé une fois que le compteur de références fortes des valeurs impliquées est à 0.
Quand vous appelez Rc::downgrade, vous obtenez un pointeur intelligent de type Weak<T>. Au lieu d’augmenter le strong_count dans l’instance Rc<T> de 1, l’appel à Rc::downgrade augmente le weak_count de 1. Le type Rc<T> utilise weak_count pour suivre combien de références Weak<T> existent, de manière similaire à strong_count. La différence est que le weak_count n’a pas besoin d’être à 0 pour que l’instance Rc<T> soit nettoyée.
Comme la valeur que Weak<T> référence pourrait avoir été libérée, pour faire quoi que ce soit avec la valeur vers laquelle un Weak<T> pointe, vous devez vous assurer que la valeur existe encore. Faites-le en appelant la méthode upgrade sur une instance Weak<T>, qui retournera un Option<Rc<T>>. Vous obtiendrez un résultat Some si la valeur Rc<T> n’a pas encore été libérée et un résultat None si la valeur Rc<T> a été libérée. Comme upgrade retourné un Option<Rc<T>>, Rust s’assurera que les cas Some et None sont gérés, et il n’y aura pas de pointeur invalide.
Comme exemple, plutôt que d’utiliser une liste dont les éléments ne connaissent que l’élément suivant, nous allons créer un arbre dont les éléments connaissent leurs éléments enfants et leurs éléments parents.
Créer une structure de données en arbre
Pour commencer, nous allons construire un arbre avec des noeuds qui connaissent leurs noeuds enfants. Nous allons créer une struct nommée Node qui contient sa propre valeur i32 ainsi que des références vers les valeurs de ses Node enfants : Filename: src/main.rs rust {{#rustdoc_include ../listings/ch15-smart-pointers/listing-15-27/src/main.rs:here}}
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
value: i32,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
children: RefCell::new(vec![]),
});
let branch = Rc::new(Node {
value: 5,
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
}Nous voulons qu’un Node possède ses enfants, et nous voulons partager cette possession avec des variables afin de pouvoir accéder directement à chaque Node dans l’arbre. Pour ce faire, nous définissons les éléments du Vec<T> comme des valeurs de type Rc<Node>. Nous voulons aussi modifier quels noeuds sont les enfants d’un autre noeud, donc nous avons un RefCell<T> dans children autour du Vec<Rc<Node>>.
Ensuite, nous utiliserons notre définition de struct pour créer une instance Node nommée leaf avec la valeur 3 et sans enfants, et une autre instance nommée branch avec la valeur 5 et leaf comme l’un de ses enfants, comme montré dans l’encart 15-27.
use std::cell::RefCell;
use std::rc::Rc;
#[derive(Debug)]
struct Node {
value: i32,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
children: RefCell::new(vec![]),
});
let branch = Rc::new(Node {
value: 5,
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
}leaf node with no children and a branch node with leaf as one of its childrenNous clonons le Rc<Node> dans leaf et le stockons dans branch, ce qui signifie que le Node dans leaf a maintenant deux propriétaires : leaf et branch. Nous pouvons aller de branch à leaf via branch.children, mais il n’y à aucun moyen d’aller de leaf à branch. La raison est que leaf n’a pas de référence vers branch et ne sait pas qu’ils sont liés. Nous voulons que leaf sache que branch est son parent. Nous ferons cela ensuite.
Ajouter une référence d’un enfant vers son parent
Pour que le noeud enfant connaisse son parent, nous devons ajouter un champ parent à notre définition de la struct Node. La difficulté réside dans le choix du type de parent. Nous savons qu’il ne peut pas contenir un Rc<T>, car cela créerait un cycle de références avec leaf.parent pointant vers branch et branch.children pointant vers leaf, ce qui ferait que leurs valeurs strong_count ne seraient jamais à 0.
En réfléchissant aux relations d’une autre manière, un noeud parent devrait posséder ses enfants : si un noeud parent est libéré, ses noeuds enfants devraient l’être aussi. Cependant, un enfant ne devrait pas posséder son parent : si nous libérons un noeud enfant, le parent devrait toujours exister. C’est un cas d’utilisation pour les références faibles !
Donc, au lieu de Rc<T>, nous allons faire en sorte que le type de parent utilise Weak<T>, spécifiquement un RefCell<Weak<Node>>. Maintenant, notre définition de la struct Node ressemble à ceci : Filename: src/main.rs rust {{#rustdoc_include ../listings/ch15-smart-pointers/listing-15-28/src/main.rs:here}}
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
}Un noeud pourra faire référence à son noeud parent mais ne possède pas son parent. Dans l’encart 15-28, nous mettons à jour main pour utiliser cette nouvelle définition afin que le noeud leaf ait un moyen de faire référence à son parent, branch.
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
}leaf node with a weak reference to its parent node, branchLa création du noeud leaf ressemble à l’encart 15-27 à l’exception du champ parent : leaf commence sans parent, donc nous créons une nouvelle instance de référence Weak<Node> vide.
À ce stade, quand nous essayons d’obtenir une référence vers le parent de leaf en utilisant la méthode upgrade, nous obtenons une valeur None. Nous voyons cela dans la sortie de la première instruction println! : text leaf parent = None
leaf parent = None
Quand nous créons le noeud branch, il aura aussi une nouvelle référence Weak<Node> dans le champ parent car branch n’a pas de noeud parent. Nous avons toujours leaf comme l’un des enfants de branch. Une fois que nous avons l’instance Node dans branch, nous pouvons modifier leaf pour lui donner une référence Weak<Node> vers son parent. Nous utilisons la méthode borrow_mut sur le RefCell<Weak<Node>> dans le champ parent de leaf, puis nous utilisons la fonction Rc::downgrade pour créer une référence Weak<Node> vers branch à partir du Rc<Node> dans branch.
Quand nous affichons le parent de leaf à nouveau, cette fois nous obtenons une variante Some contenant branch : maintenant leaf peut accéder à son parent ! Quand nous affichons leaf, nous évitons aussi le cycle qui finissait par un débordement de pile comme dans l’encart 15-26 ; les références Weak<Node> sont affichées comme (Weak) : text leaf parent = Some(Node { value: 5, parent: RefCell { value: (Weak) }, children: RefCell { value: [Node { value: 3, parent: RefCell { value: (Weak) }, children: RefCell { value: [] } }] } })
leaf parent = Some(Node { value: 5, parent: RefCell { value: (Weak) },
children: RefCell { value: [Node { value: 3, parent: RefCell { value: (Weak) },
children: RefCell { value: [] } }] } })
L’absence de sortie infinie indique que ce code n’a pas créé de cycle de références. Nous pouvons aussi le constater en regardant les valeurs que nous obtenons en appelant Rc::strong_count et Rc::weak_count.
Visualiser les changements de strong_count et weak_count
Voyons comment les valeurs strong_count et weak_count des instances Rc<Node> changent en créant une nouvelle portée intérieure et en déplaçant la création de branch dans cette portée. Ce faisant, nous pouvons voir ce qui se passe quand branch est créé puis libéré quand il sort de la portée. Les modifications sont montrées dans l’encart 15-29.
use std::cell::RefCell;
use std::rc::{Rc, Weak};
#[derive(Debug)]
struct Node {
value: i32,
parent: RefCell<Weak<Node>>,
children: RefCell<Vec<Rc<Node>>>,
}
fn main() {
let leaf = Rc::new(Node {
value: 3,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![]),
});
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
{
let branch = Rc::new(Node {
value: 5,
parent: RefCell::new(Weak::new()),
children: RefCell::new(vec![Rc::clone(&leaf)]),
});
*leaf.parent.borrow_mut() = Rc::downgrade(&branch);
println!(
"branch strong = {}, weak = {}",
Rc::strong_count(&branch),
Rc::weak_count(&branch),
);
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}
println!("leaf parent = {:?}", leaf.parent.borrow().upgrade());
println!(
"leaf strong = {}, weak = {}",
Rc::strong_count(&leaf),
Rc::weak_count(&leaf),
);
}branch in an inner scope and examining strong and weak reference countsAprès la création de leaf, son Rc<Node> à un compteur fort de 1 et un compteur faible de 0. Dans la portée intérieure, nous créons branch et l’associons à leaf, à ce moment-là, quand nous affichons les compteurs, le Rc<Node> dans branch aura un compteur fort de 1 et un compteur faible de 1 (pour leaf.parent pointant vers branch avec un Weak<Node>). Quand nous affichons les compteurs dans leaf, nous verrons qu’il aura un compteur fort de 2 car branch a maintenant un clone du Rc<Node> de leaf stocké dans branch.children mais aura toujours un compteur faible de 0.
Quand la portée intérieure se terminé, branch sort de la portée et le compteur fort du Rc<Node> diminue à 0, donc son Node est libéré. Le compteur faible de 1 provenant de leaf.parent n’à aucune incidence sur le fait que Node soit libéré ou non, donc nous n’avons aucune fuite de mémoire !
Si nous essayons d’accéder au parent de leaf après la fin de la portée, nous obtiendrons à nouveau None. À la fin du programme, le Rc<Node> dans leaf à un compteur fort de 1 et un compteur faible de 0 car la variable leaf est à nouveau la seule référence vers le Rc<Node>.
Toute la logique qui gère les compteurs et la libération des valeurs est intégrée dans Rc<T> et Weak<T> et dans leurs implémentations du trait Drop. En spécifiant que la relation d’un enfant vers son parent devrait être une référence Weak<T> dans la définition de Node, vous pouvez avoir des noeuds parents pointant vers des noeuds enfants et vice versa sans créer de cycle de références ni de fuites de mémoire.
Résumé
Ce chapitre a couvert comment utiliser les pointeurs intelligents pour obtenir des garanties et des compromis différents de ceux que Rust offre par défaut avec les références classiques. Le type Box<T> à une taille connue et pointe vers des données allouées sur le tas. Le type Rc<T> suit le nombre de références vers des données sur le tas afin que les données puissent avoir plusieurs propriétaires. Le type RefCell<T> avec sa mutabilité intérieure nous donne un type que nous pouvons utiliser quand nous avons besoin d’un type immuable mais devons changer une valeur intérieure de ce type ; il applique aussi les règles d’emprunt à l’exécution plutôt qu’à la compilation.
Nous avons aussi discuté des traits Deref et Drop, qui permettent une grande partie de la fonctionnalité des pointeurs intelligents. Nous avons exploré les cycles de références qui peuvent provoquer des fuites de mémoire et comment les prévenir en utilisant Weak<T>.
Si ce chapitre a piqué votre curiosité et que vous voulez implémenter vos propres pointeurs intelligents, consultez [“The Rustonomicon”][nomicon] pour plus d’informations utiles.
Ensuite, nous parlerons de la concurrence en Rust. Vous apprendrez même quelques nouveaux pointeurs intelligents.
La concurrence sans crainte
Gérer la programmation concurrente de manière sûre et efficace est un autre des objectifs majeurs de Rust. La programmation concurrente, dans laquelle différentes parties d’un programme s’exécutent indépendamment, et la programmation parallèle, dans laquelle différentes parties d’un programme s’exécutent en même temps, deviennent de plus en plus importantes à mesure que les ordinateurs tirent parti de leurs multiples processeurs. Historiquement, programmer dans ces contextes a été difficile et source d’erreurs. Rust espère changer cela.
Au départ, l’équipe Rust pensait que garantir la sécurité de la mémoire et prévenir les problèmes de concurrence étaient deux défis distincts à résoudre avec des méthodes différentes. Au fil du temps, l’équipe a découvert que les systèmes de possession et de types constituent un ensemble d’outils puissants pour gérer la sécurité de la mémoire et les problèmes de concurrence ! En tirant parti de la possession et de la vérification de types, de nombreuses erreurs de concurrence sont des erreurs de compilation en Rust plutôt que des erreurs d’exécution. Par conséquent, plutôt que de vous faire passer beaucoup de temps à essayer de reproduire les circonstances exactes dans lesquelles un bogue de concurrence à l’exécution se produit, le code incorrect refusera de compiler et présentera une erreur expliquant le problème. En conséquence, vous pouvez corriger votre code pendant que vous travaillez dessus plutôt que potentiellement après qu’il a été déployé en production. Nous avons surnommé cet aspect de Rust la concurrence sans crainte (fearless concurrency). La concurrence sans crainte vous permet d’écrire du code exempt de bogues subtils et facile à refactoriser sans introduire de nouveaux bogues.
Remarque : par souci de simplicité, nous désignerons bon nombre de problèmes comme concurrents plutôt que d’être plus précis en disant concurrents et/ou parallèles. Pour ce chapitre, veuillez mentalement substituer concurrent et/ou parallèle chaque fois que nous utilisons concurrent. Dans le chapitre suivant, où la distinction est plus importante, nous serons plus précis.
De nombreux langages sont dogmatiques quant aux solutions qu’ils proposent pour gérer les problèmes de concurrence. Par exemple, Erlang dispose de fonctionnalités élégantes pour la concurrence par passage de messages mais n’offre que des moyens obscurs de partager l’état entre les threads. Ne supporter qu’un sous-ensemble de solutions possibles est une stratégie raisonnable pour les langages de haut niveau car un langage de haut niveau promet des avantages en abandonnant un certain contrôle pour gagner en abstraction. Cependant, les langages de bas niveau sont censés fournir la solution offrant les meilleures performances dans n’importe quelle situation et disposent de moins d’abstractions par rapport au matériel. Par conséquent, Rust offre une variété d’outils pour modéliser les problèmes de la manière la plus appropriée à votre situation et vos besoins.
Voici les sujets que nous aborderons dans ce chapitre :
- Comment créer des threads pour exécuter plusieurs morceaux de code en même temps
- La concurrence par passage de messages, où des canaux envoient des messages entre les threads
- La concurrence par état partagé, où plusieurs threads ont accès à une même donnée
- Les traits
SyncetSend, qui étendent les garanties de concurrence de Rust aux types définis par l’utilisateur ainsi qu’aux types fournis par la bibliothèque standard
Utiliser les tâches pour exécuter du code simultanément
Utiliser les tâches pour exécuter du code simultanément
Dans la plupart des systèmes d’exploitation actuels, le code d’un programme exécuté s’exécute dans un processus, et le système d’exploitation gère plusieurs processus en même temps. Au sein d’un programme, vous pouvez aussi avoir des parties indépendantes qui s’exécutent simultanément. Les fonctionnalités qui exécutent ces parties indépendantes sont appelées threads. Par exemple, un serveur web pourrait avoir plusieurs threads pour pouvoir répondre à plus d’une requête en même temps.
Diviser le calcul de votre programme en plusieurs threads pour exécuter plusieurs tâches en même temps peut améliorer les performances, mais cela ajouté aussi de la complexité. Comme les threads peuvent s’exécuter simultanément, il n’y à aucune garantie inhérente sur l’ordre dans lequel les parties de votre code sur différents threads s’exécuteront. Cela peut mener à des problèmes, tels que : - Les conditions de course (race conditions), dans lesquelles les threads accèdent à des données ou des ressources dans un ordre incohérent - Les interblocages (deadlocks), dans lesquels deux threads s’attendent mutuellement, empêchant les deux threads de continuer - Les bogues qui ne se produisent que dans certaines situations et sont difficiles à reproduire et à corriger de manière fiable
- Les conditions de course, où les threads accèdent à des données ou des ressources dans un ordre incohérent
- Les interblocages, où deux threads s’attendent mutuellement, empêchant les deux threads de continuer
- Les bogues qui ne surviennent que dans certaines situations et sont difficiles à reproduire et à corriger de manière fiable
Rust tente d’atténuer les effets négatifs de l’utilisation des threads, mais programmer dans un contexte multi-thread nécessite toujours une réflexion soigneuse et une structure de code différente de celle des programmes s’exécutant dans un seul thread.
Les langages de programmation implémentent les threads de différentes manières, et de nombreux systèmes d’exploitation fournissent une API que le langage de programmation peut appeler pour créer de nouveaux threads. La bibliothèque standard de Rust utilise un modèle d’implémentation de threads 1:1, dans lequel un programme utilise un thread du système d’exploitation par thread du langage. Il existe des crates qui implémentent d’autres modèles de threading avec des compromis différents du modèle 1:1. (Le système async de Rust, que nous verrons dans le prochain chapitre, fournit aussi une autre approche de la concurrence.)
Créer un nouveau thread avec spawn
Pour créer un nouveau thread, nous appelons la fonction thread::spawn et lui passons une closure (nous avons parlé des closures au chapitre 13) contenant le code que nous voulons exécuter dans le nouveau thread. L’exemple de l’encart 16-1 affiche du texte depuis le thread principal et d’autre texte depuis un nouveau thread.
use std::thread;
use std::time::Duration;
fn main() {
thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
}Notez que lorsque le thread principal d’un programme Rust se terminé, tous les threads créés sont arrêtés, qu’ils aient fini ou non de s’exécuter. La sortie de ce programme peut être légèrement différente à chaque fois, mais elle ressemblera à ceci :
hi number 1 from the main thread!
hi number 1 from the spawned thread!
hi number 2 from the main thread!
hi number 2 from the spawned thread!
hi number 3 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the main thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
Les appels à thread::sleep forcent un thread à arrêter son exécution pendant une courte durée, permettant à un autre thread de s’exécuter. Les threads alterneront probablement, mais ce n’est pas garanti : cela dépend de la façon dont votre système d’exploitation planifie les threads. Dans cette exécution, le thread principal a affiché en premier, même si l’instruction d’affichage du thread créé apparaît en premier dans le code. Et même si nous avons demandé au thread créé d’afficher jusqu’à ce que i soit 9, il n’a atteint que 5 avant que le thread principal ne s’arrête.
Si vous exécutez ce code et ne voyez que la sortie du thread principal, ou ne voyez aucun chevauchement, essayez d’augmenter les nombres dans les plages pour créer plus d’opportunités pour le système d’exploitation de basculer entre les threads.
Attendre que tous les threads aient fini
Le code de l’encart 16-1 non seulement arrête prématurément le thread créé la plupart du temps en raison de la fin du thread principal, mais comme il n’y à aucune garantie sur l’ordre dans lequel les threads s’exécutent, nous ne pouvons pas non plus garantir que le thread créé s’exécutera du tout !
Nous pouvons corriger le problème du thread créé qui ne s’exécute pas ou qui se terminé prématurément en sauvegardant la valeur de retour de thread::spawn dans une variable. Le type de retour de thread::spawn est JoinHandle<T>. Un JoinHandle<T> est une valeur possédée qui, quand nous appelons la méthode join dessus, attendra que son thread finisse. L’encart 16-2 montre comment utiliser le JoinHandle<T> du thread que nous avons créé dans l’encart 16-1 et comment appeler join pour s’assurer que le thread créé finisse avant que main ne se terminé.
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
handle.join().unwrap();
}JoinHandle<T> from thread::spawn to guarantee the thread is run to completionAppeler join sur le handle bloque le thread actuellement en cours d’exécution jusqu’à ce que le thread représenté par le handle se terminé. Bloquer un thread signifie que ce thread est empêché de travailler ou de se terminer. Comme nous avons placé l’appel à join après la boucle for du thread principal, l’exécution de l’encart 16-2 devrait produire une sortie similaire à ceci :
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 1 from the spawned thread!
hi number 3 from the main thread!
hi number 2 from the spawned thread!
hi number 4 from the main thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
Les deux threads continuent d’alterner, mais le thread principal attend à cause de l’appel à handle.join() et ne se terminé pas tant que le thread créé n’a pas fini.
Mais voyons ce qui se passe quand nous déplaçons handle.join() avant la boucle for dans main, comme ceci :
use std::thread;
use std::time::Duration;
fn main() {
let handle = thread::spawn(|| {
for i in 1..10 {
println!("hi number {i} from the spawned thread!");
thread::sleep(Duration::from_millis(1));
}
});
handle.join().unwrap();
for i in 1..5 {
println!("hi number {i} from the main thread!");
thread::sleep(Duration::from_millis(1));
}
}Le thread principal attendra que le thread créé finisse puis exécutera sa boucle for, donc la sortie ne sera plus entrelacée, comme montré ici :
hi number 1 from the spawned thread!
hi number 2 from the spawned thread!
hi number 3 from the spawned thread!
hi number 4 from the spawned thread!
hi number 5 from the spawned thread!
hi number 6 from the spawned thread!
hi number 7 from the spawned thread!
hi number 8 from the spawned thread!
hi number 9 from the spawned thread!
hi number 1 from the main thread!
hi number 2 from the main thread!
hi number 3 from the main thread!
hi number 4 from the main thread!
De petits détails, comme l’endroit où join est appelé, peuvent affecter le fait que vos threads s’exécutent ou non en même temps.
Utiliser les closures move avec les threads
Nous utiliserons souvent le mot-clé move avec les closures passées à thread::spawn car la closure prendra alors la possession des valeurs qu’elle utilise de l’environnement, transférant ainsi la possession de ces valeurs d’un thread à un autre. Dans [“Capturer des références ou transférer la possession”][capture] au chapitre 13, nous avons discuté de move dans le contexte des closures. Maintenant, nous allons nous concentrer davantage sur l’interaction entre move et thread::spawn.
Remarquez dans l’encart 16-1 que la closure que nous passons à thread::spawn ne prend aucun argument : nous n’utilisons aucune donnée du thread principal dans le code du thread créé. Pour utiliser des données du thread principal dans le thread créé, la closure du thread créé doit capturer les valeurs dont elle a besoin. L’encart 16-3 montre une tentative de créer un vecteur dans le thread principal et de l’utiliser dans le thread créé. Cependant, cela ne fonctionnera pas encore, comme vous le verrez dans un instant.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {v:?}");
});
handle.join().unwrap();
}La closure utilise v, donc elle va capturer v et en faire partie de l’environnement de la closure. Comme thread::spawn exécute cette closure dans un nouveau thread, nous devrions pouvoir accéder à v dans ce nouveau thread. Mais quand nous compilons cet exemple, nous obtenons l’erreur suivante : console {{#include ../listings/ch16-fearless-concurrency/listing-16-03/output.txt}}
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0373]: closure may outlive the current function, but it borrows `v`, which is owned by the current function
--> src/main.rs:6:32
|
6 | let handle = thread::spawn(|| {
| ^^ may outlive borrowed value `v`
7 | println!("Here's a vector: {v:?}");
| - `v` is borrowed here
|
note: function requires argument type to outlive `'static`
--> src/main.rs:6:18
|
6 | let handle = thread::spawn(|| {
| __________________^
7 | | println!("Here's a vector: {v:?}");
8 | | });
| |______^
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
For more information about this error, try `rustc --explain E0373`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Rust infère comment capturer v, et comme println! n’a besoin que d’une référence vers v, la closure essaie d’emprunter v. Cependant, il y à un problème : Rust ne peut pas déterminer combien de temps le thread créé s’exécutera, donc il ne sait pas si la référence vers v sera toujours valide.
L’encart 16-4 fournit un scénario qui a plus de chances d’avoir une référence vers v qui ne sera pas valide.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(|| {
println!("Here's a vector: {v:?}");
});
drop(v); // oh no!
handle.join().unwrap();
}v from a main thread that drops vSi Rust nous permettait d’exécuter ce code, il y aurait une possibilité que le thread créé soit immédiatement mis en arrière-plan sans s’exécuter du tout. Le thread créé contient une référence vers v, mais le thread principal libère immédiatement v, en utilisant la fonction drop dont nous avons discuté au chapitre 15. Ensuite, quand le thread créé commence à s’exécuter, v n’est plus valide, donc une référence vers lui est également invalide. Oh non !
Pour corriger l’erreur de compilation de l’encart 16-3, nous pouvons suivre le conseil du message d’erreur :
help: to force the closure to take ownership of `v` (and any other referenced variables), use the `move` keyword
|
6 | let handle = thread::spawn(move || {
| ++++
En ajoutant le mot-clé move avant la closure, nous forçons la closure à prendre la possession des valeurs qu’elle utilise plutôt que de permettre à Rust d’inférer qu’elle devrait emprunter les valeurs. La modification de l’encart 16-3 montrée dans l’encart 16-5 compilera et s’exécutera comme nous le souhaitons.
use std::thread;
fn main() {
let v = vec![1, 2, 3];
let handle = thread::spawn(move || {
println!("Here's a vector: {v:?}");
});
handle.join().unwrap();
}move keyword to force a closure to take ownership of the values it usesNous pourrions être tentés d’essayer la même chose pour corriger le code de l’encart 16-4 où le thread principal appelait drop en utilisant une closure move. Cependant, cette correction ne fonctionnera pas car ce que l’encart 16-4 essaie de faire est interdit pour une raison différente. Si nous ajoutions move à la closure, nous déplacerions v dans l’environnement de la closure, et nous ne pourrions plus appeler drop dessus dans le thread principal. Nous obtiendrions plutôt cette erreur de compilation : console {{#include ../listings/ch16-fearless-concurrency/output-only-01-move-drop/output.txt}}
$ cargo run
Compiling threads v0.1.0 (file:///projects/threads)
error[E0382]: use of moved value: `v`
--> src/main.rs:10:10
|
4 | let v = vec![1, 2, 3];
| - move occurs because `v` has type `Vec<i32>`, which does not implement the `Copy` trait
5 |
6 | let handle = thread::spawn(move || {
| ------- value moved into closure here
7 | println!("Here's a vector: {v:?}");
| - variable moved due to use in closure
...
10 | drop(v); // oh no!
| ^ value used here after move
|
help: consider cloning the value before moving it into the closure
|
6 ~ let value = v.clone();
7 ~ let handle = thread::spawn(move || {
8 ~ println!("Here's a vector: {value:?}");
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `threads` (bin "threads") due to 1 previous error
Les règles de possession de Rust nous ont sauvés encore une fois ! Nous avons eu une erreur du code de l’encart 16-3 car Rust était conservateur et n’empruntait que v pour le thread, ce qui signifiait que le thread principal pouvait théoriquement invalider la référence du thread créé. En disant à Rust de déplacer la possession de v vers le thread créé, nous garantissons à Rust que le thread principal n’utilisera plus v. Si nous modifions l’encart 16-4 de la même manière, nous violons alors les règles de possession quand nous essayons d’utiliser v dans le thread principal. Le mot-clé move remplace le comportement conservateur par défaut de Rust qui est d’emprunter ; il ne nous permet pas de violer les règles de possession.
Maintenant que nous avons couvert ce que sont les threads et les méthodes fournies par l’API des threads, examinons quelques situations dans lesquelles nous pouvons utiliser les threads.
Transférer des données entre les tâches avec le passage de messages
Transférer des données entre les tâches avec le passage de messages
Une approche de plus en plus populaire pour assurer une concurrence sûre est le passage de messages, où les threads ou les acteurs communiquent en s’envoyant mutuellement des messages contenant des données. Voici l’idée résumée dans un slogan de la documentation du langage Go : “Ne communiquez pas en partageant de la mémoire ; au contraire, partagez de la mémoire en communiquant.”
Pour accomplir la concurrence par envoi de messages, la bibliothèque standard de Rust fournit une implémentation de canaux (channels). Un canal est un concept de programmation général par lequel des données sont envoyées d’un thread à un autre.
Vous pouvez imaginer un canal en programmation comme un canal d’eau directionnel, tel qu’un ruisseau ou une rivière. Si vous mettez quelque chose comme un canard en caoutchouc dans une rivière, il voyagera en aval jusqu’à la fin du cours d’eau.
Un canal a deux moitiés : un émetteur (transmitter) et un récepteur (receiver). La moitié émettrice est l’emplacement en amont où vous mettez le canard en caoutchouc dans la rivière, et la moitié réceptrice est l’endroit où le canard en caoutchouc finit en aval. Une partie de votre code appelle des méthodes sur l’émetteur avec les données que vous voulez envoyer, et une autre partie vérifie l’extrémité réceptrice pour les messages arrivant. Un canal est dit fermé si l’une où l’autre des moitiés, émettrice ou réceptrice, est libérée.
Ici, nous allons construire un programme qui à un thread pour générer des valeurs et les envoyer dans un canal, et un autre thread qui recevra les valeurs et les affichera. Nous enverrons des valeurs simples entre les threads en utilisant un canal pour illustrer la fonctionnalité. Une fois que vous serez familier avec la technique, vous pourrez utiliser des canaux pour tous les threads qui doivent communiquer entre eux, comme un système de chat ou un système où de nombreux threads effectuent des parties d’un calcul et envoient les parties à un thread qui agrège les résultats.
D’abord, dans l’encart 16-6, nous allons créer un canal mais ne rien faire avec. Notez que cela ne compilera pas encore car Rust ne peut pas déterminer quel type de valeurs nous voulons envoyer dans le canal.
use std::sync::mpsc;
fn main() {
let (tx, rx) = mpsc::channel();
}tx and rxNous créons un nouveau canal en utilisant la fonction mpsc::channel ; mpsc signifie multiple producer, single consumer (multiples producteurs, consommateur unique). En bref, la façon dont la bibliothèque standard de Rust implémente les canaux signifie qu’un canal peut avoir plusieurs extrémités émettrices qui produisent des valeurs mais une seule extrémité réceptrice qui consomme ces valeurs. Imaginez plusieurs ruisseaux se rejoignant dans une grande rivière : tout ce qui est envoyé dans n’importe lequel des ruisseaux finira dans une seule rivière à la fin. Nous commencerons avec un seul producteur pour l’instant, mais nous ajouterons plusieurs producteurs quand cet exemple fonctionnera.
La fonction mpsc::channel retourné un tuple, dont le premier élément est l’extrémité émettrice – l’émetteur – et le second élément est l’extrémité réceptrice – le récepteur. Les abréviations tx et rx sont traditionnellement utilisées dans de nombreux domaines pour transmitter (émetteur) et receiver (récepteur), respectivement, donc nous nommons nos variables ainsi pour indiquer chaque extrémité. Nous utilisons une instruction let avec un motif qui déstructure les tuples ; nous aborderons l’utilisation des motifs dans les instructions let et la déstructuration au chapitre 19. Pour l’instant, sachez qu’utiliser une instruction let de cette manière est une approche pratique pour extraire les éléments du tuple retourné par mpsc::channel.
Déplaçons l’extrémité émettrice dans un thread créé et faisons-lui envoyer une chaîne de caractères pour que le thread créé communique avec le thread principal, comme montré dans l’encart 16-7. C’est comme mettre un canard en caoutchouc en amont de la rivière ou envoyer un message de chat d’un thread à un autre.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
});
}tx to a spawned thread and sending "hi"Encore une fois, nous utilisons thread::spawn pour créer un nouveau thread puis move pour déplacer tx dans la closure afin que le thread créé possède tx. Le thread créé a besoin de posséder l’émetteur pour pouvoir envoyer des messages à travers le canal.
L’émetteur à une méthode send qui prend la valeur que nous voulons envoyer. La méthode send retourné un type Result<T, E>, donc si le récepteur a déjà été libéré et qu’il n’y a nulle part où envoyer une valeur, l’opération d’envoi retournera une erreur. Dans cet exemple, nous appelons unwrap pour paniquer en cas d’erreur. Mais dans une vraie application, nous la gérerions correctement : retournez au chapitre 9 pour revoir les stratégies de gestion d’erreurs appropriées.
Dans l’encart 16-8, nous récupérerons la valeur depuis le récepteur dans le thread principal. C’est comme récupérer le canard en caoutchouc de l’eau à la fin de la rivière ou recevoir un message de chat.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
});
let received = rx.recv().unwrap();
println!("Got: {received}");
}"hi" in the main thread and printing itLe récepteur a deux méthodes utiles : recv et try_recv. Nous utilisons recv, abréviation de receive (recevoir), qui bloquera l’exécution du thread principal et attendra jusqu’à ce qu’une valeur soit envoyée dans le canal. Une fois qu’une valeur est envoyée, recv la retournera dans un Result<T, E>. Quand l’émetteur se ferme, recv retournera une erreur pour signaler qu’il n’y aura plus de valeurs.
La méthode try_recv ne bloque pas, mais retourné immédiatement un Result<T, E> : une valeur Ok contenant un message s’il y en à un disponible et une valeur Err s’il n’y a pas de messages cette fois. Utiliser try_recv est utile si ce thread a d’autres tâches à effectuer en attendant les messages : nous pourrions écrire une boucle qui appelle try_recv régulièrement, gère un message s’il y en à un disponible, et sinon fait d’autres tâches pendant un petit moment avant de vérifier à nouveau.
Nous avons utilisé recv dans cet exemple par simplicité ; nous n’avons pas d’autre travail à faire pour le thread principal que d’attendre des messages, donc bloquer le thread principal est approprié.
Quand nous exécutons le code de l’encart 16-8, nous verrons la valeur affichée depuis le thread principal :
Got: hi
Parfait !
Transférer la possession via les canaux
Les règles de possession jouent un rôle vital dans l’envoi de messages car elles vous aident à écrire du code concurrent sûr. Prévenir les erreurs dans la programmation concurrente est l’avantage de penser à la possession tout au long de vos programmes Rust. Faisons une expérience pour montrer comment les canaux et la possession fonctionnent ensemble pour prévenir les problèmes : nous essaierons d’utiliser une valeur val dans le thread créé après l’avoir envoyée dans le canal. Essayez de compiler le code de l’encart 16-9 pour voir pourquoi ce code n’est pas autorisé.
use std::sync::mpsc;
use std::thread;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let val = String::from("hi");
tx.send(val).unwrap();
println!("val is {val}");
});
let received = rx.recv().unwrap();
println!("Got: {received}");
}val after we’ve sent it down the channelIci, nous essayons d’afficher val après l’avoir envoyé dans le canal via tx.send. Permettre cela serait une mauvaise idée : une fois que la valeur a été envoyée à un autre thread, ce thread pourrait la modifier ou la libérer avant que nous essayions d’utiliser la valeur à nouveau. Potentiellement, les modifications de l’autre thread pourraient causer des erreurs ou des résultats inattendus en raison de données incohérentes ou inexistantes. Cependant, Rust nous donne une erreur si nous essayons de compiler le code de l’encart 16-9 : console {{#include ../listings/ch16-fearless-concurrency/listing-16-09/output.txt}}
$ cargo run
Compiling message-passing v0.1.0 (file:///projects/message-passing)
error[E0382]: borrow of moved value: `val`
--> src/main.rs:10:27
|
8 | let val = String::from("hi");
| --- move occurs because `val` has type `String`, which does not implement the `Copy` trait
9 | tx.send(val).unwrap();
| --- value moved here
10 | println!("val is {val}");
| ^^^ value borrowed here after move
|
= note: this error originates in the macro `$crate::format_args_nl` which comes from the expansion of the macro `println` (in Nightly builds, run with -Z macro-backtrace for more info)
For more information about this error, try `rustc --explain E0382`.
error: could not compile `message-passing` (bin "message-passing") due to 1 previous error
Notre erreur de concurrence a causé une erreur de compilation. La fonction send prend la possession de son paramètre, et quand la valeur est déplacée, le récepteur en prend la possession. Cela nous empêche d’utiliser accidentellement la valeur à nouveau après l’avoir envoyée ; le système de possession vérifie que tout est en ordre.
Envoyer plusieurs valeurs
Le code de l’encart 16-8 a compilé et s’est exécuté, mais il ne nous a pas clairement montré que deux threads séparés communiquaient entre eux via le canal.
Dans l’encart 16-10, nous avons fait quelques modifications qui prouveront que le code de l’encart 16-8 s’exécute de manière concurrente : le thread créé enverra maintenant plusieurs messages et fera une pause d’une seconde entre chaque message.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
let (tx, rx) = mpsc::channel();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {received}");
}
}Cette fois, le thread créé à un vecteur de chaînes de caractères que nous voulons envoyer au thread principal. Nous itérons dessus, en envoyant chacune individuellement, et faisons une pause entre chacune en appelant la fonction thread::sleep avec une valeur Duration d’une seconde.
Dans le thread principal, nous n’appelons plus la fonction recv explicitement : à la place, nous traitons rx comme un itérateur. Pour chaque valeur reçue, nous l’affichons. Quand le canal est fermé, l’itération se terminera.
Lors de l’exécution du code de l’encart 16-10, vous devriez voir la sortie suivante avec une pause d’une seconde entre chaque ligne :
Got: hi
Got: from
Got: the
Got: thread
Comme nous n’avons aucun code qui fait des pauses ou des délais dans la boucle for du thread principal, nous pouvons en déduire que le thread principal attend de recevoir des valeurs du thread créé.
Créer plusieurs producteurs
Plus tôt, nous avons mentionné que mpsc était un acronyme pour multiple producer, single consumer (multiples producteurs, consommateur unique). Mettons mpsc en pratique et enrichissons le code de l’encart 16-10 pour créer plusieurs threads qui envoient tous des valeurs au même récepteur. Nous pouvons le faire en clonant l’émetteur, comme montré dans l’encart 16-11.
use std::sync::mpsc;
use std::thread;
use std::time::Duration;
fn main() {
// --snip--
let (tx, rx) = mpsc::channel();
let tx1 = tx.clone();
thread::spawn(move || {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("thread"),
];
for val in vals {
tx1.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
thread::spawn(move || {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
for received in rx {
println!("Got: {received}");
}
// --snip--
}Cette fois, avant de créer le premier thread, nous appelons clone sur l’émetteur. Cela nous donnera un nouvel émetteur que nous pouvons passer au premier thread créé. Nous passons l’émetteur original à un second thread créé. Cela nous donne deux threads, chacun envoyant des messages différents au même récepteur.
Quand vous exécutez le code, votre sortie devrait ressembler à ceci :
Got: hi
Got: more
Got: from
Got: messages
Got: for
Got: the
Got: thread
Got: you
Vous pourriez voir les valeurs dans un autre ordre, selon votre système. C’est ce qui rend la concurrence intéressante mais aussi difficile. Si vous expérimentez avec thread::sleep, en lui donnant des valeurs variées dans les différents threads, chaque exécution sera plus non déterministe et créera une sortie différente à chaque fois.
Maintenant que nous avons vu comment les canaux fonctionnent, examinons une méthode différente de concurrence.
La concurrence à état partagé
La concurrence à état partagé
Le passage de messages est un bon moyen de gérer la concurrence, mais ce n’est pas le seul. Une autre méthode serait que plusieurs threads accèdent aux mêmes données partagées. Considérez à nouveau cette partie du slogan de la documentation du langage Go : “Ne communiquez pas en partageant de la mémoire.”
À quoi ressemblerait la communication par partage de mémoire ? Et pourquoi les partisans du passage de messages recommanderaient-ils de ne pas utiliser le partage de mémoire ?
D’une certaine manière, les canaux dans n’importe quel langage de programmation sont similaires à la possession unique car une fois que vous transférez une valeur dans un canal, vous ne devriez plus utiliser cette valeur. La concurrence par mémoire partagée est comme la possession multiple : plusieurs threads peuvent accéder au même emplacement mémoire en même temps. Comme vous l’avez vu au chapitre 15, où les pointeurs intelligents rendaient possible la possession multiple, la possession multiple peut ajouter de la complexité car ces différents propriétaires doivent être gérés. Le système de types de Rust et les règles de possession aident grandement à effectuer cette gestion correctement. Pour un exemple, examinons les mutex, l’une des primitives de concurrence les plus courantes pour la mémoire partagée.
Contrôler l’accès avec les mutex
Mutex est une abréviation de mutual exclusion (exclusion mutuelle), car un mutex ne permet qu’à un seul thread d’accéder à certaines données à un moment donné. Pour accéder aux données dans un mutex, un thread doit d’abord signaler qu’il veut y accéder en demandant à acquérir le verrou du mutex. Le verrou (lock) est une structure de données qui fait partie du mutex et qui suit qui a actuellement l’accès exclusif aux données. Par conséquent, le mutex est décrit comme gardant les données qu’il contient via le système de verrouillage.
Les mutex ont la réputation d’être difficiles à utiliser car vous devez vous souvenir de deux règles :
- Vous devez tenter d’acquérir le verrou avant d’utiliser les données.
- Quand vous avez fini avec les données que le mutex garde, vous devez déverrouiller les données pour que d’autres threads puissent acquérir le verrou.
Pour une métaphore du monde réel d’un mutex, imaginez une table ronde lors d’une conférence avec un seul microphone. Avant qu’un panéliste puisse parler, il doit demander ou signaler qu’il veut utiliser le microphone. Quand il obtient le microphone, il peut parler aussi longtemps qu’il le souhaite puis passer le microphone au prochain panéliste qui demande à parler. Si un panéliste oublie de passer le microphone quand il a fini, personne d’autre ne peut parler. Si la gestion du microphone partagé se passe mal, la table ronde ne fonctionnera pas comme prévu !
La gestion des mutex peut être incroyablement délicate à réaliser correctement, c’est pourquoi tant de gens sont enthousiastes à propos des canaux. Cependant, grâce au système de types de Rust et aux règles de possession, vous ne pouvez pas vous tromper dans le verrouillage et le déverrouillage.
L’API de Mutex<T>
Comme exemple d’utilisation d’un mutex, commençons par utiliser un mutex dans un contexte mono-thread, comme montré dans l’encart 16-12.
use std::sync::Mutex;
fn main() {
let m = Mutex::new(5);
{
let mut num = m.lock().unwrap();
*num = 6;
}
println!("m = {m:?}");
}Mutex<T> in a single-threaded context for simplicityComme avec beaucoup de types, nous créons un Mutex<T> en utilisant la fonction associée new. Pour accéder aux données à l’intérieur du mutex, nous utilisons la méthode lock pour acquérir le verrou. Cet appel bloquera le thread courant pour qu’il ne puisse faire aucun travail jusqu’à ce que ce soit notre tour d’avoir le verrou.
L’appel à lock échouerait si un autre thread détenant le verrou a paniqué. Dans ce cas, personne ne pourrait jamais obtenir le verrou, donc nous avons choisi d’utiliser unwrap et de faire paniquer ce thread si nous sommes dans cette situation.
Après avoir acquis le verrou, nous pouvons traiter la valeur de retour, nommée num dans ce cas, comme une référence mutable vers les données à l’intérieur. Le système de types garantit que nous acquérons un verrou avant d’utiliser la valeur dans m. Le type de m est Mutex<i32>, pas i32, donc nous devons appeler lock pour pouvoir utiliser la valeur i32. Nous ne pouvons pas oublier ; le système de types ne nous laissera pas accéder au i32 intérieur autrement.
L’appel à lock retourné un type appelé MutexGuard, enveloppé dans un LockResult que nous avons géré avec l’appel à unwrap. Le type MutexGuard implémente Deref pour pointer vers nos données internes ; le type a aussi une implémentation de Drop qui libère le verrou automatiquement quand un MutexGuard sort de la portée, ce qui se produit à la fin de la portée intérieure. En conséquence, nous ne risquons pas d’oublier de libérer le verrou et de bloquer le mutex pour les autres threads car la libération du verrou se fait automatiquement.
Après avoir libéré le verrou, nous pouvons afficher la valeur du mutex et voir que nous avons pu changer le i32 intérieur à 6.
Accès partagé à Mutex<T>
Maintenant, essayons de partager une valeur entre plusieurs threads en utilisant Mutex<T>. Nous allons lancer 10 threads et faire en sorte que chacun incrémente un compteur de 1, de sorte que le compteur passe de 0 à 10. L’exemple de l’encart 16-13 aura une erreur de compilation, et nous utiliserons cette erreur pour en apprendre davantage sur l’utilisation de Mutex<T> et comment Rust nous aide à l’utiliser correctement.
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Mutex::new(0);
let mut handles = vec![];
for _ in 0..10 {
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Mutex<T>Nous créons une variable counter pour contenir un i32 dans un Mutex<T>, comme nous l’avons fait dans l’encart 16-12. Ensuite, nous créons 10 threads en itérant sur une plage de nombres. Nous utilisons thread::spawn et donnons à tous les threads la même closure : une qui déplace le compteur dans le thread, acquiert un verrou sur le Mutex<T> en appelant la méthode lock, puis ajouté 1 à la valeur dans le mutex. Quand un thread finit d’exécuter sa closure, num sortira de la portée et libérera le verrou pour qu’un autre thread puisse l’acquérir.
Dans le thread principal, nous collectons tous les handles de jointure. Ensuite, comme nous l’avons fait dans l’encart 16-2, nous appelons join sur chaque handle pour nous assurer que tous les threads finissent. À ce stade, le thread principal acquerra le verrou et affichera le résultat de ce programme.
Nous avons suggéré que cet exemple ne compilerait pas. Maintenant, découvrons pourquoi ! console {{#include ../listings/ch16-fearless-concurrency/listing-16-13/output.txt}}
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0382]: borrow of moved value: `counter`
--> src/main.rs:21:29
|
5 | let counter = Mutex::new(0);
| ------- move occurs because `counter` has type `std::sync::Mutex<i32>`, which does not implement the `Copy` trait
...
8 | for _ in 0..10 {
| -------------- inside of this loop
9 | let handle = thread::spawn(move || {
| ------- value moved into closure here, in previous iteration of loop
...
21 | println!("Result: {}", *counter.lock().unwrap());
| ^^^^^^^ value borrowed here after move
|
help: consider moving the expression out of the loop so it is only moved once
|
8 ~ let mut value = counter.lock();
9 ~ for _ in 0..10 {
10 | let handle = thread::spawn(move || {
11 ~ let mut num = value.unwrap();
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
Le message d’erreur indique que la valeur counter a été déplacée dans l’itération précédente de la boucle. Rust nous dit que nous ne pouvons pas déplacer la possession du verrou counter dans plusieurs threads. Corrigeons l’erreur de compilation avec la méthode de possession multiple dont nous avons discuté au chapitre 15.
Possession multiple avec plusieurs threads
Au chapitre 15, nous avons donné une valeur à plusieurs propriétaires en utilisant le pointeur intelligent Rc<T> pour créer une valeur à comptage de références. Faisons la même chose ici et voyons ce qui se passe. Nous enveloppons le Mutex<T> dans un Rc<T> dans l’encart 16-14 et clonons le Rc<T> avant de transférer la possession au thread.
use std::rc::Rc;
use std::sync::Mutex;
use std::thread;
fn main() {
let counter = Rc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Rc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Rc<T> to allow multiple threads to own the Mutex<T>Encore une fois, nous compilons et obtenons… des erreurs différentes ! Le compilateur nous en apprend beaucoup : console {{#include ../listings/ch16-fearless-concurrency/listing-16-14/output.txt}}
$ cargo run
Compiling shared-state v0.1.0 (file:///projects/shared-state)
error[E0277]: `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ------------- ^------
| | |
| ______________________|_____________within this `{closure@src/main.rs:11:36: 11:43}`
| | |
| | required by a bound introduced by this call
12 | | let mut num = counter.lock().unwrap();
13 | |
14 | | *num += 1;
15 | | });
| |_________^ `Rc<std::sync::Mutex<i32>>` cannot be sent between threads safely
|
= help: within `{closure@src/main.rs:11:36: 11:43}`, the trait `Send` is not implemented for `Rc<std::sync::Mutex<i32>>`
note: required because it's used within this closure
--> src/main.rs:11:36
|
11 | let handle = thread::spawn(move || {
| ^^^^^^^
note: required by a bound in `spawn`
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/thread/mod.rs:723:1
For more information about this error, try `rustc --explain E0277`.
error: could not compile `shared-state` (bin "shared-state") due to 1 previous error
Le message d’erreur est très verbeux ! Voici la partie importante sur laquelle se concentrer : `Rc<Mutex<i32>>` cannot be sent between threads safely (ne peut pas être envoyé entre les threads de manière sûre). Le compilateur nous dit aussi pourquoi : the trait `Send` is not implemented for `Rc<Mutex<i32>>`. Nous parlerons de Send dans la prochaine section : c’est l’un des traits qui garantit que les types que nous utilisons avec les threads sont destinés à être utilisés dans des situations concurrentes.
Malheureusement, Rc<T> n’est pas sûr à partager entre les threads. Quand Rc<T> gère le compteur de références, il ajouté au compteur pour chaque appel à clone et soustrait du compteur quand chaque clone est libéré. Mais il n’utilise aucune primitive de concurrence pour s’assurer que les modifications du compteur ne peuvent pas être interrompues par un autre thread. Cela pourrait mener à des compteurs erronés – des bogues subtils qui pourraient à leur tour provoquer des fuites de mémoire ou une valeur libérée avant que nous en ayons fini avec elle. Ce dont nous avons besoin est un type exactement comme Rc<T>, mais qui modifié le compteur de références de manière sûre pour les threads.
Comptage de références atomique avec Arc<T>
Heureusement, Arc<T> est un type comme Rc<T> qui est sûr à utiliser dans des situations concurrentes. Le a signifie atomic (atomique), ce qui signifie que c’est un type à comptage de références atomique. Les atomiques sont un type supplémentaire de primitive de concurrence que nous ne couvrirons pas en détail ici : consultez la documentation de la bibliothèque standard pour [std::sync::atomic][atomic] pour plus de détails. À ce stade, vous avez juste besoin de savoir que les atomiques fonctionnent comme les types primitifs mais sont sûrs à partager entre les threads.
Vous pourriez alors vous demander pourquoi tous les types primitifs ne sont pas atomiques et pourquoi les types de la bibliothèque standard ne sont pas implémentés pour utiliser Arc<T> par défaut. La raison est que la sécurité des threads à un coût en performance que vous ne voulez payer que quand vous en avez vraiment besoin. Si vous effectuez simplement des opérations sur des valeurs dans un seul thread, votre code peut s’exécuter plus rapidement s’il n’a pas à appliquer les garanties que fournissent les atomiques.
Revenons à notre exemple : Arc<T> et Rc<T> ont la même API, donc nous corrigeons notre programme en changeant la ligne use, l’appel à new, et l’appel à clone. Le code de l’encart 16-15 compilera et s’exécutera enfin.
use std::sync::{Arc, Mutex};
use std::thread;
fn main() {
let counter = Arc::new(Mutex::new(0));
let mut handles = vec![];
for _ in 0..10 {
let counter = Arc::clone(&counter);
let handle = thread::spawn(move || {
let mut num = counter.lock().unwrap();
*num += 1;
});
handles.push(handle);
}
for handle in handles {
handle.join().unwrap();
}
println!("Result: {}", *counter.lock().unwrap());
}Arc<T> to wrap the Mutex<T> to be able to share ownership across multiple threadsCe code affichera ce qui suit :
Result: 10
Nous avons réussi ! Nous avons compté de 0 à 10, ce qui peut ne pas sembler très impressionnant, mais cela nous a beaucoup appris sur Mutex<T> et la sécurité des threads. Vous pourriez aussi utiliser la structure de ce programme pour effectuer des opérations plus complexes que simplement incrémenter un compteur. En utilisant cette stratégie, vous pouvez diviser un calcul en parties indépendantes, répartir ces parties entre les threads, puis utiliser un Mutex<T> pour que chaque thread mette à jour le résultat final avec sa partie.
Notez que si vous effectuez des opérations numériques simples, il existe des types plus simples que les types Mutex<T> fournis par le [module std::sync::atomic de la bibliothèque standard][atomic]. Ces types fournissent un accès sûr, concurrent et atomique aux types primitifs. Nous avons choisi d’utiliser Mutex<T> avec un type primitif pour cet exemple afin de pouvoir nous concentrer sur le fonctionnement de Mutex<T>.
Comparer RefCell<T>/Rc<T> et Mutex<T>/Arc<T>
Vous avez peut-être remarqué que counter est immuable mais que nous pouvions obtenir une référence mutable vers la valeur à l’intérieur ; cela signifie que Mutex<T> fournit la mutabilité intérieure, comme la famille Cell. De la même manière que nous avons utilisé RefCell<T> au chapitre 15 pour nous permettre de modifier le contenu à l’intérieur d’un Rc<T>, nous utilisons Mutex<T> pour modifier le contenu à l’intérieur d’un Arc<T>.
Un autre détail à noter est que Rust ne peut pas vous protéger de tous les types d’erreurs logiques quand vous utilisez Mutex<T>. Rappelez-vous du chapitre 15 que l’utilisation de Rc<T> comportait le risque de créer des cycles de références, où deux valeurs Rc<T> se réfèrent mutuellement, provoquant des fuites de mémoire. De même, Mutex<T> comporte le risque de créer des interblocages (deadlocks). Ceux-ci se produisent quand une opération a besoin de verrouiller deux ressources et que deux threads ont chacun acquis l’un des verrous, les faisant s’attendre mutuellement pour toujours. Si vous êtes intéressé par les interblocages, essayez de créer un programme Rust qui à un interblocage ; puis, recherchez les stratégies d’atténuation des interblocages pour les mutex dans n’importe quel langage et essayez de les implémenter en Rust. La documentation de l’API de la bibliothèque standard pour Mutex<T> et MutexGuard offre des informations utiles.
Nous terminerons ce chapitre en parlant des traits Send et Sync et de la façon dont nous pouvons les utiliser avec des types personnalisés.
La concurrence extensible avec Send et Sync
La concurrence extensible avec Send et Sync
Fait intéressant, presque toutes les fonctionnalités de concurrence dont nous avons parlé jusqu’à présent dans ce chapitre font partie de la bibliothèque standard, pas du langage lui-même. Vos options pour gérer la concurrence ne se limitent pas au langage ou à la bibliothèque standard ; vous pouvez écrire vos propres fonctionnalités de concurrence ou utiliser celles écrites par d’autres.
Cependant, parmi les concepts clés de concurrence qui sont intégrés dans le langage plutôt que dans la bibliothèque standard, on trouve les traits marqueurs std::marker Send et Sync.
Transférer la possession entre les threads
Le trait marqueur Send indique que la possession des valeurs du type implémentant Send peut être transférée entre les threads. Presque tous les types Rust implémentent Send, mais il existe quelques exceptions, notamment Rc<T> : celui-ci ne peut pas implémenter Send car si vous cloniez une valeur Rc<T> et tentiez de transférer la possession du clone à un autre thread, les deux threads pourraient mettre à jour le compteur de références en même temps. Pour cette raison, Rc<T> est conçu pour être utilisé dans des situations mono-thread où vous ne voulez pas payer la pénalité de performance liée à la sécurité des threads.
Par conséquent, le système de types de Rust et les contraintes de traits garantissent que vous ne pouvez jamais envoyer accidentellement une valeur Rc<T> entre les threads de manière non sûre. Lorsque nous avons essayé de le faire dans l’encart 16-14, nous avons obtenu l’erreur the trait `Send` is not implemented for `Rc<Mutex<i32>>`. Lorsque nous sommes passés à Arc<T>, qui implémente bien Send, le code a compilé.
Tout type composé entièrement de types Send est automatiquement marqué comme Send également. Presque tous les types primitifs sont Send, à l’exception des pointeurs bruts, dont nous parlerons au chapitre 20.
Accéder depuis plusieurs threads
Le trait marqueur Sync indique qu’il est sûr pour le type implémentant Sync d’être référencé depuis plusieurs threads. En d’autres termes, tout type T implémente Sync si &T (une référence immuable vers T) implémente Send, ce qui signifie que la référence peut être envoyée en toute sécurité vers un autre thread. De manière similaire à Send, les types primitifs implémentent tous Sync, et les types composés entièrement de types qui implémentent Sync implémentent également Sync.
Le pointeur intelligent Rc<T> n’implémente pas non plus Sync pour les mêmes raisons qu’il n’implémente pas Send. Le type RefCell<T> (dont nous avons parlé au chapitre 15) et la famille de types Cell<T> associés n’implémentent pas Sync. L’implémentation de la vérification des emprunts que RefCell<T> effectue à l’exécution n’est pas sûre pour les threads. Le pointeur intelligent Mutex<T> implémente Sync et peut être utilisé pour partager l’accès avec plusieurs threads, comme vous l’avez vu dans [“Accès partagé à Mutex<T>”][shared-access].
Implémenter Send et Sync manuellement n’est pas sûr
Comme les types composés entièrement d’autres types qui implémentent les traits Send et Sync implémentent aussi automatiquement Send et Sync, nous n’avons pas besoin d’implémenter ces traits manuellement. En tant que traits marqueurs, ils n’ont même pas de méthodes à implémenter. Ils sont simplement utiles pour appliquer des invariants liés à la concurrence.
Implémenter ces traits manuellement implique d’écrire du code Rust non sûr (unsafe). Nous parlerons de l’utilisation du code Rust unsafe au chapitre 20 ; pour l’instant, l’information importante est que construire de nouveaux types concurrents qui ne sont pas composés de parties Send et Sync nécessite une réflexion approfondie pour respecter les garanties de sécurité. [“The Rustonomicon”][nomicon] contient plus d’informations sur ces garanties et comment les respecter.
Résumé
Ce n’est pas la dernière fois que vous verrez la concurrence dans ce livre : le prochain chapitre se concentre sur la programmation asynchrone, et le projet du chapitre 21 utilisera les concepts de ce chapitre dans une situation plus réaliste que les petits exemples abordés ici.
Comme mentionné précédemment, étant donné que très peu de la façon dont Rust gère la concurrence fait partie du langage, de nombreuses solutions de concurrence sont implémentées sous forme de crates. Celles-ci évoluent plus rapidement que la bibliothèque standard, alors n’hésitez pas à chercher en ligne les crates actuelles et à la pointe pour les situations multi-threads.
La bibliothèque standard de Rust fournit des canaux pour le passage de messages et des types de pointeurs intelligents, tels que Mutex<T> et Arc<T>, qui sont sûrs à utiliser dans des contextes concurrents. Le système de types et le vérificateur d’emprunts garantissent que le code utilisant ces solutions ne se retrouvera pas avec des courses de données ou des références invalides. Une fois que votre code compilé, vous pouvez être assuré qu’il fonctionnera sans problème sur plusieurs threads, sans les types de bogues difficiles à traquer qui sont courants dans d’autres langages. La programmation concurrente n’est plus un concept à craindre : allez de l’avant et rendez vos programmes concurrents, sans crainte !
Les fondamentaux de la programmation asynchrone : Async, Await, Futures et Streams
De nombreuses opérations que nous demandons à l’ordinateur d’effectuer peuvent prendre un certain temps. Ce serait bien de pouvoir faire autre chose en attendant que ces processus longs se terminent. Les ordinateurs modernes offrent deux techniques pour travailler sur plusieurs opérations à la fois : le parallélisme et la concurrence. Cependant, la logique de nos programmes est écrite de manière essentiellement linéaire. Nous aimerions pouvoir spécifier les opérations qu’un programme doit effectuer et les points auxquels une fonction pourrait se mettre en pause pour laisser une autre partie du programme s’exécuter à la place, sans avoir besoin de spécifier à l’avance l’ordre exact et la manière dont chaque morceau de code doit s’exécuter. La programmation asynchrone est une abstraction qui nous permet d’exprimer notre code en termes de points de pause potentiels et de résultats finaux, tout en prenant en charge les détails de la coordination pour nous.
Ce chapitre s’appuie sur l’utilisation des threads du chapitre 16 pour le parallélisme et la concurrence, en présentant une approche alternative pour écrire du code : les futures, les streams, et la syntaxe async et await de Rust qui nous permettent d’exprimer comment les opérations pourraient être asynchrones, ainsi que les crates tierces qui implémentent des runtimes asynchrones : du code qui gère et coordonne l’exécution des opérations asynchrones.
Prenons un exemple. Imaginons que vous exportez une vidéo d’une fête de famille, une opération qui peut prendre de quelques minutes à plusieurs heures. L’exportation vidéo utilisera autant de puissance CPU et GPU que possible. Si vous n’aviez qu’un seul cœur CPU et que votre système d’exploitation ne mettait pas en pause cette exportation avant qu’elle ne soit terminée — c’est-à-dire s’il exécutait l’exportation de manière synchrone — vous ne pourriez rien faire d’autre sur votre ordinateur pendant l’exécution de cette tâche. Ce serait une expérience assez frustrante. Heureusement, le système d’exploitation de votre ordinateur peut, et le fait, interrompre invisiblement l’exportation assez souvent pour vous permettre de faire d’autres choses en même temps.
Maintenant, imaginons que vous téléchargez une vidéo partagée par quelqu’un d’autre, ce qui peut aussi prendre du temps mais ne consomme pas autant de temps CPU. Dans ce cas, le CPU doit attendre que les données arrivent du réseau. Bien que vous puissiez commencer à lire les données dès qu’elles commencent à arriver, il peut falloir un certain temps pour que toutes les données soient disponibles. Même une fois que toutes les données sont présentes, si la vidéo est assez volumineuse, il pourrait falloir au moins une seconde ou deux pour tout charger. Cela peut sembler peu, mais c’est très long pour un processeur moderne qui peut effectuer des milliards d’opérations par seconde. Là encore, votre système d’exploitation interrompra invisiblement votre programme pour permettre au CPU d’effectuer d’autres tâches en attendant que l’appel réseau se terminé.
L’exportation vidéo est un exemple d’opération limitée par le CPU (CPU-bound) ou limitée par le calcul (compute-bound). Elle est limitée par la vitesse potentielle de traitement des données du CPU ou du GPU, et par la part de cette vitesse qu’il peut consacrer à l’opération. Le téléchargement vidéo est un exemple d’opération limitée par les E/S (I/O-bound), car elle est limitée par la vitesse des entrées et sorties de l’ordinateur ; elle ne peut aller que aussi vite que les données peuvent être envoyées à travers le réseau.
Dans ces deux exemples, les interruptions invisibles du système d’exploitation fournissent une forme de concurrence. Cette concurrence se produit cependant uniquement au niveau du programme entier : le système d’exploitation interrompt un programme pour permettre à d’autres programmes de travailler. Dans de nombreux cas, comme nous comprenons nos programmes à un niveau bien plus granulaire que le système d’exploitation, nous pouvons repérer des opportunités de concurrence que le système d’exploitation ne peut pas voir.
Par exemple, si nous construisons un outil pour gérer les téléchargements de fichiers, nous devrions pouvoir écrire notre programme de sorte que le démarrage d’un téléchargement ne bloque pas l’interface utilisateur, et les utilisateurs devraient pouvoir démarrer plusieurs téléchargements en même temps. Cependant, de nombreuses API de systèmes d’exploitation pour interagir avec le réseau sont bloquantes ; c’est-à-dire qu’elles bloquent la progression du programme jusqu’à ce que les données qu’elles traitent soient complètement prêtes.
Remarque : c’est ainsi que fonctionnent la plupart des appels de fonctions, si vous y réfléchissez. Cependant, le terme bloquant est généralement réservé aux appels de fonctions qui interagissent avec des fichiers, le réseau ou d’autres ressources de l’ordinateur, car ce sont les cas où un programme individuel bénéficierait d’une opération non bloquante.
Nous pourrions éviter de bloquer notre thread principal en créant un thread dédié pour télécharger chaque fichier. Cependant, le surcoût des ressources système utilisées par ces threads finirait par devenir un problème. Il serait préférable que l’appel ne soit pas bloquant en premier lieu, et qu’à la place nous puissions définir un certain nombre de tâches que nous aimerions que notre programme accomplisse et laisser le runtime choisir le meilleur ordre et la meilleure manière de les exécuter.
C’est exactement ce que l’abstraction async (abréviation d’asynchrone) de Rust nous offre. Dans ce chapitre, vous apprendrez tout sur l’async en couvrant les sujets suivants :
- Comment utiliser la syntaxe
asyncetawaitde Rust et exécuter des fonctions asynchrones avec un runtime - Comment utiliser le modèle async pour résoudre certains des mêmes défis que nous avons vus au chapitre 16
- Comment le multithreading et l’async fournissent des solutions complémentaires que vous pouvez combiner dans de nombreux cas
Avant de voir comment l’async fonctionne en pratique, nous devons cependant faire un petit détour pour discuter des différences entre le parallélisme et la concurrence.
Parallélisme et concurrence
Nous avons traité le parallélisme et la concurrence comme étant largement interchangeables jusqu’à présent. Maintenant, nous devons les distinguer plus précisément, car les différences vont apparaître lorsque nous commencerons à travailler.
Considérez les différentes manières dont une équipe pourrait répartir le travail sur un projet logiciel. Vous pourriez assigner à un seul membre plusieurs tâches, assigner à chaque membre une seule tâche, ou utiliser un mélange des deux approches.
Quand un individu travaille sur plusieurs tâches différentes avant qu’aucune d’entre elles ne soit terminée, c’est de la concurrence. Une façon d’implémenter la concurrence est similaire au fait d’avoir deux projets différents ouverts sur votre ordinateur, et quand vous vous ennuyez ou êtes bloqué sur un projet, vous passez à l’autre. Vous n’êtes qu’une seule personne, donc vous ne pouvez pas progresser sur les deux tâches exactement en même temps, mais vous pouvez faire du multitâche, en progressant sur l’une à la fois en alternant entre elles (voir la figure 17-1).

Quand l’équipe répartit un groupe de tâches en faisant prendre une tâche à chaque membre pour y travailler seul, c’est du parallélisme. Chaque personne de l’équipe peut progresser exactement en même temps (voir la figure 17-2).

Dans ces deux flux de travail, vous pourriez devoir coordonner différentes tâches. Peut-être pensiez-vous que la tâche assignée à une personne était totalement indépendante du travail de tout le monde, mais elle nécessite en fait qu’une autre personne de l’équipe terminé d’abord sa tâche. Une partie du travail pouvait être fait en parallèle, mais une autre partie était en réalité sérielle : elle ne pouvait se faire qu’en série, une tâche après l’autre, comme dans la figure 17-3.

De même, vous pourriez réaliser qu’une de vos propres tâches dépend d’une autre de vos tâches. Votre travail concurrent est alors également devenu sériel.
Le parallélisme et la concurrence peuvent également se croiser. Si vous apprenez qu’un collègue est bloqué tant que vous n’avez pas terminé une de vos tâches, vous concentrerez probablement tous vos efforts sur cette tâche pour « débloquer » votre collègue. Vous et votre collègue n’êtes plus en mesure de travailler en parallèle, et vous n’êtes plus non plus en mesure de travailler de manière concurrente sur vos propres tâches.
Les mêmes dynamiques fondamentales entrent en jeu avec les logiciels et le matériel. Sur une machine avec un seul cœur CPU, le CPU ne peut effectuer qu’une seule opération à la fois, mais il peut quand même travailler de manière concurrente. En utilisant des outils comme les threads, les processus et l’async, l’ordinateur peut mettre en pause une activité et passer à d’autres avant de revenir éventuellement à la première activité. Sur une machine avec plusieurs cœurs CPU, il peut également travailler en parallèle. Un cœur peut exécuter une tâche pendant qu’un autre cœur en exécute une complètement différente, et ces opérations se produisent réellement en même temps.
L’exécution de code async en Rust se fait généralement de manière concurrente. En fonction du matériel, du système d’exploitation et du runtime async que nous utilisons (nous en parlerons bientôt), cette concurrence peut également utiliser le parallélisme en coulisses.
Maintenant, plongeons dans le fonctionnement réel de la programmation async en Rust.
Les futures et la syntaxe async
Les futures et la syntaxe async
Les éléments clés de la programmation asynchrone en Rust sont les futures et les mots-clés async et await de Rust.
Une future est une valeur qui n’est peut-être pas prête maintenant mais qui le deviendra à un moment donné dans le futur. (Ce même concept apparaît dans de nombreux langages, parfois sous d’autres noms comme task ou promise.) Rust fournit un trait Future comme brique de base pour que différentes opérations async puissent être implémentées avec différentes structures de données mais avec une interface commune. En Rust, les futures sont des types qui implémentent le trait Future. Chaque future contient ses propres informations sur la progression réalisée et sur ce que signifie « prêt ».
Vous pouvez appliquer le mot-clé async aux blocs et aux fonctions pour spécifier qu’ils peuvent être interrompus et repris. Au sein d’un bloc async ou d’une fonction async, vous pouvez utiliser le mot-clé await pour attendre une future (c’est-à-dire attendre qu’elle devienne prête). Tout point où vous attendez une future dans un bloc ou une fonction async est un endroit potentiel pour que ce bloc ou cette fonction se mette en pause et reprenne. Le processus de vérification auprès d’une future pour voir si sa valeur est disponible s’appelle le polling (ou interrogation).
Certains autres langages, comme C# et JavaScript, utilisent également les mots-clés async et await pour la programmation asynchrone. Si vous êtes familier avec ces langages, vous remarquerez peut-être des différences significatives dans la façon dont Rust gère la syntaxe. C’est pour de bonnes raisons, comme nous le verrons !
Lorsque nous écrivons du Rust async, nous utilisons les mots-clés async et await la plupart du temps. Rust les compilé en code équivalent utilisant le trait Future, de la même manière qu’il compilé les boucles for en code équivalent utilisant le trait Iterator. Comme Rust fournit le trait Future, vous pouvez aussi l’implémenter pour vos propres types de données quand vous en avez besoin. Beaucoup de fonctions que nous verrons tout au long de ce chapitre retournent des types avec leurs propres implémentations de Future. Nous reviendrons à la définition du trait à la fin du chapitre pour approfondir son fonctionnement, mais ces détails suffisent pour avancer.
Tout cela peut sembler un peu abstrait, alors écrivons notre premier programme async : un petit web scraper. Nous passerons deux URL depuis la ligne de commande, les récupérerons toutes les deux de manière concurrente, et retournerons le résultat de celle qui finit en premier. Cet exemple comportera pas mal de nouvelle syntaxe, mais ne vous inquiétez pas — nous expliquerons tout ce que vous devez savoir au fur et à mesure.
Notre premier programme async
Pour garder l’attention de ce chapitre sur l’apprentissage de l’async plutôt que sur la gestion de l’écosystème, nous avons créé le crate trpl (trpl est l’abréviation de « The Rust Programming Language »). Il ré-exporte tous les types, traits et fonctions dont vous aurez besoin, principalement depuis les crates [futures][futures-crate] et [tokio][tokio]. Le crate futures est le lieu officiel d’expérimentation de Rust pour le code async, et c’est en fait là que le trait Future a été conçu à l’origine. Tokio est le runtime async le plus largement utilisé en Rust aujourd’hui, surtout pour les applications web. Il existe d’autres excellents runtimes qui pourraient être plus adaptés à vos besoins. Nous utilisons le crate tokio en coulisses pour trpl car il est bien testé et largement utilisé.
Dans certains cas, trpl renomme ou encapsule les API d’origine pour vous permettre de vous concentrer sur les détails pertinents pour ce chapitre. Si vous voulez comprendre ce que fait le crate, nous vous encourageons à consulter [son code source][crate-source]. Vous pourrez voir de quel crate provient chaque ré-exportation, et nous avons laissé des commentaires détaillés expliquant ce que fait le crate.
Créez un nouveau projet binaire nommé hello-async et ajoutez le crate trpl comme dépendance :
$ cargo new hello-async
$ cd hello-async
$ cargo add trpl
Nous pouvons maintenant utiliser les différents éléments fournis par trpl pour écrire notre premier programme async. Nous allons construire un petit outil en ligne de commande qui récupère deux pages web, extrait l’élément <title> de chacune, et affiche le titre de la page qui terminé ce processus en premier.
Définition de la fonction page_title
Commençons par écrire une fonction qui prend une URL de page en paramètre, effectue une requête vers celle-ci, et retourné le texte de l’élément <title> (voir l’encart 17-1).
extern crate trpl; // required for mdbook test
fn main() {
// TODO: we'll add this next!
}
use trpl::Html;
async fn page_title(url: &str) -> Option<String> {
let response = trpl::get(url).await;
let response_text = response.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}Premièrement, nous définissons une fonction nommée page_title et la marquons avec le mot-clé async. Ensuite, nous utilisons la fonction trpl::get pour récupérer l’URL passée en paramètre et ajoutons le mot-clé await pour attendre la réponse. Pour obtenir le texte de la réponse, nous appelons sa méthode text et l’attendons à nouveau avec le mot-clé await. Ces deux étapes sont asynchrones. Pour la fonction get, nous devons attendre que le serveur renvoie la première partie de sa réponse, qui inclura les en-têtes HTTP, les cookies, etc., et qui peut être délivrée séparément du corps de la réponse. Surtout si le corps est très volumineux, il peut falloir un certain temps pour qu’il arrive en entier. Comme nous devons attendre l’intégralité de la réponse, la méthode text est également async.
Nous devons explicitement attendre ces deux futures, car les futures en Rust sont paresseuses : elles ne font rien tant que vous ne leur demandez pas avec le mot-clé await. (En fait, Rust affichera un avertissement du compilateur si vous n’utilisez pas une future.) Cela pourrait vous rappeler la discussion sur les itérateurs dans la section [« Traitement d’une série d’éléments avec les itérateurs »][iterators-lazy] du chapitre 13. Les itérateurs ne font rien tant que vous n’appelez pas leur méthode next — que ce soit directement ou en utilisant des boucles for ou des méthodes comme map qui utilisent next en coulisses. De même, les futures ne font rien tant que vous ne leur demandez pas explicitement. Cette paresse permet à Rust d’éviter d’exécuter du code async tant que ce n’est pas réellement nécessaire.
section in Chapter 16, where the closure we passed to another thread started running immediately. It’s also différent from how many other languages approach async. But it’s important for Rust to be able to provide its performance guarantees, just as it is with iterators. –> Remarque : cela est différent du comportement que nous avons vu en utilisant
thread::spawndans la section [« Créer un nouveau thread avec spawn »][thread-spawn] du chapitre 16, où la closure que nous avons passée à un autre thread commençait à s’exécuter immédiatement. C’est aussi différent de la façon dont beaucoup d’autres langages abordent l’async. Mais il est important que Rust puisse fournir ses garanties de performance, tout comme avec les itérateurs.
Une fois que nous avons response_text, nous pouvons l’analyser en une instance du type Html en utilisant Html::parse. Au lieu d’une chaîne brute, nous avons maintenant un type de données que nous pouvons utiliser pour travailler avec le HTML comme une structure de données plus riche. En particulier, nous pouvons utiliser la méthode select_first pour trouver la première instance d’un sélecteur CSS donné. En passant la chaîne "title", nous obtiendrons le premier élément <title> du document, s’il y en à un. Comme il peut ne pas y avoir d’élément correspondant, select_first retourné un Option<ElementRef>. Enfin, nous utilisons la méthode Option::map, qui nous permet de travailler avec l’élément dans l’Option s’il est présent, et de ne rien faire sinon. (Nous pourrions aussi utiliser une expression match ici, mais map est plus idiomatique.) Dans le corps de la fonction que nous fournissons à map, nous appelons inner_html sur le title pour obtenir son contenu, qui est une String. Au final, nous avons un Option<String>.
Remarquez que le mot-clé await de Rust vient après l’expression que vous attendez, et non avant. C’est-à-dire que c’est un mot-clé postfixe. Cela peut différer de ce à quoi vous êtes habitué si vous avez utilisé async dans d’autres langages, mais en Rust, cela rend les chaînes de méthodes beaucoup plus agréables à utiliser. En conséquence, nous pourrions modifier le corps de page_title pour chaîner les appels de fonctions trpl::get et text avec await entre eux, comme montré dans l’encart 17-2.
extern crate trpl; // required for mdbook test
use trpl::Html;
fn main() {
// TODO: we'll add this next!
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}await keywordAvec cela, nous avons écrit avec succès notre première fonction async ! Avant d’ajouter du code dans main pour l’appeler, parlons un peu plus de ce que nous avons écrit et de ce que cela signifie.
Quand Rust voit un bloc marqué avec le mot-clé async, il le compilé en un type de données unique et anonyme qui implémente le trait Future. Quand Rust voit une fonction marquée avec async, il la compilé en une fonction non-async dont le corps est un bloc async. Le type de retour d’une fonction async est le type du type de données anonyme que le compilateur crée pour ce bloc async.
Ainsi, écrire async fn est équivalent à écrire une fonction qui retourné une future du type de retour. Pour le compilateur, une définition de fonction telle que async fn page_title dans l’encart 17-1 est à peu près équivalente à une fonction non-async définie comme ceci : rust extern crate trpl; // required for mdbook test use std::future::Future; use trpl::Html; fn page_title(url: &str) -> impl Future<Output = Option<String>> { async move { let text = trpl::get(url).await.text().await; Html::parse(&text) .select_first("title") .map(|title| title.inner_html()) } }
#![allow(unused)]
fn main() {
extern crate trpl; // required for mdbook test
use std::future::Future;
use trpl::Html;
fn page_title(url: &str) -> impl Future<Output = Option<String>> {
async move {
let text = trpl::get(url).await.text().await;
Html::parse(&text)
.select_first("title")
.map(|title| title.inner_html())
}
}
}Parcourons chaque partie de la version transformée :
- Elle utilise la syntaxe
impl Traitque nous avons abordée au chapitre 10 dans la section [« Les traits comme paramètres »][impl-trait]. - La valeur retournée implémente le trait
Futureavec un type associéOutput. Remarquez que le typeOutputestOption<String>, qui est le même que le type de retour original de la versionasync fndepage_title. - Tout le code appelé dans le corps de la fonction originale est encapsulé dans un bloc
async move. Rappelez-vous que les blocs sont des expressions. Ce bloc entier est l’expression retournée par la fonction. - Ce bloc async produit une valeur de type
Option<String>, comme décrit précédemment. Cette valeur correspond au typeOutputdans le type de retour. C’est comme les autres blocs que vous avez vus. - Le nouveau corps de la fonction est un bloc
async moveen raison de la façon dont il utilise le paramètreurl. (Nous parlerons beaucoup plus deasyncversusasync moveplus loin dans le chapitre.)
Nous pouvons maintenant appeler page_title dans main.
Exécuter une fonction async avec un runtime
Pour commencer, nous allons obtenir le titre d’une seule page, comme montré dans l’encart 17-3. Malheureusement, ce code ne compilé pas encore.
extern crate trpl; // required for mdbook test
use trpl::Html;
async fn main() {
let args: Vec<String> = std::env::args().collect();
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}page_title function from main with a user-supplied argumentNous suivons le même schéma que celui utilisé pour obtenir les arguments de la ligne de commande dans la section [« Accepter les arguments de la ligne de commande »][cli-args] du chapitre 12. Ensuite, nous passons l’argument URL à page_title et attendons le résultat. Comme la valeur produite par la future est un Option<String>, nous utilisons une expression match pour afficher différents messages selon que la page avait ou non un <title>.
Le seul endroit où nous pouvons utiliser le mot-clé await est dans les fonctions ou blocs async, et Rust ne nous laisse pas marquer la fonction spéciale main comme async.
error[E0752]: `main` function is not allowed to be `async`
--> src/main.rs:6:1
|
6 | async fn main() {
| ^^^^^^^^^^^^^^^ `main` function is not allowed to be `async`
La raison pour laquelle main ne peut pas être marquée async est que le code async a besoin d’un runtime : un crate Rust qui gère les détails de l’exécution du code asynchrone. La fonction main d’un programme peut initialiser un runtime, mais elle n’est pas un runtime elle-même. (Nous verrons bientôt pourquoi c’est le cas.) Tout programme Rust qui exécute du code async a au moins un endroit où il configure un runtime qui exécute les futures.
La plupart des langages qui supportent l’async intègrent un runtime, mais pas Rust. À la place, il existe de nombreux runtimes async différents disponibles, chacun faisant des compromis différents adaptés au cas d’utilisation qu’il cible. Par exemple, un serveur web à haut débit avec de nombreux cœurs CPU et une grande quantité de RAM à des besoins très différents d’un microcontrôleur avec un seul cœur, une petite quantité de RAM et aucune capacité d’allocation sur le tas. Les crates qui fournissent ces runtimes offrent souvent aussi des versions async de fonctionnalités courantes comme les E/S de fichiers ou réseau.
Ici, et tout au long du reste de ce chapitre, nous utiliserons la fonction block_on du crate trpl, qui prend une future en argument et bloque le thread courant jusqu’à ce que cette future s’exécute jusqu’à la fin. En coulisses, appeler block_on configure un runtime en utilisant le crate tokio qui est utilisé pour exécuter la future passée en paramètre (le comportement de block_on du crate trpl est similaire aux fonctions block_on d’autres crates de runtime). Une fois que la future est terminée, block_on retourné la valeur que la future a produite.
Nous pourrions passer la future retournée par page_title directement à block_on et, une fois terminée, faire un match sur le Option<String> résultant comme nous avons essayé de le faire dans l’encart 17-3. Cependant, pour la plupart des exemples du chapitre (et la plupart du code async dans le monde réel), nous ferons plus qu’un simple appel de fonction async, donc à la place nous passerons un bloc async et attendrons explicitement le résultat de l’appel à page_title, comme dans l’encart 17-4.
extern crate trpl; // required for mdbook test
use trpl::Html;
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let url = &args[1];
match page_title(url).await {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
})
}
async fn page_title(url: &str) -> Option<String> {
let response_text = trpl::get(url).await.text().await;
Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html())
}trpl::block_onQuand nous exécutons ce code, nous obtenons le comportement attendu initialement :
$ cargo run -- "https://www.rust-lang.org"
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.05s
Running `target/debug/async_await 'https://www.rust-lang.org'`
The title for https://www.rust-lang.org was
Rust Programming Language
Ouf — nous avons enfin du code async qui fonctionne ! Mais avant d’ajouter le code pour mettre en compétition deux sites l’un contre l’autre, tournons brièvement notre attention vers le fonctionnement des futures.
Chaque point d’attente — c’est-à-dire chaque endroit où le code utilise le mot-clé await — représente un endroit où le contrôle est rendu au runtime. Pour que cela fonctionne, Rust doit garder une trace de l’état impliqué dans le bloc async afin que le runtime puisse lancer un autre travail puis revenir quand il est prêt à essayer de faire avancer le premier à nouveau. C’est une machine à états invisible, comme si vous aviez écrit un enum comme celui-ci pour sauvegarder l’état courant à chaque point d’attente : rust {{#rustdoc_include ../listings/ch17-async-await/no-listing-state-machine/src/lib.rs:enum}}
#![allow(unused)]
fn main() {
extern crate trpl; // required for mdbook test
enum PageTitleFuture<'a> {
Initial { url: &'a str },
GetAwaitPoint { url: &'a str },
TextAwaitPoint { response: trpl::Response },
}
}Écrire le code pour effectuer la transition entre chaque état à la main serait fastidieux et source d’erreurs, surtout quand vous devez ajouter plus de fonctionnalités et plus d’états au code par la suite. Heureusement, le compilateur Rust crée et gère automatiquement les structures de données de la machine à états pour le code async. Les règles normales d’emprunt et de possession autour des structures de données s’appliquent toujours, et heureusement, le compilateur gère aussi la vérification de celles-ci pour nous et fournit des messages d’erreur utiles. Nous en verrons quelques-uns plus loin dans le chapitre.
Au final, quelque chose doit exécuter cette machine à états, et ce quelque chose est un runtime. (C’est pourquoi vous pouvez rencontrer des mentions d’exécuteurs quand vous vous renseignez sur les runtimes : un exécuteur est la partie d’un runtime responsable de l’exécution du code async.)
Vous pouvez maintenant voir pourquoi le compilateur nous a empêchés de faire de main elle-même une fonction async dans l’encart 17-3. Si main était une fonction async, quelque chose d’autre devrait gérer la machine à états pour la future que main retournerait, mais main est le point d’entrée du programme ! À la place, nous avons appelé la fonction trpl::block_on dans main pour configurer un runtime et exécuter la future retournée par le bloc async jusqu’à ce qu’elle soit terminée.
Remarque : certains runtimes fournissent des macros pour que vous puissiez écrire une fonction
mainasync. Ces macros réécriventasync fn main() { ... }en unfn mainnormal, qui fait la même chose que ce que nous avons fait manuellement dans l’encart 17-4 : appeler une fonction qui exécute une future jusqu’à son achèvement de la même manière quetrpl::block_on.
Maintenant, assemblons ces éléments et voyons comment nous pouvons écrire du code concurrent.
Mettre en compétition deux URL de manière concurrente
Dans l’encart 17-5, nous appelons page_title avec deux URL différentes passées depuis la ligne de commande et les mettons en compétition en sélectionnant la future qui terminé en premier.
extern crate trpl; // required for mdbook test
use trpl::{Either, Html};
fn main() {
let args: Vec<String> = std::env::args().collect();
trpl::block_on(async {
let title_fut_1 = page_title(&args[1]);
let title_fut_2 = page_title(&args[2]);
let (url, maybe_title) =
match trpl::select(title_fut_1, title_fut_2).await {
Either::Left(left) => left,
Either::Right(right) => right,
};
println!("{url} returned first");
match maybe_title {
Some(title) => println!("Its page title was: '{title}'"),
None => println!("It had no title."),
}
})
}
async fn page_title(url: &str) -> (&str, Option<String>) {
let response_text = trpl::get(url).await.text().await;
let title = Html::parse(&response_text)
.select_first("title")
.map(|title| title.inner_html());
(url, title)
}page_title for two URLs to see which returns firstNous commençons par appeler page_title pour chacune des URL fournies par l’utilisateur. Nous sauvegardons les futures résultantes sous les noms title_fut_1 et title_fut_2. Rappelez-vous, elles ne font encore rien, car les futures sont paresseuses et nous ne les avons pas encore attendues. Ensuite, nous passons les futures à trpl::select, qui retourné une valeur indiquant laquelle des futures passées en paramètre se terminé en premier.
Remarque : en coulisses,
trpl::selectest construit sur une fonctionselectplus générale définie dans le cratefutures. La fonctionselectdu cratefuturespeut faire beaucoup de choses que la fonctiontrpl::selectne peut pas, mais elle a aussi une complexité supplémentaire que nous pouvons ignorer pour l’instant.
L’une où l’autre des futures peut légitimement « gagner », donc il n’est pas logique de retourner un Result. À la place, trpl::select retourné un type que nous n’avons pas vu auparavant, trpl::Either. Le type Either est quelque peu similaire à un Result en ce qu’il a deux cas. Contrairement à Result, cependant, il n’y à aucune notion de succès ou d’échec intégrée dans Either. À la place, il utilise Left et Right pour indiquer « l’un où l’autre » : rust enum Either<A, B> { Left(A), Right(B), }
#![allow(unused)]
fn main() {
enum Either<A, B> {
Left(A),
Right(B),
}
}La fonction select retourné Left avec la sortie de cette future si le premier argument gagne, et Right avec la sortie du deuxième argument future si celui-là gagne. Cela correspond à l’ordre dans lequel les arguments apparaissent lors de l’appel de la fonction : le premier argument est à gauche du deuxième argument.
Nous mettons aussi à jour page_title pour retourner la même URL passée en paramètre. De cette façon, si la page qui retourné en premier n’a pas de <title> que nous pouvons résoudre, nous pouvons quand même afficher un message significatif. Avec ces informations disponibles, nous terminons en mettant à jour notre sortie println! pour indiquer à la fois quelle URL a terminé en premier et quel est, le cas échéant, le <title> de la page web à cette URL.
Vous avez maintenant construit un petit web scraper fonctionnel ! Choisissez quelques URL et exécutez l’outil en ligne de commande. Vous découvrirez peut-être que certains sites sont systématiquement plus rapides que d’autres, tandis que dans d’autres cas, le site le plus rapide varie d’une exécution à l’autre. Plus important encore, vous avez appris les bases du travail avec les futures, et nous pouvons maintenant approfondir ce que nous pouvons faire avec l’async.
Appliquer la concurrence avec async
Appliquer la concurrence avec async
Dans cette section, nous appliquerons l’async à certains des mêmes défis de concurrence que nous avons abordés avec les threads au chapitre 16. Comme nous avons déjà discuté de beaucoup d’idées clés là-bas, dans cette section nous nous concentrerons sur ce qui diffère entre les threads et les futures.
Dans de nombreux cas, les API pour travailler avec la concurrence en utilisant l’async sont très similaires à celles utilisant les threads. Dans d’autres cas, elles finissent par être assez différentes. Même quand les API semblent similaires entre les threads et l’async, elles ont souvent un comportement différent — et elles ont presque toujours des caractéristiques de performance différentes.
Créer une nouvelle tâche avec spawn_task
La première opération que nous avons abordée dans la section « Créer un nouveau thread avec spawn » du chapitre 16 était de compter sur deux threads séparés. Faisons la même chose en utilisant async. La crate trpl fournit une fonction spawn_task qui ressemble beaucoup à l’API thread::spawn, et une fonction sleep qui est une version async de l’API thread::sleep. Nous pouvons les utiliser ensemble pour implémenter l’exemple de comptage, comme le montre l’encart 17-6.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
trpl::spawn_task(async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
}Comme point de départ, nous configurons notre fonction main avec trpl::block_on pour que notre fonction de niveau supérieur puisse être async.
Remarque : à partir de maintenant dans le chapitre, chaque exemple inclura ce même code d’enveloppe avec
trpl::block_ondansmain, donc nous l’omettrons souvent comme nous le faisons avecmain. N’oubliez pas de l’inclure dans votre code !
Ensuite, nous écrivons deux boucles dans ce bloc, chacune contenant un appel à trpl::sleep, qui attend une demi-seconde (500 millisecondes) avant d’envoyer le message suivant. Nous mettons une boucle dans le corps d’un trpl::spawn_task et l’autre dans une boucle for de niveau supérieur. Nous ajoutons aussi un await après les appels à sleep.
Ce code se comporte de manière similaire à l’implémentation basée sur les threads — y compris le fait que vous pourriez voir les messages apparaître dans un ordre différent dans votre propre terminal quand vous l’exécutez :
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
Cette version s’arrête dès que la boucle for dans le corps du bloc async principal se terminé, car la tâche lancée par spawn_task est arrêtée quand la fonction main se terminé. Si vous voulez qu’elle s’exécute jusqu’à la fin de la tâche, vous devrez utiliser un handle de jointure pour attendre que la première tâche se terminé. Avec les threads, nous utilisions la méthode join pour « bloquer » jusqu’à ce que le thread ait fini de s’exécuter. Dans l’encart 17-7, nous pouvons utiliser await pour faire la même chose, car le handle de tâche est lui-même une future. Son type Output est un Result, donc nous le déballons aussi après l’avoir attendu.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let handle = trpl::spawn_task(async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
});
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
handle.await.unwrap();
});
}await with a join handle to run a task to completionCette version mise à jour s’exécute jusqu’à ce que les deux boucles soient terminées :
hi number 1 from the second task!
hi number 1 from the first task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
Jusqu’ici, il semble que l’async et les threads nous donnent des résultats similaires, juste avec une syntaxe différente : utiliser await au lieu d’appeler join sur le handle de jointure, et attendre les appels à sleep.
La plus grande différence est que nous n’avons pas eu besoin de créer un autre thread du système d’exploitation pour faire cela. En fait, nous n’avons même pas besoin de lancer une tâche ici. Comme les blocs async se compilent en futures anonymes, nous pouvons mettre chaque boucle dans un bloc async et laisser le runtime les exécuter toutes les deux jusqu’à leur achèvement en utilisant la fonction trpl::join.
Dans la section « Attendre la fin de tous les threads » du chapitre 16, nous avons utilisé la méthode join pour nous assurer que le programme n’arrêtait pas avant que les threads générés aient terminé. Nous avons besoin du même type de mécanisme ici : nous avons besoin d’un moyen d’attendre que la tâche async se terminé avant de continuer.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let fut1 = async {
for i in 1..10 {
println!("hi number {i} from the first task!");
trpl::sleep(Duration::from_millis(500)).await;
}
};
let fut2 = async {
for i in 1..5 {
println!("hi number {i} from the second task!");
trpl::sleep(Duration::from_millis(500)).await;
}
};
trpl::join(fut1, fut2).await;
});
}trpl::join to await two anonymous futuresQuand nous exécutons cela, nous voyons les deux futures s’exécuter jusqu’à leur achèvement :
hi number 1 from the first task!
hi number 1 from the second task!
hi number 2 from the first task!
hi number 2 from the second task!
hi number 3 from the first task!
hi number 3 from the second task!
hi number 4 from the first task!
hi number 4 from the second task!
hi number 5 from the first task!
hi number 6 from the first task!
hi number 7 from the first task!
hi number 8 from the first task!
hi number 9 from the first task!
Maintenant, vous verrez exactement le même ordre à chaque fois, ce qui est très différent de ce que nous avons vu avec les threads et avec trpl::spawn_task dans l’encart 17-7. C’est parce que la fonction trpl::join est équitable, ce qui signifie qu’elle vérifie chaque future aussi souvent, en alternant entre elles, et ne laisse jamais l’une prendre de l’avance si l’autre est prête. Avec les threads, le système d’exploitation décide quel thread vérifier et combien de temps le laisser s’exécuter. Avec le Rust async, c’est le runtime qui décide quelle tâche vérifier. (En pratique, les détails se compliquent car un runtime async peut utiliser des threads du système d’exploitation en coulisses dans le cadre de sa gestion de la concurrence, donc garantir l’équité peut demander plus de travail pour un runtime — mais c’est quand même possible !) Les runtimes n’ont pas à garantir l’équité pour une opération donnée, et ils offrent souvent différentes API pour vous permettre de choisir si vous voulez ou non l’équité.
Essayez quelques-unes de ces variations sur l’attente des futures et voyez ce qu’elles font :
- Retirez le bloc async autour de l’une où des deux boucles.
- Attendez chaque bloc async immédiatement après l’avoir défini.
- N’encapsulez que la première boucle dans un bloc async, et attendez la future résultante après le corps de la deuxième boucle.
Pour un défi supplémentaire, essayez de deviner quelle sera la sortie dans chaque cas avant d’exécuter le code !
Envoyer des données entre deux tâches en utilisant le passage de messages
Le partage de données entre futures vous sera aussi familier : nous utiliserons à nouveau le passage de messages, mais cette fois avec des versions async des types et des fonctions. Nous prendrons un chemin légèrement différent de celui de la section [« Transférer des données entre threads avec le passage de messages »][message-passing-threads] du chapitre 16 pour illustrer certaines des différences clés entre la concurrence basée sur les threads et celle basée sur les futures. Dans l’encart 17-9, nous commencerons avec un seul bloc async — sans lancer de tâche séparée comme nous avions lancé un thread séparé.
extern crate trpl; // required for mdbook test
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let val = String::from("hi");
tx.send(val).unwrap();
let received = rx.recv().await.unwrap();
println!("received '{received}'");
});
}tx and rxIci, nous utilisons trpl::channel, une version async de l’API de canal multiple-producteurs, unique-consommateur que nous avons utilisée avec les threads au chapitre 16. La version async de l’API est seulement un peu différente de la version basée sur les threads : elle utilise un récepteur rx mutable plutôt qu’immutable, et sa méthode recv produit une future que nous devons attendre au lieu de produire directement la valeur. Maintenant, nous pouvons envoyer des messages de l’émetteur au récepteur. Remarquez que nous n’avons pas besoin de lancer un thread séparé ni même une tâche ; nous avons simplement besoin d’attendre l’appel rx.recv.
La méthode synchrone Receiver::recv de std::mpsc::channel bloque jusqu’à recevoir un message. La méthode trpl::Receiver::recv ne le fait pas, car elle est async. Au lieu de bloquer, elle rend le contrôle au runtime jusqu’à ce qu’un message soit reçu ou que le côté émetteur du canal se ferme. En revanche, nous n’attendons pas l’appel send, car il ne bloque pas. Il n’a pas besoin de le faire, car le canal dans lequel nous envoyons est non borné.
Remarque : comme tout ce code async s’exécute dans un bloc async dans un appel à
trpl::block_on, tout ce qui est à l’intérieur peut éviter de bloquer. Cependant, le code à l’extérieur bloquera en attendant que la fonctionblock_onretourné. C’est tout l’intérêt de la fonctiontrpl::block_on: elle vous permet de choisir où bloquer sur un ensemble de code async, et donc où faire la transition entre le code sync et async.
Remarquez deux choses à propos de cet exemple. Premièrement, le message arrivera immédiatement. Deuxièmement, bien que nous utilisions une future ici, il n’y a pas encore de concurrence. Tout dans le listing se passe en séquence, comme ce serait le cas s’il n’y avait pas de futures impliquées.
Abordons la première partie en envoyant une série de messages et en dormant entre eux, comme montré dans l’encart 17-10.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
});
}await between each messageEn plus d’envoyer les messages, nous devons les recevoir. Dans ce cas, comme nous savons combien de messages arrivent, nous pourrions le faire manuellement en appelant rx.recv().await quatre fois. Dans le monde réel, cependant, nous attendrons généralement un nombre inconnu de messages, donc nous devons continuer à attendre jusqu’à ce que nous déterminions qu’il n’y a plus de messages.
Dans l’encart 16-10, nous avons utilisé une boucle for pour traiter tous les éléments reçus d’un canal synchrone. Rust n’a pas encore de moyen d’utiliser une boucle for avec une série d’éléments produits de manière asynchrone, donc nous devons utiliser une boucle que nous n’avons pas vue avant : la boucle conditionnelle while let. C’est la version boucle de la construction if let que nous avons vue dans la section [« Flux de contrôle concis avec if let et let...else »][if-let] du chapitre 6. La boucle continuera à s’exécuter tant que le motif qu’elle spécifie continue de correspondre à la valeur.
L’appel rx.recv produit une future, que nous attendons. Le runtime mettra en pause la future jusqu’à ce qu’elle soit prête. Une fois qu’un message arrive, la future se résoudra en Some(message) autant de fois qu’un message arrive. Quand le canal se ferme, que des messages soient arrivés ou non, la future se résoudra plutôt en None pour indiquer qu’il n’y a plus de valeurs et que nous devons donc arrêter d’interroger — c’est-à-dire arrêter d’attendre.
La boucle while let rassemble tout cela. Si le résultat de l’appel à rx.recv().await est Some(message), nous avons accès au message et pouvons l’utiliser dans le corps de la boucle, tout comme nous pourrions le faire avec if let. Si le résultat est None, la boucle se terminé. Chaque fois que la boucle se complète, elle atteint à nouveau le point d’attente, donc le runtime la met à nouveau en pause jusqu’à ce qu’un autre message arrive.
Le code envoie et reçoit maintenant avec succès tous les messages. Malheureusement, il reste encore quelques problèmes. D’une part, les messages n’arrivent pas à intervalles d’une demi-seconde. Ils arrivent tous en même temps, 2 secondes (2 000 millisecondes) après le démarrage du programme. D’autre part, ce programme ne se terminé jamais ! À la place, il attend indéfiniment de nouveaux messages. Vous devrez l’arrêter en utilisant ctrl-C.
Le code dans un seul bloc async s’exécute de manière linéaire
Commençons par examiner pourquoi les messages arrivent tous en même temps après le délai complet, plutôt que d’arriver avec des délais entre chacun. Dans un bloc async donné, l’ordre dans lequel les mots-clés await apparaissent dans le code est aussi l’ordre dans lequel ils sont exécutés quand le programme s’exécute.
Il n’y a qu’un seul bloc async dans l’encart 17-10, donc tout s’exécute linéairement. Il n’y a toujours pas de concurrence. Tous les appels tx.send se produisent, entrecoupés de tous les appels trpl::sleep et de leurs points d’attente associés. Ce n’est qu’ensuite que la boucle while let passe par les points d’attente des appels recv.
Pour obtenir le comportement que nous voulons, où le délai de sommeil se produit entre chaque message, nous devons mettre les opérations tx et rx dans leurs propres blocs async, comme montré dans l’encart 17-11. Ensuite, le runtime peut exécuter chacun d’eux séparément en utilisant trpl::join, comme dans l’encart 17-8. Encore une fois, nous attendons le résultat de l’appel à trpl::join, pas les futures individuelles. Si nous attendions les futures individuelles en séquence, nous nous retrouverions dans un flux séquentiel — exactement ce que nous essayons de ne pas faire.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx_fut = async {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
trpl::join(tx_fut, rx_fut).await;
});
}send and recv into their own async blocks and awaiting the futures for those blocksAvec le code mis à jour dans l’encart 17-11, les messages s’affichent à intervalles de 500 millisecondes, plutôt que tous en rafale après 2 secondes.
Déplacer la possession dans un bloc async
Le programme ne se terminé cependant toujours jamais, à cause de la façon dont la boucle while let interagit avec trpl::join :
- La future retournée par
trpl::joinne se terminé que quand les deux futures qui lui ont été passées sont terminées. - La future
tx_futse terminé une fois qu’elle a fini de dormir après l’envoi du dernier message dansvals. - La future
rx_futne se terminera pas tant que la bouclewhile letne se terminera pas. - La boucle
while letne se terminera pas tant que l’attente derx.recvne produira pasNone. - L’attente de
rx.recvne retourneraNoneque quand l’autre extrémité du canal sera fermée. - Le canal ne se fermera que si nous appelons
rx.closeou quand le côté émetteur,tx, est droppé. - Nous n’appelons
rx.closenulle part, ettxne sera pas droppé tant que le bloc async le plus externe passé àtrpl::block_onne se terminera pas. - Le bloc ne peut pas se terminer car il est bloqué en attendant que
trpl::joinse terminé, ce qui nous ramène en haut de cette liste.
Actuellement, le bloc async où nous envoyons les messages ne fait qu’emprunter tx car l’envoi d’un message ne nécessite pas la possession, mais si nous pouvions déplacer tx dans ce bloc async, il serait droppé une fois que ce bloc se terminé. Dans la section « Capturer des références ou déplacer la possession » du chapitre 13, vous avez appris à utiliser le mot-clé move avec les closures, et comme discuté dans la section « Utiliser les closures move avec les threads » du chapitre 16, nous devons souvent déplacer des données dans les closures quand nous travaillons avec les threads. Les mêmes dynamiques fondamentales s’appliquent aux blocs async, donc le mot-clé move fonctionne avec les blocs async comme il le fait avec les closures.
Dans l’encart 17-12, nous changeons le bloc utilisé pour envoyer des messages de async à async move.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx_fut = async move {
// --snip--
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
trpl::join(tx_fut, rx_fut).await;
});
}Quand nous exécutons cette version du code, il se terminé proprement après l’envoi et la réception du dernier message. Voyons maintenant ce qui devrait changer pour envoyer des données depuis plus d’une future.
Joindre un nombre de futures avec la macro join!
Ce canal async est aussi un canal à producteurs multiples, donc nous pouvons appeler clone sur tx si nous voulons envoyer des messages depuis plusieurs futures, comme montré dans l’encart 17-13.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_millis(500)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
let tx_fut = async move {
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_millis(1500)).await;
}
};
trpl::join!(tx1_fut, tx_fut, rx_fut);
});
}D’abord, nous clonons tx, créant tx1 en dehors du premier bloc async. Nous déplaçons tx1 dans ce bloc comme nous l’avons fait auparavant avec tx. Puis, plus tard, nous déplaçons le tx original dans un nouveau bloc async, où nous envoyons plus de messages avec un délai légèrement plus lent. Il se trouve que nous mettons ce nouveau bloc async après le bloc async de réception des messages, mais il pourrait tout aussi bien être avant. Ce qui compte, c’est l’ordre dans lequel les futures sont attendues, pas l’ordre dans lequel elles sont créées.
Les deux blocs async pour l’envoi de messages doivent être des blocs async move pour que tx et tx1 soient tous les deux droppés quand ces blocs se terminent. Sinon, nous nous retrouverons dans la même boucle infinie qu’au départ.
Enfin, nous passons de trpl::join à trpl::join! pour gérer la future supplémentaire : la macro join! attend un nombre arbitraire de futures dont nous connaissons le nombre au moment de la compilation. Nous discuterons de l’attente d’une collection d’un nombre inconnu de futures plus loin dans ce chapitre.
Maintenant nous voyons tous les messages des deux futures d’envoi, et comme les futures d’envoi utilisent des délais légèrement différents après l’envoi, les messages sont aussi reçus à ces différents intervalles :
received 'hi'
received 'more'
received 'from'
received 'the'
received 'messages'
received 'future'
received 'for'
received 'you'
Nous avons exploré comment utiliser le passage de messages pour envoyer des données entre futures, comment le code dans un bloc async s’exécute séquentiellement, comment déplacer la possession dans un bloc async, et comment joindre plusieurs futures. Voyons maintenant comment et pourquoi indiquer au runtime qu’il peut passer à une autre tâche.
Travailler avec un nombre quelconque de futures
Céder le contrôle au runtime
Rappelez-vous dans la section « Notre premier programme async » du chapitre 17, nous avons utilisé trpl::block_on pour attendre qu’un futur unique se terminé en pilotant l’exécution manuellement.
Cela signifie que si vous effectuez beaucoup de travail dans un bloc async sans point d’attente, cette future bloquera toutes les autres futures et les empêchera de progresser. Vous entendrez parfois parler d’une future qui affame les autres futures. Dans certains cas, cela peut ne pas être grave. Cependant, si vous effectuez une configuration coûteuse ou un travail de longue durée, ou si vous avez une future qui continuera à effectuer une tâche particulière indéfiniment, vous devrez réfléchir à quand et où rendre le contrôle au runtime.
Simulons une opération de longue durée pour illustrer le problème d’affamement, puis explorons comment le résoudre. L’encart 17-14 introduit une fonction slow.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
// We will call `slow` here later
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}thread::sleep to simulate slow operationsCe code utilise std::thread::sleep au lieu de trpl::sleep pour que l’appel à slow bloque le thread courant pendant un certain nombre de millisecondes. Nous pouvons utiliser slow pour représenter des opérations du monde réel qui sont à la fois longues et bloquantes.
Dans l’encart 17-15, nous utilisons slow pour émuler ce type de travail limité par le CPU dans une paire de futures.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let a = async {
println!("'a' started.");
slow("a", 30);
slow("a", 10);
slow("a", 20);
trpl::sleep(Duration::from_millis(50)).await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
slow("b", 10);
slow("b", 15);
slow("b", 350);
trpl::sleep(Duration::from_millis(50)).await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}slow function to simulate slow operationsChaque future ne rend le contrôle au runtime qu’après avoir effectué une série d’opérations lentes. Si vous exécutez ce code, vous verrez cette sortie :
'a' started.
'a' ran for 30ms
'a' ran for 10ms
'a' ran for 20ms
'b' started.
'b' ran for 75ms
'b' ran for 10ms
'b' ran for 15ms
'b' ran for 350ms
'a' finished.
Comme dans l’encart 17-5 où nous avons utilisé trpl::select pour mettre en compétition des futures récupérant deux URL, select se terminé toujours dès que a est terminée. Il n’y a cependant pas d’entrelacement entre les appels à slow dans les deux futures. La future a fait tout son travail jusqu’à ce que l’appel trpl::sleep soit attendu, puis la future b fait tout son travail jusqu’à ce que son propre appel trpl::sleep soit attendu, et enfin la future a se terminé. Pour permettre aux deux futures de progresser entre leurs tâches lentes, nous avons besoin de points d’attente pour pouvoir rendre le contrôle au runtime. Cela signifie que nous avons besoin de quelque chose que nous pouvons attendre !
Nous pouvons déjà voir ce type de transfert se produire dans l’encart 17-15 : si nous supprimions le trpl::sleep à la fin de la future a, elle se terminerait sans que la future b ne s’exécute du tout. Essayons d’utiliser la fonction trpl::sleep comme point de départ pour laisser les opérations alterner leur progression, comme montré dans l’encart 17-16.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let one_ms = Duration::from_millis(1);
let a = async {
println!("'a' started.");
slow("a", 30);
trpl::sleep(one_ms).await;
slow("a", 10);
trpl::sleep(one_ms).await;
slow("a", 20);
trpl::sleep(one_ms).await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
trpl::sleep(one_ms).await;
slow("b", 10);
trpl::sleep(one_ms).await;
slow("b", 15);
trpl::sleep(one_ms).await;
slow("b", 350);
trpl::sleep(one_ms).await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}trpl::sleep to let operations switch off making progressNous avons ajouté des appels trpl::sleep avec des points d’attente entre chaque appel à slow. Maintenant le travail des deux futures est entrelacé :
'a' started.
'a' ran for 30ms
'b' started.
'b' ran for 75ms
'a' ran for 10ms
'b' ran for 10ms
'a' ran for 20ms
'b' ran for 15ms
'a' finished.
La future a s’exécute encore un peu avant de passer le contrôle à b, car elle appelle slow avant d’appeler trpl::sleep, mais après cela les futures alternent à chaque fois que l’une d’elles atteint un point d’attente. Dans ce cas, nous avons fait cela après chaque appel à slow, mais nous pourrions découper le travail de la manière qui à le plus de sens pour nous.
Nous ne voulons pas vraiment dormir ici : nous voulons progresser aussi vite que possible. Nous avons juste besoin de rendre le contrôle au runtime. Nous pouvons le faire directement en utilisant la fonction trpl::yield_now. Dans l’encart 17-17, nous remplaçons tous ces appels trpl::sleep par trpl::yield_now.
extern crate trpl; // required for mdbook test
use std::{thread, time::Duration};
fn main() {
trpl::block_on(async {
let a = async {
println!("'a' started.");
slow("a", 30);
trpl::yield_now().await;
slow("a", 10);
trpl::yield_now().await;
slow("a", 20);
trpl::yield_now().await;
println!("'a' finished.");
};
let b = async {
println!("'b' started.");
slow("b", 75);
trpl::yield_now().await;
slow("b", 10);
trpl::yield_now().await;
slow("b", 15);
trpl::yield_now().await;
slow("b", 350);
trpl::yield_now().await;
println!("'b' finished.");
};
trpl::select(a, b).await;
});
}
fn slow(name: &str, ms: u64) {
thread::sleep(Duration::from_millis(ms));
println!("'{name}' ran for {ms}ms");
}yield_now to let operations switch off making progressCe code est à la fois plus clair quant à l’intention réelle et peut être significativement plus rapide que l’utilisation de sleep, car les minuteries comme celle utilisée par sleep ont souvent des limites sur leur granularité. La version de sleep que nous utilisons, par exemple, dormira toujours pendant au moins une milliseconde, même si nous lui passons une Duration d’une nanoseconde. Encore une fois, les ordinateurs modernes sont rapides : ils peuvent faire beaucoup en une milliseconde !
Cela signifie que l’async peut être utile même pour les tâches limitées par le calcul, en fonction de ce que fait d’autre votre programme, car il fournit un outil utile pour structurer les relations entre différentes parties du programme (mais au prix du surcoût de la machine à états async). C’est une forme de multitâche coopératif, où chaque future à le pouvoir de déterminer quand elle cède le contrôle via les points d’attente. Chaque future a donc aussi la responsabilité d’éviter de bloquer trop longtemps. Dans certains systèmes d’exploitation embarqués basés sur Rust, c’est le seul type de multitâche !
Dans le code du monde réel, vous n’alternerez bien sûr pas habituellement les appels de fonctions avec des points d’attente à chaque ligne. Bien que céder le contrôle de cette manière soit relativement peu coûteux, ce n’est pas gratuit. Dans de nombreux cas, essayer de découper une tâche limitée par le calcul pourrait la rendre significativement plus lente, donc parfois il est préférable pour les performances globales de laisser une opération bloquer brièvement. Mesurez toujours pour voir quels sont les véritables goulots d’étranglement de performance de votre code. La dynamique sous-jacente est cependant importante à garder à l’esprit, si vous constatez beaucoup de travail s’effectuant en série alors que vous vous attendiez à ce qu’il se fasse de manière concurrente !
Construire nos propres abstractions async
Nous pouvons aussi composer des futures ensemble pour créer de nouveaux motifs. Par exemple, nous pouvons construire une fonction timeout avec les blocs de construction async que nous avons déjà. Quand nous aurons terminé, le résultat sera un autre bloc de construction que nous pourrons utiliser pour créer encore plus d’abstractions async.
L’encart 17-18 montre comment nous nous attendrions à ce que ce timeout fonctionne avec une future lente.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}timeout to run a slow operation with a time limitImplémentons cela ! Pour commencer, réfléchissons à l’API de timeout :
- Elle doit être une fonction async elle-même pour que nous puissions l’attendre.
- Son premier paramètre devrait être une future à exécuter. Nous pouvons la rendre générique pour qu’elle fonctionne avec n’importe quelle future.
- Son deuxième paramètre sera le temps maximum d’attente. Si nous utilisons une
Duration, ce sera facile de la passer àtrpl::sleep. - Elle devrait retourner un
Result. Si la future se terminé avec succès, leResultseraOkavec la valeur produite par la future. Si le timeout s’écoule en premier, leResultseraErravec la durée pendant laquelle le timeout a attendu.
L’encart 17-19 montre cette déclaration.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}
async fn timeout<F: Future>(
future_to_try: F,
max_time: Duration,
) -> Result<F::Output, Duration> {
// Here is where our implémentation will go!
}timeoutCela satisfait nos objectifs pour les types. Maintenant, réfléchissons au comportement dont nous avons besoin : nous voulons mettre en compétition la future passée en paramètre contre la durée. Nous pouvons utiliser trpl::sleep pour créer une future de minuterie à partir de la durée, et utiliser trpl::select pour exécuter cette minuterie avec la future que l’appelant passe.
Dans l’encart 17-20, nous implémentons timeout en faisant un match sur le résultat de l’attente de trpl::select.
extern crate trpl; // required for mdbook test
use std::time::Duration;
use trpl::Either;
// --snip--
fn main() {
trpl::block_on(async {
let slow = async {
trpl::sleep(Duration::from_secs(5)).await;
"Finally finished"
};
match timeout(slow, Duration::from_secs(2)).await {
Ok(message) => println!("Succeeded with '{message}'"),
Err(duration) => {
println!("Failed after {} seconds", duration.as_secs())
}
}
});
}
async fn timeout<F: Future>(
future_to_try: F,
max_time: Duration,
) -> Result<F::Output, Duration> {
match trpl::select(future_to_try, trpl::sleep(max_time)).await {
Either::Left(output) => Ok(output),
Either::Right(_) => Err(max_time),
}
}timeout with select and sleepL’implémentation de trpl::select n’est pas équitable : elle interroge toujours les arguments dans l’ordre dans lequel ils sont passés (d’autres implémentations de select choisiront aléatoirement quel argument interroger en premier). Ainsi, nous passons future_to_try à select en premier pour qu’elle ait une chance de se terminer même si max_time est une durée très courte. Si future_to_try se terminé en premier, select retournera Left avec la sortie de future_to_try. Si timer se terminé en premier, select retournera Right avec la sortie () de la minuterie.
Si future_to_try réussit et que nous obtenons un Left(output), nous retournons Ok(output). Si la minuterie de sommeil s’écoule à la place et que nous obtenons un Right(()), nous ignorons le () avec _ et retournons Err(max_time) à la place.
Avec cela, nous avons un timeout fonctionnel construit à partir de deux autres aides async. Si nous exécutons notre code, il affichera le mode d’échec après le timeout : text Failed after 2 seconds
Failed after 2 seconds
Comme les futures se composent avec d’autres futures, vous pouvez construire des outils vraiment puissants en utilisant de petits blocs de construction async. Par exemple, vous pouvez utiliser cette même approche pour combiner des timeouts avec des tentatives de reprise, et à leur tour les utiliser avec des opérations comme des appels réseau (comme ceux de l’encart 17-5).
En pratique, vous travaillerez généralement directement avec async et await, et secondairement avec des fonctions comme select et des macros comme la macro join! pour contrôler comment les futures les plus extérieures sont exécutées.
Nous avons maintenant vu plusieurs façons de travailler avec plusieurs futures en même temps. Ensuite, nous verrons comment nous pouvons travailler avec plusieurs futures en séquence au fil du temps avec les streams.
Les streams : des futures en séquence
Les streams : des futures en séquence
Rappelez-vous comment nous avons utilisé le récepteur de notre canal async plus tôt dans ce chapitre dans la section [« Passage de messages »][17-02-messages]. La méthode async recv produit une séquence d’éléments au fil du temps. C’est une instance d’un motif beaucoup plus général connu sous le nom de stream. De nombreux concepts sont naturellement représentés sous forme de streams : des éléments devenant disponibles dans une file d’attente, des morceaux de données extraits progressivement du système de fichiers quand l’ensemble complet de données est trop volumineux pour la mémoire de l’ordinateur, ou des données arrivant par le réseau au fil du temps. Comme les streams sont des futures, nous pouvons les utiliser avec tout autre type de future et les combiner de manières intéressantes. Par exemple, nous pouvons regrouper des événements pour éviter de déclencher trop d’appels réseau, définir des timeouts sur des séquences d’opérations longues, ou limiter les événements de l’interface utilisateur pour éviter de faire un travail inutile.
Nous avons vu une séquence d’éléments au chapitre 13, quand nous avons examiné le trait Iterator dans la section [« Le trait Iterator et la méthode next »][iterator-trait], mais il y a deux différences entre les itérateurs et le récepteur de canal async. La première différence est le temps : les itérateurs sont synchrones, tandis que le récepteur de canal est asynchrone. La deuxième différence est l’API. En travaillant directement avec Iterator, nous appelons sa méthode synchrone next. Avec le stream trpl::Receiver en particulier, nous avons appelé une méthode asynchrone recv à la place. Sinon, ces API sont très similaires, et cette similarité n’est pas une coïncidence. Un stream est comme une forme asynchrone d’itération. Alors que trpl::Receiver attend spécifiquement de recevoir des messages, l’API de stream à usage général est beaucoup plus large : elle fournit l’élément suivant comme le fait Iterator, mais de manière asynchrone.
La similarité entre les itérateurs et les streams en Rust signifie que nous pouvons réellement créer un stream à partir de n’importe quel itérateur. Comme avec un itérateur, nous pouvons travailler avec un stream en appelant sa méthode next puis en attendant la sortie, comme dans l’encart 17-21, qui ne compilera pas encore.
extern crate trpl; // required for mdbook test
fn main() {
trpl::block_on(async {
let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
let iter = values.iter().map(|n| n * 2);
let mut stream = trpl::stream_from_iter(iter);
while let Some(value) = stream.next().await {
println!("The value was: {value}");
}
});
}Nous commençons avec un tableau de nombres, que nous convertissons en itérateur puis sur lequel nous appelons map pour doubler toutes les valeurs. Ensuite, nous convertissons l’itérateur en stream en utilisant la fonction trpl::stream_from_iter. Puis, nous bouclons sur les éléments du stream à mesure qu’ils arrivent avec la boucle while let.
Malheureusement, quand nous essayons d’exécuter le code, il ne compilé pas et signale qu’il n’y a pas de méthode next disponible :
error[E0599]: no method named `next` found for struct `tokio_stream::iter::Iter` in the current scope
--> src/main.rs:10:40
|
10 | while let Some(value) = stream.next().await {
| ^^^^
|
= help: items from traits can only be used if the trait is in scope
help: the following traits which provide `next` are implemented but not in scope; perhaps you want to import one of them
|
1 + use crate::trpl::StreamExt;
|
1 + use futures_util::stream::stream::StreamExt;
|
1 + use std::iter::Iterator;
|
1 + use std::str::pattern::Searcher;
|
help: there is a method `try_next` with a similar name
|
10 | while let Some(value) = stream.try_next().await {
| ~~~~~~~~
Comme cette sortie l’explique, la raison de l’erreur du compilateur est que nous avons besoin du bon trait dans la portée pour pouvoir utiliser la méthode next. Compte tenu de notre discussion jusqu’à présent, vous pourriez raisonnablement vous attendre à ce que ce trait soit Stream, mais c’est en fait StreamExt. Abréviation d’extension, Ext est un motif courant dans la communauté Rust pour étendre un trait avec un autre.
Le trait Stream définit une interface de bas niveau qui combine effectivement les traits Iterator et Future. StreamExt fournit un ensemble d’API de plus haut niveau par-dessus Stream, incluant la méthode next ainsi que d’autres méthodes utilitaires similaires à celles fournies par le trait Iterator. Stream et StreamExt ne font pas encore partie de la bibliothèque standard de Rust, mais la plupart des crates de l’écosystème utilisent des définitions similaires.
La solution à l’erreur du compilateur est d’ajouter une instruction use pour trpl::StreamExt, comme dans l’encart 17-22.
extern crate trpl; // required for mdbook test
use trpl::StreamExt;
fn main() {
trpl::block_on(async {
let values = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10];
// --snip--
let iter = values.iter().map(|n| n * 2);
let mut stream = trpl::stream_from_iter(iter);
while let Some(value) = stream.next().await {
println!("The value was: {value}");
}
});
}Avec tous ces éléments assemblés, ce code fonctionne comme nous le voulons ! De plus, maintenant que nous avons StreamExt dans la portée, nous pouvons utiliser toutes ses méthodes utilitaires, tout comme avec les itérateurs.
Un regard approfondi sur les traits pour l’async
Un regard approfondi sur les traits pour l’async
Tout au long du chapitre, nous avons utilisé les traits Future, Stream et StreamExt de diverses manières. Jusqu’ici, cependant, nous avons évité d’entrer trop dans les détails de leur fonctionnement ou de la façon dont ils s’articulent ensemble, ce qui convient la plupart du temps pour votre travail Rust quotidien. Parfois, cependant, vous rencontrerez des situations où vous devrez comprendre quelques détails supplémentaires de ces traits, ainsi que le type Pin et le trait Unpin. Dans cette section, nous approfondirons juste assez pour aider dans ces scénarios, en laissant la plongée vraiment profonde à d’autre documentation.
Le trait Future
Commençons par regarder de plus près comment fonctionne le trait Future. Voici comment Rust le définit : rust use std::pin::Pin; use std::task::{Context, Poll}; pub trait Future { type Output; fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; }
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
pub trait Future {
type Output;
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
}Cette définition de trait inclut un tas de nouveaux types et aussi une syntaxe que nous n’avons pas vue auparavant, alors parcourons la définition morceau par morceau.
Premièrement, le type associé Output de Future indique en quoi la future se résout. C’est analogue au type associé Item du trait Iterator. Deuxièmement, Future à la méthode poll, qui prend une référence spéciale Pin pour son paramètre self et une référence mutable vers un type Context, et retourné un Poll<Self::Output>. Nous parlerons davantage de Pin et de Context dans un moment. Pour l’instant, concentrons-nous sur ce que la méthode retourné, le type Poll : rust pub enum Poll<T> { Ready(T), Pending, }
#![allow(unused)]
fn main() {
pub enum Poll<T> {
Ready(T),
Pending,
}
}Ce type Poll est similaire à une Option. Il à une variante qui contient une valeur, Ready(T), et une qui n’en contient pas, Pending. Cependant, Poll signifie quelque chose de très différent d’Option ! La variante Pending indique que la future a encore du travail à faire, donc l’appelant devra vérifier à nouveau plus tard. La variante Ready indique que la Future a terminé son travail et que la valeur T est disponible.
Remarque : il est rare d’avoir besoin d’appeler
polldirectement, mais si vous devez le faire, gardez à l’esprit qu’avec la plupart des futures, l’appelant ne devrait pas appelerpollà nouveau après que la future a retournéReady. Beaucoup de futures paniqueront si elles sont interrogées à nouveau après être devenues prêtes. Les futures qui peuvent être interrogées à nouveau en toute sécurité le diront explicitement dans leur documentation. C’est similaire au comportement deIterator::next.
Quand vous voyez du code qui utilise await, Rust le compilé en coulisses en code qui appelle poll. Si vous revenez à l’encart 17-4, où nous avons affiché le titre de la page pour une seule URL une fois qu’elle s’est résolue, Rust le compilé en quelque chose qui ressemble à peu près (bien que pas exactement) à ceci : rust,ignore match page_title(url).poll() { Ready(page_title) => match page_title { Some(title) => println!("The title for {url} was {title}"), None => println!("{url} had no title"), } Pending => { // But what goes here? } }
match page_title(url).poll() {
Ready(page_title) => match page_title {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
Pending => {
// But what goes here?
}
}Que devons-nous faire quand la future est encore Pending ? Nous avons besoin d’un moyen de réessayer, encore et encore, jusqu’à ce que la future soit enfin prête. En d’autres termes, nous avons besoin d’une boucle : rust,ignore let mut page_title_fut = page_title(url); loop { match page_title_fut.poll() { Ready(value) => match page_title { Some(title) => println!("The title for {url} was {title}"), None => println!("{url} had no title"), } Pending => { // continue } } }
let mut page_title_fut = page_title(url);
loop {
match page_title_fut.poll() {
Ready(value) => match page_title {
Some(title) => println!("The title for {url} was {title}"),
None => println!("{url} had no title"),
}
Pending => {
// continue
}
}
}Si Rust le compilait exactement en ce code, cependant, chaque await serait bloquant — exactement le contraire de ce que nous recherchions ! À la place, Rust s’assuré que la boucle peut passer le contrôle à quelque chose qui peut mettre en pause le travail sur cette future pour travailler sur d’autres futures puis revérifier celle-ci plus tard. Comme nous l’avons vu, ce quelque chose est un runtime async, et ce travail de planification et de coordination est l’un de ses principaux rôles.
Dans la section « Envoyer des données entre deux tâches en utilisant le passage de messages », nous avons envoyé plusieurs valeurs à travers un canal. Voyons maintenant comment recevoir ces valeurs sous forme de flux (stream) en utilisant async.
Les détails exacts de la façon dont un runtime fait cela dépassent le cadre de ce livre, mais l’essentiel est de voir les mécanismes de base des futures : un runtime interroge chaque future dont il est responsable, remettant la future en sommeil quand elle n’est pas encore prête.
Le type Pin et le trait Unpin
Dans l’encart 17-13, nous avons utilisé la macro trpl::join! pour attendre trois futures. Cependant, il est courant d’avoir une collection comme un vecteur contenant un certain nombre de futures qui ne sera pas connu avant l’exécution. Modifions l’encart 17-13 en le code de l’encart 17-23 qui met les trois futures dans un vecteur et appelle la fonction trpl::join_all à la place, ce qui ne compilera pas encore.
extern crate trpl; // required for mdbook test
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = async move {
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let rx_fut = async {
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
};
let tx_fut = async move {
// --snip--
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
};
let futures: Vec<Box<dyn Future<Output = ()>>> =
vec![Box::new(tx1_fut), Box::new(rx_fut), Box::new(tx_fut)];
trpl::join_all(futures).await;
});
}Nous mettons chaque future dans un Box pour en faire des objets trait, comme nous l’avons fait dans la section « Retourner les erreurs depuis run » au chapitre 12. (Nous couvrirons les objets trait en détail au chapitre 18.) Utiliser des objets trait nous permet de traiter chacune des futures anonymes produites par ces types comme le même type, car elles implémentent toutes le trait Future.
Cela peut être surprenant. Après tout, aucun des blocs async ne retourné quoi que ce soit, donc chacun produit une Future<Output = ()>. Rappelez-vous cependant que Future est un trait, et que le compilateur crée un enum unique pour chaque bloc async, même quand ils ont des types de sortie identiques. Tout comme vous ne pouvez pas mettre deux structs différentes écrites à la main dans un Vec, vous ne pouvez pas mélanger des enums générés par le compilateur.
Ensuite, nous passons la collection de futures à la fonction trpl::join_all et attendons le résultat. Cependant, cela ne compilé pas ; voici la partie pertinente des messages d’erreur.
error[E0277]: `dyn Future<Output = ()>` cannot be unpinned
--> src/main.rs:48:33
|
48 | trpl::join_all(futures).await;
| ^^^^^ the trait `Unpin` is not implemented for `dyn Future<Output = ()>`
|
= note: consider using the `pin!` macro
consider using `Box::pin` if you need to access the pinned value outside of the current scope
= note: required for `Box<dyn Future<Output = ()>>` to implement `Future`
note: required by a bound in `futures_util::future::join_all::JoinAll`
--> file:///home/.cargo/registry/src/index.crates.io-1949cf8c6b5b557f/futures-util-0.3.30/src/future/join_all.rs:29:8
|
27 | pub struct JoinAll<F>
| ------- required by a bound in this struct
28 | where
29 | F: Future,
| ^^^^^^ required by this bound in `JoinAll`
La note dans ce message d’erreur nous dit que nous devrions utiliser la macro pin! pour épingler les valeurs, ce qui signifie les mettre à l’intérieur du type Pin qui garantit que les valeurs ne seront pas déplacées en mémoire. Le message d’erreur dit que l’épinglage est nécessaire car dyn Future<Output = ()> doit implémenter le trait Unpin et ne le fait pas actuellement.
La fonction trpl::join_all retourné une struct appelée JoinAll. Cette struct est générique sur un type F, qui est contraint d’implémenter le trait Future. Attendre directement une future avec await épingle la future implicitement. C’est pourquoi nous n’avons pas besoin d’utiliser pin! partout où nous voulons attendre des futures.
Cependant, nous n’attendons pas directement une future ici. À la place, nous construisons une nouvelle future, JoinAll, en passant une collection de futures à la fonction join_all. La signature de join_all requiert que les types des éléments de la collection implémentent tous le trait Future, et Box<T> n’implémente Future que si le T qu’il encapsule est une future qui implémente le trait Unpin.
C’est beaucoup à absorber ! Pour vraiment comprendre, plongeons un peu plus dans le fonctionnement réel du trait Future, en particulier autour de l’épinglage. Regardez à nouveau la définition du trait Future : rust use std::pin::Pin; use std::task::{Context, Poll}; pub trait Future { type Output; // Required method fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>; }
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
pub trait Future {
type Output;
// Required method
fn poll(self: Pin<&mut Self>, cx: &mut Context<'_>) -> Poll<Self::Output>;
}
}Le paramètre cx et son type Context sont la clé pour comprendre comment un runtime sait réellement quand vérifier une future donnée tout en restant paresseux. Encore une fois, les détails de ce fonctionnement dépassent le cadre de ce chapitre, et vous n’avez généralement besoin d’y penser que lorsque vous écrivez une implémentation personnalisée de Future. Nous nous concentrerons plutôt sur le type de self, car c’est la première fois que nous voyons une méthode où self à une annotation de type. Une annotation de type pour self fonctionne comme les annotations de type pour d’autres paramètres de fonction mais avec deux différences clés :
- Elle indique à Rust quel type
selfdoit avoir pour que la méthode puisse être appelée. - Ce ne peut pas être n’importe quel type. C’est restreint au type sur lequel la méthode est implémentée, une référence ou un pointeur intelligent vers ce type, ou un
Pinencapsulant une référence vers ce type.
Nous en verrons plus sur cette syntaxe au chapitre 18. Pour l’instant, il suffit de savoir que si nous voulons interroger un futur pour vérifier s’il est Pending ou Ready(Output), nous avons besoin d’une référence mutable enveloppée dans Pin vers le type.
Pin est un wrapper pour les types semblables à des pointeurs comme &, &mut, Box et Rc. (Techniquement, Pin fonctionne avec les types qui implémentent les traits Deref ou DerefMut, mais c’est effectivement équivalent à ne travailler qu’avec des références et des pointeurs intelligents.) Pin n’est pas un pointeur lui-même et n’à aucun comportement propre comme Rc et Arc avec le comptage de références ; c’est purement un outil que le compilateur peut utiliser pour imposer des contraintes sur l’utilisation des pointeurs.
Se rappeler que await est implémenté en termes d’appels à poll commence à expliquer le message d’erreur que nous avons vu plus tôt, mais c’était en termes d’Unpin, pas de Pin. Alors comment exactement Pin est-il lié à Unpin, et pourquoi Future a-t-il besoin que self soit dans un type Pin pour appeler poll ?
Rappelez-vous du début de ce chapitre qu’une série de points d’attente dans une future est compilée en une machine à états, et le compilateur s’assuré que cette machine à états respecte toutes les règles normales de Rust concernant la sécurité, y compris l’emprunt et la possession. Pour que cela fonctionne, Rust regarde quelles données sont nécessaires entre un point d’attente et soit le point d’attente suivant, soit la fin du bloc async. Il crée ensuite une variante correspondante dans la machine à états compilée. Chaque variante obtient l’accès dont elle a besoin aux données qui seront utilisées dans cette section du code source, que ce soit en prenant possession de ces données ou en obtenant une référence mutable ou immutable vers celles-ci.
Jusqu’ici, tout va bien : si nous faisons quoi que ce soit de mal avec la possession ou les références dans un bloc async donné, le vérificateur d’emprunts nous le dira. Quand nous voulons déplacer la future qui correspond à ce bloc — comme la déplacer dans un Vec pour la passer à join_all — les choses se compliquent.
Quand nous déplaçons une future — que ce soit en la poussant dans une structure de données pour l’utiliser comme itérateur avec join_all ou en la retournant depuis une fonction — cela signifie en fait déplacer la machine à états que Rust crée pour nous. Et contrairement à la plupart des autres types en Rust, les futures que Rust crée pour les blocs async peuvent se retrouver avec des références vers elles-mêmes dans les champs de n’importe quelle variante donnée, comme montré dans l’illustration simplifiée de la figure 17-4.

Par défaut, cependant, tout objet qui à une référence vers lui-même est dangereux à déplacer, car les références pointent toujours vers l’adresse mémoire réelle de ce qu’elles référencent (voir la figure 17-5). Si vous déplacez la structure de données elle-même, ces références internes continueront de pointer vers l’ancien emplacement. Cependant, cet emplacement mémoire est maintenant invalide. D’une part, sa valeur ne sera pas mise à jour quand vous apporterez des modifications à la structure de données. D’autre part — et c’est plus important — l’ordinateur est maintenant libre de réutiliser cette mémoire à d’autres fins ! Vous pourriez finir par lire des données complètement sans rapport plus tard.

Théoriquement, le compilateur Rust pourrait essayer de mettre à jour chaque référence vers un objet chaque fois qu’il est déplacé, mais cela pourrait ajouter beaucoup de surcoût en performance, surtout si tout un réseau de références doit être mis à jour. Si nous pouvions plutôt nous assurer que la structure de données en question ne se déplace pas en mémoire, nous n’aurions pas besoin de mettre à jour les références. C’est exactement le rôle du vérificateur d’emprunts de Rust : en code sûr, il vous empêche de déplacer tout élément qui à une référence activé vers lui.
Pin s’appuie sur cela pour nous donner exactement la garantie dont nous avons besoin. Quand nous épinglons une valeur en encapsulant un pointeur vers cette valeur dans Pin, elle ne peut plus se déplacer. Ainsi, si vous avez Pin<Box<SomeType>>, vous épinglez en fait la valeur SomeType, pas le pointeur Box. La figure 17-6 illustre ce processus.

En fait, le pointeur Box peut toujours se déplacer librement. Rappelez-vous : ce qui nous importe, c’est de nous assurer que les données finalement référencées restent en place. Si un pointeur se déplace, mais les données vers lesquelles il pointe sont au même endroit, comme dans la figure 17-7, il n’y a pas de problème potentiel. (Comme exercice indépendant, regardez la documentation des types ainsi que le module std::pin et essayez de déterminer comment vous feriez cela avec un Pin encapsulant un Box.) L’essentiel est que le type auto-référentiel lui-même ne peut pas se déplacer, car il est toujours épinglé.

Cependant, la plupart des types sont parfaitement sûrs à déplacer, même s’ils se trouvent derrière un pointeur Pin. Nous n’avons besoin de penser à l’épinglage que quand les éléments ont des références internes. Les valeurs primitives comme les nombres et les booléens sont sûres car elles n’ont évidemment aucune référence interne. La plupart des types avec lesquels vous travaillez normalement en Rust non plus. Vous pouvez déplacer un Vec, par exemple, sans vous inquiéter. Étant donné ce que nous avons vu jusqu’ici, si vous avez un Pin<Vec<String>>, vous devriez tout faire via les API sûres mais restrictives fournies par Pin, même si un Vec<String> est toujours sûr à déplacer s’il n’y a pas d’autres références vers lui. Nous avons besoin d’un moyen de dire au compilateur qu’il est acceptable de déplacer des éléments dans des cas comme celui-ci — et c’est là qu’Unpin entre en jeu.
Unpin est un trait marqueur, similaire aux traits Send et Sync que nous avons vus au chapitre 16, et n’a donc aucune fonctionnalité propre. Les traits marqueurs n’existent que pour dire au compilateur qu’il est sûr d’utiliser le type implémentant un trait donné dans un contexte particulier. Unpin informe le compilateur qu’un type donné n’a pas besoin de respecter de garanties concernant le déplacement sûr de la valeur en question.
Tout comme avec Send et Sync, le compilateur implémente Unpin automatiquement pour tous les types pour lesquels il peut prouver que c’est sûr. Un cas spécial, encore similaire à Send et Sync, est quand Unpin n’est pas implémenté pour un type. La notation pour cela est impl !Unpin for SomeType, où SomeType est le nom d’un type qui doit respecter ces garanties pour être sûr chaque fois qu’un pointeur vers ce type est utilisé dans un Pin.
En d’autres termes, il y a deux choses à garder à l’esprit concernant la relation entre Pin et Unpin. Premièrement, Unpin est le cas « normal », et !Unpin est le cas spécial. Deuxièmement, qu’un type implémente Unpin ou !Unpin n’a d’importance que quand vous utilisez un pointeur épinglé vers ce type comme Pin<&mut SomeType>.
Pour rendre cela concret, pensez à une String : elle à une longueur et les caractères Unicode qui la composent. Nous pouvons encapsuler une String dans Pin, comme vu dans la figure 17-8. Cependant, String implémente automatiquement Unpin, comme la plupart des autres types en Rust.

En conséquence, nous pouvons faire des choses qui seraient illégales si String implémentait !Unpin à la place, comme remplacer une chaîne par une autre exactement au même emplacement en mémoire comme dans la figure 17-9. Cela ne viole pas le contrat de Pin, car String n’a pas de références internes qui rendraient son déplacement dangereux. C’est précisément pourquoi elle implémente Unpin plutôt que !Unpin.

Nous en savons maintenant assez pour comprendre les erreurs signalées pour cet appel à join_all dans l’encart 17-23. Nous avons initialement essayé de déplacer les futures produites par les blocs async dans un Vec<Box<dyn Future<Output = ()>>>, mais comme nous l’avons vu, ces futures peuvent avoir des références internes, donc elles n’implémentent pas automatiquement Unpin. Une fois que nous les épinglons, nous pouvons passer le type Pin résultant dans le Vec, confiants que les données sous-jacentes dans les futures ne seront pas déplacées. L’encart 17-24 montre comment corriger le code en appelant la macro pin! là où chacune des trois futures est définie et en ajustant le type d’objet trait.
extern crate trpl; // required for mdbook test
use std::pin::{Pin, pin};
// --snip--
use std::time::Duration;
fn main() {
trpl::block_on(async {
let (tx, mut rx) = trpl::channel();
let tx1 = tx.clone();
let tx1_fut = pin!(async move {
// --snip--
let vals = vec![
String::from("hi"),
String::from("from"),
String::from("the"),
String::from("future"),
];
for val in vals {
tx1.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
});
let rx_fut = pin!(async {
// --snip--
while let Some(value) = rx.recv().await {
println!("received '{value}'");
}
});
let tx_fut = pin!(async move {
// --snip--
let vals = vec![
String::from("more"),
String::from("messages"),
String::from("for"),
String::from("you"),
];
for val in vals {
tx.send(val).unwrap();
trpl::sleep(Duration::from_secs(1)).await;
}
});
let futures: Vec<Pin<&mut dyn Future<Output = ()>>> =
vec![tx1_fut, rx_fut, tx_fut];
trpl::join_all(futures).await;
});
}Cet exemple compilé et s’exécute maintenant, et nous pourrions ajouter ou retirer des futures du vecteur à l’exécution et les joindre toutes.
Pin et Unpin sont surtout importants pour construire des bibliothèques de bas niveau, ou quand vous construisez un runtime lui-même, plutôt que pour le code Rust quotidien. Quand vous verrez ces traits dans les messages d’erreur, cependant, vous aurez maintenant une meilleure idée de comment corriger votre code !
Remarque : cette combinaison de
PinetUnpinrend possible l’implémentation sûre de toute une classe de types complexes en Rust qui seraient autrement difficiles car ils sont auto-référentiels. Les types qui nécessitentPinapparaissent le plus souvent dans le Rust async aujourd’hui, mais de temps en temps, vous pourriez aussi les voir dans d’autres contextes. Les spécificités du fonctionnement dePinetUnpin, et les règles qu’ils doivent respecter, sont couvertes en détail dans la documentation de l’API pourstd::pin, donc si vous souhaitez en savoir plus, c’est un excellent point de départ. Si vous voulez comprendre comment les choses fonctionnent en coulisses encore plus en détail, voyez les chapitres [2][under-the-hood] et [4][pinning] de [Asynchronous Programming in Rust][async-book].Les détails de fonctionnement de
PinetUnpin, et les règles qu’ils doivent respecter, sont largement couverts dans la documentation de l’API pourstd::pin, donc si vous êtes intéressé par en savoir plus, c’est un excellent point de départ.Si vous voulez comprendre comment les choses fonctionnent sous le capot avec encore plus de détails, consultez les chapitres 2 et 4 de Asynchronous Programming in Rust.
Le trait Stream
Maintenant que vous avez une compréhension plus profonde des traits Future, Pin et Unpin, nous pouvons tourner notre attention vers le trait Stream. Comme vous l’avez appris plus tôt dans le chapitre, les streams sont similaires aux itérateurs asynchrones. Contrairement à Iterator et Future, cependant, Stream n’a pas de définition dans la bibliothèque standard au moment de la rédaction, mais il existe une définition très courante du crate futures utilisée dans tout l’écosystème.
Revoyons les définitions des traits Iterator et Future avant de regarder comment un trait Stream pourrait les fusionner. De Iterator, nous avons l’idée d’une séquence : sa méthode next fournit un Option<Self::Item>. De Future, nous avons l’idée de disponibilité au fil du temps : sa méthode poll fournit un Poll<Self::Output>. Pour représenter une séquence d’éléments qui deviennent disponibles au fil du temps, nous définissons un trait Stream qui rassemble ces fonctionnalités : rust use std::pin::Pin; use std::task::{Context, Poll}; trait Stream { type Item; fn poll_next( self: Pin<&mut Self>, cx: &mut Context<'_> ) -> Poll<Option<Self::Item>>; }
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
trait Stream {
type Item;
fn poll_next(
self: Pin<&mut Self>,
cx: &mut Context<'_>
) -> Poll<Option<Self::Item>>;
}
}Le trait Stream définit un type associé appelé Item pour le type des éléments produits par le stream. C’est similaire à Iterator, où il peut y avoir de zéro à plusieurs éléments, et contrairement à Future, où il y a toujours un seul Output, même si c’est le type unit ().
Stream définit aussi une méthode pour obtenir ces éléments. Nous l’appelons poll_next, pour rendre clair qu’elle interroge de la même manière que Future::poll et produit une séquence d’éléments de la même manière que Iterator::next. Son type de retour combine Poll avec Option. Le type extérieur est Poll, car il doit être vérifié pour la disponibilité, tout comme une future. Le type intérieur est Option, car il doit signaler s’il y a plus de messages, tout comme un itérateur.
Quelque chose de très similaire à cette définition finira probablement par faire partie de la bibliothèque standard de Rust. En attendant, cela fait partie de la boîte à outils de la plupart des runtimes, donc vous pouvez vous y fier, et tout ce que nous couvrons ensuite devrait généralement s’appliquer !
Dans les exemples que nous avons vus dans la section [« Streams : des futures en séquence »][streams], cependant, nous n’avons pas utilisé poll_next ni Stream, mais plutôt next et StreamExt. Nous pourrions travailler directement avec l’API poll_next en écrivant manuellement nos propres machines à états Stream, bien sûr, tout comme nous pourrions travailler avec les futures directement via leur méthode poll. Utiliser await est beaucoup plus agréable, cependant, et le trait StreamExt fournit la méthode next pour que nous puissions faire exactement cela : rust {{#rustdoc_include ../listings/ch17-async-await/no-listing-stream-ext/src/lib.rs:here}}
#![allow(unused)]
fn main() {
use std::pin::Pin;
use std::task::{Context, Poll};
trait Stream {
type Item;
fn poll_next(
self: Pin<&mut Self>,
cx: &mut Context<'_>,
) -> Poll<Option<Self::Item>>;
}
trait StreamExt: Stream {
async fn next(&mut self) -> Option<Self::Item>
where
Self: Unpin;
// other methods...
}
}Remarque : la définition réelle que nous avons utilisée plus tôt dans le chapitre est légèrement différente de celle-ci, car elle prend en charge les versions de Rust qui ne supportaient pas encore l’utilisation de fonctions async dans les traits. En conséquence, elle ressemble à ceci :
rust,ignore fn next(&mut self) -> Next<'_, Self> where Self: Unpin;Ce typeNextest unestructqui implémenteFutureet nous permet de nommer la durée de vie de la référence versselfavecNext<'_, Self>, pour queawaitpuisse fonctionner avec cette méthode.fn next(&mut self) -> Next<'_, Self> where Self: Unpin;Ce type
Nextest unestructqui implémenteFutureet nous permet de nommer la durée de vie de la référence àselfavecNext<'_, Self>, afin qu’awaitpuisse fonctionner avec cette méthode.
Le trait StreamExt est aussi le lieu de toutes les méthodes intéressantes disponibles pour utiliser avec les streams. StreamExt est automatiquement implémenté pour chaque type qui implémente Stream, mais ces traits sont définis séparément pour permettre à la communauté d’itérer sur les API de commodité sans affecter le trait fondamental.
Dans la version de StreamExt utilisée dans le crate trpl, le trait non seulement définit la méthode next mais fournit aussi une implémentation par défaut de next qui gère correctement les détails de l’appel à Stream::poll_next. Cela signifie que même quand vous devez écrire votre propre type de données de streaming, vous n’avez qu’à implémenter Stream, et ensuite quiconque utilise votre type de données peut utiliser StreamExt et ses méthodes automatiquement.
C’est tout ce que nous allons couvrir pour les détails de bas niveau de ces traits. Pour conclure, voyons comment les futures (y compris les streams), les tâches et les threads s’articulent ensemble !
Les futures, les tâches et les tâches de fond
Tout assembler : futures, tâches et threads
Comme nous l’avons vu au chapitre 16, les threads fournissent une approche de la concurrence. Nous en avons vu une autre dans ce chapitre, à savoir l’utilisation d’async avec des futures et des streams. Si vous vous demandez quand vous utiliseriez l’une plutôt que l’autre, la réponse est : cela dépend{N}! Et dans de nombreux cas, le choix n’est pas threads ou async mais plutôt threads et async.
De nombreux systèmes d’exploitation fournissent des modèles de concurrence basés sur les threads depuis des décennies maintenant, et de nombreux langages de programmation les supportent en conséquence. Cependant, ces modèles ne sont pas sans compromis. Sur de nombreux systèmes d’exploitation, ils utilisent pas mal de mémoire pour chaque thread. Les threads ne sont aussi une option que quand votre système d’exploitation et votre matériel les supportent. Contrairement aux ordinateurs de bureau et mobiles grand public, certains systèmes embarqués n’ont pas du tout de système d’exploitation, donc ils n’ont pas non plus de threads.
Le modèle async fournit un ensemble de compromis différent — et finalement complémentaire. Dans le modèle async, les opérations concurrentes ne nécessitent pas leurs propres threads. À la place, elles peuvent s’exécuter sur des tâches, comme quand nous avons utilisé trpl::spawn_task pour lancer du travail depuis une fonction synchrone dans la section sur les streams. Une tâche est similaire à un thread, mais au lieu d’être gérée par le système d’exploitation, elle est gérée par du code au niveau de la bibliothèque : le runtime.
Il y à une raison pour laquelle les API pour lancer des threads et lancer des tâches sont si similaires. Les threads agissent comme une frontière pour des ensembles d’opérations synchrones ; la concurrence est possible entre les threads. Les tâches agissent comme une frontière pour des ensembles d’opérations asynchrones ; la concurrence est possible à la fois entre et au sein des tâches, car une tâche peut alterner entre les futures dans son corps. Enfin, les futures sont l’unité de concurrence la plus granulaire de Rust, et chaque future peut représenter un arbre d’autres futures. Le runtime — spécifiquement, son exécuteur — gère les tâches, et les tâches gèrent les futures. À cet égard, les tâches sont similaires à des threads légers gérés par le runtime avec des capacités supplémentaires qui viennent du fait d’être gérées par un runtime plutôt que par le système d’exploitation.
Cela ne signifie pas que les tâches async sont toujours meilleures que les threads (ou vice versa). La concurrence avec les threads est à certains égards un modèle de programmation plus simple que la concurrence avec async. Cela peut être une force ou une faiblesse. Les threads sont quelque peu « lancer et oublier » ; ils n’ont pas d’équivalent natif à une future, donc ils s’exécutent simplement jusqu’à la fin sans être interrompus sauf par le système d’exploitation lui-même.
Et il s’avère que les threads et les tâches fonctionnent souvent très bien ensemble, car les tâches peuvent (au moins dans certains runtimes) être déplacées entre les threads. En fait, en coulisses, le runtime que nous avons utilisé — y compris les fonctions spawn_blocking et spawn_task — est multithread par défaut ! Beaucoup de runtimes utilisent une approche appelée vol de travail (work stealing) pour déplacer de manière transparente les tâches entre les threads, en fonction de la façon dont les threads sont actuellement utilisés, pour améliorer les performances globales du système. Cette approche nécessite en fait des threads et des tâches, et donc des futures.
Quand vous réfléchissez à quelle méthode utiliser et quand, considérez ces règles empiriques :
- Si le travail est très parallélisable (c’est-à-dire limité par le CPU), comme traiter un ensemble de données où chaque partie peut être traitée séparément, les threads sont un meilleur choix.
- Si le travail est très concurrent (c’est-à-dire limité par les E/S), comme gérer des messages provenant de nombreuses sources différentes qui peuvent arriver à différents intervalles ou à différentes fréquences, l’async est un meilleur choix.
Et si vous avez besoin à la fois du parallélisme et de la concurrence, vous n’avez pas à choisir entre les threads et l’async. Vous pouvez les utiliser ensemble librement, en laissant chacun jouer le rôle dans lequel il excelle. Par exemple, l’encart 17-25 montre un exemple assez courant de ce type de mélange dans le code Rust du monde réel.
extern crate trpl; // for mdbook test
use std::{thread, time::Duration};
fn main() {
let (tx, mut rx) = trpl::channel();
thread::spawn(move || {
for i in 1..11 {
tx.send(i).unwrap();
thread::sleep(Duration::from_secs(1));
}
});
trpl::block_on(async {
while let Some(message) = rx.recv().await {
println!("{message}");
}
});
}Nous commençons par créer un canal async, puis lançons un thread qui prend possession du côté émetteur du canal en utilisant le mot-clé move. Dans le thread, nous envoyons les nombres de 1 à 10, en dormant une seconde entre chaque. Enfin, nous exécutons une future créée avec un bloc async passé à trpl::block_on comme nous l’avons fait tout au long du chapitre. Dans cette future, nous attendons ces messages, comme dans les autres exemples de passage de messages que nous avons vus.
Pour revenir au scénario avec lequel nous avons ouvert le chapitre, imaginez exécuter un ensemble de tâches d’encodage vidéo en utilisant un thread dédié (parce que l’encodage vidéo est limité par le calcul) mais notifier l’interface utilisateur que ces opérations sont terminées avec un canal async. Il existe d’innombrables exemples de ce genre de combinaisons dans les cas d’utilisation du monde réel.
Résumé
Ce n’est pas la dernière fois que vous verrez la concurrence dans ce livre. Le projet du chapitre 21 utilisera les concepts de ce chapitre dans une situation plus réaliste que les petits exemples abordés ici — et les comparera de manière plus directe à ce à quoi ressemble la tâche de le faire avec des threads.
Quelle que soit l’approche que vous choisissez, Rust vous donne les outils dont vous avez besoin pour écrire du code concurrent sûr et rapide — que ce soit pour un serveur web à haut débit ou un système d’exploitation embarqué.
Ensuite, nous parlerons des façons idiomatiques de modéliser les problèmes et de structurer les solutions à mesure que vos programmes Rust grandissent. De plus, nous discuterons de la relation entre les idiomes de Rust et ceux que vous pourriez connaître de la programmation orientée objet.
Les fonctionnalités de la programmation orientée objet
La programmation orientée objet (POO) est une façon de modéliser les programmes. Les objets en tant que concept de programmation ont été introduits dans le langage de programmation Simula dans les années 1960. Ces objets ont influencé l’architecture de programmation d’Alan Kay, dans laquelle les objets s’envoient des messages les uns aux autres. Pour décrire cette architecture, il a inventé le terme programmation orientée objet en 1967. De nombreuses définitions concurrentes décrivent ce qu’est la POO, et selon certaines de ces définitions, Rust est orienté objet, mais selon d’autres, il ne l’est pas. Dans ce chapitre, nous explorerons certaines caractéristiques communément considérées comme orientées objet et comment ces caractéristiques se traduisent en Rust idiomatique. Nous vous montrerons ensuite comment implémenter un patron de conception orienté objet en Rust et discuterons des compromis par rapport à l’implémentation d’une solution utilisant plutôt certaines des forces de Rust.
Les caractéristiques des langages orientés objet
Les caractéristiques des langages orientés objet
Il n’y a pas de consensus dans la communauté de la programmation sur les fonctionnalités qu’un langage doit posséder pour être considéré comme orienté objet. Rust est influencé par de nombreux paradigmes de programmation, y compris la POO ; par exemple, nous avons exploré les fonctionnalités issues de la programmation fonctionnelle au chapitre 13. On peut argumenter que les langages POO partagent certaines caractéristiques communes — à savoir les objets, l’encapsulation et l’héritage. Voyons ce que chacune de ces caractéristiques signifie et si Rust la prend en charge.
Les objets contiennent des données et du comportement
Le livre Design Patterns: Éléments of Reusable Object-Oriented Software d’Erich Gamma, Richard Helm, Ralph Johnson et John Vlissides (Addison-Wesley, 1994), communément appelé le livre du Gang of Four (GoF), est un catalogue de patrons de conception orientés objet. Il définit la POO de cette manière :
Les programmes orientés objet sont composés d’objets. Un objet regroupe à la fois les données et les procédures qui opèrent sur ces données. Les procédures sont généralement appelées méthodes ou opérations.
Selon cette définition, Rust est orienté objet : les structs et les enums contiennent des données, et les blocs impl fournissent des méthodes sur les structs et les enums. Même si les structs et les enums avec des méthodes ne sont pas appelés objets, ils fournissent la même fonctionnalité, selon la définition des objets du Gang of Four.
L’encapsulation qui masque les détails d’implémentation
Un autre aspect couramment associé à la POO est l’idée d’encapsulation, ce qui signifie que les détails d’implémentation d’un objet ne sont pas accessibles au code utilisant cet objet. Par conséquent, la seule façon d’interagir avec un objet est à travers son API publique ; le code utilisant l’objet ne devrait pas pouvoir accéder aux composants internes de l’objet et modifier directement les données ou le comportement. Cela permet au programmeur de modifier et refactoriser les composants internes d’un objet sans avoir besoin de modifier le code qui utilise l’objet.
Nous avons discuté de la façon de contrôler l’encapsulation au chapitre 7 : nous pouvons utiliser le mot-clé pub pour décider quels modules, types, fonctions et méthodes de notre code doivent être publics, et par défaut tout le reste est privé. Par exemple, nous pouvons définir une struct AveragedCollection qui à un champ contenant un vecteur de valeurs i32. La struct peut aussi avoir un champ qui contient la moyenne des valeurs du vecteur, ce qui signifie que la moyenne n’a pas besoin d’être calculée à la demande chaque fois que quelqu’un en a besoin. En d’autres termes, AveragedCollection mettra en cache la moyenne calculée pour nous. L’encart 18-1 contient la définition de la struct AveragedCollection.
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}AveragedCollection struct that maintains a list of integers and the average of the items in the collectionLa struct est marquée pub pour que d’autre code puisse l’utiliser, mais les champs au sein de la struct restent privés. C’est important dans ce cas car nous voulons nous assurer que chaque fois qu’une valeur est ajoutée ou retirée de la liste, la moyenne est également mise à jour. Nous faisons cela en implémentant les méthodes add, remove et average sur la struct, comme montré dans l’encart 18-2.
pub struct AveragedCollection {
list: Vec<i32>,
average: f64,
}
impl AveragedCollection {
pub fn add(&mut self, value: i32) {
self.list.push(value);
self.update_average();
}
pub fn remove(&mut self) -> Option<i32> {
let result = self.list.pop();
match result {
Some(value) => {
self.update_average();
Some(value)
}
None => None,
}
}
pub fn average(&self) -> f64 {
self.average
}
fn update_average(&mut self) {
let total: i32 = self.list.iter().sum();
self.average = total as f64 / self.list.len() as f64;
}
}add, remove, and average on AveragedCollectionLes méthodes publiques add, remove et average sont les seules façons d’accéder ou de modifier les données dans une instance de AveragedCollection. Quand un élément est ajouté à list en utilisant la méthode add ou retiré en utilisant la méthode remove, les implémentations de chacune appellent la méthode privée update_average qui gère aussi la mise à jour du champ average.
Nous laissons les champs list et average privés pour qu’il n’y ait aucun moyen pour du code externe d’ajouter ou de retirer des éléments du champ list directement ; sinon, le champ average pourrait se désynchroniser quand list change. La méthode average retourné la valeur du champ average, permettant au code externe de lire la moyenne mais pas de la modifier.
Comme nous avons encapsulé les détails d’implémentation de la struct AveragedCollection, nous pouvons facilement changer des aspects, comme la structure de données, à l’avenir. Par exemple, nous pourrions utiliser un HashSet<i32> au lieu d’un Vec<i32> pour le champ list. Tant que les signatures des méthodes publiques add, remove et average restent les mêmes, le code utilisant AveragedCollection n’aurait pas besoin de changer. Si nous avions rendu list public à la place, ce ne serait pas nécessairement le cas : HashSet<i32> et Vec<i32> ont des méthodes différentes pour ajouter et retirer des éléments, donc le code externe devrait probablement changer s’il modifiait list directement.
Si l’encapsulation est un aspect requis pour qu’un langage soit considéré comme orienté objet, alors Rust satisfait cette exigence. L’option d’utiliser pub ou non pour différentes parties du code permet l’encapsulation des détails d’implémentation.
L’héritage comme système de types et comme partage de code
L’héritage est un mécanisme par lequel un objet peut hériter d’éléments de la définition d’un autre objet, obtenant ainsi les données et le comportement de l’objet parent sans avoir à les redéfinir.
Si un langage doit avoir l’héritage pour être orienté objet, alors Rust n’est pas un tel langage. Il n’y à aucun moyen de définir une struct qui hérite des champs et des implémentations de méthodes de la struct parente sans utiliser une macro.
Cependant, si vous êtes habitué à avoir l’héritage dans votre boîte à outils de programmation, vous pouvez utiliser d’autres solutions en Rust, selon la raison pour laquelle vous avez recours à l’héritage en premier lieu.
Vous choisiriez l’héritage pour deux raisons principales. La première est la réutilisation du code : vous pouvez implémenter un comportement particulier pour un type, et l’héritage vous permet de réutiliser cette implémentation pour un type différent. Vous pouvez faire cela de manière limitée en Rust en utilisant les implémentations par défaut des méthodes de trait, ce que vous avez vu dans l’encart 10-14 quand nous avons ajouté une implémentation par défaut de la méthode summarize sur le trait Summary. Tout type implémentant le trait Summary aurait la méthode summarize disponible sans code supplémentaire. C’est similaire à une classe parente ayant une implémentation d’une méthode et une classe enfant héritante ayant aussi l’implémentation de la méthode. Nous pouvons aussi surcharger l’implémentation par défaut de la méthode summarize quand nous implémentons le trait Summary, ce qui est similaire à une classe enfant surchargeant l’implémentation d’une méthode héritée d’une classe parente.
L’autre raison d’utiliser l’héritage est liée au système de types : permettre à un type enfant d’être utilisé aux mêmes endroits que le type parent. Cela s’appelle aussi le polymorphisme, ce qui signifie que vous pouvez substituer plusieurs objets les uns aux autres à l’exécution s’ils partagent certaines caractéristiques.
Polymorphisme
Pour beaucoup de gens, le polymorphisme est synonyme d’héritage. Mais c’est en réalité un concept plus général qui fait référence à du code pouvant travailler avec des données de plusieurs types. Pour l’héritage, ces types sont généralement des sous-classes.
Rust utilise plutôt les génériques pour abstraire les différents types possibles et les contraintes de trait pour imposer des contraintes sur ce que ces types doivent fournir. Cela s’appelle parfois le polymorphisme paramétrique borné.
Rust a choisi un ensemble différent de compromis en ne proposant pas l’héritage. L’héritage risque souvent de partager plus de code que nécessaire. Les sous-classes ne devraient pas toujours partager toutes les caractéristiques de leur classe parente, mais elles le font avec l’héritage. Cela peut rendre la conception d’un programme moins flexible. Cela introduit aussi la possibilité d’appeler des méthodes sur des sous-classes qui n’ont pas de sens ou qui causent des erreurs parce que les méthodes ne s’appliquent pas à la sous-classe. De plus, certains langages ne permettent que l’héritage simple (ce qui signifie qu’une sous-classe ne peut hériter que d’une seule classe), limitant encore davantage la flexibilité de la conception d’un programme.
Pour ces raisons, Rust adopte l’approche différente d’utiliser des objets trait au lieu de l’héritage pour obtenir le polymorphisme à l’exécution. Voyons comment les objets trait fonctionnent.
Utiliser des objets trait pour abstraire un comportement commun
Utiliser des objets trait pour abstraire un comportement commun
Au chapitre 8, nous avons mentionné qu’une limitation des vecteurs est qu’ils ne peuvent stocker des éléments que d’un seul type. Nous avons créé une solution de contournement dans l’encart 8-9 où nous avons défini un enum SpreadsheetCell qui avait des variantes pour contenir des entiers, des flottants et du texte. Cela signifiait que nous pouvions stocker différents types de données dans chaque cellule et avoir quand même un vecteur représentant une ligne de cellules. C’est une solution parfaitement valable quand nos éléments interchangeables sont un ensemble fixe de types que nous connaissons au moment de la compilation de notre code.
Cependant, parfois nous voulons que l’utilisateur de notre bibliothèque puisse étendre l’ensemble des types valides dans une situation particulière. Pour montrer comment nous pourrions y parvenir, nous allons créer un exemple d’outil d’interface graphique utilisateur (GUI) qui parcourt une liste d’éléments, en appelant une méthode draw sur chacun pour le dessiner à l’écran — une technique courante pour les outils GUI. Nous créerons un crate de bibliothèque appelé gui qui contient la structure d’une bibliothèque GUI. Ce crate pourrait inclure certains types à utiliser, comme Button ou TextField. De plus, les utilisateurs de gui voudront créer leurs propres types pouvant être dessinés : par exemple, un programmeur pourrait ajouter un Image, et un autre pourrait ajouter un SelectBox.
Au moment d’écrire la bibliothèque, nous ne pouvons pas connaître et définir tous les types que d’autres programmeurs pourraient vouloir créer. Mais nous savons que gui doit garder une trace de nombreuses valeurs de différents types, et qu’il doit appeler une méthode draw sur chacune de ces valeurs de types différents. Il n’a pas besoin de savoir exactement ce qui va se passer quand nous appelons la méthode draw, juste que la valeur aura cette méthode disponible pour que nous puissions l’appeler.
Pour faire cela dans un langage avec héritage, nous pourrions définir une classe nommée Component qui à une méthode nommée draw. Les autres classes, comme Button, Image et SelectBox, hériteraient de Component et donc hériteraient de la méthode draw. Elles pourraient chacune surcharger la méthode draw pour définir leur comportement personnalisé, mais le framework pourrait traiter tous les types comme s’ils étaient des instances de Component et appeler draw sur eux. Mais comme Rust n’a pas d’héritage, nous avons besoin d’une autre façon de structurer la bibliothèque gui pour permettre aux utilisateurs de créer de nouveaux types compatibles avec la bibliothèque.
Définir un trait pour un comportement commun
Pour implémenter le comportement que nous voulons que gui ait, nous définirons un trait nommé Draw qui aura une méthode nommée draw. Ensuite, nous pourrons définir un vecteur qui prend un objet trait. Un objet trait pointe à la fois vers une instance d’un type implémentant notre trait spécifié et vers une table utilisée pour rechercher les méthodes du trait sur ce type à l’exécution. Nous créons un objet trait en spécifiant une sorte de pointeur, comme une référence ou un pointeur intelligent Box<T>, puis le mot-clé dyn, puis en spécifiant le trait pertinent. (Nous parlerons de la raison pour laquelle les objets trait doivent utiliser un pointeur dans [« Types de taille dynamique et le trait Sized »][dynamically-sized] au chapitre 20.) Nous pouvons utiliser des objets trait à la place d’un type générique ou concret. Partout où nous utilisons un objet trait, le système de types de Rust s’assurera au moment de la compilation que toute valeur utilisée dans ce contexte implémentera le trait de l’objet trait. Par conséquent, nous n’avons pas besoin de connaître tous les types possibles au moment de la compilation.
Nous avons mentionné qu’en Rust, nous nous abstenons d’appeler les structs et les enums des « objets » pour les distinguer des objets des autres langages. Dans une struct ou un enum, les données dans les champs de la struct et le comportement dans les blocs impl sont séparés, tandis que dans d’autres langages, les données et le comportement combinés en un seul concept sont souvent qualifiés d’objet. Les objets trait diffèrent des objets dans d’autres langages en ce que nous ne pouvons pas ajouter de données à un objet trait. Les objets trait ne sont pas aussi généralement utiles que les objets dans d’autres langages : leur but spécifique est de permettre l’abstraction à travers un comportement commun.
L’encart 18-3 montre comment définir un trait nommé Draw avec une méthode nommée draw.
pub trait Draw {
fn draw(&self);
}Draw traitCette syntaxe devrait vous être familière de nos discussions sur la façon de définir des traits au chapitre 10. Vient ensuite une nouvelle syntaxe : l’encart 18-4 définit une struct nommée Screen qui contient un vecteur nommé components. Ce vecteur est de type Box<dyn Draw>, qui est un objet trait ; c’est un substitut pour tout type à l’intérieur d’un Box qui implémente le trait Draw.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}Screen struct with a components field holding a vector of trait objects that implement the Draw traitSur la struct Screen, nous définirons une méthode nommée run qui appellera la méthode draw sur chacun de ses components, comme montré dans l’encart 18-5.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}run method on Screen that calls the draw method on each componentCela fonctionne différemment de la définition d’une struct qui utilise un paramètre de type générique avec des contraintes de trait. Un paramètre de type générique ne peut être substitué qu’avec un seul type concret à la fois, tandis que les objets trait permettent à plusieurs types concrets de remplir le rôle de l’objet trait à l’exécution. Par exemple, nous aurions pu définir la struct Screen en utilisant un type générique et une contrainte de trait, comme dans l’encart 18-6.
pub trait Draw {
fn draw(&self);
}
pub struct Screen<T: Draw> {
pub components: Vec<T>,
}
impl<T> Screen<T>
where
T: Draw,
{
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}Screen struct and its run method using generics and trait boundsCela nous restreint à une instance de Screen qui à une liste de composants tous de type Button ou tous de type TextField. Si vous n’aurez jamais que des collections homogènes, utiliser des génériques et des contraintes de trait est préférable car les définitions seront monomorphisées au moment de la compilation pour utiliser les types concrets.
D’un autre côté, avec la méthode utilisant des objets trait, une instance de Screen peut contenir un Vec<T> qui contient un Box<Button> ainsi qu’un Box<TextField>. Voyons comment cela fonctionne, puis nous parlerons des implications en termes de performance à l’exécution.
Implémenter le trait
Nous allons maintenant ajouter quelques types qui implémentent le trait Draw. Nous fournirons le type Button. Encore une fois, implémenter réellement une bibliothèque GUI dépasse le cadre de ce livre, donc la méthode draw n’aura pas d’implémentation utile dans son corps. Pour imaginer à quoi l’implémentation pourrait ressembler, une struct Button pourrait avoir des champs pour width, height et label, comme montré dans l’encart 18-7.
pub trait Draw {
fn draw(&self);
}
pub struct Screen {
pub components: Vec<Box<dyn Draw>>,
}
impl Screen {
pub fn run(&self) {
for component in self.components.iter() {
component.draw();
}
}
}
pub struct Button {
pub width: u32,
pub height: u32,
pub label: String,
}
impl Draw for Button {
fn draw(&self) {
// code to actually draw a button
}
}Button struct that implements the Draw traitLes champs width, height et label de Button différeront des champs des autres composants ; par exemple, un type TextField pourrait avoir ces mêmes champs plus un champ placeholder. Chacun des types que nous voulons dessiner à l’écran implémentera le trait Draw mais utilisera un code différent dans la méthode draw pour définir comment dessiner ce type particulier, comme Button le fait ici (sans le code GUI réel, comme mentionné). Le type Button, par exemple, pourrait avoir un bloc impl supplémentaire contenant des méthodes liées à ce qui se passe quand un utilisateur clique sur le bouton. Ces types de méthodes ne s’appliqueront pas à des types comme TextField.
Si quelqu’un utilisant notre bibliothèque décide d’implémenter une struct SelectBox qui à des champs width, height et options, il implémenterait aussi le trait Draw sur le type SelectBox, comme montré dans l’encart 18-8.
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
fn main() {}gui and implementing the Draw trait on a SelectBox structL’utilisateur de notre bibliothèque peut maintenant écrire sa fonction main pour créer une instance de Screen. À l’instance de Screen, il peut ajouter un SelectBox et un Button en mettant chacun dans un Box<T> pour devenir un objet trait. Il peut ensuite appeler la méthode run sur l’instance de Screen, qui appellera draw sur chacun des composants. L’encart 18-9 montre cette implémentation.
use gui::Draw;
struct SelectBox {
width: u32,
height: u32,
options: Vec<String>,
}
impl Draw for SelectBox {
fn draw(&self) {
// code to actually draw a select box
}
}
use gui::{Button, Screen};
fn main() {
let screen = Screen {
components: vec![
Box::new(SelectBox {
width: 75,
height: 10,
options: vec![
String::from("Yes"),
String::from("Maybe"),
String::from("No"),
],
}),
Box::new(Button {
width: 50,
height: 10,
label: String::from("OK"),
}),
],
};
screen.run();
}Quand nous avons écrit la bibliothèque, nous ne savions pas que quelqu’un pourrait ajouter le type SelectBox, mais notre implémentation de Screen a pu opérer sur le nouveau type et le dessiner parce que SelectBox implémente le trait Draw, ce qui signifie qu’il implémente la méthode draw.
Ce concept — ne se préoccuper que des messages auxquels une valeur répond plutôt que du type concret de la valeur — est similaire au concept de duck typing dans les langages à typage dynamique : si ça marche comme un canard et si ça cancane comme un canard, alors ça doit être un canard ! Dans l’implémentation de run sur Screen dans l’encart 18-5, run n’a pas besoin de connaître le type concret de chaque composant. Il ne vérifie pas si un composant est une instance de Button ou de SelectBox, il appelle simplement la méthode draw sur le composant. En spécifiant Box<dyn Draw> comme type des valeurs dans le vecteur components, nous avons défini Screen comme ayant besoin de valeurs sur lesquelles nous pouvons appeler la méthode draw.
L’avantage d’utiliser des objets trait et le système de types de Rust pour écrire du code similaire au code utilisant le duck typing est que nous n’avons jamais à vérifier si une valeur implémente une méthode particulière à l’exécution ni à nous inquiéter d’obtenir des erreurs si une valeur n’implémente pas une méthode mais que nous l’appelons quand même. Rust ne compilera pas notre code si les valeurs n’implémentent pas les traits dont les objets trait ont besoin.
Par exemple, l’encart 18-10 montre ce qui se passe si nous essayons de créer un Screen avec une String comme composant.
use gui::Screen;
fn main() {
let screen = Screen {
components: vec![Box::new(String::from("Hi"))],
};
screen.run();
}Nous obtiendrons cette erreur parce que String n’implémente pas le trait Draw : console {{#include ../listings/ch18-oop/listing-18-10/output.txt}}
$ cargo run
Compiling gui v0.1.0 (file:///projects/gui)
error[E0277]: the trait bound `String: Draw` is not satisfied
--> src/main.rs:5:26
|
5 | components: vec![Box::new(String::from("Hi"))],
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^ the trait `Draw` is not implemented for `String`
|
= help: the trait `Draw` is implemented for `Button`
= note: required for the cast from `Box<String>` to `Box<dyn Draw>`
For more information about this error, try `rustc --explain E0277`.
error: could not compile `gui` (bin "gui") due to 1 previous error
Cette erreur nous indique que soit nous passons quelque chose à Screen que nous n’avions pas l’intention de passer et donc nous devrions passer un type différent, soit nous devrions implémenter Draw sur String pour que Screen puisse appeler draw dessus.
Effectuer la répartition dynamique
Rappelez-vous dans « Performance du code utilisant des génériques » au chapitre 10 notre discussion sur le processus de monomorphisation effectué par le compilateur quand nous utilisons des contraintes de trait sur des génériques : le compilateur génère des implémentations non génériques de fonctions et de méthodes pour chaque type concret que nous utilisons à la place d’un paramètre de type générique. Le code qui résulte de la monomorphisation effectue une répartition statique, qui est lorsque le compilateur sait quelle méthode vous appelez au moment de la compilation. Cela s’oppose à la répartition dynamique, qui est lorsque le compilateur ne peut pas dire au moment de la compilation quelle méthode vous appelez. Dans les cas de répartition dynamique, le compilateur émet du code qui au moment de l’exécution déterminera quelle méthode appeler.
Quand nous utilisons des objets trait, Rust doit utiliser la répartition dynamique. Le compilateur ne connaît pas tous les types qui pourraient être utilisés avec le code utilisant des objets trait, donc il ne sait pas quelle méthode implémentée sur quel type appeler. À la place, à l’exécution, Rust utilise les pointeurs à l’intérieur de l’objet trait pour savoir quelle méthode appeler. Cette recherche engendre un coût à l’exécution qui ne se produit pas avec la répartition statique. La répartition dynamique empêche aussi le compilateur de choisir d’inliner le code d’une méthode, ce qui à son tour empêche certaines optimisations, et Rust a certaines règles sur les endroits où vous pouvez et ne pouvez pas utiliser la répartition dynamique, appelées compatibilité dyn. Ces règles dépassent le cadre de cette discussion, mais vous pouvez en lire davantage [dans la référence][dyn-compatibility]. Cependant, nous avons obtenu une flexibilité supplémentaire dans le code que nous avons écrit dans l’encart 18-5 et que nous avons pu prendre en charge dans l’encart 18-9, donc c’est un compromis à considérer.
Implémenter un patron de conception orienté objet
Implémenter un patron de conception orienté objet
Le patron état est un patron de conception orienté objet. Le cœur du patron est que nous définissons un ensemble d’états qu’une valeur peut avoir en interne. Les états sont représentés par un ensemble d’objets état, et le comportement de la valeur change en fonction de son état. Nous allons travailler sur un exemple de struct d’article de blog qui à un champ pour contenir son état, qui sera un objet état de l’ensemble « brouillon », « en revue » ou « publié ».
Les objets état partagent des fonctionnalités : en Rust, bien sûr, nous utilisons des structs et des traits plutôt que des objets et l’héritage. Chaque objet état est responsable de son propre comportement et de déterminer quand il doit changer vers un autre état. La valeur qui contient un objet état ne sait rien du comportement différent des états ni de quand effectuer la transition entre les états.
L’avantage d’utiliser le patron état est que, quand les exigences métier du programme changent, nous n’aurons pas besoin de modifier le code de la valeur contenant l’état ni le code qui utilise la valeur. Nous n’aurons qu’à mettre à jour le code à l’intérieur d’un des objets état pour changer ses règles, ou peut-être ajouter d’autres objets état.
D’abord, nous allons implémenter le patron état de manière plus traditionnelle orientée objet. Ensuite, nous utiliserons une approche un peu plus naturelle en Rust. Plongeons-y pour implémenter progressivement un flux de travail d’articles de blog en utilisant le patron état.
La fonctionnalité finale ressemblera à ceci :
- Un article de blog commence comme un brouillon vide.
- Quand le brouillon est terminé, une revue de l’article est demandée.
- Quand l’article est approuvé, il est publié.
- Seuls les articles de blog publiés retournent du contenu à afficher pour que les articles non approuvés ne puissent pas être publiés accidentellement.
Toute autre modification tentée sur un article ne devrait avoir aucun effet. Par exemple, si nous essayons d’approuver un brouillon d’article de blog avant d’avoir demandé une revue, l’article devrait rester un brouillon non publié.
Tenter le style orienté objet traditionnel
Il existe une infinité de façons de structurer du code pour résoudre le même problème, chacune avec des compromis différents. L’implémentation de cette section est plus dans un style orienté objet traditionnel, qu’il est possible d’écrire en Rust, mais qui ne tire pas parti de certaines des forces de Rust. Plus tard, nous démontrerons une solution différente qui utilise toujours le patron de conception orienté objet mais qui est structurée d’une manière qui pourrait sembler moins familière aux programmeurs ayant de l’expérience en programmation orientée objet. Nous comparerons les deux solutions pour expérimenter les compromis de la conception de code Rust différemment du code dans d’autres langages.
L’encart 18-11 montre ce flux de travail sous forme de code : c’est un exemple d’utilisation de l’API que nous implémenterons dans un crate de bibliothèque nommé blog. Cela ne compilera pas encore car nous n’avons pas implémenté le crate blog.
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}blog crate to haveNous voulons permettre à l’utilisateur de créer un nouveau brouillon d’article de blog avec Post::new. Nous voulons permettre d’ajouter du texte à l’article de blog. Si nous essayons d’obtenir le contenu de l’article immédiatement, avant l’approbation, nous ne devrions obtenir aucun texte car l’article est encore un brouillon. Nous avons ajouté assert_eq! dans le code à des fins de démonstration. Un excellent test unitaire pour cela serait de vérifier qu’un brouillon d’article de blog retourné une chaîne vide depuis la méthode content, mais nous n’allons pas écrire de tests pour cet exemple.
Ensuite, nous voulons permettre de demander une revue de l’article, et nous voulons que content retourné une chaîne vide en attendant la revue. Quand l’article reçoit l’approbation, il devrait être publié, ce qui signifie que le texte de l’article sera retourné quand content est appelé.
Remarquez que le seul type avec lequel nous interagissons depuis le crate est le type Post. Ce type utilisera le patron état et contiendra une valeur qui sera l’un des trois objets état représentant les différents états dans lesquels un article peut se trouver — brouillon, revue ou publié. Le passage d’un état à un autre sera géré en interne au sein du type Post. Les états changent en réponse aux méthodes appelées par les utilisateurs de notre bibliothèque sur l’instance Post, mais ils n’ont pas à gérer directement les changements d’état. De plus, les utilisateurs ne peuvent pas faire d’erreur avec les états, comme publier un article avant qu’il ne soit révisé.
Définir Post et créer une nouvelle instance
Commençons l’implémentation de la bibliothèque ! Nous savons que nous avons besoin d’une struct publique Post qui contient du contenu, donc nous commencerons par la définition de la struct et une fonction publique associée new pour créer une instance de Post, comme montré dans l’encart 18-12. Nous créerons aussi un trait privé State qui définira le comportement que tous les objets état d’un Post doivent avoir.
Ensuite, Post contiendra un objet trait de Box<dyn State> à l’intérieur d’un Option<T> dans un champ privé nommé state pour contenir l’objet état. Vous verrez bientôt pourquoi l’Option<T> est nécessaire.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
}
trait State {}
struct Draft {}
impl State for Draft {}Post struct and a new function that creates a new Post instance, a State trait, and a Draft structLe trait State définit le comportement partagé par les différents états d’article. Les objets état sont Draft, PendingReview et Published, et ils implémenteront tous le trait State. Pour l’instant, le trait n’à aucune méthode, et nous commencerons par définir uniquement l’état Draft car c’est l’état dans lequel nous voulons qu’un article démarre.
Quand nous créons un nouveau Post, nous définissons son champ state à une valeur Some qui contient un Box. Ce Box pointe vers une nouvelle instance de la struct Draft. Cela garantit que chaque fois que nous créons une nouvelle instance de Post, elle commencera en tant que brouillon. Comme le champ state de Post est privé, il n’y à aucun moyen de créer un Post dans un autre état ! Dans la fonction Post::new, nous définissons le champ content à une nouvelle String vide.
Stocker le texte du contenu de l’article
Nous avons vu dans l’encart 18-11 que nous voulons pouvoir appeler une méthode nommée add_text et lui passer un &str qui sera ensuite ajouté comme contenu texte de l’article de blog. Nous implémentons cela comme une méthode, plutôt que d’exposer le champ content comme pub, pour que plus tard nous puissions implémenter une méthode qui contrôlera comment les données du champ content sont lues. La méthode add_text est assez simple, alors ajoutons l’implémentation dans l’encart 18-13 au bloc impl Post.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}
trait State {}
struct Draft {}
impl State for Draft {}add_text method to add text to a post’s contentLa méthode add_text prend une référence mutable vers self car nous modifions l’instance Post sur laquelle nous appelons add_text. Nous appelons ensuite push_str sur la String dans content et passons l’argument text pour l’ajouter au content sauvegardé. Ce comportement ne dépend pas de l’état dans lequel se trouve l’article, donc il ne fait pas partie du patron état. La méthode add_text n’interagit pas du tout avec le champ state, mais elle fait partie du comportement que nous voulons supporter.
S’assurer que le contenu d’un brouillon d’article est vide
Même après avoir appelé add_text et ajouté du contenu à notre article, nous voulons toujours que la méthode content retourné une tranche de chaîne vide car l’article est encore dans l’état brouillon, comme montré par le premier assert_eq! dans l’encart 18-11. Pour l’instant, implémentons la méthode content avec la chose la plus simple qui satisfera cette exigence : toujours retourner une tranche de chaîne vide. Nous changerons cela plus tard quand nous implémenterons la capacité de changer l’état d’un article pour qu’il puisse être publié. Jusqu’ici, les articles ne peuvent être que dans l’état brouillon, donc le contenu de l’article devrait toujours être vide. L’encart 18-14 montre cette implémentation provisoire.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
}
trait State {}
struct Draft {}
impl State for Draft {}content method on Post that always returns an empty string sliceAvec cette méthode content ajoutée, tout dans l’encart 18-11 jusqu’au premier assert_eq! fonctionne comme prévu.
Demander une revue, ce qui change l’état de l’article
Ensuite, nous devons ajouter la fonctionnalité pour demander une revue d’un article, ce qui devrait changer son état de Draft à PendingReview. L’encart 18-15 montre ce code.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
}request_review methods on Post and the State traitNous donnons à Post une méthode publique nommée request_review qui prendra une référence mutable vers self. Ensuite, nous appelons une méthode interne request_review sur l’état actuel de Post, et cette seconde méthode request_review consomme l’état actuel et retourné un nouvel état.
Nous ajoutons la méthode request_review au trait State ; tous les types qui implémentent le trait devront maintenant implémenter la méthode request_review. Notez que plutôt que d’avoir self, &self ou &mut self comme premier paramètre de la méthode, nous avons self: Box<Self>. Cette syntaxe signifie que la méthode n’est valide que lorsqu’elle est appelée sur un Box contenant le type. Cette syntaxe prend possession de Box<Self>, invalidant l’ancien état pour que la valeur d’état du Post puisse se transformer en un nouvel état.
Pour consommer l’ancien état, la méthode request_review doit prendre possession de la valeur d’état. C’est là que l’Option dans le champ state de Post entre en jeu : nous appelons la méthode take pour extraire la valeur Some du champ state et laisser un None à sa place car Rust ne nous laisse pas avoir des champs non remplis dans les structs. Cela nous permet de déplacer la valeur state hors de Post plutôt que de l’emprunter. Ensuite, nous définirons la valeur state de l’article au résultat de cette opération.
Nous devons mettre state à None temporairement plutôt que de le définir directement avec du code comme self.state = self.state.request_review(); pour obtenir la possession de la valeur state. Cela garantit que Post ne peut pas utiliser l’ancienne valeur state après que nous l’ayons transformée en un nouvel état.
La méthode request_review sur Draft retourné une nouvelle instance boxée d’une nouvelle struct PendingReview, qui représente l’état quand un article attend une revue. La struct PendingReview implémente aussi la méthode request_review mais ne fait aucune transformation. Elle se retourné elle-même car quand nous demandons une revue sur un article déjà dans l’état PendingReview, il devrait rester dans l’état PendingReview.
Nous pouvons maintenant commencer à voir les avantages du patron état : la méthode request_review sur Post est la même quel que soit sa valeur state. Chaque état est responsable de ses propres règles.
Nous laisserons la méthode content de Post telle quelle, retournant une tranche de chaîne vide. Nous pouvons maintenant avoir un Post dans l’état PendingReview aussi bien que dans l’état Draft, mais nous voulons le même comportement dans l’état PendingReview. L’encart 18-11 fonctionne maintenant jusqu’au deuxième appel assert_eq! !
Ajouter approve pour changer le comportement de content
La méthode approve sera similaire à la méthode request_review : elle définira state à la valeur que l’état actuel dit qu’il devrait avoir quand cet état est approuvé, comme montré dans l’encart 18-16.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
""
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}approve method on Post and the State traitNous ajoutons la méthode approve au trait State et ajoutons une nouvelle struct qui implémente State, l’état Published.
De la même manière que request_review fonctionne sur PendingReview, si nous appelons la méthode approve sur un Draft, cela n’aura aucun effet car approve retournera self. Quand nous appelons approve sur PendingReview, il retourné une nouvelle instance boxée de la struct Published. La struct Published implémente le trait State, et pour les méthodes request_review et approve, elle se retourné elle-même car l’article devrait rester dans l’état Published dans ces cas.
Maintenant, nous devons mettre à jour la méthode content de Post. Nous voulons que la valeur retournée par content dépende de l’état actuel du Post, donc nous allons faire en sorte que Post délègue à une méthode content définie sur son state, comme montré dans l’encart 18-17.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
// --snip--
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
// --snip--
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
}
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}content method on Post to delegate to a content method on StateComme l’objectif est de garder toutes ces règles à l’intérieur des structs qui implémentent State, nous appelons une méthode content sur la valeur dans state et passons l’instance de l’article (c’est-à-dire self) comme argument. Ensuite, nous retournons la valeur retournée par l’utilisation de la méthode content sur la valeur state.
Nous appelons la méthode as_ref sur l’Option car nous voulons une référence vers la valeur à l’intérieur de l’Option plutôt que la possession de la valeur. Comme state est un Option<Box<dyn State>>, quand nous appelons as_ref, un Option<&Box<dyn State>> est retourné. Si nous n’appelions pas as_ref, nous obtiendrions une erreur car nous ne pouvons pas déplacer state hors du &self emprunté du paramètre de la fonction.
Nous appelons ensuite la méthode unwrap, dont nous savons qu’elle ne paniquera jamais car nous savons que les méthodes de Post garantissent que state contiendra toujours une valeur Some quand ces méthodes sont terminées. C’est l’un des cas dont nous avons parlé dans la section [« Quand vous avez plus d’informations que le compilateur »][more-info-than-rustc] du chapitre 9, quand nous savons qu’une valeur None n’est jamais possible, même si le compilateur n’est pas en mesure de le comprendre.
À ce stade, quand nous appelons content sur le &Box<dyn State>, la coercition de déréférencement prendra effet sur le & et le Box pour que la méthode content soit finalement appelée sur le type qui implémente le trait State. Cela signifie que nous devons ajouter content à la définition du trait State, et c’est là que nous mettrons la logique pour déterminer quel contenu retourner en fonction de l’état dans lequel nous sommes, comme montré dans l’encart 18-18.
pub struct Post {
state: Option<Box<dyn State>>,
content: String,
}
impl Post {
pub fn new() -> Post {
Post {
state: Some(Box::new(Draft {})),
content: String::new(),
}
}
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn content(&self) -> &str {
self.state.as_ref().unwrap().content(self)
}
pub fn request_review(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.request_review())
}
}
pub fn approve(&mut self) {
if let Some(s) = self.state.take() {
self.state = Some(s.approve())
}
}
}
trait State {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State>;
fn approve(self: Box<Self>) -> Box<dyn State>;
fn content<'a>(&self, post: &'a Post) -> &'a str {
""
}
}
// --snip--
struct Draft {}
impl State for Draft {
fn request_review(self: Box<Self>) -> Box<dyn State> {
Box::new(PendingReview {})
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
}
struct PendingReview {}
impl State for PendingReview {
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
Box::new(Published {})
}
}
struct Published {}
impl State for Published {
// --snip--
fn request_review(self: Box<Self>) -> Box<dyn State> {
self
}
fn approve(self: Box<Self>) -> Box<dyn State> {
self
}
fn content<'a>(&self, post: &'a Post) -> &'a str {
&post.content
}
}content method to the State traitNous ajoutons une implémentation par défaut pour la méthode content qui retourné une tranche de chaîne vide. Cela signifie que nous n’avons pas besoin d’implémenter content sur les structs Draft et PendingReview. La struct Published surchargera la méthode content et retournera la valeur dans post.content. Bien que pratique, avoir la méthode content sur State qui détermine le contenu du Post brouille les frontières entre la responsabilité de State et la responsabilité de Post.
Notez que nous avons besoin d’annotations de durée de vie sur cette méthode, comme nous l’avons discuté au chapitre 10. Nous prenons une référence vers un post comme argument et retournons une référence vers une partie de ce post, donc la durée de vie de la référence retournée est liée à la durée de vie de l’argument post.
Et c’est terminé — tout l’encart 18-11 fonctionne maintenant ! Nous avons implémenté le patron état avec les règles du flux de travail des articles de blog. La logique liée aux règles réside dans les objets état plutôt que d’être dispersée dans Post.
Pourquoi pas une énumération ?
Vous vous êtes peut-être demandé pourquoi nous n’avons pas utilisé une énumération avec les différents états possibles de l’article comme variantes. C’est certainement une solution possible ; essayez-la et comparez les résultats finaux pour voir laquelle vous préférez ! Un inconvénient de l’utilisation d’une énumération est que chaque endroit qui vérifie la valeur de l’énumération aura besoin d’une expression match ou similaire pour gérer chaque variante possible. Cela pourrait devenir plus répétitif que cette solution à base d’objets trait.
Évaluer le patron état
Nous avons montré que Rust est capable d’implémenter le patron état orienté objet pour encapsuler les différents types de comportement qu’un article devrait avoir dans chaque état. Les méthodes de Post ne savent rien des différents comportements. Grâce à la façon dont nous avons organisé le code, nous n’avons qu’un seul endroit à regarder pour connaître les différentes façons dont un article publié peut se comporter : l’implémentation du trait State sur la struct Published.
Si nous devions créer une implémentation alternative qui n’utilise pas le patron état, nous pourrions plutôt utiliser des expressions match dans les méthodes de Post ou même dans le code main qui vérifie l’état de l’article et change le comportement à ces endroits. Cela signifierait que nous devrions regarder à plusieurs endroits pour comprendre toutes les implications d’un article dans l’état publié.
Avec le patron état, les méthodes de Post et les endroits où nous utilisons Post n’ont pas besoin d’expressions match, et pour ajouter un nouvel état, nous n’aurions qu’à ajouter une nouvelle struct et implémenter les méthodes du trait sur cette struct à un seul endroit.
L’implémentation utilisant le patron état est facile à étendre pour ajouter plus de fonctionnalités. Pour voir la simplicité de la maintenance du code qui utilise le patron état, essayez quelques-unes de ces suggestions :
- Ajouter une méthode
rejectqui change l’état de l’article dePendingReviewàDraft. - Exiger deux appels à
approveavant que l’état puisse être changé enPublished. - Permettre aux utilisateurs d’ajouter du contenu texte uniquement quand un article est dans l’état
Draft. Indice : faites en sorte que l’objet état soit responsable de ce qui pourrait changer dans le contenu mais pas de la modification duPost.
Un inconvénient du patron état est que, comme les états implémentent les transitions entre états, certains des états sont couplés les uns aux autres. Si nous ajoutons un autre état entre PendingReview et Published, comme Scheduled, nous devrions changer le code dans PendingReview pour effectuer la transition vers Scheduled à la place. Ce serait moins de travail si PendingReview n’avait pas besoin de changer avec l’ajout d’un nouvel état, mais cela signifierait passer à un autre patron de conception.
Un autre inconvénient est que nous avons dupliqué une partie de la logique. Pour éliminer une partie de la duplication, nous pourrions essayer de créer des implémentations par défaut pour les méthodes request_review et approve du trait State qui retournent self. Cependant, cela ne fonctionnerait pas : en utilisant State comme objet trait, le trait ne sait pas ce que sera exactement le self concret, donc le type de retour n’est pas connu au moment de la compilation. (C’est l’une des règles de compatibilité dyn mentionnées plus tôt.)
D’autres duplications incluent les implémentations similaires des méthodes request_review et approve de Post. Les deux méthodes utilisent Option::take avec le champ state de Post, et si state est Some, elles délèguent à l’implémentation de la même méthode de la valeur encapsulée et définissent la nouvelle valeur du champ state au résultat. Si nous avions beaucoup de méthodes sur Post qui suivaient ce motif, nous pourrions envisager de définir une macro pour éliminer la répétition (voir la section [« Macros »][macros] au chapitre 20).
En implémentant le patron état exactement comme il est défini pour les langages orientés objet, nous ne tirons pas pleinement parti des forces de Rust comme nous le pourrions. Voyons quelques changements que nous pouvons apporter au crate blog pour transformer les états et transitions invalides en erreurs de compilation.
Encoder les états et le comportement comme des types
Nous allons vous montrer comment repenser le patron état pour obtenir un ensemble différent de compromis. Plutôt que d’encapsuler complètement les états et les transitions pour que le code extérieur n’en ait aucune connaissance, nous encoderons les états dans différents types. Par conséquent, le système de vérification de types de Rust empêchera les tentatives d’utiliser des brouillons d’articles là où seuls les articles publiés sont autorisés en émettant une erreur de compilation.
Considérons la première partie de main dans l’encart 18-11 :
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
assert_eq!("", post.content());
post.request_review();
assert_eq!("", post.content());
post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}Nous permettons toujours la création de nouveaux articles dans l’état brouillon en utilisant Post::new et la capacité d’ajouter du texte au contenu de l’article. Mais au lieu d’avoir une méthode content sur un brouillon d’article qui retourné une chaîne vide, nous ferons en sorte que les brouillons d’articles n’aient pas du tout la méthode content. De cette façon, si nous essayons d’obtenir le contenu d’un brouillon d’article, nous obtiendrons une erreur du compilateur nous disant que la méthode n’existe pas. En conséquence, il sera impossible pour nous d’afficher accidentellement le contenu d’un brouillon d’article en production car ce code ne compilera même pas. L’encart 18-19 montre la définition d’une struct Post et d’une struct DraftPost, ainsi que les méthodes sur chacune.
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
}Post with a content method and a DraftPost without a content methodLes structs Post et DraftPost ont toutes deux un champ privé content qui stocké le texte de l’article de blog. Les structs n’ont plus le champ state car nous déplaçons l’encodage de l’état vers les types des structs. La struct Post représentera un article publié, et elle à une méthode content qui retourné le content.
Nous avons toujours une fonction Post::new, mais au lieu de retourner une instance de Post, elle retourné une instance de DraftPost. Comme content est privé et qu’il n’y a pas de fonctions qui retournent Post, il n’est pas possible de créer une instance de Post pour l’instant.
La struct DraftPost à une méthode add_text, donc nous pouvons ajouter du texte à content comme avant, mais notez que DraftPost n’a pas de méthode content définie ! Donc maintenant le programme garantit que tous les articles commencent comme des brouillons, et les brouillons n’ont pas leur contenu disponible pour l’affichage. Toute tentative de contourner ces contraintes résultera en une erreur du compilateur.
Alors, comment obtenir un article publié ? Nous voulons imposer la règle qu’un brouillon d’article doit être révisé et approuvé avant de pouvoir être publié. Un article en état de revue en attente ne devrait toujours pas afficher de contenu. Implémentons ces contraintes en ajoutant une autre struct, PendingReviewPost, en définissant la méthode request_review sur DraftPost pour retourner un PendingReviewPost et en définissant une méthode approve sur PendingReviewPost pour retourner un Post, comme montré dans l’encart 18-20.
pub struct Post {
content: String,
}
pub struct DraftPost {
content: String,
}
impl Post {
pub fn new() -> DraftPost {
DraftPost {
content: String::new(),
}
}
pub fn content(&self) -> &str {
&self.content
}
}
impl DraftPost {
// --snip--
pub fn add_text(&mut self, text: &str) {
self.content.push_str(text);
}
pub fn request_review(self) -> PendingReviewPost {
PendingReviewPost {
content: self.content,
}
}
}
pub struct PendingReviewPost {
content: String,
}
impl PendingReviewPost {
pub fn approve(self) -> Post {
Post {
content: self.content,
}
}
}PendingReviewPost that gets created by calling request_review on DraftPost and an approve method that turns a PendingReviewPost into a published PostLes méthodes request_review et approve prennent possession de self, consommant ainsi les instances DraftPost et PendingReviewPost et les transformant en un PendingReviewPost et un Post publié, respectivement. De cette façon, nous n’aurons pas d’instances DraftPost persistantes après avoir appelé request_review sur elles, et ainsi de suite. La struct PendingReviewPost n’a pas de méthode content définie, donc tenter de lire son contenu résulte en une erreur du compilateur, comme avec DraftPost. Comme le seul moyen d’obtenir une instance de Post publiée qui à une méthode content définie est d’appeler la méthode approve sur un PendingReviewPost, et le seul moyen d’obtenir un PendingReviewPost est d’appeler la méthode request_review sur un DraftPost, nous avons maintenant encodé le flux de travail des articles de blog dans le système de types.
Mais nous devons aussi apporter quelques petites modifications à main. Les méthodes request_review et approve retournent de nouvelles instances plutôt que de modifier la struct sur laquelle elles sont appelées, donc nous devons ajouter plus d’assignations par masquage let post = pour sauvegarder les instances retournées. Nous ne pouvons pas non plus avoir les assertions sur le contenu des brouillons et des articles en revue en attente comme des chaînes vides, et nous n’en avons pas besoin : nous ne pouvons plus compiler du code qui essaie d’utiliser le contenu des articles dans ces états. Le code mis à jour dans main est montré dans l’encart 18-21.
use blog::Post;
fn main() {
let mut post = Post::new();
post.add_text("I ate a salad for lunch today");
let post = post.request_review();
let post = post.approve();
assert_eq!("I ate a salad for lunch today", post.content());
}main to use the new implementation of the blog post workflowLes changements que nous avons dû apporter à main pour réassigner post signifient que cette implémentation ne suit plus tout à fait le patron état orienté objet : les transformations entre les états ne sont plus entièrement encapsulées dans l’implémentation de Post. Cependant, notre gain est que les états invalides sont maintenant impossibles grâce au système de types et à la vérification de types qui se fait au moment de la compilation ! Cela garantit que certains bugs, comme l’affichage du contenu d’un article non publié, seront découverts avant qu’ils n’arrivent en production.
Essayez les tâches suggérées au début de cette section sur le crate blog tel qu’il est après l’encart 18-21 pour voir ce que vous pensez de la conception de cette version du code. Notez que certaines des tâches pourraient déjà être complétées dans cette conception.
Nous avons vu que même si Rust est capable d’implémenter des patrons de conception orientés objet, d’autres patrons, comme encoder l’état dans le système de types, sont aussi disponibles en Rust. Ces patrons ont des compromis différents. Bien que vous puissiez être très familier avec les patrons orientés objet, repenser le problème pour tirer parti des fonctionnalités de Rust peut apporter des avantages, comme prévenir certains bugs au moment de la compilation. Les patrons orientés objet ne seront pas toujours la meilleure solution en Rust en raison de certaines fonctionnalités, comme la possession, que les langages orientés objet n’ont pas.
Résumé
Que vous pensiez ou non que Rust est un langage orienté objet après avoir lu ce chapitre, vous savez maintenant que vous pouvez utiliser des objets trait pour obtenir certaines fonctionnalités orientées objet en Rust. La répartition dynamique peut donner à votre code une certaine flexibilité en échange d’un peu de performance à l’exécution. Vous pouvez utiliser cette flexibilité pour implémenter des patrons orientés objet qui peuvent aider la maintenabilité de votre code. Rust a aussi d’autres fonctionnalités, comme la possession, que les langages orientés objet n’ont pas. Un patron orienté objet ne sera pas toujours la meilleure façon de tirer parti des forces de Rust, mais c’est une option disponible.
Ensuite, nous examinerons les motifs, qui sont une autre fonctionnalité de Rust permettant beaucoup de flexibilité. Nous les avons examinés brièvement tout au long du livre mais n’avons pas encore vu toutes leurs capacités. Allons-y !
Les motifs et le filtrage
Les motifs sont une syntaxe spéciale en Rust permettant de faire correspondre la structure des types, qu’ils soient complexes ou simples. L’utilisation de motifs en conjonction avec les expressions match et d’autres constructions vous donne davantage de contrôle sur le flux d’exécution d’un programme. Un motif est constitué d’une combinaison des éléments suivants :
- Des littéraux
- Des tableaux, enums, structures ou tuples déstructurés
- Des variables
- Des jokers (wildcards)
- Des espaces réservés (placeholders)
Quelques exemples de motifs incluent x, (a, 3) et Some(Color::Red). Dans les contextes où les motifs sont valides, ces composants décrivent la forme des données. Notre programme compare ensuite les valeurs aux motifs pour déterminer si les données ont la forme correcte pour continuer l’exécution d’un morceau de code particulier.
Pour utiliser un motif, nous le comparons à une valeur. Si le motif correspond à la valeur, nous utilisons les parties de la valeur dans notre code. Rappelez-vous les expressions match du chapitre 6 qui utilisaient des motifs, comme l’exemple de la machine à trier les pièces de monnaie. Si la valeur correspond à la forme du motif, nous pouvons utiliser les éléments nommés. Sinon, le code associé au motif ne s’exécutera pas.
Ce chapitre est une référence sur tout ce qui concerne les motifs. Nous couvrirons les endroits valides pour utiliser des motifs, la différence entre les motifs réfutables et irréfutables, et les différents types de syntaxe de motifs que vous pourriez rencontrer. À la fin du chapitre, vous saurez comment utiliser les motifs pour exprimer de nombreux concepts de manière claire.
Tous les endroits où les motifs peuvent être utilisés
Tous les endroits où les motifs peuvent être utilisés
Les motifs apparaissent à de nombreux endroits en Rust, et vous les avez beaucoup utilisés sans vous en rendre compte ! Cette section présente tous les endroits où les motifs sont valides.
Les branches de match
Comme nous l’avons vu au chapitre 6, nous utilisons des motifs dans les branches des expressions match. Formellement, les expressions match sont définies par le mot-clé match, une valeur sur laquelle effectuer la correspondance, et une où plusieurs branches composées d’un motif et d’une expression à exécuter si la valeur correspond au motif de cette branche, comme ceci :
match VALUE {
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
PATTERN => EXPRESSION,
}Par exemple, voici l’expression match de l’encart 6-5 qui effectue une correspondance sur une valeur Option<i32> dans la variable x :
match x {
None => None,
Some(i) => Some(i + 1),
}Les motifs dans cette expression match sont None et Some(i) à gauche de chaque flèche.
Une exigence des expressions match est qu’elles doivent être exhaustives, c’est-à-dire que toutes les possibilités pour la valeur dans l’expression match doivent être couvertes. Un moyen de s’assurer que vous avez couvert toutes les possibilités est d’avoir un motif attrape-tout pour la dernière branche : par exemple, un nom de variable qui correspond à n’importe quelle valeur ne peut jamais échouer et couvre donc tous les cas restants.
Le motif particulier _ correspond à n’importe quoi, mais il ne se lie jamais à une variable, c’est pourquoi il est souvent utilisé dans la dernière branche de match. Le motif _ peut être utile lorsque vous souhaitez ignorer toute valeur non spécifiée, par exemple. Nous couvrirons le motif _ plus en détail dans la section [“Ignorer des valeurs dans un motif”][ignoring-values-in-a-pattern] plus loin dans ce chapitre.
Les instructions let
Avant ce chapitre, nous n’avions discuté explicitement de l’utilisation des motifs qu’avec match et if let, mais en réalité, nous avons utilisé des motifs à d’autres endroits également, notamment dans les instructions let. Par exemple, considérez cette assignation simple de variable avec let :
#![allow(unused)]
fn main() {
let x = 5;
}Chaque fois que vous avez utilisé une instruction let comme celle-ci, vous utilisiez des motifs, même si vous ne vous en êtes peut-être pas rendu compte ! Plus formellement, une instruction let ressemble à ceci :
let PATTERN = EXPRESSION;
Dans les instructions comme let x = 5; avec un nom de variable à l’emplacement du MOTIF, le nom de variable n’est qu’une forme particulièrement simple de motif. Rust compare l’expression au motif et assigne tous les noms qu’il trouve. Ainsi, dans l’exemple let x = 5;, x est un motif qui signifie “lier ce qui correspond ici à la variable x.” Comme le nom x constitue l’intégralité du motif, ce motif signifie effectivement “lier tout à la variable x, quelle que soit la valeur.”
Pour voir l’aspect de correspondance de motifs de let plus clairement, considérez l’encart 19-1, qui utilise un motif avec let pour déstructurer un tuple.
fn main() {
let (x, y, z) = (1, 2, 3);
}Ici, nous faisons correspondre un tuple à un motif. Rust compare la valeur (1, 2, 3) au motif (x, y, z) et constate que la valeur correspond au motif – c’est-à-dire qu’il voit que le nombre d’éléments est le même dans les deux – donc Rust lie 1 à x, 2 à y et 3 à z. Vous pouvez considérer ce motif de tuple comme l’imbrication de trois motifs de variables individuels.
Si le nombre d’éléments dans le motif ne correspond pas au nombre d’éléments dans le tuple, le type global ne correspondra pas et nous obtiendrons une erreur du compilateur. Par exemple, l’encart 19-2 montre une tentative de déstructurer un tuple de trois éléments en deux variables, ce qui ne fonctionnera pas.
fn main() {
let (x, y) = (1, 2, 3);
}Tenter de compiler ce code produit cette erreur de type : console {{#include ../listings/ch19-patterns-and-matching/listing-19-02/output.txt}}
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0308]: mismatched types
--> src/main.rs:2:9
|
2 | let (x, y) = (1, 2, 3);
| ^^^^^^ --------- this expression has type `({integer}, {integer}, {integer})`
| |
| expected a tuple with 3 elements, found one with 2 elements
|
= note: expected tuple `({integer}, {integer}, {integer})`
found tuple `(_, _)`
For more information about this error, try `rustc --explain E0308`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Pour corriger l’erreur, nous pourrions ignorer une où plusieurs valeurs du tuple en utilisant _ ou .., comme vous le verrez dans la section [“Ignorer des valeurs dans un motif”][ignoring-values-in-a-pattern]. Si le problème est que nous avons trop de variables dans le motif, la solution est de faire correspondre les types en supprimant des variables afin que le nombre de variables soit égal au nombre d’éléments dans le tuple.
Les expressions conditionnelles if let
Au chapitre 6, nous avons vu comment utiliser les expressions if let principalement comme une manière plus concise d’écrire l’équivalent d’un match qui ne correspond qu’à un seul cas. Optionnellement, if let peut avoir un else correspondant contenant du code à exécuter si le motif du if let ne correspond pas.
L’encart 19-3 montre qu’il est également possible de combiner des expressions if let, else if et else if let. Cela nous donne plus de flexibilité qu’une expression match dans laquelle nous ne pouvons exprimer qu’une seule valeur à comparer avec les motifs. De plus, Rust n’exige pas que les conditions d’une série de branches if let, else if et else if let soient liées entre elles.
Le code de l’encart 19-3 détermine quelle couleur donner à votre arrière-plan en fonction d’une série de vérifications de plusieurs conditions. Pour cet exemple, nous avons créé des variables avec des valeurs codées en dur qu’un vrai programme pourrait recevoir en entrée de l’utilisateur.
fn main() {
let favorite_color: Option<&str> = None;
let is_tuesday = false;
let age: Result<u8, _> = "34".parse();
if let Some(color) = favorite_color {
println!("Using your favorite color, {color}, as the background");
} else if is_tuesday {
println!("Tuesday is green day!");
} else if let Ok(age) = age {
if age > 30 {
println!("Using purple as the background color");
} else {
println!("Using orange as the background color");
}
} else {
println!("Using blue as the background color");
}
}if let, else if, else if let, and elseSi l’utilisateur spécifie une couleur préférée, cette couleur est utilisée comme arrière-plan. Si aucune couleur préférée n’est spécifiée et que nous sommes mardi, la couleur d’arrière-plan est le vert. Sinon, si l’utilisateur spécifie son âge sous forme de chaîne de caractères et que nous pouvons l’analyser avec succès comme un nombre, la couleur est soit le violet soit l’orange selon la valeur du nombre. Si aucune de ces conditions ne s’applique, la couleur d’arrière-plan est le bleu.
Cette structure conditionnelle nous permet de prendre en charge des exigences complexes. Avec les valeurs codées en dur que nous avons ici, cet exemple affichera Using purple as the background color.
Vous pouvez voir que if let peut aussi introduire de nouvelles variables qui masquent les variables existantes de la même manière que les branches de match : la ligne if let Ok(age) = age introduit une nouvelle variable age qui contient la valeur à l’intérieur de la variante Ok, masquant la variable age existante. Cela signifie que nous devons placer la condition if age > 30 à l’intérieur de ce bloc : nous ne pouvons pas combiner ces deux conditions en if let Ok(age) = age && age > 30. Le nouveau age que nous voulons comparer à 30 n’est pas valide tant que la nouvelle portée ne commence pas avec l’accolade ouvrante.
L’inconvénient d’utiliser des expressions if let est que le compilateur ne vérifie pas l’exhaustivité, alors qu’il le fait avec les expressions match. Si nous omettions le dernier bloc else et manquions ainsi la gestion de certains cas, le compilateur ne nous alerterait pas du possible bogue logique.
Les boucles conditionnelles while let
De construction similaire à if let, la boucle conditionnelle while let permet à une boucle while de s’exécuter tant qu’un motif continue de correspondre. Dans l’encart 19-4, nous montrons une boucle while let qui attend des messages envoyés entre des tâches, mais dans ce cas en vérifiant un Result au lieu d’un Option.
fn main() {
let (tx, rx) = std::sync::mpsc::channel();
std::thread::spawn(move || {
for val in [1, 2, 3] {
tx.send(val).unwrap();
}
});
while let Ok(value) = rx.recv() {
println!("{value}");
}
}while let loop to print values for as long as rx.recv() returns OkCet exemple affiche 1, 2, puis 3. La méthode recv prend le premier message du côté récepteur du canal et retourné un Ok(value). Lorsque nous avons vu recv pour la première fois au chapitre 16, nous avions déballé l’erreur directement, ou nous avions interagi avec lui comme un itérateur en utilisant une boucle for. Comme le montre l’encart 19-4, cependant, nous pouvons aussi utiliser while let, car la méthode recv retourné un Ok chaque fois qu’un message arrive, tant que l’émetteur existe, puis produit un Err une fois que le côté émetteur se déconnecte.
Les boucles for
Dans une boucle for, la valeur qui suit directement le mot-clé for est un motif. Par exemple, dans for x in y, le x est le motif. L’encart 19-5 montre comment utiliser un motif dans une boucle for pour déstructurer, ou décomposer, un tuple dans le cadre de la boucle for.
fn main() {
let v = vec!['a', 'b', 'c'];
for (index, value) in v.iter().enumerate() {
println!("{value} is at index {index}");
}
}for loop to destructure a tupleLe code de l’encart 19-5 affichera ce qui suit : console {{#include ../listings/ch19-patterns-and-matching/listing-19-05/output.txt}}
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.52s
Running `target/debug/patterns`
a is at index 0
b is at index 1
c is at index 2
Nous adaptons un itérateur en utilisant la méthode enumerate afin qu’il produise une valeur et l’indice de cette valeur, placés dans un tuple. La première valeur produite est le tuple (0, 'a'). Lorsque cette valeur est mise en correspondance avec le motif (index, value), index vaudra 0 et value vaudra 'a', affichant la première ligne de la sortie.
Les paramètres de fonction
Les paramètres de fonction peuvent également être des motifs. Le code de l’encart 19-6, qui déclare une fonction nommée foo prenant un paramètre nommé x de type i32, devrait désormais vous sembler familier.
fn foo(x: i32) {
// code goes here
}
fn main() {}La partie x est un motif ! Comme nous l’avons fait avec let, nous pourrions faire correspondre un tuple dans les arguments d’une fonction au motif. L’encart 19-7 décompose les valeurs d’un tuple lorsque nous le passons à une fonction.
fn print_coordinates(&(x, y): &(i32, i32)) {
println!("Current location: ({x}, {y})");
}
fn main() {
let point = (3, 5);
print_coordinates(&point);
}Ce code affiche Current location: (3, 5). Les valeurs &(3, 5) correspondent au motif &(x, y), donc x vaut 3 et y vaut 5.
Nous pouvons également utiliser des motifs dans les listes de paramètres des fermetures de la même manière que dans les listes de paramètres des fonctions, car les fermetures sont similaires aux fonctions, comme nous l’avons vu au chapitre 13.
À ce stade, vous avez vu plusieurs manières d’utiliser les motifs, mais les motifs ne fonctionnent pas de la même façon à chaque endroit où nous pouvons les utiliser. À certains endroits, les motifs doivent être irréfutables ; dans d’autres circonstances, ils peuvent être réfutables. Nous allons discuter de ces deux concepts maintenant.
La réfutabilité : quand un motif pourrait ne pas correspondre
La réfutabilité : quand un motif pourrait ne pas correspondre
Les motifs se présentent sous deux formes : réfutables et irréfutables. Les motifs qui correspondent à toute valeur possible sont irréfutables. Un exemple serait x dans l’instruction let x = 5; car x correspond à n’importe quoi et ne peut donc pas échouer. Les motifs qui peuvent échouer pour certaines valeurs possibles sont réfutables. Un exemple serait Some(x) dans l’expression if let Some(x) = a_value car si la valeur dans la variable a_value est None plutôt que Some, le motif Some(x) ne correspondra pas.
Les paramètres de fonction, les instructions let et les boucles for ne peuvent accepter que des motifs irréfutables car le programme ne peut rien faire de significatif lorsque les valeurs ne correspondent pas. Les expressions if let et while let et l’instruction let...else acceptent des motifs réfutables et irréfutables, mais le compilateur avertit contre les motifs irréfutables car, par définition, ils sont destinés à gérer un éventuel échec : la fonctionnalité d’une condition réside dans sa capacité à se comporter différemment selon le succès ou l’échec.
En général, vous ne devriez pas avoir à vous soucier de la distinction entre motifs réfutables et irréfutables ; cependant, vous devez être familier avec le concept de réfutabilité afin de pouvoir réagir lorsque vous le rencontrez dans un message d’erreur. Dans ces cas, vous devrez modifier soit le motif, soit la construction avec laquelle vous utilisez le motif, selon le comportement souhaité du code.
Regardons un exemple de ce qui se passe lorsque nous essayons d’utiliser un motif réfutable là où Rust exige un motif irréfutable et vice versa. L’encart 19-8 montre une instruction let, mais pour le motif, nous avons spécifié Some(x), un motif réfutable. Comme vous pouvez vous y attendre, ce code ne compilera pas.
fn main() {
let some_option_value: Option<i32> = None;
let Some(x) = some_option_value;
}letSi some_option_value était une valeur None, elle ne correspondrait pas au motif Some(x), ce qui signifie que le motif est réfutable. Cependant, l’instruction let ne peut accepter qu’un motif irréfutable car le code ne peut rien faire de valide avec une valeur None. Au moment de la compilation, Rust se plaindra que nous avons essayé d’utiliser un motif réfutable là où un motif irréfutable est requis : console {{#include ../listings/ch19-patterns-and-matching/listing-19-08/output.txt}}
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error[E0005]: refutable pattern in local binding
--> src/main.rs:3:9
|
3 | let Some(x) = some_option_value;
| ^^^^^^^ pattern `None` not covered
|
= note: `let` bindings require an "irrefutable pattern", like a `struct` or an `enum` with only one variant
= note: for more information, visit https://doc.rust-lang.org/book/ch19-02-refutability.html
= note: the matched value is of type `Option<i32>`
help: you might want to use `let else` to handle the variant that isn't matched
|
3 | let Some(x) = some_option_value else { todo!() };
| ++++++++++++++++
For more information about this error, try `rustc --explain E0005`.
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Comme nous n’avons pas couvert (et ne pouvions pas couvrir !) toutes les valeurs valides avec le motif Some(x), Rust produit à juste titre une erreur de compilation.
Si nous avons un motif réfutable là où un motif irréfutable est nécessaire, nous pouvons corriger cela en modifiant le code qui utilise le motif : au lieu d’utiliser let, nous pouvons utiliser let...else. Alors, si le motif ne correspond pas, le code entre les accolades gérera la valeur. L’encart 19-9 montre comment corriger le code de l’encart 19-8.
fn main() {
let some_option_value: Option<i32> = None;
let Some(x) = some_option_value else {
return;
};
}let...else and a block with refutable patterns instead of letNous avons donné au code une porte de sortie ! Ce code est parfaitement valide, bien que cela signifie que nous ne pouvons pas utiliser un motif irréfutable sans recevoir un avertissement. Si nous donnons à let...else un motif qui correspondra toujours, comme x, comme montré dans l’encart 19-10, le compilateur émettra un avertissement.
fn main() {
let x = 5 else {
return;
};
}let...elseRust se plaint qu’il n’a pas de sens d’utiliser let...else avec un motif irréfutable : console {{#include ../listings/ch19-patterns-and-matching/listing-19-10/output.txt}}
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
warning: irrefutable `let...else` pattern
--> src/main.rs:2:5
|
2 | let x = 5 else {
| ^^^^^^^^^
|
= note: this pattern will always match, so the `else` clause is useless
= help: consider removing the `else` clause
= note: `#[warn(irrefutable_let_patterns)]` on by default
warning: `patterns` (bin "patterns") generated 1 warning
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.39s
Running `target/debug/patterns`
Pour cette raison, les branches de match doivent utiliser des motifs réfutables, sauf pour la dernière branche, qui doit correspondre à toutes les valeurs restantes avec un motif irréfutable. Rust nous permet d’utiliser un motif irréfutable dans un match avec une seule branche, mais cette syntaxe n’est pas particulièrement utile et pourrait être remplacée par une instruction let plus simple.
Maintenant que vous savez où utiliser les motifs et la différence entre les motifs réfutables et irréfutables, couvrons toute la syntaxe que nous pouvons utiliser pour créer des motifs.
La syntaxe des motifs
La syntaxe des motifs
Dans cette section, nous rassemblons toute la syntaxe valide dans les motifs et discutons pourquoi et quand vous pourriez vouloir utiliser chacune d’elles.
Correspondance avec des littéraux
Comme vous l’avez vu au chapitre 6, vous pouvez faire correspondre des motifs directement avec des littéraux. Le code suivant donne quelques exemples : rust {{#rustdoc_include ../listings/ch19-patterns-and-matching/no-listing-01-literals/src/main.rs:here}}
fn main() {
let x = 1;
match x {
1 => println!("one"),
2 => println!("two"),
3 => println!("three"),
_ => println!("anything"),
}
}Ce code affiche one car la valeur de x est 1. Cette syntaxe est utile lorsque vous voulez que votre code effectue une action s’il reçoit une valeur concrète particulière.
Correspondance avec des variables nommées
Les variables nommées sont des motifs irréfutables qui correspondent à n’importe quelle valeur, et nous les avons utilisées de nombreuses fois dans ce livre. Cependant, il y à une complication lorsque vous utilisez des variables nommées dans des expressions match, if let ou while let. Comme chacun de ces types d’expressions ouvre une nouvelle portée, les variables déclarées en tant que partie d’un motif à l’intérieur de ces expressions masqueront celles ayant le même nom en dehors de la construction, comme c’est le cas pour toutes les variables. Dans l’encart 19-11, nous déclarons une variable nommée x avec la valeur Some(5) et une variable y avec la valeur 10. Nous créons ensuite une expression match sur la valeur x. Regardez les motifs dans les branches du match et le println! à la fin, et essayez de deviner ce que le code affichera avant de l’exécuter ou de lire plus loin.
fn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("Got 50"),
Some(y) => println!("Matched, y = {y}"),
_ => println!("Default case, x = {x:?}"),
}
println!("at the end: x = {x:?}, y = {y}");
}match expression with an arm that introduces a new variable which shadows an existing variable yVoyons ce qui se passe lorsque l’expression match s’exécute. Le motif de la première branche ne correspond pas à la valeur définie de x, donc le code continue.
Le motif de la deuxième branche introduit une nouvelle variable nommée y qui correspondra à n’importe quelle valeur à l’intérieur d’une valeur Some. Comme nous sommes dans une nouvelle portée à l’intérieur de l’expression match, c’est une nouvelle variable y, pas le y que nous avons déclaré au début avec la valeur 10. Cette nouvelle liaison y correspondra à n’importe quelle valeur à l’intérieur d’un Some, ce qui est ce que nous avons dans x. Par conséquent, ce nouveau y se lie à la valeur interne du Some dans x. Cette valeur est 5, donc l’expression de cette branche s’exécute et affiche Matched, y = 5.
Si x avait été une valeur None au lieu de Some(5), les motifs des deux premières branches n’auraient pas correspondu, donc la valeur aurait correspondu au tiret bas. Nous n’avons pas introduit la variable x dans le motif de la branche avec le tiret bas, donc le x dans l’expression est toujours le x extérieur qui n’a pas été masqué. Dans ce cas hypothétique, le match aurait affiché Default case, x = None.
Lorsque l’expression match est terminée, sa portée se terminé, et celle du y interne aussi. Le dernier println! produit at the end: x = Some(5), y = 10.
Pour créer une expression match qui compare les valeurs du x et du y extérieurs, plutôt que d’introduire une nouvelle variable qui masque la variable y existante, nous devrions utiliser une condition de garde de correspondance à la place. Nous parlerons des gardes de correspondance plus loin dans la section “Ajouter des conditions avec les gardes de correspondance”.
Correspondance avec plusieurs motifs
Dans les expressions match, vous pouvez faire correspondre plusieurs motifs en utilisant la syntaxe |, qui est l’opérateur ou pour les motifs. Par exemple, dans le code suivant, nous faisons correspondre la valeur de x aux branches du match, la première ayant une option ou, ce qui signifie que si la valeur de x correspond à l’une où l’autre des valeurs de cette branche, le code de cette branche s’exécutera : rust {{#rustdoc_include ../listings/ch19-patterns-and-matching/no-listing-02-multiple-patterns/src/main.rs:here}}
fn main() {
let x = 1;
match x {
1 | 2 => println!("one or two"),
3 => println!("three"),
_ => println!("anything"),
}
}Ce code affiche one or two.
Correspondance avec des intervalles de valeurs avec ..=
La syntaxe ..= nous permet de faire correspondre un intervalle inclusif de valeurs. Dans le code suivant, lorsqu’un motif correspond à l’une des valeurs de l’intervalle donné, cette branche s’exécutera : rust {{#rustdoc_include ../listings/ch19-patterns-and-matching/no-listing-03-ranges/src/main.rs:here}}
fn main() {
let x = 5;
match x {
1..=5 => println!("one through five"),
_ => println!("something else"),
}
}Si x vaut 1, 2, 3, 4 ou 5, la première branche correspondra. Cette syntaxe est plus pratique pour des correspondances avec plusieurs valeurs que d’utiliser l’opérateur | pour exprimer la même idée ; si nous utilisions |, nous devrions spécifier 1 | 2 | 3 | 4 | 5. Spécifier un intervalle est beaucoup plus court, surtout si nous voulons correspondre, disons, à n’importe quel nombre entre 1 et 1 000 !
Le compilateur vérifie que l’intervalle n’est pas vide au moment de la compilation, et comme les seuls types pour lesquels Rust peut déterminer si un intervalle est vide ou non sont char et les valeurs numériques, les intervalles ne sont autorisés qu’avec des valeurs numériques ou char.
Voici un exemple utilisant des intervalles de valeurs char : rust {{#rustdoc_include ../listings/ch19-patterns-and-matching/no-listing-04-ranges-of-char/src/main.rs:here}}
fn main() {
let x = 'c';
match x {
'a'..='j' => println!("early ASCII letter"),
'k'..='z' => println!("late ASCII letter"),
_ => println!("something else"),
}
}Rust peut déterminer que 'c' se trouve dans l’intervalle du premier motif et affiche early ASCII letter.
La déstructuration pour décomposer des valeurs
Nous pouvons également utiliser des motifs pour déstructurer des structures, des enums et des tuples afin d’utiliser différentes parties de ces valeurs. Parcourons chaque type de valeur.
Les structures
L’encart 19-12 montre une structure Point avec deux champs, x et y, que nous pouvons décomposer en utilisant un motif avec une instruction let.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x: a, y: b } = p;
assert_eq!(0, a);
assert_eq!(7, b);
}Ce code crée les variables a et b qui correspondent aux valeurs des champs x et y de la structure p. Cet exemple montre que les noms des variables dans le motif n’ont pas besoin de correspondre aux noms des champs de la structure. Cependant, il est courant de faire correspondre les noms de variables aux noms de champs pour faciliter la mémorisation de quelles variables proviennent de quels champs. En raison de cet usage courant, et parce qu’écrire let Point { x: x, y: y } = p; contient beaucoup de duplication, Rust propose un raccourci pour les motifs qui correspondent aux champs de structures : vous n’avez qu’à lister le nom du champ de la structure, et les variables créées à partir du motif auront les mêmes noms. L’encart 19-13 se comporte de la même manière que le code de l’encart 19-12, mais les variables créées dans le motif let sont x et y au lieu de a et b.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
let Point { x, y } = p;
assert_eq!(0, x);
assert_eq!(7, y);
}Ce code crée les variables x et y qui correspondent aux champs x et y de la variable p. Le résultat est que les variables x et y contiennent les valeurs de la structure p.
Nous pouvons aussi déstructurer avec des valeurs littérales dans le motif de la structure plutôt que de créer des variables pour tous les champs. Cela nous permet de tester certains champs pour des valeurs particulières tout en créant des variables pour déstructurer les autres champs.
Dans l’encart 19-14, nous avons une expression match qui sépare les valeurs Point en trois cas : les points qui se trouvent directement sur l’axe x (ce qui est vrai lorsque y = 0), sur l’axe y (x = 0), ou sur aucun des deux axes.
struct Point {
x: i32,
y: i32,
}
fn main() {
let p = Point { x: 0, y: 7 };
match p {
Point { x, y: 0 } => println!("On the x axis at {x}"),
Point { x: 0, y } => println!("On the y axis at {y}"),
Point { x, y } => {
println!("On neither axis: ({x}, {y})");
}
}
}La première branche correspondra à tout point situé sur l’axe x en spécifiant que le champ y correspond si sa valeur correspond au littéral 0. Le motif crée toujours une variable x que nous pouvons utiliser dans le code de cette branche.
De même, la deuxième branche correspond à tout point sur l’axe y en spécifiant que le champ x correspond si sa valeur est 0 et crée une variable y pour la valeur du champ y. La troisième branche ne spécifie aucun littéral, elle correspond donc à tout autre Point et crée des variables pour les champs x et y.
Dans cet exemple, la valeur p correspond à la deuxième branche car x contient 0, donc ce code affichera On the y axis at 7.
Rappelez-vous qu’une expression match arrête de vérifier les branches dès qu’elle a trouvé le premier motif correspondant, donc même si Point { x: 0, y: 0 } est sur l’axe x et l’axe y, ce code n’afficherait que On the x axis at 0.
Les enums
Nous avons déstructuré des enums dans ce livre (par exemple, l’encart 6-5 au chapitre 6), mais nous n’avons pas encore discuté explicitement du fait que le motif pour déstructurer un enum correspond à la manière dont les données stockées dans l’enum sont définies. À titre d’exemple, dans l’encart 19-15, nous utilisons l’enum Message de l’encart 6-2 et écrivons un match avec des motifs qui déstructureront chaque valeur interne.
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(i32, i32, i32),
}
fn main() {
let msg = Message::ChangeColor(0, 160, 255);
match msg {
Message::Quit => {
println!("The Quit variant has no data to destructure.");
}
Message::Move { x, y } => {
println!("Move in the x direction {x} and in the y direction {y}");
}
Message::Write(text) => {
println!("Text message: {text}");
}
Message::ChangeColor(r, g, b) => {
println!("Change color to red {r}, green {g}, and blue {b}");
}
}
}Ce code affichera Change color to red 0, green 160, and blue 255. Essayez de changer la valeur de msg pour voir le code des autres branches s’exécuter.
Pour les variantes d’enum sans données, comme Message::Quit, nous ne pouvons pas déstructurer davantage la valeur. Nous ne pouvons que correspondre à la valeur littérale Message::Quit, et il n’y a pas de variables dans ce motif.
Pour les variantes d’enum de type structure, comme Message::Move, nous pouvons utiliser un motif similaire à celui que nous spécifions pour correspondre aux structures. Après le nom de la variante, nous plaçons des accolades, puis listons les champs avec des variables afin de décomposer les éléments à utiliser dans le code de cette branche. Ici, nous utilisons la forme raccourcie comme dans l’encart 19-13.
Pour les variantes d’enum de type tuple, comme Message::Write qui contient un tuple avec un élément et Message::ChangeColor qui contient un tuple avec trois éléments, le motif est similaire à celui que nous spécifions pour correspondre aux tuples. Le nombre de variables dans le motif doit correspondre au nombre d’éléments dans la variante que nous faisons correspondre.
Les structures et enums imbriqués
Jusqu’à présent, nos exemples ont tous fait correspondre des structures ou des enums à un seul niveau de profondeur, mais la correspondance peut aussi fonctionner sur des éléments imbriqués ! Par exemple, nous pouvons remanier le code de l’encart 19-15 pour prendre en charge les couleurs RGB et HSV dans le message ChangeColor, comme montré dans l’encart 19-16.
enum Color {
Rgb(i32, i32, i32),
Hsv(i32, i32, i32),
}
enum Message {
Quit,
Move { x: i32, y: i32 },
Write(String),
ChangeColor(Color),
}
fn main() {
let msg = Message::ChangeColor(Color::Hsv(0, 160, 255));
match msg {
Message::ChangeColor(Color::Rgb(r, g, b)) => {
println!("Change color to red {r}, green {g}, and blue {b}");
}
Message::ChangeColor(Color::Hsv(h, s, v)) => {
println!("Change color to hue {h}, saturation {s}, value {v}");
}
_ => (),
}
}Le motif de la première branche dans l’expression match correspond à une variante d’enum Message::ChangeColor qui contient une variante Color::Rgb ; ensuite, le motif se lie aux trois valeurs i32 internes. Le motif de la deuxième branche correspond aussi à une variante d’enum Message::ChangeColor, mais l’enum interne correspond à Color::Hsv à la place. Nous pouvons spécifier ces conditions complexes dans une seule expression match, même si deux enums sont impliqués.
Les structures et les tuples
Nous pouvons combiner, faire correspondre et imbriquer des motifs de déstructuration de manières encore plus complexes. L’exemple suivant montre une déstructuration compliquée où nous imbriquons des structures et des tuples dans un tuple et déstructurons toutes les valeurs primitives : rust {{#rustdoc_include ../listings/ch19-patterns-and-matching/no-listing-05-destructuring-structs-and-tuples/src/main.rs:here}}
fn main() {
struct Point {
x: i32,
y: i32,
}
let ((feet, inches), Point { x, y }) = ((3, 10), Point { x: 3, y: -10 });
}Ce code nous permet de décomposer des types complexes en leurs éléments constitutifs afin que nous puissions utiliser séparément les valeurs qui nous intéressent.
La déstructuration avec des motifs est un moyen pratique d’utiliser des morceaux de valeurs, comme la valeur de chaque champ d’une structure, séparément les uns des autres.
Ignorer des valeurs dans un motif
Vous avez vu qu’il est parfois utile d’ignorer des valeurs dans un motif, comme dans la dernière branche d’un match, pour obtenir un attrape-tout qui ne fait rien en pratique mais couvre toutes les valeurs possibles restantes. Il existe plusieurs manières d’ignorer des valeurs entières ou des parties de valeurs dans un motif : en utilisant le motif _ (que vous avez déjà vu), en utilisant le motif _ à l’intérieur d’un autre motif, en utilisant un nom commençant par un tiret bas, ou en utilisant .. pour ignorer les parties restantes d’une valeur. Explorons comment et pourquoi utiliser chacun de ces motifs.
Une valeur entière avec _
Nous avons utilisé le tiret bas comme motif joker qui correspond à n’importe quelle valeur sans se lier à la valeur. C’est particulièrement utile comme dernière branche d’une expression match, mais nous pouvons aussi l’utiliser dans n’importe quel motif, y compris les paramètres de fonction, comme montré dans l’encart 19-17.
fn foo(_: i32, y: i32) {
println!("This code only uses the y parameter: {y}");
}
fn main() {
foo(3, 4);
}_ in a function signatureCe code ignorera complètement la valeur 3 passée comme premier argument, et affichera This code only uses the y parameter: 4.
Dans la plupart des cas, lorsque vous n’avez plus besoin d’un paramètre de fonction particulier, vous changeriez la signature pour qu’elle n’inclue pas le paramètre inutilisé. Ignorer un paramètre de fonction peut être particulièrement utile dans les cas où, par exemple, vous implémentez un trait nécessitant une certaine signature de type mais le corps de la fonction dans votre implémentation n’a pas besoin de l’un des paramètres. Vous évitez alors un avertissement du compilateur concernant les paramètres de fonction inutilisés, comme cela se produirait si vous utilisiez un nom à la place.
Des parties d’une valeur avec un _ imbriqué
Nous pouvons aussi utiliser _ à l’intérieur d’un autre motif pour ignorer seulement une partie d’une valeur, par exemple, lorsque nous voulons tester seulement une partie d’une valeur mais n’avons pas besoin des autres parties dans le code correspondant que nous voulons exécuter. L’encart 19-18 montre du code chargé de gérer la valeur d’un paramètre. Les exigences métier sont que l’utilisateur ne doit pas être autorisé à écraser une personnalisation existante d’un paramètre, mais peut annuler le paramètre et lui donner une valeur s’il n’est pas actuellement défini.
fn main() {
let mut setting_value = Some(5);
let new_setting_value = Some(10);
match (setting_value, new_setting_value) {
(Some(_), Some(_)) => {
println!("Can't overwrite an existing customized value");
}
_ => {
setting_value = new_setting_value;
}
}
println!("setting is {setting_value:?}");
}Some variants when we don’t need to use the value inside the SomeCe code affichera Can't overwrite an existing customized value puis setting is Some(5). Dans la première branche du match, nous n’avons pas besoin de faire correspondre ou d’utiliser les valeurs à l’intérieur des variantes Some, mais nous devons tester le cas où setting_value et new_setting_value sont des variantes Some. Dans ce cas, nous affichons la raison pour laquelle nous ne changeons pas setting_value, et elle n’est pas modifiée.
Dans tous les autres cas (si soit setting_value soit new_setting_value est None) exprimés par le motif _ dans la deuxième branche, nous voulons permettre à new_setting_value de devenir setting_value.
Nous pouvons aussi utiliser des tirets bas à plusieurs endroits dans un seul motif pour ignorer des valeurs particulières. L’encart 19-19 montre un exemple d’ignorance de la deuxième et de la quatrième valeurs dans un tuple de cinq éléments.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(first, _, third, _, fifth) => {
println!("Some numbers: {first}, {third}, {fifth}");
}
}
}Ce code affichera Some numbers: 2, 8, 32, et les valeurs 4 et 16 seront ignorées.
Une variable inutilisée en commençant son nom par _
Si vous créez une variable mais ne l’utilisez nulle part, Rust émettra généralement un avertissement car une variable inutilisée pourrait être un bogue. Cependant, il est parfois utile de pouvoir créer une variable que vous n’utiliserez pas encore, par exemple lorsque vous faites du prototypage ou que vous démarrez un projet. Dans cette situation, vous pouvez dire à Rust de ne pas vous avertir de la variable inutilisée en commençant le nom de la variable par un tiret bas. Dans l’encart 19-20, nous créons deux variables inutilisées, mais lorsque nous compilons ce code, nous ne devrions recevoir un avertissement que pour l’une d’entre elles.
fn main() {
let _x = 5;
let y = 10;
}Ici, nous recevons un avertissement pour la non-utilisation de la variable y, mais nous n’en recevons pas pour la non-utilisation de _x.
Notez qu’il y à une différence subtile entre utiliser uniquement _ et utiliser un nom qui commence par un tiret bas. La syntaxe _x lie toujours la valeur à la variable, tandis que _ ne lie pas du tout. Pour montrer un cas où cette distinction est importante, l’encart 19-21 nous donnera une erreur.
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_s) = s {
println!("found a string");
}
println!("{s:?}");
}Nous recevrons une erreur car la valeur s sera toujours déplacée dans _s, ce qui nous empêche d’utiliser s à nouveau. Cependant, utiliser le tiret bas seul ne lie jamais la valeur. L’encart 19-22 compilera sans erreur car s n’est pas déplacé dans _.
fn main() {
let s = Some(String::from("Hello!"));
if let Some(_) = s {
println!("found a string");
}
println!("{s:?}");
}Ce code fonctionne parfaitement car nous ne lions jamais s à quoi que ce soit ; il n’est pas déplacé.
Les parties restantes d’une valeur avec ..
Avec des valeurs qui ont de nombreuses parties, nous pouvons utiliser la syntaxe .. pour utiliser des parties spécifiques et ignorer le reste, évitant ainsi de devoir lister des tirets bas pour chaque valeur ignorée. Le motif .. ignore toutes les parties d’une valeur que nous n’avons pas explicitement fait correspondre dans le reste du motif. Dans l’encart 19-23, nous avons une structure Point qui contient une coordonnée dans l’espace tridimensionnel. Dans l’expression match, nous voulons opérer uniquement sur la coordonnée x et ignorer les valeurs des champs y et z.
fn main() {
struct Point {
x: i32,
y: i32,
z: i32,
}
let origin = Point { x: 0, y: 0, z: 0 };
match origin {
Point { x, .. } => println!("x is {x}"),
}
}Point except for x by using ..Nous listons la valeur x puis incluons simplement le motif ... C’est plus rapide que de devoir lister y: _ et z: _, en particulier lorsque nous travaillons avec des structures ayant de nombreux champs dans des situations où seuls un où deux champs sont pertinents.
La syntaxe .. s’étendra à autant de valeurs que nécessaire. L’encart 19-24 montre comment utiliser .. avec un tuple.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(first, .., last) => {
println!("Some numbers: {first}, {last}");
}
}
}Dans ce code, la première et la dernière valeur sont mises en correspondance avec first et last. Le .. correspondra et ignorera tout ce qui se trouve au milieu.
Cependant, l’utilisation de .. doit être non ambiguë. S’il n’est pas clair quelles valeurs sont destinées à la correspondance et lesquelles doivent être ignorées, Rust nous donnera une erreur. L’encart 19-25 montre un exemple d’utilisation ambiguë de .., qui ne compilera donc pas.
fn main() {
let numbers = (2, 4, 8, 16, 32);
match numbers {
(.., second, ..) => {
println!("Some numbers: {second}")
},
}
}.. in an ambiguous wayLorsque nous compilons cet exemple, nous obtenons cette erreur : console {{#include ../listings/ch19-patterns-and-matching/listing-19-25/output.txt}}
$ cargo run
Compiling patterns v0.1.0 (file:///projects/patterns)
error: `..` can only be used once per tuple pattern
--> src/main.rs:5:22
|
5 | (.., second, ..) => {
| -- ^^ can only be used once per tuple pattern
| |
| previously used here
error: could not compile `patterns` (bin "patterns") due to 1 previous error
Il est impossible pour Rust de déterminer combien de valeurs du tuple ignorer avant de faire correspondre une valeur avec second et combien de valeurs supplémentaires ignorer ensuite. Ce code pourrait signifier que nous voulons ignorer 2, lier second à 4, puis ignorer 8, 16 et 32 ; ou que nous voulons ignorer 2 et 4, lier second à 8, puis ignorer 16 et 32 ; et ainsi de suite. Le nom de variable second n’à aucune signification particulière pour Rust, donc nous obtenons une erreur du compilateur car utiliser .. à deux endroits comme cela est ambigu.
Ajouter des conditions avec les gardes de correspondance
Une garde de correspondance (match guard) est une condition if supplémentaire, spécifiée après le motif dans une branche de match, qui doit également être satisfaite pour que cette branche soit choisie. Les gardes de correspondance sont utiles pour exprimer des idées plus complexes que ce qu’un motif seul permet. Notez, cependant, qu’elles ne sont disponibles que dans les expressions match, pas dans les expressions if let ou while let.
La condition peut utiliser des variables créées dans le motif. L’encart 19-26 montre un match où la première branche à le motif Some(x) et aussi une garde de correspondance if x % 2 == 0 (qui sera true si le nombre est pair).
fn main() {
let num = Some(4);
match num {
Some(x) if x % 2 == 0 => println!("The number {x} is even"),
Some(x) => println!("The number {x} is odd"),
None => (),
}
}Cet exemple affichera The number 4 is even. Lorsque num est comparé au motif de la première branche, il correspond car Some(4) correspond à Some(x). Ensuite, la garde de correspondance vérifie si le reste de la division de x par 2 est égal à 0, et comme c’est le cas, la première branche est sélectionnée.
Si num avait été Some(5), la garde de correspondance de la première branche aurait été false car le reste de 5 divisé par 2 est 1, ce qui n’est pas égal à 0. Rust passerait alors à la deuxième branche, qui correspondrait car la deuxième branche n’a pas de garde de correspondance et correspond donc à n’importe quelle variante Some.
Il n’y à aucun moyen d’exprimer la condition if x % 2 == 0 dans un motif, donc la garde de correspondance nous donne la possibilité d’exprimer cette logique. L’inconvénient de cette expressivité supplémentaire est que le compilateur n’essaie pas de vérifier l’exhaustivité lorsque des expressions de garde de correspondance sont impliquées.
Lorsque nous avons discuté de l’encart 19-11, nous avons mentionné que nous pouvions utiliser des gardes de correspondance pour résoudre notre problème de masquage de motif. Rappelez-vous que nous avions créé une nouvelle variable à l’intérieur du motif dans l’expression match au lieu d’utiliser la variable en dehors du match. Cette nouvelle variable signifiait que nous ne pouvions pas tester contre la valeur de la variable extérieure. L’encart 19-27 montre comment nous pouvons utiliser une garde de correspondance pour corriger ce problème.
fn main() {
let x = Some(5);
let y = 10;
match x {
Some(50) => println!("Got 50"),
Some(n) if n == y => println!("Matched, n = {n}"),
_ => println!("Default case, x = {x:?}"),
}
println!("at the end: x = {x:?}, y = {y}");
}Ce code affichera maintenant Default case, x = Some(5). Le motif de la deuxième branche n’introduit pas de nouvelle variable y qui masquerait le y extérieur, ce qui signifie que nous pouvons utiliser le y extérieur dans la garde de correspondance. Au lieu de spécifier le motif comme Some(y), ce qui aurait masqué le y extérieur, nous spécifions Some(n). Cela crée une nouvelle variable n qui ne masque rien car il n’y a pas de variable n en dehors du match.
La garde de correspondance if n == y n’est pas un motif et n’introduit donc pas de nouvelles variables. Ce y est le y extérieur plutôt qu’un nouveau y le masquant, et nous pouvons chercher une valeur ayant la même valeur que le y extérieur en comparant n à y.
Vous pouvez aussi utiliser l’opérateur ou | dans une garde de correspondance pour spécifier plusieurs motifs ; la condition de la garde de correspondance s’appliquera à tous les motifs. L’encart 19-28 montre la précédence lors de la combinaison d’un motif utilisant | avec une garde de correspondance. La partie importante de cet exemple est que la garde de correspondance if y s’applique à 4, 5 et 6, même s’il pourrait sembler que if y ne s’applique qu’à 6.
fn main() {
let x = 4;
let y = false;
match x {
4 | 5 | 6 if y => println!("yes"),
_ => println!("no"),
}
}La condition de correspondance stipule que la branche ne correspond que si la valeur de x est égale à 4, 5 ou 6 et si y est true. Lorsque ce code s’exécute, le motif de la première branche correspond car x vaut 4, mais la garde de correspondance if y est false, donc la première branche n’est pas choisie. Le code passe à la deuxième branche, qui correspond, et ce programme affiche no. La raison est que la condition if s’applique à l’ensemble du motif 4 | 5 | 6, pas seulement à la dernière valeur 6. En d’autres termes, la précédence d’une garde de correspondance par rapport à un motif se comporte comme ceci :
(4 | 5 | 6) if y => ...
plutôt que comme ceci :
4 | 5 | (6 if y) => ...
Après l’exécution du code, le comportement de précédence est évident : si la garde de correspondance n’était appliquée qu’à la dernière valeur de la liste de valeurs spécifiées avec l’opérateur |, la branche aurait correspondu, et le programme aurait affiché yes.
Utiliser les liaisons @
L’opérateur at @ nous permet de créer une variable qui contient une valeur en même temps que nous testons cette valeur pour une correspondance de motif. Dans l’encart 19-29, nous voulons tester que le champ id d’un Message::Hello se trouve dans l’intervalle 3..=7. Nous voulons aussi lier la valeur à la variable id afin de pouvoir l’utiliser dans le code associé à la branche.
fn main() {
enum Message {
Hello { id: i32 },
}
let msg = Message::Hello { id: 5 };
match msg {
Message::Hello { id: id @ 3..=7 } => {
println!("Found an id in range: {id}")
}
Message::Hello { id: 10..=12 } => {
println!("Found an id in another range")
}
Message::Hello { id } => println!("Found some other id: {id}"),
}
}@ to bind to a value in a pattern while also testing itCet exemple affichera Found an id in range: 5. En spécifiant id @ avant l’intervalle 3..=7, nous capturons la valeur qui correspond à l’intervalle dans une variable nommée id tout en testant que la valeur correspond au motif d’intervalle.
Dans la deuxième branche, où nous n’avons qu’un intervalle spécifié dans le motif, le code associé à la branche n’a pas de variable contenant la valeur réelle du champ id. La valeur du champ id aurait pu être 10, 11 ou 12, mais le code qui accompagne ce motif ne sait pas laquelle. Le code du motif ne peut pas utiliser la valeur du champ id car nous n’avons pas sauvegardé la valeur de id dans une variable.
Dans la dernière branche, où nous avons spécifié une variable sans intervalle, nous avons bien la valeur disponible pour utilisation dans le code de la branche dans une variable nommée id. La raison est que nous avons utilisé la syntaxe raccourcie des champs de structure. Mais nous n’avons appliqué aucun test à la valeur du champ id dans cette branche, comme nous l’avons fait avec les deux premières branches : n’importe quelle valeur correspondrait à ce motif.
Utiliser @ nous permet de tester une valeur et de la sauvegarder dans une variable au sein d’un seul motif.
Résumé
Les motifs de Rust sont très utiles pour distinguer les différents types de données. Lorsqu’ils sont utilisés dans des expressions match, Rust s’assuré que vos motifs couvrent toutes les valeurs possibles, sinon votre programme ne compilera pas. Les motifs dans les instructions let et les paramètres de fonction rendent ces constructions plus utiles, permettant la déstructuration des valeurs en parties plus petites et l’assignation de ces parties à des variables. Nous pouvons créer des motifs simples ou complexes pour répondre à nos besoins.
Ensuite, pour l’avant-dernier chapitre du livre, nous examinerons quelques aspects avancés de diverses fonctionnalités de Rust.
Les fonctionnalités avancées
À présent, vous avez appris les parties les plus couramment utilisées du langage de programmation Rust. Avant de réaliser un dernier projet au chapitre 21, nous allons examiner quelques aspects du langage que vous pourriez rencontrer de temps en temps mais que vous n’utiliserez peut-être pas tous les jours. Vous pouvez utiliser ce chapitre comme référence lorsque vous rencontrez des inconnues. Les fonctionnalités couvertes ici sont utiles dans des situations très spécifiques. Bien que vous ne les utilisiez peut-être pas souvent, nous voulons nous assurer que vous maîtrisez toutes les fonctionnalités que Rust a à offrir.
Dans ce chapitre, nous couvrirons :
- Le Rust unsafe : comment désactiver certaines garanties de Rust et prendre la responsabilité de les maintenir manuellement
- Les traits avancés : les types associés, les paramètres de type par défaut, la syntaxe pleinement qualifiée, les supertraits et le patron newtype en relation avec les traits
- Les types avancés : plus sur le patron newtype, les alias de types, le type never et les types à taille dynamique
- Les fonctions et fermetures avancées : les pointeurs de fonction et le retour de fermetures
- Les macros : des moyens de définir du code qui définit davantage de code au moment de la compilation
C’est tout un arsenal de fonctionnalités Rust avec quelque chose pour chacun ! Allons-y !
Le Rust unsafe
Le Rust unsafe
Tout le code que nous avons vu jusqu’à présent bénéficiait des garanties de sécurité mémoire de Rust appliquées au moment de la compilation. Cependant, Rust contient un second langage caché qui n’applique pas ces garanties de sécurité mémoire : il s’appelle Rust unsafe et fonctionne comme le Rust normal mais nous donne des super-pouvoirs supplémentaires.
Le Rust unsafe existe car, par nature, l’analyse statique est conservatrice. Lorsque le compilateur essaie de déterminer si le code respecte les garanties, il vaut mieux pour lui rejeter certains programmes valides que d’accepter des programmes invalides. Bien que le code puisse être correct, si le compilateur Rust n’a pas assez d’informations pour en être certain, il rejettera le code. Dans ces cas, vous pouvez utiliser du code unsafe pour dire au compilateur : “Fais-moi confiance, je sais ce que je fais.” Soyez cependant averti que vous utilisez le Rust unsafe à vos propres risques : si vous utilisez du code unsafe incorrectement, des problèmes liés à l’insécurité mémoire peuvent survenir, comme le déréférencement de pointeur nul.
Une autre raison pour laquelle Rust à un alter ego unsafe est que le matériel informatique sous-jacent est intrinsèquement non sécurisé. Si Rust ne vous permettait pas de faire des opérations unsafe, vous ne pourriez pas accomplir certaines tâches. Rust doit vous permettre de faire de la programmation système bas niveau, comme interagir directement avec le système d’exploitation ou même écrire votre propre système d’exploitation. Travailler avec la programmation système bas niveau est l’un des objectifs du langage. Explorons ce que nous pouvons faire avec le Rust unsafe et comment le faire.
Utiliser les super-pouvoirs unsafe
Pour passer en Rust unsafe, utilisez le mot-clé unsafe puis ouvrez un nouveau bloc contenant le code unsafe. Vous pouvez effectuer cinq actions en Rust unsafe que vous ne pouvez pas faire en Rust safe, que nous appelons les super-pouvoirs unsafe. Ces super-pouvoirs incluent la capacité de :
- Déréférencer un pointeur brut.
- Appeler une fonction ou méthode unsafe.
- Accéder ou modifier une variable statique mutable.
- Implémenter un trait unsafe.
- Accéder aux champs de
unions.
Il est important de comprendre que unsafe ne désactive pas le vérificateur d’emprunt ni aucune des autres vérifications de sécurité de Rust : si vous utilisez une référence dans du code unsafe, elle sera toujours vérifiée. Le mot-clé unsafe ne vous donne accès qu’à ces cinq fonctionnalités qui ne sont alors pas vérifiées par le compilateur pour la sécurité mémoire. Vous bénéficierez toujours d’un certain degré de sécurité à l’intérieur d’un bloc unsafe.
De plus, unsafe ne signifie pas que le code à l’intérieur du bloc est nécessairement dangereux ou qu’il aura forcément des problèmes de sécurité mémoire : l’intention est que vous, en tant que programmeur, vous assurerez que le code à l’intérieur d’un bloc unsafe accédera à la mémoire de manière valide.
Les gens sont faillibles et les erreurs arrivent, mais en exigeant que ces cinq opérations unsafe soient dans des blocs annotés avec unsafe, vous saurez que toute erreur liée à la sécurité mémoire doit se trouver dans un bloc unsafe. Gardez les blocs unsafe petits ; vous vous en féliciterez plus tard lorsque vous chercherez des bogues mémoire.
Pour isoler le code unsafe autant que possible, il est préférable d’encapsuler ce code dans une abstraction sûre et de fournir une API sûre, ce dont nous discuterons plus loin dans le chapitre lorsque nous examinerons les fonctions et méthodes unsafe. Des parties de la bibliothèque standard sont implémentées comme des abstractions sûres par-dessus du code unsafe qui a été audité. Encapsuler du code unsafe dans une abstraction sûre empêche les utilisations d’unsafe de fuiter dans tous les endroits où vous ou vos utilisateurs pourriez vouloir utiliser la fonctionnalité implémentée avec du code unsafe, car utiliser une abstraction sûre est sûr.
Examinons chacun des cinq super-pouvoirs unsafe à tour de rôle. Nous verrons aussi quelques abstractions qui fournissent une interface sûre au code unsafe.
Déréférencer un pointeur brut
Au chapitre 4, dans la section « Les références pendantes », nous avons mentionné que le compilateur s’assuré que les références sont toujours valides. Le Rust unsafe possède deux nouveaux types appelés pointeurs bruts qui sont similaires aux références. Comme les références, les pointeurs bruts peuvent être immuables ou mutables et s’écrivent respectivement *const T et *mut T. L’astérisque n’est pas l’opérateur de déréférencement ; il fait partie du nom du type. Dans le contexte des pointeurs bruts, immuable signifie que le pointeur ne peut pas être directement assigné après avoir été déréférencé.
Contrairement aux références et aux pointeurs intelligents, les pointeurs bruts :
- Peuvent ignorer les règles d’emprunt en ayant à la fois des pointeurs immuables et mutables ou plusieurs pointeurs mutables vers le même emplacement
- Ne sont pas garantis de pointer vers de la mémoire valide
- Sont autorisés à être nuls
- N’implémentent aucun nettoyage automatique
En renonçant à ce que Rust applique ces garanties, vous pouvez abandonner la sécurité garantie en échange de meilleures performances ou de la capacité d’interfacer avec un autre langage ou du matériel où les garanties de Rust ne s’appliquent pas.
L’encart 20-1 montre comment créer un pointeur brut immuable et un pointeur brut mutable.
fn main() {
let mut num = 5;
let r1 = &raw const num;
let r2 = &raw mut num;
}Remarquez que nous n’incluons pas le mot-clé unsafe dans ce code. Nous pouvons créer des pointeurs bruts dans du code safe ; nous ne pouvons simplement pas déréférencer des pointeurs bruts en dehors d’un bloc unsafe, comme vous le verrez bientôt.
Nous avons créé des pointeurs bruts en utilisant les opérateurs d’emprunt brut : &raw const num crée un pointeur brut immuable *const i32, et &raw mut num crée un pointeur brut mutable *mut i32. Comme nous les avons créés directement à partir d’une variable locale, nous savons que ces pointeurs bruts particuliers sont valides, mais nous ne pouvons pas faire cette hypothèse pour n’importe quel pointeur brut.
Pour illustrer cela, nous allons ensuite créer un pointeur brut dont nous ne pouvons pas être aussi certains de la validité, en utilisant le mot-clé as pour convertir une valeur au lieu d’utiliser l’opérateur d’emprunt brut. L’encart 20-2 montre comment créer un pointeur brut vers un emplacement arbitraire en mémoire. Essayer d’utiliser de la mémoire arbitraire est un comportement indéfini : il peut y avoir des données à cette adresse ou non, le compilateur peut optimiser le code de sorte qu’il n’y ait pas d’accès mémoire, ou le programme peut se terminer par une erreur de segmentation. En général, il n’y a pas de bonne raison d’écrire du code comme celui-ci, surtout dans les cas où vous pouvez utiliser un opérateur d’emprunt brut à la place, mais c’est possible.
fn main() {
let address = 0x012345usize;
let r = address as *const i32;
}Rappelez-vous que nous pouvons créer des pointeurs bruts dans du code safe, mais nous ne pouvons pas déréférencer des pointeurs bruts et lire les données pointées. Dans l’encart 20-3, nous utilisons l’opérateur de déréférencement * sur un pointeur brut, ce qui nécessite un bloc unsafe.
fn main() {
let mut num = 5;
let r1 = &raw const num;
let r2 = &raw mut num;
unsafe {
println!("r1 is: {}", *r1);
println!("r2 is: {}", *r2);
}
}unsafe blockCréer un pointeur ne fait aucun mal ; c’est seulement lorsque nous essayons d’accéder à la valeur vers laquelle il pointe que nous risquons de traiter une valeur invalide.
Notez aussi que dans les encarts 20-1 et 20-3, nous avons créé des pointeurs bruts *const i32 et *mut i32 qui pointaient tous les deux vers le même emplacement mémoire, où num est stocké. Si nous avions essayé de créer une référence immuable et une référence mutable vers num, le code n’aurait pas compilé car les règles de possession de Rust n’autorisent pas une référence mutable en même temps que des références immuables. Avec les pointeurs bruts, nous pouvons créer un pointeur mutable et un pointeur immuable vers le même emplacement et modifier les données via le pointeur mutable, créant potentiellement une situation de compétition de données. Soyez prudent !
Avec tous ces dangers, pourquoi utiliseriez-vous des pointeurs bruts ? Un cas d’utilisation majeur est l’interfaçage avec du code C, comme vous le verrez dans la section suivante. Un autre cas est la construction d’abstractions sûres que le vérificateur d’emprunt ne comprend pas. Nous allons présenter les fonctions unsafe puis examiner un exemple d’abstraction sûre utilisant du code unsafe.
Appeler une fonction ou méthode unsafe
Le deuxième type d’opération que vous pouvez effectuer dans un bloc unsafe est l’appel de fonctions unsafe. Les fonctions et méthodes unsafe ressemblent exactement aux fonctions et méthodes normales, mais elles ont un unsafe supplémentaire avant le reste de la définition. Le mot-clé unsafe dans ce contexte indique que la fonction à des exigences que nous devons respecter lorsque nous l’appelons, car Rust ne peut pas garantir que nous les avons satisfaites. En appelant une fonction unsafe dans un bloc unsafe, nous disons que nous avons lu la documentation de cette fonction et que nous prenons la responsabilité de respecter les contrats de la fonction.
Voici une fonction unsafe nommée dangerous qui ne fait rien dans son corps : rust {{#rustdoc_include ../listings/ch20-advanced-features/no-listing-01-unsafe-fn/src/main.rs:here}}
fn main() {
unsafe fn dangerous() {}
unsafe {
dangerous();
}
}Nous devons appeler la fonction dangerous dans un bloc unsafe séparé. Si nous essayons d’appeler dangerous sans le bloc unsafe, nous obtiendrons une erreur : console {{#include ../listings/ch20-advanced-features/output-only-01-missing-unsafe/output.txt}}
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0133]: call to unsafe function `dangerous` is unsafe and requires unsafe block
--> src/main.rs:4:5
|
4 | dangerous();
| ^^^^^^^^^^^ call to unsafe function
|
= note: consult the function's documentation for information on how to avoid undefined behavior
For more information about this error, try `rustc --explain E0133`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
Avec le bloc unsafe, nous affirmons à Rust que nous avons lu la documentation de la fonction, que nous comprenons comment l’utiliser correctement, et que nous avons vérifié que nous respectons le contrat de la fonction.
Pour effectuer des opérations unsafe dans le corps d’une fonction unsafe, vous devez toujours utiliser un bloc unsafe, comme dans une fonction normale, et le compilateur vous avertira si vous oubliez. Cela nous aide à garder les blocs unsafe aussi petits que possible, car les opérations unsafe peuvent ne pas être nécessaires dans tout le corps de la fonction.
Créer une abstraction sûre par-dessus du code unsafe
Ce n’est pas parce qu’une fonction contient du code unsafe que nous devons marquer toute la fonction comme unsafe. En fait, encapsuler du code unsafe dans une fonction sûre est une abstraction courante. À titre d’exemple, étudions la fonction split_at_mut de la bibliothèque standard, qui nécessite du code unsafe. Nous allons explorer comment nous pourrions l’implémenter. Cette méthode sûre est définie sur les slices mutables : elle prend une slice et la divise en deux en la scindant à l’indice donné en argument. L’encart 20-4 montre comment utiliser split_at_mut.
fn main() {
let mut v = vec![1, 2, 3, 4, 5, 6];
let r = &mut v[..];
let (a, b) = r.split_at_mut(3);
assert_eq!(a, &mut [1, 2, 3]);
assert_eq!(b, &mut [4, 5, 6]);
}split_at_mut functionNous ne pouvons pas implémenter cette fonction en utilisant uniquement du Rust safe. Une tentative pourrait ressembler à l’encart 20-5, qui ne compilera pas. Par souci de simplicité, nous allons implémenter split_at_mut comme une fonction plutôt qu’une méthode et uniquement pour des slices de valeurs i32 plutôt que pour un type générique T.
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
assert!(mid <= len);
(&mut values[..mid], &mut values[mid..])
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}split_at_mut using only safe RustCette fonction obtient d’abord la longueur totale de la slice. Ensuite, elle vérifie par une assertion que l’indice donné en paramètre se trouve dans la slice en vérifiant s’il est inférieur ou égal à la longueur. L’assertion signifie que si nous passons un indice supérieur à la longueur pour scinder la slice, la fonction paniquera avant de tenter d’utiliser cet indice.
Ensuite, nous retournons deux slices mutables dans un tuple : une du début de la slice originale jusqu’à l’indice mid et une autre de mid jusqu’à la fin de la slice.
Lorsque nous essayons de compiler le code de l’encart 20-5, nous obtenons une erreur : console {{#include ../listings/ch20-advanced-features/listing-20-05/output.txt}}
$ cargo run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
error[E0499]: cannot borrow `*values` as mutable more than once at a time
--> src/main.rs:6:31
|
1 | fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
| - let's call the lifetime of this reference `'1`
...
6 | (&mut values[..mid], &mut values[mid..])
| --------------------------^^^^^^--------
| | | |
| | | second mutable borrow occurs here
| | first mutable borrow occurs here
| returning this value requires that `*values` is borrowed for `'1`
|
= help: use `.split_at_mut(position)` to obtain two mutable non-overlapping sub-slices
For more information about this error, try `rustc --explain E0499`.
error: could not compile `unsafe-example` (bin "unsafe-example") due to 1 previous error
Le vérificateur d’emprunt de Rust ne peut pas comprendre que nous empruntons des parties différentes de la slice ; il sait seulement que nous empruntons la même slice deux fois. Emprunter des parties différentes d’une slice est fondamentalement correct car les deux slices ne se chevauchent pas, mais Rust n’est pas assez intelligent pour le savoir. Quand nous savons que le code est correct, mais que Rust ne le sait pas, il est temps de recourir au code unsafe.
L’encart 20-6 montre comment utiliser un bloc unsafe, un pointeur brut et quelques appels à des fonctions unsafe pour faire fonctionner l’implémentation de split_at_mut.
use std::slice;
fn split_at_mut(values: &mut [i32], mid: usize) -> (&mut [i32], &mut [i32]) {
let len = values.len();
let ptr = values.as_mut_ptr();
assert!(mid <= len);
unsafe {
(
slice::from_raw_parts_mut(ptr, mid),
slice::from_raw_parts_mut(ptr.add(mid), len - mid),
)
}
}
fn main() {
let mut vector = vec![1, 2, 3, 4, 5, 6];
let (left, right) = split_at_mut(&mut vector, 3);
}split_at_mut functionRappelez-vous dans la section « Le type slice » du chapitre 4 que le compilateur garantit qu’une slice est toujours une référence valide vers un tableau. Lorsque nous utilisons des pointeurs bruts, nous n’avons pas cette garantie.
Nous conservons l’assertion que l’indice mid se trouve dans la slice. Ensuite, nous passons au code unsafe : la fonction slice::from_raw_parts_mut prend un pointeur brut et une longueur, et crée une slice. Nous utilisons cette fonction pour créer une slice qui commence à ptr et fait mid éléments de long. Ensuite, nous appelons la méthode add sur ptr avec mid en argument pour obtenir un pointeur brut commençant à mid, et nous créons une slice utilisant ce pointeur et le nombre restant d’éléments après mid comme longueur.
La fonction slice::from_raw_parts_mut est unsafe car elle prend un pointeur brut et doit faire confiance au fait que ce pointeur est valide. La méthode add sur les pointeurs bruts est aussi unsafe car elle doit faire confiance au fait que l’emplacement décalé est aussi un pointeur valide. C’est pourquoi nous avons dû placer un bloc unsafe autour de nos appels à slice::from_raw_parts_mut et add pour pouvoir les appeler. En examinant le code et en ajoutant l’assertion que mid doit être inférieur ou égal à len, nous pouvons affirmer que tous les pointeurs bruts utilisés dans le bloc unsafe seront des pointeurs valides vers des données dans la slice. C’est une utilisation acceptable et appropriée d’unsafe.
Notez que nous n’avons pas besoin de marquer la fonction résultante split_at_mut comme unsafe, et nous pouvons appeler cette fonction depuis du Rust safe. Nous avons créé une abstraction sûre pour le code unsafe avec une implémentation de la fonction qui utilise du code unsafe de manière sûre, car elle ne crée que des pointeurs valides à partir des données auxquelles cette fonction a accès.
En revanche, l’utilisation de slice::from_raw_parts_mut dans l’encart 20-7 provoquerait probablement un plantage lorsque la slice est utilisée. Ce code prend un emplacement mémoire arbitraire et crée une slice de 10 000 éléments.
fn main() {
use std::slice;
let address = 0x01234usize;
let r = address as *mut i32;
let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) };
}Nous ne possédons pas la mémoire à cet emplacement arbitraire, et il n’y à aucune garantie que la slice créée par ce code contienne des valeurs i32 valides. Tenter d’utiliser values comme s’il s’agissait d’une slice valide entraîne un comportement indéfini.
Utiliser les fonctions extern pour appeler du code externe
Parfois, votre code Rust peut avoir besoin d’interagir avec du code écrit dans un autre langage. Pour cela, Rust possède le mot-clé extern qui facilite la création et l’utilisation d’une interface de fonctions étrangères (FFI), qui est un moyen pour un langage de programmation de définir des fonctions et de permettre à un autre langage de programmation (étranger) d’appeler ces fonctions.
L’encart 20-8 montre comment mettre en place une intégration avec la fonction abs de la bibliothèque standard C. Les fonctions déclarées dans les blocs extern sont généralement unsafe à appeler depuis du code Rust, donc les blocs extern doivent aussi être marqués unsafe. La raison est que les autres langages n’appliquent pas les règles et garanties de Rust, et Rust ne peut pas les vérifier, donc la responsabilité incombe au programmeur d’assurer la sécurité.
unsafe extern "C" {
fn abs(input: i32) -> i32;
}
fn main() {
unsafe {
println!("Absolute value of -3 according to C: {}", abs(-3));
}
}extern function defined in another languageDans le bloc unsafe extern "C", nous listons les noms et signatures des fonctions externes d’un autre langage que nous voulons appeler. La partie "C" définit quelle interface binaire d’application (ABI) la fonction externe utilise : l’ABI définit comment appeler la fonction au niveau de l’assembleur. L’ABI "C" est la plus courante et suit l’ABI du langage de programmation C. Des informations sur toutes les ABI prises en charge par Rust sont disponibles dans [la Référence Rust][ABI].
Chaque élément déclaré dans un bloc unsafe extern est implicitement unsafe. Cependant, certaines fonctions FFI sont sûres à appeler. Par exemple, la fonction abs de la bibliothèque standard C n’à aucune considération de sécurité mémoire, et nous savons qu’elle peut être appelée avec n’importe quel i32. Dans de tels cas, nous pouvons utiliser le mot-clé safe pour indiquer que cette fonction spécifique est sûre à appeler même si elle se trouve dans un bloc unsafe extern. Une fois ce changement effectué, l’appeler ne nécessite plus de bloc unsafe, comme montré dans l’encart 20-9.
unsafe extern "C" {
safe fn abs(input: i32) -> i32;
}
fn main() {
println!("Absolute value of -3 according to C: {}", abs(-3));
}safe within an unsafe extern block and calling it safelyMarquer une fonction comme safe ne la rend pas intrinsèquement sûre ! C’est plutôt une promesse que vous faites à Rust qu’elle est sûre. Il reste de votre responsabilité de vous assurer que cette promesse est tenue !
Appeler des fonctions Rust depuis d’autres langages
Nous pouvons aussi utiliser extern pour créer une interface permettant à d’autres langages d’appeler des fonctions Rust. Au lieu de créer un bloc extern complet, nous ajoutons le mot-clé extern et spécifions l’ABI à utiliser juste avant le mot-clé fn de la fonction concernée. Nous devons aussi ajouter une annotation #[unsafe(no_mangle)] pour dire au compilateur Rust de ne pas modifier le nom de cette fonction. Le name mangling est le processus par lequel un compilateur change le nom que nous avons donné à une fonction en un nom différent contenant plus d’informations pour d’autres parties du processus de compilation, mais moins lisible par l’humain. Chaque compilateur de langage de programmation modifié les noms légèrement différemment, donc pour qu’une fonction Rust soit nommable par d’autres langages, nous devons désactiver le name mangling du compilateur Rust. C’est unsafe car il pourrait y avoir des collisions de noms entre bibliothèques sans le mangling intégré, donc c’est notre responsabilité de s’assurer que le nom choisi peut être exporté sans mangling en toute sécurité.
Dans l’exemple suivant, nous rendons la fonction call_from_c accessible depuis du code C, après compilation en bibliothèque partagée et liaison depuis C :
#[unsafe(no_mangle)]
pub extern "C" fn call_from_c() {
println!("Just called a Rust function from C!");
}
Cette utilisation d’extern ne nécessite unsafe que dans l’attribut, pas sur le bloc extern.
Accéder ou modifier une variable statique mutable
Dans ce livre, nous n’avons pas encore parlé des variables globales, que Rust prend en charge mais qui peuvent être problématiques avec les règles de possession de Rust. Si deux threads accèdent à la même variable globale mutable, cela peut provoquer une situation de compétition de données.
En Rust, les variables globales sont appelées variables statiques. L’encart 20-10 montre un exemple de déclaration et d’utilisation d’une variable statique avec une slice de chaîne de caractères comme valeur.
static HELLO_WORLD: &str = "Hello, world!";
fn main() {
println!("value is: {HELLO_WORLD}");
}Les variables statiques sont similaires aux constantes, que nous avons abordées dans la section « Déclarer des constantes » du chapitre 3. Les noms des variables statiques sont en SCREAMING_SNAKE_CASE par convention. Les variables statiques ne peuvent stocker que des références avec la durée de vie 'static, ce qui signifie que le compilateur Rust peut déterminer la durée de vie et que nous n’avons pas besoin de l’annoter explicitement. Accéder à une variable statique immuable est sûr.
Une différence subtile entre les constantes et les variables statiques immuables est que les valeurs dans une variable statique ont une adresse fixe en mémoire. Utiliser la valeur accédera toujours aux mêmes données. Les constantes, en revanche, sont autorisées à dupliquer leurs données chaque fois qu’elles sont utilisées. Une autre différence est que les variables statiques peuvent être mutables. Accéder et modifier des variables statiques mutables est unsafe. L’encart 20-11 montre comment déclarer, accéder et modifier une variable statique mutable nommée COUNTER.
static mut COUNTER: u32 = 0;
/// SAFETY: Calling this from more than a single thread at a time is undefined
/// behavior, so you *must* guarantee you only call it from a single thread at
/// a time.
unsafe fn add_to_count(inc: u32) {
unsafe {
COUNTER += inc;
}
}
fn main() {
unsafe {
// SAFETY: This is only called from a single thread in `main`.
add_to_count(3);
println!("COUNTER: {}", *(&raw const COUNTER));
}
}Comme pour les variables normales, nous spécifions la mutabilité avec le mot-clé mut. Tout code qui lit ou écrit depuis COUNTER doit se trouver dans un bloc unsafe. Le code de l’encart 20-11 compilé et affiche COUNTER: 3 comme nous l’attendrions car il est mono-thread. Avoir plusieurs threads accédant à COUNTER entraînerait probablement des situations de compétition de données, ce qui est un comportement indéfini. Par conséquent, nous devons marquer la fonction entière comme unsafe et documenter la limitation de sécurité afin que quiconque appelle la fonction sache ce qu’il est autorisé ou non à faire de manière sûre.
Chaque fois que nous écrivons une fonction unsafe, il est idiomatique d’écrire un commentaire commençant par SAFETY et expliquant ce que l’appelant doit faire pour appeler la fonction de manière sûre. De même, chaque fois que nous effectuons une opération unsafe, il est idiomatique d’écrire un commentaire commençant par SAFETY pour expliquer comment les règles de sécurité sont respectées.
De plus, le compilateur refusera par défaut toute tentative de créer des références vers une variable statique mutable via un lint du compilateur. Vous devez soit explicitement désactiver les protections de ce lint en ajoutant une annotation #[allow(static_mut_refs)], soit accéder à la variable statique mutable via un pointeur brut créé avec l’un des opérateurs d’emprunt brut. Cela inclut les cas où la référence est créée de manière invisible, comme lorsqu’elle est utilisée dans le println! de cet encart de code. Exiger que les références aux variables statiques mutables soient créées via des pointeurs bruts aide à rendre les exigences de sécurité pour leur utilisation plus évidentes.
Avec des données mutables accessibles globalement, il est difficile de s’assurer qu’il n’y a pas de situations de compétition de données, c’est pourquoi Rust considère les variables statiques mutables comme unsafe. Dans la mesure du possible, il est préférable d’utiliser les techniques de concurrence et les pointeurs intelligents thread-safe que nous avons vus au chapitre 16 afin que le compilateur vérifie que l’accès aux données depuis différents threads se fait de manière sûre.
Implémenter un trait unsafe
Nous pouvons utiliser unsafe pour implémenter un trait unsafe. Un trait est unsafe lorsqu’au moins une de ses méthodes possède un invariant que le compilateur ne peut pas vérifier. Nous déclarons qu’un trait est unsafe en ajoutant le mot-clé unsafe avant trait et en marquant l’implémentation du trait comme unsafe également, comme montré dans l’encart 20-12.
unsafe trait Foo {
// methods go here
}
unsafe impl Foo for i32 {
// method implémentations go here
}
fn main() {}En utilisant unsafe impl, nous promettons de respecter les invariants que le compilateur ne peut pas vérifier.
section in Chapter 16: The compiler implements these traits automatically if our types are composed entirely of other types that implement Send and Sync. If we implement a type that contains a type that does not implement Send or Sync, such as raw pointers, and we want to mark that type as Send or Sync, we must use unsafe. Rust can’t verify that our type upholds the guarantees that it can be safely sent across threads or accessed from multiple threads; therefore, we need to do those checks manually and indicate as such with unsafe. –> À titre d’exemple, rappelez-vous les traits marqueurs Send et Sync que nous avons vus dans la section [“La concurrence extensible avec Send et Sync”][send-and-sync] du chapitre 16 : le compilateur implémente ces traits automatiquement si nos types sont entièrement composés d’autres types qui implémentent Send et Sync. Si nous implémentons un type contenant un type qui n’implémente pas Send ou Sync, comme les pointeurs bruts, et que nous voulons marquer ce type comme Send ou Sync, nous devons utiliser unsafe. Rust ne peut pas vérifier que notre type respecte les garanties qu’il peut être envoyé entre les threads de manière sûre ou accédé depuis plusieurs threads ; par conséquent, nous devons effectuer ces vérifications manuellement et l’indiquer avec unsafe.
Accéder aux champs d’une union
L’action finale qui ne fonctionne qu’avec unsafe est d’accéder aux champs d’une union. Une union est similaire à une struct, mais une seule instance de champ déclarée est utilisée dans une instance particulière à la fois. Les unions servent principalement à s’interfacer avec les unions en code C. Accéder aux champs d’une union est unsafe car Rust ne peut pas garantir le type des données actuellement stockées dans l’instance de l’union. Vous pouvez en apprendre davantage sur les unions dans la référence Rust.
Utiliser Miri pour vérifier le code unsafe
Lorsque vous écrivez du code unsafe, vous voudrez peut-être vérifier que ce que vous avez écrit est réellement sûr et correct. L’un des meilleurs moyens de le faire est d’utiliser Miri, un outil officiel de Rust pour détecter les comportements indéfinis. Alors que le vérificateur d’emprunt est un outil statique qui fonctionne au moment de la compilation, Miri est un outil dynamique qui fonctionne à l’exécution. Il vérifie votre code en exécutant votre programme, ou sa suite de tests, et en détectant quand vous violez les règles qu’il comprend sur le fonctionnement de Rust.
L’utilisation de Miri nécessite une version nightly de Rust (dont nous parlons davantage dans [l’Annexe G : Comment Rust est fait et “Nightly Rust”][nightly]). Vous pouvez installer à la fois une version nightly de Rust et l’outil Miri en tapant rustup +nightly component add miri. Cela ne change pas la version de Rust utilisée par votre projet ; cela ajouté seulement l’outil à votre système pour que vous puissiez l’utiliser quand vous le souhaitez. Vous pouvez exécuter Miri sur un projet en tapant cargo +nightly miri run ou cargo +nightly miri test.
Pour un exemple de l’utilité de cet outil, voyons ce qui se passe lorsque nous l’exécutons sur l’encart 20-7. console {{#include ../listings/ch20-advanced-features/listing-20-07/output.txt}}
$ cargo +nightly miri run
Compiling unsafe-example v0.1.0 (file:///projects/unsafe-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.01s
Running `file:///home/.rustup/toolchains/nightly/bin/cargo-miri runner target/miri/debug/unsafe-example`
warning: integer-to-pointer cast
--> src/main.rs:5:13
|
5 | let r = address as *mut i32;
| ^^^^^^^^^^^^^^^^^^^ integer-to-pointer cast
|
= help: this program is using integer-to-pointer casts or (equivalently) `ptr::with_exposed_provenance`, which means that Miri might miss pointer bugs in this program
= help: see https://doc.rust-lang.org/nightly/std/ptr/fn.with_exposed_provenance.html for more details on that operation
= help: to ensure that Miri does not miss bugs in your program, use Strict Provenance APIs (https://doc.rust-lang.org/nightly/std/ptr/index.html#strict-provenance, https://crates.io/crates/sptr) instead
= help: you can then set `MIRIFLAGS=-Zmiri-strict-provenance` to ensure you are not relying on `with_exposed_provenance` semantics
= help: alternatively, `MIRIFLAGS=-Zmiri-permissive-provenance` disables this warning
= note: BACKTRACE:
= note: inside `main` at src/main.rs:5:13: 5:32
error: Undefined Behavior: pointer not dereferenceable: pointer must be dereferenceable for 40000 bytes, but got 0x1234[noalloc] which is a dangling pointer (it has no provenance)
--> src/main.rs:7:35
|
7 | let values: &[i32] = unsafe { slice::from_raw_parts_mut(r, 10000) };
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ Undefined Behavior occurred here
|
= help: this indicates a bug in the program: it performed an invalid operation, and caused Undefined Behavior
= help: see https://doc.rust-lang.org/nightly/reference/behavior-considered-undefined.html for further information
= note: BACKTRACE:
= note: inside `main` at src/main.rs:7:35: 7:70
note: some details are omitted, run with `MIRIFLAGS=-Zmiri-backtrace=full` for a verbose backtrace
error: aborting due to 1 previous error; 1 warning emitted
Miri nous avertit correctement que nous convertissons un entier en pointeur, ce qui pourrait être un problème, mais Miri ne peut pas déterminer si un problème existe car il ne sait pas d’où provient le pointeur. Ensuite, Miri renvoie une erreur là où l’encart 20-7 à un comportement indéfini car nous avons un pointeur pendant. Grâce à Miri, nous savons maintenant qu’il y à un risque de comportement indéfini, et nous pouvons réfléchir à comment rendre le code sûr. Dans certains cas, Miri peut même faire des recommandations sur la façon de corriger les erreurs.
Miri n’attrape pas tout ce que vous pourriez mal faire en écrivant du code unsafe. Miri est un outil d’analyse dynamique, donc il ne détecte que les problèmes avec du code qui est réellement exécuté. Cela signifie que vous devrez l’utiliser en conjonction avec de bonnes techniques de test pour augmenter votre confiance dans le code unsafe que vous avez écrit. Miri ne couvre pas non plus toutes les manières possibles dont votre code peut être incorrect.
Autrement dit : si Miri détecte un problème, vous savez qu’il y à un bogue, mais ce n’est pas parce que Miri ne détecte pas un bogue qu’il n’y a pas de problème. Il peut cependant en attraper beaucoup. Essayez de l’exécuter sur les autres exemples de code unsafe de ce chapitre et voyez ce qu’il dit !
Vous pouvez en apprendre plus sur Miri dans [son dépôt GitHub][miri].
Utiliser le code unsafe correctement
Utiliser unsafe pour utiliser l’un des cinq super-pouvoirs que nous venons de voir n’est ni incorrect ni mal vu, mais il est plus délicat d’obtenir un code unsafe correct car le compilateur ne peut pas aider à maintenir la sécurité mémoire. Lorsque vous avez une raison d’utiliser du code unsafe, vous pouvez le faire, et avoir l’annotation explicite unsafe facilite la recherche de la source des problèmes lorsqu’ils surviennent. Chaque fois que vous écrivez du code unsafe, vous pouvez utiliser Miri pour vous aider à être plus confiant que le code que vous avez écrit respecte les règles de Rust.
Pour une exploration beaucoup plus approfondie de la manière de travailler efficacement avec le Rust unsafe, lisez le guide officiel de Rust pour unsafe, [le Rustonomicon][nomicon].
Les traits avancés
Les traits avancés
Nous avons d’abord couvert les traits dans la section « Définir un comportement partagé avec les traits » du chapitre 10, mais nous n’avons pas discuté des détails plus avancés. Maintenant que vous en savez plus sur Rust, nous pouvons entrer dans le vif du sujet.
Définir des traits avec des types associés
Les types associés connectent un type générique de substitution avec un trait de sorte que les définitions des méthodes du trait puissent utiliser ces types de substitution dans leurs signatures. L’implémenteur d’un trait spécifiera le type concret à utiliser à la place du type de substitution pour l’implémentation particulière. De cette manière, nous pouvons définir un trait qui utilise certains types sans avoir besoin de savoir exactement quels sont ces types jusqu’à ce que le trait soit implémenté.
Nous avons décrit la plupart des fonctionnalités avancées de ce chapitre comme étant rarement nécessaires. Les types associés se situent quelque part au milieu : ils sont utilisés plus rarement que les fonctionnalités expliquées dans le reste du livre mais plus couramment que beaucoup d’autres fonctionnalités discutées dans ce chapitre.
Un exemple de trait avec un type associé est le trait Iterator fourni par la bibliothèque standard. Le type associé est nommé Item et représente le type des valeurs sur lesquelles le type implémentant le trait Iterator itère. La définition du trait Iterator est celle montrée dans l’encart 20-13.
pub trait Iterator {
type Item;
fn next(&mut self) -> Option<Self::Item>;
}Iterator trait that has an associated type ItemLe type Item est un type de substitution, et la définition de la méthode next montre qu’elle retournera des valeurs de type Option<Self::Item>. Les implémenteurs du trait Iterator spécifieront le type concret pour Item, et la méthode next retournera une Option contenant une valeur de ce type concret.
Les types associés pourraient sembler être un concept similaire aux génériques, dans la mesure où ces derniers nous permettent de définir une fonction sans spécifier quels types elle peut traiter. Pour examiner la différence entre les deux concepts, nous allons regarder une implémentation du trait Iterator sur un type nommé Counter qui spécifie que le type Item est u32 :
struct Counter {
count: u32,
}
impl Counter {
fn new() -> Counter {
Counter { count: 0 }
}
}
impl Iterator for Counter {
type Item = u32;
fn next(&mut self) -> Option<Self::Item> {
// --snip--
if self.count < 5 {
self.count += 1;
Some(self.count)
} else {
None
}
}
}Cette syntaxe semble comparable à celle des génériques. Alors, pourquoi ne pas simplement définir le trait Iterator avec des génériques, comme montré dans l’encart 20-14 ?
pub trait Iterator<T> {
fn next(&mut self) -> Option<T>;
}Iterator trait using genericsLa différence est que lorsque nous utilisons des génériques, comme dans l’encart 20-14, nous devons annoter les types dans chaque implémentation ; parce que nous pourrions aussi implémenter Iterator<String> for Counter ou n’importe quel autre type, nous pourrions avoir plusieurs implémentations d’Iterator pour Counter. En d’autres termes, lorsqu’un trait à un paramètre générique, il peut être implémenté pour un type plusieurs fois, en changeant les types concrets des paramètres de type générique à chaque fois. Lorsque nous utilisons la méthode next sur Counter, nous devrions fournir des annotations de type pour indiquer quelle implémentation d’Iterator nous voulons utiliser.
Avec les types associés, nous n’avons pas besoin d’annoter les types, car nous ne pouvons pas implémenter un trait sur un type plusieurs fois. Dans l’encart 20-13 avec la définition qui utilise des types associés, nous ne pouvons choisir le type d’Item qu’une seule fois car il ne peut y avoir qu’un seul impl Iterator for Counter. Nous n’avons pas à spécifier que nous voulons un itérateur de valeurs u32 partout où nous appelons next sur Counter.
Les types associés font aussi partie du contrat du trait : les implémenteurs du trait doivent fournir un type pour remplacer le type de substitution associé. Les types associés ont souvent un nom qui décrit comment le type sera utilisé, et documenter le type associé dans la documentation de l’API est une bonne pratique.
Utiliser les paramètres de type générique par défaut et la surcharge d’opérateurs
Lorsque nous utilisons des paramètres de type générique, nous pouvons spécifier un type concret par défaut pour le type générique. Cela élimine la nécessité pour les implémenteurs du trait de spécifier un type concret si le type par défaut convient. Vous spécifiez un type par défaut en déclarant un type générique avec la syntaxe <TypeDeSubstitution=TypeConcret>.
Un excellent exemple de situation où cette technique est utile est la surcharge d’opérateurs, dans laquelle vous personnalisez le comportement d’un opérateur (comme +) dans des situations particulières.
Rust ne vous permet pas de créer vos propres opérateurs ni de surcharger des opérateurs arbitraires. Mais vous pouvez surcharger les opérations et les traits correspondants listés dans std::ops en implémentant les traits associés à l’opérateur. Par exemple, dans l’encart 20-15, nous surchargeons l’opérateur + pour additionner deux instances de Point. Nous faisons cela en implémentant le trait Add sur une structure Point.
use std::ops::Add;
#[derive(Debug, Copy, Clone, PartialEq)]
struct Point {
x: i32,
y: i32,
}
impl Add for Point {
type Output = Point;
fn add(self, other: Point) -> Point {
Point {
x: self.x + other.x,
y: self.y + other.y,
}
}
}
fn main() {
assert_eq!(
Point { x: 1, y: 0 } + Point { x: 2, y: 3 },
Point { x: 3, y: 3 }
);
}Add trait to overload the + operator for Point instancesLa méthode add additionne les valeurs x de deux instances de Point et les valeurs y de deux instances de Point pour créer un nouveau Point. Le trait Add possède un type associé nommé Output qui détermine le type retourné par la méthode add.
Le type générique par défaut dans ce code se trouve dans le trait Add. Voici sa définition :
#![allow(unused)]
fn main() {
trait Add<Rhs=Self> {
type Output;
fn add(self, rhs: Rhs) -> Self::Output;
}
}Ce code devrait vous sembler généralement familier : un trait avec une méthode et un type associé. La partie nouvelle est Rhs=Self : cette syntaxe s’appelle les paramètres de type par défaut. Le paramètre de type générique Rhs (abréviation de “right-hand side”, côté droit) définit le type du paramètre rhs dans la méthode add. Si nous ne spécifions pas de type concret pour Rhs lorsque nous implémentons le trait Add, le type de Rhs sera par défaut Self, qui sera le type sur lequel nous implémentons Add.
Lorsque nous avons implémenté Add pour Point, nous avons utilisé la valeur par défaut pour Rhs car nous voulions additionner deux instances de Point. Regardons un exemple d’implémentation du trait Add où nous voulons personnaliser le type Rhs plutôt que d’utiliser la valeur par défaut.
Nous avons deux structures, Millimeters et Meters, contenant des valeurs dans des unités différentes. Cet enveloppement fin d’un type existant dans une autre structure est connu sous le nom de patron newtype, que nous décrivons plus en détail dans la section [“Implémenter des traits externes avec le patron newtype”][newtype]. Nous voulons additionner des valeurs en millimètres à des valeurs en mètres et que l’implémentation d’Add fasse la conversion correctement. Nous pouvons implémenter Add pour Millimeters avec Meters comme Rhs, comme montré dans l’encart 20-16.
use std::ops::Add;
struct Millimeters(u32);
struct Meters(u32);
impl Add<Meters> for Millimeters {
type Output = Millimeters;
fn add(self, other: Meters) -> Millimeters {
Millimeters(self.0 + (other.0 * 1000))
}
}Add trait on Millimeters to add Millimeters and MetersPour additionner Millimeters et Meters, nous spécifions impl Add<Meters> pour définir la valeur du paramètre de type Rhs au lieu d’utiliser la valeur par défaut Self.
Vous utiliserez les paramètres de type par défaut de deux manières principales :
- Pour étendre un type sans casser le code existant
- Pour permettre la personnalisation dans des cas spécifiques dont la plupart des utilisateurs n’auront pas besoin
Le trait Add de la bibliothèque standard est un exemple du second objectif : généralement, vous additionnerez deux types identiques, mais le trait Add offre la possibilité de personnaliser au-delà. Utiliser un paramètre de type par défaut dans la définition du trait Add signifie que vous n’avez pas à spécifier le paramètre supplémentaire la plupart du temps. En d’autres termes, un peu de code standard d’implémentation n’est pas nécessaire, rendant le trait plus facile à utiliser.
Le premier objectif est similaire au second mais en sens inverse : si vous voulez ajouter un paramètre de type à un trait existant, vous pouvez lui donner une valeur par défaut pour permettre l’extension de la fonctionnalité du trait sans casser le code d’implémentation existant.
Lever l’ambiguïté entre des méthodes portant le même nom
Rien en Rust n’empêche un trait d’avoir une méthode portant le même nom que la méthode d’un autre trait, et Rust ne vous empêche pas non plus d’implémenter les deux traits sur un même type. Il est aussi possible d’implémenter une méthode directement sur le type avec le même nom que les méthodes des traits.
Lors de l’appel de méthodes portant le même nom, vous devrez indiquer à Rust laquelle vous souhaitez utiliser. Considérez le code de l’encart 20-17 où nous avons défini deux traits, Pilot et Wizard, qui ont tous deux une méthode appelée fly. Nous implémentons ensuite les deux traits sur un type Human qui possède déjà une méthode nommée fly. Chaque méthode fly fait quelque chose de différent.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {}fly method and are implemented on the Human type, and a fly method is implemented on Human directly.Lorsque nous appelons fly sur une instance de Human, le compilateur appelle par défaut la méthode directement implémentée sur le type, comme montré dans l’encart 20-18.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {
let person = Human;
person.fly();
}fly on an instance of HumanL’exécution de ce code affichera *waving arms furiously*, montrant que Rust a appelé la méthode fly implémentée directement sur Human.
Pour appeler les méthodes fly du trait Pilot ou du trait Wizard, nous devons utiliser une syntaxe plus explicite pour spécifier quelle méthode fly nous voulons dire. L’encart 20-19 illustre cette syntaxe.
trait Pilot {
fn fly(&self);
}
trait Wizard {
fn fly(&self);
}
struct Human;
impl Pilot for Human {
fn fly(&self) {
println!("This is your captain speaking.");
}
}
impl Wizard for Human {
fn fly(&self) {
println!("Up!");
}
}
impl Human {
fn fly(&self) {
println!("*waving arms furiously*");
}
}
fn main() {
let person = Human;
Pilot::fly(&person);
Wizard::fly(&person);
person.fly();
}fly method we want to callSpécifier le nom du trait avant le nom de la méthode clarifie pour Rust quelle implémentation de fly nous voulons appeler. Nous pourrions aussi écrire Human::fly(&person), qui est équivalent au person.fly() que nous avons utilisé dans l’encart 20-19, mais c’est un peu plus long à écrire si nous n’avons pas besoin de lever l’ambiguïté.
L’exécution de ce code affiche le résultat suivant : console {{#include ../listings/ch13-functional-features/listing-13-01/output.txt}}
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.46s
Running `target/debug/traits-example`
This is your captain speaking.
Up!
*waving arms furiously*
Parce que la méthode fly prend un paramètre self, si nous avions deux types qui implémentent tous les deux un même trait, Rust pourrait déterminer quelle implémentation du trait utiliser en se basant sur le type de self.
Cependant, les fonctions associées qui ne sont pas des méthodes n’ont pas de paramètre self. Lorsqu’il y à plusieurs types ou traits qui définissent des fonctions non-méthodes avec le même nom de fonction, Rust ne sait pas toujours quel type vous voulez dire à moins que vous n’utilisiez la syntaxe pleinement qualifiée. Par exemple, dans l’encart 20-20, nous créons un trait pour un refuge animalier qui veut nommer tous les chiots Spot. Nous créons un trait Animal avec une fonction associée non-méthode baby_name. Le trait Animal est implémenté pour la structure Dog, sur laquelle nous fournissons aussi directement une fonction associée non-méthode baby_name.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Dog::baby_name());
}Nous implémentons le code pour nommer tous les chiots Spot dans la fonction associée baby_name définie sur Dog. Le type Dog implémente aussi le trait Animal, qui décrit les caractéristiques communes à tous les animaux. Les bébés chiens s’appellent des chiots, et cela est exprimé dans l’implémentation du trait Animal sur Dog dans la fonction baby_name associée au trait Animal.
Dans main, nous appelons la fonction Dog::baby_name, qui appelle la fonction associée définie directement sur Dog. Ce code affiche ce qui suit : console {{#include ../listings/ch20-advanced-features/listing-20-20/output.txt}}
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.54s
Running `target/debug/traits-example`
A baby dog is called a Spot
Cette sortie n’est pas ce que nous voulions. Nous voulons appeler la fonction baby_name qui fait partie du trait Animal que nous avons implémenté sur Dog pour que le code affiche A baby dog is called a puppy. La technique de spécification du nom du trait que nous avons utilisée dans l’encart 20-19 ne nous aide pas ici ; si nous changeons main avec le code de l’encart 20-21, nous obtiendrons une erreur de compilation.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", Animal::baby_name());
}baby_name function from the Animal trait, but Rust doesn’t know which implementation to useParce que Animal::baby_name n’a pas de paramètre self, et qu’il pourrait y avoir d’autres types qui implémentent le trait Animal, Rust ne peut pas déterminer quelle implémentation d’Animal::baby_name nous voulons. Nous obtiendrons cette erreur du compilateur : console {{#include ../listings/ch20-advanced-features/listing-20-21/output.txt}}
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0790]: cannot call associated function on trait without specifying the corresponding `impl` type
--> src/main.rs:20:43
|
2 | fn baby_name() -> String;
| ------------------------- `Animal::baby_name` defined here
...
20 | println!("A baby dog is called a {}", Animal::baby_name());
| ^^^^^^^^^^^^^^^^^^^ cannot call associated function of trait
|
help: use the fully-qualified path to the only available implementation
|
20 | println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
| +++++++ +
For more information about this error, try `rustc --explain E0790`.
error: could not compile `traits-example` (bin "traits-example") due to 1 previous error
Pour lever l’ambiguïté et dire à Rust que nous voulons utiliser l’implémentation d’Animal pour Dog par opposition à l’implémentation d’Animal pour un autre type, nous devons utiliser la syntaxe pleinement qualifiée. L’encart 20-22 montre comment utiliser la syntaxe pleinement qualifiée.
trait Animal {
fn baby_name() -> String;
}
struct Dog;
impl Dog {
fn baby_name() -> String {
String::from("Spot")
}
}
impl Animal for Dog {
fn baby_name() -> String {
String::from("puppy")
}
}
fn main() {
println!("A baby dog is called a {}", <Dog as Animal>::baby_name());
}baby_name function from the Animal trait as implemented on DogNous fournissons à Rust une annotation de type entre les chevrons, qui indique que nous voulons appeler la méthode baby_name du trait Animal telle qu’implémentée sur Dog en disant que nous voulons traiter le type Dog comme un Animal pour cet appel de fonction. Ce code affichera maintenant ce que nous voulons : console {{#include ../listings/ch20-advanced-features/listing-20-22/output.txt}}
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.48s
Running `target/debug/traits-example`
A baby dog is called a puppy
En général, la syntaxe pleinement qualifiée est définie comme suit :
<Type as Trait>::function(receiver_if_method, next_arg, ...);Pour les fonctions associées qui ne sont pas des méthodes, il n’y aurait pas de receiver : il n’y aurait que la liste des autres arguments. Vous pourriez utiliser la syntaxe pleinement qualifiée partout où vous appelez des fonctions ou des méthodes. Cependant, vous êtes autorisé à omettre toute partie de cette syntaxe que Rust peut déduire d’autres informations dans le programme. Vous n’avez besoin d’utiliser cette syntaxe plus verbeuse que dans les cas où il y à plusieurs implémentations utilisant le même nom et où Rust a besoin d’aide pour identifier quelle implémentation vous voulez appeler.
Utiliser les supertraits
Parfois, vous pourriez écrire une définition de trait qui dépend d’un autre trait : pour qu’un type implémente le premier trait, vous voulez exiger que ce type implémente aussi le second trait. Vous feriez cela pour que la définition de votre trait puisse utiliser les éléments associés du second trait. Le trait sur lequel votre définition de trait s’appuie est appelé un supertrait de votre trait.
Par exemple, disons que nous voulons créer un trait OutlinePrint avec une méthode outline_print qui affichera une valeur donnée formatée de sorte qu’elle soit encadrée d’astérisques. C’est-à-dire, étant donné une structure Point qui implémente le trait Display de la bibliothèque standard pour produire (x, y), lorsque nous appelons outline_print sur une instance de Point qui a 1 pour x et 3 pour y, elle devrait afficher ce qui suit :
**********
* *
* (1, 3) *
* *
**********
Dans l’implémentation de la méthode outline_print, nous voulons utiliser la fonctionnalité du trait Display. Par conséquent, nous devons spécifier que le trait OutlinePrint ne fonctionnera que pour les types qui implémentent aussi Display et fournissent la fonctionnalité dont OutlinePrint a besoin. Nous pouvons faire cela dans la définition du trait en spécifiant OutlinePrint: Display. Cette technique est similaire à l’ajout d’une contrainte de trait au trait. L’encart 20-23 montre une implémentation du trait OutlinePrint.
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
fn main() {}OutlinePrint trait that requires the functionality from DisplayParce que nous avons spécifié qu’OutlinePrint nécessite le trait Display, nous pouvons utiliser la fonction to_string qui est automatiquement implémentée pour tout type qui implémente Display. Si nous essayions d’utiliser to_string sans ajouter un deux-points et spécifier le trait Display après le nom du trait, nous obtiendrions une erreur disant qu’aucune méthode nommée to_string n’a été trouvée pour le type &Self dans la portée actuelle.
Voyons ce qui se passe lorsque nous essayons d’implémenter OutlinePrint sur un type qui n’implémente pas Display, comme la structure Point :
use std::fmt;
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}Nous obtenons une erreur disant que Display est requis mais n’est pas implémenté : console {{#include ../listings/ch20-advanced-features/no-listing-02-impl-outlineprint-for-point/output.txt}}
$ cargo run
Compiling traits-example v0.1.0 (file:///projects/traits-example)
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:20:23
|
20 | impl OutlinePrint for Point {}
| ^^^^^ the trait `std::fmt::Display` is not implemented for `Point`
|
note: required by a bound in `OutlinePrint`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint`
error[E0277]: `Point` doesn't implement `std::fmt::Display`
--> src/main.rs:24:7
|
24 | p.outline_print();
| ^^^^^^^^^^^^^ the trait `std::fmt::Display` is not implemented for `Point`
|
note: required by a bound in `OutlinePrint::outline_print`
--> src/main.rs:3:21
|
3 | trait OutlinePrint: fmt::Display {
| ^^^^^^^^^^^^ required by this bound in `OutlinePrint::outline_print`
4 | fn outline_print(&self) {
| ------------- required by a bound in this associated function
For more information about this error, try `rustc --explain E0277`.
error: could not compile `traits-example` (bin "traits-example") due to 2 previous errors
Pour corriger cela, nous implémentons Display sur Point et satisfaisons la contrainte qu’OutlinePrint exige, comme suit :
trait OutlinePrint: fmt::Display {
fn outline_print(&self) {
let output = self.to_string();
let len = output.len();
println!("{}", "*".repeat(len + 4));
println!("*{}*", " ".repeat(len + 2));
println!("* {output} *");
println!("*{}*", " ".repeat(len + 2));
println!("{}", "*".repeat(len + 4));
}
}
struct Point {
x: i32,
y: i32,
}
impl OutlinePrint for Point {}
use std::fmt;
impl fmt::Display for Point {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "({}, {})", self.x, self.y)
}
}
fn main() {
let p = Point { x: 1, y: 3 };
p.outline_print();
}Ensuite, l’implémentation du trait OutlinePrint sur Point compilera avec succès, et nous pourrons appeler outline_print sur une instance de Point pour l’afficher dans un cadre d’astérisques.
Implémenter des traits externes avec le patron newtype
Dans la section [“Implémenter un trait sur un type”][implementing-a-trait-on-a-type] du chapitre 10, nous avons mentionné la règle de l’orphelin qui stipule que nous ne sommes autorisés à implémenter un trait sur un type que si soit le trait, soit le type, soit les deux, sont locaux à notre crate. Il est possible de contourner cette restriction en utilisant le patron newtype, qui consiste à créer un nouveau type dans une structure tuple. (Nous avons couvert les structures tuple dans la section [“Créer différents types avec les structures tuple”][tuple-structs] du chapitre 5.) La structure tuple aura un seul champ et sera un enveloppement fin autour du type pour lequel nous voulons implémenter un trait. Ensuite, le type enveloppeur est local à notre crate, et nous pouvons implémenter le trait sur l’enveloppeur. Newtype est un terme qui provient du langage de programmation Haskell. Il n’y a pas de pénalité de performance à l’exécution pour l’utilisation de ce patron, et le type enveloppeur est éliminé au moment de la compilation.
À titre d’exemple, disons que nous voulons implémenter Display sur Vec<T>, ce que la règle de l’orphelin nous empêche de faire directement car le trait Display et le type Vec<T> sont définis en dehors de notre crate. Nous pouvons créer une structure Wrapper qui contient une instance de Vec<T> ; ensuite, nous pouvons implémenter Display sur Wrapper et utiliser la valeur Vec<T>, comme montré dans l’encart 20-24.
use std::fmt;
struct Wrapper(Vec<String>);
impl fmt::Display for Wrapper {
fn fmt(&self, f: &mut fmt::Formatter) -> fmt::Result {
write!(f, "[{}]", self.0.join(", "))
}
}
fn main() {
let w = Wrapper(vec![String::from("hello"), String::from("world")]);
println!("w = {w}");
}Wrapper type around Vec<String> to implement DisplayL’implémentation de Display utilise self.0 pour accéder au Vec<T> interne car Wrapper est une structure tuple et Vec<T> est l’élément à l’indice 0 dans le tuple. Ensuite, nous pouvons utiliser la fonctionnalité du trait Display sur Wrapper.
section in Chapter 15). If we didn’t want the Wrapper type to have all the methods of the inner type—for example, to restrict the Wrapper type’s behavior—we would have to implement just the methods we do want manually. –> L’inconvénient d’utiliser cette technique est que Wrapper est un nouveau type, il n’a donc pas les méthodes de la valeur qu’il contient. Nous devrions implémenter toutes les méthodes de Vec<T> directement sur Wrapper de sorte que les méthodes délèguent à self.0, ce qui nous permettrait de traiter Wrapper exactement comme un Vec<T>. Si nous voulions que le nouveau type ait toutes les méthodes du type interne, implémenter le trait Deref sur Wrapper pour retourner le type interne serait une solution (nous avons discuté de l’implémentation du trait Deref dans la section [“Traiter les pointeurs intelligents comme des références normales”][smart-pointer-deref] du chapitre 15). Si nous ne voulions pas que le type Wrapper ait toutes les méthodes du type interne – par exemple, pour restreindre le comportement du type Wrapper – nous devrions implémenter manuellement seulement les méthodes que nous souhaitons.
Ce patron newtype est aussi utile même quand les traits ne sont pas impliqués. Changeons de sujet et examinons quelques manières avancées d’interagir avec le système de types de Rust.
Les types avancés
Les types avancés
Le système de types de Rust possède des fonctionnalités que nous avons mentionnées jusqu’à présent mais que nous n’avons pas encore discutées. Nous commencerons par discuter des newtypes en général en examinant pourquoi ils sont utiles en tant que types. Ensuite, nous passerons aux alias de types, une fonctionnalité similaire aux newtypes mais avec une sémantique légèrement différente. Nous discuterons aussi du type ! et des types à taille dynamique.
Sécurité de type et abstraction avec le patron newtype
Cette section suppose que vous avez lu la section précédente [“Implémenter des traits externes avec le patron newtype”][newtype]. Le patron newtype est aussi utile pour des tâches au-delà de celles que nous avons discutées jusqu’à présent, notamment pour imposer statiquement que les valeurs ne soient jamais confondues et indiquer les unités d’une valeur. Vous avez vu un exemple d’utilisation des newtypes pour indiquer les unités dans l’encart 20-16 : rappelez-vous que les structures Millimeters et Meters enveloppaient des valeurs u32 dans un newtype. Si nous écrivions une fonction avec un paramètre de type Millimeters, nous ne pourrions pas compiler un programme qui essaierait accidentellement d’appeler cette fonction avec une valeur de type Meters ou un simple u32.
Nous pouvons aussi utiliser le patron newtype pour abstraire certains détails d’implémentation d’un type : le nouveau type peut exposer une API publique différente de l’API du type interne privé.
section in Chapter 18. –> Les newtypes peuvent aussi masquer l’implémentation interne. Par exemple, nous pourrions fournir un type People pour envelopper un HashMap<i32, String> qui stocké l’identifiant d’une personne associé à son nom. Le code utilisant People n’interagirait qu’avec l’API publique que nous fournissons, comme une méthode pour ajouter un nom en chaîne de caractères à la collection People ; ce code n’aurait pas besoin de savoir que nous assignons un identifiant i32 aux noms en interne. Le patron newtype est un moyen léger d’atteindre l’encapsulation pour masquer les détails d’implémentation, ce dont nous avons discuté dans la section [“L’encapsulation qui masque les détails d’implémentation”][encapsulation-that-hides-implementation-details] du chapitre 18.
Les synonymes de types et les alias de types
Rust offre la possibilité de déclarer un alias de type pour donner un autre nom à un type existant. Pour cela, nous utilisons le mot-clé type. Par exemple, nous pouvons créer l’alias Kilometers pour i32 comme suit : rust {{#rustdoc_include ../listings/ch20-advanced-features/no-listing-04-kilometers-alias/src/main.rs:here}}
fn main() {
type Kilometers = i32;
let x: i32 = 5;
let y: Kilometers = 5;
println!("x + y = {}", x + y);
}Maintenant l’alias Kilometers est un synonyme de i32 ; contrairement aux types Millimeters et Meters que nous avons créés dans l’encart 20-16, Kilometers n’est pas un type nouveau et distinct. Les valeurs de type Kilometers seront traitées de la même manière que les valeurs de type i32 : rust {{#rustdoc_include ../listings/ch20-advanced-features/no-listing-04-kilometers-alias/src/main.rs:there}}
fn main() {
type Kilometers = i32;
let x: i32 = 5;
let y: Kilometers = 5;
println!("x + y = {}", x + y);
}Comme Kilometers et i32 sont le même type, nous pouvons additionner des valeurs des deux types et passer des valeurs Kilometers à des fonctions qui prennent des paramètres i32. Cependant, avec cette méthode, nous n’obtenons pas les avantages de vérification de types que nous obtenons avec le patron newtype discuté précédemment. En d’autres termes, si nous mélangeons des valeurs Kilometers et i32 quelque part, le compilateur ne nous donnera pas d’erreur.
Le principal cas d’utilisation des synonymes de types est de réduire la répétition. Par exemple, nous pourrions avoir un type long comme celui-ci :
Box<dyn Fn() + Send + 'static>Écrire ce type long dans les signatures de fonctions et comme annotations de type partout dans le code peut être fastidieux et source d’erreurs. Imaginez avoir un projet plein de code comme dans l’encart 20-25.
fn main() {
let f: Box<dyn Fn() + Send + 'static> = Box::new(|| println!("hi"));
fn takes_long_type(f: Box<dyn Fn() + Send + 'static>) {
// --snip--
}
fn returns_long_type() -> Box<dyn Fn() + Send + 'static> {
// --snip--
Box::new(|| ())
}
}Un alias de type rend ce code plus gérable en réduisant la répétition. Dans l’encart 20-26, nous avons introduit un alias nommé Thunk pour le type verbeux et pouvons remplacer toutes les utilisations du type par l’alias plus court Thunk.
fn main() {
type Thunk = Box<dyn Fn() + Send + 'static>;
let f: Thunk = Box::new(|| println!("hi"));
fn takes_long_type(f: Thunk) {
// --snip--
}
fn returns_long_type() -> Thunk {
// --snip--
Box::new(|| ())
}
}Thunk, to reduce repetitionCe code est beaucoup plus facile à lire et à écrire ! Choisir un nom significatif pour un alias de type peut aussi aider à communiquer votre intention (thunk est un mot désignant du code à évaluer ultérieurement, c’est donc un nom approprié pour une fermeture qui est stockée).
Les alias de types sont aussi couramment utilisés avec le type Result<T, E> pour réduire la répétition. Considérez le module std::io de la bibliothèque standard. Les opérations d’E/S retournent souvent un Result<T, E> pour gérer les situations où les opérations échouent. Cette bibliothèque possède une structure std::io::Error qui représente toutes les erreurs d’E/S possibles. Beaucoup de fonctions dans std::io retourneront un Result<T, E> où E est std::io::Error, comme ces fonctions dans le trait Write : rust,noplayground {{#rustdoc_include ../listings/ch20-advanced-features/no-listing-05-write-trait/src/lib.rs}}
use std::fmt;
use std::io::Error;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize, Error>;
fn flush(&mut self) -> Result<(), Error>;
fn write_all(&mut self, buf: &[u8]) -> Result<(), Error>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<(), Error>;
}Le Result<..., Error> est beaucoup répété. C’est pourquoi std::io possède cette déclaration d’alias de type : rust,noplayground {{#rustdoc_include ../listings/ch20-advanced-features/no-listing-06-result-alias/src/lib.rs:here}}
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}Comme cette déclaration se trouve dans le module std::io, nous pouvons utiliser l’alias pleinement qualifié std::io::Result<T> ; c’est-à-dire un Result<T, E> avec E rempli par std::io::Error. Les signatures des fonctions du trait Write finissent par ressembler à ceci : rust,noplayground {{#rustdoc_include ../listings/ch20-advanced-features/no-listing-06-result-alias/src/lib.rs:there}}
use std::fmt;
type Result<T> = std::result::Result<T, std::io::Error>;
pub trait Write {
fn write(&mut self, buf: &[u8]) -> Result<usize>;
fn flush(&mut self) -> Result<()>;
fn write_all(&mut self, buf: &[u8]) -> Result<()>;
fn write_fmt(&mut self, fmt: fmt::Arguments) -> Result<()>;
}L’alias de type aide de deux manières : il rend le code plus facile à écrire et nous donne une interface cohérente dans tout std::io. Parce que c’est un alias, c’est juste un autre Result<T, E>, ce qui signifie que nous pouvons utiliser toutes les méthodes qui fonctionnent sur Result<T, E> avec lui, ainsi que la syntaxe spéciale comme l’opérateur ?.
Le type never qui ne retourné jamais
Rust possède un type spécial nommé ! qui est connu dans le jargon de la théorie des types comme le type vide car il n’a pas de valeurs. Nous préférons l’appeler le type never car il tient la place du type de retour lorsqu’une fonction ne retournera jamais. Voici un exemple : rust,noplayground {{#rustdoc_include ../listings/ch20-advanced-features/no-listing-07-never-type/src/lib.rs:here}}
fn bar() -> ! {
// --snip--
panic!();
}Ce code se lit comme “la fonction bar ne retourné jamais.” Les fonctions qui ne retournent jamais sont appelées fonctions divergentes. Nous ne pouvons pas créer de valeurs du type !, donc bar ne peut jamais retourner.
Mais à quoi sert un type dont vous ne pouvez jamais créer de valeurs ? Rappelez-vous le code de l’encart 2-5, partie du jeu de devinette de nombres ; nous en avons reproduit un extrait ici dans l’encart 20-27.
use std::cmp::Ordering;
use std::io;
use rand::Rng;
fn main() {
println!("Guess the number!");
let secret_number = rand::thread_rng().gen_range(1..=100);
println!("The secret number is: {secret_number}");
loop {
println!("Please input your guess.");
let mut guess = String::new();
// --snip--
io::stdin()
.read_line(&mut guess)
.expect("Failed to read line");
let guess: u32 = match guess.trim().parse() {
Ok(num) => num,
Err(_) => continue,
};
println!("You guessed: {guess}");
// --snip--
match guess.cmp(&secret_number) {
Ordering::Less => println!("Too small!"),
Ordering::Greater => println!("Too big!"),
Ordering::Equal => {
println!("You win!");
break;
}
}
}
}match with an arm that ends in continueÀ l’époque, nous avions passé sous silence certains détails de ce code. Dans la section « La construction de flux de contrôle match » du chapitre 6, nous avons discuté du fait que toutes les branches de match doivent retourner le même type. Ainsi, par exemple, le code suivant ne fonctionne pas{N}:
fn main() {
let guess = "3";
let guess = match guess.trim().parse() {
Ok(_) => 5,
Err(_) => "hello",
};
}Le type de guess dans ce code devrait être à la fois un entier et une chaîne de caractères, et Rust exige que guess n’ait qu’un seul type. Alors, que retourné continue ? Comment avons-nous été autorisés à retourner un u32 d’une branche et à avoir une autre branche qui se terminé par continue dans l’encart 20-27 ?
Comme vous l’avez peut-être deviné, continue à une valeur de type !. C’est-à-dire, lorsque Rust calcule le type de guess, il regarde les deux branches du match, la première avec une valeur u32 et la seconde avec une valeur !. Parce que ! ne peut jamais avoir de valeur, Rust décide que le type de guess est u32.
La manière formelle de décrire ce comportement est que les expressions de type ! peuvent être converties implicitement en n’importe quel autre type. Nous sommes autorisés à terminer cette branche du match avec continue car continue ne retourné pas de valeur ; à la place, il transfère le contrôle au début de la boucle, donc dans le cas Err, nous n’assignons jamais de valeur à guess.
Le type never est aussi utile avec la macro panic!. Rappelez-vous la fonction unwrap que nous appelons sur les valeurs Option<T> pour produire une valeur ou paniquer avec cette définition : rust,ignore {{#rustdoc_include ../listings/ch20-advanced-features/no-listing-09-unwrap-definition/src/lib.rs:here}}
enum Option<T> {
Some(T),
None,
}
use crate::Option::*;
impl<T> Option<T> {
pub fn unwrap(self) -> T {
match self {
Some(val) => val,
None => panic!("called `Option::unwrap()` on a `None` value"),
}
}
}Dans ce code, la même chose se passe que dans le match de l’encart 20-27 : Rust voit que val à le type T et panic! à le type !, donc le résultat de l’expression match globale est T. Ce code fonctionne car panic! ne produit pas de valeur ; il terminé le programme. Dans le cas None, nous ne retournerons pas de valeur depuis unwrap, donc ce code est valide.
Une dernière expression qui à le type ! est une boucle : rust,ignore {{#rustdoc_include ../listings/ch20-advanced-features/no-listing-10-loop-returns-never/src/main.rs:here}}
fn main() {
print!("forever ");
loop {
print!("and ever ");
}
}Ici, la boucle ne se terminé jamais, donc ! est la valeur de l’expression. Cependant, ce ne serait pas vrai si nous incluions un break, car la boucle se terminerait lorsqu’elle atteindrait le break.
Les types à taille dynamique et le trait Sized
Rust a besoin de connaître certains détails sur ses types, comme combien d’espace allouer pour une valeur d’un type particulier. Cela laisse un coin de son système de types un peu déroutant au début : le concept de types à taille dynamique. Parfois appelés DST ou types non dimensionnés, ces types nous permettent d’écrire du code utilisant des valeurs dont nous ne pouvons connaître la taille qu’à l’exécution.
Creusons les détails d’un type à taille dynamique appelé str, que nous avons utilisé tout au long du livre. C’est exact, pas &str, mais str seul, est un DST. Dans de nombreux cas, comme lors du stockage de texte saisi par un utilisateur, nous ne pouvons pas savoir quelle est la longueur de la chaîne avant l’exécution. Cela signifie que nous ne pouvons pas créer une variable de type str, ni prendre un argument de type str. Considérez le code suivant, qui ne fonctionne pas : rust,ignore,does_not_compile {{#rustdoc_include ../listings/ch20-advanced-features/no-listing-11-cant-create-str/src/main.rs:here}}
fn main() {
let s1: str = "Hello there!";
let s2: str = "How's it going?";
}Rust a besoin de savoir combien de mémoire allouer pour toute valeur d’un type particulier, et toutes les valeurs d’un type doivent utiliser la même quantité de mémoire. Si Rust nous permettait d’écrire ce code, ces deux valeurs str devraient occuper la même quantité d’espace. Mais elles ont des longueurs différentes : s1 a besoin de 12 octets de stockage et s2 a besoin de 15. C’est pourquoi il n’est pas possible de créer une variable contenant un type à taille dynamique.
Alors, que faisons-nous ? Dans ce cas, vous connaissez déjà la réponse : nous faisons du type de s1 et s2 une slice de chaîne (&str) plutôt que str. Rappelez-vous de la section [“Les slices de chaînes”][string-slices] du chapitre 4 que la structure de données slice ne stocké que la position de début et la longueur de la slice. Ainsi, bien que &T soit une seule valeur qui stocké l’adresse mémoire où se trouve le T, une slice de chaîne est deux valeurs : l’adresse du str et sa longueur. En tant que tel, nous pouvons connaître la taille d’une valeur de slice de chaîne au moment de la compilation : c’est deux fois la longueur d’un usize. C’est-à-dire que nous connaissons toujours la taille d’une slice de chaîne, quelle que soit la longueur de la chaîne à laquelle elle se réfère. En général, c’est de cette manière que les types à taille dynamique sont utilisés en Rust : ils ont un bit supplémentaire de métadonnées qui stocké la taille de l’information dynamique. La règle d’or des types à taille dynamique est que nous devons toujours placer les valeurs de types à taille dynamique derrière un pointeur d’un type ou d’un autre.
Nous pouvons combiner str avec toutes sortes de pointeurs : par exemple, Box<str> ou Rc<str>. En fait, vous avez déjà vu cela mais avec un type à taille dynamique différent : les traits. Chaque trait est un type à taille dynamique auquel nous pouvons nous référer en utilisant le nom du trait. Dans la section [“Utiliser les objets trait pour abstraire un comportement partagé”][using-trait-objects-to-abstract-over-shared-behavior] du chapitre 18, nous avons mentionné que pour utiliser des traits comme objets trait, nous devons les placer derrière un pointeur, comme &dyn Trait ou Box<dyn Trait> (Rc<dyn Trait> fonctionnerait aussi).
Pour travailler avec les DST, Rust fournit le trait Sized pour déterminer si la taille d’un type est connue ou non au moment de la compilation. Ce trait est automatiquement implémenté pour tout ce dont la taille est connue au moment de la compilation. De plus, Rust ajouté implicitement une contrainte sur Sized à chaque fonction générique. C’est-à-dire qu’une définition de fonction générique comme celle-ci : rust,ignore {{#rustdoc_include ../listings/ch20-advanced-features/no-listing-12-generic-fn-definition/src/lib.rs}}
fn generic<T>(t: T) {
// --snip--
}est en fait traitée comme si nous avions écrit ceci : rust,ignore {{#rustdoc_include ../listings/ch20-advanced-features/no-listing-13-generic-implicit-sized-bound/src/lib.rs}}
fn generic<T: Sized>(t: T) {
// --snip--
}Par défaut, les fonctions génériques ne fonctionneront que sur des types dont la taille est connue au moment de la compilation. Cependant, vous pouvez utiliser la syntaxe spéciale suivante pour assouplir cette restriction : rust,ignore {{#rustdoc_include ../listings/ch20-advanced-features/no-listing-14-generic-maybe-sized/src/lib.rs}}
fn generic<T: ?Sized>(t: &T) {
// --snip--
}Une contrainte de trait sur ?Sized signifie “T peut ou non être Sized”, et cette notation remplace la valeur par défaut selon laquelle les types génériques doivent avoir une taille connue au moment de la compilation. La syntaxe ?Trait avec cette signification n’est disponible que pour Sized, pas pour d’autres traits.
Notez aussi que nous avons changé le type du paramètre t de T à &T. Parce que le type pourrait ne pas être Sized, nous devons l’utiliser derrière un pointeur d’un type ou d’un autre. Dans ce cas, nous avons choisi une référence.
Ensuite, nous allons parler des fonctions et des fermetures !
Les fonctions et les closures avancées
Les fonctions et les closures avancées
Cette section explore quelques fonctionnalités avancées liées aux fonctions et aux fermetures, notamment les pointeurs de fonction et le retour de fermetures.
Les pointeurs de fonction
Nous avons parlé de comment passer des fermetures aux fonctions ; vous pouvez aussi passer des fonctions normales aux fonctions ! Cette technique est utile lorsque vous voulez passer une fonction que vous avez déjà définie plutôt que de définir une nouvelle fermeture. Les fonctions se convertissent implicitement vers le type fn (avec un f minuscule), à ne pas confondre avec le trait de fermeture Fn. Le type fn est appelé un pointeur de fonction. Passer des fonctions avec des pointeurs de fonction vous permettra d’utiliser des fonctions comme arguments d’autres fonctions.
La syntaxe pour spécifier qu’un paramètre est un pointeur de fonction est similaire à celle des fermetures, comme montré dans l’encart 20-28, où nous avons défini une fonction add_one qui ajouté 1 à son paramètre. La fonction do_twice prend deux paramètres : un pointeur de fonction vers toute fonction qui prend un paramètre i32 et retourné un i32, et une valeur i32. La fonction do_twice appelle la fonction f deux fois, en lui passant la valeur arg, puis additionne les deux résultats des appels de fonction. La fonction main appelle do_twice avec les arguments add_one et 5.
fn add_one(x: i32) -> i32 {
x + 1
}
fn do_twice(f: fn(i32) -> i32, arg: i32) -> i32 {
f(arg) + f(arg)
}
fn main() {
let answer = do_twice(add_one, 5);
println!("The answer is: {answer}");
}fn type to accept a function pointer as an argumentCe code affiche The answer is: 12. Nous spécifions que le paramètre f dans do_twice est un fn qui prend un paramètre de type i32 et retourné un i32. Nous pouvons ensuite appeler f dans le corps de do_twice. Dans main, nous pouvons passer le nom de fonction add_one comme premier argument à do_twice.
Contrairement aux fermetures, fn est un type plutôt qu’un trait, donc nous spécifions fn comme type de paramètre directement plutôt que de déclarer un paramètre de type générique avec l’un des traits Fn comme contrainte de trait.
Les pointeurs de fonction implémentent les trois traits de fermeture (Fn, FnMut et FnOnce), ce qui signifie que vous pouvez toujours passer un pointeur de fonction comme argument d’une fonction qui attend une fermeture. Il est préférable d’écrire des fonctions utilisant un type générique et l’un des traits de fermeture afin que vos fonctions puissent accepter aussi bien des fonctions que des fermetures.
Cela dit, un exemple où vous voudriez n’accepter que fn et pas les fermetures est lors de l’interfaçage avec du code externe qui n’a pas de fermetures : les fonctions C peuvent accepter des fonctions comme arguments, mais C n’a pas de fermetures.
Comme exemple d’un cas où vous pourriez utiliser soit une fermeture définie en ligne soit une fonction nommée, regardons une utilisation de la méthode map fournie par le trait Iterator de la bibliothèque standard. Pour utiliser la méthode map afin de transformer un vecteur de nombres en un vecteur de chaînes de caractères, nous pourrions utiliser une fermeture, comme dans l’encart 20-29.
fn main() {
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> =
list_of_numbers.iter().map(|i| i.to_string()).collect();
}map method to convert numbers to stringsOu nous pourrions nommer une fonction comme argument de map au lieu de la fermeture. L’encart 20-30 montre à quoi cela ressemblerait.
fn main() {
let list_of_numbers = vec![1, 2, 3];
let list_of_strings: Vec<String> =
list_of_numbers.iter().map(ToString::to_string).collect();
}String::to_string function with the map method to convert numbers to stringsNotez que nous devons utiliser la syntaxe complètement qualifiée dont nous avons parlé dans la section « Traits avancés » plus tôt dans ce chapitre. Parce qu’il y à plusieurs fonctions appelées f (une pour Dog et une pour Animal), Rust ne peut pas déterminer à quelle fonction nous nous référons sans la syntaxe complètement qualifiée.
Ici, nous utilisons la fonction to_string définie dans le trait ToString, que la bibliothèque standard a implémenté pour tout type qui implémente Display.
Rappelez-vous dans la section « Les valeurs d’enum » du chapitre 6 que le nom que nous définissons pour chaque variante d’enum devient aussi une fonction d’initialisation pour la variante. Nous pouvons utiliser ces fonctions d’initialisation comme des pointeurs de fonction qui implémentent les traits de fermeture, ce qui signifie que nous pouvons spécifier les fonctions d’initialisation comme arguments pour les méthodes qui prennent des fermetures.
fn main() {
enum Status {
Value(u32),
Stop,
}
let list_of_statuses: Vec<Status> = (0u32..20).map(Status::Value).collect();
}map method to create a Status instance from numbersIci, nous créons des instances de Status::Value en utilisant chaque valeur u32 de l’intervalle sur lequel map est appelé en utilisant la fonction d’initialisation de Status::Value. Certaines personnes préfèrent ce style et d’autres préfèrent utiliser des fermetures. Ils compilent vers le même code, donc utilisez le style qui vous semble le plus clair.
Retourner des fermetures
Les fermetures sont représentées par des traits, ce qui signifie que vous ne pouvez pas retourner des fermetures directement. Dans la plupart des cas où vous voudriez retourner un trait, vous pouvez utiliser à la place le type concret qui implémente le trait comme valeur de retour de la fonction. Cependant, vous ne pouvez généralement pas faire cela avec les fermetures car elles n’ont pas de type concret qui peut être retourné ; vous n’êtes pas autorisé à utiliser le pointeur de fonction fn comme type de retour si la fermeture capture des valeurs de sa portée, par exemple.
À la place, vous utiliserez normalement la syntaxe impl Trait que nous avons apprise au chapitre 10. Vous pouvez retourner n’importe quel type de fonction, en utilisant Fn, FnOnce et FnMut. Par exemple, le code de l’encart 20-32 compilera sans problème.
#![allow(unused)]
fn main() {
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 1
}
}impl Trait syntaxCependant, comme nous l’avons noté dans la section « Inférer et annoter les types de fermeture », le compilateur a tendance à inférer un type concret pour chaque paramètre de fermeture ou type de retour. Cela signifie que vous ne pouvez pas retourner deux fermetures différentes qui implémentent le même trait en tant que types abstraits.
fn main() {
let handlers = vec![returns_closure(), returns_initialized_closure(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn returns_closure() -> impl Fn(i32) -> i32 {
|x| x + 1
}
fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
move |x| x + init
}Vec<T> of closures defined by functions that return impl Fn typesIci nous avons deux fonctions, returns_closure et returns_initialized_closure, qui retournent toutes les deux impl Fn(i32) -> i32. Remarquez que les fermetures qu’elles retournent sont différentes, même si elles implémentent le même type. Si nous essayons de compiler ceci, Rust nous fait savoir que cela ne fonctionnera pas : text {{#include ../listings/ch20-advanced-features/listing-20-33/output.txt}}
$ cargo build
Compiling functions-example v0.1.0 (file:///projects/functions-example)
error[E0308]: mismatched types
--> src/main.rs:2:44
|
2 | let handlers = vec![returns_closure(), returns_initialized_closure(123)];
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^ expected opaque type, found a different opaque type
...
9 | fn returns_closure() -> impl Fn(i32) -> i32 {
| ------------------- the expected opaque type
...
13 | fn returns_initialized_closure(init: i32) -> impl Fn(i32) -> i32 {
| ------------------- the found opaque type
|
= note: expected opaque type `impl Fn(i32) -> i32`
found opaque type `impl Fn(i32) -> i32`
= note: distinct uses of `impl Trait` result in different opaque types
For more information about this error, try `rustc --explain E0308`.
error: could not compile `functions-example` (bin "functions-example") due to 1 previous error
Le message d’erreur nous dit que chaque fois que nous retournons un impl Trait, Rust crée un type opaque unique, un type dont nous ne pouvons pas voir les détails de ce que Rust construit pour nous, et dont nous ne pouvons pas deviner le type que Rust générera pour l’écrire nous-mêmes. Ainsi, même si ces fonctions retournent des fermetures qui implémentent le même trait, Fn(i32) -> i32, les types opaques que Rust génère pour chacune sont distincts. (C’est similaire à la façon dont Rust produit des types concrets différents pour des blocs async distincts même quand ils ont le même type de sortie, comme nous l’avons vu dans [“Le type Pin et le trait Unpin”][future-types] au chapitre 17.) Nous avons vu une solution à ce problème plusieurs fois maintenant : nous pouvons utiliser un objet trait, comme dans l’encart 20-34.
fn main() {
let handlers = vec![returns_closure(), returns_initialized_closure(123)];
for handler in handlers {
let output = handler(5);
println!("{output}");
}
}
fn returns_closure() -> Box<dyn Fn(i32) -> i32> {
Box::new(|x| x + 1)
}
fn returns_initialized_closure(init: i32) -> Box<dyn Fn(i32) -> i32> {
Box::new(move |x| x + init)
}Vec<T> of closures defined by functions that return Box<dyn Fn> so that they have the same typeCe code compilera sans problème. Pour en savoir plus sur les objets trait, référez-vous à la section [“Utiliser les objets trait pour abstraire un comportement partagé”][trait-objects] du chapitre 18.
Ensuite, regardons les macros !
Les macros
Les macros
Nous avons utilisé des macros comme println! tout au long de ce livre, mais nous n’avons pas exploré en détail ce qu’est une macro et comment elle fonctionne. Le terme macro fait référence à une famille de fonctionnalités en Rust – les macros déclaratives avec macro_rules! et trois types de macros procédurales :
- Les macros
#[derive]personnalisées qui spécifient du code ajouté avec l’attributderiveutilisé sur les structures et les enums - Les macros de type attribut qui définissent des attributs personnalisés utilisables sur n’importe quel élément
- Les macros de type fonction qui ressemblent à des appels de fonction mais opèrent sur les tokens spécifiés comme arguments
Nous allons parler de chacune d’elles à tour de rôle, mais d’abord, voyons pourquoi nous avons même besoin de macros alors que nous avons déjà des fonctions.
La différence entre les macros et les fonctions
Fondamentalement, les macros sont un moyen d’écrire du code qui écrit d’autre code, ce qu’on appelle la métaprogrammation. Dans l’annexe C, nous discutons de l’attribut derive, qui génère une implémentation de divers traits pour vous. Nous avons aussi utilisé les macros println! et vec! tout au long du livre. Toutes ces macros se développent pour produire plus de code que le code que vous avez écrit manuellement.
La métaprogrammation est utile pour réduire la quantité de code que vous devez écrire et maintenir, ce qui est aussi l’un des rôles des fonctions. Cependant, les macros possèdent des pouvoirs supplémentaires que les fonctions n’ont pas.
Une signature de fonction doit déclarer le nombre et le type de paramètres de la fonction. Les macros, en revanche, peuvent prendre un nombre variable de paramètres : nous pouvons appeler println!("hello") avec un argument ou println!("hello {}", name) avec deux arguments. De plus, les macros sont développées avant que le compilateur n’interprète la signification du code, donc une macro peut, par exemple, implémenter un trait sur un type donné. Une fonction ne le peut pas, car elle est appelée à l’exécution et un trait doit être implémenté au moment de la compilation.
L’inconvénient d’implémenter une macro au lieu d’une fonction est que les définitions de macros sont plus complexes que les définitions de fonctions car vous écrivez du code Rust qui écrit du code Rust. En raison de cette indirection, les définitions de macros sont généralement plus difficiles à lire, comprendre et maintenir que les définitions de fonctions.
Une autre différence importante entre les macros et les fonctions est que vous devez définir les macros ou les importer dans la portée avant de les appeler dans un fichier, contrairement aux fonctions que vous pouvez définir n’importe où et appeler n’importe où.
Les macros déclaratives pour la métaprogrammation générale
La forme de macros la plus largement utilisée en Rust est la macro déclarative. Celles-ci sont aussi parfois appelées “macros par l’exemple”, “macros macro_rules!” ou simplement “macros”. En leur coeur, les macros déclaratives vous permettent d’écrire quelque chose de similaire à une expression match de Rust. Comme discuté au chapitre 6, les expressions match sont des structures de contrôle qui prennent une expression, comparent la valeur résultante de l’expression à des motifs, puis exécutent le code associé au motif correspondant. Les macros comparent aussi une valeur à des motifs associés à du code particulier : dans cette situation, la valeur est le code source Rust littéral passé à la macro ; les motifs sont comparés à la structure de ce code source ; et le code associé à chaque motif, lorsqu’il correspond, remplace le code passé à la macro. Tout cela se produit pendant la compilation.
Pour définir une macro, vous utilisez la construction macro_rules!. Explorons comment utiliser macro_rules! en regardant comment la macro vec! est définie. Le chapitre 8 a couvert comment nous pouvons utiliser la macro vec! pour créer un nouveau vecteur avec des valeurs particulières. Par exemple, la macro suivante crée un nouveau vecteur contenant trois entiers :
#![allow(unused)]
fn main() {
let v: Vec<u32> = vec![1, 2, 3];
}Nous pourrions aussi utiliser la macro vec! pour créer un vecteur de deux entiers ou un vecteur de cinq slices de chaînes. Nous ne pourrions pas utiliser une fonction pour faire la même chose car nous ne connaîtrions pas le nombre ou le type de valeurs à l’avance.
L’encart 20-35 montre une définition légèrement simplifiée de la macro vec!.
#[macro_export]
macro_rules! vec {
( $( $x:expr ),* ) => {
{
let mut temp_vec = Vec::new();
$(
temp_vec.push($x);
)*
temp_vec
}
};
}vec! macro definitionRemarque : la définition réelle de la macro
vec!dans la bibliothèque standard inclut du code pour pré-allouer la bonne quantité de mémoire à l’avance. Ce code est une optimisation que nous n’incluons pas ici, pour simplifier l’exemple.
L’annotation #[macro_export] indique que cette macro devrait être rendue disponible chaque fois que le crate dans lequel la macro est définie est importé dans la portée. Sans cette annotation, la macro ne peut pas être importée dans la portée.
Nous commençons ensuite la définition de la macro avec macro_rules! et le nom de la macro que nous définissons sans le point d’exclamation. Le nom, dans ce cas vec, est suivi d’accolades indiquant le corps de la définition de la macro.
La structure dans le corps de vec! est similaire à la structure d’une expression match. Ici nous avons une branche avec le motif ( $( $x:expr ),* ), suivi de => et du bloc de code associé à ce motif. Si le motif correspond, le bloc de code associé sera émis. Étant donné que c’est le seul motif dans cette macro, il n’y a qu’une seule manière valide de correspondre ; tout autre motif entraînera une erreur. Les macros plus complexes auront plus d’une branche.
La syntaxe de motifs valide dans les définitions de macros est différente de la syntaxe de motifs couverte au chapitre 19 car les motifs de macros sont comparés à la structure du code Rust plutôt qu’à des valeurs. Parcourons ce que signifient les éléments du motif dans l’encart 20-29 ; pour la syntaxe complète des motifs de macros, consultez la [Référence Rust][ref].
D’abord, nous utilisons un jeu de parenthèses pour englober tout le motif. Nous utilisons un signé dollar ($) pour déclarer une variable dans le système de macros qui contiendra le code Rust correspondant au motif. Le signé dollar indique clairement qu’il s’agit d’une variable de macro par opposition à une variable Rust normale. Ensuite vient un jeu de parenthèses qui capture les valeurs correspondant au motif à l’intérieur des parenthèses pour utilisation dans le code de remplacement. À l’intérieur de $() se trouve $x:expr, qui correspond à n’importe quelle expression Rust et donne à l’expression le nom $x.
La virgule suivant $() indique qu’un caractère séparateur virgule littéral doit apparaître entre chaque instance du code correspondant au code dans $(). Le * spécifie que le motif correspond à zéro ou plusieurs occurrences de ce qui précède le *.
Lorsque nous appelons cette macro avec vec![1, 2, 3];, le motif $x correspond trois fois avec les trois expressions 1, 2 et 3.
Maintenant regardons le motif dans le corps du code associé à cette branche : temp_vec.push() à l’intérieur de $()* est généré pour chaque partie qui correspond à $() dans le motif zéro ou plusieurs fois selon le nombre de fois que le motif correspond. Le $x est remplacé par chaque expression correspondante. Lorsque nous appelons cette macro avec vec![1, 2, 3];, le code généré qui remplace cet appel de macro sera le suivant :
{
let mut temp_vec = Vec::new();
temp_vec.push(1);
temp_vec.push(2);
temp_vec.push(3);
temp_vec
}Nous avons défini une macro qui peut prendre n’importe quel nombre d’arguments de n’importe quel type et peut générer du code pour créer un vecteur contenant les éléments spécifiés.
Pour en apprendre plus sur l’écriture de macros, consultez la documentation en ligne ou d’autres ressources, comme [“The Little Book of Rust Macros”][tlborm] commencé par Daniel Keep et continué par Lukas Wirth.
Les macros procédurales pour générer du code à partir d’attributs
La deuxième forme de macros est la macro procédurale, qui agit davantage comme une fonction (et est un type de procédure). Les macros procédurales acceptent du code en entrée, opèrent sur ce code et produisent du code en sortie plutôt que de faire correspondre des motifs et de remplacer le code par un autre code comme le font les macros déclaratives. Les trois types de macros procédurales sont les macros derive personnalisées, les macros de type attribut et les macros de type fonction, et toutes fonctionnent de manière similaire.
Lors de la création de macros procédurales, les définitions doivent résider dans leur propre crate avec un type de crate spécial. C’est pour des raisons techniques complexes que nous espérons éliminer à l’avenir. Dans l’encart 20-36, nous montrons comment définir une macro procédurale, où some_attribute est un espace réservé pour l’utilisation d’une variété spécifique de macro.
use proc_macro::TokenStream;
#[some_attribute]
pub fn some_name(input: TokenStream) -> TokenStream {
}La fonction qui définit une macro procédurale prend un TokenStream en entrée et produit un TokenStream en sortie. Le type TokenStream est défini par le crate proc_macro inclus avec Rust et représente une séquence de tokens. C’est le coeur de la macro : le code source sur lequel la macro opère constitue le TokenStream d’entrée, et le code que la macro produit est le TokenStream de sortie. La fonction a aussi un attribut attaché qui spécifie quel type de macro procédurale nous créons. Nous pouvons avoir plusieurs types de macros procédurales dans le même crate.
Regardons les différents types de macros procédurales. Nous commencerons par une macro derive personnalisée puis expliquerons les petites différences qui distinguent les autres formes.
Les macros derive personnalisées
Créons un crate nommé hello_macro qui définit un trait nommé HelloMacro avec une fonction associée nommée hello_macro. Plutôt que de demander à nos utilisateurs d’implémenter le trait HelloMacro pour chacun de leurs types, nous fournirons une macro procédurale pour que les utilisateurs puissent annoter leur type avec #[derive(HelloMacro)] pour obtenir une implémentation par défaut de la fonction hello_macro. L’implémentation par défaut affichera Hello, Macro! My name is TypeName! où TypeName est le nom du type sur lequel ce trait a été défini. En d’autres termes, nous écrirons un crate qui permettra à un autre programmeur d’écrire du code comme l’encart 20-37 en utilisant notre crate.
use hello_macro::HelloMacro;
use hello_macro_derive::HelloMacro;
#[derive(HelloMacro)]
struct Pancakes;
fn main() {
Pancakes::hello_macro();
}Ce code affichera Hello, Macro! My name is Pancakes! lorsque nous aurons terminé. La première étape est de créer un nouveau crate de bibliothèque, comme ceci :
$ cargo new hello_macro --lib
Ensuite, dans l’encart 20-38, nous définirons le trait HelloMacro et sa fonction associée.
pub trait HelloMacro {
fn hello_macro();
}derive macroNous avons un trait et sa fonction. À ce stade, l’utilisateur de notre crate pourrait implémenter le trait pour obtenir la fonctionnalité souhaitée, comme dans l’encart 20-39.
use hello_macro::HelloMacro;
struct Pancakes;
impl HelloMacro for Pancakes {
fn hello_macro() {
println!("Hello, Macro! My name is Pancakes!");
}
}
fn main() {
Pancakes::hello_macro();
}HelloMacro traitCependant, ils devraient écrire le bloc d’implémentation pour chaque type qu’ils voudraient utiliser avec hello_macro ; nous voulons leur épargner ce travail.
De plus, nous ne pouvons pas encore fournir à la fonction hello_macro une implémentation par défaut qui afficherait le nom du type sur lequel le trait est implémenté : Rust n’a pas de capacités de réflexion, il ne peut donc pas rechercher le nom du type à l’exécution. Nous avons besoin d’une macro pour générer du code au moment de la compilation.
L’étape suivante est de définir la macro procédurale. Au moment de l’écriture, les macros procédurales doivent être dans leur propre crate. À terme, cette restriction pourrait être levée. La convention pour structurer les crates et les crates de macros est la suivante : pour un crate nommé foo, un crate de macro procédurale derive personnalisée s’appelle foo_derive. Commençons un nouveau crate appelé hello_macro_derive dans notre projet hello_macro :
$ cargo new hello_macro_derive --lib
Nos deux crates sont étroitement liés, nous créons donc le crate de macro procédurale dans le répertoire de notre crate hello_macro. Si nous changeons la définition du trait dans hello_macro, nous devrons aussi changer l’implémentation de la macro procédurale dans hello_macro_derive. Les deux crates devront être publiés séparément, et les programmeurs utilisant ces crates devront ajouter les deux comme dépendances et les importer tous les deux dans la portée. Nous pourrions plutôt faire en sorte que le crate hello_macro utilise hello_macro_derive comme dépendance et ré-exporte le code de la macro procédurale. Cependant, la manière dont nous avons structuré le projet permet aux programmeurs d’utiliser hello_macro même s’ils ne veulent pas la fonctionnalité derive.
Nous devons déclarer le crate hello_macro_derive comme un crate de macro procédurale. Nous aurons aussi besoin des fonctionnalités des crates syn et quote, comme vous le verrez dans un instant, nous devons donc les ajouter comme dépendances. Ajoutez ce qui suit au fichier Cargo.toml de hello_macro_derive :
[lib]
proc-macro = true
[dependencies]
syn = "2.0"
quote = "1.0"
Pour commencer à définir la macro procédurale, placez le code de l’encart 20-40 dans votre fichier src/lib.rs du crate hello_macro_derive. Notez que ce code ne compilera pas tant que nous n’ajoutons pas une définition pour la fonction impl_hello_macro.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a représentation of Rust code as a syntax tree
// that we can manipulate.
let ast = syn::parse(input).unwrap();
// Build the trait implémentation.
impl_hello_macro(&ast)
}Remarquez que nous avons séparé le code en la fonction hello_macro_derive, qui est responsable de l’analyse du TokenStream, et la fonction impl_hello_macro, qui est responsable de la transformation de l’arbre syntaxique : cela rend l’écriture d’une macro procédurale plus pratique. Le code dans la fonction externe (hello_macro_derive dans ce cas) sera le même pour presque chaque crate de macro procédurale que vous verrez ou créerez. Le code que vous spécifiez dans le corps de la fonction interne (impl_hello_macro dans ce cas) sera différent selon l’objectif de votre macro procédurale.
Nous avons introduit trois nouvelles crates{N}: proc_macro, syn et quote. La crate proc_macro est livrée avec Rust, nous n’avons donc pas eu besoin de l’ajouter aux dépendances dans Cargo.toml. La crate proc_macro est l’API du compilateur qui nous permet de lire et de manipuler du code Rust depuis notre code.
Le crate syn analyse le code Rust depuis une chaîne de caractères vers une structure de données sur laquelle nous pouvons effectuer des opérations. Le crate quote retransforme les structures de données syn en code Rust. Ces crates rendent beaucoup plus simple l’analyse de tout type de code Rust que nous pourrions vouloir traiter : écrire un analyseur complet pour le code Rust n’est pas une tâche simple.
La fonction hello_macro_derive sera appelée lorsqu’un utilisateur de notre bibliothèque spécifie #[derive(HelloMacro)] sur un type. C’est possible car nous avons annoté la fonction hello_macro_derive ici avec proc_macro_derive et spécifié le nom HelloMacro, qui correspond au nom de notre trait ; c’est la convention que la plupart des macros procédurales suivent.
La fonction hello_macro_derive convertit d’abord l’input d’un TokenStream vers une structure de données que nous pouvons ensuite interpréter et sur laquelle nous pouvons effectuer des opérations. C’est là que syn entre en jeu. La fonction parse de syn prend un TokenStream et retourné une structure DeriveInput représentant le code Rust analysé. L’encart 20-41 montre les parties pertinentes de la structure DeriveInput que nous obtenons de l’analyse de la chaîne struct Pancakes;.
DeriveInput {
// --snip--
ident: Ident {
ident: "Pancakes",
span: #0 bytes(95..103)
},
data: Struct(
DataStruct {
struct_token: Struct,
fields: Unit,
semi_token: Some(
Semi
)
}
)
}DeriveInput instance we get when parsing the code that has the macro’s attribute in Listing 20-37Les champs de cette structure montrent que le code Rust que nous avons analysé est une structure unitaire avec l’ident (identifiant, c’est-à-dire le nom) Pancakes. Il y a d’autres champs sur cette structure pour décrire toutes sortes de code Rust ; consultez la [documentation de syn pour DeriveInput][syn-docs] pour plus d’informations.
Bientôt nous définirons la fonction impl_hello_macro, qui est l’endroit où nous construirons le nouveau code Rust que nous voulons inclure. Mais avant cela, notez que la sortie de notre macro derive est aussi un TokenStream. Le TokenStream retourné est ajouté au code que les utilisateurs de notre crate écrivent, donc lorsqu’ils compilent leur crate, ils obtiendront la fonctionnalité supplémentaire que nous fournissons dans le TokenStream modifié.
Vous avez peut-être remarqué que nous appelons unwrap pour faire paniquer la fonction hello_macro_derive si l’appel à la fonction syn::parse échoue ici. Il est nécessaire que notre macro procédurale panique en cas d’erreur car les fonctions proc_macro_derive doivent retourner un TokenStream plutôt qu’un Result pour se conformer à l’API des macros procédurales. Nous avons simplifié cet exemple en utilisant unwrap ; dans du code de production, vous devriez fournir des messages d’erreur plus spécifiques sur ce qui s’est mal passé en utilisant panic! ou expect.
Maintenant que nous avons le code pour transformer le code Rust annoté d’un TokenStream en une instance DeriveInput, générons le code qui implémente le trait HelloMacro sur le type annoté, comme montré dans l’encart 20-42.
use proc_macro::TokenStream;
use quote::quote;
#[proc_macro_derive(HelloMacro)]
pub fn hello_macro_derive(input: TokenStream) -> TokenStream {
// Construct a représentation of Rust code as a syntax tree
// that we can manipulate
let ast = syn::parse(input).unwrap();
// Build the trait implémentation
impl_hello_macro(&ast)
}
fn impl_hello_macro(ast: &syn::DeriveInput) -> TokenStream {
let name = &ast.ident;
let generated = quote! {
impl HelloMacro for #name {
fn hello_macro() {
println!("Hello, Macro! My name is {}!", stringify!(#name));
}
}
};
generated.into()
}HelloMacro trait using the parsed Rust codeNous obtenons une instance de la structure Ident contenant le nom (identifiant) du type annoté en utilisant ast.ident. La structure dans l’encart 20-41 montre que lorsque nous exécutons la fonction impl_hello_macro sur le code de l’encart 20-37, l’ident que nous obtenons aura le champ ident avec une valeur de "Pancakes". Ainsi, la variable name dans l’encart 20-42 contiendra une instance de la structure Ident qui, lorsqu’elle sera affichée, sera la chaîne "Pancakes", le nom de la structure dans l’encart 20-37.
La macro quote! nous permet de définir le code Rust que nous voulons retourner. Le compilateur attend quelque chose de différent du résultat direct de l’exécution de la macro quote!, nous devons donc le convertir en un TokenStream. Nous faisons cela en appelant la méthode into, qui consomme cette représentation intermédiaire et retourné une valeur du type TokenStream requis.
La macro quote! fournit aussi des mécanismes de modèles très pratiques : nous pouvons entrer #name, et quote! le remplacera par la valeur de la variable name. Vous pouvez même faire de la répétition de manière similaire au fonctionnement des macros normales. Consultez [la documentation du crate quote][quote-docs] pour une introduction approfondie.
Nous voulons que notre macro procédurale génère une implémentation de notre trait HelloMacro pour le type que l’utilisateur a annoté, que nous pouvons obtenir en utilisant #name. L’implémentation du trait à une seule fonction hello_macro, dont le corps contient la fonctionnalité que nous voulons fournir : afficher Hello, Macro! My name is suivi du nom du type annoté.
La macro stringify! utilisée ici est intégrée à Rust. Elle prend une expression Rust, comme 1 + 2, et au moment de la compilation transformé l’expression en un littéral de chaîne, comme "1 + 2". C’est différent de format! ou println!, qui sont des macros qui évaluent l’expression puis transforment le résultat en une String. Il est possible que l’entrée #name soit une expression à afficher littéralement, c’est pourquoi nous utilisons stringify!. L’utilisation de stringify! économise aussi une allocation en convertissant #name en un littéral de chaîne au moment de la compilation.
À ce stade, cargo build devrait se terminer avec succès dans hello_macro et hello_macro_derive. Connectons ces crates au code de l’encart 20-37 pour voir la macro procédurale en action ! Créez un nouveau projet binaire dans votre répertoire projects en utilisant cargo new pancakes. Nous devons ajouter hello_macro et hello_macro_derive comme dépendances dans le Cargo.toml du crate pancakes. Si vous publiez vos versions de hello_macro et hello_macro_derive sur crates.io, ce seraient des dépendances normales ; sinon, vous pouvez les spécifier comme dépendances path comme suit : toml {{#include ../listings/ch20-advanced-features/no-listing-21-pancakes/pancakes/Cargo.toml:6:8}}
[dependencies]
hello_macro = { path = "../hello_macro" }
hello_macro_derive = { path = "../hello_macro/hello_macro_derive" }
Placez le code de l’encart 20-37 dans src/main.rs et exécutez cargo run : il devrait afficher Hello, Macro! My name is Pancakes!. L’implémentation du trait HelloMacro par la macro procédurale a été incluse sans que le crate pancakes n’ait besoin de l’implémenter ; le #[derive(HelloMacro)] a ajouté l’implémentation du trait.
Ensuite, explorons en quoi les autres types de macros procédurales diffèrent des macros derive personnalisées.
Les macros de type attribut
Les macros de type attribut sont similaires aux macros derive personnalisées, mais au lieu de générer du code pour l’attribut derive, elles vous permettent de créer de nouveaux attributs. Elles sont aussi plus flexibles : derive ne fonctionne que pour les structures et les enums ; les attributs peuvent être appliqués à d’autres éléments aussi, comme les fonctions. Voici un exemple d’utilisation d’une macro de type attribut. Imaginons que vous ayez un attribut nommé route qui annote des fonctions lors de l’utilisation d’un framework d’application web :
#[route(GET, "/")]
fn index() {Cet attribut #[route] serait défini par le framework comme une macro procédurale. La signature de la fonction de définition de la macro ressemblerait à ceci :
#[proc_macro_attribute]
pub fn route(attr: TokenStream, item: TokenStream) -> TokenStream {Ici, nous avons deux paramètres de type TokenStream. Le premier est pour le contenu de l’attribut : la partie GET, "/". Le second est le corps de l’élément auquel l’attribut est attaché : dans ce cas, fn index() {} et le reste du corps de la fonction.
À part cela, les macros de type attribut fonctionnent de la même manière que les macros derive personnalisées : vous créez un crate avec le type de crate proc-macro et implémentez une fonction qui génère le code que vous voulez !
Les macros de type fonction
Les macros de type fonction définissent des macros qui ressemblent à des appels de fonction. Comme les macros macro_rules!, elles sont plus flexibles que les fonctions ; par exemple, elles peuvent prendre un nombre inconnu d’arguments. Cependant, les macros macro_rules! ne peuvent être définies qu’en utilisant la syntaxe de type match que nous avons discutée dans la section [“Les macros déclaratives pour la métaprogrammation générale”][decl] plus tôt. Les macros de type fonction prennent un paramètre TokenStream, et leur définition manipule ce TokenStream en utilisant du code Rust comme le font les deux autres types de macros procédurales. Un exemple de macro de type fonction est une macro sql! qui pourrait être appelée comme suit :
let sql = sql!(SELECT * FROM posts WHERE id=1);Cette macro analyserait l’instruction SQL à l’intérieur et vérifierait qu’elle est syntaxiquement correcte, ce qui est un traitement beaucoup plus complexe que ce qu’une macro macro_rules! peut faire. La macro sql! serait définie comme ceci :
#[proc_macro]
pub fn sql(input: TokenStream) -> TokenStream {Cette définition est similaire à la signature de la macro derive personnalisée : nous recevons les tokens qui sont à l’intérieur des parenthèses et retournons le code que nous voulions générer.
Résumé
Ouf ! Vous avez maintenant quelques fonctionnalités Rust dans votre boîte à outils que vous n’utiliserez probablement pas souvent, mais vous saurez qu’elles sont disponibles dans des circonstances très particulières. Nous avons introduit plusieurs sujets complexes afin que lorsque vous les rencontrez dans les suggestions de messages d’erreur ou dans le code d’autres personnes, vous puissiez reconnaître ces concepts et cette syntaxe. Utilisez ce chapitre comme référence pour vous guider vers des solutions.
Ensuite, nous mettrons en pratique tout ce que nous avons discuté tout au long du livre et réaliserons un dernier projet !
Projet final : construire un serveur web multitâche
Ce fut un long voyage, mais nous avons atteint la fin du livre. Dans ce chapitre, nous allons construire un dernier projet ensemble pour illustrer certains des concepts que nous avons abordés dans les derniers chapitres, ainsi que pour récapituler certaines leçons précédentes.
Pour notre projet final, nous allons créer un serveur web qui affiche “Hello!” et ressemble à la Figure 21-1 dans un navigateur web.
Voici notre plan pour construire le serveur web :
- Apprendre un peu sur TCP et HTTP.
- Écouter les connexions TCP sur un socket.
- Analyser un petit nombre de requêtes HTTP.
- Créer une réponse HTTP correcte.
- Améliorer le débit de notre serveur avec un groupe de threads (thread pool).
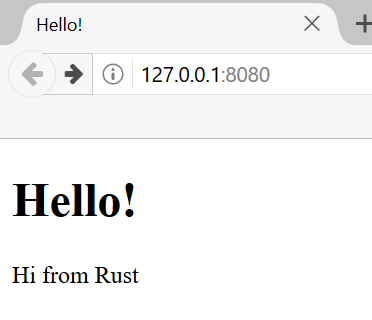
Figure 21-1 : Notre dernier projet partagé
Avant de commencer, nous devons mentionner deux détails. Premièrement, la méthode que nous utiliserons ne sera pas la meilleure façon de construire un serveur web avec Rust. Des membres de la communauté ont publié un certain nombre de crates prêtes pour la production, disponibles sur crates.io, qui fournissent des implémentations de serveur web et de groupe de threads plus complètes que ce que nous allons construire. Cependant, notre intention dans ce chapitre est de vous aider à apprendre, pas de prendre le chemin le plus facile. Comme Rust est un langage de programmation système, nous pouvons choisir le niveau d’abstraction avec lequel nous voulons travailler et descendre à un niveau plus bas que ce qui est possible ou pratique dans d’autres langages.
Deuxièmement, nous n’utiliserons pas async et await ici. Construire un groupe de threads est déjà un défi suffisamment important en soi, sans y ajouter la construction d’un runtime async ! Cependant, nous noterons comment async et await pourraient s’appliquer à certains des mêmes problèmes que nous verrons dans ce chapitre. En fin de compte, comme nous l’avons noté au chapitre 17, de nombreux runtimes async utilisent des groupes de threads pour gérer leur travail.
Nous allons donc écrire le serveur HTTP basique et le groupe de threads manuellement afin que vous puissiez apprendre les idées générales et les techniques derrière les crates que vous pourriez utiliser à l’avenir.
Construire un serveur web monotâche
Construire un serveur web monotâche
Nous allons commencer par faire fonctionner un serveur web monothread. Avant de commencer, examinons un rapide aperçu des protocoles impliqués dans la construction de serveurs web. Les détails de ces protocoles dépassent le cadre de ce livre, mais un bref aperçu vous donnera les informations dont vous avez besoin.
Les deux principaux protocoles impliqués dans les serveurs web sont le Hypertext Transfer Protocol (HTTP) et le Transmission Control Protocol (TCP). Ces deux protocoles sont des protocoles de type requête-réponse, ce qui signifie qu’un client initie des requêtes et qu’un serveur écoute les requêtes et fournit une réponse au client. Le contenu de ces requêtes et réponses est défini par les protocoles.
TCP est le protocole de plus bas niveau qui décrit les détails de la façon dont l’information circule d’un serveur à un autre, mais ne spécifie pas ce qu’est cette information. HTTP s’appuie sur TCP en définissant le contenu des requêtes et des réponses. Il est techniquement possible d’utiliser HTTP avec d’autres protocoles, mais dans la grande majorité des cas, HTTP envoie ses données via TCP. Nous allons travailler avec les octets bruts des requêtes et réponses TCP et HTTP.
Écouter la connexion TCP
Notre serveur web doit écouter une connexion TCP, c’est donc la première partie sur laquelle nous allons travailler. La bibliothèque standard offre un module std::net qui nous permet de faire cela. Créons un nouveau projet de la manière habituelle :
$ cargo new hello
Created binary (application) `hello` project
$ cd hello
Maintenant, entrez le code de l’encart 21-1 dans src/main.rs pour commencer. Ce code écoutera à l’adresse locale 127.0.0.1:7878 les flux TCP entrants. Quand il recevra un flux entrant, il affichera Connection established!.
use std::net::TcpListener;
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
println!("Connection established!");
}
}En utilisant TcpListener, nous pouvons écouter les connexions TCP à l’adresse 127.0.0.1:7878. Dans l’adresse, la partie avant les deux-points est une adresse IP représentant votre ordinateur (c’est la même sur tous les ordinateurs et ne représente pas spécifiquement l’ordinateur des auteurs), et 7878 est le port. Nous avons choisi ce port pour deux raisons : HTTP n’est normalement pas accepté sur ce port, donc notre serveur a peu de chances d’entrer en conflit avec un autre serveur web que vous pourriez avoir en fonctionnement sur votre machine, et 7878 correspond à rust tapé sur un téléphone.
La fonction bind dans ce scénario fonctionne comme la fonction new en ce qu’elle retourné une nouvelle instance de TcpListener. La fonction s’appelle bind parce que, en réseau, se connecter à un port pour l’écouter est connu sous le nom de « liaison à un port » (binding).
La fonction bind retourné un Result<T, E>, ce qui indique qu’il est possible que la liaison échoue, par exemple si nous exécutions deux instances de notre programme et avions donc deux programmes écoutant sur le même port. Comme nous écrivons un serveur basique uniquement à des fins d’apprentissage, nous ne nous soucierons pas de gérer ce type d’erreurs ; à la place, nous utilisons unwrap pour arrêter le programme si des erreurs surviennent.
La méthode incoming sur TcpListener retourné un itérateur qui nous donne une séquence de flux (plus précisément, des flux de type TcpStream). Un seul flux (stream) représente une connexion ouverte entre le client et le serveur. Connexion est le nom du processus complet de requête et réponse dans lequel un client se connecte au serveur, le serveur génère une réponse, et le serveur ferme la connexion. Ainsi, nous lirons depuis le TcpStream pour voir ce que le client a envoyé, puis nous écrirons notre réponse dans le flux pour renvoyer des données au client. Globalement, cette boucle for traitera chaque connexion à tour de rôle et produira une série de flux à gérer.
Pour l’instant, notre gestion du flux consiste à appeler unwrap pour terminer notre programme si le flux à des erreurs ; s’il n’y a pas d’erreurs, le programme affiche un message. Nous ajouterons plus de fonctionnalités pour le cas de succès dans le prochain encart. La raison pour laquelle nous pourrions recevoir des erreurs de la méthode incoming quand un client se connecte au serveur est que nous n’itérons pas réellement sur des connexions. Au lieu de cela, nous itérons sur des tentatives de connexion. La connexion pourrait ne pas réussir pour plusieurs raisons, dont beaucoup sont spécifiques au système d’exploitation. Par exemple, de nombreux systèmes d’exploitation ont une limite au nombre de connexions ouvertes simultanées qu’ils peuvent prendre en charge ; les nouvelles tentatives de connexion au-delà de ce nombre produiront une erreur jusqu’à ce que certaines des connexions ouvertes soient fermées.
Essayons d’exécuter ce code ! Lancez cargo run dans le terminal puis chargez 127.0.0.1:7878 dans un navigateur web. Le navigateur devrait afficher un message d’erreur comme « Connection reset » car le serveur ne renvoie actuellement aucune donnée. Mais quand vous regardez votre terminal, vous devriez voir plusieurs messages qui ont été affichés quand le navigateur s’est connecté au serveur !
Running `target/debug/hello`
Connection established!
Connection established!
Connection established!
Parfois, vous verrez plusieurs messages affichés pour une seule requête du navigateur ; la raison pourrait être que le navigateur fait une requête pour la page ainsi qu’une requête pour d’autres ressources, comme l’icône favicon.ico qui apparaît dans l’onglet du navigateur.
Il se pourrait aussi que le navigateur essaie de se connecter au serveur plusieurs fois parce que le serveur ne répond avec aucune donnée. Quand stream sort de la portée et est libéré à la fin de la boucle, la connexion est fermée dans le cadre de l’implémentation de drop. Les navigateurs gèrent parfois les connexions fermées en réessayant, car le problème pourrait être temporaire.
Les navigateurs ouvrent aussi parfois plusieurs connexions au serveur sans envoyer de requêtes afin que s’ils envoient effectivement des requêtes plus tard, celles-ci puissent être traitées plus rapidement. Quand cela se produit, notre serveur verra chaque connexion, qu’il y ait ou non des requêtes sur cette connexion. De nombreuses versions de navigateurs basés sur Chrome font cela, par exemple ; vous pouvez désactiver cette optimisation en utilisant le mode de navigation privée ou en utilisant un autre navigateur.
Le point important est que nous avons réussi à obtenir un handle vers une connexion TCP !
N’oubliez pas d’arrêter le programme en appuyant sur ctrl-C quand vous avez fini d’exécuter une version particulière du code. Ensuite, redémarrez le programme en invoquant la commande cargo run après avoir effectué chaque ensemble de modifications du code pour vous assurer que vous exécutez le code le plus récent.
Lire la requête
Implémentons la fonctionnalité pour lire la requête depuis le navigateur ! Pour séparer les préoccupations entre d’abord obtenir une connexion et ensuite effectuer une action avec la connexion, nous allons créer une nouvelle fonction pour traiter les connexions. Dans cette nouvelle fonction handle_connection, nous lirons les données du flux TCP et les afficherons pour que nous puissions voir les données envoyées par le navigateur. Modifiez le code pour qu’il ressemble à l’encart 21-2.
use std::{
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
println!("Request: {http_request:#?}");
}TcpStream and printing the dataNous importons std::io::BufReader et std::io::prelude dans la portée pour accéder aux traits et types qui nous permettent de lire et d’écrire dans le flux. Dans la boucle for de la fonction main, au lieu d’afficher un message disant que nous avons établi une connexion, nous appelons maintenant la nouvelle fonction handle_connection et lui passons le stream.
Dans la fonction handle_connection, nous créons une nouvelle instance de BufReader qui enveloppe une référence au stream. Le BufReader ajouté une mise en tampon en gérant les appels aux méthodes du trait std::io::Read pour nous.
Nous créons une variable nommée http_request pour collecter les lignes de la requête que le navigateur envoie à notre serveur. Nous indiquons que nous voulons collecter ces lignes dans un vecteur en ajoutant l’annotation de type Vec<_>.
BufReader implémente le trait std::io::BufRead, qui fournit la méthode lines. La méthode lines retourné un itérateur de Result<String, std::io::Error> en découpant le flux de données chaque fois qu’elle rencontre un octet de retour à la ligne. Pour obtenir chaque String, nous appliquons map et unwrap sur chaque Result. Le Result pourrait être une erreur si les données ne sont pas du UTF-8 valide ou s’il y a eu un problème de lecture depuis le flux. Encore une fois, un programme en production devrait gérer ces erreurs plus élégamment, mais nous choisissons d’arrêter le programme en cas d’erreur par souci de simplicité.
Le navigateur signale la fin d’une requête HTTP en envoyant deux caractères de retour à la ligne consécutifs, donc pour obtenir une requête depuis le flux, nous prenons des lignes jusqu’à obtenir une ligne qui est la chaîne vide. Une fois que nous avons collecté les lignes dans le vecteur, nous les affichons en utilisant le formatage de débogage élégant pour que nous puissions examiner les instructions que le navigateur web envoie à notre serveur.
Essayons ce code ! Démarrez le programme et faites une requête dans un navigateur web à nouveau. Notez que nous obtiendrons toujours une page d’erreur dans le navigateur, mais la sortie de notre programme dans le terminal ressemblera maintenant à ceci :
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.42s
Running `target/debug/hello`
Request: [
"GET / HTTP/1.1",
"Host: 127.0.0.1:7878",
"User-Agent: Mozilla/5.0 (Macintosh; Intel Mac OS X 10.15; rv:99.0) Gecko/20100101 Firefox/99.0",
"Accept: text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
"Accept-Language: en-US,en;q=0.5",
"Accept-Encoding: gzip, deflate, br",
"DNT: 1",
"Connection: keep-alive",
"Upgrade-Insecure-Requests: 1",
"Sec-Fetch-Dest: document",
"Sec-Fetch-Mode: navigate",
"Sec-Fetch-Site: none",
"Sec-Fetch-User: ?1",
"Cache-Control: max-age=0",
]
Selon votre navigateur, vous pourriez obtenir une sortie légèrement différente. Maintenant que nous affichons les données de la requête, nous pouvons voir pourquoi nous obtenons plusieurs connexions à partir d’une seule requête du navigateur en regardant le chemin après GET dans la première ligne de la requête. Si les connexions répétées demandent toutes /, nous savons que le navigateur essaie de récupérer / de manière répétée parce qu’il ne reçoit pas de réponse de notre programme.
Décomposons ces données de requête pour comprendre ce que le navigateur demande à notre programme.
Examiner de plus près une requête HTTP
HTTP est un protocole basé sur le texte, et une requête prend ce format :
Method Request-URI HTTP-Version CRLF
headers CRLF
message-body
La première ligne est la ligne de requête qui contient les informations sur ce que le client demande. La première partie de la ligne de requête indique la méthode utilisée, comme GET ou POST, qui décrit comment le client fait cette requête. Notre client a utilisé une requête GET, ce qui signifie qu’il demande des informations.
La partie suivante de la ligne de requête est /, qui indique l’identifiant de ressource uniforme (URI) que le client demande : un URI est presque, mais pas tout à fait, la même chose qu’un localisateur de ressource uniforme (URL). La différence entre les URI et les URL n’est pas importante pour nos besoins dans ce chapitre, mais la spécification HTTP utilise le terme URI, donc nous pouvons simplement substituer mentalement URL à URI ici.
La dernière partie est la version HTTP que le client utilise, puis la ligne de requête se terminé par une séquence CRLF. (CRLF signifie carriage return (retour chariot) et line feed (saut de ligne), qui sont des termes issus de l’époque des machines à écrire !) La séquence CRLF peut aussi s’écrire \r , où \r est un retour chariot et est un saut de ligne. La séquence CRLF sépare la ligne de requête du reste des données de la requête. Notez que quand le CRLF est affiché, nous voyons un nouveau retour à la ligne plutôt que \r .
En regardant les données de la ligne de requête que nous avons reçues en exécutant notre programme jusqu’à présent, nous voyons que GET est la méthode, / est l’URI de la requête, et HTTP/1.1 est la version.
Après la ligne de requête, les lignes restantes à partir de Host: sont les en-têtes. Les requêtes GET n’ont pas de corps.
Essayez de faire une requête depuis un autre navigateur ou de demander une adresse différente, comme 127.0.0.1:7878/test, pour voir comment les données de la requête changent.
Maintenant que nous savons ce que le navigateur demande, renvoyons-lui quelques données !
Écrire une réponse
Nous allons implémenter l’envoi de données en réponse à une requête client. Les réponses ont le format suivant :
HTTP-Version Status-Code Reason-Phrase CRLF
headers CRLF
message-body
La première ligne est une ligne de statut qui contient la version HTTP utilisée dans la réponse, un code de statut numérique qui résume le résultat de la requête, et une phrase de raison qui fournit une description textuelle du code de statut. Après la séquence CRLF se trouvent les en-têtes, une autre séquence CRLF, et le corps de la réponse.
Voici un exemple de réponse qui utilise la version HTTP 1.1 et à un code de statut 200, une phrase de raison OK, pas d’en-têtes et pas de corps :
HTTP/1.1 200 OK\r\n\r\n
Le code de statut 200 est la réponse de succès standard. Le texte est une toute petite réponse HTTP réussie. Écrivons cela dans le flux comme notre réponse à une requête réussie ! Depuis la fonction handle_connection, supprimez le println! qui affichait les données de la requête et remplacez-le par le code de l’encart 21-3.
use std::{
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let response = "HTTP/1.1 200 OK\r
\r
";
stream.write_all(response.as_bytes()).unwrap();
}La première nouvelle ligne définit la variable response qui contient les données du message de succès. Ensuite, nous appelons as_bytes sur notre response pour convertir les données de la chaîne en octets. La méthode write_all sur stream prend un &[u8] et envoie ces octets directement à travers la connexion. Comme l’opération write_all pourrait échouer, nous utilisons unwrap sur tout résultat d’erreur comme précédemment. Encore une fois, dans une application réelle, vous ajouteriez la gestion des erreurs ici.
Avec ces changements, exécutons notre code et faisons une requête. Nous n’affichons plus aucune donnée dans le terminal, donc nous ne verrons aucune sortie autre que celle de Cargo. Quand vous chargez 127.0.0.1:7878 dans un navigateur web, vous devriez obtenir une page vierge au lieu d’une erreur. Vous venez de coder à la main la réception d’une requête HTTP et l’envoi d’une réponse !
Renvoyer du vrai HTML
Implémentons la fonctionnalité pour renvoyer plus qu’une page vierge. Créez le nouveau fichier hello.html à la racine du répertoire de votre projet, pas dans le répertoire src. Vous pouvez saisir le HTML que vous voulez ; l’encart 21-4 montre une possibilité.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Hello!</h1>
<p>Hi from Rust</p>
</body>
</html>
C’est un document HTML5 minimal avec un titre et du texte. Pour le renvoyer depuis le serveur quand une requête est reçue, nous allons modifier handle_connection comme montré dans l’encart 21-5 pour lire le fichier HTML, l’ajouter à la réponse comme corps, et l’envoyer.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
// --snip--
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let http_request: Vec<_> = buf_reader
.lines()
.map(|result| result.unwrap())
.take_while(|line| !line.is_empty())
.collect();
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response =
format!("{status_line}\r
Content-Length: {length}\r
\r
{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Nous avons ajouté fs à l’instruction use pour importer le module de système de fichiers de la bibliothèque standard dans la portée. Le code pour lire le contenu d’un fichier dans une chaîne devrait vous sembler familier ; nous l’avons utilisé quand nous avons lu le contenu d’un fichier pour notre projet d’E/S dans l’encart 12-4.
Ensuite, nous utilisons format! pour ajouter le contenu du fichier comme corps de la réponse de succès. Pour garantir une réponse HTTP valide, nous ajoutons l’en-tête Content-Length, qui est défini à la taille du corps de notre réponse – dans ce cas, la taille de hello.html.
Exécutez ce code avec cargo run et chargez 127.0.0.1:7878 dans votre navigateur ; vous devriez voir votre HTML affiché !
Actuellement, nous ignorons les données de la requête dans http_request et renvoyons simplement le contenu du fichier HTML de manière inconditionnelle. Cela signifie que si vous essayez de demander 127.0.0.1:7878/something-else dans votre navigateur, vous obtiendrez toujours la même réponse HTML. Pour le moment, notre serveur est très limité et ne fait pas ce que font la plupart des serveurs web. Nous voulons personnaliser nos réponses en fonction de la requête et ne renvoyer le fichier HTML que pour une requête bien formée vers /.
Valider la requête et répondre de manière sélective
Pour l’instant, notre serveur web renverra le HTML du fichier peu importe ce que le client a demandé. Ajoutons une fonctionnalité pour vérifier que le navigateur demande / avant de renvoyer le fichier HTML et pour renvoyer une erreur si le navigateur demande autre chose. Pour cela, nous devons modifier handle_connection, comme montré dans l’encart 21-6. Ce nouveau code vérifie le contenu de la requête reçue par rapport à ce que nous savons être une requête pour / et ajouté des blocs if et else pour traiter les requêtes différemment.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
// --snip--
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
if request_line == "GET / HTTP/1.1" {
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r
Content-Length: {length}\r
\r
{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
} else {
// some other request
}
}Nous n’allons examiner que la première ligne de la requête HTTP, donc plutôt que de lire la requête entière dans un vecteur, nous appelons next pour obtenir le premier élément de l’itérateur. Le premier unwrap gère l’Option et arrête le programme si l’itérateur n’a pas d’éléments. Le second unwrap gère le Result et à le même effet que le unwrap qui était dans le map ajouté dans l’encart 21-2.
Ensuite, nous vérifions la request_line pour voir si elle correspond à la ligne de requête d’une requête GET vers le chemin /. Si c’est le cas, le bloc if renvoie le contenu de notre fichier HTML.
Si la request_line ne correspond pas à la requête GET vers le chemin /, cela signifie que nous avons reçu une autre requête. Nous ajouterons du code au bloc else dans un instant pour répondre à toutes les autres requêtes.
Exécutez ce code maintenant et demandez 127.0.0.1:7878 ; vous devriez obtenir le HTML de hello.html. Si vous faites une autre requête, comme 127.0.0.1:7878/something-else, vous obtiendrez une erreur de connexion comme celles que vous avez vues en exécutant le code des encarts 21-1 et 21-2.
Maintenant, ajoutons le code de l’encart 21-7 au bloc else pour renvoyer une réponse avec le code de statut 404, qui signale que le contenu de la requête n’a pas été trouvé. Nous renverrons aussi du HTML pour une page à afficher dans le navigateur indiquant la réponse à l’utilisateur final.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
if request_line == "GET / HTTP/1.1" {
let status_line = "HTTP/1.1 200 OK";
let contents = fs::read_to_string("hello.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r
Content-Length: {length}\r
\r
{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
// --snip--
} else {
let status_line = "HTTP/1.1 404 NOT FOUND";
let contents = fs::read_to_string("404.html").unwrap();
let length = contents.len();
let response = format!(
"{status_line}\r
Content-Length: {length}\r
\r
{contents}"
);
stream.write_all(response.as_bytes()).unwrap();
}
}Ici, notre réponse à une ligne de statut avec le code de statut 404 et la phrase de raison NOT FOUND. Le corps de la réponse sera le HTML du fichier 404.html. Vous devrez créer un fichier 404.html à côté de hello.html pour la page d’erreur ; encore une fois, n’hésitez pas à utiliser le HTML que vous voulez, ou utilisez l’exemple de HTML de l’encart 21-8.
<!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8">
<title>Hello!</title>
</head>
<body>
<h1>Oops!</h1>
<p>Sorry, I don't know what you're asking for.</p>
</body>
</html>
Avec ces changements, relancez votre serveur. Demander 127.0.0.1:7878 devrait renvoyer le contenu de hello.html, et toute autre requête, comme 127.0.0.1:7878/foo, devrait renvoyer le HTML d’erreur de 404.html.
Refactorisation
Pour le moment, les blocs if et else ont beaucoup de répétitions : ils lisent tous les deux des fichiers et écrivent le contenu des fichiers dans le flux. Les seules différences sont la ligne de statut et le nom du fichier. Rendons le code plus concis en extrayant ces différences dans des lignes if et else séparées qui assigneront les valeurs de la ligne de statut et du nom de fichier à des variables ; nous pourrons ensuite utiliser ces variables de manière inconditionnelle dans le code pour lire le fichier et écrire la réponse. L’encart 21-9 montre le code résultant après le remplacement des gros blocs if et else.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
// --snip--
fn handle_connection(mut stream: TcpStream) {
// --snip--
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = if request_line == "GET / HTTP/1.1" {
("HTTP/1.1 200 OK", "hello.html")
} else {
("HTTP/1.1 404 NOT FOUND", "404.html")
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r
Content-Length: {length}\r
\r
{contents}");
stream.write_all(response.as_bytes()).unwrap();
}if and else blocks to contain only the code that differs between the two casesMaintenant, les blocs if et else ne renvoient que les valeurs appropriées pour la ligne de statut et le nom de fichier dans un tuple ; nous utilisons ensuite la déstructuration pour assigner ces deux valeurs à status_line et filename en utilisant un motif dans l’instruction let, comme discuté au chapitre 19.
Le code précédemment dupliqué est maintenant en dehors des blocs if et else et utilise les variables status_line et filename. Cela rend plus facile de voir la différence entre les deux cas, et cela signifie que nous n’avons qu’un seul endroit où mettre à jour le code si nous voulons changer la façon dont la lecture du fichier et l’écriture de la réponse fonctionnent. Le comportement du code de l’encart 21-9 sera le même que celui de l’encart 21-7.
Formidable ! Nous avons maintenant un serveur web simple en environ 40 lignes de code Rust qui répond à une requête avec une page de contenu et répond à toutes les autres requêtes avec une réponse 404.
Actuellement, notre serveur fonctionne dans un seul thread, ce qui signifie qu’il ne peut traiter qu’une seule requête à la fois. Examinons comment cela peut poser problème en simulant des requêtes lentes. Ensuite, nous le corrigerons pour que notre serveur puisse gérer plusieurs requêtes à la fois.
Du serveur monotâche au serveur multitâche
D’un serveur monothread à un serveur multithreadé
Pour l’instant, le serveur traitera chaque requête à tour de rôle, ce qui signifie qu’il ne traitera pas une deuxième connexion tant que la première connexion n’aura pas fini d’être traitée. Si le serveur recevait de plus en plus de requêtes, cette exécution séquentielle serait de moins en moins optimale. Si le serveur reçoit une requête qui prend beaucoup de temps à traiter, les requêtes suivantes devront attendre que la longue requête soit terminée, même si les nouvelles requêtes peuvent être traitées rapidement. Nous devons corriger cela, mais d’abord nous allons observer le problème en action.
Simuler une requête lente
Nous allons voir comment une requête traitée lentement peut affecter les autres requêtes faites à notre implémentation actuelle du serveur. L’encart 21-10 implémente la gestion d’une requête vers /sleep avec une réponse lente simulée qui fera dormir le serveur pendant cinq secondes avant de répondre.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
// --snip--
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
handle_connection(stream);
}
}
fn handle_connection(mut stream: TcpStream) {
// --snip--
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
// --snip--
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r
Content-Length: {length}\r
\r
{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Nous sommes passés de if à match maintenant que nous avons trois cas. Nous devons faire correspondre explicitement sur une slice de request_line pour faire du pattern matching avec les valeurs littérales de chaîne ; match ne fait pas de référencement et déréférencement automatique, contrairement à la méthode d’égalité.
Le premier bras est le même que le bloc if de l’encart 21-9. Le deuxième bras correspond à une requête vers /sleep. Quand cette requête est reçue, le serveur dormira pendant cinq secondes avant d’afficher la page HTML de succès. Le troisième bras est le même que le bloc else de l’encart 21-9.
Vous pouvez voir à quel point notre serveur est primitif : de vraies bibliothèques géreraient la reconnaissance de multiples requêtes de manière bien moins verbeuse !
Démarrez le serveur en utilisant cargo run. Ensuite, ouvrez deux fenêtres de navigateur : une pour http://127.0.0.1:7878 et l’autre pour http://127.0.0.1:7878/sleep. Si vous entrez l’URI / quelques fois, comme avant, vous verrez qu’il répond rapidement. Mais si vous entrez /sleep puis chargez /, vous verrez que / attend que sleep ait dormi pendant ses cinq secondes complètes avant de se charger.
Il existe plusieurs techniques que nous pourrions utiliser pour éviter que les requêtes ne s’accumulent derrière une requête lente, notamment l’utilisation d’async comme nous l’avons fait au chapitre 17 ; celle que nous allons implémenter est un groupe de threads (thread pool).
Améliorer le débit avec un groupe de threads
Un thread pool (groupe de threads) est un groupe de threads créés qui sont prêts et en attente de traiter une tâche. Quand le programme reçoit une nouvelle tâche, il assigne l’un des threads du pool à la tâche, et ce thread traitera la tâche. Les threads restants dans le pool sont disponibles pour gérer toute autre tâche qui arrive pendant que le premier thread est en cours de traitement. Quand le premier thread a terminé de traiter sa tâche, il est renvoyé dans le pool de threads inactifs, prêt à traiter une nouvelle tâche. Un thread pool vous permet de traiter des connexions de manière concurrente, augmentant le débit de votre serveur.
Nous limiterons le nombre de threads dans le pool à un petit nombre pour nous protéger des attaques DoS ; si notre programme créait un nouveau thread pour chaque requête entrante, quelqu’un faisant 10 millions de requêtes à notre serveur pourrait semer le chaos en épuisant toutes les ressources de notre serveur et en paralysant le traitement des requêtes.
Plutôt que de créer un nombre illimité de threads, nous aurons donc un nombre fixe de threads en attente dans le pool. Les requêtes entrantes sont envoyées au pool pour traitement. Le pool maintiendra une file d’attente de requêtes entrantes. Chaque thread du pool retirera une requête de cette file, traitera la requête, puis demandera une autre requête à la file. Avec cette conception, nous pouvons traiter jusqu’à N requêtes de manière concurrente, où N est le nombre de threads. Si chaque thread répond à une requête de longue durée, les requêtes suivantes peuvent toujours s’accumuler dans la file, mais nous avons augmenté le nombre de requêtes de longue durée que nous pouvons gérer avant d’atteindre ce point.
Cette technique n’est qu’un des nombreux moyens d’améliorer le débit d’un serveur web. D’autres options que vous pourriez explorer sont le modèle fork/join, le modèle d’E/S async monothread et le modèle d’E/S async multithreadé. Si ce sujet vous intéresse, vous pouvez en lire davantage sur les autres solutions et essayer de les implémenter ; avec un langage de bas niveau comme Rust, toutes ces options sont possibles.
Avant de commencer à implémenter un thread pool, parlons de ce à quoi l’utilisation du pool devrait ressembler. Quand vous essayez de concevoir du code, écrire l’interface client en premier peut aider à guider votre conception. Écrivez l’API du code de sorte qu’elle soit structurée de la manière dont vous voulez l’appeler ; ensuite, implémentez la fonctionnalité au sein de cette structure plutôt que d’implémenter la fonctionnalité puis de concevoir l’API publique.
De manière similaire à la façon dont nous avons utilisé le développement piloté par les tests dans le projet du chapitre 12, nous utiliserons ici le développement piloté par le compilateur. Nous écrirons le code qui appelle les fonctions que nous voulons, puis nous examinerons les erreurs du compilateur pour déterminer ce que nous devons changer ensuite pour que le code fonctionne. Avant de faire cela, cependant, nous explorerons la technique que nous n’allons pas utiliser comme point de départ.
Créer un thread pour chaque requête
D’abord, explorons à quoi notre code pourrait ressembler s’il créait un nouveau thread pour chaque connexion. Comme mentionné précédemment, ce n’est pas notre plan final en raison des problèmes liés à la création potentiellement illimitée de threads, mais c’est un point de départ pour obtenir d’abord un serveur multithreadé fonctionnel. Ensuite, nous ajouterons le thread pool comme amélioration, et comparer les deux solutions sera plus facile.
L’encart 21-11 montre les modifications à apporter à main pour créer un nouveau thread afin de gérer chaque flux dans la boucle for.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
for stream in listener.incoming() {
let stream = stream.unwrap();
thread::spawn(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r
Content-Length: {length}\r
\r
{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Comme vous l’avez appris au chapitre 16, thread::spawn créera un nouveau thread puis exécutera le code de la closure dans le nouveau thread. Si vous exécutez ce code et chargez /sleep dans votre navigateur, puis / dans deux autres onglets du navigateur, vous verrez effectivement que les requêtes vers / n’ont pas besoin d’attendre que /sleep se terminé. Cependant, comme nous l’avons mentionné, cela finira par submerger le système car vous créeriez de nouveaux threads sans aucune limite.
Vous vous souvenez peut-être aussi du chapitre 17 que c’est exactement le type de situation où async et await brillent vraiment ! Gardez cela à l’esprit pendant que nous construisons le thread pool et réfléchissez à ce qui serait différent ou identique avec async.
Créer un nombre fini de threads
Nous voulons que notre thread pool fonctionne de manière similaire et familière afin que passer des threads à un thread pool ne nécessite pas de grands changements dans le code qui utilise notre API. L’encart 21-12 montre l’interface hypothétique d’une structure ThreadPool que nous voulons utiliser à la place de thread::spawn.
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r
Content-Length: {length}\r
\r
{contents}");
stream.write_all(response.as_bytes()).unwrap();
}ThreadPool interfaceNous utilisons ThreadPool::new pour créer un nouveau thread pool avec un nombre configurable de threads, dans ce cas quatre. Ensuite, dans la boucle for, pool.execute à une interface similaire à thread::spawn en ce qu’il prend une closure que le pool devrait exécuter pour chaque flux. Nous devons implémenter pool.execute de sorte qu’il prenne la closure et la donne à un thread du pool pour l’exécuter. Ce code ne compilera pas encore, mais nous allons essayer pour que le compilateur puisse nous guider dans la correction.
Construire ThreadPool en utilisant le développement piloté par le compilateur
Effectuez les modifications de l’encart 21-12 dans src/main.rs, puis utilisons les erreurs du compilateur de cargo check pour piloter notre développement. Voici la première erreur que nous obtenons : console {{#include ../listings/ch21-web-server/listing-21-12/output.txt}}
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0433]: failed to resolve: use of undeclared type `ThreadPool`
--> src/main.rs:11:16
|
11 | let pool = ThreadPool::new(4);
| ^^^^^^^^^^ use of undeclared type `ThreadPool`
For more information about this error, try `rustc --explain E0433`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Parfait ! Cette erreur nous dit que nous avons besoin d’un type ou module ThreadPool, donc nous allons en construire un maintenant. Notre implémentation de ThreadPool sera indépendante du type de travail que notre serveur web effectue. Donc, transformons le crate hello d’un crate binaire en un crate de bibliothèque pour héberger notre implémentation de ThreadPool. Après être passé à un crate de bibliothèque, nous pourrons aussi utiliser la bibliothèque de thread pool séparée pour tout travail que nous voulons faire en utilisant un thread pool, pas seulement pour servir des requêtes web.
Créez un fichier src/lib.rs qui contient ce qui suit, qui est la définition la plus simple d’une structure ThreadPool que nous puissions avoir pour le moment :
pub struct ThreadPool;Ensuite, modifiez le fichier main.rs pour importer ThreadPool dans la portée depuis le crate de bibliothèque en ajoutant le code suivant en haut de src/main.rs :
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming() {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r
Content-Length: {length}\r
\r
{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Ce code ne fonctionnera toujours pas, mais vérifions-le à nouveau pour obtenir la prochaine erreur que nous devons traiter : console {{#include ../listings/ch21-web-server/no-listing-01-define-threadpool-struct/output.txt}}
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no function or associated item named `new` found for struct `ThreadPool` in the current scope
--> src/main.rs:12:28
|
12 | let pool = ThreadPool::new(4);
| ^^^ function or associated item not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Cette erreur indique qu’ensuite nous devons créer une fonction associée nommée new pour ThreadPool. Nous savons aussi que new doit avoir un paramètre qui peut accepter 4 comme argument et devrait retourner une instance de ThreadPool. Implémentons la fonction new la plus simple qui aura ces caractéristiques :
pub struct ThreadPool;
impl ThreadPool {
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
}Nous avons choisi usize comme type du paramètre size car nous savons qu’un nombre négatif de threads n’à aucun sens. Nous savons aussi que nous utiliserons ce 4 comme nombre d’éléments dans une collection de threads, ce qui est la raison d’être du type usize, comme discuté dans la section [« Les types d’entiers »][integer-types] du chapitre 3.
Vérifions le code à nouveau : console {{#include ../listings/ch21-web-server/no-listing-02-impl-threadpool-new/output.txt}}
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0599]: no method named `execute` found for struct `ThreadPool` in the current scope
--> src/main.rs:17:14
|
17 | pool.execute(|| {
| -----^^^^^^^ method not found in `ThreadPool`
For more information about this error, try `rustc --explain E0599`.
error: could not compile `hello` (bin "hello") due to 1 previous error
Maintenant l’erreur survient parce que nous n’avons pas de méthode execute sur ThreadPool. Rappelez-vous de la section « Créer un nombre fini de threads » que nous avions décidé que notre thread pool devrait avoir une interface similaire à thread::spawn. De plus, nous allons implémenter la fonction execute de sorte qu’elle prenne la closure qu’on lui donne et la transmette à un thread inactif du pool pour l’exécuter.
Nous allons définir la méthode execute sur ThreadPool pour prendre une closure comme paramètre. Rappelez-vous de la section [« Déplacer les valeurs capturées hors des closures »][moving-out-of-closures] du chapitre 13 que nous pouvons prendre des closures comme paramètres avec trois traits différents : Fn, FnMut et FnOnce. Nous devons décider quel type de closure utiliser ici. Nous savons que nous finirons par faire quelque chose de similaire à l’implémentation de thread::spawn de la bibliothèque standard, donc nous pouvons regarder quelles contraintes la signature de thread::spawn a sur son paramètre. La documentation nous montre ce qui suit :
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,Le paramètre de type F est celui qui nous intéresse ici ; le paramètre de type T est lié à la valeur de retour, et cela ne nous concerne pas. Nous pouvons voir que spawn utilise FnOnce comme contrainte de trait sur F. C’est probablement ce que nous voulons aussi, car nous finirons par passer l’argument que nous recevons dans execute à spawn. Nous pouvons être encore plus confiants que FnOnce est le trait que nous voulons utiliser parce que le thread exécutant une requête n’exécutera la closure de cette requête qu’une seule fois, ce qui correspond au Once de FnOnce.
Le paramètre de type F a aussi la contrainte de trait Send et la contrainte de durée de vie 'static, qui sont utiles dans notre situation : nous avons besoin de Send pour transférer la closure d’un thread à un autre et de 'static parce que nous ne savons pas combien de temps le thread prendra pour s’exécuter. Créons une méthode execute sur ThreadPool qui prendra un paramètre générique de type F avec ces contraintes :
pub struct ThreadPool;
impl ThreadPool {
// --snip--
pub fn new(size: usize) -> ThreadPool {
ThreadPool
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}Nous utilisons toujours () après FnOnce parce que ce FnOnce représente une closure qui ne prend pas de paramètres et retourné le type unitaire (). Tout comme les définitions de fonctions, le type de retour peut être omis de la signature, mais même si nous n’avons pas de paramètres, nous avons toujours besoin des parenthèses.
Encore une fois, c’est l’implémentation la plus simple de la méthode execute : elle ne fait rien, mais nous essayons seulement de faire compiler notre code. Vérifions-le à nouveau : console {{#include ../listings/ch21-web-server/no-listing-03-define-execute/output.txt}}
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.24s
Ça compilé ! Mais notez que si vous essayez cargo run et faites une requête dans le navigateur, vous verrez les erreurs dans le navigateur que nous avons vues au début du chapitre. Notre bibliothèque n’appelle pas encore réellement la closure passée à execute !
Remarque : un dicton que vous pourriez entendre à propos des langages avec des compilateurs stricts, comme Haskell et Rust, est « Si le code compilé, il fonctionne. » Mais ce dicton n’est pas universellement vrai. Notre projet compilé, mais il ne fait absolument rien ! Si nous construisions un vrai projet complet, ce serait le bon moment pour commencer à écrire des tests unitaires pour vérifier que le code compilé et à le comportement que nous voulons.
Réfléchissez : qu’est-ce qui serait différent ici si nous allions exécuter une future au lieu d’une closure ?
Valider le nombre de threads dans new
Nous ne faisons rien avec les paramètres de new et execute. Implémentons les corps de ces fonctions avec le comportement que nous voulons. Pour commencer, pensons à new. Plus tôt, nous avons choisi un type non signé pour le paramètre size parce qu’un pool avec un nombre négatif de threads n’à aucun sens. Cependant, un pool avec zéro thread n’a pas de sens non plus, pourtant zéro est une valeur usize parfaitement valide. Nous ajouterons du code pour vérifier que size est supérieur à zéro avant de retourner une instance de ThreadPool, et nous ferons paniquer le programme s’il reçoit zéro en utilisant la macro assert!, comme montré dans l’encart 21-13.
pub struct ThreadPool;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
ThreadPool
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}ThreadPool::new to panic if size is zeroNous avons aussi ajouté de la documentation pour notre ThreadPool avec des commentaires de documentation. Notez que nous avons suivi les bonnes pratiques de documentation en ajoutant une section qui signale les situations dans lesquelles notre fonction peut paniquer, comme discuté au chapitre 14. Essayez d’exécuter cargo doc --open et de cliquer sur la structure ThreadPool pour voir à quoi ressemble la documentation générée pour new !
Au lieu d’ajouter la macro assert! comme nous l’avons fait ici, nous pourrions transformer new en build et retourner un Result comme nous l’avons fait avec Config::build dans le projet d’E/S de l’encart 12-9. Mais nous avons décidé dans ce cas qu’essayer de créer un thread pool sans aucun thread devrait être une erreur irrécupérable. Si vous êtes ambitieux, essayez d’écrire une fonction nommée build avec la signature suivante pour la comparer avec la fonction new :
pub fn build(size: usize) -> Result<ThreadPool, PoolCreationError> {Créer l’espace pour stocker les threads
Maintenant que nous avons un moyen de savoir que nous avons un nombre valide de threads à stocker dans le pool, nous pouvons créer ces threads et les stocker dans la structure ThreadPool avant de retourner la structure. Mais comment « stocker » un thread ? Regardons à nouveau la signature de thread::spawn :
pub fn spawn<F, T>(f: F) -> JoinHandle<T>
where
F: FnOnce() -> T,
F: Send + 'static,
T: Send + 'static,La fonction spawn retourné un JoinHandle<T>, où T est le type que la closure retourné. Essayons d’utiliser JoinHandle aussi et voyons ce qui se passe. Dans notre cas, les closures que nous passons au thread pool géreront la connexion et ne retourneront rien, donc T sera le type unitaire ().
Le code de l’encart 21-14 compilera, mais il ne crée pas encore de threads. Nous avons changé la définition de ThreadPool pour contenir un vecteur d’instances thread::JoinHandle<()>, initialisé le vecteur avec une capacité de size, mis en place une boucle for qui exécutera du code pour créer les threads, et retourné une instance de ThreadPool les contenant.
use std::thread;
pub struct ThreadPool {
threads: Vec<thread::JoinHandle<()>>,
}
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut threads = Vec::with_capacity(size);
for _ in 0..size {
// create some threads and store them in the vector
}
ThreadPool { threads }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}ThreadPool to hold the threadsNous avons importé std::thread dans la portée du crate de bibliothèque car nous utilisons thread::JoinHandle comme type des éléments du vecteur dans ThreadPool.
Une fois qu’une taille valide est reçue, notre ThreadPool crée un nouveau vecteur qui peut contenir size éléments. La fonction with_capacity effectue la même tâche que Vec::new mais avec une différence importante : elle pré-alloue l’espace dans le vecteur. Parce que nous savons que nous devons stocker size éléments dans le vecteur, faire cette allocation à l’avance est légèrement plus efficace que d’utiliser Vec::new, qui se redimensionne au fur et à mesure que les éléments sont insérés.
Quand vous exécutez cargo check à nouveau, cela devrait réussir.
Envoyer du code du ThreadPool vers un thread
Nous avons laissé un commentaire dans la boucle for de l’encart 21-14 concernant la création de threads. Ici, nous allons voir comment nous créons réellement les threads. La bibliothèque standard fournit thread::spawn comme moyen de créer des threads, et thread::spawn s’attend à recevoir du code que le thread devrait exécuter dès que le thread est créé. Cependant, dans notre cas, nous voulons créer les threads et les faire attendre du code que nous enverrons plus tard. L’implémentation des threads de la bibliothèque standard n’inclut aucun moyen de faire cela ; nous devons l’implémenter manuellement.
Nous allons implémenter ce comportement en introduisant une nouvelle structure de données entre le ThreadPool et les threads qui gérera ce nouveau comportement. Nous appellerons cette structure de données Worker, qui est un terme courant dans les implémentations de pools. Le Worker récupère le code qui doit être exécuté et l’exécute dans son thread.
Pensez aux personnes travaillant en cuisine dans un restaurant : les workers attendent que les commandes arrivent des clients, puis ils sont responsables de prendre ces commandes et de les exécuter.
Au lieu de stocker un vecteur d’instances JoinHandle<()> dans le thread pool, nous stockerons des instances de la structure Worker. Chaque Worker stockera une seule instance de JoinHandle<()>. Ensuite, nous implémenterons une méthode sur Worker qui prendra une closure de code à exécuter et l’enverra au thread déjà en cours d’exécution pour traitement. Nous donnerons aussi à chaque Worker un id pour que nous puissions distinguer les différentes instances de Worker dans le pool lors de la journalisation ou du débogage.
Voici le nouveau processus qui se produira quand nous créerons un ThreadPool. Nous implémenterons le code qui envoie la closure au thread après avoir mis en place le Worker de cette manière : 1. Définir une structure Worker qui contient un id et un JoinHandle<()>. 2. Modifier ThreadPool pour contenir un vecteur d’instances de Worker. 3. Définir une fonction Worker::new qui prend un numéro d’id et retourné une instance de Worker qui contient l’id et un thread créé avec une closure vide. 4. Dans ThreadPool::new, utiliser le compteur de la boucle for pour générer un id, créer un nouveau Worker avec cet id, et stocker le Worker dans le vecteur.
- Définir une structure
Workerqui contient unidet unJoinHandle<()>. - Modifier
ThreadPoolpour contenir un vecteur d’instances deWorker. - Définir une fonction
Worker::newqui prend un numéro d’idet retourné une instance deWorkerqui contient l’idet un thread créé avec une closure vide. - Dans
ThreadPool::new, utiliser le compteur de la boucleforpour générer unid, créer un nouveauWorkeravec cetid, et stocker leWorkerdans le vecteur.
Si vous aimez les défis, essayez d’implémenter ces changements par vous-même avant de regarder le code de l’encart 21-15.
Prêt ? Voici l’encart 21-15 avec une façon de faire les modifications précédentes.
use std::thread;
pub struct ThreadPool {
workers: Vec<Worker>,
}
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}ThreadPool to hold Worker instances instead of holding threads directlyNous avons changé le nom du champ sur ThreadPool de threads à workers car il contient maintenant des instances de Worker au lieu d’instances de JoinHandle<()>. Nous utilisons le compteur dans la boucle for comme argument pour Worker::new, et nous stockons chaque nouveau Worker dans le vecteur nommé workers.
Le code externe (comme notre serveur dans src/main.rs) n’a pas besoin de connaître les détails d’implémentation concernant l’utilisation d’une structure Worker au sein de ThreadPool, donc nous rendons la structure Worker et sa fonction new privées. La fonction Worker::new utilise l’id que nous lui donnons et stocké une instance de JoinHandle<()> qui est créée en lançant un nouveau thread avec une closure vide.
Remarque : si le système d’exploitation ne peut pas créer un thread parce qu’il n’y a pas assez de ressources système,
thread::spawnpaniquera. Cela fera paniquer tout notre serveur, même si la création de certains threads aurait pu réussir. Par souci de simplicité, ce comportement est acceptable, mais dans une implémentation de thread pool en production, vous voudriez probablement utiliser [std::thread::Builder][builder] et sa méthode [spawn][builder-spawn] qui retourné unResultà la place.
Ce code compilera et stockera le nombre d’instances de Worker que nous avons spécifié comme argument de ThreadPool::new. Mais nous ne traitons toujours pas la closure que nous recevons dans execute. Voyons comment faire cela ensuite.
Envoyer des requêtes aux threads via des canaux
Le prochain problème que nous allons aborder est que les closures données à thread::spawn ne font absolument rien. Actuellement, nous recevons la closure que nous voulons exécuter dans la méthode execute. Mais nous devons donner à thread::spawn une closure à exécuter quand nous créons chaque Worker lors de la création du ThreadPool.
Nous voulons que les structures Worker que nous venons de créer récupèrent le code à exécuter depuis une file d’attente détenue par le ThreadPool et envoient ce code à leur thread pour l’exécuter.
Les canaux que nous avons appris au chapitre 16 – un moyen simple de communiquer entre deux threads – seraient parfaits pour ce cas d’utilisation. Nous utiliserons un canal pour fonctionner comme la file d’attente de tâches, et execute enverra une tâche du ThreadPool aux instances de Worker, qui enverront la tâche à leur thread. Voici le plan : 1. Le ThreadPool créera un canal et conservera l’émetteur (sender). 2. Chaque Worker conservera le récepteur (receiver). 3. Nous créerons une nouvelle structure Job qui contiendra les closures que nous voulons envoyer à travers le canal. 4. La méthode execute enverra la tâche qu’elle veut exécuter à travers l’émetteur. 5. Dans son thread, le Worker bouclera sur son récepteur et exécutera les closures de toutes les tâches qu’il reçoit.
- Le
ThreadPoolcréera un canal et conservera l’émetteur (sender). - Chaque
Workerconservera le récepteur (receiver). - Nous créerons une nouvelle structure
Jobqui contiendra les closures que nous voulons envoyer à travers le canal. - La méthode
executeenverra la tâche qu’elle veut exécuter à travers l’émetteur. - Dans son thread, le
Workerbouclera sur son récepteur et exécutera les closures de toutes les tâches qu’il reçoit.
Commençons par créer un canal dans ThreadPool::new et en conservant l’émetteur dans l’instance de ThreadPool, comme montré dans l’encart 21-16. La structure Job ne contient rien pour le moment mais sera le type d’élément que nous enverrons à travers le canal.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize) -> Worker {
let thread = thread::spawn(|| {});
Worker { id, thread }
}
}ThreadPool to store the sender of a channel that transmits Job instancesDans ThreadPool::new, nous créons notre nouveau canal et faisons en sorte que le pool conserve l’émetteur. Cela compilera avec succès.
Essayons de passer un récepteur du canal à chaque Worker au moment où le thread pool crée le canal. Nous savons que nous voulons utiliser le récepteur dans le thread que les instances de Worker créent, donc nous référencerons le paramètre receiver dans la closure. Le code de l’encart 21-17 ne compilera pas tout à fait encore.
use std::{sync::mpsc, thread};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, receiver));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}WorkerNous avons fait quelques petits changements simples : nous passons le récepteur à Worker::new, puis nous l’utilisons à l’intérieur de la closure.
Quand nous essayons de vérifier ce code, nous obtenons cette erreur : console {{#include ../listings/ch21-web-server/listing-21-17/output.txt}}
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0382]: use of moved value: `receiver`
--> src/lib.rs:26:42
|
21 | let (sender, receiver) = mpsc::channel();
| -------- move occurs because `receiver` has type `std::sync::mpsc::Receiver<Job>`, which does not implement the `Copy` trait
...
25 | for id in 0..size {
| ----------------- inside of this loop
26 | workers.push(Worker::new(id, receiver));
| ^^^^^^^^ value moved here, in previous iteration of loop
|
note: consider changing this parameter type in method `new` to borrow instead if owning the value isn't necessary
--> src/lib.rs:47:33
|
47 | fn new(id: usize, receiver: mpsc::Receiver<Job>) -> Worker {
| --- in this method ^^^^^^^^^^^^^^^^^^^ this parameter takes ownership of the value
help: consider moving the expression out of the loop so it is only moved once
|
25 ~ let mut value = Worker::new(id, receiver);
26 ~ for id in 0..size {
27 ~ workers.push(value);
|
For more information about this error, try `rustc --explain E0382`.
error: could not compile `hello` (lib) due to 1 previous error
Le code essaie de passer receiver à plusieurs instances de Worker. Cela ne fonctionnera pas, comme vous vous en souviendrez du chapitre 16 : l’implémentation de canal que Rust fournit est à producteurs multiples, consommateur unique. Cela signifie que nous ne pouvons pas simplement cloner l’extrémité consommatrice du canal pour corriger ce code. Nous ne voulons pas non plus envoyer un message plusieurs fois à plusieurs consommateurs ; nous voulons une liste de messages avec plusieurs instances de Worker de sorte que chaque message soit traité une seule fois.
De plus, retirer une tâche de la file d’attente du canal implique de muter le receiver, donc les threads ont besoin d’un moyen sûr de partager et modifier receiver ; sinon, nous pourrions obtenir des conditions de concurrence (comme abordé au chapitre 16).
Rappelez-vous les pointeurs intelligents thread-safe discutés au chapitre 16 : pour partager la propriété entre plusieurs threads et permettre aux threads de muter la valeur, nous devons utiliser Arc<Mutex<T>>. Le type Arc permettra à plusieurs instances de Worker de posséder le récepteur, et Mutex garantira qu’un seul Worker obtient une tâche du récepteur à la fois. L’encart 21-18 montre les changements que nous devons effectuer.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
// --snip--
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
struct Job;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
// --snip--
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
// --snip--
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Worker instances using Arc and MutexDans ThreadPool::new, nous plaçons le récepteur dans un Arc et un Mutex. Pour chaque nouveau Worker, nous clonons l’Arc pour incrémenter le compteur de références afin que les instances de Worker puissent partager la propriété du récepteur.
Avec ces changements, le code compilé ! Nous y arrivons !
Implémenter la méthode execute
Implémentons enfin la méthode execute sur ThreadPool. Nous allons aussi changer Job d’une structure vers un alias de type pour un objet trait qui contient le type de closure que execute reçoit. Comme discuté dans la section [« Synonymes de types et alias de types »][type-aliases] du chapitre 20, les alias de types nous permettent de raccourcir les types longs pour faciliter leur utilisation. Regardez l’encart 21-19.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
// --snip--
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
// --snip--
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(|| {
receiver;
});
Worker { id, thread }
}
}Job type alias for a Box that holds each closure and then sending the job down the channelAprès avoir créé une nouvelle instance de Job en utilisant la closure que nous recevons dans execute, nous envoyons cette tâche par l’extrémité émettrice du canal. Nous appelons unwrap sur send pour le cas où l’envoi échouerait. Cela pourrait se produire si, par exemple, nous arrêtions tous nos threads, ce qui signifierait que l’extrémité réceptrice a cessé de recevoir de nouveaux messages. Pour le moment, nous ne pouvons pas arrêter nos threads : nos threads continuent de s’exécuter tant que le pool existe. La raison pour laquelle nous utilisons unwrap est que nous savons que le cas d’échec ne se produira pas, mais le compilateur ne le sait pas.
Mais nous n’avons pas tout à fait fini ! Dans le Worker, notre closure passée à thread::spawn ne fait encore que référencer l’extrémité réceptrice du canal. Au lieu de cela, nous avons besoin que la closure boucle indéfiniment, en demandant à l’extrémité réceptrice du canal une tâche et en exécutant la tâche quand elle en obtient une. Effectuons la modification montrée dans l’encart 21-20 sur Worker::new.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Worker instance’s threadIci, nous appelons d’abord lock sur le receiver pour acquérir le mutex, puis nous appelons unwrap pour paniquer en cas d’erreur. L’acquisition d’un verrou peut échouer si le mutex est dans un état empoisonné (poisoned), ce qui peut se produire si un autre thread a paniqué tout en détenant le verrou au lieu de le libérer. Dans cette situation, appeler unwrap pour faire paniquer ce thread est l’action correcte à prendre. N’hésitez pas à remplacer cet unwrap par un expect avec un message d’erreur qui a du sens pour vous.
Si nous obtenons le verrou sur le mutex, nous appelons recv pour recevoir un Job du canal. Un dernier unwrap passe outre toute erreur ici aussi, qui pourrait survenir si le thread détenant l’émetteur s’est arrêté, de manière similaire à la façon dont la méthode send retourné Err si le récepteur s’arrête.
L’appel à recv bloque, donc s’il n’y a pas encore de tâche, le thread courant attendra qu’une tâche devienne disponible. Le Mutex<T> garantit qu’un seul thread Worker à la fois essaie de demander une tâche.
Notre thread pool est maintenant en état de fonctionnement ! Lancez un cargo run et faites quelques requêtes :
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
warning: field `workers` is never read
--> src/lib.rs:7:5
|
6 | pub struct ThreadPool {
| ---------- field in this struct
7 | workers: Vec<Worker>,
| ^^^^^^^
|
= note: `#[warn(dead_code)]` on by default
warning: fields `id` and `thread` are never read
--> src/lib.rs:48:5
|
47 | struct Worker {
| ------ fields in this struct
48 | id: usize,
| ^^
49 | thread: thread::JoinHandle<()>,
| ^^^^^^
warning: `hello` (lib) generated 2 warnings
Finished `dev` profile [unoptimized + debuginfo] target(s) in 4.91s
Running `target/debug/hello`
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Worker 1 got a job; executing.
Worker 3 got a job; executing.
Worker 0 got a job; executing.
Worker 2 got a job; executing.
Succès ! Nous avons maintenant un thread pool qui exécute les connexions de manière asynchrone. Il n’y a jamais plus de quatre threads créés, donc notre système ne sera pas surchargé si le serveur reçoit beaucoup de requêtes. Si nous faisons une requête vers /sleep, le serveur pourra servir d’autres requêtes en faisant exécuter celles-ci par un autre thread.
Remarque : si vous ouvrez /sleep dans plusieurs fenêtres de navigateur simultanément, elles pourraient se charger une à la fois à des intervalles de cinq secondes. Certains navigateurs web exécutent séquentiellement plusieurs instances de la même requête pour des raisons de mise en cache. Cette limitation n’est pas causée par notre serveur web.
C’est un bon moment pour faire une pause et considérer comment le code des encarts 21-18, 21-19 et 21-20 serait différent si nous utilisions des futures au lieu d’une closure pour le travail à effectuer. Quels types changeraient ? Comment les signatures des méthodes seraient-elles différentes, si elles l’étaient ? Quelles parties du code resteraient les mêmes ?
Après avoir appris la boucle while let aux chapitres 17 et 19, vous vous demandez peut-être pourquoi nous n’avons pas écrit le code du thread Worker comme montré dans l’encart 21-21.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
// --snip--
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
while let Ok(job) = receiver.lock().unwrap().recv() {
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}Worker::new using while letCe code compilé et s’exécute mais ne produit pas le comportement de threading souhaité : une requête lente fera toujours attendre les autres requêtes pour être traitées. La raison est assez subtile : la structure Mutex n’a pas de méthode publique unlock car la propriété du verrou est basée sur la durée de vie du MutexGuard<T> au sein du LockResult<MutexGuard<T>> que la méthode lock retourné. Au moment de la compilation, le vérificateur d’emprunt peut alors appliquer la règle selon laquelle une ressource protégée par un Mutex ne peut pas être accédée à moins que nous détenions le verrou. Cependant, cette implémentation peut aussi faire en sorte que le verrou soit détenu plus longtemps que prévu si nous ne sommes pas attentifs à la durée de vie du MutexGuard<T>.
Le code de l’encart 21-20 qui utilise let job = receiver.lock().unwrap().recv().unwrap(); fonctionne car avec let, toutes les valeurs temporaires utilisées dans l’expression du côté droit du signé égal sont immédiatement libérées quand l’instruction let se terminé. Cependant, while let (et if let et match) ne libère pas les valeurs temporaires avant la fin du bloc associé. Dans l’encart 21-21, le verrou reste détenu pendant toute la durée de l’appel à job(), ce qui signifie que les autres instances de Worker ne peuvent pas recevoir de tâches.
Arrêt gracieux et nettoyage
Arrêt gracieux et nettoyage
Le code de l’encart 21-20 répond aux requêtes de manière asynchrone grâce à l’utilisation d’un thread pool, comme nous le souhaitions. Nous recevons des avertissements concernant les champs workers, id et thread que nous n’utilisons pas directement, ce qui nous rappelle que nous ne nettoyons rien. Quand nous utilisons la méthode peu élégante ctrl-C pour arrêter le thread principal, tous les autres threads sont arrêtés immédiatement aussi, même s’ils sont en train de traiter une requête.
Ensuite, nous allons implémenter le trait Drop pour appeler join sur chacun des threads du pool afin qu’ils puissent terminer les requêtes sur lesquelles ils travaillent avant de se fermer. Puis, nous implémenterons un moyen de dire aux threads qu’ils devraient arrêter d’accepter de nouvelles requêtes et s’arrêter. Pour voir ce code en action, nous modifierons notre serveur pour n’accepter que deux requêtes avant d’arrêter proprement son thread pool.
Une chose à remarquer au passage : rien de tout cela n’affecte les parties du code qui gèrent l’exécution des closures, donc tout ce qui est ici serait identique si nous utilisions un thread pool pour un runtime async.
Implémenter le trait Drop sur ThreadPool
Commençons par implémenter Drop sur notre thread pool. Quand le pool est libéré, tous nos threads devraient se joindre (join) pour s’assurer qu’ils terminent leur travail. L’encart 21-22 montre une première tentative d’implémentation de Drop ; ce code ne fonctionnera pas tout à fait encore.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}D’abord, nous bouclons sur chaque worker du thread pool. Nous utilisons &mut pour cela car self est une référence mutable, et nous devons aussi pouvoir muter worker. Pour chaque worker, nous affichons un message disant que cette instance particulière de Worker s’arrête, puis nous appelons join sur le thread de cette instance de Worker. Si l’appel à join échoue, nous utilisons unwrap pour faire paniquer Rust et entrer dans un arrêt non propre.
Voici l’erreur que nous obtenons quand nous compilons ce code : console {{#include ../listings/ch21-web-server/listing-21-22/output.txt}}
$ cargo check
Checking hello v0.1.0 (file:///projects/hello)
error[E0507]: cannot move out of `worker.thread` which is behind a mutable reference
--> src/lib.rs:52:13
|
52 | worker.thread.join().unwrap();
| ^^^^^^^^^^^^^ ------ `worker.thread` moved due to this method call
| |
| move occurs because `worker.thread` has type `JoinHandle<()>`, which does not implement the `Copy` trait
|
note: `JoinHandle::<T>::join` takes ownership of the receiver `self`, which moves `worker.thread`
--> /rustc/1159e78c4747b02ef996e55082b704c09b970588/library/std/src/thread/mod.rs:1921:17
For more information about this error, try `rustc --explain E0507`.
error: could not compile `hello` (lib) due to 1 previous error
L’erreur nous dit que nous ne pouvons pas appeler join parce que nous n’avons qu’un emprunt mutable de chaque worker et que join prend la propriété de son argument. Pour résoudre ce problème, nous devons déplacer le thread hors de l’instance de Worker qui possède thread afin que join puisse consommer le thread. Une façon de faire cela est de prendre la même approche que celle de l’encart 18-15. Si Worker contenait un Option<thread::JoinHandle<()>>, nous pourrions appeler la méthode take sur l’Option pour déplacer la valeur hors de la variante Some et laisser une variante None à sa place. En d’autres termes, un Worker en cours d’exécution aurait une variante Some dans thread, et quand nous voudrions nettoyer un Worker, nous remplacerions Some par None pour que le Worker n’ait plus de thread à exécuter.
Cependant, le seul moment où cela se produirait serait lors de la libération du Worker. En contrepartie, nous devrions gérer un Option<thread::JoinHandle<()>> partout où nous accéderions à worker.thread. Le Rust idiomatique utilise beaucoup Option, mais quand vous vous retrouvez à envelopper quelque chose que vous savez toujours présent dans un Option comme solution de contournement comme celle-ci, c’est une bonne idée de chercher des approches alternatives pour rendre votre code plus propre et moins sujet aux erreurs.
Dans ce cas, une meilleure alternative existe : la méthode Vec::drain. Elle accepte un paramètre de plage pour spécifier quels éléments retirer du vecteur et retourné un itérateur de ces éléments. Passer la syntaxe de plage .. retirera chaque valeur du vecteur.
Donc, nous devons mettre à jour l’implémentation de drop du ThreadPool comme ceci :
#![allow(unused)]
fn main() {
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: mpsc::Sender<Job>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool { workers, sender }
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}
}Cela résout l’erreur du compilateur et ne nécessite aucune autre modification de notre code. Notez que, comme drop peut être appelé lors d’un panic, le unwrap pourrait aussi paniquer et causer un double panic, ce qui fait immédiatement planter le programme et met fin à tout nettoyage en cours. C’est acceptable pour un programme d’exemple, mais ce n’est pas recommandé pour du code en production.
Signaler aux threads d’arrêter d’écouter les tâches
Avec toutes les modifications que nous avons faites, notre code compilé sans aucun avertissement. Cependant, la mauvaise nouvelle est que ce code ne fonctionne pas encore comme nous le voulons. La clé est la logique dans les closures exécutées par les threads des instances de Worker : pour le moment, nous appelons join, mais cela n’arrêtera pas les threads, car ils bouclent (loop) indéfiniment à la recherche de tâches. Si nous essayons de libérer notre ThreadPool avec notre implémentation actuelle de drop, le thread principal se bloquera indéfiniment, en attendant que le premier thread se terminé.
Pour corriger ce problème, nous aurons besoin d’un changement dans l’implémentation de drop du ThreadPool puis d’un changement dans la boucle du Worker.
D’abord, nous allons modifier l’implémentation de drop du ThreadPool pour libérer explicitement le sender avant d’attendre que les threads se terminent. L’encart 21-23 montre les modifications apportées au ThreadPool pour libérer explicitement sender. Contrairement au thread, ici nous avons besoin d’utiliser un Option pour pouvoir déplacer sender hors du ThreadPool avec Option::take.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
// --snip--
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
// --snip--
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let job = receiver.lock().unwrap().recv().unwrap();
println!("Worker {id} got a job; executing.");
job();
}
});
Worker { id, thread }
}
}sender before joining the Worker threadsLibérer sender ferme le canal, ce qui indique qu’aucun autre message ne sera envoyé. Quand cela se produit, tous les appels à recv que les instances de Worker font dans la boucle infinie retourneront une erreur. Dans l’encart 21-24, nous modifions la boucle du Worker pour sortir proprement de la boucle dans ce cas, ce qui signifie que les threads se termineront quand l’implémentation de drop du ThreadPool appellera join sur eux.
use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in self.workers.drain(..) {
println!("Shutting down worker {}", worker.id);
worker.thread.join().unwrap();
}
}
}
struct Worker {
id: usize,
thread: thread::JoinHandle<()>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
}
});
Worker { id, thread }
}
}recv returns an errorPour voir ce code en action, modifions main pour n’accepter que deux requêtes avant d’arrêter proprement le serveur, comme montré dans l’encart 21-25.
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r
Content-Length: {length}\r
\r
{contents}");
stream.write_all(response.as_bytes()).unwrap();
}Vous ne voudriez pas qu’un serveur web réel s’arrête après avoir servi seulement deux requêtes. Ce code démontre simplement que l’arrêt propre et le nettoyage fonctionnent correctement.
La méthode take est définie dans le trait Iterator et limite l’itération aux deux premiers éléments au maximum. Le ThreadPool sortira de la portée à la fin de main, et l’implémentation de drop s’exécutera.
Démarrez le serveur avec cargo run et faites trois requêtes. La troisième requête devrait échouer, et dans votre terminal, vous devriez voir une sortie similaire à ceci :
$ cargo run
Compiling hello v0.1.0 (file:///projects/hello)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 0.41s
Running `target/debug/hello`
Worker 0 got a job; executing.
Shutting down.
Shutting down worker 0
Worker 3 got a job; executing.
Worker 1 disconnected; shutting down.
Worker 2 disconnected; shutting down.
Worker 3 disconnected; shutting down.
Worker 0 disconnected; shutting down.
Shutting down worker 1
Shutting down worker 2
Shutting down worker 3
Vous pourriez voir un ordre différent des identifiants de Worker et des messages affichés. Nous pouvons voir comment ce code fonctionne d’après les messages : les instances de Worker 0 et 3 ont reçu les deux premières requêtes. Le serveur a arrêté d’accepter les connexions après la deuxième connexion, et l’implémentation de Drop sur ThreadPool commence à s’exécuter avant même que Worker 3 ne commence sa tâche. La libération du sender déconnecte toutes les instances de Worker et leur dit de s’arrêter. Les instances de Worker affichent chacune un message quand elles se déconnectent, puis le thread pool appelle join pour attendre que chaque thread Worker se terminé.
Remarquez un aspect intéressant de cette exécution particulière : le ThreadPool a libéré le sender, et avant qu’aucun Worker n’ait reçu d’erreur, nous avons essayé de joindre Worker 0. Worker 0 n’avait pas encore reçu d’erreur de recv, donc le thread principal s’est bloqué, en attendant que Worker 0 se terminé. Entre-temps, Worker 3 a reçu une tâche et ensuite tous les threads ont reçu une erreur. Quand Worker 0 a terminé, le thread principal a attendu que le reste des instances de Worker se terminé. À ce moment-là, elles avaient toutes quitté leurs boucles et s’étaient arrêtées.
Félicitations ! Nous avons maintenant terminé notre projet ; nous avons un serveur web basique qui utilise un thread pool pour répondre de manière asynchrone. Nous sommes capables d’effectuer un arrêt propre du serveur, qui nettoie tous les threads du pool.
Voici le code complet pour référence :
use hello::ThreadPool;
use std::{
fs,
io::{BufReader, prelude::*},
net::{TcpListener, TcpStream},
thread,
time::Duration,
};
fn main() {
let listener = TcpListener::bind("127.0.0.1:7878").unwrap();
let pool = ThreadPool::new(4);
for stream in listener.incoming().take(2) {
let stream = stream.unwrap();
pool.execute(|| {
handle_connection(stream);
});
}
println!("Shutting down.");
}
fn handle_connection(mut stream: TcpStream) {
let buf_reader = BufReader::new(&stream);
let request_line = buf_reader.lines().next().unwrap().unwrap();
let (status_line, filename) = match &request_line[..] {
"GET / HTTP/1.1" => ("HTTP/1.1 200 OK", "hello.html"),
"GET /sleep HTTP/1.1" => {
thread::sleep(Duration::from_secs(5));
("HTTP/1.1 200 OK", "hello.html")
}
_ => ("HTTP/1.1 404 NOT FOUND", "404.html"),
};
let contents = fs::read_to_string(filename).unwrap();
let length = contents.len();
let response =
format!("{status_line}\r
Content-Length: {length}\r
\r
{contents}");
stream.write_all(response.as_bytes()).unwrap();
}use std::{
sync::{Arc, Mutex, mpsc},
thread,
};
pub struct ThreadPool {
workers: Vec<Worker>,
sender: Option<mpsc::Sender<Job>>,
}
type Job = Box<dyn FnOnce() + Send + 'static>;
impl ThreadPool {
/// Create a new ThreadPool.
///
/// The size is the number of threads in the pool.
///
/// # Panics
///
/// The `new` function will panic if the size is zero.
pub fn new(size: usize) -> ThreadPool {
assert!(size > 0);
let (sender, receiver) = mpsc::channel();
let receiver = Arc::new(Mutex::new(receiver));
let mut workers = Vec::with_capacity(size);
for id in 0..size {
workers.push(Worker::new(id, Arc::clone(&receiver)));
}
ThreadPool {
workers,
sender: Some(sender),
}
}
pub fn execute<F>(&self, f: F)
where
F: FnOnce() + Send + 'static,
{
let job = Box::new(f);
self.sender.as_ref().unwrap().send(job).unwrap();
}
}
impl Drop for ThreadPool {
fn drop(&mut self) {
drop(self.sender.take());
for worker in &mut self.workers {
println!("Shutting down worker {}", worker.id);
if let Some(thread) = worker.thread.take() {
thread.join().unwrap();
}
}
}
}
struct Worker {
id: usize,
thread: Option<thread::JoinHandle<()>>,
}
impl Worker {
fn new(id: usize, receiver: Arc<Mutex<mpsc::Receiver<Job>>>) -> Worker {
let thread = thread::spawn(move || {
loop {
let message = receiver.lock().unwrap().recv();
match message {
Ok(job) => {
println!("Worker {id} got a job; executing.");
job();
}
Err(_) => {
println!("Worker {id} disconnected; shutting down.");
break;
}
}
}
});
Worker {
id,
thread: Some(thread),
}
}
}Nous pourrions faire plus ici ! Si vous voulez continuer à améliorer ce projet, voici quelques idées :
- Ajouter plus de documentation à
ThreadPoolet à ses méthodes publiques. - Ajouter des tests de la fonctionnalité de la bibliothèque.
- Remplacer les appels à
unwrappar une gestion d’erreurs plus robuste. - Utiliser
ThreadPoolpour effectuer une tâche autre que servir des requêtes web. - Trouver une crate de thread pool sur crates.io et implémenter un serveur web similaire en utilisant cette crate à la place. Ensuite, comparer son API et sa robustesse au thread pool que nous avons implémenté.
Résumé
Bien joué ! Vous êtes arrivé à la fin du livre ! Nous voulons vous remercier de nous avoir accompagnés dans cette visite de Rust. Vous êtes maintenant prêt à implémenter vos propres projets Rust et à aider dans les projets des autres. Gardez à l’esprit qu’il existe une communauté accueillante d’autres Rustacés qui seraient ravis de vous aider avec tous les défis que vous rencontrerez dans votre parcours Rust.
Annexes
Les sections suivantes contiennent des informations de référence qui pourraient vous être utiles dans votre apprentissage de Rust.
A - Les mots-clés
Annexe A : les mots-clés
Les listes suivantes contiennent des mots-clés réservés qui sont actuellement utilisés dans le langage Rust ou qui pourraient l’être à l’avenir. De ce fait, ils ne peuvent pas être utilisés comme identificateurs (sauf comme identificateurs bruts, ce que nous allons voir dans la section « les identificateurs bruts »). Les identificateurs sont les noms de fonctions, de variables, de paramètres, de champs de structures, de modules, de crates, de constantes, de macros, de valeurs statiques, d’attributs, de types, de traits ou de durées de vie.
Les mots-clés actuellement utilisés
Les mots-clés suivants ont actuellement la fonction décrite.
as: effectue une transformation de type primitive, précise le trait qui contient un élément ou renomme des éléments dans les instructionsuse.async: retourné unFutureplutôt que de bloquer la tâche en cours.await: met en pause l’exécution jusqu’à ce que le résultat d’unFuturesoit disponible.break: sort immédiatement d’une boucle.const: définit des éléments constants ou des pointeurs bruts constants.continue: passe directement à la prochaine itération de la boucle.crate: dans un chemin de module, fait référence à la racine de la crate.dyn: utilisation dynamique d’un objet trait.else: une branche de repli pour les structures de contrôle de fluxifetif let.enum: définit une énumération.extern: crée un lien vers une fonction ou une variable externe.false: le littéral booléen qui vaut faux.fn: définit une fonction ou le type pointeur de fonction.for: crée une boucle sur les éléments d’un itérateur, implémente un trait ou renseigne une durée de vie de niveau supérieur.if: une branche liée au résultat d’une expression conditionnelle.impl: implémente des fonctionnalités propres à un élément ou à un trait.in: fait partie de la syntaxe de la bouclefor.let: lie une variable.loop: fait une boucle sans condition (théoriquement infinie).match: compare une valeur à des motifs.mod: définit un module.move: fait en sorte qu’une fermeture prenne possession de tout ce qu’elle capture.mut: autorise la mutabilité sur des références, des pointeurs bruts ou des éléments issus de motifs.pub: autorise la visibilité publique sur des champs de structures, des blocsimplou des modules.ref: lie une valeur par référence.return: retourné une valeur depuis une fonction.Self: un alias de type pour le type que nous définissons ou implémentons.self: désigne le sujet d’une méthode ou le module courant.static: une variable globale ou une durée de vie qui persiste tout au long de l’exécution du programme.struct: définit une structure.super: le module parent du module courant.trait: définit un trait.true: le littéral booléen qui vaut vrai.type: définit un alias de type ou un type associé.union: définit une union ; n’est un mot-clé que lorsqu’il est utilisé dans la déclaration d’une union.unsafe: autorise du code, des fonctions, des traits ou des implémentations non sécurisés.use: importe des éléments dans la portée.where: indique des conditions pour contraindre un type.while: crée une boucle en fonction du résultat d’une expression.
Les mots-clés réservés pour une utilisation future
Les mots-clés suivants n’offrent actuellement aucune fonctionnalité mais sont réservés par Rust pour une potentielle utilisation future : - abstract - become - box - do - final - gen - macro - override - priv - try - typeof - unsized - virtual - yield
abstractbecomeboxdofinalgenmacrooverrideprivtrytypeofunsizedvirtualyield
Les identificateurs bruts
Les identificateurs bruts sont une syntaxe qui vous permet d’utiliser des mots-clés là où ils ne devraient pas pouvoir l’être. Vous pouvez utiliser un identificateur brut en faisant précéder un mot-clé par r#.
Par exemple, match est un mot-clé. Si vous essayez de compiler la fonction suivante qui utilise match comme nom :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}… vous allez obtenir l’erreur suivante : text error: expected identifier, found keyword `match` --> src/main.rs:4:4 | 4 | fn match(needle: &str, haystack: &str) -> bool { | ^^^^^ expected identifier, found keyword
error: expected identifier, found keyword `match`
--> src/main.rs:4:4
|
4 | fn match(needle: &str, haystack: &str) -> bool {
| ^^^^^ expected identifier, found keyword
L’erreur montre que vous ne pouvez pas utiliser le mot-clé match comme identificateur de la fonction. Pour utiliser match comme nom de fonction, vous devez utiliser la syntaxe d’identificateur brut, comme ceci :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn r#match(needle: &str, haystack: &str) -> bool {
haystack.contains(needle)
}
fn main() {
assert!(r#match("foo", "foobar"));
}Ce code va se compiler sans erreur. Remarquez le préfixe r# sur le nom de la fonction dans sa définition mais aussi lorsque cette fonction est appelée dans main.
Les identificateurs bruts vous permettent d’utiliser n’importe quel mot de votre choix comme identificateur, même si ce mot est un mot-clé réservé. Cela nous donne plus de liberté pour choisir les noms des identificateurs, et nous permet aussi de nous intégrer avec des programmes écrits dans un langage où ces mots ne sont pas des mots-clés. De plus, les identificateurs bruts vous permettent d’utiliser des bibliothèques écrites dans des éditions de Rust différentes de celle qu’utilise votre crate. Par exemple, try n’est pas un mot-clé dans l’édition 2015, mais il l’est dans les éditions 2018, 2021 et 2024. Si vous dépendez d’une bibliothèque qui a été écrite avec l’édition 2015 et qui possède une fonction try, vous allez avoir besoin d’utiliser la syntaxe d’identificateur brut r#try dans ce cas, pour faire appel à cette fonction à partir de votre code dans les éditions ultérieures. Voir l’annexe E pour plus d’informations sur les éditions.
B - Les opérateurs et les symboles
Annexe B : les opérateurs et les symboles
Cette annexe contient un glossaire de la syntaxe de Rust, qui comprend les opérateurs et d’autres symboles qui apparaissent seuls ou dans le contexte de chemins, de génériques, de limites de traits, de macros, d’attributs, de commentaires, de tuples et de crochets.
Les opérateurs
Le tableau B-1 contient les opérateurs de Rust, un exemple montrant comment l’opérateur pourrait apparaître en contexte, une courte explication, et si cet opérateur est surchargeable. Si un opérateur est surchargeable, le trait correspondant à utiliser pour le surcharger est indiqué.
Tableau B-1 : les opérateurs
| Opérateur | Exemple | Explication | Surchargeable ? |
|---|---|---|---|
! | ident!(...), ident!{...}, ident![...] | Expansion de macro | |
! | !expr | Complément binaire ou logique | Not |
!= | expr != expr | Comparaison de non-égalité | PartialEq |
% | expr % expr | Reste arithmétique | Rem |
%= | var %= expr | Reste arithmétique et assignation | RemAssign |
& | &expr, &mut expr | Emprunt | |
& | &type, &mut type, &'a type, &'a mut type | Type de pointeur emprunté | |
& | expr & expr | ET binaire | BitAnd |
&= | var &= expr | ET binaire et assignation | BitAndAssign |
&& | expr && expr | ET logique avec court-circuit | |
* | expr * expr | Multiplication arithmétique | Mul |
*= | var *= expr | Multiplication arithmétique et assignation | MulAssign |
* | *expr | Déréférencement | Deref |
* | *const type, *mut type | Pointeur brut | |
+ | trait + trait, 'a + trait | Contrainte de type composée | |
+ | expr + expr | Addition arithmétique | Add |
+= | var += expr | Addition arithmétique et assignation | AddAssign |
, | expr, expr | Séparateur d’arguments et d’éléments | |
- | - expr | Négation arithmétique | Neg |
- | expr - expr | Soustraction arithmétique | Sub |
-= | var -= expr | Soustraction arithmétique et assignation | SubAssign |
-> | fn(...) -> type, |…| -> type | Type de retour d’une fonction ou d’une fermeture | |
. | expr.ident | Accès à un champ | |
. | expr.ident(expr, ...) | Appel de méthode | |
. | expr.0, expr.1, et ainsi de suite | Indexation de tuple | |
.. | .., expr.., ..expr, expr..expr | Littéral d’intervalle exclusif à droite | PartialOrd |
..= | ..=expr, expr..=expr | Littéral d’intervalle inclusif à droite | PartialOrd |
.. | ..expr | Syntaxe de mise à jour de littéral de structure | |
.. | variant(x, ..), struct_type { x, .. } | Motif “et le reste” | |
... | expr...expr | (Déprécié, utilisez ..= à la place) Dans un motif : motif d’intervalle inclusif | |
/ | expr / expr | Division arithmétique | Div |
/= | var /= expr | Division arithmétique et assignation | DivAssign |
: | pat: type, ident: type | Contraintes | |
: | ident: expr | Initialiseur de champ de structure | |
: | 'a: loop {...} | Étiquette de boucle | |
; | expr; | Fin d’instruction et d’élément | |
; | [...; len] | Partie de la syntaxe de tableau à taille fixe | |
<< | expr << expr | Décalage à gauche | Shl |
<<= | var <<= expr | Décalage à gauche et assignation | ShlAssign |
< | expr < expr | Comparaison inférieur à | PartialOrd |
<= | expr <= expr | Comparaison inférieur ou égal à | PartialOrd |
= | var = expr, ident = type | Assignation/équivalence | |
== | expr == expr | Comparaison d’égalité | PartialEq |
=> | pat => expr | Partie de la syntaxe d’une branche de match | |
> | expr > expr | Comparaison supérieur à | PartialOrd |
>= | expr >= expr | Comparaison supérieur ou égal à | PartialOrd |
>> | expr >> expr | Décalage à droite | Shr |
>>= | var >>= expr | Décalage à droite et assignation | ShrAssign |
@ | ident @ pat | Liaison de motif | |
^ | expr ^ expr | Ou exclusif binaire | BitXor |
^= | var ^= expr | Ou exclusif binaire et assignation | BitXorAssign |
| | pat | pat | Alternatives de motif | |
| | expr | expr | Ou binaire | BitOr |
|= | var |= expr | Ou binaire et assignation | BitOrAssign |
|| | expr || expr | Ou logique avec court-circuit | |
? | expr? | Propagation d’erreur |
Les symboles non-opérateurs
Les tableaux suivants contiennent tous les symboles qui ne fonctionnent pas comme des opérateurs ; c’est-à-dire qu’ils ne se comportent pas comme un appel de fonction ou de méthode.
Le tableau B-2 montre les symboles qui apparaissent seuls et sont valides à divers emplacements.
Tableau B-2 : syntaxe autonome
| Symbole | Explication |
|---|---|
'ident | Durée de vie nommée ou étiquette de boucle |
Chiffres immédiatement suivis de u8, i32, f64, usize, etc. | Littéral numérique d’un type spécifique |
"..." | Littéral de chaîne de caractères |
r"...", r#"..."#, r##"..."##, et ainsi de suite | Littéral de chaîne brute ; les caractères d’échappement ne sont pas traités |
b"..." | Littéral de chaîne d’octets ; construit un tableau d’octets plutôt qu’une chaîne |
br"...", br#"..."#, br##"..."##, et ainsi de suite | Littéral de chaîne d’octets brute ; combinaison de chaîne brute et d’octets |
'...' | Littéral de caractère |
b'...' | Littéral d’octet ASCII |
|…| expr | Fermeture |
! | Type bas (bottom) toujours vide pour les fonctions divergentes |
_ | Motif “ignoré” ; utilisé aussi pour rendre les littéraux entiers lisibles |
Le tableau B-3 montre les symboles qui apparaissent dans le contexte d’un chemin à travers la hiérarchie de modules vers un élément.
Tableau B-3 : syntaxe relative aux chemins
| Symbole | Explication |
|---|---|
ident::ident | Chemin d’espace de noms |
::path | Chemin relatif à la racine de la crate (c’est-à-dire un chemin explicitement absolu) |
self::path | Chemin relatif au module courant (c’est-à-dire un chemin explicitement relatif) |
super::path | Chemin relatif au module parent du module courant |
type::ident, <type as trait>::ident | Constantes, fonctions et types associés |
<type>::... | Élément associé pour un type qui ne peut pas être directement nommé (par exemple, <&T>::..., <[T]>::..., etc.) |
trait::method(...) | Désambiguïsation d’un appel de méthode en nommant le trait qui la définit |
type::method(...) | Désambiguïsation d’un appel de méthode en nommant le type pour lequel elle est définie |
<type as trait>::method(...) | Désambiguïsation d’un appel de méthode en nommant le trait et le type |
Le tableau B-4 montre les symboles qui apparaissent dans le contexte de l’utilisation de paramètres de types génériques.
Tableau B-4 : les génériques
| Symbole | Explication |
|---|---|
path<...> | Renseigne les paramètres d’un type générique dans un type (par exemple, Vec<u8>) |
path::<...>, method::<...> | Renseigne les paramètres d’un type, d’une fonction ou d’une méthode générique dans une expression ; souvent appelé turbofish (par exemple, "42".parse::<i32>()) |
fn ident<...> ... | Définit une fonction générique |
struct ident<...> ... | Définit une structure générique |
enum ident<...> ... | Définit une énumération générique |
impl<...> ... | Définit une implémentation générique |
for<...> type | Limites de durée de vie de rang supérieur |
type<ident=type> | Un type générique où un où plusieurs types associés ont des assignations spécifiques (par exemple, Iterator<Item=T>) |
Le tableau B-5 montre les symboles qui apparaissent dans le contexte de la contrainte de paramètres de types génériques avec des limites de traits.
Tableau B-5 : les contraintes de limites de traits
| Symbole | Explication |
|---|---|
T: U | Le paramètre générique T est contraint aux types qui implémentent U |
T: 'a | Le type générique T doit vivre au moins aussi longtemps que la durée de vie 'a (le type ne peut pas contenir transitivement de références avec des durées de vie plus courtes que 'a) |
T: 'static | Le type générique T ne contient pas d’autres références empruntées que des références 'static |
'b: 'a | La durée de vie générique 'b doit vivre au moins aussi longtemps que la durée de vie 'a |
T: ?Sized | Autorise le paramètre de type générique à être un type à taille dynamique |
'a + trait, trait + trait | Contrainte de type composée |
Le tableau B-6 montre les symboles qui apparaissent dans le contexte de l’appel ou de la définition de macros et de la spécification d’attributs sur un élément.
Tableau B-6 : les macros et les attributs
| Symbole | Explication |
|---|---|
#[meta] | Attribut externe |
#![meta] | Attribut interne |
$ident | Substitution de macro |
$ident:kind | Métavariable de macro |
$(...)... | Répétition de macro |
ident!(...), ident!{...}, ident![...] | Invocation de macro |
Le tableau B-7 montre les symboles qui créent des commentaires.
Tableau B-7 : les commentaires
| Symbole | Explication |
|---|---|
// | Commentaire de ligne |
//! | Commentaire de documentation interne |
/// | Commentaire de documentation externe |
/*...*/ | Commentaire de bloc |
/*!...*/ | Commentaire de documentation interne de bloc |
/**...*/ | Commentaire de documentation externe de bloc |
Le tableau B-8 montre les contextes dans lesquels les parenthèses sont utilisées.
Tableau B-8 : les parenthèses
| Symbole | Explication |
|---|---|
() | Tuple vide (aussi appelé unit), aussi bien en littéral qu’en type |
(expr) | Expression entre parenthèses |
(expr,) | Expression de tuple à un seul élément |
(type,) | Type de tuple à un seul élément |
(expr, ...) | Expression de tuple |
(type, ...) | Type de tuple |
expr(expr, ...) | Appel de fonction ; utilisé aussi pour initialiser les struct tuples et les variantes d’enum tuples |
Le tableau B-9 montre les contextes dans lesquels les accolades sont utilisées.
Tableau B-9 : les accolades
| Contexte | Explication |
|---|---|
{...} | Expression de bloc |
Type {...} | Littéral de structure |
Le tableau B-10 montre les contextes dans lesquels les crochets sont utilisés.
Tableau B-10 : les crochets
| Contexte | Explication |
|---|---|
[...] | Littéral de tableau |
[expr; len] | Littéral de tableau contenant len copies de expr |
[type; len] | Type de tableau contenant len instances de type |
expr[expr] | Indexation de collection ; surchargeable (Index, IndexMut) |
expr[..], expr[a..], expr[..b], expr[a..b] | Indexation de collection simulant un découpage de collection, en utilisant Range, RangeFrom, RangeTo ou RangeFull comme “index” |
C - Les traits dérivables
Annexe C : Les traits dérivables
À plusieurs endroits dans ce livre, nous avons abordé l’attribut derive, que vous pouvez appliquer à une définition de structure ou d’énumération. L’attribut derive génère du code qui implémente un trait avec sa propre implémentation par défaut sur le type que vous avez annoté avec la syntaxe derive.
Dans cette annexe, nous fournissons une référence de tous les traits de la bibliothèque standard que vous pouvez utiliser avec derive. Chaque section couvre :
- Quels opérateurs et méthodes la dérivation de ce trait activera
- Ce que fait l’implémentation du trait fournie par
derive - Ce que l’implémentation du trait signifie pour le type
- Les conditions dans lesquelles vous êtes autorisé ou non à implémenter le trait
- Des exemples d’opérations qui nécessitent le trait
Si vous souhaitez un comportement différent de celui fourni par l’attribut derive, consultez la documentation de la bibliothèque standard pour chaque trait afin d’obtenir des détails sur la manière de les implémenter manuellement.
Les traits listés ici sont les seuls définis par la bibliothèque standard qui peuvent être implémentés sur vos types en utilisant derive. Les autres traits définis dans la bibliothèque standard n’ont pas de comportement par défaut pertinent, c’est donc à vous de les implémenter de la manière qui correspond à ce que vous essayez d’accomplir.
Un exemple de trait qui ne peut pas être dérivé est Display, qui gère le formatage pour les utilisateurs finaux. Vous devriez toujours réfléchir à la manière appropriée d’afficher un type pour un utilisateur final. Quelles parties du type un utilisateur final devrait-il pouvoir voir ? Quelles parties trouverait-il pertinentes ? Quel format des données serait le plus pertinent pour lui ? Le compilateur Rust n’a pas cette connaissance, il ne peut donc pas fournir un comportement par défaut approprié pour vous.
La liste des traits dérivables fournie dans cette annexe n’est pas exhaustive : les bibliothèques peuvent implémenter derive pour leurs propres traits, ce qui rend la liste des traits utilisables avec derive véritablement ouverte. L’implémentation de derive implique l’utilisation d’une macro procédurale, qui est traitée dans la section « Les macros derive personnalisées » du chapitre 20.
Debug pour l’affichage destiné aux développeurs
Le trait Debug activé le formatage de débogage dans les chaînes de formatage, que vous indiquez en ajoutant :? à l’intérieur des espaces réservés {}.
Le trait Debug vous permet d’afficher des instances d’un type à des fins de débogage, afin que vous et les autres développeurs utilisant votre type puissiez inspecter une instance à un moment précis de l’exécution d’un programme.
Le trait Debug est requis, par exemple, lors de l’utilisation de la macro assert_eq!. Cette macro affiche les valeurs des instances passées en arguments si l’assertion d’égalité échoue, afin que les développeurs puissent voir pourquoi les deux instances n’étaient pas égales.
PartialEq et Eq pour les comparaisons d’égalité
Le trait PartialEq vous permet de comparer des instances d’un type pour vérifier l’égalité et activé l’utilisation des opérateurs == et !=.
Dériver PartialEq implémente la méthode eq. Lorsque PartialEq est dérivé sur des structures, deux instances sont égales uniquement si tous les champs sont égaux, et les instances ne sont pas égales si un quelconque champ n’est pas égal. Lorsqu’il est dérivé sur des énumérations, chaque variante est égale à elle-même et différente des autres variantes.
Le trait PartialEq est requis, par exemple, lors de l’utilisation de la macro assert_eq!, qui doit pouvoir comparer deux instances d’un type pour vérifier l’égalité.
Le trait Eq n’a pas de méthodes. Son objectif est de signaler que pour chaque valeur du type annoté, la valeur est égale à elle-même. Le trait Eq ne peut être appliqué qu’aux types qui implémentent également PartialEq, bien que tous les types qui implémentent PartialEq ne puissent pas implémenter Eq. Un exemple est celui des types de nombres à virgule flottante : l’implémentation des nombres à virgule flottante stipule que deux instances de la valeur « pas un nombre » (NaN) ne sont pas égales entre elles.
Un exemple où Eq est requis est pour les clés d’un HashMap<K, V>, afin que le HashMap<K, V> puisse déterminer si deux clés sont identiques.
PartialOrd et Ord pour les comparaisons d’ordre
Le trait PartialOrd vous permet de comparer des instances d’un type à des fins de tri. Un type qui implémente PartialOrd peut être utilisé avec les opérateurs <, >, <= et >=. Vous ne pouvez appliquer le trait PartialOrd qu’aux types qui implémentent également PartialEq.
Dériver PartialOrd implémente la méthode partial_cmp, qui retourné un Option<Ordering> qui sera None lorsque les valeurs fournies ne produisent pas d’ordre. Un exemple de valeur qui ne produit pas d’ordre, même si la plupart des valeurs de ce type peuvent être comparées, est la valeur à virgule flottante NaN. Appeler partial_cmp avec n’importe quel nombre à virgule flottante et la valeur à virgule flottante NaN retournera None.
Lorsqu’il est dérivé sur des structures, PartialOrd compare deux instances en comparant la valeur de chaque champ dans l’ordre dans lequel les champs apparaissent dans la définition de la structure. Lorsqu’il est dérivé sur des énumérations, les variantes de l’énumération déclarées plus tôt dans la définition sont considérées comme inférieures aux variantes listées après.
Le trait PartialOrd est requis, par exemple, pour la méthode gen_range du crate rand qui génère une valeur aléatoire dans l’intervalle spécifié par une expression d’intervalle.
Le trait Ord vous permet de savoir que pour deux valeurs quelconques du type annoté, un ordre valide existera. Le trait Ord implémente la méthode cmp, qui retourné un Ordering plutôt qu’un Option<Ordering> car un ordre valide sera toujours possible. Vous ne pouvez appliquer le trait Ord qu’aux types qui implémentent également PartialOrd et Eq (et Eq nécessite PartialEq). Lorsqu’il est dérivé sur des structures et des énumérations, cmp se comporte de la même manière que l’implémentation dérivée de partial_cmp avec PartialOrd.
Un exemple où Ord est requis est lors du stockage de valeurs dans un BTreeSet<T>, une structure de données qui stocké les données en fonction de l’ordre de tri des valeurs.
Clone et Copy pour dupliquer des valeurs
Le trait Clone vous permet de créer explicitement une copie en profondeur d’une valeur, et le processus de duplication peut impliquer l’exécution de code arbitraire et la copie de données du tas. Consultez la section « Les variables et les données interagissant avec Clone » du chapitre 4 pour plus d’informations sur Clone.
Dériver Clone implémente la méthode clone, qui, lorsqu’elle est implémentée pour le type entier, appelle clone sur chacune des parties du type. Cela signifie que tous les champs ou valeurs du type doivent également implémenter Clone pour pouvoir dériver Clone.
Un exemple où Clone est requis est lors de l’appel de la méthode to_vec sur une slice. La slice ne possède pas les instances du type qu’elle contient, mais le vecteur retourné par to_vec devra posséder ses instances, donc to_vec appelle clone sur chaque élément. Ainsi, le type stocké dans la slice doit implémenter Clone.
Le trait Copy vous permet de dupliquer une valeur en copiant uniquement les bits stockés sur la pile ; aucun code arbitraire n’est nécessaire. Consultez la section « Les données uniquement sur la pile : Copy » du chapitre 4 pour plus d’informations sur Copy.
Le trait Copy ne définit aucune méthode afin d’empêcher les développeurs de surcharger ces méthodes et de violer l’hypothèse qu’aucun code arbitraire n’est exécuté. De cette façon, tous les développeurs peuvent supposer que la copie d’une valeur sera très rapide.
Vous pouvez dériver Copy sur tout type dont toutes les parties implémentent Copy. Un type qui implémente Copy doit également implémenter Clone car un type qui implémente Copy à une implémentation triviale de Clone qui effectue la même tâche que Copy.
Le trait Copy est rarement requis ; les types qui implémentent Copy disposent d’optimisations, ce qui signifie que vous n’avez pas besoin d’appeler clone, ce qui rend le code plus concis.
Tout ce qui est possible avec Copy peut également être accompli avec Clone, mais le code pourrait être plus lent ou devoir utiliser clone par endroits.
Hash pour associer une valeur à une valeur de taille fixe
Le trait Hash vous permet de prendre une instance d’un type de taille arbitraire et d’associer cette instance à une valeur de taille fixe en utilisant une fonction de hachage. Dériver Hash implémente la méthode hash. L’implémentation dérivée de la méthode hash combine le résultat de l’appel de hash sur chacune des parties du type, ce qui signifie que tous les champs ou valeurs doivent également implémenter Hash pour pouvoir dériver Hash.
Un exemple où Hash est requis est lors du stockage des clés dans un HashMap<K, V> pour stocker des données efficacement.
Default pour les valeurs par défaut
Le trait Default vous permet de créer une valeur par défaut pour un type. Dériver Default implémente la fonction default. L’implémentation dérivée de la fonction default appelle la fonction default sur chaque partie du type, ce qui signifie que tous les champs ou valeurs du type doivent également implémenter Default pour pouvoir dériver Default.
La fonction Default::default est couramment utilisée en combinaison avec la syntaxe de mise à jour de structure abordée dans la section « Créer des instances à partir d’autres instances avec la syntaxe de mise à jour de structure » du chapitre 5. Vous pouvez personnaliser quelques champs d’une structure puis définir et utiliser une valeur par défaut pour le reste des champs en utilisant ..Default::default().
Le trait Default est requis lorsque vous utilisez la méthode unwrap_or_default sur des instances d’Option<T>, par exemple. Si l’Option<T> est None, la méthode unwrap_or_default retournera le résultat de Default::default pour le type T stocké dans l’Option<T>.
D - Les outils de développement utiles
Annexe D : outils de développement utiles
Dans cette annexe, nous présentons quelques outils de développement utiles fournis par le projet Rust. Nous verrons le formatage automatique, des moyens rapides d’appliquer des corrections d’avertissements, un linter, et l’intégration avec les IDE.
Le formatage automatique avec rustfmt
L’outil rustfmt reformate votre code selon le style de code de la communauté. De nombreux projets collaboratifs utilisent rustfmt pour éviter les débats sur le style à utiliser lors de l’écriture de Rust : tout le monde formate son code en utilisant cet outil.
Les installations de Rust incluent rustfmt par défaut, vous devriez donc déjà avoir les programmes rustfmt et cargo-fmt sur votre système. Ces deux commandes sont analogues à rustc et cargo dans le sens où rustfmt offre un contrôle plus fin et cargo-fmt comprend les conventions d’un projet qui utilise Cargo. Pour formater n’importe quel projet Cargo, saisissez la commande suivante :
$ cargo fmt
L’exécution de cette commande reformate tout le code Rust dans la crate actuelle. Cela ne devrait modifier que le style du code, pas sa sémantique. Pour plus d’informations sur rustfmt, consultez sa documentation.
Corriger votre code avec rustfix
L’outil rustfix est inclus avec les installations de Rust et peut automatiquement corriger les avertissements du compilateur qui ont une façon claire de résoudre le problème, ce qui est probablement ce que vous souhaitez. Vous avez probablement déjà vu des avertissements du compilateur. Par exemple, considérez ce code :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let mut x = 42;
println!("{x}");
}Ici, nous définissons la variable x comme mutable, mais nous ne la modifions jamais en réalité. Rust nous avertit à ce sujet :
$ cargo build
Compiling myprogram v0.1.0 (file:///projects/myprogram)
warning: variable does not need to be mutable
--> src/main.rs:2:9
|
2 | let mut x = 0;
| ----^
| |
| help: remove this `mut`
|
= note: `#[warn(unused_mut)]` on by default
L’avertissement suggère de supprimer le mot-clé mut. Nous pouvons appliquer automatiquement cette suggestion en utilisant l’outil rustfix en exécutant la commande cargo fix :
$ cargo fix
Checking myprogram v0.1.0 (file:///projects/myprogram)
Fixing src/main.rs (1 fix)
Finished dev [unoptimized + debuginfo] target(s) in 0.59s
Lorsque nous regardons à nouveau src/main.rs, nous constatons que cargo fix a modifié le code :
Fichier : src/main.rs rust {{#rustdoc_include ../listings/ch05-using-structs-to-structure-related-data/no-listing-03-associated-functions/src/main.rs:here}}
fn main() {
let x = 42;
println!("{x}");
}La variable x est maintenant immuable, et l’avertissement n’apparaît plus.
Vous pouvez également utiliser la commande cargo fix pour faire migrer votre code entre différentes éditions de Rust. Les éditions sont traitées dans l’annexe E.
Plus de lints avec Clippy
L’outil Clippy est une collection de lints qui analysent votre code afin que vous puissiez détecter les erreurs courantes et améliorer votre code Rust. Clippy est inclus avec les installations standard de Rust.
Pour exécuter les lints de Clippy sur n’importe quel projet Cargo, saisissez la commande suivante :
$ cargo clippy
Par exemple, imaginons que vous écrivez un programme qui utilise une approximation d’une constante mathematique, comme pi, comme le fait ce programme :
fn main() {
let x = 3.1415;
let r = 8.0;
println!("the area of the circle is {}", x * r * r);
}L’exécution de cargo clippy sur ce projet produit cette erreur :
error: approximate value of `f{32, 64}::consts::PI` found
--> src/main.rs:2:13
|
2 | let x = 3.1415;
| ^^^^^^
|
= note: `#[deny(clippy::approx_constant)]` on by default
= help: consider using the constant directly
= help: for further information visit https://rust-lang.github.io/rust-clippy/master/index.html#approx_constant
Cette erreur vous indique que Rust dispose déjà d’une constante PI plus précise, et que votre programme serait plus correct si vous utilisiez cette constante à la place. Vous modifieriez alors votre code pour utiliser la constante PI.
Le code suivant ne produit aucune erreur ni avertissement de la part de Clippy :
fn main() {
let x = std::f64::consts::PI;
let r = 8.0;
println!("the area of the circle is {}", x * r * r);
}Pour plus d’informations sur Clippy, consultez sa documentation.
Intégration avec les IDE en utilisant rust-analyzer
Pour faciliter l’intégration avec les IDE, la communauté Rust recommande d’utiliser rust-analyzer. Cet outil est un ensemble d’utilitaires centrés sur le compilateur qui utilisent le Language Server Protocol, une spécification permettant aux IDE et aux langages de programmation de communiquer entre eux. Différents clients peuvent utiliser rust-analyzer, comme le plugin Rust analyzer pour Visual Studio Code.
Visitez la page d’accueil du projet rust-analyzer pour les instructions d’installation, puis installez le support du serveur de langage dans votre IDE. Votre IDE disposera alors de fonctionnalités telles que l’autocomplétion, la navigation vers la définition, et l’affichage des erreurs en ligne.
E - Les éditions
Annexe E : Les éditions
Au chapitre 1, vous avez vu que cargo new ajouté un peu de métadonnées à votre fichier Cargo.toml concernant une édition. Cette annexe explique ce que cela signifie !
Le langage Rust et son compilateur ont un cycle de publication de six semaines, ce qui signifie que les utilisateurs reçoivent un flux constant de nouvelles fonctionnalités. D’autres langages de programmation publient des changements plus importants moins souvent ; Rust publié des mises à jour plus petites plus fréquemment. Au bout d’un moment, tous ces petits changements s’accumulent. Mais d’une version à l’autre, il peut être difficile de prendre du recul et de dire : “Wow, entre Rust 1.10 et Rust 1.31, Rust a beaucoup changé !”
Environ tous les trois ans, l’équipe Rust produit une nouvelle édition de Rust. Chaque édition rassemble les fonctionnalités qui ont été intégrées dans un ensemble clair avec une documentation et des outils entièrement mis à jour. Les nouvelles éditions sont publiées dans le cadre du processus habituel de publication de six semaines.
Les éditions servent des objectifs différents selon les personnes :
- Pour les utilisateurs actifs de Rust, une nouvelle édition rassemble les changements incrémentaux dans un ensemble facile à comprendre.
- Pour les non-utilisateurs, une nouvelle édition signale que des avancées majeures ont été intégrées, ce qui pourrait justifier de reconsidérer Rust.
- Pour ceux qui développent Rust, une nouvelle édition fournit un point de ralliement pour le projet dans son ensemble.
Au moment de la rédaction de ce livre, quatre éditions de Rust sont disponibles : Rust 2015, Rust 2018, Rust 2021 et Rust 2024. Ce livre est écrit en utilisant les conventions de l’édition Rust 2024.
La clé edition dans Cargo.toml indique quelle édition le compilateur doit utiliser pour votre code. Si la clé n’existe pas, Rust utilise 2015 comme valeur d’édition pour des raisons de compatibilité ascendante.
Chaque projet peut opter pour une édition autre que l’édition 2015 par défaut. Les éditions peuvent contenir des changements incompatibles, comme l’ajout d’un nouveau mot-clé qui entre en conflit avec des identifiants dans le code. Cependant, à moins que vous n’optiez pour ces changements, votre code continuera à compiler même si vous mettez à jour la version du compilateur Rust que vous utilisez.
Toutes les versions du compilateur Rust prennent en charge toute édition qui existait avant la publication de ce compilateur, et elles peuvent lier ensemble des crates de n’importe quelles éditions prises en charge. Les changements d’édition n’affectent que la façon dont le compilateur analyse initialement le code. Par conséquent, si vous utilisez Rust 2015 et que l’une de vos dépendances utilise Rust 2018, votre projet compilera et pourra utiliser cette dépendance. La situation inverse, où votre projet utilise Rust 2018 et qu’une dépendance utilise Rust 2015, fonctionne également.
Pour être clair : la plupart des fonctionnalités seront disponibles sur toutes les éditions. Les développeurs utilisant n’importe quelle édition de Rust continueront à voir des améliorations au fil des nouvelles versions stables. Cependant, dans certains cas, principalement lorsque de nouveaux mots-clés sont ajoutés, certaines nouvelles fonctionnalités pourraient n’être disponibles que dans les éditions ultérieures. Vous devrez changer d’édition si vous souhaitez profiter de ces fonctionnalités.
For more details, see The Rust Edition Guide. This is a complete book that enumerates the differences between editions and explains how to automatically upgrade your code to a new edition via cargo fix.
F - Les traductions du livre
Annexe F : Traductions du livre
Pour des ressources dans des langues autres que l’anglais. La plupart sont encore en cours ; consultez le label Translations pour nous aider ou nous signaler une nouvelle traduction !
- Português (BR)
- Português (PT)
- 简体中文 : KaiserY/trpl-zh-cn, gnu4cn/rust-lang-Zh_CN
- 正體中文
- Українська
- Español, alternate, Español por RustLangES
- Русский
- 한국어
- 日本語
- Français
- Polski
- Cebuano
- Tagalog
- Esperanto
- ελληνική
- Svenska
- Farsi, Persian (FA)
- Deutsch
- हिंदी
- ไทย
- Danske
- O’zbek
- Tiếng Việt
- Italiano
- বাংলা
G - Comment Rust est conçu et « Rust Nightly »
Annexe G - Comment Rust est conçu et « Rust Nightly »
Cette annexe explique comment Rust est conçu et comment cela vous affecte en tant que développeur Rust.
La stabilité sans la stagnation
En tant que langage, Rust se soucie énormément de la stabilité de votre code. Nous voulons que Rust soit une fondation solide comme le roc sur laquelle vous pouvez construire, et si les choses changeaient constamment, ce serait impossible. En même temps, si nous ne pouvons pas expérimenter de nouvelles fonctionnalités, nous risquons de ne découvrir des défauts importants qu’après leur publication, lorsqu’il n’est plus possible de les modifier.
Notre solution à ce problème est ce que nous appelons “la stabilité sans la stagnation”, et notre principe directeur est le suivant : vous ne devriez jamais avoir à craindre de passer à une nouvelle version de Rust stable. Chaque mise à jour devrait être indolore, mais devrait aussi vous apporter de nouvelles fonctionnalités, moins de bogues et des temps de compilation plus rapides.
Tchou, tchou ! Les canaux de publication et le modèle du train
Le développement de Rust fonctionne selon un calendrier de train. C’est-à-dire que tout le développement est effectué dans la branche principale du dépôt Rust. Les publications suivent un modèle de train de publication logiciel, qui a été utilisé par Cisco IOS et d’autres projets logiciels. Il existe trois canaux de publication pour Rust :
- Nightly
- Beta
- Stable
La plupart des développeurs Rust utilisent principalement le canal stable, mais ceux qui veulent essayer de nouvelles fonctionnalités expérimentales peuvent utiliser nightly ou beta.
Voici un exemple du fonctionnement du processus de développement et de publication : supposons que l’équipe Rust travaille sur la publication de Rust 1.5. Cette publication a eu lieu en décembre 2015, mais elle nous fournira des numéros de version réalistes. Une nouvelle fonctionnalité est ajoutée à Rust : un nouveau commit arrive sur la branche principale. Chaque nuit, une nouvelle version nightly de Rust est produite. Chaque jour est un jour de publication, et ces publications sont créées automatiquement par notre infrastructure de publication. Ainsi, au fil du temps, nos publications ressemblent à ceci, une fois par nuit :
nightly: * - - * - - *
Toutes les six semaines, il est temps de préparer une nouvelle publication ! La branche beta du dépôt Rust se sépare de la branche principale utilisée par nightly. Maintenant, il y a deux publications :
nightly: * - - * - - *
|
beta: *
La plupart des utilisateurs de Rust n’utilisent pas activement les versions beta, mais testent avec la version beta dans leur système d’intégration continue pour aider Rust à découvrir d’éventuelles régressions. Entre-temps, il y a toujours une publication nightly chaque nuit :
nightly: * - - * - - * - - * - - *
|
beta: *
Disons qu’une régression est trouvée. Heureusement que nous avons eu le temps de tester la version beta avant que la régression ne se glisse dans une version stable ! Le correctif est appliqué à la branche principale, de sorte que nightly est corrigé, puis le correctif est rétroporté sur la branche beta, et une nouvelle version beta est produite :
nightly: * - - * - - * - - * - - * - - *
|
beta: * - - - - - - - - *
Six semaines après la création de la première beta, il est temps pour une publication stable ! La branche stable est produite à partir de la branche beta :
nightly: * - - * - - * - - * - - * - - * - * - *
|
beta: * - - - - - - - - *
|
stable: *
Hourra ! Rust 1.5 est terminé ! Cependant, nous avons oublié une chose : comme les six semaines se sont écoulées, nous avons aussi besoin d’une nouvelle beta de la prochaine version de Rust, la 1.6. Donc après que stable se sépare de beta, la prochaine version de beta se sépare à nouveau de nightly :
nightly: * - - * - - * - - * - - * - - * - * - *
| |
beta: * - - - - - - - - * *
|
stable: *
C’est ce qu’on appelle le “modèle du train” car toutes les six semaines, une publication “quitte la gare”, mais doit encore effectuer un voyage à travers le canal beta avant d’arriver en tant que publication stable.
Rust publié une nouvelle version toutes les six semaines, comme une horloge. Si vous connaissez la date d’une publication de Rust, vous pouvez connaître la date de la suivante : c’est six semaines plus tard. Un avantage agréable d’avoir des publications programmées toutes les six semaines est que le prochain train arrive bientôt. Si une fonctionnalité manque une publication particulière, il n’y a pas lieu de s’inquiéter : une autre arrivera dans peu de temps ! Cela aide à réduire la pression pour glisser des fonctionnalités potentiellement non finalisées juste avant la date limite de publication.
Grâce à ce processus, vous pouvez toujours essayer la prochaine version de Rust et vérifier par vous-même qu’il est facile de la mettre à jour : si une version beta ne fonctionne pas comme prévu, vous pouvez le signaler à l’équipe et obtenir un correctif avant la prochaine publication stable ! Les problèmes dans une version beta sont relativement rares, mais rustc reste un logiciel, et les bogues existent.
Durée de maintenance
Le projet Rust prend en charge la version stable la plus récente. Lorsqu’une nouvelle version stable est publiée, l’ancienne version atteint sa fin de vie (EOL). Cela signifie que chaque version est prise en charge pendant six semaines.
Les fonctionnalités instables
Il y à un autre aspect important de ce modèle de publication : les fonctionnalités instables. Rust utilise une technique appelée “feature flags” pour déterminer quelles fonctionnalités sont activées dans une publication donnée. Si une nouvelle fonctionnalité est en cours de développement actif, elle arrive sur la branche principale, et donc dans nightly, mais derrière un feature flag. Si vous, en tant qu’utilisateur, souhaitez essayer la fonctionnalité en cours de développement, vous le pouvez, mais vous devez utiliser une version nightly de Rust et annoter votre code source avec le flag approprié pour l’activer.
Si vous utilisez une version beta ou stable de Rust, vous ne pouvez utiliser aucun feature flag. C’est la clé qui nous permet d’obtenir une utilisation pratique des nouvelles fonctionnalités avant de les déclarer stables pour toujours. Ceux qui souhaitent opter pour les toutes dernières nouveautés peuvent le faire, et ceux qui veulent une expérience solide comme le roc peuvent rester sur stable en sachant que leur code ne cassera pas. La stabilité sans la stagnation.
Ce livre ne contient que des informations sur les fonctionnalités stables, car les fonctionnalités en cours de développement changent encore, et elles seront certainement différentes entre le moment où ce livre a été écrit et celui où elles seront activées dans les versions stables. Vous pouvez trouver la documentation des fonctionnalités réservées à nightly en ligne.
Rustup et le rôle de Rust Nightly
Rustup facilite le passage entre les différents canaux de publication de Rust, que ce soit globalement ou par projet. Par défaut, vous aurez Rust stable installé. Pour installer nightly, par exemple :
$ rustup toolchain install nightly
Vous pouvez également voir toutes les toolchains (versions de Rust et composants associés) que vous avez installées avec rustup. Voici un exemple sur l’ordinateur Windows de l’un des auteurs :
> rustup toolchain list
stable-x86_64-pc-windows-msvc (default)
beta-x86_64-pc-windows-msvc
nightly-x86_64-pc-windows-msvc
Comme vous pouvez le voir, la toolchain stable est celle par défaut. La plupart des utilisateurs de Rust utilisent stable la plupart du temps. Vous pourriez vouloir utiliser stable la plupart du temps, mais utiliser nightly sur un projet spécifique, parce qu’une fonctionnalité de pointe vous intéresse. Pour ce faire, vous pouvez utiliser rustup override dans le répertoire de ce projet pour définir la toolchain nightly comme celle que rustup doit utiliser lorsque vous êtes dans ce répertoire :
$ cd ~/projects/needs-nightly
$ rustup override set nightly
Désormais, chaque fois que vous appelez rustc ou cargo à l’intérieur de ~/projects/needs-nightly, rustup s’assurera que vous utilisez Rust nightly, plutôt que votre Rust stable par défaut. C’est très pratique quand vous avez beaucoup de projets Rust !
Le processus RFC et les équipes
Alors comment se renseigner sur ces nouvelles fonctionnalités ? Le modèle de développement de Rust suit un processus de Request For Comments (RFC). Si vous souhaitez une amélioration dans Rust, vous pouvez rédiger une proposition, appelée RFC.
N’importe qui peut écrire des RFC pour améliorer Rust, et les propositions sont examinées et discutées par l’équipe Rust, qui est composée de nombreuses sous-équipes thématiques. Il y à une liste complète des équipes sur le site web de Rust, qui inclut des équipes pour chaque domaine du projet : conception du langage, implémentation du compilateur, infrastructure, documentation, et plus encore. L’équipe appropriée lit la proposition et les commentaires, rédige ses propres commentaires, et finalement, un consensus est atteint pour accepter ou rejeter la fonctionnalité.
Si la fonctionnalité est acceptée, une issue est ouverte sur le dépôt Rust, et quelqu’un peut l’implémenter. La personne qui l’implémente peut très bien ne pas être celle qui a proposé la fonctionnalité en premier lieu ! Lorsque l’implémentation est prête, elle arrive sur la branche principale derrière un feature gate, comme nous l’avons discuté dans la section « Les fonctionnalités instables ».
Après un certain temps, une fois que les développeurs Rust qui utilisent les versions nightly ont pu essayer la nouvelle fonctionnalité, les membres de l’équipe discutent de la fonctionnalité, de son fonctionnement sur nightly, et décident si elle doit intégrer Rust stable ou non. Si la décision est d’aller de l’avant, le feature gate est supprimé, et la fonctionnalité est désormais considérée comme stable ! Elle prend le train vers une nouvelle publication stable de Rust.